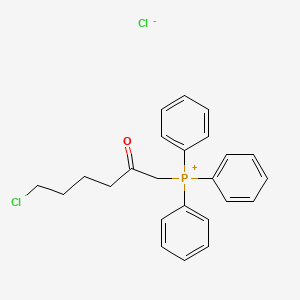
(6-Chloro-2-oxohexyl) triphenylphosphonium chloride
Numéro de catalogue B8466807
Poids moléculaire: 431.3 g/mol
Clé InChI: VAWBQEAZOIRDRO-UHFFFAOYSA-M
Attention: Uniquement pour un usage de recherche. Non destiné à un usage humain ou vétérinaire.
Patent
US04041050
Procedure details


The latter reactions are exemplified by the cleavage of δ-valerolactone with zinc chloride and thionyl chloride to produce 5-chlorovaleryl chloride, reaction of that acid chloride with diazomethane, followed by treatment of the resulting diazomethyl ketone with hydrochloric acid to yield 1,6-dichloro-2-hexanone, and reaction of that ketone with triphenylphosphine to afford (6-chloro-2-oxohexyl)triphenylphosphonium chloride. This product is converted to (5-chloropentanoylmethylene)triphenyl phosphorane by reaction with aqueous sodium hydroxide. Condensation of that phosphorane with the aforementioned 3α-(tetrahydropyran-2-yloxy)-2β-formyl-5-oxocyclopentane-1α-heptanoic acid affords a mixture of stereoisomers, which are separated by chromatographic techniques to afford, as the major product, 3α-(tetrahydropyran-2-yloxy)-2β-(7-chloro-3-oxo-1-heptenyl)-5-oxocyclopentane-1α-heptanoic acid. Removal of the tetrahydropyran-2-yl group is effected by reaction with acetic acid in aqueous tetrahydrofuran, thus affording 3α-hydroxy-2β-(7-chloro-3-oxo-1-heptenyl)-5-oxocyclopentane-1α-heptanoic acid.

[Compound]
Name
acid chloride
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Four
Name
diazomethyl ketone
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Five
[Compound]
Name
ketone
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Seven

Identifiers
|
REACTION_CXSMILES
|
C1(=O)OCCCC1.S(Cl)([Cl:10])=O.ClCCCCC(Cl)=O.[N+](=C)=[N-].[N+](=CC(C=[N+]=[N-])=O)=[N-].Cl.Cl[CH2:33][C:34](=[O:40])[CH2:35][CH2:36][CH2:37][CH2:38][Cl:39].[C:41]1([P:47]([C:54]2[CH:59]=[CH:58][CH:57]=[CH:56][CH:55]=2)[C:48]2[CH:53]=[CH:52][CH:51]=[CH:50][CH:49]=2)[CH:46]=[CH:45][CH:44]=[CH:43][CH:42]=1>[Cl-].[Zn+2].[Cl-]>[Cl-:10].[Cl:39][CH2:38][CH2:37][CH2:36][CH2:35][C:34](=[O:40])[CH2:33][P+:47]([C:48]1[CH:49]=[CH:50][CH:51]=[CH:52][CH:53]=1)([C:54]1[CH:59]=[CH:58][CH:57]=[CH:56][CH:55]=1)[C:41]1[CH:42]=[CH:43][CH:44]=[CH:45][CH:46]=1 |f:8.9.10,11.12|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C1(CCCCO1)=O
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
catalyst
|
|
Smiles
|
[Cl-].[Zn+2].[Cl-]
|
Step Three
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
S(=O)(Cl)Cl
|
Step Four
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
ClCCCCC(=O)Cl
|
[Compound]
|
Name
|
acid chloride
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
[N+](=[N-])=C
|
Step Five
|
Name
|
diazomethyl ketone
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
[N+](=[N-])=CC(=O)C=[N+]=[N-]
|
Step Six
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
Cl
|
Step Seven
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
ClCC(CCCCCl)=O
|
[Compound]
|
Name
|
ketone
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C1(=CC=CC=C1)P(C1=CC=CC=C1)C1=CC=CC=C1
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
to produce
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
to yield
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
[Cl-].ClCCCCC(C[P+](C1=CC=CC=C1)(C1=CC=CC=C1)C1=CC=CC=C1)=O
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
