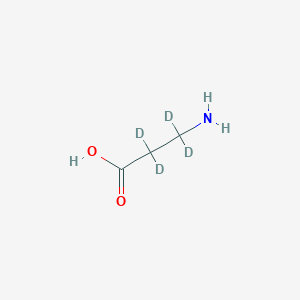
b-Alanine-2,2,3,3-d4
Numéro de catalogue B106953
Poids moléculaire: 93.12 g/mol
Clé InChI: UCMIRNVEIXFBKS-LNLMKGTHSA-N
Attention: Uniquement pour un usage de recherche. Non destiné à un usage humain ou vétérinaire.
Patent
US05591646
Procedure details


Optionally a gel film plate of the type in Example 3 may have a tetrapeptide spacer attached to the substrate. A plate prepared as in Example 3 had Fmoc-beta-alanine (BAla) coupled to it (standard PyBOP+HOBt/NMM procedure, 2 hours). Following thorough DMF washes, the plate was treated with 30% piperidine in DMF (1, 45 minutes). The plate was washed 2 times with DMF, and the piperidine treatments and subsequent washes were pooled and read spectrophotometrically at 301 nm to determine the Fmoc-loading (in this example 2 micromoles per substrate area). Three more coupling cycles were then performed adding Fmoc-epsilon-aminocaproic acid twice, then beta-alanine again to give the final BAla-Aca-BAla spacer arm film plate as used in the preferred embodiment for ASBCL or ASPCL libraries.
[Compound]
Name
tetrapeptide
Quantity
0 (± 1) mol
Type
reactant
Reaction Step One

