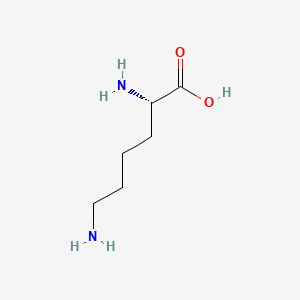
Lysine
Description
Structure
3D Structure
Propriétés
IUPAC Name |
(2S)-2,6-diaminohexanoic acid |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C6H14N2O2/c7-4-2-1-3-5(8)6(9)10/h5H,1-4,7-8H2,(H,9,10)/t5-/m0/s1 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
KDXKERNSBIXSRK-YFKPBYRVSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
C(CCN)CC(C(=O)O)N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Isomeric SMILES |
C(CCN)C[C@@H](C(=O)O)N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C6H14N2O2 |
Source
|
| Record name | lysine | |
| Source | Wikipedia | |
| URL | https://en.wikipedia.org/wiki/Lysine | |
| Description | Chemical information link to Wikipedia. | |
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Related CAS |
25104-18-1, Array |
Source
|
| Record name | Poly(L-lysine) | |
| Source | CAS Common Chemistry | |
| URL | https://commonchemistry.cas.org/detail?cas_rn=25104-18-1 | |
| Description | CAS Common Chemistry is an open community resource for accessing chemical information. Nearly 500,000 chemical substances from CAS REGISTRY cover areas of community interest, including common and frequently regulated chemicals, and those relevant to high school and undergraduate chemistry classes. This chemical information, curated by our expert scientists, is provided in alignment with our mission as a division of the American Chemical Society. | |
| Explanation | The data from CAS Common Chemistry is provided under a CC-BY-NC 4.0 license, unless otherwise stated. | |
| Record name | Lysine [USAN:INN] | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0000056871 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
DSSTOX Substance ID |
DTXSID6023232 |
Source
|
| Record name | L-Lysine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID6023232 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
146.19 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Physical Description |
Liquid, Solid; [Merck Index], Solid, White crystals or crystalline powder; odourless |
Source
|
| Record name | L-Lysine | |
| Source | EPA Chemicals under the TSCA | |
| URL | https://www.epa.gov/chemicals-under-tsca | |
| Description | EPA Chemicals under the Toxic Substances Control Act (TSCA) collection contains information on chemicals and their regulations under TSCA, including non-confidential content from the TSCA Chemical Substance Inventory and Chemical Data Reporting. | |
| Record name | Lysine | |
| Source | Haz-Map, Information on Hazardous Chemicals and Occupational Diseases | |
| URL | https://haz-map.com/Agents/15293 | |
| Description | Haz-Map® is an occupational health database designed for health and safety professionals and for consumers seeking information about the adverse effects of workplace exposures to chemical and biological agents. | |
| Explanation | Copyright (c) 2022 Haz-Map(R). All rights reserved. Unless otherwise indicated, all materials from Haz-Map are copyrighted by Haz-Map(R). No part of these materials, either text or image may be used for any purpose other than for personal use. Therefore, reproduction, modification, storage in a retrieval system or retransmission, in any form or by any means, electronic, mechanical or otherwise, for reasons other than personal use, is strictly prohibited without prior written permission. | |
| Record name | L-Lysine | |
| Source | Human Metabolome Database (HMDB) | |
| URL | http://www.hmdb.ca/metabolites/HMDB0000182 | |
| Description | The Human Metabolome Database (HMDB) is a freely available electronic database containing detailed information about small molecule metabolites found in the human body. | |
| Explanation | HMDB is offered to the public as a freely available resource. Use and re-distribution of the data, in whole or in part, for commercial purposes requires explicit permission of the authors and explicit acknowledgment of the source material (HMDB) and the original publication (see the HMDB citing page). We ask that users who download significant portions of the database cite the HMDB paper in any resulting publications. | |
| Record name | L-Lysine | |
| Source | Joint FAO/WHO Expert Committee on Food Additives (JECFA) | |
| URL | https://www.fao.org/food/food-safety-quality/scientific-advice/jecfa/jecfa-flav/details/en/c/1427/ | |
| Description | The flavoring agent databse provides the most recent specifications for flavorings evaluated by JECFA. | |
| Explanation | Permission from WHO is not required for the use of WHO materials issued under the Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Intergovernmental Organization (CC BY-NC-SA 3.0 IGO) licence. | |
Solubility |
Insoluble in ethanol, ethyl ether, acetone, benzene, Insolulble in common neutral solvents, Very freely soluble in water., Water solubility: >100 g/100 g H20 at 25 °C, In water, 5.84X10+5 mg/L at 27 °C, 1000.0 mg/mL, Soluble in water, Slightly soluble (in ethanol) |
Source
|
| Record name | Lysine | |
| Source | DrugBank | |
| URL | https://www.drugbank.ca/drugs/DB00123 | |
| Description | The DrugBank database is a unique bioinformatics and cheminformatics resource that combines detailed drug (i.e. chemical, pharmacological and pharmaceutical) data with comprehensive drug target (i.e. sequence, structure, and pathway) information. | |
| Explanation | Creative Common's Attribution-NonCommercial 4.0 International License (http://creativecommons.org/licenses/by-nc/4.0/legalcode) | |
| Record name | L-Lysine | |
| Source | Hazardous Substances Data Bank (HSDB) | |
| URL | https://pubchem.ncbi.nlm.nih.gov/source/hsdb/2108 | |
| Description | The Hazardous Substances Data Bank (HSDB) is a toxicology database that focuses on the toxicology of potentially hazardous chemicals. It provides information on human exposure, industrial hygiene, emergency handling procedures, environmental fate, regulatory requirements, nanomaterials, and related areas. The information in HSDB has been assessed by a Scientific Review Panel. | |
| Record name | L-Lysine | |
| Source | Human Metabolome Database (HMDB) | |
| URL | http://www.hmdb.ca/metabolites/HMDB0000182 | |
| Description | The Human Metabolome Database (HMDB) is a freely available electronic database containing detailed information about small molecule metabolites found in the human body. | |
| Explanation | HMDB is offered to the public as a freely available resource. Use and re-distribution of the data, in whole or in part, for commercial purposes requires explicit permission of the authors and explicit acknowledgment of the source material (HMDB) and the original publication (see the HMDB citing page). We ask that users who download significant portions of the database cite the HMDB paper in any resulting publications. | |
| Record name | L-Lysine | |
| Source | Joint FAO/WHO Expert Committee on Food Additives (JECFA) | |
| URL | https://www.fao.org/food/food-safety-quality/scientific-advice/jecfa/jecfa-flav/details/en/c/1427/ | |
| Description | The flavoring agent databse provides the most recent specifications for flavorings evaluated by JECFA. | |
| Explanation | Permission from WHO is not required for the use of WHO materials issued under the Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Intergovernmental Organization (CC BY-NC-SA 3.0 IGO) licence. | |
Vapor Pressure |
5.28X10+9 mm Hg at 25 °C /extrapolated/ |
Source
|
| Record name | L-Lysine | |
| Source | Hazardous Substances Data Bank (HSDB) | |
| URL | https://pubchem.ncbi.nlm.nih.gov/source/hsdb/2108 | |
| Description | The Hazardous Substances Data Bank (HSDB) is a toxicology database that focuses on the toxicology of potentially hazardous chemicals. It provides information on human exposure, industrial hygiene, emergency handling procedures, environmental fate, regulatory requirements, nanomaterials, and related areas. The information in HSDB has been assessed by a Scientific Review Panel. | |
Color/Form |
Needles from water, hexagonal plates from dilute alcohol, Colorless crystals | |
CAS No. |
56-87-1, 20166-34-1 |
Source
|
| Record name | L-Lysine | |
| Source | CAS Common Chemistry | |
| URL | https://commonchemistry.cas.org/detail?cas_rn=56-87-1 | |
| Description | CAS Common Chemistry is an open community resource for accessing chemical information. Nearly 500,000 chemical substances from CAS REGISTRY cover areas of community interest, including common and frequently regulated chemicals, and those relevant to high school and undergraduate chemistry classes. This chemical information, curated by our expert scientists, is provided in alignment with our mission as a division of the American Chemical Society. | |
| Explanation | The data from CAS Common Chemistry is provided under a CC-BY-NC 4.0 license, unless otherwise stated. | |
| Record name | Lysine [USAN:INN] | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0000056871 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
| Record name | L-Lysine, labeled with tritium | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0020166341 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
| Record name | Lysine | |
| Source | DrugBank | |
| URL | https://www.drugbank.ca/drugs/DB00123 | |
| Description | The DrugBank database is a unique bioinformatics and cheminformatics resource that combines detailed drug (i.e. chemical, pharmacological and pharmaceutical) data with comprehensive drug target (i.e. sequence, structure, and pathway) information. | |
| Explanation | Creative Common's Attribution-NonCommercial 4.0 International License (http://creativecommons.org/licenses/by-nc/4.0/legalcode) | |
| Record name | L-Lysine | |
| Source | EPA Chemicals under the TSCA | |
| URL | https://www.epa.gov/chemicals-under-tsca | |
| Description | EPA Chemicals under the Toxic Substances Control Act (TSCA) collection contains information on chemicals and their regulations under TSCA, including non-confidential content from the TSCA Chemical Substance Inventory and Chemical Data Reporting. | |
| Record name | L-Lysine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID6023232 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
| Record name | L-lysine | |
| Source | European Chemicals Agency (ECHA) | |
| URL | https://echa.europa.eu/substance-information/-/substanceinfo/100.000.268 | |
| Description | The European Chemicals Agency (ECHA) is an agency of the European Union which is the driving force among regulatory authorities in implementing the EU's groundbreaking chemicals legislation for the benefit of human health and the environment as well as for innovation and competitiveness. | |
| Explanation | Use of the information, documents and data from the ECHA website is subject to the terms and conditions of this Legal Notice, and subject to other binding limitations provided for under applicable law, the information, documents and data made available on the ECHA website may be reproduced, distributed and/or used, totally or in part, for non-commercial purposes provided that ECHA is acknowledged as the source: "Source: European Chemicals Agency, http://echa.europa.eu/". Such acknowledgement must be included in each copy of the material. ECHA permits and encourages organisations and individuals to create links to the ECHA website under the following cumulative conditions: Links can only be made to webpages that provide a link to the Legal Notice page. | |
| Record name | LYSINE | |
| Source | FDA Global Substance Registration System (GSRS) | |
| URL | https://gsrs.ncats.nih.gov/ginas/app/beta/substances/K3Z4F929H6 | |
| Description | The FDA Global Substance Registration System (GSRS) enables the efficient and accurate exchange of information on what substances are in regulated products. Instead of relying on names, which vary across regulatory domains, countries, and regions, the GSRS knowledge base makes it possible for substances to be defined by standardized, scientific descriptions. | |
| Explanation | Unless otherwise noted, the contents of the FDA website (www.fda.gov), both text and graphics, are not copyrighted. They are in the public domain and may be republished, reprinted and otherwise used freely by anyone without the need to obtain permission from FDA. Credit to the U.S. Food and Drug Administration as the source is appreciated but not required. | |
| Record name | L-Lysine | |
| Source | Hazardous Substances Data Bank (HSDB) | |
| URL | https://pubchem.ncbi.nlm.nih.gov/source/hsdb/2108 | |
| Description | The Hazardous Substances Data Bank (HSDB) is a toxicology database that focuses on the toxicology of potentially hazardous chemicals. It provides information on human exposure, industrial hygiene, emergency handling procedures, environmental fate, regulatory requirements, nanomaterials, and related areas. The information in HSDB has been assessed by a Scientific Review Panel. | |
| Record name | L-Lysine | |
| Source | Human Metabolome Database (HMDB) | |
| URL | http://www.hmdb.ca/metabolites/HMDB0000182 | |
| Description | The Human Metabolome Database (HMDB) is a freely available electronic database containing detailed information about small molecule metabolites found in the human body. | |
| Explanation | HMDB is offered to the public as a freely available resource. Use and re-distribution of the data, in whole or in part, for commercial purposes requires explicit permission of the authors and explicit acknowledgment of the source material (HMDB) and the original publication (see the HMDB citing page). We ask that users who download significant portions of the database cite the HMDB paper in any resulting publications. | |
Melting Point |
224 °C, decomposes, 224.5 °C |
Source
|
| Record name | Lysine | |
| Source | DrugBank | |
| URL | https://www.drugbank.ca/drugs/DB00123 | |
| Description | The DrugBank database is a unique bioinformatics and cheminformatics resource that combines detailed drug (i.e. chemical, pharmacological and pharmaceutical) data with comprehensive drug target (i.e. sequence, structure, and pathway) information. | |
| Explanation | Creative Common's Attribution-NonCommercial 4.0 International License (http://creativecommons.org/licenses/by-nc/4.0/legalcode) | |
| Record name | L-Lysine | |
| Source | Hazardous Substances Data Bank (HSDB) | |
| URL | https://pubchem.ncbi.nlm.nih.gov/source/hsdb/2108 | |
| Description | The Hazardous Substances Data Bank (HSDB) is a toxicology database that focuses on the toxicology of potentially hazardous chemicals. It provides information on human exposure, industrial hygiene, emergency handling procedures, environmental fate, regulatory requirements, nanomaterials, and related areas. The information in HSDB has been assessed by a Scientific Review Panel. | |
| Record name | L-Lysine | |
| Source | Human Metabolome Database (HMDB) | |
| URL | http://www.hmdb.ca/metabolites/HMDB0000182 | |
| Description | The Human Metabolome Database (HMDB) is a freely available electronic database containing detailed information about small molecule metabolites found in the human body. | |
| Explanation | HMDB is offered to the public as a freely available resource. Use and re-distribution of the data, in whole or in part, for commercial purposes requires explicit permission of the authors and explicit acknowledgment of the source material (HMDB) and the original publication (see the HMDB citing page). We ask that users who download significant portions of the database cite the HMDB paper in any resulting publications. | |
Foundational & Exploratory
A Deep Dive into Microbial Lysine Biosynthesis: Pathways, Regulation, and Experimental Analysis
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
L-lysine, an essential amino acid for animals, is synthesized de novo by a diverse array of microorganisms through two primary, evolutionarily distinct metabolic routes: the Diaminopimelate (DAP) pathway and the α-Aminoadipate (AAA) pathway. The absence of these pathways in humans makes their constituent enzymes prime targets for the development of novel antimicrobial agents. This technical guide provides a comprehensive overview of these core biosynthetic pathways, detailing their enzymatic steps, regulatory mechanisms, and the experimental methodologies used for their investigation.
The Diaminopimelate (DAP) Pathway: A Bacterial Hallmark
Predominantly found in bacteria and plants, the DAP pathway initiates from aspartate and culminates in the production of L-lysine. A key intermediate, meso-diaminopimelate (m-DAP), is not only a direct precursor to lysine but also a crucial component of the peptidoglycan cell wall in most Gram-negative bacteria, highlighting the pathway's dual importance for bacterial survival.[1][2] The DAP pathway exhibits several variations in its central steps, leading to the classification of four main sub-pathways.
Variants of the Diaminopimelate Pathway
The initial and final steps of the DAP pathway are conserved across its variants. The pathway begins with the phosphorylation of aspartate by Aspartate Kinase (AK) , followed by the reduction of the resulting β-aspartyl phosphate to aspartate semialdehyde by Aspartate-Semialdehyde Dehydrogenase (ASD) .[2] The pathway concludes with the decarboxylation of m-DAP to L-lysine by Diaminopimelate Decarboxylase (DapF/LysA) . The divergence lies in the conversion of L-2,3,4,5-tetrahydrodipicolinate (THDP), which is formed from the condensation of aspartate semialdehyde and pyruvate, to m-DAP.
The four recognized variants are:
-
The Succinylase Pathway: This is the most common variant, found in most Gram-negative bacteria and many Gram-positive bacteria, including Escherichia coli.[3][4] It involves four enzymatic steps where THDP is first succinylated, followed by a transamination, desuccinylation, and finally epimerization to yield m-DAP.
-
The Acetylase Pathway: Utilized by certain Bacillus species, this pathway is analogous to the succinylase pathway but employs acetylated intermediates instead of succinylated ones.[5]
-
The Dehydrogenase Pathway: This is a more direct route where m-Diaminopimelate Dehydrogenase (Ddh) catalyzes the direct conversion of THDP to m-DAP. This pathway is found in some bacteria, including Corynebacterium glutamicum, which notably possesses both the dehydrogenase and succinylase pathways.
-
The Aminotransferase Pathway (DapL Pathway): This recently discovered pathway utilizes a single enzyme, L,L-Diaminopimelate Aminotransferase (DapL) , to directly convert THDP to L,L-diaminopimelate, which is then epimerized to m-DAP.[6] This pathway has been identified in various bacteria and plants.[6]
Diagram of the Diaminopimelate (DAP) Pathway Variants
The α-Aminoadipate (AAA) Pathway: A Fungal Specialty
Unique to fungi, some archaea, and euglenids, the AAA pathway represents a completely different evolutionary solution to this compound biosynthesis.[1][7] This pathway is part of the glutamate family of amino acid synthesis and begins with the condensation of acetyl-CoA and α-ketoglutarate. The absence of this pathway in bacteria makes it an attractive target for the development of specific antifungal drugs.
The key steps of the AAA pathway are:
-
Homocitrate Synthase (HCS): Catalyzes the condensation of acetyl-CoA and α-ketoglutarate to form homocitrate. This is a key regulatory point in the pathway.
-
Homoaconitase (HACN): Isomerizes homocitrate to homoisocitrate via cis-homoaconitate. In some fungi, this step may require the concerted action of two enzymes.[8]
-
Homoisocitrate Dehydrogenase (HIDH): Catalyzes the oxidative decarboxylation of homoisocitrate to α-ketoadipate.
-
Aminoadipate Aminotransferase: Converts α-ketoadipate to α-aminoadipate (AAA).
-
α-Aminoadipate Reductase (AAR): A complex enzymatic step that reduces AAA to α-aminoadipate semialdehyde. This step often requires post-translational modification by a phosphopantetheinyl transferase.[9][10]
-
Saccharopine Dehydrogenase (glutamate-forming): Catalyzes the reductive condensation of α-aminoadipate semialdehyde with glutamate to form saccharopine.
-
Saccharopine Dehydrogenase (this compound-forming): The final step, which cleaves saccharopine to yield L-lysine and α-ketoglutarate.
Diagram of the α-Aminoadipate (AAA) Pathway
This compound Biosynthesis in Archaea
The distribution of this compound biosynthesis pathways in Archaea is diverse. Methanogenic archaea have been shown to utilize the DAP pathway for the synthesis of α-lysine.[11] Specifically, genomic analyses suggest the presence of the aminotransferase subpathway of the DAP pathway in methanogens.[12] In contrast, some hyperthermophilic archaea employ a variant of the AAA pathway, known as the LysW-mediated AAA pathway, for this compound synthesis.[12][13] Interestingly, some haloarchaea appear to utilize the DAP pathway.[13] The study of this compound biosynthesis in archaea is an active area of research, with evidence suggesting a complex evolutionary history of these pathways within this domain.
Regulation of this compound Biosynthesis
To maintain cellular homeostasis, this compound biosynthesis is tightly regulated at both the enzymatic and genetic levels.
Allosteric Regulation
A primary mechanism of regulation is feedback inhibition, where the final product, L-lysine, allosterically inhibits the activity of the first enzyme in the pathway.
-
DAP Pathway: In many bacteria, Aspartate Kinase (AK) is the key regulatory enzyme. For instance, in E. coli, there are three AK isozymes, with LysC being specifically inhibited by this compound.[3] The binding of this compound to a regulatory domain on the enzyme induces a conformational change that reduces its catalytic activity.[14]
-
AAA Pathway: In fungi, Homocitrate Synthase (HCS) is subject to feedback inhibition by this compound. This regulation controls the entry of substrates into the pathway.
Genetic Regulation
Gene expression is also modulated in response to this compound availability.
-
The LYS Element (Riboswitch): In many bacteria, the expression of genes involved in this compound biosynthesis and transport is controlled by a this compound-sensing riboswitch, also known as the LYS element or L box, located in the 5' untranslated region of the corresponding mRNAs.[1][2][3][4][15] When this compound concentrations are high, it binds to the riboswitch, inducing a conformational change in the mRNA that typically leads to premature transcription termination or inhibition of translation initiation.[15] The this compound riboswitch binds L-lysine with high specificity and an apparent dissociation constant (KD) of approximately 1 µM.[16]
-
Transcriptional Regulation in Fungi: In Saccharomyces cerevisiae, the transcription of several this compound biosynthesis genes is activated by the protein product of the LYS14 gene.[16][17][18] This activation is dependent on the presence of an intermediate of the pathway, α-aminoadipate semialdehyde, which acts as an inducer.[16][17] this compound appears to antagonize this activation, possibly by limiting the availability of the inducer.[17]
Quantitative Data on this compound Biosynthesis Enzymes
The following tables summarize available kinetic data for key enzymes in the DAP and AAA pathways from various microorganisms.
Table 1: Kinetic Parameters of Key Enzymes in the Diaminopimelate (DAP) Pathway
| Enzyme | Organism | Substrate | Km (mM) | kcat (s-1) | kcat/Km (M-1s-1) |
| Diaminopimelate Decarboxylase (DAPDC) | Cyanothece sp. ATCC 51142 | meso-DAP | 1.20 ± 0.17 | 1.68 | 1.40 x 103 |
| Vibrio cholerae | meso-DAP | 1.9 | 22 | - | |
| N-succinyl-L,L-diaminopimelic Acid Desuccinylase (DapE) | Haemophilus influenzae | N-succinyl-L,L-DAP | 1.3 | 200 | - |
| Haemophilus influenzae (H67A mutant) | N-succinyl-L,L-DAP | 1.4 ± 0.2 | 1.5 ± 0.5 | - | |
| Dihydrodipicolinate Reductase (DHDPR) | Thermotoga maritima | DHDP | - | - | - |
| Staphylococcus aureus (MRSA) | NADPH | 0.012 | - | - | |
| Staphylococcus aureus (MRSA) | NADH | 0.026 | - | - | |
| L,L-Diaminopimelate Aminotransferase (DapL) | Multiple Orthologs | L,L-DAP / 2-oxoglutarate | 0.1 - 4.0 | - | - |
Data compiled from various sources.[6][19]
Table 2: Kinetic Parameters of Key Enzymes in the α-Aminoadipate (AAA) Pathway
| Enzyme | Organism | Substrate | Km (mM) | kcat (s-1) | kcat/Km (M-1s-1) |
| Homoisocitrate Dehydrogenase (HIcDH) | Saccharomyces cerevisiae | Homoisocitrate | 0.01 | - | - |
| Saccharomyces cerevisiae | NAD | 0.33 | - | - | |
| Saccharopine Dehydrogenase (this compound-forming) | Saccharomyces cerevisiae | Saccharopine | 1.7 | - | - |
| Saccharomyces cerevisiae | NAD | 0.1 | - | - | |
| Saccharomyces cerevisiae | This compound | 2 | - | - | |
| Saccharomyces cerevisiae | α-Ketoglutarate | 0.55 | - | - | |
| Saccharomyces cerevisiae | NADH | 0.089 | - | - | |
| Saccharopine Reductase (glutamate-forming) | Saccharomyces cerevisiae | - | - | - | - |
| Homoaconitase (HACN) | Thermus thermophilus | cis-homoaconitate | 0.0082 ± 0.0002 | 1.3 ± 0.2 | - |
| α-Aminoadipate Aminotransferase | Yeast | α-oxoadipate | 14 | - | - |
| Yeast | aminoadipate | 20 | - | - | |
| α-Aminoadipate Reductase (AAR) | Saccharomyces cerevisiae (PCP fragment) | CoASH | 0.001 | 0.05 | - |
Data compiled from various sources.[9][17][18][20][21][22]
Experimental Protocols for Studying this compound Biosynthesis
A variety of experimental techniques are employed to elucidate the function and regulation of this compound biosynthesis pathways.
Enzyme Assays
Characterizing the kinetic properties of individual enzymes is fundamental to understanding pathway flux.
Protocol: Coupled Spectrophotometric Assay for Diaminopimelate Decarboxylase (DAPDC)
This assay couples the production of this compound by DAPDC to the oxidation of NADH by saccharopine dehydrogenase (SDH).
-
Reaction Mixture Preparation: In a cuvette, prepare a reaction mixture containing:
-
Tris buffer (e.g., 200 mM, pH 8.0)
-
α-ketoglutarate (e.g., 25 mM)
-
NADH (e.g., 0.16 mM)
-
Pyridoxal 5'-phosphate (PLP) (e.g., 0.1 mM)
-
Saccharopine dehydrogenase (SDH) (e.g., 2.5 µM)
-
Varying concentrations of the substrate, meso-diaminopimelate (DAP) (e.g., 0.25–40 mM).
-
-
Pre-incubation: Incubate the reaction mixture at a constant temperature (e.g., 37°C) for a sufficient time (e.g., 10 minutes) to allow for temperature equilibration and any pre-reactions to complete.
-
Initiation: Initiate the reaction by adding a known concentration of purified DAPDC enzyme.
-
Measurement: Immediately monitor the decrease in absorbance at 340 nm (the wavelength at which NADH absorbs light) over time using a spectrophotometer. The rate of NADH oxidation is proportional to the rate of this compound production by DAPDC.
-
Data Analysis: Calculate the initial reaction velocity from the linear portion of the absorbance versus time plot. By performing the assay at various substrate concentrations, the Michaelis-Menten kinetic parameters (Km and Vmax) can be determined.
Diagram of the Coupled DAPDC Enzyme Assay
13C-Metabolic Flux Analysis (13C-MFA)
13C-MFA is a powerful technique to quantify the in vivo fluxes through metabolic pathways.
General Protocol for 13C-MFA:
-
Cell Culture with Labeled Substrate: Cultivate the microorganism of interest in a defined medium containing a 13C-labeled carbon source (e.g., [1-13C]glucose or [U-13C]glucose).
-
Metabolite Quenching and Extraction: Rapidly quench metabolic activity (e.g., by using cold methanol) and extract intracellular metabolites.
-
Analysis of Labeling Patterns: Analyze the mass isotopomer distribution of key metabolites (often proteinogenic amino acids after hydrolysis) using techniques such as gas chromatography-mass spectrometry (GC-MS) or liquid chromatography-mass spectrometry (LC-MS).
