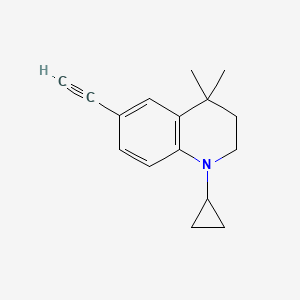
1-cyclopropyl-6-ethynyl-4,4-dimethyl-2,3-dihydroquinoline
Numéro de catalogue B8570675
Poids moléculaire: 225.33 g/mol
Clé InChI: CYADGSZOXJQFMO-UHFFFAOYSA-N
Attention: Uniquement pour un usage de recherche. Non destiné à un usage humain ou vétérinaire.
Patent
US06252090B1
Procedure details


Following general procedure F and using 1-cyclopropyl-6-ethynyl-4,4-dimethyl-1,2,3,4-tetrahydro quinoline (Intermediate 53, 0.11 g, 0.43 mmol), ethyl-4-iodo-benzoate (Reagent A, 0.11 g, 0.9 mmol), triethyl amine (3 mL), tetrahydrofuran(3 mL), copper(I)iodide (0.02 g, 0.1 mmol) and dichlorobis(triphenylphosphine)palladium(II) (0.060 g, 0.085 mmol) followed by flash column chromatography over silica gel (230-400 mesh) using 5-10% ethyl acetate in hexane as the eluent, the title compound was obtained (0.05 g, 31%).
Name
1-cyclopropyl-6-ethynyl-4,4-dimethyl-1,2,3,4-tetrahydro quinoline
Quantity
0.11 g
Type
reactant
Reaction Step One

Name
Intermediate 53
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Three
Name
copper(I)iodide
Quantity
0.02 g
Type
catalyst
Reaction Step Nine

Name
Identifiers
|
REACTION_CXSMILES
|
COC(=O)C1C=CC(C#C[C:12]2[CH:13]=[C:14]([CH:26]3[CH2:28]C3)[C:15]3O[C:19]4(CC4)[CH2:18][C:17]([CH3:24])([CH3:23])[C:16]=3[CH:25]=2)=CC=1F.C(O[C:34](=O)[C:35]1[CH:40]=CC(I)=CC=1)C.C([N:45](CC)CC)C.O1CCCC1>CCCCCC.[Cu]I.Cl[Pd](Cl)([P](C1C=CC=CC=1)(C1C=CC=CC=1)C1C=CC=CC=1)[P](C1C=CC=CC=1)(C1C=CC=CC=1)C1C=CC=CC=1.C(OCC)(=O)C>[CH:35]1([N:45]2[C:25]3[C:16](=[CH:15][C:14]([C:26]#[CH:28])=[CH:13][CH:12]=3)[C:17]([CH3:23])([CH3:24])[CH2:18][CH2:19]2)[CH2:34][CH2:40]1 |^1:65,84|
|
Inputs
Step One
|
Name
|
1-cyclopropyl-6-ethynyl-4,4-dimethyl-1,2,3,4-tetrahydro quinoline
|
|
Quantity
|
0.11 g
|
|
Type
|
reactant
|
|
Smiles
|
COC(C1=C(C=C(C=C1)C#CC=1C=C(C2=C(C(CC3(CC3)O2)(C)C)C1)C1CC1)F)=O
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
C(C)(=O)OCC
|
Step Three
|
Name
|
Intermediate 53
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
COC(C1=C(C=C(C=C1)C#CC=1C=C(C2=C(C(CC3(CC3)O2)(C)C)C1)C1CC1)F)=O
|
Step Four
|
Name
|
|
|
Quantity
|
0.11 g
|
|
Type
|
reactant
|
|
Smiles
|
C(C)OC(C1=CC=C(C=C1)I)=O
|
Step Five
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C(C)OC(C1=CC=C(C=C1)I)=O
|
Step Six
|
Name
|
|
|
Quantity
|
3 mL
|
|
Type
|
reactant
|
|
Smiles
|
C(C)N(CC)CC
|
Step Seven
|
Name
|
|
|
Quantity
|
3 mL
|
|
Type
|
reactant
|
|
Smiles
|
O1CCCC1
|
Step Eight
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
CCCCCC
|
Step Nine
|
Name
|
copper(I)iodide
|
|
Quantity
|
0.02 g
|
|
Type
|
catalyst
|
|
Smiles
|
[Cu]I
|
Step Ten
|
Name
|
|
|
Quantity
|
0.06 g
|
|
Type
|
catalyst
|
|
Smiles
|
Cl[Pd]([P](C1=CC=CC=C1)(C2=CC=CC=C2)C3=CC=CC=C3)([P](C4=CC=CC=C4)(C5=CC=CC=C5)C6=CC=CC=C6)Cl
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C1(CC1)N1CCC(C2=CC(=CC=C12)C#C)(C)C
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