Name
PyBOP HOBt NMM
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Three

Identifiers
|
REACTION_CXSMILES
|
[C:1]([NH:18][CH2:19][CH2:20][C:21]([OH:23])=[O:22])([O:3][CH2:4][CH:5]1[C:17]2[C:12](=[CH:13][CH:14]=[CH:15][CH:16]=2)[C:11]2[C:6]1=[CH:7][CH:8]=[CH:9][CH:10]=2)=[O:2].C1CN([P+](ON2N=NC3C=CC=CC2=3)(N2CCCC2)N2CCCC2)CC1.F[P-](F)(F)(F)(F)F.C1C=CC2N(O)N=NC=2C=1.CN1CCOCC1.N1CCCCC1>CN(C=O)C>[NH2:18][CH2:19][CH2:20][C:21]([OH:23])=[O:22].[C:1]([NH:18][CH2:19][CH2:20][C:21]([OH:23])=[O:22])([O:3][CH2:4][CH:5]1[C:6]2[C:11](=[CH:10][CH:9]=[CH:8][CH:7]=2)[C:12]2[C:17]1=[CH:16][CH:15]=[CH:14][CH:13]=2)=[O:2] |f:1.2.3.4|
|
Inputs
Step One
[Compound]
|
Name
|
tetrapeptide
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(=O)(OCC1C2=CC=CC=C2C2=CC=CC=C12)NCCC(=O)O
|
Step Three
|
Name
|
PyBOP HOBt NMM
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C1CCN(C1)[P+](N2CCCC2)(N3CCCC3)ON4C5=C(C=CC=C5)N=N4.F[P-](F)(F)(F)(F)F.C=1C=CC2=C(C1)N=NN2O.CN1CCOCC1
|
Step Four
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
N1CCCCC1
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
CN(C)C=O
|
Step Five
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
CN(C)C=O
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
A plate prepared as in Example 3
|
WASH
|
Type
|
WASH
|
|
Details
|
The plate was washed 2 times with DMF
|
ADDITION
|
Type
|
ADDITION
|
|
Details
|
Three more coupling cycles were then performed adding Fmoc-epsilon-aminocaproic acid twice
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
NCCC(=O)O
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C(=O)(OCC1C2=CC=CC=C2C2=CC=CC=C12)NCCC(=O)O
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
Patent
US05591646
Procedure details
Optionally a gel film plate of the type in Example 3 may have a tetrapeptide spacer attached to the substrate. A plate prepared as in Example 3 had Fmoc-beta-alanine (BAla) coupled to it (standard PyBOP+HOBt/NMM procedure, 2 hours). Following thorough DMF washes, the plate was treated with 30% piperidine in DMF (1, 45 minutes). The plate was washed 2 times with DMF, and the piperidine treatments and subsequent washes were pooled and read spectrophotometrically at 301 nm to determine the Fmoc-loading (in this example 2 micromoles per substrate area). Three more coupling cycles were then performed adding Fmoc-epsilon-aminocaproic acid twice, then beta-alanine again to give the final BAla-Aca-BAla spacer arm film plate as used in the preferred embodiment for ASBCL or ASPCL libraries.
[Compound]
Name
tetrapeptide
Quantity
0 (± 1) mol
Type
reactant
Reaction Step One
Name
PyBOP HOBt NMM
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Three
Identifiers
|
REACTION_CXSMILES
|
[C:1]([NH:18][CH2:19][CH2:20][C:21]([OH:23])=[O:22])([O:3][CH2:4][CH:5]1[C:17]2[C:12](=[CH:13][CH:14]=[CH:15][CH:16]=2)[C:11]2[C:6]1=[CH:7][CH:8]=[CH:9][CH:10]=2)=[O:2].C1CN([P+](ON2N=NC3C=CC=CC2=3)(N2CCCC2)N2CCCC2)CC1.F[P-](F)(F)(F)(F)F.C1C=CC2N(O)N=NC=2C=1.CN1CCOCC1.N1CCCCC1>CN(C=O)C>[NH2:18][CH2:19][CH2:20][C:21]([OH:23])=[O:22].[C:1]([NH:18][CH2:19][CH2:20][C:21]([OH:23])=[O:22])([O:3][CH2:4][CH:5]1[C:6]2[C:11](=[CH:10][CH:9]=[CH:8][CH:7]=2)[C:12]2[C:17]1=[CH:16][CH:15]=[CH:14][CH:13]=2)=[O:2] |f:1.2.3.4|
|
Inputs
Step One
[Compound]
|
Name
|
tetrapeptide
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(=O)(OCC1C2=CC=CC=C2C2=CC=CC=C12)NCCC(=O)O
|
Step Three
|
Name
|
PyBOP HOBt NMM
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C1CCN(C1)[P+](N2CCCC2)(N3CCCC3)ON4C5=C(C=CC=C5)N=N4.F[P-](F)(F)(F)(F)F.C=1C=CC2=C(C1)N=NN2O.CN1CCOCC1
|
Step Four
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
N1CCCCC1
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
CN(C)C=O
|
Step Five
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
CN(C)C=O
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
A plate prepared as in Example 3
|
WASH
|
Type
|
WASH
|
|
Details
|
The plate was washed 2 times with DMF
|
ADDITION
|
Type
|
ADDITION
|
|
Details
|
Three more coupling cycles were then performed adding Fmoc-epsilon-aminocaproic acid twice
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
NCCC(=O)O
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C(=O)(OCC1C2=CC=CC=C2C2=CC=CC=C12)NCCC(=O)O
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
Patent
US05591646
Procedure details
Optionally a gel film plate of the type in Example 3 may have a tetrapeptide spacer attached to the substrate. A plate prepared as in Example 3 had Fmoc-beta-alanine (BAla) coupled to it (standard PyBOP+HOBt/NMM procedure, 2 hours). Following thorough DMF washes, the plate was treated with 30% piperidine in DMF (1, 45 minutes). The plate was washed 2 times with DMF, and the piperidine treatments and subsequent washes were pooled and read spectrophotometrically at 301 nm to determine the Fmoc-loading (in this example 2 micromoles per substrate area). Three more coupling cycles were then performed adding Fmoc-epsilon-aminocaproic acid twice, then beta-alanine again to give the final BAla-Aca-BAla spacer arm film plate as used in the preferred embodiment for ASBCL or ASPCL libraries.
[Compound]
Name
tetrapeptide
Quantity
0 (± 1) mol
Type
reactant
Reaction Step One
Name
PyBOP HOBt NMM
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Three
Identifiers
|
REACTION_CXSMILES
|
[C:1]([NH:18][CH2:19][CH2:20][C:21]([OH:23])=[O:22])([O:3][CH2:4][CH:5]1[C:17]2[C:12](=[CH:13][CH:14]=[CH:15][CH:16]=2)[C:11]2[C:6]1=[CH:7][CH:8]=[CH:9][CH:10]=2)=[O:2].C1CN([P+](ON2N=NC3C=CC=CC2=3)(N2CCCC2)N2CCCC2)CC1.F[P-](F)(F)(F)(F)F.C1C=CC2N(O)N=NC=2C=1.CN1CCOCC1.N1CCCCC1>CN(C=O)C>[NH2:18][CH2:19][CH2:20][C:21]([OH:23])=[O:22].[C:1]([NH:18][CH2:19][CH2:20][C:21]([OH:23])=[O:22])([O:3][CH2:4][CH:5]1[C:6]2[C:11](=[CH:10][CH:9]=[CH:8][CH:7]=2)[C:12]2[C:17]1=[CH:16][CH:15]=[CH:14][CH:13]=2)=[O:2] |f:1.2.3.4|
|
Inputs
Step One
[Compound]
|
Name
|
tetrapeptide
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(=O)(OCC1C2=CC=CC=C2C2=CC=CC=C12)NCCC(=O)O
|
Step Three
|
Name
|
PyBOP HOBt NMM
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C1CCN(C1)[P+](N2CCCC2)(N3CCCC3)ON4C5=C(C=CC=C5)N=N4.F[P-](F)(F)(F)(F)F.C=1C=CC2=C(C1)N=NN2O.CN1CCOCC1
|
Step Four
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
N1CCCCC1
|
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
CN(C)C=O
|
Step Five
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
CN(C)C=O
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
A plate prepared as in Example 3
|
WASH
|
Type
|
WASH
|
|
Details
|
The plate was washed 2 times with DMF
|
ADDITION
|
Type
|
ADDITION
|
|
Details
|
Three more coupling cycles were then performed adding Fmoc-epsilon-aminocaproic acid twice
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
NCCC(=O)O
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C(=O)(OCC1C2=CC=CC=C2C2=CC=CC=C12)NCCC(=O)O
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