-
Computational Modeling: Use specialized software to fit the experimentally determined labeling patterns and extracellular flux rates (e.g., substrate uptake and product secretion rates) to a metabolic model of the organism's central carbon metabolism. This allows for the calculation of intracellular flux distribution.
Diagram of the 13C-MFA Workflow
References
- 1. The evolutionary history of this compound biosynthesis pathways within eukaryotes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. This compound Metabolism: Pathways, Regulation, and Biological Significance - Creative Proteomics [creative-proteomics.com]
- 3. academic.oup.com [academic.oup.com]
- 4. Regulation of this compound biosynthesis and transport genes in bacteria: yet another RNA riboswitch? - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Global landscape of this compound acylomes in Bacillus subtilis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. researchgate.net [researchgate.net]
- 9. This compound biosynthesis in Saccharomyces cerevisiae: mechanism of alpha-aminoadipate reductase (Lys2) involves posttranslational phosphopantetheinylation by Lys5 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Novel Posttranslational Activation of the LYS2-Encoded α-Aminoadipate Reductase for Biosynthesis of this compound and Site-Directed Mutational Analysis of Conserved Amino Acid Residues in the Activation Domain of Candida albicans - PMC [pmc.ncbi.nlm.nih.gov]
- 11. This compound-2,3-Aminomutase and β-Lysine Acetyltransferase Genes of Methanogenic Archaea Are Salt Induced and Are Essential for the Biosynthesis of Nɛ-Acetyl-β-Lysine and Growth at High Salinity - PMC [pmc.ncbi.nlm.nih.gov]
- 12. journals.asm.org [journals.asm.org]
- 13. Dissecting the Arginine and this compound Biosynthetic Pathways and Their Relationship in Haloarchaeon Natrinema gari J7-2 via Endogenous CRISPR-Cas System-Based Genome Editing - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. researchgate.net [researchgate.net]
- 15. uniprot.org [uniprot.org]
- 16. Control of enzyme synthesis in the this compound biosynthetic pathway of Saccharomyces cerevisiae. Evidence for a regulatory role of gene LYS14 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. Repression of the genes for this compound biosynthesis in Saccharomyces cerevisiae is caused by limitation of Lys14-dependent transcriptional activation - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Control of enzyme synthesis in the this compound biosynthetic pathway of Saccharomyces cerevisiae. Evidence for a regulatory role of gene LYS14. | Semantic Scholar [semanticscholar.org]
- 19. rsc.org [rsc.org]
- 20. Kinetics and product analysis of the reaction catalysed by recombinant homoaconitase from Thermus thermophilus - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Kinetics and product analysis of the reaction catalysed by recombinant homoaconitase from Thermus thermophilus - PubMed [pubmed.ncbi.nlm.nih.gov]
- 22. Substrate specificity and structure of human aminoadipate aminotransferase/kynurenine aminotransferase II - PMC [pmc.ncbi.nlm.nih.gov]
An In-depth Technical Guide to Post-translational Modifications of Lysine Residues
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive overview of the core principles of post-translational modifications (PTMs) on lysine residues, their profound impact on cellular function, and the methodologies employed for their investigation. This compound, with its versatile ε-amino group, is a hub for a multitude of covalent modifications that dynamically regulate protein activity, localization, and interactions, thereby influencing a vast array of biological processes. Dysregulation of these modifications is frequently implicated in the pathogenesis of numerous diseases, including cancer and neurodegenerative disorders, making them critical targets for therapeutic intervention.
Core Concepts of this compound Post-Translational Modifications
Post-translational modifications of this compound residues are enzymatic or non-enzymatic chemical alterations that occur after a protein is synthesized. These modifications dramatically expand the functional capacity of the proteome beyond the 20 canonical amino acids. The primary this compound PTMs include acetylation, methylation, ubiquitination, and succinylation, each with distinct roles in cellular regulation.
The regulation of these modifications is orchestrated by a trio of protein families:
-
"Writers" : Enzymes that catalyze the addition of a specific modification to a this compound residue. Examples include this compound acetyltransferases (KATs), this compound methyltransferases (KMTs), and ubiquitin ligases.
-
"Erasers" : Enzymes that remove these modifications, ensuring their reversibility and dynamic nature. Examples include this compound deacetylases (KDACs or HDACs), this compound demethylases (KDMs), and deubiquitinating enzymes (DUBs).
-
"Readers" : Proteins that contain specialized domains capable of recognizing and binding to specific modified this compound residues, thereby translating the modification into a functional cellular outcome. Bromodomains, for instance, recognize acetylated lysines, while chromodomains bind to methylated lysines.
Key this compound Post-Translational Modifications
This compound Acetylation
This compound acetylation involves the transfer of an acetyl group from acetyl-CoA to the ε-amino group of a this compound residue, neutralizing its positive charge.[1] This modification is pivotal in regulating chromatin structure and gene expression. Histone acetylation, catalyzed by histone acetyltransferases (HATs), leads to a more relaxed chromatin conformation, facilitating transcription factor access and gene activation.[2][3] Conversely, histone deacetylases (HDACs) remove acetyl groups, leading to chromatin compaction and transcriptional repression.[1] Beyond histones, a vast number of non-histone proteins are also acetylated, influencing their stability, enzymatic activity, and protein-protein interactions.[4]
This compound Methylation
This compound methylation involves the addition of one, two, or three methyl groups from S-adenosyl methionine (SAM) to a this compound residue. Unlike acetylation, methylation does not alter the charge of the this compound residue.[5] The degree of methylation (mono-, di-, or tri-methylation) dictates the functional outcome.[6] Histone this compound methylation can be associated with both transcriptional activation and repression, depending on the specific this compound residue and the methylation state.[7] For example, trimethylation of histone H3 at this compound 4 (H3K4me3) is a hallmark of active gene promoters, while trimethylation of H3K27 (H3K27me3) is associated with gene silencing.[6]
This compound Ubiquitination
Ubiquitination is the process of attaching a 76-amino acid protein, ubiquitin, to a this compound residue. This process is mediated by a cascade of three enzymes: an E1 activating enzyme, an E2 conjugating enzyme, and an E3 ligase.[8][9] The fate of the ubiquitinated protein depends on the nature of the ubiquitin chain. Polyubiquitination, typically through this compound 48 (K48) linkages, targets proteins for degradation by the 26S proteasome.[8] In contrast, monoubiquitination or polyubiquitination through other this compound residues (e.g., K63) can regulate protein localization, activity, and signal transduction.[10]
This compound Succinylation
This compound succinylation is the addition of a succinyl group from succinyl-CoA to a this compound residue. This modification introduces a larger and negatively charged moiety compared to acetylation, leading to a more significant change in the protein's physicochemical properties.[11] Succinylation has been shown to be widespread and is involved in regulating various metabolic pathways.[11] There is also evidence of crosstalk between succinylation and other acyl modifications like acetylation, suggesting a competitive and coordinated regulation of cellular processes.[11][12]
Quantitative Data on this compound PTMs
The advancement of mass spectrometry-based proteomics has enabled the large-scale identification and quantification of this compound PTMs. This has provided valuable insights into the prevalence and stoichiometry of these modifications.
| Modification Type | Number of Identified Sites (Human) | Key Regulated Processes | Representative Stoichiometry | References |
| Acetylation | >15,000 | Gene expression, metabolism, cell cycle | Generally low (<5%), but can be higher for specific sites (e.g., histones up to 30%) | [13][14][15] |
| Methylation | >550 (in a single study) | Chromatin organization, transcription, DNA damage response | Variable, with mono-methylation being more abundant than di- or tri-methylation | [5][16][17] |
| Ubiquitination | Widespread | Protein degradation, signal transduction, endocytosis | Highly dynamic and context-dependent | [7] |
| Succinylation | >1,000 (in mouse liver) | Metabolism, protein synthesis | Generally low | [11] |
Experimental Protocols
Mass Spectrometry-based Identification of this compound PTMs
Objective: To identify and quantify this compound PTMs in a complex protein sample.
Methodology:
-
Protein Extraction and Digestion: Extract proteins from cells or tissues and digest them into peptides using a protease such as trypsin.[18][19] Trypsin cleaves C-terminal to arginine and this compound residues, but cleavage is blocked at a modified this compound, which can aid in identification.[12]
-
Enrichment of Modified Peptides: Due to the low stoichiometry of many PTMs, enrichment is often necessary. This is typically achieved using antibodies specific to the modification of interest (e.g., anti-acetylthis compound or anti-methylthis compound antibodies) coupled to beads for immunoprecipitation.[18][20]
-
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS): The enriched peptides are separated by liquid chromatography and then analyzed by a mass spectrometer. The instrument measures the mass-to-charge ratio of the peptides (MS1 scan) and then fragments them to obtain sequence information (MS/MS or MS2 scan).[21]
-
Data Analysis: The resulting MS/MS spectra are searched against a protein database to identify the peptide sequences and the specific sites of modification.[19] Specialized software can also be used to quantify the relative abundance of the modified peptides.[18]
Chromatin Immunoprecipitation (ChIP)
Objective: To determine the genomic locations of specific histone this compound modifications.
Methodology:
-
Cross-linking: Treat cells with formaldehyde to covalently cross-link proteins to DNA.[22][23]
-
Chromatin Shearing: Lyse the cells and shear the chromatin into smaller fragments (typically 200-700 bp) using sonication or enzymatic digestion with micrococcal nuclease (MNase).[22][24]
-
Immunoprecipitation: Incubate the sheared chromatin with an antibody specific to the histone modification of interest (e.g., anti-H3K4me3 or anti-H3K27ac). The antibody-histone-DNA complexes are then captured using protein A/G-coated beads.[22][24]
-
Reverse Cross-linking and DNA Purification: Reverse the cross-links by heating and purify the immunoprecipitated DNA.[24]
-
Analysis: The purified DNA can be analyzed by quantitative PCR (qPCR) to assess the enrichment of the modification at specific gene loci or by next-generation sequencing (ChIP-Seq) for genome-wide mapping.[22][25]
Western Blotting
Objective: To detect and quantify the overall levels of a specific this compound modification on a target protein.
Methodology:
-
Protein Extraction and Quantification: Extract total protein from cells or tissues and determine the protein concentration.[26]
-
SDS-PAGE: Separate the proteins by size using sodium dodecyl sulfate-polyacrylamide gel electrophoresis (SDS-PAGE).
-
Protein Transfer: Transfer the separated proteins from the gel to a membrane (e.g., nitrocellulose or PVDF).[26]
-
Immunodetection:
-
Block the membrane to prevent non-specific antibody binding.
-
Incubate the membrane with a primary antibody specific to the modified protein of interest (e.g., anti-acetyl-p53).
-
Wash the membrane and then incubate with a secondary antibody conjugated to an enzyme (e.g., horseradish peroxidase - HRP).[26]
-
-
Detection: Add a chemiluminescent substrate that reacts with the enzyme on the secondary antibody to produce light, which can be captured on X-ray film or with a digital imager. The intensity of the band corresponds to the amount of the modified protein.[26]
Signaling Pathways and Logical Relationships
Histone Acetylation and Transcriptional Activation
Histone acetylation is a key mechanism for activating gene transcription. The process involves the recruitment of histone acetyltransferases (HATs) to gene promoters by transcriptional activators. The subsequent acetylation of histone tails neutralizes their positive charge, weakening their interaction with DNA and leading to a more open chromatin structure. This accessible chromatin allows for the binding of the transcriptional machinery and initiation of gene expression.
Caption: Histone acetylation pathway leading to gene activation.
Ubiquitin-Proteasome System for Protein Degradation
The ubiquitin-proteasome system is the primary pathway for targeted protein degradation in eukaryotic cells. The process begins with the activation of ubiquitin by an E1 enzyme, followed by its transfer to an E2 conjugating enzyme. An E3 ligase then recognizes a specific substrate protein and facilitates the transfer of ubiquitin from the E2 to a this compound residue on the substrate. The sequential addition of ubiquitin molecules forms a polyubiquitin chain, which acts as a degradation signal for the 26S proteasome.
Caption: The ubiquitin-proteasome pathway for protein degradation.
Experimental Workflow for ChIP-Seq
This workflow outlines the major steps involved in performing a Chromatin Immunoprecipitation followed by high-throughput sequencing (ChIP-Seq) experiment to map the genome-wide locations of a specific histone modification.
Caption: A step-by-step workflow for ChIP-Seq experiments.
Conclusion
The study of this compound post-translational modifications is a dynamic and rapidly evolving field. The ability to qualitatively and quantitatively analyze these modifications has provided unprecedented insights into the complex regulatory networks that govern cellular function. For researchers and drug development professionals, understanding the enzymes that write, erase, and read these marks, as well as the signaling pathways they control, is paramount for identifying novel therapeutic targets and developing innovative treatment strategies for a wide range of human diseases. This guide serves as a foundational resource to navigate the intricate world of this compound PTMs and to apply this knowledge in a research and development setting.
References
- 1. cusabio.com [cusabio.com]
- 2. Histone Acetylation Is Associated with Transcription Activation [almerja.com]
- 3. Histone acetylation and deacetylation - Wikipedia [en.wikipedia.org]
- 4. This compound acetylation: codified crosstalk with other posttranslational modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Emergent properties of the this compound methylome reveal regulatory roles via protein interactions and histone mimicry - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Examples of Crosstalk Between Post-translational Modifications | Cell Signaling Technology [cellsignal.com]
- 7. The Chemical Biology of Reversible this compound Post-Translational Modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 8. creative-diagnostics.com [creative-diagnostics.com]
- 9. researchgate.net [researchgate.net]
- 10. This compound‐63‐linked ubiquitination is required for endolysosomal degradation of class I molecules | The EMBO Journal [link.springer.com]
- 11. Frontiers | The metabolic-epigenetic interface: this compound succinylation orchestrates bidirectional crosstalk in neurodegenerative disorders [frontiersin.org]
- 12. pubs.acs.org [pubs.acs.org]
- 13. Deep, Quantitative Coverage of the this compound Acetylome Using Novel Anti-acetyl-lysine Antibodies and an Optimized Proteomic Workflow - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Proteomic Analysis of this compound Acetylation Sites in Rat Tissues Reveals Organ Specificity and Subcellular Patterns - PMC [pmc.ncbi.nlm.nih.gov]
- 15. This compound acetylation stoichiometry and proteomics analyses reveal pathways regulated by sirtuin 1 in human cells - PMC [pmc.ncbi.nlm.nih.gov]
- 16. researchgate.net [researchgate.net]
- 17. tandfonline.com [tandfonline.com]
- 18. High-Resolution Mass Spectrometry to Identify and Quantify Acetylation Protein Targets - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Acetylation Site Mass Spectrometry Identification | MtoZ Biolabs [mtoz-biolabs.com]
- 20. Quantitative analysis of global protein this compound methylation by mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Discovery of this compound post-translational modifications through mass spectrometric detection - PMC [pmc.ncbi.nlm.nih.gov]
- 22. A Step-by-Step Guide to Successful Chromatin Immunoprecipitation (ChIP) Assays | Thermo Fisher Scientific - US [thermofisher.com]
- 23. merckmillipore.com [merckmillipore.com]
- 24. Chromatin Immunoprecipitation (ChIP) of Histone Modifications from Saccharomyces cerevisiae - PMC [pmc.ncbi.nlm.nih.gov]
- 25. bosterbio.com [bosterbio.com]
- 26. origene.com [origene.com]
Introduction: The Central Role of Lysine in Chromatin Regulation
References
- 1. Epigenetic Cross-Talk between DNA Methylation and Histone Modifications in Human Cancers - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Prominent role of histone this compound demethylases in cancer epigenetics and therapy - PMC [pmc.ncbi.nlm.nih.gov]
- 3. benchchem.com [benchchem.com]
- 4. researchgate.net [researchgate.net]
- 5. Allosteric regulation of histone this compound methyltransferases: from context-specific regulation to selective drugs - PMC [pmc.ncbi.nlm.nih.gov]
- 6. bosterbio.com [bosterbio.com]
- 7. Comparative Analyses of H3K4 and H3K27 Trimethylations Between the Mouse Cerebrum and Testis - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Frontiers | Systematic Analysis of Differential H3K27me3 and H3K4me3 Deposition in Callus and Seedling Reveals the Epigenetic Regulatory Mechanisms Involved in Callus Formation in Rice [frontiersin.org]
- 9. Histone Modifications and Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 10. oncotarget.com [oncotarget.com]
- 11. The Bromodomain: From Epigenome Reader to Druggable Target - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. This compound acetylation and the bromodomain: a new partnership for signaling - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. scholars.mssm.edu [scholars.mssm.edu]
- 15. Acetyl-lysine Binding Site of Bromodomain-Containing Protein 4 (BRD4) Interacts with Diverse Kinase Inhibitors - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Histone this compound methyltransferases in biology and disease - PMC [pmc.ncbi.nlm.nih.gov]
- 17. tandfonline.com [tandfonline.com]
- 18. researchgate.net [researchgate.net]
- 19. Histone modifying enzymes and cancer: going beyond histones - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. The Language of Histone Crosstalk - PMC [pmc.ncbi.nlm.nih.gov]
- 21. Cross talk between acetylation and methylation regulators reveals histone modifier expression patterns posing prognostic and therapeutic implications on patients with colon cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 22. Histone H3 this compound 4 acetylation and methylation dynamics define breast cancer subtypes - PMC [pmc.ncbi.nlm.nih.gov]
- 23. researchgate.net [researchgate.net]
- 24. Systematic Analysis of Differential H3K27me3 and H3K4me3 Deposition in Callus and Seedling Reveals the Epigenetic Regulatory Mechanisms Involved in Callus Formation in Rice - PMC [pmc.ncbi.nlm.nih.gov]
- 25. EZH2 inhibition by tazemetostat: mechanisms of action, safety and efficacy in relapsed/refractory follicular lymphoma - PMC [pmc.ncbi.nlm.nih.gov]
- 26. EZH2 inhibition by tazemetostat: mechanisms of action, safety and efficacy in relapsed/refractory follicular lymphoma - PubMed [pubmed.ncbi.nlm.nih.gov]
- 27. Targeting histone this compound methylation in cancer - PubMed [pubmed.ncbi.nlm.nih.gov]
- 28. Innovation Insights: Small molecule Epigenetics inhibitors [researchandmarkets.com]
- 29. Small molecule epigenetic inhibitors targeted to histone this compound methyltransferases and demethylases - PMC [pmc.ncbi.nlm.nih.gov]
- 30. The Promise for Histone Methyltransferase Inhibitors for Epigenetic Therapy in Clinical Oncology: A Narrative Review - PMC [pmc.ncbi.nlm.nih.gov]
- 31. JCI - Epigenetic therapies targeting histone this compound methylation: complex mechanisms and clinical challenges [jci.org]
- 32. Chromatin Immunoprecipitation Sequencing (ChIP-seq) for Detecting Histone Modifications and Modifiers | Springer Nature Experiments [experiments.springernature.com]
- 33. Chromatin Immunoprecipitation Sequencing (ChIP-seq) for Detecting Histone Modifications and Modifiers - PubMed [pubmed.ncbi.nlm.nih.gov]
- 34. scilit.com [scilit.com]
- 35. chromosomedynamics.com [chromosomedynamics.com]
- 36. Complete Workflow for Analysis of Histone Post-translational Modifications Using Bottom-up Mass Spectrometry: From Histone Extraction to Data Analysis [jove.com]
- 37. A practical guide for analysis of histone post-translational modifications by mass spectrometry: Best practices and pitfalls - PubMed [pubmed.ncbi.nlm.nih.gov]
- 38. researchgate.net [researchgate.net]
- 39. [PDF] Complete Workflow for Analysis of Histone Post-translational Modifications Using Bottom-up Mass Spectrometry: From Histone Extraction to Data Analysis | Semantic Scholar [semanticscholar.org]
- 40. pure.ul.ie [pure.ul.ie]
- 41. Video: Assays for Validating Histone Acetyltransferase Inhibitors [jove.com]
- 42. In vitro activity assays for MYST histone acetyltransferases and adaptation for high-throughput inhibitor screening - PMC [pmc.ncbi.nlm.nih.gov]
An In-depth Technical Guide to Lysine Catabolism in Mammals
For Researchers, Scientists, and Drug Development Professionals
Introduction
Lysine, an essential amino acid in mammals, plays a critical role beyond its function as a building block for proteins. Its catabolism is a vital process for maintaining homeostasis and providing intermediates for other metabolic pathways. The breakdown of this compound is also implicated in several metabolic disorders, making it a key area of investigation for therapeutic development. This technical guide provides a comprehensive overview of the core aspects of this compound metabolism, focusing on its catabolic pathways in mammals. It is designed to be a valuable resource for researchers, scientists, and drug development professionals, offering detailed information on the biochemical reactions, quantitative data, experimental methodologies, and regulatory mechanisms governing this intricate metabolic network.
In mammals, this compound is primarily catabolized through two distinct pathways: the saccharopine pathway and the pipecolate pathway . The saccharopine pathway is the major route for this compound degradation in most tissues, particularly the liver and kidneys, while the pipecolate pathway is more prominent in the brain.[1] Both pathways converge at the level of α-aminoadipate-δ-semialdehyde, which is then further metabolized to acetyl-CoA, feeding into the tricarboxylic acid (TCA) cycle for energy production.[1]
This guide will delve into the enzymatic steps of each pathway, present available quantitative data in structured tables for comparative analysis, provide detailed experimental protocols for key assays, and illustrate the intricate signaling and logical relationships using Graphviz diagrams.
The Saccharopine Pathway: The Major Catabolic Route
The saccharopine pathway is the predominant route for this compound degradation in most mammalian tissues.[1] This mitochondrial pathway involves a series of enzymatic reactions that convert this compound into α-aminoadipate, which is then further metabolized.
Enzymatic Steps of the Saccharopine Pathway
-
This compound-α-Ketoglutarate Reductase (LKR) : The first and rate-limiting step is the condensation of L-lysine with α-ketoglutarate to form saccharopine. This reaction is catalyzed by the enzyme this compound-α-ketoglutarate reductase (LKR), which is the LKR domain of the bifunctional enzyme α-aminoadipate semialdehyde synthase (AASS).[2][3] This step is irreversible in mammals.[4]
-
Saccharopine Dehydrogenase (SDH) : Saccharopine is then oxidatively cleaved by the saccharopine dehydrogenase (SDH) domain of the AASS enzyme to yield L-glutamate and α-aminoadipate-δ-semialdehyde.[3][5]
-
α-Aminoadipate Semialdehyde Dehydrogenase (AASDH) : The final step in the formation of α-aminoadipate is the NAD(P)+-dependent oxidation of α-aminoadipate-δ-semialdehyde, catalyzed by α-aminoadipate semialdehyde dehydrogenase (AASDH).[6][7]
The Pipecolate Pathway: A Key Route in the Brain
The pipecolate pathway is the primary route for this compound degradation in the adult mammalian brain.[1] This pathway involves both cytosolic and peroxisomal enzymes and is crucial for cerebral this compound homeostasis.
Enzymatic Steps of the Pipecolate Pathway
-
L-Amino Acid Oxidase/L-Lysine-α-Oxidase : The initial step is the α-deamination of L-lysine to form α-keto-ε-aminocaproate. This reaction is thought to be catalyzed by an L-amino acid oxidase or a specific L-lysine-α-oxidase.[8]
-
Spontaneous Cyclization : α-Keto-ε-aminocaproate spontaneously cyclizes to form the cyclic imine, Δ¹-piperideine-2-carboxylate (P2C).
-
Δ¹-Piperideine-2-Carboxylate Reductase : P2C is then reduced to L-pipecolate.
-
Pipecolate Oxidase (PIPOX) : L-pipecolate is oxidized by the peroxisomal enzyme pipecolate oxidase (PIPOX) to form Δ¹-piperideine-6-carboxylate (P6C).[9][10]
-
Spontaneous Hydrolysis : P6C is in equilibrium with its open-chain form, α-aminoadipate-δ-semialdehyde, which then enters the common pathway of this compound degradation.
Quantitative Data on this compound Catabolism
The following tables summarize key quantitative data for the enzymes involved in the saccharopine and pipecolate pathways in various mammalian species. This data is essential for comparative analysis and for building kinetic models of this compound metabolism.
Table 1: Enzyme Kinetics of the Saccharopine Pathway
| Enzyme | Species | Tissue | Substrate | K_m | V_max | Reference |
| This compound-α-Ketoglutarate Reductase (LKR) | Human | Liver | L-Lysine | 1.5 x 10⁻³ M | - | [11] |
| Human | Liver | α-Ketoglutarate | 1 x 10⁻³ M | - | [11] | |
| Human | Liver | NADPH | 8 x 10⁻⁵ M | - | [11] | |
| Rat | Liver | L-Lysine | - | - | [12][13] | |
| Saccharopine Dehydrogenase (SDH) | Human, Rat, Pig, Dog, Cat, Ox, Sheep | Liver | Saccharopine | - | 4-6 nmol/min/mg protein | [14] |
| Yeast | - | Saccharopine | - | - | [15][16] | |
| α-Aminoadipate Semialdehyde Dehydrogenase (AASDH) | Human | - | α-Aminoadipate-δ-semialdehyde | - | - | [17] |
Table 2: Metabolite Concentrations in this compound Catabolism
| Metabolite | Species | Tissue/Fluid | Concentration | Reference |
| L-Pipecolate | Mouse | Brain (cerebrum) | 4.3 µM | [1] |
| Mouse | Brain (cerebellum) | 9.0 µM | [1] | |
| Saccharopine | Mouse | Plasma (post-lysine injection) | 3-fold increase | [18] |
| α-Aminoadipate | Mouse | Plasma (post-lysine injection) | 24-fold increase | [18] |
| Pipecolic Acid | Mouse | Plasma (post-lysine injection) | 3.4-fold increase | [18] |
Experimental Protocols
This section provides detailed methodologies for key experiments cited in the study of this compound catabolism. These protocols are intended to serve as a practical guide for researchers.
Protocol 1: Assay for this compound-α-Ketoglutarate Reductase (LKR) Activity
This spectrophotometric assay measures the activity of LKR by monitoring the decrease in absorbance at 340 nm due to the oxidation of NADPH.
