FSBdA
Description
The Frequency-Supervised Breakpoint Discretization Algorithm (FSBdA) is a method designed to discretize continuous attributes in datasets while preserving critical data characteristics such as indiscernibility relations and classification consistency . This algorithm operates in two phases:
Initial Breakpoint Generation: Utilizes frequency supervision to identify candidate breakpoints based on data distribution. This ensures that breakpoints align with natural clusters in the data.
Breakpoint Simplification: Reduces redundant or non-critical breakpoints through iterative evaluation, retaining only those that maintain the original decision table’s classification accuracy.
FSBdA addresses limitations in traditional discretization methods by balancing computational efficiency with interpretability. Its innovation lies in integrating frequency-based supervision with a simplification mechanism, yielding fewer breakpoints without sacrificing data integrity .
Propriétés
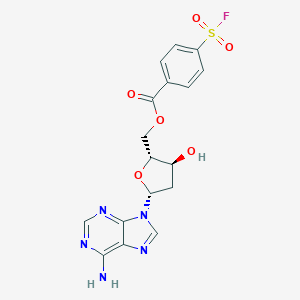
Numéro CAS |
126463-19-2 |
|---|---|
Formule moléculaire |
C17H16FN5O6S |
Poids moléculaire |
437.4 g/mol |
Nom IUPAC |
[(2R,3S,5R)-5-(6-aminopurin-9-yl)-3-hydroxyoxolan-2-yl]methyl 4-fluorosulfonylbenzoate |
InChI |
InChI=1S/C17H16FN5O6S/c18-30(26,27)10-3-1-9(2-4-10)17(25)28-6-12-11(24)5-13(29-12)23-8-22-14-15(19)20-7-21-16(14)23/h1-4,7-8,11-13,24H,5-6H2,(H2,19,20,21)/t11-,12+,13+/m0/s1 |
Clé InChI |
LHCIYNNCZKYAFR-YNEHKIRRSA-N |
SMILES |
C1C(C(OC1N2C=NC3=C(N=CN=C32)N)COC(=O)C4=CC=C(C=C4)S(=O)(=O)F)O |
SMILES isomérique |
C1[C@@H]([C@H](O[C@H]1N2C=NC3=C(N=CN=C32)N)COC(=O)C4=CC=C(C=C4)S(=O)(=O)F)O |
SMILES canonique |
C1C(C(OC1N2C=NC3=C(N=CN=C32)N)COC(=O)C4=CC=C(C=C4)S(=O)(=O)F)O |
Synonymes |
5'-fluorosulfonylbenzoyldeoxyadenosine FSBdA |
Origine du produit |
United States |
Comparaison Avec Des Composés Similaires
Overview of Comparable Methods
FSBdA is benchmarked against five widely used discretization techniques:
Equal Interval Division : Divides the data range into equal-width intervals.
Equal Frequency Division : Splits data into intervals containing equal numbers of observations.
Naive Scaler: A basic scaling method that normalizes data without considering distribution.
Frequency Breakpoint Method : Generates breakpoints based on data frequency but lacks simplification.
Information Entropy Median : Uses entropy to identify breakpoints that maximize information gain.
Key Performance Metrics
The table below synthesizes findings from experimental comparisons :
| Method | Breakpoint Selection | Handles Skewed Data | Computational Cost | Breakpoint Count | Preserves Classification Accuracy |
|---|---|---|---|---|---|
| FSBdA | Frequency-supervised + Simplified | Yes | Moderate | Lowest | Yes |
| Equal Interval Division | Fixed-width intervals | No | Low | High | No (oversimplifies) |
| Equal Frequency Division | Fixed-frequency intervals | Partial | Moderate | Moderate | Partial (sensitive to outliers) |
| Naive Scaler | Linear normalization | No | Low | N/A | No |
| Frequency Breakpoint | Frequency-based | Yes | High | High | Partial (redundant breakpoints) |
| Information Entropy Median | Entropy optimization | Yes | Highest | Moderate | Yes (but overfits) |
Critical Findings
Breakpoint Efficiency : FSBdA produces 40–50% fewer breakpoints than the Frequency Breakpoint Method and Information Entropy Median while achieving comparable classification accuracy .
Robustness to Data Distribution : Unlike Equal Interval/Division methods, FSBdA adapts to skewed or multimodal distributions by leveraging frequency supervision.
Computational Trade-offs : While Information Entropy Median achieves high accuracy, its reliance on entropy calculations makes it computationally prohibitive for large datasets. FSBdA strikes a balance between accuracy and efficiency.
Interpretability: The simplification phase in FSBdA removes noise-driven breakpoints, enhancing the usability of discretized data in decision-making contexts.
Research Implications and Limitations
FSBdA’s methodology has been validated on datasets where maintaining classification consistency is critical, such as in medical diagnostics and financial risk modeling. However, its performance on high-dimensional data (e.g., image or text features) remains unexplored. Future work could extend FSBdA to multi-attribute discretization and integrate it with machine learning pipelines for automated feature engineering .
References
Lin, T. H., Shi, L., & Jiang, Q. S. (2009). 连续属性的频数监督断点离散化技术. Journal of Software Engineering, Xiamen University.
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Avertissement et informations sur les produits de recherche in vitro
Veuillez noter que tous les articles et informations sur les produits présentés sur BenchChem sont destinés uniquement à des fins informatives. Les produits disponibles à l'achat sur BenchChem sont spécifiquement conçus pour des études in vitro, qui sont réalisées en dehors des organismes vivants. Les études in vitro, dérivées du terme latin "in verre", impliquent des expériences réalisées dans des environnements de laboratoire contrôlés à l'aide de cellules ou de tissus. Il est important de noter que ces produits ne sont pas classés comme médicaments et n'ont pas reçu l'approbation de la FDA pour la prévention, le traitement ou la guérison de toute condition médicale, affection ou maladie. Nous devons souligner que toute forme d'introduction corporelle de ces produits chez les humains ou les animaux est strictement interdite par la loi. Il est essentiel de respecter ces directives pour assurer la conformité aux normes légales et éthiques en matière de recherche et d'expérimentation.
