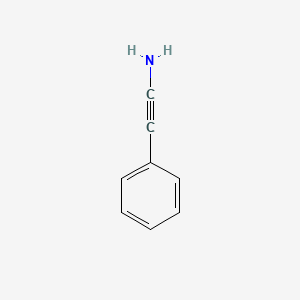
2-Phenylethynamine
Numéro de catalogue B3057851
Poids moléculaire: 117.15 g/mol
Clé InChI: GTCLFEMMPGBNOI-UHFFFAOYSA-N
Attention: Uniquement pour un usage de recherche. Non destiné à un usage humain ou vétérinaire.
Patent
US06100429
Procedure details


Sabourin, Prepr. Div. Pet. Chem., Am. Chem. Soc., vol. 24, pp. 233-239 discloses the preparation of 2-methyl-4-(3-aminophenyl)-3-butyn-2-ol (an aminophenylacetylene) and 3-aminophenylacetylene in two and three steps, respectively, from 3-bromonitrobenzene and 2-methyl-3-butyn-2-ol. In the first step, 3-bromonitrobenzene and 2-methyl-3-butyn-2-ol were reacted in the presence of a catalyst system of bis(triphenylphosphine)palladium dichloride, additional triphenylphosphine, and cuprous iodide in triethylamine solvent at the reflux temperature to obtain 2-methyl-4-(3-nitrophenyl)-3-butyn-2-ol. In the second step, this nitrophenylacetylene was hydrogenated in isopropanol in the presence of a Ru/Al2 03 catalyst to obtain 2-methyl-4-(3-aminophenyl)-3-butyn-2-ol. This reference states that is essential to stop the hydrogenation reaction at the stoichiometric point because reduction of the triple bond ensues. In the third step, this aminophenylacetylene was heated in toluene in the presence of sodium hydroxide pellets, with removal of the acetone co-product by distillation, to obtain 3-aminophenylacetylene.

[Compound]
Name
cuprous iodide
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Four
Quantity
0 (± 1) mol
Type
catalyst
Reaction Step Four

Identifiers
|
REACTION_CXSMILES
|
[CH3:1][C:2]([OH:13])([C:4]#[C:5]C1C=CC=C(N)C=1)[CH3:3].NC#CC1C=CC=CC=1.NC1C=C(C#C)C=CC=1.Br[C:33]1[CH:34]=[C:35]([N+:39]([O-:41])=[O:40])[CH:36]=[CH:37][CH:38]=1.CC(O)(C#C)C.C1(P(C2C=CC=CC=2)C2C=CC=CC=2)C=CC=CC=1>C(N(CC)CC)C.Cl[Pd](Cl)([P](C1C=CC=CC=1)(C1C=CC=CC=1)C1C=CC=CC=1)[P](C1C=CC=CC=1)(C1C=CC=CC=1)C1C=CC=CC=1>[CH3:1][C:2]([OH:13])([C:4]#[C:5][C:33]1[CH:38]=[CH:37][CH:36]=[C:35]([N+:39]([O-:41])=[O:40])[CH:34]=1)[CH3:3] |^1:76,95|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CC(C)(C#CC1=CC(=CC=C1)N)O
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
NC#CC1=CC=CC=C1
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
NC=1C=C(C=CC1)C#C
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
BrC=1C=C(C=CC1)[N+](=O)[O-]
|
Step Three
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CC(C)(C#C)O
|
Step Four
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
BrC=1C=C(C=CC1)[N+](=O)[O-]
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CC(C)(C#C)O
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C1(=CC=CC=C1)P(C1=CC=CC=C1)C1=CC=CC=C1
|
[Compound]
|
Name
|
cuprous iodide
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
C(C)N(CC)CC
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
catalyst
|
|
Smiles
|
Cl[Pd]([P](C1=CC=CC=C1)(C2=CC=CC=C2)C3=CC=CC=C3)([P](C4=CC=CC=C4)(C5=CC=CC=C5)C6=CC=CC=C6)Cl
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
CC(C)(C#CC1=CC(=CC=C1)[N+](=O)[O-])O
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