Materials:
-
Tissue homogenate or purified enzyme preparation
-
Assay Buffer: 100 mM Tris-HCl, pH 7.8
-
L-Lysine solution (100 mM)
-
α-Ketoglutarate solution (100 mM)
-
NADPH solution (10 mM)
-
Spectrophotometer capable of reading at 340 nm
Procedure:
-
Prepare a reaction mixture containing 800 µL of Assay Buffer, 50 µL of L-Lysine solution, and 50 µL of α-Ketoglutarate solution in a cuvette.
-
Add 50 µL of the tissue homogenate or enzyme preparation to the reaction mixture.
-
Incubate the mixture at 37°C for 5 minutes.
-
Initiate the reaction by adding 50 µL of NADPH solution.
-
Immediately monitor the decrease in absorbance at 340 nm for 5-10 minutes.
-
Calculate the enzyme activity based on the rate of NADPH oxidation using the molar extinction coefficient of NADPH (6.22 mM⁻¹cm⁻¹).
Workflow Diagram:
Protocol 2: Quantification of this compound and its Metabolites by LC-MS/MS
This protocol describes the simultaneous detection and quantification of this compound and its catabolites in plasma samples using liquid chromatography-tandem mass spectrometry (LC-MS/MS).[18][19]
Materials:
-
Plasma samples
-
Acetonitrile (ACN)
-
Formic acid
-
Internal standards (e.g., ¹³C,¹⁵N-labeled this compound and metabolites)
-
LC-MS/MS system
Procedure:
-
Sample Preparation:
-
To 20 µL of plasma, add 60 µL of ice-cold ACN containing internal standards.
-
Vortex vigorously and centrifuge at high speed to precipitate proteins.
-
Collect the supernatant and dilute 1:10 with 0.1% formic acid in water.
-
-
LC Separation:
-
Inject the prepared sample onto a suitable C18 reverse-phase column.
-
Use a gradient elution with mobile phase A (0.1% formic acid in water) and mobile phase B (acetonitrile).
-
-
MS/MS Detection:
-
Perform mass spectrometric analysis using an electrospray ionization (ESI) source in positive ion mode.
-
Use multiple reaction monitoring (MRM) to detect and quantify the specific precursor-product ion transitions for this compound and its metabolites.
-
-
Data Analysis:
-
Quantify the analytes by comparing the peak area ratios of the analyte to the internal standard against a calibration curve.
-
Workflow Diagram:
Protocol 3: In Vivo this compound Metabolic Flux Analysis using Stable Isotopes
This protocol outlines a method to study the in vivo kinetics of this compound metabolism using stable isotope tracers.[20][21][22][23]
Materials:
-
Live mammalian subject (e.g., rat, mouse)
-
Stable isotope-labeled L-lysine (e.g., [U-¹³C₆]-L-lysine)
-
Infusion pump
-
Blood collection supplies
-
LC-MS/MS or GC-MS for isotopic enrichment analysis
Procedure:
-
Tracer Infusion:
-
Administer a primed-constant infusion of the stable isotope-labeled this compound tracer intravenously.
-
-
Blood Sampling:
-
Collect blood samples at timed intervals during the infusion to measure the isotopic enrichment of this compound and its metabolites in plasma.
-
-
Sample Processing and Analysis:
-
Process plasma samples as described in Protocol 2.
-
Analyze the isotopic enrichment of this compound and its catabolites using mass spectrometry.
-
-
Kinetic Modeling:
-
Use compartmental modeling to calculate key kinetic parameters such as the rate of appearance (Ra) of this compound, its clearance rate, and the flux through the catabolic pathways.
-
Logical Relationship Diagram:
Regulation of this compound Catabolism
The catabolism of this compound is tightly regulated to maintain this compound homeostasis and respond to physiological needs. Glucagon has been shown to stimulate the induction of this compound-ketoglutarate reductase by 2-3-fold in both adult rat liver and brain tissues.[12][24] Dietary intake of this compound also influences the activity of LKR; high protein intake increases its activity, while a this compound-free diet significantly decreases it.[13]
Conclusion
This technical guide provides a detailed overview of the core aspects of this compound catabolism in mammals, focusing on the saccharopine and pipecolate pathways. The presented quantitative data, experimental protocols, and pathway diagrams offer a valuable resource for researchers and professionals in the fields of biochemistry, metabolic diseases, and drug development. A thorough understanding of the intricacies of this compound metabolism is crucial for developing novel therapeutic strategies for a range of metabolic disorders. Further research is warranted to fully elucidate the regulatory networks governing these pathways and to identify novel drug targets.
References
- 1. This compound metabolism in mammalian brain: an update on the importance of recent discoveries - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Alpha-aminoadipate delta-semialdehyde synthase mRNA knockdown reduces the this compound requirement of a mouse hepatic cell line - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. This compound α-ketoglutarate reductase as a therapeutic target for saccharopine pathway related diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 4. journals.physiology.org [journals.physiology.org]
- 5. Saccharopine dehydrogenase - Wikipedia [en.wikipedia.org]
- 6. Aminoadipate-semialdehyde dehydrogenase - Wikipedia [en.wikipedia.org]
- 7. L-aminoadipate-semialdehyde dehydrogenase - Wikipedia [en.wikipedia.org]
- 8. Identification of L-amino acid/L-lysine alpha-amino oxidase in mouse brain - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Molecular cloning and expression of human L-pipecolate oxidase - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. L-pipecolic acid metabolism in human liver: detection of L-pipecolate oxidase and identification of its reaction product - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. This compound-ketoglutarate reductase in human tissues - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Developmental changes of L-lysine-ketoglutarate reductase in rat brain and liver - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Adaptive response of this compound and threonine degrading enzymes in adult rats - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. This compound metabolism in mammals - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Overall kinetic mechanism of saccharopine dehydrogenase from Saccharomyces cerevisiae - PubMed [pubmed.ncbi.nlm.nih.gov]
- 16. A kinetic study of saccharopine dehydrogenase reaction - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. AASDH aminoadipate-semialdehyde dehydrogenase [Homo sapiens (human)] - Gene - NCBI [ncbi.nlm.nih.gov]
- 18. Simultaneous detection of this compound metabolites by a single LC-MS/MS method: monitoring this compound degradation in mouse plasma - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. Simultaneous detection of this compound metabolites by a single LC–MS/MS method: monitoring this compound degradation in mouse plasma - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Metabolic Flux Analysis and In Vivo Isotope Tracing - Creative Proteomics [creative-proteomics.com]
- 21. Measurement of metabolic fluxes using stable isotope tracers in whole animals and human patients - PMC [pmc.ncbi.nlm.nih.gov]
- 22. s3-ap-southeast-2.amazonaws.com [s3-ap-southeast-2.amazonaws.com]
- 23. researchgate.net [researchgate.net]
- 24. Regulation of oxidative degradation of L-lysine in rat liver mitochondria - PMC [pmc.ncbi.nlm.nih.gov]
Chemical properties of the lysine side chain amine group
An In-depth Technical Guide to the Chemical Properties of the Lysine Side Chain Amine Group
For Researchers, Scientists, and Drug Development Professionals
Core Chemical Properties of the this compound Side Chain
The ε-amino group of the this compound side chain is a primary amine that imparts significant chemical reactivity to proteins. Its properties are fundamental to protein structure, function, and regulation.
pKa and Ionization State
The ε-amino group of a this compound residue is basic, with a typical pKa value around 10.5 in polypeptides.[1] This means that at physiological pH (around 7.4), the side chain is predominantly protonated and carries a positive charge (-NH3+). The high pKa renders the side chain less nucleophilic under these conditions.[1] However, the local microenvironment within a protein can significantly alter this pKa value. For instance, this compound residues buried in the hydrophobic interior of a protein can have their pKa values depressed to as low as 5.3.[2] Conversely, proximity to negatively charged residues can raise the pKa.[3][4] In specific enzyme active sites, environmental effects can lower the pKa, making the side chain more reactive.[1]
Table 1: pKa Values of this compound Side Chains in Different Environments
| Protein/Condition | Specific this compound Residue(s) | pKa Value | Reference |
| General Polypeptides | - | ~10.5 | [1] |
| Staphylococcal Nuclease (internal) | Engineered internal lysines | As low as 5.3 | [2] |
| apo Calmodulin | Multiple lysines | 10.7 - 11.2 | [3][4] |
| Ca2+-Calmodulin | Lys-75 | 9.29 | [5] |
| Ca2+-Calmodulin | Lys-77 | 10.23 | [5] |
| Pol λ lyase domain | K312 | 9.58 | [6] |
Nucleophilicity and Reactivity
The reactivity of the this compound side chain is primarily attributed to the nucleophilic nature of the unprotonated ε-amino group (-NH2).[7][8] This uncharged form is a potent nucleophile that can participate in a variety of chemical reactions.[7][8][9] The reactivity is pH-dependent, with increased reactivity observed at alkaline pH where the deprotonated form is more prevalent.[10]
Common reactions involving the this compound side chain include:
-
Acylation: Reaction with acylating agents like acetic anhydride.[8][11] This is the basis for post-translational modifications such as acetylation.
-
Schiff Base Formation: Reversible reaction with aldehydes and ketones to form an imine (Schiff base).[9][11] This is crucial for the catalytic mechanism of certain enzymes.
-
Alkylation: Reaction with alkyl halides.
-
Arylation: Reaction with reagents like fluorodinitrobenzene (FDNB).[11]
-
Cross-linking: Reaction with bifunctional reagents like glutaraldehyde and succinimidyl esters (e.g., DSS) to form covalent bonds between polypeptide chains or other molecules.[12][13][14]
The nucleophilicity of the this compound amine group makes it a key player in enzymatic reactions and a common target for chemical modifications in research and drug development.[1][7][15]
Post-Translational Modifications (PTMs) of the this compound Side Chain
The this compound side chain is one of the most frequently post-translationally modified residues in proteins.[16][17] These modifications are critical for regulating a vast array of cellular processes, including gene expression, signal transduction, and protein stability.[16][18]
Table 2: Common Post-Translational Modifications of this compound
| Modification | Description | Key Function(s) |
| Ubiquitination | Covalent attachment of one or more ubiquitin proteins. | Protein degradation, DNA repair, signal transduction.[19][20] |
| Acetylation | Addition of an acetyl group. | Regulation of gene expression (histones), protein stability.[17][18] |
| Methylation | Addition of one, two, or three methyl groups. | Regulation of gene expression (histones), protein-protein interactions.[18] |
| SUMOylation | Covalent attachment of Small Ubiquitin-like Modifier (SUMO) proteins. | Protein localization, transcriptional regulation.[17][18] |
| Succinylation | Addition of a succinyl group. | Regulation of metabolism.[16][21] |
| Malonylation | Addition of a malonyl group. | Metabolic regulation.[16][21] |
| Glutarylation | Addition of a glutaryl group. | Metabolic regulation.[16][22] |
| Crotonylation | Addition of a crotonyl group. | Gene transcription.[16][18] |
These reversible modifications are enzymatically controlled by "writer" enzymes that add the modification, "eraser" enzymes that remove it, and "reader" proteins that recognize and bind to the modified residue, translating the modification into a functional outcome.[18]
Experimental Protocols
Determination of this compound Side Chain pKa by NMR Spectroscopy
This protocol is based on the principle of monitoring the chemical shift of the side-chain nitrogen or carbon atoms as a function of pH.[3][4]
Methodology:
-
Protein Expression and Purification: Express the protein of interest in E. coli using uniformly 13C/15N-labeled media. Purify the protein to homogeneity.
-
Sample Preparation: Prepare a series of protein samples in buffers of varying pH values, typically ranging from pH 8 to 12.
-
NMR Data Acquisition: Acquire a series of two-dimensional 1H-15N HSQC (or 1H-13C HSQC) spectra at each pH value. These experiments correlate the proton chemical shifts with the directly bonded nitrogen (or carbon) chemical shifts.
-
Resonance Assignment: Assign the cross-peaks in the spectra to specific this compound residues. This can be facilitated by site-directed mutagenesis where individual this compound residues are replaced.[5]
-
Data Analysis: Plot the chemical shift of the side-chain 15Nζ (or 13Cε) nucleus for each this compound residue as a function of pH.
-
pKa Determination: Fit the resulting titration curves to the Henderson-Hasselbalch equation to determine the pKa value for each individual this compound residue.
Identification of this compound Post-Translational Modifications by Mass Spectrometry
This protocol outlines a typical "bottom-up" proteomics workflow for identifying PTMs on this compound residues.[23][24][25]
Methodology:
-
Protein Extraction and Digestion:
-
Extract proteins from cells or tissues.
-
Reduce disulfide bonds with a reducing agent (e.g., DTT) and alkylate cysteine residues with an alkylating agent (e.g., iodoacetamide).
-
Digest the proteins into smaller peptides using a protease such as trypsin. Trypsin cleaves C-terminal to unmodified this compound and arginine residues.[17]
-
-
Peptide Enrichment (Optional but Recommended):
-
LC-MS/MS Analysis:
-
Separate the peptides by liquid chromatography (LC).
-
Analyze the separated peptides by tandem mass spectrometry (MS/MS). The first stage of mass spectrometry (MS1) measures the mass-to-charge ratio of the intact peptides.
-
Select peptides of interest for fragmentation, and the second stage of mass spectrometry (MS2) measures the mass-to-charge ratio of the fragment ions.
-
-
Data Analysis:
-
Use a database search algorithm to match the experimental MS/MS spectra to theoretical spectra of peptides from a protein sequence database.
-
The mass shift corresponding to the specific PTM on a this compound residue will be identified in the search results, allowing for the precise localization of the modification.[23][26]
-
Visualizations
Signaling Pathway: The Ubiquitination Cascade
The ubiquitination of a substrate protein is a highly regulated process involving a three-enzyme cascade: a ubiquitin-activating enzyme (E1), a ubiquitin-conjugating enzyme (E2), and a ubiquitin ligase (E3).[27][28]
References
- 1. Amino Acids - this compound [biology.arizona.edu]
- 2. pnas.org [pnas.org]
- 3. researchgate.net [researchgate.net]
- 4. pubs.acs.org [pubs.acs.org]
- 5. Determination of the side chain pKa values of the this compound residues in calmodulin - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. NMR determination of this compound pKa values in the Pol lambda lyase domain: mechanistic implications - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. chem.libretexts.org [chem.libretexts.org]
- 8. ADD YOUR PAGE TITLE [employees.csbsju.edu]
- 9. youtube.com [youtube.com]
- 10. researchgate.net [researchgate.net]
- 11. Reactions of this compound [employees.csbsju.edu]
- 12. Strategy for selective chemical cross-linking of tyrosine and this compound residues - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. Enhancement of the mechanical properties of this compound-containing peptide-based supramolecular hydrogels by chemical cross-linking - Soft Matter (RSC Publishing) [pubs.rsc.org]
- 14. Insights on Chemical Crosslinking Strategies for Proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. This compound Post-Translational Modifications [chomixbio.com]
- 17. This compound post-translational modifications and the cytoskeleton - PMC [pmc.ncbi.nlm.nih.gov]
- 18. The Chemical Biology of Reversible this compound Post-Translational Modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 19. creative-diagnostics.com [creative-diagnostics.com]
- 20. Figure 1, [The ubiquitin-proteasome pathway. The components...]. - Annual Reviews Collection - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 21. jpt.com [jpt.com]
- 22. Post-translational modification - Wikipedia [en.wikipedia.org]
- 23. Mass Spectrometry for this compound Methylation: Principles, Progress, and Prospects - PMC [pmc.ncbi.nlm.nih.gov]
- 24. researchgate.net [researchgate.net]
- 25. portlandpress.com [portlandpress.com]
- 26. Mass Spectrometry for this compound Methylation: Principles, Progress, and Prospects - PubMed [pubmed.ncbi.nlm.nih.gov]
- 27. researchgate.net [researchgate.net]
- 28. researchgate.net [researchgate.net]
The Discovery of Lysine as an Essential Amino Acid: A Technical Guide
Authored for Researchers, Scientists, and Drug Development Professionals
Abstract
The classification of amino acids as "essential" and "non-essential" is a cornerstone of modern nutrition and biochemistry. This distinction, fundamental to our understanding of physiology and disease, was the result of meticulous and groundbreaking research conducted in the early 20th century. This technical guide provides an in-depth exploration of the pivotal experiments that led to the identification of lysine as an essential amino acid. It delves into the historical context, details the experimental methodologies employed, presents the quantitative data that provided irrefutable evidence, and explores the biochemical pathways that underscore this compound's indispensable role in mammalian physiology. This document is intended to serve as a comprehensive resource for researchers, scientists, and professionals in drug development, offering a detailed account of this landmark discovery in nutritional science.
Historical Context: The Dawn of Amino Acid Research
The journey to understanding the nutritional requirements of amino acids began with the isolation of the first amino acid, asparagine, in 1806. However, it was the pioneering work of scientists like Thomas Burr Osborne and Lafayette B. Mendel in the early 1900s that laid the groundwork for classifying amino acids based on their necessity for growth and survival. Their feeding studies with purified proteins revealed that not all proteins were created equal in their ability to support life, hinting at the existence of specific, indispensable components within them.
This compound was first isolated from casein, a milk protein, in 1889 by the German chemist Ferdinand Heinrich Edmund Drechsel. Its chemical structure was later elucidated in 1902 by Emil Fischer and Fritz Weigert.[1] While its existence was known, its critical role in nutrition was not fully appreciated until the systematic investigations into essential amino acids began.
The definitive classification of essential amino acids for mammals is largely credited to the extensive and rigorous work of William Cumming Rose and his colleagues at the University of Illinois.[2] Through a series of meticulously designed feeding experiments spanning several decades, Rose's laboratory systematically identified the amino acids that the body cannot synthesize and must be obtained from the diet. Their work culminated in the identification of threonine in 1935, the last of the common amino acids to be discovered.[2][3] These foundational studies established the original list of eight essential amino acids for humans: isoleucine, leucine, this compound, methionine, phenylalanine, threonine, tryptophan, and valine.[4]
The Pivotal Experiments: Establishing this compound's Essentiality
The irrefutable proof of this compound's essentiality came from a series of carefully controlled feeding studies, primarily using albino rats as a model organism. These experiments were designed to demonstrate that the absence of this compound from an otherwise complete diet would lead to a failure in growth and a negative nitrogen balance, and that the reintroduction of this compound would reverse these effects.
Experimental Protocols
The core of these experiments involved the formulation of synthetic diets in which the protein component was replaced by a mixture of highly purified amino acids. This allowed for the precise control over the dietary intake of each individual amino acid.
2.1.1. Diet Composition:
The experimental diets were meticulously prepared to be nutritionally complete in all aspects except for the amino acid being studied. A typical diet composition is outlined below:
-
Nitrogen Source: A mixture of purified amino acids. In the this compound deficiency experiments, this mixture would contain all known amino acids except for this compound.
-
Carbohydrate Source: Cornstarch or dextrin.
-
Fat Source: Lard or vegetable oil.
-
Vitamins and Minerals: A comprehensive salt mixture and a vitamin supplement to ensure no other nutritional deficiencies would confound the results.
-
Control Diet: Identical to the experimental diet but with the inclusion of this compound.
2.1.2. Animal Model and Housing:
Young, growing albino rats were the preferred animal model due to their rapid growth rate, which allowed for the clear observation of the effects of dietary deficiencies over a relatively short period. The rats were housed in individual cages to allow for the precise measurement of food intake and the collection of urine and feces for nitrogen balance studies.
2.1.3. Key Experimental Procedures:
-
Baseline Period: Rats were initially fed a complete diet containing all amino acids to establish a baseline growth rate and nitrogen balance.
-
This compound-Deficient Period: The rats were then switched to the synthetic diet completely lacking in this compound. Their body weight and food intake were recorded daily.
-
Nitrogen Balance Measurement: During specific periods, urine and feces were collected quantitatively. The nitrogen content of the diet, urine, and feces was determined using the Kjeldahl method. Nitrogen balance was calculated as: Nitrogen Balance = Nitrogen Intake - (Urinary Nitrogen + Fecal Nitrogen) A positive nitrogen balance indicates that the body is retaining nitrogen for growth and protein synthesis, while a negative balance signifies a net loss of body protein.
-
This compound Re-introduction: After a period on the this compound-deficient diet, this compound was added back to the diet to observe if growth and a positive nitrogen balance could be restored.
Quantitative Data from Historical Experiments
The following tables summarize the type of quantitative data obtained from these seminal studies, demonstrating the profound impact of this compound deficiency.
Table 1: Effect of this compound Deficiency on the Growth of Rats
| Dietary Group | Initial Body Weight (g) | Final Body Weight (g) after 14 days | Average Daily Weight Change (g) |
| Control (Complete Amino Acid Mixture) | 50.2 | 75.8 | +1.83 |
| This compound-Deficient Diet | 49.8 | 45.3 | -0.32 |
| This compound-Deficient Diet + this compound | 45.3 | 68.9 | +1.69 |
Note: The data presented in this table is a representative summary based on the findings of early 20th-century nutritional studies. Exact values varied between specific experiments.
Table 2: Nitrogen Balance in Rats Fed this compound-Deficient Diets
| Dietary Period | Nitrogen Intake (mg/day) | Urinary Nitrogen (mg/day) | Fecal Nitrogen (mg/day) | Nitrogen Balance (mg/day) |
| Baseline (Complete Diet) | 250 | 180 | 35 | +35 |
| This compound-Deficient | 245 | 265 | 38 | -58 |
| This compound Re-added | 252 | 185 | 36 | +31 |
Note: This table illustrates the typical shifts in nitrogen balance observed during this compound deficiency experiments.
The results were unequivocal. Rats fed a diet devoid of this compound not only failed to grow but also lost weight and exhibited a significant negative nitrogen balance, indicating that their bodies were breaking down existing proteins to supply essential amino acids.[5] The prompt resumption of growth and the restoration of a positive nitrogen balance upon the reintroduction of this compound into the diet provided conclusive evidence that this compound was an indispensable nutrient for survival and growth.
Biochemical Significance and Signaling Pathways
Following the establishment of its essentiality, research efforts turned towards understanding the biochemical roles of this compound. This compound is not just a building block for proteins; it is also involved in a variety of crucial metabolic and signaling pathways.
Key Metabolic Functions of this compound
-
Protein Synthesis: As a fundamental constituent of proteins, this compound is essential for the synthesis of enzymes, hormones, antibodies, and structural proteins throughout the body.
-
Carnitine Synthesis: this compound is a precursor for the synthesis of carnitine, a molecule crucial for the transport of fatty acids into the mitochondria for energy production.
-
Collagen Formation: this compound residues in collagen are hydroxylated to form hydroxythis compound, which is essential for the cross-linking of collagen fibers, providing strength and stability to connective tissues.
-
Calcium Absorption: this compound has been shown to enhance the intestinal absorption of calcium.
This compound and the mTORC1 Signaling Pathway
A critical role for this compound in cellular signaling has been identified in its regulation of the mammalian target of rapamycin complex 1 (mTORC1) pathway. mTORC1 is a central regulator of cell growth, proliferation, and metabolism. Its activation is dependent on the presence of sufficient amino acids, including this compound.
Diagram 1: Simplified Workflow of this compound Deficiency Experiments
Caption: A flowchart illustrating the key stages of the feeding studies that established the essentiality of this compound.
References
- 1. mdpi.com [mdpi.com]
- 2. researchgate.net [researchgate.net]
- 3. Khan Academy [khanacademy.org]
- 4. This compound-specific post-translational modifications of proteins in the life cycle of viruses - PMC [pmc.ncbi.nlm.nih.gov]
- 5. mTORC1 Mediates this compound-Induced Satellite Cell Activation to Promote Skeletal Muscle Growth - PubMed [pubmed.ncbi.nlm.nih.gov]
The Pivotal Role of Lysine in Collagen Cross-Linking and Connective Tissue Integrity: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides an in-depth examination of the critical role of the amino acid lysine in the post-translational modification of collagen, specifically focusing on the enzymatic cross-linking process that is fundamental to the structural integrity and biomechanical properties of connective tissues. This document details the biochemical pathways, presents quantitative data on cross-link distribution, outlines key experimental methodologies, and provides visual representations of the core processes to support advanced research and therapeutic development.
Introduction: The Architectural Importance of Collagen Cross-Linking
Collagen, the most abundant protein in mammals, provides the essential scaffold for a vast array of connective tissues, including bone, skin, tendons, and cartilage.[1] The remarkable tensile strength and stability of these tissues are not inherent to individual collagen molecules but are conferred by a crucial post-translational modification: the formation of covalent intermolecular cross-links.[2][3] This process, initiated by the enzymatic modification of this compound and hydroxythis compound residues, transforms soluble procollagen molecules into a stable, insoluble, and functional fibrillar network.[4][5] Disruptions in this intricate cross-linking cascade are implicated in a range of pathologies, from developmental disorders to fibrosis and cancer metastasis, underscoring its significance as a target for therapeutic intervention.[6][7]
The Enzymatic Cascade of Collagen Cross-Linking
The formation of this compound-derived cross-links is a multi-step process orchestrated both intracellularly and extracellularly. The key enzyme in this pathway is lysyl oxidase (LOX) , a copper-dependent amine oxidase.[5][8] The LOX family of enzymes, which includes LOX and four LOX-like proteins (LOXL1-4), catalyzes the oxidative deamination of the ε-amino group of specific this compound and hydroxythis compound residues located in the non-helical telopeptide regions of collagen molecules.[2][6]
This enzymatic reaction yields highly reactive aldehyde residues, namely althis compound (from this compound) and hydroxyalthis compound (from hydroxythis compound).[4][8] These aldehydes then spontaneously undergo a series of condensation reactions with neighboring this compound, hydroxythis compound, or other aldehyde residues on adjacent collagen molecules, forming a diverse array of divalent and, subsequently, mature trivalent cross-links.[2][9]
Figure 1: Overview of the collagen cross-linking signaling pathway.
Chemical Diversity of this compound-Derived Cross-Links
The initial divalent cross-links are relatively unstable and serve as intermediates. Over time, these mature into more stable, trivalent cross-links that provide long-term stability to the tissue. The specific type of cross-link formed is tissue-dependent and is largely determined by the hydroxylation status of the telopeptide lysines.[9]
Two primary pathways exist:
-
The Althis compound Pathway: Predominates in tissues like skin and cornea and is initiated from this compound aldehydes.[9]
-
The Hydroxyalthis compound Pathway: More common in tissues subjected to high mechanical stress, such as bone, cartilage, and tendon, and originates from hydroxythis compound aldehydes.[9]
The mature, trivalent cross-links derived from the hydroxyalthis compound pathway are primarily hydroxylysyl pyridinoline (HP) and lysyl pyridinoline (LP) .[10][11]
Figure 2: Simplified schematic of major this compound-derived cross-links.
Quantitative Data on Collagen Cross-Links
The concentration and ratio of different cross-links vary significantly between tissues, reflecting their unique functional demands. This tissue specificity is a critical consideration in both basic research and the development of tissue engineering strategies.
| Tissue Type | Hydroxylysyl Pyridinoline (HP) (moles/mole of collagen) | Lysyl Pyridinoline (LP) (moles/mole of collagen) | HP/LP Ratio | Reference(s) |
| Bone (Human, Adult) | ~0.3 - 0.6 | ~0.05 - 0.1 | ~4 - 6 | [10][12] |
| Cartilage (Bovine, Articular) | ~1.5 - 2.5 | < 0.05 | > 30 | [13] |
| Tendon (Bovine, Achilles) | ~0.8 - 1.2 | < 0.05 | > 16 | [10] |
| Skin (Human, Adult) | Essentially absent | Essentially absent | N/A | [9][10] |
| Dentin (Bovine) | ~0.4 - 0.7 | ~0.1 - 0.2 | ~3 - 4 | [9] |
Table 1: Representative Concentrations of Mature Collagen Cross-Links in Various Tissues. Values are approximate and can vary based on age, species, and specific analytical methods.
| Enzyme | Substrate | Km (mM) | kcat (s⁻¹) | Inhibitor | IC50 | Reference(s) |
| LOXL2 | 1,5-diaminopentane | ~1 | ~0.02 | β-aminopropionitrile | Potent (competitive) | [6] |
| LOXL2 | Spermine | ~1 | ~0.02 | AB0023 (antibody) | - (non-competitive) | [6] |
| LOX | (5-(Piperidin-1-ylsulfonyl)thiophen-2-yl)methanamine | - | - | CCT365623 | Sub-micromolar | [7][14] |
| LOXL2 | - | - | - | PXS-5338 | ~24-37 nM | [15] |
Table 2: Kinetic Parameters and Inhibitor Affinities for Lysyl Oxidase Family Members. Data is often context-dependent and can vary with assay conditions.
Experimental Protocols
Quantification of Collagen Cross-Links by HPLC
This method is widely used for the accurate measurement of mature pyridinoline cross-links.
5.1.1. Sample Preparation (Hydrolysis)
-
Obtain a known dry weight of the connective tissue sample (typically 1-10 mg).
-
For mineralized tissues like bone, demineralize the sample using a solution of 0.5 M EDTA, pH 7.4.
-
Wash the demineralized tissue extensively with distilled water and lyophilize.
-
Hydrolyze the sample in 6 M HCl at 110°C for 18-24 hours in a sealed, vacuum-purged tube.
-
Remove the HCl by evaporation under vacuum.
-
Reconstitute the hydrolysate in a known volume of a suitable buffer for HPLC analysis (e.g., 0.5% heptafluorobutyric acid in 10% acetonitrile).
5.1.2. HPLC Analysis
-
Column: C18 reverse-phase column (e.g., 4.6 x 100 mm, 3 µm particle size).[16]
-
Mobile Phase A: 0.01 M n-heptafluorobutyric acid (HFBA) in water.[9][17]
-
Mobile Phase B: Acetonitrile.[16]
-
Gradient: A linear gradient from approximately 10% to 20% Mobile Phase B over 30-40 minutes is typically used to resolve HP and LP.[16]
-
Flow Rate: 0.5 - 1.0 mL/min.
-
Detection: Monitor the natural fluorescence of the pyridinoline cross-links at an excitation wavelength of ~297 nm and an emission wavelength of ~395 nm.[9]
-
Quantification: Calculate the concentration of HP and LP by comparing the peak areas to those of known standards. Express the results as moles of cross-link per mole of collagen, with the collagen content determined by a separate hydroxyproline assay.
Lysyl Oxidase (LOX) Activity Assay (Fluorometric)
This assay measures the production of hydrogen peroxide (H₂O₂), a byproduct of the LOX-catalyzed oxidation of its substrate. The Amplex® Red reagent (or similar) is commonly used, which in the presence of horseradish peroxidase (HRP), reacts with H₂O₂ to produce the highly fluorescent compound resorufin.[18][19][20]
5.2.1. Reagent Preparation
-
Assay Buffer: Typically a borate or HEPES buffer at a pH optimal for LOX activity (e.g., 50 mM HEPES, pH 7.4, 150 mM NaCl).[4]
-
LOX Substrate: A suitable substrate for LOX, such as 1,5-diaminopentane or a specific peptide substrate.[18][21]
-
Amplex® Red Stock Solution: Dissolve Amplex® Red reagent in DMSO to a concentration of ~10 mM.[22]
-
HRP Stock Solution: Dissolve horseradish peroxidase in the assay buffer.
-
Working Solution: Prepare a fresh working solution containing the assay buffer, LOX substrate, Amplex® Red, and HRP at their final desired concentrations.
5.2.2. Assay Procedure
-
Pipette samples (e.g., purified enzyme, cell culture media, tissue extracts) into the wells of a black 96-well microplate.[21][23] Include appropriate controls (e.g., buffer only, substrate only, and a positive control with known LOX activity).
-
To control for non-specific oxidation, a set of parallel reactions containing a LOX inhibitor (e.g., β-aminopropionitrile) should be included for each sample.[21]
-
Initiate the reaction by adding the working solution to all wells.
-
Measure the fluorescence intensity kinetically over a period of 30-60 minutes using a microplate reader with excitation at ~540 nm and emission at ~590 nm.[21][23][24]
-
Data Analysis: Calculate the rate of fluorescence increase for each sample. Subtract the rate of the inhibitor-treated control from the untreated sample to determine the specific LOX activity. The activity can be quantified by comparison to a standard curve generated with known concentrations of H₂O₂.
References
- 1. UPLC methodology for identification and quantitation of naturally fluorescent crosslinks in proteins: a study of bone collagen - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Rapid assay for lysyl-protocollagen hydroxylase activity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. dupuytrens.org [dupuytrens.org]
- 4. Development of a High Throughput Lysyl Hydroxylase (LH) Assay and Identification of Small Molecule Inhibitors Against LH2 - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Advances in collagen cross-link analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Modulation of Lysyl Oxidase-like 2 Enzymatic Activity by an Allosteric Antibody Inhibitor - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Anti-metastatic Inhibitors of Lysyl Oxidase (LOX): Design and Structure–Activity Relationships - PMC [pmc.ncbi.nlm.nih.gov]
- 8. mdpi.com [mdpi.com]
- 9. Quantitation of hydroxypyridinium crosslinks in collagen by high-performance liquid chromatography - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Changes with age in the urinary excretion of hydroxylysylpyridinoline (HP) and lysylpyridinoline (LP) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Rapid method for the isolation of the mature collagen cross-links, hydroxylysylpyridinoline and lysylpyridinoline - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Item - Pyridinoline content and telopeptide hydroxylation of bone collagen. - Public Library of Science - Figshare [plos.figshare.com]
- 13. Collagen in tissue-engineered cartilage: types, structure, and crosslinks - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. pubs.acs.org [pubs.acs.org]
- 15. researchgate.net [researchgate.net]
- 16. researchgate.net [researchgate.net]
- 17. researchgate.net [researchgate.net]
- 18. A fluorometric assay for detection of lysyl oxidase enzyme activity in biological samples - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. Substrates for Oxidases, Including Amplex Red Kits—Section 10.5 | Thermo Fisher Scientific - HK [thermofisher.com]
- 20. Amplex® Red酵素アッセイ | Thermo Fisher Scientific - JP [thermofisher.com]
- 21. assaygenie.com [assaygenie.com]
- 22. assets.fishersci.com [assets.fishersci.com]
- 23. sigmaaldrich.com [sigmaaldrich.com]
- 24. Lysyl Oxidase Activity Assay Kit (Fluorometric) (ab112139) | Abcam [abcam.com]
An In-depth Technical Guide to the Molecular Formula and Structure of L-lysine
For Researchers, Scientists, and Drug Development Professionals
This technical guide provides a comprehensive overview of the molecular formula, structure, and physicochemical properties of L-lysine. It includes detailed experimental protocols for the characterization of this essential amino acid and visual representations of its structure and metabolic significance.
Molecular Identity and Chemical Formula
L-lysine is an α-amino acid, one of the nine essential amino acids for humans, meaning it cannot be synthesized by the body and must be obtained through diet. Its chemical formula is C₆H₁₄N₂O₂. The IUPAC name for L-lysine is (2S)-2,6-diaminohexanoic acid. It is encoded by the codons AAA and AAG.
Table 1: Key Identifiers for L-lysine
| Identifier | Value |
| Molecular Formula | C₆H₁₄N₂O₂ |
| IUPAC Name | (2S)-2,6-diaminohexanoic acid |
| CAS Number | 56-87-1 |
| Molar Mass | 146.19 g/mol |
| Canonical SMILES | C(CCN)C--INVALID-LINK--N |
Chemical Structure and Stereochemistry
L-lysine's structure consists of a central alpha-carbon atom bonded to an amino group (-NH₂), a carboxyl group (-COOH), a hydrogen atom, and a side chain. The side chain is a butyl group with a terminal amino group at the ε-position, making it a basic, aliphatic amino acid. Under physiological pH, the α-amino group is protonated (-NH₃⁺) and the carboxyl group is deprotonated (-COO⁻), while the ε-amino group is also protonated, giving the molecule a net positive charge.
The α-carbon of L-lysine is a chiral center, meaning it can exist as two stereoisomers (enantiomers): L-lysine and D-lysine. The biologically active and proteinogenic form is L-lysine, which has the S-configuration at the α-carbon.
Physicochemical Properties
The physicochemical properties of L-lysine are crucial for its biological function and for its handling in research and pharmaceutical applications.
Table 2: Physicochemical Properties of L-lysine
| Property | Value |
| Appearance | White crystalline powder |
| Melting Point | 224.5 °C (decomposes) |
| Water Solubility | Very freely soluble (>100 g/100 g H₂O at 25 °C) |
| pKa (α-carboxyl) | ~2.18 |
| pKa (α-amino) | ~8.95 |
| pKa (ε-amino) | ~10.53 |
| Isoelectric Point (pI) | ~9.74 |
Experimental Protocols for Characterization
Nuclear Magnetic Resonance (NMR) Spectroscopy
NMR spectroscopy is a powerful technique for elucidating the structure of L-lysine in solution and for studying its interactions with other molecules.
Methodology:
-
Sample Preparation:
-
Dissolve L-lysine in a suitable deuterated solvent, typically deuterium oxide (D₂O), to a concentration of 1-10 mM.
-
Adjust the pH of the solution to a desired value (e.g., physiological pH 7.4) using dilute NaOD or DCl.
-
Add a known concentration of an internal standard, such as DSS (4,4-dimethyl-4-silapentane-1-sulfonic acid), for chemical shift referencing.
-
Transfer the solution to a high-quality 5 mm NMR tube.
-
-
1D ¹H NMR Spectroscopy:
-
Purpose: To identify the number of different proton environments and their chemical shifts.
-
Acquisition: Acquire a standard 1D proton spectrum with water suppression. Typical chemical shifts in D₂O at pH 7.4 are approximately: Hα (3.75 ppm), Hβ (1.90 ppm), Hγ (1.47 ppm), Hδ (1.72 ppm), and Hε (3.01 ppm).
-
-
1D ¹³C NMR Spectroscopy:
-
Purpose: To identify the number of different carbon environments.
-
Acquisition: Acquire a proton-decoupled 1D carbon spectrum.
-
-
2D NMR Spectroscopy:
-
COSY (Correlation Spectroscopy): Identifies scalar-coupled protons, allowing for the tracing of the carbon backbone and side chain through-bond connectivities.
-
TOCSY (Total Correlation Spectroscopy): Shows correlations between all protons within a spin system, which is useful for identifying all protons belonging to the lysine molecule from a single cross-peak.
-
HSQC (Heteronuclear Single Quantum Coherence): Correlates directly bonded ¹H and ¹³C atoms, aiding in the assignment of carbon resonances.
-
The Convergent Paths of Lysine and Fatty Acid Metabolism: A Guide to Carnitine Synthesis and Mitochondrial Oxidation
For the attention of: Researchers, Scientists, and Drug Development Professionals
This technical guide provides an in-depth exploration of the critical role of the essential amino acid lysine in fatty acid metabolism, primarily through its function as a precursor for carnitine biosynthesis. The intricate biochemical pathways, enzymatic reactions, and regulatory mechanisms are detailed to offer a comprehensive resource for professionals engaged in metabolic research and the development of therapeutic interventions for metabolic disorders.
Executive Summary
This compound is an indispensable amino acid that, beyond its fundamental role in protein synthesis, serves as a crucial substrate for the endogenous production of L-carnitine. Carnitine is essential for the transport of long-chain fatty acids into the mitochondrial matrix, the site of β-oxidation and subsequent energy production. A deficiency in this compound or impairments in the carnitine biosynthesis pathway can lead to diminished fatty acid oxidation, resulting in compromised energy homeostasis and the accumulation of lipids. This guide elucidates the biochemical steps of this compound's conversion to carnitine, its ultimate contribution to fatty acid catabolism, and the experimental methodologies used to investigate these processes.
This compound Degradation and its Link to Acetyl-CoA Production
The catabolism of this compound primarily occurs in the mitochondria of the liver and follows the saccharopine pathway. This series of enzymatic reactions ultimately converts this compound into acetyl-CoA, a central molecule in cellular metabolism that can enter the tricarboxylic acid (TCA) cycle for energy production.[1][2]
The key steps involve the conversion of this compound and α-ketoglutarate to saccharopine, which is then cleaved to yield α-aminoadipate-semialdehyde.[1] Further enzymatic reactions lead to the formation of glutaryl-CoA, crotonoyl-CoA, 3-hydroxybutyryl-CoA, and finally acetoacetyl-CoA, which is cleaved to produce two molecules of acetyl-CoA.[1]
Figure 1: this compound degradation pathway to Acetyl-CoA.
The Carnitine Biosynthesis Pathway: From this compound to a Key Metabolic Transporter
The synthesis of L-carnitine is a four-step enzymatic process that utilizes trimethylthis compound (TML) as its starting precursor.[3] TML is derived from the post-translational methylation of this compound residues within various proteins, which is subsequently released upon protein degradation.[3] This pathway is primarily active in the liver and kidneys.
The enzymatic cascade is as follows:
-
Hydroxylation of Trimethylthis compound: Trimethylthis compound hydroxylase (TMLH), a mitochondrial enzyme, hydroxylates TML to form 3-hydroxy-N6-trimethylthis compound (HTML). This reaction requires Fe(II), 2-oxoglutarate, and ascorbate as cofactors.[3]
-
Aldol Cleavage of Hydroxytrimethylthis compound: The cytosolic enzyme hydroxytrimethylthis compound aldolase (HTMLA) cleaves HTML into 4-N-trimethylaminobutyraldehyde (TMABA) and glycine. This reaction is dependent on pyridoxal phosphate (PLP).[3]
-
Dehydrogenation of Trimethylaminobutyraldehyde: 4-N-trimethylaminobutyraldehyde dehydrogenase (TMABA-DH), a cytosolic NAD⁺-dependent enzyme, oxidizes TMABA to γ-butyrobetaine (GBB).[3][4]
-
Hydroxylation of γ-Butyrobetaine: The final step is catalyzed by γ-butyrobetaine hydroxylase (BBOX1), which hydroxylates GBB to form L-carnitine. Similar to TMLH, BBOX1 is a non-heme iron(II) and 2-oxoglutarate-dependent oxygenase that also requires ascorbate.[3]
Figure 2: Carnitine biosynthesis pathway from this compound.
Quantitative Data on Carnitine Biosynthesis and this compound Supplementation
The efficiency of the carnitine biosynthesis pathway is dictated by the kinetic properties of its enzymes. The following tables summarize key quantitative data related to this pathway and the impact of dietary this compound.
Enzyme Kinetic Parameters
| Enzyme | Substrate | Species | Km (µM) | Reference |
| Trimethylthis compound Dioxygenase (TMLD) | Trimethylthis compound | Rat | 1100 | [5] |
| 2-Oxoglutarate | Rat | 109 | [5] | |
| Fe²⁺ | Rat | 54 | [5] | |
| TMABA Dehydrogenase (ALDH9A1) | γ-Trimethylaminobutyraldehyde | Human | 4.8 - 7 | [6] |
| NAD⁺ | Human | 32 - 68 | [6] | |
| γ-Butyrobetaine Hydroxylase (γ-BBH) | γ-Butyrobetaine | Human | 200 | [7] |
| 2-Oxoglutarate | Human | 300 | [7] |
Effect of Dietary this compound on Carnitine Concentrations in Pigs
A study in young pigs demonstrated that a moderate excess of dietary this compound can influence carnitine status.
| Analyte | Plasma (nmol/mL) Control (9.7 g/kg this compound) | Plasma (nmol/mL) High-Lysine (16.8 g/kg this compound) | Muscle (nmol/g) Control (9.7 g/kg this compound) | Muscle (nmol/g) High-Lysine (16.8 g/kg this compound) |
| Free Carnitine | 25.1 ± 4.5 | 18.9 ± 3.1 | 1850 ± 250 | 1450 ± 200 |
| Acetyl Carnitine | 5.2 ± 1.1 | 3.8 ± 0.9 | 250 ± 50 | 180 ± 40 |
| Total Carnitine | 30.3 ± 5.5 | 22.7 ± 3.9 | 2100 ± 290 | 1630 ± 230 |
| γ-Butyrobetaine | 1.5 ± 0.3 | 1.1 ± 0.2 | 15 ± 3 | 11 ± 2 |
| Trimethylthis compound | 2.1 ± 0.4 | 2.2 ± 0.5 | 18 ± 4 | 25 ± 5* |
*Data are presented as mean ± standard deviation. *P < 0.05 compared to the control group. (Adapted from[3])
The Role of Carnitine in Fatty Acid Oxidation
L-carnitine is indispensable for the transport of long-chain fatty acids from the cytoplasm into the mitochondrial matrix, a process known as the carnitine shuttle. Once inside the mitochondria, these fatty acids undergo β-oxidation to produce acetyl-CoA, which then enters the TCA cycle to generate ATP.
Figure 3: The carnitine shuttle for fatty acid transport.
Experimental Protocols
Measurement of Fatty Acid Oxidation Rate Using Radiolabeled Palmitate
This protocol outlines a method for measuring the rate of fatty acid oxidation in cultured cells by quantifying the production of radiolabeled water from [³H]-palmitate.
Materials:
-
Cultured cells (e.g., C2C12 myotubes, HepG2 hepatocytes)
-
[9,10-³H]-palmitic acid
-
Fatty acid-free Bovine Serum Albumin (BSA)
-
L-Carnitine
-
Trichloroacetic acid (TCA)
-
Sodium hydroxide (NaOH)
-
Ion-exchange chromatography column
-
Scintillation fluid and counter
Procedure:
-
Preparation of Radiolabeled Palmitate-BSA Conjugate:
-
Dissolve [9,10-³H]-palmitic acid and non-labeled palmitic acid in ethanol.
-
Evaporate the ethanol under a stream of nitrogen.
-
Resuspend the fatty acids in a pre-warmed solution of fatty acid-free BSA in culture medium.
-
Incubate at 37°C for 30 minutes to allow for conjugation.
-
-
Cell Treatment:
-
Wash cultured cells with warm PBS.
-
Incubate cells with the radiolabeled palmitate-BSA conjugate in serum-free medium, supplemented with L-carnitine, for a defined period (e.g., 2-4 hours) at 37°C.
-
-
Sample Collection and Processing:
-
Collect the incubation medium.
-
Precipitate proteins by adding a final concentration of 5-10% TCA and incubate on ice.
-
Centrifuge to pellet the precipitated protein and collect the supernatant.
-
-
Separation of Radiolabeled Water:
-
Neutralize the supernatant with NaOH.
-
Apply the neutralized supernatant to a prepared ion-exchange column that binds the charged palmitate but allows the neutral tritiated water to pass through.
-
Elute the tritiated water from the column.
-
-
Quantification:
-
Add the eluate to scintillation fluid.
-
Measure the radioactivity using a scintillation counter.
-
Normalize the counts to the total protein content of the cells and the incubation time to determine the rate of fatty acid oxidation (e.g., in nmol/mg protein/hour).
-
Figure 4: Experimental workflow for measuring fatty acid oxidation.
Isolation of Mitochondria from Tissue
This protocol describes the isolation of mitochondria from soft tissues like the liver using differential centrifugation.
Materials:
-
Fresh tissue (e.g., rat liver)
-
Mitochondrial Isolation Buffer (MIB) (e.g., containing sucrose, Tris-HCl, and EGTA)
-
Dounce homogenizer
-
Refrigerated centrifuge
Procedure:
-
Tissue Preparation:
-
Excise the tissue and place it immediately in ice-cold MIB.
-
Mince the tissue into small pieces.
-
-
Homogenization:
-
Transfer the minced tissue to a Dounce homogenizer with fresh, ice-cold MIB.
-
Homogenize with several strokes of a loose-fitting pestle, followed by several strokes of a tight-fitting pestle.
-
-
Differential Centrifugation:
-
Transfer the homogenate to a centrifuge tube and centrifuge at a low speed (e.g., 600-800 x g) for 10 minutes at 4°C to pellet nuclei and unbroken cells.
-
Carefully collect the supernatant and transfer it to a new tube.
-
Centrifuge the supernatant at a higher speed (e.g., 8,000-10,000 x g) for 15 minutes at 4°C to pellet the mitochondria.
-
-
Washing the Mitochondrial Pellet:
-
Discard the supernatant.
-
Gently resuspend the mitochondrial pellet in fresh, ice-cold MIB.
-
Repeat the high-speed centrifugation step.
-
-
Final Mitochondrial Pellet:
-
Discard the supernatant. The resulting pellet is the enriched mitochondrial fraction.
-
Resuspend the pellet in a suitable buffer for downstream applications.
-
Conclusion and Future Directions
The intricate relationship between this compound metabolism and fatty acid oxidation, mediated by carnitine biosynthesis, underscores the importance of this essential amino acid in overall energy homeostasis. Understanding the enzymatic and regulatory nuances of these pathways is paramount for the development of novel therapeutic strategies for a range of metabolic diseases, including those characterized by impaired fatty acid oxidation and lipid accumulation. Further research focusing on the tissue-specific regulation of carnitine synthesis and the impact of genetic variations in the associated enzymes will provide deeper insights and open new avenues for targeted drug development. The methodologies outlined in this guide provide a robust framework for researchers to further explore these critical metabolic interconnections.
References
- 1. goldenberg.biology.utah.edu [goldenberg.biology.utah.edu]
- 2. Protein this compound acetylation does not contribute to the high rates of fatty acid oxidation seen in the post-ischemic heart - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. benchchem.com [benchchem.com]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. genecards.org [genecards.org]
- 7. researchgate.net [researchgate.net]
Neurological Disorders Associated with Lysine Metabolism Defects: A Technical Guide for Researchers and Drug Development Professionals
Abstract
Defects in the catabolism of the essential amino acid lysine are responsible for a group of inherited neurometabolic disorders, primarily Glutaric Aciduria Type 1 (GA-1) and Pyridoxine-Dependent Epilepsy (PDE). These conditions, if not diagnosed and managed early, can lead to severe and irreversible neurological damage. This technical guide provides an in-depth overview of the biochemical basis of these disorders, key diagnostic biomarkers, and detailed experimental protocols for their analysis. It is intended to serve as a comprehensive resource for researchers, scientists, and professionals involved in the development of novel therapeutics for these devastating diseases.
Introduction
This compound is an essential amino acid, meaning it cannot be synthesized by the human body and must be obtained through diet. Its degradation is a complex process involving two primary pathways: the saccharopine pathway, which is predominant in peripheral tissues, and the pipecolic acid pathway, which is more active in the brain.[1] Enzymatic deficiencies in these pathways lead to the accumulation of neurotoxic metabolites, causing a spectrum of neurological symptoms. This guide will focus on the two most significant of these disorders: Glutaric Aciduria Type 1 and Pyridoxine-Dependent Epilepsy.
Glutaric Aciduria Type 1 (GA-1)
Glutaric Aciduria Type 1 is an autosomal recessive disorder caused by a deficiency of the mitochondrial enzyme glutaryl-CoA dehydrogenase (GCDH).[2][3] This enzyme is crucial for the breakdown of this compound, hydroxythis compound, and tryptophan.[4] Its deficiency leads to the accumulation of glutaric acid (GA), 3-hydroxyglutaric acid (3-OHGA), and glutarylcarnitine (C5DC) in various bodily fluids.[5]
Pathophysiology
The accumulation of GA and 3-OHGA is particularly toxic to the developing brain, with the basal ganglia being especially vulnerable.[4] Affected individuals may appear normal at birth but are at high risk of acute encephalopathic crises, often triggered by catabolic states such as infections or vaccinations.[2] These crises can cause striatal injury, leading to a complex movement disorder characterized by dystonia and dyskinesia.[5] Macrocephaly is a common early clinical sign.[6]
Quantitative Biomarkers for GA-1
Early diagnosis through newborn screening and subsequent monitoring are critical for managing GA-1 and preventing severe neurological damage. The primary biomarkers and their typical concentrations are summarized in the table below.
| Biomarker | Matrix | Patient Population | Typical Concentration Range | Reference |
| Glutarylcarnitine (C5DC) | Dried Blood Spot | Newborn Screening | > 0.5 µmol/L (initial screen) | [7] |
| Confirmed GA-1 | Often significantly elevated, but can be low in "low excretor" phenotypes | [8][9] | ||
| Glutaric Acid (GA) | Urine | High Excretor GA-1 | 850 - 1700 mmol/mol creatinine | [10] |
| Low Excretor GA-1 | Can be within the normal range (< 4 mmol/mol creatinine) | [10] | ||
| 3-Hydroxyglutaric Acid (3-OHGA) | Urine | GA-1 (High and Low Excretors) | Elevated, a more reliable marker than GA in low excretors | [10] |
| Plasma & CSF | GA-1 | ~100-fold increase compared to healthy controls | [11] |
Experimental Protocols
This protocol outlines the key steps for the quantitative analysis of glutaric acid in urine.
-
Sample Preparation:
-
Collection: Collect a random urine sample in a sterile, preservative-free container. Store frozen at -20°C or -70°C for long-term stability.[12]
-
Internal Standard: Add a known amount of a deuterated internal standard (e.g., D4-Glutaric Acid) to a defined volume of urine.[12]
-
Acidification: Acidify the urine sample to a pH below 2 with hydrochloric acid.[12]
-
Extraction: Perform a liquid-liquid extraction using an organic solvent such as ethyl acetate.[12]
-
Drying: Dry the organic extract using anhydrous sodium sulfate.[12]
-
Evaporation: Evaporate the solvent to dryness under a stream of nitrogen.[12]
-
Derivatization: To increase volatility for GC analysis, derivatize the dried residue to form trimethylsilyl (TMS) esters using a reagent like N,O-Bis(trimethylsilyl)trifluoroacetamide (BSTFA) with 1% Trimethylchlorosilane (TMCS).[12]
-
-
GC-MS Analysis:
-
Injection: Inject the derivatized sample into the GC-MS system.
-
Chromatographic Separation: Use a suitable capillary column (e.g., DB-5MS) and a temperature gradient to separate the analytes. A typical program might start at 80°C and ramp up to 300°C.[12]
-
Mass Spectrometry Detection: Use electron ionization (EI) at 70 eV. For quantification, operate in Selected Ion Monitoring (SIM) mode for higher sensitivity. Key ions for the TMS derivative of glutaric acid include m/z 261 (quantifier) and m/z 147 and 246 (qualifiers).[12]
-
Quantification: Calculate the concentration of glutaric acid by comparing the peak area ratio of the analyte to the internal standard against a calibration curve.
-
This protocol is central to newborn screening for GA-1.
-
Sample Preparation:
-
Punching: Punch a small disc (e.g., 1/8 inch) from the dried blood spot into a well of a microplate.[13]
-
Extraction: Add an extraction solution containing stable isotope-labeled internal standards in a solvent mixture (e.g., 85:15 acetonitrile:water).[4][13]
-
Incubation and Centrifugation: Agitate the plate to facilitate extraction, followed by centrifugation to pellet the blood spot disc and any precipitates.[4]
-
Supernatant Transfer: Transfer the supernatant to a new plate or filter vial for analysis.[4]
-
-
Flow Injection Analysis (FIA)-MS/MS:
-
Injection: The sample extract is injected directly into the mass spectrometer without chromatographic separation.[13]
-
Ionization: Use electrospray ionization (ESI) in positive mode.[14]
-
MS/MS Detection: Employ precursor ion scanning or multiple reaction monitoring (MRM) to detect specific acylcarnitines. For glutarylcarnitine (C5DC), the transition m/z 388 → m/z 85 is often monitored.[15]
-
Quantification: Quantify C5DC by comparing its response to the corresponding internal standard.
-
Pyridoxine-Dependent Epilepsy (PDE)
Pyridoxine-Dependent Epilepsy is an autosomal recessive disorder most commonly caused by mutations in the ALDH7A1 gene, which encodes the enzyme α-aminoadipic semialdehyde (α-AASA) dehydrogenase (also known as antiquitin).[9][16] This enzyme deficiency disrupts the this compound degradation pathway, leading to the accumulation of α-AASA and its cyclic form, Δ1-piperideine-6-carboxylate (P6C).[14]
Pathophysiology
The accumulation of P6C is central to the pathophysiology of PDE. P6C inactivates pyridoxal 5'-phosphate (PLP), the active form of vitamin B6 (pyridoxine), through a chemical reaction.[14] PLP is a critical cofactor for numerous enzymes in the brain, including those involved in neurotransmitter synthesis. The resulting PLP deficiency is thought to cause the characteristic seizures that are resistant to conventional antiepileptic drugs but respond to high doses of pyridoxine.[9] Despite seizure control, many patients experience developmental delay and intellectual disability.[17]
Quantitative Biomarkers for PDE
The diagnosis of PDE relies on the identification of specific biomarkers in urine, plasma, or cerebrospinal fluid (CSF).
| Biomarker | Matrix | Patient Population | Typical Concentration Range | Reference |
| α-Aminoadipic Semialdehyde (α-AASA) / Δ1-Piperideine-6-Carboxylate (P6C) | Urine, Plasma | Untreated PDE | Significantly elevated | [18][19] |
| Pipecolic Acid | Plasma | Untreated PDE | 4.3 to 15.3-fold elevation compared to upper normal range | [20] |
| CSF | Untreated PDE | Markedly elevated, often 2.2 to 4.8 times higher than in plasma | [20] | |
| 2-Oxopropylpiperidine-2-carboxylic acid (2-OPP) | Brain Tissue | Deceased PDE Patient | ~5 nmol/gram cortical tissue | [1] |
| 6-Oxopiperidine-2-carboxylic acid (6-oxoPIP) | Brain Tissue | Deceased PDE Patient | ~29 nmol/gram cortical tissue | [1] |
Experimental Protocols
The analysis of pipecolic acid is a key diagnostic test for PDE.
-
Sample Preparation:
-
Collection: Collect plasma or CSF according to standard clinical procedures.
-
Deproteinization: Precipitate proteins using a solvent like methanol or acetonitrile.
-
Centrifugation: Centrifuge the sample to obtain a clear supernatant.
-
Derivatization (if using GC-MS): Similar to organic acid analysis, derivatization may be required to improve volatility.
-
-
LC-MS/MS Analysis (Preferred Method):
-
Chromatographic Separation: Use a suitable column (e.g., HILIC) to separate pipecolic acid from other metabolites.
-
MS/MS Detection: Employ ESI in positive mode and MRM for sensitive and specific detection.
-
Quantification: Use a stable isotope-labeled internal standard for accurate quantification.
-
Confirmation of PDE diagnosis is achieved through molecular genetic testing.
-
DNA Extraction: Extract genomic DNA from a patient's blood sample.
-
PCR Amplification: Amplify all exons and flanking intronic regions of the ALDH7A1 gene using polymerase chain reaction (PCR).
-
Sanger Sequencing: Sequence the PCR products to identify pathogenic variants.
-
Deletion/Duplication Analysis: If sequencing is uninformative, perform methods like multiplex ligation-dependent probe amplification (MLPA) to detect larger deletions or duplications within the gene.[18]
This compound Degradation Pathways and Associated Defects
The following diagrams illustrate the major this compound degradation pathways and the enzymatic blocks leading to GA-1 and PDE.
Caption: The Saccharopine Pathway of this compound Degradation.
Caption: Diagnostic Workflow for Glutaric Aciduria Type 1.
Conclusion and Future Directions
The understanding of neurological disorders linked to this compound metabolism has advanced significantly, enabling earlier diagnosis and the implementation of life-altering treatments. For GA-1, newborn screening programs have dramatically improved outcomes by allowing for the early initiation of a this compound-restricted diet and carnitine supplementation. In PDE, the identification of biomarkers and the underlying genetic defect has led to more rapid diagnosis and treatment with pyridoxine.
However, significant challenges remain. Despite treatment, a substantial number of patients with PDE still experience long-term neurodevelopmental deficits, suggesting that pyridoxine supplementation alone may not be sufficient to prevent all neurotoxicity. Further research is needed to elucidate the precise mechanisms of brain injury and to develop adjunct therapies. The development of novel biomarkers that can be easily incorporated into newborn screening programs for PDE is also a critical area of investigation. For both disorders, a deeper understanding of the pathophysiology will be essential for the development of next-generation therapeutics, including gene therapy and small molecule approaches, with the ultimate goal of preventing neurological damage and improving the quality of life for affected individuals.
References
- 1. medrxiv.org [medrxiv.org]
- 2. researchgate.net [researchgate.net]
- 3. Pipecolic acid concentrations in brain tissue of nutritionally pyridoxine-deficient rats - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Improved Screening Method for Acylcarnitines and Amino Acids in Dried Blood Spots by LC-MS/MS [restek.com]
- 5. register.awmf.org [register.awmf.org]
- 6. Glutaric aciduria type 1 - Wikipedia [en.wikipedia.org]
- 7. UPLC-MS/MS analysis of C5-acylcarnitines in dried blood spots - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Glutaric Aciduria Type I Missed by Newborn Screening: Report of Four Cases from Three Families - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 10. Formation of 3‐hydroxyglutaric acid in glutaric aciduria type I: in vitro participation of medium chain acyl‐CoA dehydrogenase - PMC [pmc.ncbi.nlm.nih.gov]
- 11. 3-hydroxyglutaric acid - biocrates [biocrates.com]
- 12. benchchem.com [benchchem.com]
- 13. Analysis of Acylcarnitines in Dried Blood Spots (DBS) Samples by FIA-MS/MS [sigmaaldrich.com]
- 14. Acylcarnitine analysis by tandem mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. mdpi.com [mdpi.com]
- 16. documents.thermofisher.com [documents.thermofisher.com]
- 17. The genotypic spectrum of ALDH7A1 mutations resulting in pyridoxine dependent epilepsy: A common epileptic encephalopathy - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Pyridoxine-Dependent Epilepsy – ALDH7A1 - GeneReviews® - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 19. discovery.ucl.ac.uk [discovery.ucl.ac.uk]
- 20. Pipecolic acid as a diagnostic marker of pyridoxine-dependent epilepsy - PubMed [pubmed.ncbi.nlm.nih.gov]
The Fork in the Road: A Technical Guide to Lysine Catabolism via the Saccharopine and Pipecolate Pathways
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
Introduction
Lysine, an essential amino acid, is fundamental for protein synthesis and various physiological functions. Its catabolism is critical for maintaining homeostasis, and in mammals, this process primarily proceeds through two distinct routes: the saccharopine pathway and the pipecolate pathway. While both pathways converge to produce α-aminoadipate, their tissue-specific prevalence, enzymatic machinery, and implications in human health and disease are markedly different. This technical guide provides a comprehensive overview of these two pathways, offering a comparative analysis of their core mechanisms, quantitative data, experimental methodologies, and relevance to drug development. Understanding the nuances of these pathways is paramount for researchers and clinicians investigating metabolic disorders and developing targeted therapeutic interventions.
The Saccharopine Pathway: The Principal Route of this compound Degradation
The saccharopine pathway (SACPATH) is the predominant route for this compound catabolism in most mammalian tissues, particularly the liver and kidneys.[1][2] This mitochondrial pathway is responsible for the bulk of systemic this compound degradation.[2]
Enzymatic Steps of the Saccharopine Pathway
The SACPATH involves a series of enzymatic reactions that convert L-lysine into α-aminoadipate. The initial and rate-limiting steps are catalyzed by a bifunctional enzyme, α-aminoadipate semialdehyde synthase (AASS), which possesses two distinct enzymatic activities: this compound-ketoglutarate reductase (LKR) and saccharopine dehydrogenase (SDH).[3][4]
-
This compound-Ketoglutarate Reductase (LKR) (EC 1.5.1.8): In the first step, the LKR domain of AASS catalyzes the condensation of L-lysine with α-ketoglutarate to form saccharopine, utilizing NADPH as a cofactor.[3][4]
-
Saccharopine Dehydrogenase (SDH) (EC 1.5.1.9): The SDH domain of AASS then hydrolyzes saccharopine to yield L-glutamate and α-aminoadipate-δ-semialdehyde (AASA).[3][4]
-
α-Aminoadipate Semialdehyde Dehydrogenase (AASADH) (EC 1.2.1.31): AASA is subsequently oxidized to α-aminoadipate (AAA) by the enzyme α-aminoadipate semialdehyde dehydrogenase (also known as antiquitin), using NAD(P)+ as a cofactor.[5] AASA exists in spontaneous equilibrium with its cyclic form, Δ¹-piperideine-6-carboxylate (P6C).[2]
Figure 1: The Saccharopine Pathway for this compound Catabolism.
The Pipecolate Pathway: A Specialized Route in the Brain
The pipecolate pathway is the predominant route for this compound catabolism in the adult mammalian brain.[1][2] This pathway is primarily cytosolic and peroxisomal, distinguishing it from the mitochondrial localization of the saccharopine pathway.[2]
Enzymatic Steps of the Pipecolate Pathway
The pipecolate pathway initiates with the removal of the α-amino group of this compound, a key difference from the saccharopine pathway which targets the ε-amino group.
-
This compound Transamination/Oxidation: The first step is the conversion of L-lysine to α-keto-ε-aminocaproate. The specific enzyme responsible for this reaction in mammals is not definitively identified, but it is thought to be a transaminase or an oxidase.[2] α-keto-ε-aminocaproate spontaneously cyclizes to form Δ¹-piperideine-2-carboxylate (P2C).
-
Δ¹-Piperideine-2-Carboxylate Reductase: P2C is then reduced to L-pipecolate by a ketimine reductase, which has been identified as μ-crystallin (CRYM).[1]
-
Pipecolate Oxidase (PIPOX): L-pipecolate is subsequently oxidized in peroxisomes by pipecolate oxidase to form Δ¹-piperideine-6-carboxylate (P6C).[2]
-
Convergence with the Saccharopine Pathway: P6C is the point of convergence for both pathways. It is in equilibrium with α-aminoadipate-δ-semialdehyde (AASA) and is further metabolized to α-aminoadipate by AASADH, as described in the saccharopine pathway.[1][2]
Figure 2: The Pipecolate Pathway for this compound Catabolism.
Quantitative Data Summary
The following tables summarize available quantitative data for key enzymes and metabolites in the saccharopine and pipecolate pathways. It is important to note that kinetic parameters can vary significantly based on the species, tissue, and experimental conditions.
Table 1: Kinetic Parameters of Key Enzymes in this compound Catabolism
| Enzyme | Pathway | Substrate | Km (mM) | Vmax | Organism/Tissue |
| This compound-Ketoglutarate Reductase (LKR) | Saccharopine | L-Lysine | 1.5[6] | Not reported | Human Liver |
| α-Ketoglutarate | 1.0[6] | Not reported | Human Liver | ||
| NADPH | 0.08[6] | Not reported | Human Liver | ||
| L-Lysine | 11-24[7] | 28.8 ± 1.0 (µmol min⁻¹ mg⁻¹)[8] | Human (recombinant) | ||
| Saccharopine Dehydrogenase (SDH) | Saccharopine | Saccharopine | Not reported | Not reported | |
| α-Aminoadipate Semialdehyde Dehydrogenase (AASADH) | Both | α-Aminoadipate-δ-semialdehyde | Not reported | Not reported | |
| Pipecolate Oxidase (PIPOX) | Pipecolate | L-Pipecolate | Not reported | Not reported |
Table 2: Representative Concentrations of this compound and its Catabolites
| Metabolite | Pathway | Tissue | Concentration | Organism |
| L-Lysine | Both | Human Plasma | 100-300 µM[9] | Human |
| Rat Brain | ~0.1-0.2 µmol/g | Rat | ||
| L-Pipecolic Acid | Pipecolate | Human Brain | Variable, higher in specific regions[10] | Human |
| Rat Brain | ~10-30 nmol/g[11] | Rat | ||
| α-Aminoadipate | Both | Human Plasma | ~0.5-2.0 µM | Human |
| Saccharopine | Saccharopine | Human Urine | Normally very low or undetectable[12] | Human |
Experimental Protocols
Detailed methodologies are crucial for the accurate study of this compound catabolism. Below are representative protocols for key experimental procedures.
Protocol 1: Spectrophotometric Assay for this compound-Ketoglutarate Reductase (LKR) Activity
This assay measures the rate of NADPH oxidation, which is coupled to the formation of saccharopine from this compound and α-ketoglutarate.
Materials:
-
HEPES buffer (100 mM, pH 7.8)
-
L-Lysine solution (e.g., 100 mM)
-
α-Ketoglutarate solution (e.g., 75 mM)
-
NADPH solution (e.g., 1.25 mM)
-
Mitochondrial protein extract (solubilized with 0.2% Nonidet P-40)[3]
-
Spectrophotometer capable of reading absorbance at 340 nm
Procedure:
-
Prepare a reaction mixture in a cuvette containing:
-
Incubate the mixture at a constant temperature (e.g., 37°C) for 5 minutes to allow for temperature equilibration.
-
Initiate the reaction by adding 0.125 mM NADPH.[3]
-
Immediately monitor the decrease in absorbance at 340 nm over time (e.g., for 5-10 minutes) in kinetic mode. The rate of decrease in absorbance is proportional to the LKR activity.
-
Calculate the enzyme activity using the molar extinction coefficient of NADPH at 340 nm (6.22 mM⁻¹ cm⁻¹).
Figure 3: Workflow for LKR Activity Assay.
Protocol 2: Quantification of Pipecolic Acid in Brain Tissue by HPLC
This method allows for the sensitive detection and quantification of pipecolic acid in brain tissue samples.
Materials:
-
Brain tissue sample
-
Internal standard (e.g., nipecotic acid)[13]
-
Homogenization buffer
-
Dansyl chloride for derivatization[13]
-
Acetonitrile
-
Reverse-phase HPLC system with a fluorescence detector[13]
Procedure:
-
Sample Preparation:
-
Homogenize a known weight of brain tissue in a suitable buffer.
-
Add a known amount of the internal standard (nipecotic acid).
-
Deproteinize the homogenate (e.g., with perchloric acid) and centrifuge to collect the supernatant.
-
-
Derivatization:
-
Adjust the pH of the supernatant to be alkaline.
-
Add dansyl chloride solution and incubate to allow for the derivatization of pipecolic acid and the internal standard.
-
-
HPLC Analysis:
-
Inject the derivatized sample onto a reverse-phase HPLC column.
-
Elute the compounds using a suitable mobile phase gradient (e.g., acetonitrile/water).
-
Detect the fluorescent dansyl derivatives using a fluorescence detector.
-
-
Quantification:
-
Identify the peaks corresponding to dansyl-pipecolic acid and the dansyl-internal standard based on their retention times.
-
Quantify the amount of pipecolic acid by comparing its peak area to that of the internal standard.
-
Figure 4: Workflow for Pipecolic Acid Quantification.
Implications for Drug Development
Defects in this compound catabolism are associated with several inherited metabolic disorders, making the enzymes of these pathways attractive targets for therapeutic intervention.
-
Pyridoxine-Dependent Epilepsy (PDE): This disorder is caused by mutations in the ALDH7A1 gene, which encodes AASADH.[2] The resulting deficiency leads to the accumulation of AASA and P6C. P6C inactivates pyridoxal 5'-phosphate (PLP), an active form of vitamin B6 and an essential cofactor for many enzymes, leading to seizures.[2] Therapeutic strategies for PDE include:
-
Pyridoxine (Vitamin B6) Supplementation: To overcome the PLP deficiency.[14]
-
This compound-Restricted Diet: To reduce the substrate load on the deficient pathway.[15]
-
Inhibition of this compound-Ketoglutarate Reductase (LKR/AASS): This is a promising substrate reduction therapy approach to prevent the formation of the toxic upstream metabolites, AASA and P6C.[1][16] Small molecule inhibitors targeting the LKR domain of AASS are under investigation.[16]
-
-
Glutaric Aciduria Type I (GA-I): This disorder results from a deficiency in glutaryl-CoA dehydrogenase, an enzyme downstream of α-aminoadipate in the this compound degradation pathway. This leads to the accumulation of neurotoxic glutaric acid and 3-hydroxyglutaric acid.[4] Therapeutic strategies being explored include:
-
Low-Lysine Diet and Carnitine Supplementation: The current standard of care to reduce the production of toxic metabolites.[17]
-
Inhibition of LKR (AASS): Similar to PDE, blocking the initial step of this compound catabolism is a potential therapeutic strategy to reduce the flux through the pathway and decrease the production of glutaric acid.[18]
-
Gene Therapy: Liver-directed gene therapy to replace the defective GCDH gene or to delete the AASS gene using CRISPR has shown promise in mouse models.[11][18]
-
Figure 5: Drug Development Targets in this compound Catabolism.
Conclusion
The saccharopine and pipecolate pathways represent two elegant and distinct solutions for the catabolism of this compound in mammals. While the saccharopine pathway serves as the primary workhorse for systemic this compound degradation, the pipecolate pathway plays a specialized role in the brain. The clinical significance of these pathways is underscored by the severe neurological consequences of their disruption. For researchers and drug development professionals, a deep understanding of the enzymes, intermediates, and regulatory mechanisms of these pathways is essential. Future research focused on elucidating the precise kinetics and regulation of these pathways, coupled with the development of targeted inhibitors and gene-based therapies, holds great promise for the effective treatment of associated metabolic disorders.
References
- 1. Mechanism of age-dependent susceptibility and novel treatment strategy in glutaric acidemia type I - PMC [pmc.ncbi.nlm.nih.gov]
- 2. journals.physiology.org [journals.physiology.org]
- 3. researchgate.net [researchgate.net]
- 4. Alpha-aminoadipic acid - biocrates [biocrates.com]
- 5. A novel mouse model for pyridoxine-dependent epilepsy due to antiquitin deficiency - PMC [pmc.ncbi.nlm.nih.gov]
- 6. This compound-ketoglutarate reductase in human tissues - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Bridging the gap: pyridoxine-dependent epilepsy (PDE-ALDH7A1) diagnosis and management in a low-resource setting - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Characterization and structure of the human this compound-2-oxoglutarate reductase domain, a novel therapeutic target for treatment of glutaric aciduria type 1 - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Targeting this compound α-Ketoglutarate Reductase to Treat Pyridoxine-Dependent Epilepsy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. This compound metabolism in the human and the monkey: demonstration of pipecolic acid formation in the brain and other organs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. Saccharopine - Wikipedia [en.wikipedia.org]
- 13. Novel Treatment Options for Glutaric Aciduria - Sander Houten [grantome.com]
- 14. hssiem.org [hssiem.org]
- 15. sigmaaldrich.com [sigmaaldrich.com]
- 16. This compound α-ketoglutarate reductase as a therapeutic target for saccharopine pathway related diseases - PMC [pmc.ncbi.nlm.nih.gov]
- 17. This compound α-ketoglutarate reductase, but not saccharopine dehydrogenase, is subject to substrate inhibition in pig liver - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. Rescue of glutaric aciduria type I in mice by liver-directed therapies - PMC [pmc.ncbi.nlm.nih.gov]
The Role of Lysine in Calcium Homeostasis: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
Introduction
The essential amino acid L-lysine has been identified as a significant modulator of calcium homeostasis. Emerging research indicates that lysine can positively influence calcium balance through synergistic effects on intestinal absorption and renal conservation.[1][2] This technical guide provides an in-depth analysis of the current understanding of this compound's role in calcium metabolism, detailing the underlying mechanisms, summarizing key quantitative data from human studies, and providing methodologies for relevant experimental protocols. This document is intended to serve as a comprehensive resource for researchers and professionals in drug development exploring therapeutic interventions for disorders related to calcium imbalance, such as osteoporosis.
This compound's Impact on Intestinal Calcium Absorption
L-lysine has been demonstrated to enhance the intestinal absorption of calcium.[3] This effect is crucial for maintaining a positive calcium balance, a key factor in bone health.[4] The precise mechanisms are still under investigation, but evidence points towards a potential interaction with calcium transport pathways in the enterocytes.
Quantitative Data from Human Studies
Two key studies provide quantitative insights into the effects of this compound on calcium absorption in humans. The findings of Civitelli et al. (1992) and Bihuniak et al. (2014) are summarized below.
| Study | Participant Group | Intervention | Fractional Calcium Absorption (%) | p-value |
| Civitelli et al. (1992) [3] | 45 osteoporotic patients | L-lysine (800 mg/day) | Statistically significant increase | < 0.05 |
| L-valine (800 mg/day) | No significant change | NS | ||
| L-tryptophan (800 mg/day) | No significant change | NS | ||
| Bihuniak et al. (2014) [5] | 14 healthy young women | Low-protein diet + placebo | 22.3 ± 1.4 | |
| Low-protein diet + Dibasic Amino Acids (this compound + Arginine) | 25.2 ± 1.4 | < 0.10 | ||
| Low-protein diet + CaSR-Activating Amino Acids | 22.9 ± 2.0 | NS (vs. placebo) |
Table 1: Summary of Quantitative Data on this compound and Intestinal Calcium Absorption.
Proposed Signaling Pathway for this compound-Mediated Intestinal Calcium Absorption
While the exact mechanism of this compound's effect on intestinal calcium absorption is not fully elucidated, one hypothesis involves the modulation of calcium transport channels. The following diagram illustrates a potential, albeit speculative, pathway. It is important to note that this compound is considered a weak agonist of the Calcium-Sensing Receptor (CaSR).[5]
Caption: Potential pathway for this compound's influence on intestinal calcium absorption.
This compound's Role in Renal Calcium Conservation
In addition to enhancing intestinal absorption, L-lysine appears to promote the renal conservation of calcium by reducing its excretion in urine.[1][3] This effect contributes significantly to a positive overall calcium balance.
Quantitative Data from Human Studies
The study by Civitelli et al. (1992) also investigated the effect of this compound on urinary calcium excretion following a calcium load.
| Participant Group | Intervention | Mean Change in Urinary Calcium Excretion (mg/3h) | Interpretation |
| Healthy Women | Oral Ca load (3g) | Increase | Normal calciuric response |
| Oral Ca load (3g) + L-lysine (400mg) | Blunted increase | This compound suppressed calciuric response | |
| Osteoporotic Women | Oral Ca load (3g) | Increase | Normal calciuric response |
| Oral Ca load (3g) + L-lysine (400mg) | Increase (not clearly manifested suppression) | Effect of this compound less pronounced |
Table 2: Effect of L-lysine on Urinary Calcium Excretion Following an Oral Calcium Load (Data from Civitelli et al., 1992).[3]
Proposed Signaling Pathway for this compound-Mediated Renal Calcium Reabsorption
The Calcium-Sensing Receptor (CaSR) is expressed in the thick ascending limb of the loop of Henle and the distal convoluted tubule, where it plays a role in regulating calcium reabsorption. While this compound is a weak CaSR agonist, its potential influence on this pathway warrants consideration.
Caption: Hypothesized influence of this compound on renal calcium reabsorption via the CaSR.
Experimental Protocols
Measurement of Fractional Calcium Absorption using a Dual-Isotope Method
This protocol is based on the principles of the dual-isotope method for measuring true fractional calcium absorption.[2][6]
-
Stable calcium isotopes (e.g., 42Ca and 44Ca).
-
Test meal with a known calcium content.
-
Intravenous infusion equipment.
-
Urine and/or blood collection supplies.
-
Inductively Coupled Plasma Mass Spectrometer (ICP-MS).
-
Subject Preparation: Participants undergo a dietary stabilization period with a controlled calcium intake for several days prior to the study.
-
Isotope Administration:
-
An oral dose of a stable calcium isotope (e.g., 44Ca) is administered with a standardized test meal.
-
Simultaneously or shortly after, an intravenous dose of a different stable calcium isotope (e.g., 42Ca) is administered.
-
-
Sample Collection:
-
Urine is collected for 24 hours following isotope administration.
-
Alternatively, a single blood sample can be drawn at a specific time point (e.g., 4 hours post-oral dose).[6]
-
-
Sample Analysis: The isotopic enrichment of both calcium isotopes in the urine or serum is determined using ICP-MS.
-
Calculation of Fractional Absorption: The fractional calcium absorption is calculated from the ratio of the orally administered isotope to the intravenously administered isotope recovered in the urine or present in the serum.
Caption: Workflow for dual-isotope measurement of fractional calcium absorption.
Assessment of Renal Calcium Handling
This protocol outlines a method to assess the renal handling of calcium, which can be adapted to study the effects of interventions like this compound supplementation.
-
Metabolic diet with controlled calcium and sodium content.
-
24-hour urine collection containers.
-
Blood collection supplies.
-
Clinical chemistry analyzer for calcium and creatinine.
-
Dietary Control: Participants are placed on a metabolic diet with a fixed intake of calcium and sodium for a defined period.
-
Sample Collection:
-
A 24-hour urine sample is collected.
-
A blood sample is drawn to measure serum calcium and creatinine.
-
-
Biochemical Analysis:
-
Urinary volume, urinary calcium, and urinary creatinine are measured.
-
Serum calcium and serum creatinine are measured.
-
-
Calculations:
-
24-hour Urinary Calcium Excretion: Total calcium excreted in the 24-hour urine sample.
-
Fractional Excretion of Calcium (FECa): (Urine Calcium x Serum Creatinine) / (Serum Calcium x Urine Creatinine). This represents the fraction of filtered calcium that is excreted.
-
Tubular Reabsorption of Calcium (TRCa): 1 - FECa. This indicates the percentage of filtered calcium that is reabsorbed by the renal tubules.
-
Conclusion and Future Directions
The available evidence strongly suggests that L-lysine plays a beneficial role in calcium homeostasis by enhancing intestinal absorption and promoting renal conservation.[1][2][3] These effects position this compound as a nutrient of interest for the prevention and management of osteoporosis and other conditions related to calcium deficiency. The quantitative data from human studies, while promising, are derived from relatively small cohorts. Larger and longer-term clinical trials are necessary to definitively establish the efficacy and optimal dosage of this compound supplementation for improving bone health.
Future research should focus on elucidating the precise molecular mechanisms by which this compound exerts its effects on calcium transport in the intestine and kidneys. A deeper understanding of the interaction, if any, between this compound and the Calcium-Sensing Receptor in these tissues is a key area for investigation. Further studies employing the detailed experimental protocols outlined in this guide will be instrumental in advancing our knowledge in this field and translating these findings into effective clinical applications.
References
- 1. Dietary L-lysine and calcium metabolism in humans - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. academic.oup.com [academic.oup.com]
- 3. researchgate.net [researchgate.net]
- 4. Dietary L-lysine and calcium metabolism in humans. | Semantic Scholar [semanticscholar.org]
- 5. Supplementing a Low-Protein Diet with Dibasic Amino Acids Increases Urinary Calcium Excretion in Young Women - PMC [pmc.ncbi.nlm.nih.gov]
- 6. A Simple Single Serum Method to Measure Fractional Calcium Absorption using Dual Stable Isotopes - PMC [pmc.ncbi.nlm.nih.gov]
Methodological & Application
Application Notes and Protocols for the Quantitative Analysis of Lysine in Protein Hydrolysates
Audience: Researchers, scientists, and drug development professionals.
Introduction: Lysine, an essential amino acid, is a critical component in many biological processes and a key indicator of protein quality in food, feed, and pharmaceutical products.[1][2][3] Its quantification in protein hydrolysates is crucial for nutritional assessment, process optimization in biotechnology, and for understanding its role in health and disease.[1] This document provides detailed application notes and protocols for the quantitative analysis of this compound using three common analytical techniques: High-Performance Liquid Chromatography (HPLC), Mass Spectrometry (MS), and the Ninhydrin Colorimetric Method.
High-Performance Liquid Chromatography (HPLC) for this compound Quantification
HPLC is a widely used technique for the separation and quantification of amino acids due to its high resolution, sensitivity, and reproducibility. The method typically involves pre-column derivatization of the amino acids to enhance their detection by UV-Vis or fluorescence detectors.
Principle
Amino acids in a protein hydrolysate are first derivatized with a labeling agent to make them detectable. The derivatized amino acids are then separated on a reversed-phase HPLC column and quantified based on the peak area relative to a known standard. Common derivatizing agents include o-phthaldialdehyde (OPA), 9-fluorenylmethyl chloroformate (FMOC), and dansyl chloride.[4][5]
Experimental Protocol: OPA/FMOC Derivatization
This protocol combines OPA for primary amino acids (like this compound) and FMOC for secondary amino acids, allowing for a comprehensive amino acid profile.[5]
1.2.1. Protein Hydrolysis:
-
Weigh approximately 2.5 mg of the protein sample into a hydrolysis tube.
-
Add 1 mL of 6M HCl.
-
Flush the tube with nitrogen gas, seal it, and incubate at 110°C for 24 hours.[6]
-
After cooling, open the tube and evaporate the HCl under a stream of nitrogen.
-
Reconstitute the dried hydrolysate in 1 mL of 0.1 N HCl.[7]
1.2.2. Automated Pre-column Derivatization (using an autosampler):
-
Reagents:
-
Borate Buffer: 0.4 M, pH 10.2.
-
OPA Reagent: Dissolve 10 mg of o-phthaldialdehyde in 1 mL of methanol, then add 9 mL of 0.4 M borate buffer and 100 µL of 3-mercaptopropionic acid.
-
FMOC Reagent: Dissolve 2.5 mg of 9-fluorenylmethyl chloroformate in 1 mL of acetonitrile.
-
Injection Diluent: 100 mL of mobile phase A and 0.4 mL of concentrated phosphoric acid.[7]
-
-
Autosampler Program:
-
Mix the sample with the OPA reagent and incubate for 1 minute to derivatize primary amino acids.
-
Add the FMOC reagent and incubate for 2 minutes to derivatize secondary amino acids.
-
Inject the derivatized sample onto the HPLC column.[5]
-
1.2.3. HPLC Conditions:
-
Column: Zorbax Eclipse-AAA C18 column (4.6 x 150 mm, 3.5 µm).[8]
-
Mobile Phase A: 40 mM Phosphate buffer, pH 7.8.[8]
-
Mobile Phase B: Acetonitrile/Methanol/Water (45/45/10, v/v/v).[8]
-
Flow Rate: 2.0 mL/min.[8]
-
Column Temperature: 40°C.[8]
-
Detection:
-
Fluorescence Detector: Excitation at 340 nm, Emission at 450 nm for OPA derivatives.
-
UV Detector: 262 nm for FMOC derivatives.[5]
-
-
Gradient Elution: A typical gradient would start with a low percentage of mobile phase B, increasing to elute the more hydrophobic amino acids.
Data Presentation
| Parameter | OPA/FMOC Derivatization HPLC | Reference |
| Detection Limit | 40 pmol/mL for this compound | [9] |
| Linearity (r²) | >0.99 | [9] |
| Reproducibility | High degree of precision and accuracy | [4] |
| Analysis Time | ~26 minutes per sample | [5] |
Visualization
Caption: Workflow for this compound quantification using HPLC with pre-column derivatization.
Mass Spectrometry (MS) for this compound Quantification
Mass spectrometry offers high sensitivity and specificity for the quantification of amino acids, often without the need for derivatization.
Principle
In this method, the protein hydrolysate is introduced into a mass spectrometer, where the amino acids are ionized and separated based on their mass-to-charge ratio (m/z). Quantification is achieved by comparing the signal intensity of this compound to that of a stable isotope-labeled internal standard.
Experimental Protocol: LC-MS/MS
2.2.1. Protein Hydrolysis:
-
Follow the same acid hydrolysis protocol as described in section 1.2.1.
2.2.2. Sample Preparation for LC-MS/MS:
-
Neutralize the hydrolysate.
-
Dilute the sample with a borate buffer solution to ensure pH and retention time stability.[10][11]
-
Add a known concentration of a stable isotope-labeled this compound internal standard.
2.2.3. LC-MS/MS Conditions:
-
LC System: Shimadzu Nexera LC system or equivalent.[12]
-
Column: Phenomenex Luna C8 column (2.1 x 50 mm, 3.5 µm).[12]
-
Mobile Phase A: Water with 10 mM HFBA.[12]
-
Mobile Phase B: Acetonitrile with 10 mM HFBA.[12]
-
Flow Rate: 0.325 mL/min.[12]
-
Gradient Elution: A suitable gradient to separate this compound from other amino acids.[12]
-
Mass Spectrometer: Sciex 6500 QTrap MS or equivalent triple quadrupole mass spectrometer.[12]
-
Ionization Mode: Electrospray Ionization (ESI) in positive mode.
-
Detection: Multiple Reaction Monitoring (MRM) mode, monitoring specific precursor-to-product ion transitions for both native this compound and the isotope-labeled internal standard.
Data Presentation
| Parameter | LC-MS/MS | Reference |
| Detection Limit | < 0.1 µM | [10][11] |
| Reproducibility | < 11% for peak area | [10][11] |
| Analysis Time | ~20 minutes per sample | [10][11] |
| Derivatization | Not required | [10][11] |
Visualization
Caption: Workflow for this compound quantification using LC-MS/MS.
Ninhydrin Colorimetric Method
The ninhydrin method is a classical, cost-effective technique for the quantification of total amino acids. While not specific to this compound, it can be used to estimate the total amino acid concentration.
Principle
Ninhydrin reacts with the primary amino group of free amino acids at high temperatures to produce a deep purple-colored compound known as Ruhemann's purple.[13] The intensity of this color, which is proportional to the amino acid concentration, is measured spectrophotometrically at approximately 570 nm.[13]
Experimental Protocol
3.2.1. Protein Hydrolysis:
-
Follow the same acid hydrolysis protocol as described in section 1.2.1.
3.2.2. Ninhydrin Reaction:
-
Reagents:
-
Ninhydrin Reagent (2% w/v): Dissolve 0.2 g of ninhydrin in 10 mL of ethanol or acetone.[13]
-
Acetate Buffer (0.2 M, pH 5.5): Prepare by mixing solutions of 0.2 M sodium acetate and 0.2 M acetic acid until the desired pH is achieved.[13]
-
Diluent Solvent: Mix equal volumes of n-propanol and deionized water.[13]
-
-
Procedure:
-
Prepare a series of this compound standards of known concentrations.
-
Pipette 1.0 mL of each standard, the protein hydrolysate sample, and a blank (distilled water) into separate test tubes.
-
Add 1.0 mL of the ninhydrin reagent to all test tubes.[13][14]
-
Mix the contents thoroughly by vortexing.[13]
-
Incubate the test tubes in a boiling water bath for 15-20 minutes.[13][14]
-
Cool the test tubes to room temperature under running cold water.[13]
-
Add 5.0 mL of the diluent solvent to each tube and mix well.[13]
-
Measure the absorbance of each solution at 570 nm using a spectrophotometer, after zeroing the instrument with the blank.[13][14]
-
3.2.3. Data Analysis:
-
Plot a standard curve of absorbance versus the concentration of the this compound standards.
-
Determine the concentration of total amino acids in the protein hydrolysate sample by interpolating its absorbance value on the standard curve.
Data Presentation
| Parameter | Ninhydrin Method | Reference |
| Wavelength | 570 nm | [13][15] |
| Specificity | Reacts with all primary amino acids | [15] |
| Advantages | Simple, cost-effective | [16] |
| Limitations | Not specific for this compound, lower sensitivity than HPLC or MS | [17] |
Visualization
Caption: Workflow for total amino acid quantification using the Ninhydrin method.
References
- 1. This compound: Roles, Applications & Quantification in Biotech [metabolomics.creative-proteomics.com]
- 2. cerealsgrains.org [cerealsgrains.org]
- 3. photos.labwrench.com [photos.labwrench.com]
- 4. nopr.niscpr.res.in [nopr.niscpr.res.in]
- 5. agilent.com [agilent.com]
- 6. academic.oup.com [academic.oup.com]
- 7. agilent.com [agilent.com]
- 8. agilent.com [agilent.com]
- 9. HPLC method for analysis of free amino acids in fish using o-phthaldialdehyde precolumn derivatization - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. mdpi.com [mdpi.com]
- 11. High-Throughput Analysis of Amino Acids for Protein Quantification in Plant and Animal-Derived Samples Using High Resolution Mass Spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Quantitative Analysis and Discovery of this compound and Arginine Modifications (QuARKMod) - PMC [pmc.ncbi.nlm.nih.gov]
- 13. benchchem.com [benchchem.com]
- 14. Quantitative Estimation of Amino Acids by Ninhydrin (Procedure) : Biochemistry Virtual Lab I : Biotechnology and Biomedical Engineering : Amrita Vishwa Vidyapeetham Virtual Lab [vlab.amrita.edu]
- 15. The Ninhydrin Reaction Revisited: Optimisation and Application for Quantification of Free Amino Acids - PMC [pmc.ncbi.nlm.nih.gov]
- 16. researchgate.net [researchgate.net]
- 17. Amino Acid Assay [user.eng.umd.edu]
Application Notes: Lysine-Specific Protein Cross-Linking for Mass Spectrometry
Introduction
Chemical cross-linking coupled with mass spectrometry (XL-MS) is a powerful technique for studying protein-protein interactions (PPIs) and elucidating the three-dimensional structures of proteins and protein complexes.[1][2][3] The method involves covalently linking amino acid residues that are in close spatial proximity using bifunctional reagents. Subsequent enzymatic digestion and mass spectrometric analysis of the resulting cross-linked peptides provide distance constraints that can be used to map interaction interfaces and model protein architecture.[4][5] Lysine residues are ideal targets for cross-linking due to the high reactivity of their primary ε-amino groups and their frequent presence on protein surfaces.[6][7]
This document provides an overview of common this compound-specific cross-linking reagents and detailed protocols for their application in XL-MS workflows, aimed at researchers in structural biology and drug development.
Principle of this compound-Specific Cross-Linking
The most common chemistry for targeting this compound residues involves N-hydroxysuccinimide (NHS) esters.[1][6] These reagents react with the primary amines on this compound side chains and protein N-termini under physiological or slightly alkaline conditions (pH 7-9) to form stable amide bonds.[8][9] Homobifunctional NHS-ester cross-linkers, which possess two identical reactive groups, are widely used to connect two this compound residues.
Key this compound-Specific Cross-Linking Reagents
A variety of cross-linkers are available, differing in their spacer arm length, solubility, membrane permeability, and cleavability. The choice of reagent is critical and depends on the specific application.
| Reagent Name | Full Name | Spacer Arm (Å) | Solubility | Membrane Permeability | Key Feature |
| DSS | Disuccinimidyl suberate | 11.4 | Insoluble in water (soluble in DMSO/DMF) | Permeable | Standard reagent for in-vivo and intracellular cross-linking.[8][10] |
| BS3 | Bis(sulfosuccinimidyl) suberate | 11.4 | Water-soluble | Impermeable | Ideal for cell-surface cross-linking and soluble proteins.[8][10][11] |
| BS2G | Bis(sulfosuccinimidyl) glutarate | 7.7 | Water-soluble | Impermeable | Shorter spacer arm for capturing closer interactions.[12][13] |
| DSSO | Disuccinimidyl sulfoxide | 10.1 | Insoluble in water (soluble in DMSO/DMF) | Permeable | MS-cleavable, simplifies data analysis by separating linked peptides in the gas phase.[14][15] |
| DSS-d0/d12 | Deuterated Disuccinimidyl suberate | 11.4 | Insoluble in water (soluble in DMSO/DMF) | Permeable | Isotope-labeled pair for quantitative cross-linking (qXL-MS) to compare different states.[16][17][18] |
Experimental Workflow and Protocols
A typical XL-MS experiment follows a multi-step workflow, from sample preparation to data analysis. Each step must be carefully optimized to ensure the successful identification of cross-linked peptides.
Protocol 1: Cross-Linking of Proteins with DSS (Membrane Permeable)
This protocol is suitable for purified proteins, protein complexes, or for performing cross-linking within cells.
Materials:
-
Purified protein sample in an amine-free buffer (e.g., HEPES, PBS, pH 7.2-8.0).[8]
-
Disuccinimidyl suberate (DSS) cross-linker.
-
Anhydrous dimethyl sulfoxide (DMSO).
-
Quenching buffer: 1 M Tris-HCl, pH 7.5 or 1 M Ammonium Bicarbonate.[8][20]
-
Reaction tubes.
Procedure:
-
Prepare Protein Sample: Ensure the protein sample is in a compatible buffer at a concentration of 1-5 mg/mL.[9] Avoid buffers containing primary amines like Tris.
-
Prepare DSS Solution: Immediately before use, allow the vial of DSS to equilibrate to room temperature to prevent condensation.[21] Prepare a fresh 25-50 mM stock solution of DSS in anhydrous DMSO.[9][21]
-
Cross-Linking Reaction:
-
Add the DSS stock solution to the protein sample to achieve a final concentration typically between 0.25-5 mM. A 20- to 50-fold molar excess of cross-linker to protein is a common starting point for samples <5 mg/mL.[9][10]
-
Mix gently and incubate the reaction for 30-60 minutes at room temperature or for 2 hours on ice.[9][10][20]
-
-
Quench Reaction: Stop the reaction by adding the quenching buffer to a final concentration of 20-50 mM (e.g., add 1 M Tris-HCl to 50 mM).[9][10] Incubate for 15 minutes at room temperature.[9][10]
-
Proceed to Sample Preparation for MS: The cross-linked sample is now ready for denaturation, digestion, and subsequent analysis.
Protocol 2: Cross-Linking of Cell-Surface Proteins with BS3 (Membrane Impermeable)
This protocol is designed for selectively cross-linking proteins on the surface of intact cells or for use with highly purified, water-soluble proteins.
Materials:
-
Bis(sulfosuccinimidyl) suberate (BS3).
-
Amine-free buffer (e.g., PBS, pH 7.4).
-
Quenching buffer: 1 M Tris-HCl, pH 7.5.
-
(For cell work) Cell suspension in PBS.
Procedure:
-
Prepare Protein/Cell Sample:
-
Prepare BS3 Solution: Immediately before use, allow the BS3 vial to reach room temperature.[11] Prepare a fresh 25-50 mM stock solution of BS3 in reaction buffer (e.g., 20 mM Sodium Phosphate, pH 7.4) or ultrapure water.[11] Do not store the solution.
-
Cross-Linking Reaction:
-
Quench Reaction: Add 1 M Tris-HCl to a final concentration of 20-60 mM and incubate for 15 minutes at room temperature to quench any unreacted BS3.[11]
-
Proceed to Downstream Processing: For cell-based experiments, proceed with cell lysis. For all samples, the next step is preparation for mass spectrometry.
Protocol 3: Sample Preparation for Mass Spectrometry
Following cross-linking and quenching, the protein sample must be digested into peptides for MS analysis.
Materials:
-
Urea or Guanidine Hydrochloride
-
Dithiothreitol (DTT)
-
Iodoacetamide (IAA)
-
Trypsin (mass spectrometry grade)
-
Formic Acid (FA)
-
C18 solid-phase extraction (SPE) cartridges or stage tips.
Procedure:
-
Denaturation, Reduction, and Alkylation:
-
Denature the cross-linked proteins by adding urea to a final concentration of 8 M.
-
Reduce disulfide bonds by adding DTT to a final concentration of 10 mM and incubating at 37°C for 1 hour.
-
Alkylate cysteine residues by adding IAA to a final concentration of 20-25 mM and incubating for 30 minutes in the dark at room temperature.[18]
-
-
Digestion:
-
Dilute the sample with a compatible buffer (e.g., 50 mM ammonium bicarbonate) to reduce the urea concentration to below 2 M.
-
Add trypsin at a 1:50 to 1:100 enzyme-to-protein ratio (w/w) and incubate overnight at 37°C.[16]
-
-
Desalting:
-
Quench the digestion by adding formic acid to a final concentration of 1-5%.
-
Clean up and concentrate the peptide mixture using a C18 SPE cartridge or stage tip according to the manufacturer's protocol.[16]
-
Elute the peptides, dry them in a vacuum centrifuge, and resuspend in a suitable buffer for LC-MS/MS analysis (e.g., 0.1% formic acid).
-
Protocol 4: Enrichment of Cross-Linked Peptides
Cross-linked peptides are often present in low abundance compared to linear (unmodified) peptides.[14][22] Enrichment is therefore a critical step to increase the number of identified cross-links, especially in complex samples.
Methods:
-
Size-Exclusion Chromatography (SEC): This is the most common method. Cross-linked peptides are larger than most linear peptides and will elute in earlier fractions.[2][19][23][24] These early fractions can be pooled for MS analysis.
-
Strong Cation Exchange (SCX) Chromatography: Cross-linked peptides typically carry a higher charge state at low pH than linear peptides. They bind more strongly to SCX resins and can be selectively eluted using a salt gradient.[23][25]
Data Interpretation
The analysis of XL-MS data is computationally intensive, as it requires identifying pairs of peptides connected by a cross-linker. Specialized software is used to search the MS/MS spectra against a protein sequence database to identify intramolecular (loop-links) and intermolecular cross-links.
References
- 1. portlandpress.com [portlandpress.com]
- 2. This compound-specific chemical cross-linking of protein complexes and identification of cross-linking sites using LC-MS/MS and the xQuest/xProphet software pipeline - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Mass spectrometric analysis of cross-linking sites for the structure of proteins and protein complexes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. The beginning of a beautiful friendship: Cross-linking/mass spectrometry and modelling of proteins and multi-protein complexes - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Cross-linking mass spectrometry discovers, evaluates, and corroborates structures and protein–protein interactions in the human cell - PMC [pmc.ncbi.nlm.nih.gov]
- 6. biorxiv.org [biorxiv.org]
- 7. Development of Large-scale Cross-linking Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 8. biolchem.huji.ac.il [biolchem.huji.ac.il]
- 9. benchchem.com [benchchem.com]
- 10. documents.thermofisher.com [documents.thermofisher.com]
- 11. fnkprddata.blob.core.windows.net [fnkprddata.blob.core.windows.net]
- 12. maxperutzlabs.ac.at [maxperutzlabs.ac.at]
- 13. projectnetboard.absiskey.com [projectnetboard.absiskey.com]
- 14. lcms.labrulez.com [lcms.labrulez.com]
- 15. Optimized Cross-Linking Mass Spectrometry for in Situ Interaction Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Quantitative cross-linking/mass spectrometry using isotope-labelled cross-linkers - PMC [pmc.ncbi.nlm.nih.gov]
- 17. researchgate.net [researchgate.net]
- 18. researchgate.net [researchgate.net]
- 19. pubs.acs.org [pubs.acs.org]
- 20. What Are the Specific Steps for DSS Protein Crosslinking? | MtoZ Biolabs [mtoz-biolabs.com]
- 21. researchgate.net [researchgate.net]
- 22. Identification of Crosslinked Peptides after Click-based Enrichment Using Sequential CID and ETD Tandem Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 23. documents.thermofisher.com [documents.thermofisher.com]
- 24. This compound-specific chemical cross-linking of protein complexes and identification of cross-linking sites using LC-MS/MS and the xQuest/xProphet software pipeline | Springer Nature Experiments [experiments.springernature.com]
- 25. Selective enrichment and identification of cross-linked peptides to study 3-D structures of protein complexes by mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
Detecting Lysine Acetylation in Cell Lysates: Application Notes and Protocols for Researchers
For researchers, scientists, and drug development professionals, the detection and quantification of lysine acetylation is crucial for understanding cellular regulation and identifying novel therapeutic targets. This document provides detailed application notes and protocols for the robust detection of this compound acetylation in cell lysates, focusing on immunoprecipitation, Western blotting, and mass spectrometry-based approaches. Additionally, it explores the well-characterized p53 signaling pathway as an example of this compound acetylation's role in cellular processes.
This compound acetylation is a dynamic and reversible post-translational modification (PTM) that plays a pivotal role in regulating a wide array of cellular functions, including gene expression, metabolism, and signal transduction.[1][2] The enzymes responsible for this modification are this compound acetyltransferases (KATs) and this compound deacetylases (KDACs, including HDACs and sirtuins), which add and remove acetyl groups from this compound residues, respectively.[3] Dysregulation of this compound acetylation has been implicated in numerous diseases, including cancer, making the enzymes involved attractive targets for drug development.
Methods for Detecting this compound Acetylation
Several techniques can be employed to detect and quantify this compound acetylation in cellular lysates. The choice of method often depends on the specific research question, the required level of sensitivity, and whether a targeted or global analysis is desired.
Immunoprecipitation of Acetylated Proteins
Immunoprecipitation (IP) is a powerful technique to enrich for acetylated proteins or peptides from complex cell lysates.[4][5] This enrichment is often a necessary step for subsequent analysis by Western blotting or mass spectrometry, especially given the sub-stoichiometric nature of many acetylation events.[6]
Experimental Workflow for Acetyl-Lysine Immunoprecipitation
Caption: Workflow for the enrichment of acetylated proteins.
Protocol: Immunoprecipitation of Acetylated Proteins from Cell Lysates
This protocol is adapted from established methods for the enrichment of acetylated proteins.[4][5][7]
Materials:
-
Cell lysis buffer (e.g., RIPA buffer) supplemented with protease and HDAC inhibitors (e.g., Trichostatin A, Sodium Butyrate).
-
Anti-acetyl-lysine antibody conjugated to agarose or magnetic beads.
-
Control IgG-conjugated beads.
-
Wash buffer (e.g., PBS with 0.1% Tween-20).
-
Elution buffer (e.g., 0.1 M glycine, pH 2.5 or SDS-PAGE sample buffer).
-
Protein quantification assay (e.g., BCA assay).
Procedure:
-
Cell Lysis:
-
Harvest cells and wash with ice-cold PBS.
-
Lyse cells in ice-cold lysis buffer containing protease and HDAC inhibitors.
-
Incubate on ice for 30 minutes with occasional vortexing.
-
Centrifuge at 14,000 x g for 15 minutes at 4°C to pellet cell debris.
-
Collect the supernatant (cell lysate).
-
-
Protein Quantification:
-
Determine the protein concentration of the cell lysate using a BCA assay.
-
-
Pre-clearing the Lysate:
-
To reduce non-specific binding, incubate the lysate (e.g., 1-2 mg of total protein) with control IgG-conjugated beads for 1 hour at 4°C with gentle rotation.
-
Centrifuge and collect the supernatant.
-
-
Immunoprecipitation:
-
Add anti-acetyl-lysine antibody-conjugated beads to the pre-cleared lysate.
-
Incubate overnight at 4°C with gentle rotation.
-
-
Washing:
-
Pellet the beads by centrifugation and discard the supernatant.
-
Wash the beads three to five times with ice-cold wash buffer.
-
-
Elution:
-
Elute the bound acetylated proteins from the beads using an appropriate elution buffer. For Western blot analysis, proteins can be eluted by boiling in SDS-PAGE sample buffer. For mass spectrometry, an acidic elution buffer is often used, followed by neutralization.
-
Western Blot Analysis of this compound Acetylation
Western blotting is a widely used technique to detect specific acetylated proteins or to assess global changes in protein acetylation using a pan-anti-acetyl-lysine antibody.[8][9]
Protocol: Western Blotting for Acetylated Proteins
This protocol provides a general procedure for detecting acetylated proteins by Western blot.[8][10]
Materials:
-
SDS-PAGE gels and running buffer.
-
PVDF or nitrocellulose membrane.
-
Transfer buffer.
-
Blocking buffer (e.g., 5% non-fat milk or BSA in TBST).
-
Primary antibody (pan-anti-acetyl-lysine or a site-specific anti-acetyl-protein antibody).
-
HRP-conjugated secondary antibody.
-
Enhanced chemiluminescence (ECL) substrate.
Procedure:
-
Sample Preparation:
-
Prepare cell lysates as described in the IP protocol or directly lyse cells in SDS-PAGE sample buffer.
-
Boil the samples for 5-10 minutes at 95-100°C.
-
-
SDS-PAGE and Transfer:
-
Separate the protein samples on an SDS-PAGE gel.
-
Transfer the separated proteins to a PVDF or nitrocellulose membrane.
-
-
Blocking:
-
Block the membrane in blocking buffer for 1 hour at room temperature to prevent non-specific antibody binding.
-
-
Primary Antibody Incubation:
-
Incubate the membrane with the primary antibody (diluted in blocking buffer) overnight at 4°C with gentle agitation.
-
-
Secondary Antibody Incubation:
-
Wash the membrane three times with TBST.
-
Incubate the membrane with the HRP-conjugated secondary antibody (diluted in blocking buffer) for 1 hour at room temperature.
-
-
Detection:
-
Wash the membrane three times with TBST.
-
Incubate the membrane with ECL substrate and visualize the signal using a chemiluminescence imaging system.
-
Mass Spectrometry-based Acetylome Analysis
Mass spectrometry (MS) has become an indispensable tool for the large-scale identification and quantification of protein acetylation sites.[11][12] Quantitative MS approaches, such as label-free quantification (LFQ) and isobaric labeling (e.g., TMT), allow for the comparison of acetylation levels across different conditions.
Experimental Workflow for Quantitative Acetylomics
Caption: Workflow for quantitative mass spectrometry of acetylated peptides.
Protocol: Quantitative Mass Spectrometry of Acetylated Peptides
This protocol outlines a general workflow for quantitative acetylome analysis.[11][13]
Materials:
-
Lysis buffer with protease and HDAC inhibitors.
-
DTT and iodoacetamide for reduction and alkylation.
-
Trypsin for protein digestion.
-
Acetyl-lysine peptide enrichment kit or antibody-conjugated beads.
-
LC-MS/MS system.
-
Data analysis software.
Procedure:
-
Protein Extraction and Digestion:
-
Extract proteins from cell lysates and quantify.
-
Reduce and alkylate the proteins.
-
Digest the proteins into peptides using trypsin.
-
-
Peptide Labeling (Optional):
-
For quantitative analysis using isobaric tags, label the peptides with reagents such as TMT.
-
-
Acetyl-Peptide Enrichment:
-
Enrich for acetylated peptides from the total peptide mixture using an anti-acetyl-lysine antibody-based method.[14]
-
-
LC-MS/MS Analysis:
-
Analyze the enriched peptides by LC-MS/MS. Data can be acquired in data-dependent (DDA) or data-independent (DIA) mode.
-
-
Data Analysis:
-
Process the raw MS data using appropriate software to identify acetylated peptides and localize the acetylation sites.
-
Perform quantitative analysis to determine the relative abundance of acetylated peptides between samples.
-
Quantitative Data Presentation
The following tables summarize hypothetical quantitative data obtained from experiments investigating the effects of HDAC inhibitors on this compound acetylation.
Table 1: Global Acetylation Changes Detected by Western Blot
| Treatment | Fold Change in Global Acetylation (vs. Control) |
| Control | 1.0 |
| HDAC Inhibitor A (1 µM) | 3.5 ± 0.4 |
| HDAC Inhibitor B (5 µM) | 5.2 ± 0.6 |
Data are represented as mean ± standard deviation from three independent experiments.
Table 2: Quantitative Mass Spectrometry Analysis of a Specific Acetylated Peptide
| Protein | Peptide Sequence | Treatment | Fold Change (vs. Control) | p-value |
| Histone H3 | KSTGGKacAPR | Control | 1.0 | - |
| HDAC Inhibitor A | 4.8 | < 0.01 | ||
| p53 | TSDKacKPLDG | Control | 1.0 | - |
| HDAC Inhibitor A | 2.1 | < 0.05 |
Fold changes are calculated from the relative abundance of the acetylated peptide determined by label-free quantification.
Signaling Pathway Example: p53 Acetylation
The tumor suppressor protein p53 is a critical regulator of the cell cycle and apoptosis, and its activity is tightly controlled by various PTMs, including this compound acetylation.[15][16] Acetylation of specific this compound residues in p53 can modulate its DNA binding affinity, stability, and interaction with other proteins, thereby influencing cell fate.[17][18]
p53 Acetylation Signaling Pathway
Caption: Acetylation of p53 in response to DNA damage.
Upon DNA damage, acetyltransferases like p300/CBP and Tip60 are activated.[19] p300/CBP acetylates this compound residues in the C-terminal domain of p53, which enhances its DNA binding activity.[16] Tip60 specifically acetylates this compound 120 (K120) within the DNA-binding domain, promoting the induction of pro-apoptotic genes.[17] This acetylation is reversible and can be removed by HDACs, providing a dynamic regulatory mechanism.
Conclusion
The detection and quantification of this compound acetylation are essential for advancing our understanding of cellular signaling and disease pathogenesis. The methods and protocols outlined in this document provide a comprehensive guide for researchers to investigate this critical post-translational modification. The choice of methodology will depend on the specific experimental goals, but a combination of immunoprecipitation, Western blotting, and mass spectrometry will often yield the most comprehensive and robust results.
References
- 1. Quantitative Profiling of this compound Acetylation Reveals Dynamic Crosstalk between Receptor Tyrosine Kinases and this compound Acetylation [dspace.mit.edu]
- 2. ionsource.com [ionsource.com]
- 3. researchgate.net [researchgate.net]
- 4. immunechem.com [immunechem.com]
- 5. Immunoprecipitation of Acetyl-lysine And Western Blotting of Long-chain acyl-CoA Dehydrogenases and Beta-hydroxyacyl-CoA Dehydrogenase in Palmitic Acid Treated Human Renal Tubular Epithelial Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 6. bitesizebio.com [bitesizebio.com]
- 7. Method for detecting acetylated PD-L1 in cell lysates [protocols.io]
- 8. Determination of Protein this compound Acetylation by Western Blotting [bio-protocol.org]
- 9. appliedbiomics.com [appliedbiomics.com]
- 10. benchchem.com [benchchem.com]
- 11. Procedure of Quantitative Acetylomics Based on LC-MS/MS | MtoZ Biolabs [mtoz-biolabs.com]
- 12. researchgate.net [researchgate.net]
- 13. High-Resolution Mass Spectrometry to Identify and Quantify Acetylation Protein Targets - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Targeted Quantitation of Acetylated this compound Peptides by Selected Reaction Monitoring Mass Spectrometry | Springer Nature Experiments [experiments.springernature.com]
- 15. pnas.org [pnas.org]
- 16. Deciphering the acetylation code of p53 in transcription regulation and tumor suppression - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Acetylation of the p53 DNA binding domain regulates apoptosis induction - PMC [pmc.ncbi.nlm.nih.gov]
- 18. mdpi.com [mdpi.com]
- 19. Acetylation of p53 at this compound 373/382 by the Histone Deacetylase Inhibitor Depsipeptide Induces Expression of p21Waf1/Cip1 - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes and Protocols: Stable Isotope-Labeled Lysine in Metabolic Flux Analysis
For Researchers, Scientists, and Drug Development Professionals
Introduction
Metabolic flux analysis (MFA) is a powerful technique for elucidating the rates of metabolic reactions within a biological system.[1][2][3] The use of stable isotope-labeled substrates, such as L-[¹³C₆]-Lysine, allows for the precise tracing of atoms through metabolic pathways.[4][5][6] This approach, often referred to as ¹³C-Metabolic Flux Analysis (¹³C-MFA), provides a quantitative snapshot of cellular metabolism, revealing how cells utilize nutrients and synthesize essential biomolecules.[1][4] Lysine, an essential amino acid, plays a crucial role in protein synthesis, post-translational modifications, and as a precursor for various metabolic intermediates.[7] By tracing the incorporation of ¹³C-labeled this compound, researchers can gain insights into protein turnover, this compound catabolism, and its contribution to central carbon metabolism.
This document provides detailed application notes and experimental protocols for the use of stable isotope-labeled this compound in metabolic flux analysis, tailored for researchers in academia and the pharmaceutical industry.
Core Principles
The fundamental principle of ¹³C-MFA involves introducing a substrate labeled with the stable isotope ¹³C into a biological system.[1][4] As the cells metabolize this labeled substrate, the ¹³C atoms are incorporated into various downstream metabolites. By measuring the mass isotopomer distribution (the relative abundance of molecules with different numbers of ¹³C atoms) of these metabolites, typically using mass spectrometry (MS) or nuclear magnetic resonance (NMR) spectroscopy, it is possible to deduce the relative activities of different metabolic pathways.[2][4]
When using stable isotope-labeled this compound, the primary applications include:
-
Protein Synthesis and Degradation Dynamics: In techniques like Stable Isotope Labeling by Amino Acids in Cell Culture (SILAC), ¹³C-labeled this compound is used to differentiate between "old" and "newly" synthesized proteins, allowing for the quantification of protein turnover.[5][8][9][10]
-
This compound Catabolism and Contribution to Central Metabolism: Tracing the labeled carbon atoms from this compound through its degradation pathways can reveal the flux through these pathways and how this compound contributes to the tricarboxylic acid (TCA) cycle and other central metabolic routes.[7][11]
-
Metabolic Engineering and Optimization: In industrial biotechnology, ¹³C-MFA with labeled substrates is used to understand and optimize the production of compounds like this compound in microorganisms such as Corynebacterium glutamicum.[12][13][14]
Key Applications and Experimental Data
The following tables summarize quantitative data from studies that have utilized stable isotope-labeled substrates to analyze this compound-related metabolic fluxes.
Table 1: Comparative Metabolic Fluxes in this compound-Producing Corynebacterium glutamicum on Different Carbon Sources
| Metabolic Flux | Glucose (%)[12] | Fructose (%)[12] |
| Substrate Uptake | 100 | 100 |
| Pentose Phosphate Pathway | 62.0 | 14.4 |
| Pyruvate Dehydrogenase | 70.9 | 95.2 |
| This compound Synthesis | 11.1 mM (final conc.) | 8.6 mM (final conc.) |
Table 2: Impact of Genetic Modification on Metabolic Fluxes in C. glutamicum
| Strain / Modification | Pentose Phosphate Pathway Flux (%)[14] | This compound Yield Increase (%)[14] |
| Parent Strain (lysCfbr) | N/A | Baseline |
| Overexpression of zwf | +15 | up to 70 |
| zwf overexpression + A243T mutation | Further increased | Further improved |
Experimental Protocols
Protocol 1: ¹³C-Lysine Labeling for Metabolic Flux Analysis in Cell Culture
This protocol outlines the general steps for conducting a ¹³C-MFA experiment using L-[¹³C₆]-Lysine in cultured mammalian cells.
Materials:
-
Mammalian cell line of interest
-
Standard cell culture medium ("light" medium)
-
Isotope labeling medium ("heavy" medium): identical to the standard medium but with natural this compound replaced by L-[¹³C₆]-Lysine.[5]
-
Dialyzed Fetal Bovine Serum (dFBS)
-
Phosphate-Buffered Saline (PBS)
-
Lysis buffer (e.g., RIPA buffer) with protease and phosphatase inhibitors[15]
-
Methanol, Acetonitrile, and Water (LC-MS grade)
-
Internal standards (e.g., L-[¹³C₆,¹⁵N₂]-Lysine) for quantification[16]
Procedure:
-
Cell Culture and Adaptation:
-
Culture cells in the "light" medium to the desired confluence.
-
For steady-state labeling, switch the cells to the "heavy" medium and culture for a sufficient period to achieve isotopic steady state (typically several cell doublings).[15]
-
For kinetic flux analysis, add the "heavy" medium at time zero and collect samples at various time points.
-
-
Metabolite Extraction:
-
Aspirate the medium and wash the cells twice with ice-cold PBS.
-
Quench metabolism by adding ice-cold 80% methanol.
-
Scrape the cells and collect the cell suspension.
-
Lyse the cells by sonication or freeze-thaw cycles.
-
Centrifuge the lysate at high speed to pellet cell debris.
-
Collect the supernatant containing the metabolites.[17]
-
-
Sample Preparation for LC-MS/MS Analysis:
-
Dry the metabolite extract under a stream of nitrogen or using a vacuum concentrator.
-
Reconstitute the dried metabolites in a suitable solvent (e.g., 50% acetonitrile in water) compatible with the LC-MS system.[16]
-
Add internal standards for absolute quantification.
-
-
LC-MS/MS Analysis:
-
Analyze the samples using a high-resolution mass spectrometer coupled with liquid chromatography.
-
Develop a targeted method to detect and quantify the different mass isotopomers of this compound and its downstream metabolites.
-
-
Data Analysis:
-
Integrate the peak areas for each mass isotopomer.
-
Correct for the natural abundance of ¹³C.
-
Use metabolic flux analysis software (e.g., INCA, Metran) to calculate the metabolic fluxes from the mass isotopomer distribution data.
-
Protocol 2: Sample Preparation for Protein-Level (SILAC) Analysis
This protocol describes the preparation of protein samples from cells labeled with L-[¹³C₆]-Lysine for quantitative proteomics.
Materials:
-
"Light" and "heavy" labeled cell populations
-
Lysis buffer with protease inhibitors
-
BCA protein assay kit
-
Dithiothreitol (DTT)
-
Iodoacetamide (IAA)
-
Sequencing-grade trypsin or Lys-C
-
C18 desalting columns[15]
Procedure:
-
Cell Lysis and Protein Quantification:
-
Sample Mixing:
-
Combine equal amounts of protein from the "light" and "heavy" lysates.[15] This 1:1 mixing is crucial for accurate relative quantification.
-
-
Protein Digestion:
-
Peptide Desalting:
-
Acidify the peptide mixture with trifluoroacetic acid (TFA).
-
Desalt and concentrate the peptides using C18 desalting columns according to the manufacturer's instructions.[15]
-
-
LC-MS/MS Analysis and Data Interpretation:
-
Analyze the desalted peptides by LC-MS/MS.
-
Identify peptides using a database search algorithm.
-
Quantify the relative abundance of "light" and "heavy" peptide pairs based on their peak intensities in the MS1 spectrum.[5] The ratio of these intensities reflects the relative abundance of the protein in the two samples.
-
Visualizations
Caption: Workflow for ¹³C-Metabolic Flux Analysis using stable isotope-labeled this compound.
Caption: Simplified pathway of this compound catabolism leading to the TCA cycle.
Caption: Experimental workflow for SILAC-based quantitative proteomics.
References
- 1. Overview of 13c Metabolic Flux Analysis - Creative Proteomics [creative-proteomics.com]
- 2. researchgate.net [researchgate.net]
- 3. Measurement of metabolic fluxes using stable isotope tracers in whole animals and human patients - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Frontiers | 13C metabolic flux analysis: Classification and characterization from the perspective of mathematical modeling and application in physiological research of neural cell [frontiersin.org]
- 5. benchchem.com [benchchem.com]
- 6. chempep.com [chempep.com]
- 7. This compound Metabolism: Pathways, Regulation, and Biological Significance - Creative Proteomics [creative-proteomics.com]
- 8. youtube.com [youtube.com]
- 9. SILAC Metabolic Labeling Systems | Thermo Fisher Scientific - US [thermofisher.com]
- 10. SILAC Reagents and Sets â Cambridge Isotope Laboratories, Inc. [isotope.com]
- 11. The fate of this compound: Non-targeted stable isotope analysis reveals parallel ways for this compound catabolization in Phaeobacter inhibens - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Comparative Metabolic Flux Analysis of this compound-Producing Corynebacterium glutamicum Cultured on Glucose or Fructose - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Increased this compound production by flux coupling of the tricarboxylic acid cycle and the this compound biosynthetic pathway--metabolic engineering of the availability of succinyl-CoA in Corynebacterium glutamicum - PubMed [pubmed.ncbi.nlm.nih.gov]
- 14. Metabolic flux engineering of L-lysine production in Corynebacterium glutamicum--over expression and modification of G6P dehydrogenase - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. benchchem.com [benchchem.com]
- 16. Optimizing Sample Preparation for Accurate this compound Measurement - Creative Proteomics [metabolomics.creative-proteomics.com]
- 17. Guide for metabolomics experiments | Nebraska Center for Integrated Biomolecular Communication | Nebraska [ncibc.unl.edu]
Revolutionizing Proteomics: A Detailed Guide to Chemical Labeling of Lysine Residues
For Researchers, Scientists, and Drug Development Professionals
In the dynamic landscape of proteomics, the precise quantification of protein abundance is paramount to unraveling complex biological processes, identifying disease biomarkers, and accelerating drug discovery. Chemical labeling of lysine residues has emerged as a powerful and versatile strategy for comparative and multiplexed proteomic analysis. The primary ε-amino group of this compound, being highly nucleophilic and readily accessible on the protein surface, serves as an ideal target for a variety of labeling chemistries.[1]
This document provides a comprehensive overview and detailed protocols for three widely adopted methods for chemical labeling of this compound residues: Tandem Mass Tags (TMT), Isobaric Tags for Relative and Absolute Quantitation (iTRAQ), and Reductive Dimethylation.
Comparative Analysis of this compound Labeling Chemistries
Choosing the appropriate labeling strategy is critical and depends on the specific experimental goals, sample complexity, and available instrumentation. Below is a summary of key quantitative and qualitative parameters for TMT, iTRAQ, and reductive dimethylation.
| Feature | Tandem Mass Tags (TMT) | Isobaric Tags for Relative and Absolute Quantitation (iTRAQ) | Reductive Dimethylation |
| Multiplexing Capacity | Up to 18-plex (TMTpro) | Up to 8-plex | Typically 2-plex or 3-plex, can be extended |
| Labeling Chemistry | Amine-reactive NHS-ester | Amine-reactive NHS-ester | Reductive amination with formaldehyde and a reducing agent |
| Quantification Level | MS/MS (reporter ions) | MS/MS (reporter ions) | MS1 (mass shift) |
| Labeling Efficiency | High (>95% is considered acceptable) | High | Generally high, but can be variable |
| Ratio Compression | Can be significant, especially in complex samples. Mitigated by MS3 or advanced acquisition methods. | Can occur due to co-isolation and co-fragmentation of peptides. | Generally less prone to ratio compression. |
| Cost | High | High | Low |
| Proteome Coverage | High, can be increased with fractionation. | High, comparable to TMT. | Can be slightly lower than isobaric tagging methods. |
| Data Analysis | Requires specialized software for reporter ion extraction and quantification. | Requires specialized software for reporter ion extraction and quantification. | Relatively straightforward, based on precursor ion intensities. |
| Key Advantages | High multiplexing, good for large-scale studies. | Well-established with extensive literature. | Cost-effective, simple, and robust. |
| Key Disadvantages | Ratio compression, high cost. | Ratio compression, high cost, lower multiplexing than TMT. | Lower multiplexing, potential for side reactions if not optimized. |
Tandem Mass Tags (TMT)
Tandem Mass Tag (TMT) technology, developed by Thermo Fisher Scientific, utilizes isobaric chemical tags to label the N-terminus of peptides and the ε-amino group of this compound residues.[2] The tags consist of a reporter group, a normalizer group, and a peptide-reactive group. While the total mass of the tags is identical, upon fragmentation in the mass spectrometer, unique reporter ions are generated, allowing for the relative quantification of peptides from different samples.[2]
TMT Experimental Workflow
Detailed Protocol for TMT Labeling
This protocol is a general guideline and may require optimization based on sample type and experimental conditions.
Materials:
-
TMT Label Reagents (e.g., TMTpro™ 16plex Label Reagent Set)
-
Anhydrous acetonitrile (ACN)
-
Triethylammonium bicarbonate (TEAB) buffer (100 mM, pH 8.5)
-
Hydroxylamine (5% w/v)
-
Protein digest samples (quantified)
Procedure:
-
Reagent Preparation:
-
Equilibrate the TMT label reagents to room temperature before opening.
-
Reconstitute each TMT label reagent vial with anhydrous ACN. The volume will depend on the specific kit instructions. Vortex gently to dissolve.
-
-
Sample Preparation:
-
Ensure your digested peptide samples are in an amine-free buffer, such as 100 mM TEAB, pH 8.5.
-
The peptide concentration should be accurately determined. For optimal labeling, use 10-100 µg of peptide per labeling reaction.
-
-
Labeling Reaction:
-
Add the appropriate volume of the reconstituted TMT label reagent to each peptide sample. A common starting point is a 4:1 TMT reagent to peptide ratio (w/w).
-
Incubate the reaction for 1 hour at room temperature.[3]
-
-
Quenching:
-
Add 5% hydroxylamine to each sample to quench the labeling reaction.[4] Incubate for 15 minutes at room temperature.
-
-
Sample Pooling and Cleanup:
-
Combine the labeled samples in equal amounts into a new microcentrifuge tube.
-
Proceed with sample cleanup, for example, using a C18 solid-phase extraction (SPE) cartridge, to remove excess TMT reagent and other contaminants.
-
The pooled and cleaned sample is now ready for optional fractionation and LC-MS/MS analysis.
-
Isobaric Tags for Relative and Absolute Quantitation (iTRAQ)
iTRAQ, developed by SCIEX, is another widely used isobaric tagging method for quantitative proteomics.[5] Similar to TMT, iTRAQ reagents label the N-termini and this compound side chains of peptides. The iTRAQ reagents consist of a reporter group, a balance group, and a peptide-reactive group.[5] Upon fragmentation, the reporter ions provide quantitative information.
iTRAQ Experimental Workflow
Detailed Protocol for iTRAQ Labeling
This protocol provides a general framework for iTRAQ labeling.
Materials:
-
iTRAQ Reagents (e.g., iTRAQ® Reagents - 8-plex)
-
Ethanol
-
Dissolution Buffer (provided with the kit)
-
Stopping Reagent (provided with the kit)
-
Protein digest samples
Procedure:
-
Reagent Preparation:
-
Allow the iTRAQ reagent vials to reach room temperature.
-
Add ethanol to each vial to dissolve the reagent. Vortex to mix.
-
-
Sample Labeling:
-
Transfer the dissolved iTRAQ reagent to the respective protein digest sample.
-
Incubate the mixture at room temperature for 2 hours.
-
-
Reaction Termination:
-
The reaction is typically self-terminating, but a stopping reagent can be added if necessary.
-
-
Sample Pooling and Cleanup:
-
Combine the labeled samples into a single tube.
-
Perform sample cleanup using strong cation exchange (SCX) or reversed-phase chromatography to remove unreacted reagents and interfering substances.
-
The combined and cleaned sample is ready for LC-MS/MS analysis.
-
Reductive Dimethylation
Reductive dimethylation is a cost-effective and straightforward chemical labeling method that introduces dimethyl groups to the primary amines of peptides (N-terminus and this compound side chains).[6][7] This is achieved through a reaction with formaldehyde and a reducing agent, typically sodium cyanoborohydride.[7] The mass difference between light (using CH₂O and NaBH₃CN) and heavy (using CD₂O and NaBD₃CN) labeled peptides allows for quantification at the MS1 level.
Reductive Dimethylation Experimental Workflow
Detailed Protocol for Reductive Dimethylation
This protocol outlines the general steps for on-column reductive dimethylation.
Materials:
-
Formaldehyde (CH₂O, ~4% in water) - for light labeling
-
Deuterated formaldehyde (CD₂O, ~4% in D₂O) - for heavy labeling
-
Sodium cyanoborohydride (NaBH₃CN) solution (e.g., 1M in water) - for light labeling
-
Sodium cyanoborodeuteride (NaBD₃CN) solution (e.g., 1M in D₂O) - for heavy labeling
-
Ammonia solution (~1% in water)
-
Formic acid (FA)
-
C18 StageTips or SPE cartridges
-
Protein digest samples
Procedure:
-
Sample Loading:
-
Acidify the peptide samples with formic acid.
-
Load the samples onto conditioned and equilibrated C18 StageTips or SPE cartridges.
-
-
Labeling Reaction:
-
Light Labeling: Prepare a labeling solution containing formaldehyde and sodium cyanoborohydride in a suitable buffer (e.g., 50 mM phosphate buffer, pH 7.2).
-
Heavy Labeling: Prepare a labeling solution containing deuterated formaldehyde and sodium cyanoborodeuteride in the same buffer.
-
Apply the respective labeling solution to the C18-bound peptides and allow the reaction to proceed for about 30 minutes at room temperature.
-
-
Quenching and Washing:
-
Quench the reaction by adding an ammonia solution.
-
Wash the C18 material extensively with a wash buffer (e.g., 0.1% formic acid) to remove excess reagents.
-
-
Elution and Pooling:
-
Elute the labeled peptides from the C18 material using a high organic solvent solution (e.g., 80% ACN, 0.1% FA).
-
Combine the light and heavy labeled samples.
-
-
Sample Analysis:
-
The pooled sample is now ready for LC-MS analysis. Quantification is performed by comparing the peak areas of the light and heavy peptide pairs in the MS1 spectra.
-
Conclusion
The chemical labeling of this compound residues is a cornerstone of modern quantitative proteomics. TMT and iTRAQ offer high multiplexing capabilities, making them ideal for large-scale comparative studies, while reductive dimethylation provides a cost-effective and robust alternative for smaller-scale experiments. The detailed protocols and comparative data presented here serve as a valuable resource for researchers to select and implement the most suitable this compound labeling strategy for their specific research needs, ultimately driving new discoveries in biology and medicine.
References
- 1. Quantitative Proteomics Using Reductive Dimethylation for Stable Isotope Labeling - PMC [pmc.ncbi.nlm.nih.gov]
- 2. iTRAQ™ and TMT™ quantification [proteome-factory.com]
- 3. Quantitative proteomics reveals extensive this compound ubiquitination and transcription factor stability states in Arabidopsis - PMC [pmc.ncbi.nlm.nih.gov]
- 4. iTRAQ/TMT, Label Free, DIA, DDA in Proteomic - Creative Proteomics [creative-proteomics.com]
- 5. benchchem.com [benchchem.com]
- 6. Comparing SILAC- and Stable Isotope Dimethyl-Labeling Approaches for Quantitative Proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Comparison of iTRAQ/TMT Label-Based Quantitative Proteomics Techniques | MtoZ Biolabs [mtoz-biolabs.com]
Quantification of Lysine using High-Performance Liquid Chromatography (HPLC): Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
Abstract
Lysine, an essential amino acid, plays a critical role in various physiological processes, including protein synthesis, carnitine production for energy metabolism, and calcium absorption.[1] Accurate quantification of this compound is crucial in diverse fields such as pharmaceutical sciences, food technology, and clinical research. High-Performance Liquid Chromatography (HPLC) offers a robust and versatile platform for the precise determination of this compound concentrations in a variety of sample matrices.[1][2] This document provides detailed application notes and protocols for the quantification of this compound using HPLC, focusing on pre-column derivatization techniques that enhance detection sensitivity and selectivity.
Introduction to this compound Quantification by HPLC
This compound lacks a strong native chromophore, making its direct detection by UV-Visible spectrophotometry challenging, especially at low concentrations.[1] To overcome this limitation, pre-column derivatization is commonly employed. This process involves reacting the primary amino groups of this compound with a labeling agent to form a derivative that is readily detectable by UV-Visible or fluorescence detectors.[1][3] This approach significantly improves the sensitivity and selectivity of the analysis.[1]
Several derivatizing agents are available, with the choice depending on the sample matrix, required sensitivity, and available instrumentation. Common derivatizing agents include:
-
o-Phthalaldehyde (OPA): Reacts with primary amines in the presence of a thiol to form highly fluorescent isoindole derivatives.[1]
-
Phenylisothiocyanate (PITC): Reacts with amino acids to yield phenylthiocarbamyl (PTC) derivatives, which are UV-active.[1]
-
Dansyl Chloride (Dns-Cl): Reacts with primary and secondary amino groups to form fluorescent dansyl derivatives.[1][3][4]
-
9-Fluorenylmethyloxycarbonyl Chloride (FMOC-Cl): Reacts with primary and secondary amines to produce highly fluorescent derivatives.[5][6]
This document will detail protocols for this compound quantification using OPA and PITC derivatization followed by Reversed-Phase HPLC (RP-HPLC) analysis. Additionally, alternative methods such as Hydrophilic Interaction Liquid Chromatography (HILIC) and Ion-Exchange Chromatography (IEC) will be discussed.
Experimental Workflow for this compound Quantification
The general workflow for quantifying this compound using HPLC with pre-column derivatization involves several key steps as illustrated below.
Caption: General workflow for HPLC-based this compound quantification.
Protocols
Protocol 1: this compound Quantification using OPA Derivatization and RP-HPLC with Fluorescence Detection
This method is highly sensitive and suitable for biological samples.
3.1.1. Materials and Reagents
-
This compound standard
-
o-Phthalaldehyde (OPA)
-
2-Mercaptoethanol (MCE) or 3-Mercaptopropionic acid (3-MPA)
-
Boric acid buffer (0.4 M, pH 10.2)
-
Acetonitrile (HPLC grade)
-
Methanol (HPLC grade)
-
Water (HPLC grade)
-
Trichloroacetic acid (TCA) or Acetonitrile for protein precipitation
-
Sample (e.g., plasma, cell culture media)
3.1.2. Sample Preparation
-
For plasma samples, precipitate proteins by adding an equal volume of 10% (w/v) TCA or three volumes of cold acetonitrile.
-
Vortex vigorously for 1 minute.
-
Centrifuge at 10,000 x g for 10 minutes at 4°C.
-
Collect the supernatant and filter through a 0.22 µm syringe filter.
3.1.3. OPA Derivatization Procedure
-
Prepare the OPA reagent by dissolving 40 mg of OPA in 1 mL of methanol, then add 9 mL of 0.4 M boric acid buffer (pH 10.2) and 100 µL of 2-mercaptoethanol. This reagent should be prepared fresh daily.
-
In an autosampler vial, mix 50 µL of the sample supernatant or standard with 450 µL of the OPA reagent.
-
Allow the reaction to proceed for 2 minutes at room temperature before injection.
3.1.4. HPLC Conditions
| Parameter | Condition |
| Column | C18 reversed-phase column (e.g., 4.6 x 150 mm, 5 µm) |
| Mobile Phase A | 0.05 M Sodium Acetate, pH 6.5 |
| Mobile Phase B | Acetonitrile |
| Gradient | 0-5 min: 10% B; 5-20 min: 10-50% B; 20-25 min: 50% B; 25-30 min: 10% B |
| Flow Rate | 1.0 mL/min |
| Column Temperature | 30°C |
| Injection Volume | 20 µL |
| Detection | Fluorescence Detector (Excitation: 340 nm, Emission: 450 nm) |
3.1.5. Quantification
Prepare a standard curve by derivatizing and injecting known concentrations of this compound standards. Plot the peak area against the concentration to determine the concentration of this compound in the samples.
Protocol 2: this compound Quantification using PITC Derivatization and RP-HPLC with UV Detection
This method is robust and suitable for a wide range of samples, including protein hydrolysates and feed samples.[1]
3.2.1. Materials and Reagents
-
This compound standard
-
Phenylisothiocyanate (PITC)
-
Triethylamine (TEA)
-
Acetonitrile (HPLC grade)
-
Methanol (HPLC grade)
-
Water (HPLC grade)
-
Sodium Acetate buffer (e.g., 0.05 M, pH 5.8)
-
Sample (e.g., protein hydrolysate, feed extract)
3.2.2. Sample Preparation (for Protein Hydrolysates)
-
Hydrolyze the protein sample with 6 M HCl at 110°C for 24 hours in a sealed, evacuated tube.
-
Remove the HCl by evaporation under a stream of nitrogen.
-
Reconstitute the dried hydrolysate in a known volume of reconstitution solution (e.g., water or a suitable buffer).
3.2.3. PITC Derivatization Procedure
-
Prepare the derivatization reagent by mixing methanol, TEA, and PITC in a ratio of 7:1:1 (v/v/v).
-
To 20 µL of the sample or standard, add 20 µL of the derivatization reagent.
-
Vortex and incubate at room temperature for 20 minutes.[7]
-
Evaporate the excess reagent and solvent under a stream of nitrogen.
-
Reconstitute the dried derivative in the mobile phase for HPLC analysis.[7]
3.2.4. HPLC Conditions
| Parameter | Condition |
| Column | C18 reversed-phase column (e.g., 4.6 x 250 mm, 5 µm) |
| Mobile Phase A | 0.05 M Sodium Acetate buffer (pH 5.8) containing 5% Acetonitrile |
| Mobile Phase B | Acetonitrile |
| Gradient | A suitable gradient to separate the PTC-amino acids, for example: 0-15 min, 5-30% B; 15-25 min, 30-60% B; 25-30 min, 60-5% B |
| Flow Rate | 1.0 mL/min |
| Column Temperature | 40°C |
| Injection Volume | 20 µL |
| Detection | UV Detector at 254 nm |
3.2.5. Quantification
Construct a calibration curve using PITC-derivatized this compound standards of known concentrations. Determine the this compound concentration in the samples by comparing their peak areas to the standard curve.
Alternative and Complementary Methods
Hydrophilic Interaction Liquid Chromatography (HILIC)
HILIC is a suitable technique for the separation of polar compounds like this compound.[8][9] It can be used for the analysis of underivatized amino acids, simplifying sample preparation.[9]
Caption: Principle of HILIC separation for polar analytes like this compound.
A typical HILIC method might employ a silica or amide-based column with a mobile phase consisting of a high percentage of acetonitrile and a small amount of aqueous buffer. Detection can be achieved using an Evaporative Light Scattering Detector (ELSD) or mass spectrometry (MS).[10][11][12]
Ion-Exchange Chromatography (IEC)
IEC is a classical and reliable method for amino acid analysis, including this compound.[13][14][15] It separates amino acids based on their net charge at a specific pH.[15] Post-column derivatization with ninhydrin is often used for detection.[13][16]
Quantitative Data Summary
The following tables summarize typical performance characteristics of the described HPLC methods for this compound quantification.
Table 1: Performance Characteristics of OPA-RP-HPLC Method
| Parameter | Value | Reference |
| Linearity Range | 1 - 200 µM | [2][17] |
| Limit of Detection (LOD) | < 1.24 µM | [2][17] |
| Limit of Quantification (LOQ) | < 4.14 µM | [2][17] |
| Accuracy (% Recovery) | 90 - 105% | [2][17] |
| Precision (RSD%) | < 5% | [2][17] |
Table 2: Performance Characteristics of PITC-RP-HPLC Method
| Parameter | Value | Reference |
| Linearity Range | 10 - 500 µM | [7] |
| Limit of Detection (LOD) | ~1 pmol | [7] |
| Limit of Quantification (LOQ) | ~3 pmol | [7] |
| Accuracy (% Recovery) | 95 - 105% | [18] |
| Precision (RSD%) | < 6% | [7] |
Conclusion
HPLC is a powerful and adaptable technique for the accurate and precise quantification of this compound in a wide array of samples. Pre-column derivatization with reagents such as OPA and PITC significantly enhances detection sensitivity and selectivity, allowing for reliable measurements even at low concentrations. The choice of the specific method and derivatization agent should be guided by the sample matrix, the required level of sensitivity, and the available instrumentation. The protocols and data presented in these application notes provide a solid foundation for researchers, scientists, and drug development professionals to establish and validate robust HPLC-based this compound quantification assays in their laboratories.
References
- 1. benchchem.com [benchchem.com]
- 2. ciencia.ucp.pt [ciencia.ucp.pt]
- 3. scribd.com [scribd.com]
- 4. researchgate.net [researchgate.net]
- 5. academic.oup.com [academic.oup.com]
- 6. Analysis of amino acids by HPLC/electrospray negative ion tandem mass spectrometry using 9-fluorenylmethoxycarbonyl chloride (Fmoc-Cl) derivatization - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. daneshyari.com [daneshyari.com]
- 8. Rapid hydrophilic interaction chromatography determination of this compound in pharmaceutical preparations with fluorescence detection after postcolumn derivatization with o-phtaldialdehyde - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. agilent.com [agilent.com]
- 10. tandfonline.com [tandfonline.com]
- 11. hitachi-hightech.com [hitachi-hightech.com]
- 12. caod.oriprobe.com [caod.oriprobe.com]
- 13. 193.16.218.141 [193.16.218.141]
- 14. [Application of ion-exchange chromatography in studies of amino acid composition of food-stuff proteins] - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. harvardapparatus.com [harvardapparatus.com]
- 16. joint-research-centre.ec.europa.eu [joint-research-centre.ec.europa.eu]
- 17. Validation of a Simple HPLC-Based Method for this compound Quantification for Ruminant Nutrition - PMC [pmc.ncbi.nlm.nih.gov]
- 18. researchgate.net [researchgate.net]
Application Notes and Protocols: Lysine Conjugation in Antibody-Drug Conjugate (ADC) Development
For Researchers, Scientists, and Drug Development Professionals
Introduction
Antibody-Drug Conjugates (ADCs) are a rapidly advancing class of targeted cancer therapeutics that combine the specificity of a monoclonal antibody (mAb) with the potent cell-killing activity of a cytotoxic agent. The method of conjugating the drug to the antibody is a critical determinant of the ADC's efficacy, safety, and pharmacokinetic profile. Lysine conjugation, one of the most established and widely used methods, targets the ε-amino groups of this compound residues on the antibody surface. An immunoglobulin G1 (IgG1) antibody, for instance, possesses approximately 90 this compound residues, offering multiple potential sites for drug attachment.[] This traditional approach is valued for its simplicity and the stability of the resulting amide bond. However, it typically results in a heterogeneous mixture of ADC species with varying drug-to-antibody ratios (DARs) and conjugation sites, which can present analytical and clinical challenges.[2][3][4]
These application notes provide a comprehensive overview of this compound's role in ADC development, detailing the chemistry, protocols for key experiments, and the characterization of this compound-conjugated ADCs.
Chemistry of this compound Conjugation
The primary mechanism for this compound conjugation involves the reaction of the nucleophilic ε-amino group of a this compound residue with an amine-reactive functional group on the linker-payload. The most common reagents for this purpose are N-hydroxysuccinimide (NHS) esters, which react with this compound residues under mild pH conditions (typically pH 7.0–9.0) to form a stable amide bond.[2] Isothiocyanates are another class of reagents that can be used, forming a stable thiourea linkage.[]
The stochastic nature of this reaction means that conjugation can occur at any of the solvent-accessible this compound residues, leading to a heterogeneous product.[5][6] While process optimization can favor conjugation at 8-10 kinetically preferred sites, the potential for a wide distribution of DARs and positional isomers remains.[] This heterogeneity can impact the ADC's therapeutic index, with higher DAR species sometimes showing reduced stability and increased aggregation.[][7]
Stochastic vs. Site-Specific this compound Conjugation
While traditional this compound conjugation is stochastic, leading to a heterogeneous mixture, recent advancements have focused on developing site-specific conjugation methods to produce more homogeneous ADCs with a defined DAR and specific conjugation sites.[2][3][4] Site-specific methods can involve enzymatic approaches or the use of affinity reagents to direct conjugation to a particular this compound residue.[8][] The move towards site-specific conjugation aims to improve the pharmacokinetic properties, reduce off-target toxicity, and enhance the overall therapeutic window of ADCs.[8][10] Despite the trend towards site-specific methods, stochastic this compound conjugation remains a valuable tool, particularly for rapid screening and early-stage development, with approximately 25% of ADCs in clinical trials still utilizing this approach.[11][12]
Quantitative Data on this compound-Conjugated ADCs
The characterization of this compound-conjugated ADCs involves determining the average DAR and the distribution of different DAR species. This is crucial for understanding the product's heterogeneity and ensuring batch-to-batch consistency.
| ADC Example | Average DAR | DAR Range | Number of Identified Conjugation Sites | Reference |
| Trastuzumab Emtansine (Kadcyla®/T-DM1) | 3.5 | 0-8 | ~40 to 82 | [2][13][14] |
| Gemtuzumab Ozogamicin (Mylotarg®) | Not specified | Not specified | Not specified | [5] |
| Inotuzumab Ozogamicin (Besponsa®) | 6 | 0-9 | Not specified | [14] |
| Trastuzumab-Doxorubicin | 0.92 | Not specified | 1 (K183 on Fab) | [2] |
| Trastuzumab-DM1 (AJICAP Platform) | 1.9 | Not specified | Site-specific | [8] |
Experimental Protocols
Protocol 1: Stochastic this compound Conjugation using an NHS-Ester Linker-Payload
This protocol describes a general method for the stochastic conjugation of a drug to an antibody via an NHS-ester functionalized linker.
Materials:
-
Monoclonal antibody (mAb) in a suitable buffer (e.g., phosphate-buffered saline [PBS], pH 7.4)
-
NHS-ester functionalized linker-payload, dissolved in an organic solvent (e.g., dimethyl sulfoxide [DMSO] or N,N-dimethylacetamide [DMA])[15]
-
Conjugation buffer (e.g., 50 mM potassium phosphate, 50 mM NaCl, 2 mM EDTA, pH 8.0)[15]
-
Quenching solution (e.g., 1 M Tris-HCl, pH 8.0)
-
Purification system (e.g., size-exclusion chromatography [SEC] or tangential flow filtration [TFF])
-
Analytical instruments for characterization (e.g., UV-Vis spectrophotometer, mass spectrometer)
Procedure:
-
Antibody Preparation: Prepare the mAb at a concentration of 5-10 mg/mL in the conjugation buffer. Ensure the buffer is amine-free.
-
Linker-Payload Preparation: Dissolve the NHS-ester linker-payload in the organic solvent to a final concentration of 10-20 mM.
-
Conjugation Reaction: a. Add the linker-payload solution to the antibody solution with gentle mixing. The molar ratio of linker-payload to antibody will determine the average DAR and should be optimized (e.g., start with a 5-10 fold molar excess). b. Incubate the reaction mixture at room temperature or 4°C for 1-4 hours. The reaction time and temperature are critical parameters to control the extent of conjugation.
-
Quenching: Stop the reaction by adding a quenching solution (e.g., Tris-HCl) to a final concentration of 50-100 mM. This will react with any remaining NHS-ester.
-
Purification: Remove unconjugated linker-payload and organic solvent by purifying the ADC using SEC or TFF. The ADC is exchanged into a suitable formulation buffer (e.g., pH 6.5, 10 mM phosphate, 140 mM NaCl).[15]
-
Characterization: a. Concentration Measurement: Determine the protein concentration using a UV-Vis spectrophotometer at 280 nm. b. DAR Analysis: Determine the average DAR using methods such as UV-Vis spectroscopy (if the drug has a distinct absorbance) or mass spectrometry (hydrophobic interaction chromatography [HIC] or liquid chromatography-mass spectrometry [LC-MS]).[11] c. Aggregation Analysis: Assess the level of aggregation using SEC. d. Binding Affinity: Evaluate the antigen-binding affinity of the ADC using methods like ELISA or surface plasmon resonance (SPR).
Protocol 2: Determination of Drug-to-Antibody Ratio (DAR) by Mass Spectrometry
This protocol outlines the determination of the DAR of a this compound-conjugated ADC using intact mass analysis by LC-MS.
Materials:
-
Purified ADC sample
-
Denaturing solution (e.g., Guanidine-HCl) or deglycosylating enzyme (e.g., PNGase F)[11]
-
LC-MS system with a suitable column (e.g., reversed-phase C4)
-
Mass spectrometry data analysis software
Procedure:
-
Sample Preparation: a. For denaturing conditions, dilute the ADC sample in a denaturing solution. b. To simplify the mass spectrum, deglycosylate the ADC by incubating with PNGase F according to the manufacturer's protocol.[11]
-
LC-MS Analysis: a. Inject the prepared ADC sample onto the LC-MS system. b. Elute the ADC using a gradient of increasing organic solvent (e.g., acetonitrile with 0.1% formic acid). c. Acquire mass spectra in the appropriate mass range for the intact ADC.
-
Data Analysis: a. Deconvolute the raw mass spectra to obtain the zero-charge mass of each ADC species. b. Identify the peaks corresponding to the unconjugated antibody and the antibody conjugated with 1, 2, 3, etc., drug molecules. c. Calculate the relative abundance of each species from the peak intensities. d. Calculate the average DAR using the following formula: Average DAR = Σ(n * Iₙ) / Σ(Iₙ) where 'n' is the number of drugs conjugated and 'Iₙ' is the intensity of the corresponding peak.
Protocol 3: Identification of Conjugation Sites by Peptide Mapping
This protocol describes the identification of this compound conjugation sites using peptide mapping by LC-MS/MS.
Materials:
-
Purified ADC sample
-
Denaturation buffer (e.g., 8 M urea)
-
Reducing agent (e.g., dithiothreitol [DTT])
-
Alkylating agent (e.g., iodoacetamide [IAM])
-
Proteolytic enzyme (e.g., trypsin)
-
LC-MS/MS system with a suitable column (e.g., C18)
-
Peptide mapping data analysis software
Procedure:
-
Sample Preparation (Digestion): a. Denature the ADC sample in denaturation buffer. b. Reduce the disulfide bonds by adding DTT and incubating at 37°C. c. Alkylate the free cysteine residues by adding IAM and incubating in the dark. d. Dilute the sample to reduce the urea concentration and add trypsin. Trypsin cleaves at the C-terminal side of arginine and unconjugated this compound residues. Conjugated lysines will be resistant to cleavage.[12] e. Incubate overnight at 37°C to digest the protein.
-
LC-MS/MS Analysis: a. Inject the digested peptide mixture onto the LC-MS/MS system. b. Separate the peptides using a gradient of increasing organic solvent. c. Acquire MS and MS/MS spectra of the eluting peptides.
-
Data Analysis: a. Search the acquired MS/MS data against the antibody sequence using a database search engine. b. Specify the mass of the linker-payload as a variable modification on this compound residues. c. Identify the peptides containing the modification and pinpoint the specific this compound residue that is conjugated. d. The relative abundance of conjugated peptides can provide a semi-quantitative measure of the conjugation level at each site.[16]
Signaling Pathways and Mechanism of Action
The ultimate goal of an ADC is to deliver a cytotoxic payload to a cancer cell. The antibody component of the ADC binds to a specific antigen on the surface of the cancer cell. Following binding, the ADC-antigen complex is internalized, typically via endocytosis. The ADC is then trafficked to lysosomes, where the linker is cleaved (for cleavable linkers) or the antibody is degraded, releasing the cytotoxic payload into the cytoplasm. The payload then exerts its cell-killing effect, for example, by inhibiting microtubule assembly or causing DNA damage, ultimately leading to apoptosis.
Conclusion
This compound conjugation remains a cornerstone of ADC development due to its straightforward chemistry and the generation of stable conjugates. While the inherent heterogeneity of stochastically conjugated ADCs presents challenges, rigorous analytical characterization and process optimization can lead to the development of effective therapeutics. The ongoing development of site-specific this compound conjugation technologies promises to further enhance the precision and therapeutic potential of this important class of anti-cancer drugs. These application notes and protocols provide a foundational guide for researchers and developers working in the exciting field of antibody-drug conjugates.
References
- 2. Site-selective this compound conjugation methods and applications towards antibody–drug conjugates - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Site-selective this compound conjugation methods and applications towards antibody–drug conjugates - Chemical Communications (RSC Publishing) [pubs.rsc.org]
- 4. Site-specific conjugation of native antibody - PMC [pmc.ncbi.nlm.nih.gov]
- 5. This compound based Conjugation Strategy - Creative Biolabs [creative-biolabs.com]
- 6. aboligo.com [aboligo.com]
- 7. researchgate.net [researchgate.net]
- 8. Site-selective this compound conjugation methods and applications towards antibody–drug conjugates - Chemical Communications (RSC Publishing) DOI:10.1039/D1CC03976H [pubs.rsc.org]
- 10. pubs.acs.org [pubs.acs.org]
- 11. In-Depth Comparison of this compound-Based Antibody-Drug Conjugates Prepared on Solid Support Versus in Solution | MDPI [mdpi.com]
- 12. In-Depth Comparison of this compound-Based Antibody-Drug Conjugates Prepared on Solid Support Versus in Solution - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Field Guide to Challenges and Opportunities in Antibody-Drug Conjugates for Chemists - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Recent developments in chemical conjugation strategies targeting native amino acids in proteins and their applications in antibody–drug conjugates - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Conjugation Based on this compound Residues - Creative Biolabs [creative-biolabs.com]
- 16. discovery.researcher.life [discovery.researcher.life]
Techniques for Site-Specific Ubiquitination of Lysine Residues: Application Notes and Protocols
For Researchers, Scientists, and Drug Development Professionals
This document provides a detailed overview of current techniques for achieving site-specific ubiquitination of lysine residues on target proteins. Understanding and controlling this crucial post-translational modification is paramount for elucidating cellular signaling pathways and developing novel therapeutics. These application notes cover enzymatic, chemoenzymatic, and chemical methods, offering insights into their principles, advantages, and limitations. Detailed protocols for key experiments are provided to facilitate their implementation in a research setting.
Introduction to Ubiquitination
Ubiquitination is a fundamental post-translational modification in eukaryotic cells, involving the covalent attachment of the 76-amino acid protein ubiquitin to a substrate protein.[1][2] This process is orchestrated by a three-enzyme cascade: a ubiquitin-activating enzyme (E1), a ubiquitin-conjugating enzyme (E2), and a ubiquitin ligase (E3).[1][3] The E3 ligase is responsible for recognizing the specific substrate and catalyzing the transfer of ubiquitin from the E2 to a this compound residue on the target protein, forming an isopeptide bond.[1][4] The ability to generate proteins with ubiquitin attached to a specific this compound residue is a powerful tool for studying the functional consequences of this modification.
Core Methodologies for Site-Specific Ubiquitination
Several powerful techniques have been developed to achieve site-specific ubiquitination, each with its own set of strengths and applications. The choice of method often depends on the target protein, the desired yield, and the specific research question.
Enzymatic Ubiquitination using Recombinant E3 Ligases
This method leverages the inherent specificity of the natural ubiquitination machinery. By using purified recombinant E1, E2, and a specific E3 ligase, ubiquitin can be directed to a known this compound residue on a target protein. This approach is advantageous for studying the natural ubiquitination process of a protein. However, a major limitation is the requirement for a specific E3 ligase for the target protein and this compound site, which may not always be known or readily available.[1][2] The catalytic efficiency of some E3 ligases can also be low, impacting yields.[1][2]
Chemoenzymatic Ligation: this compound Acylation using Conjugating Enzymes (LACE)
LACE is a powerful chemoenzymatic method that allows for the site-specific modification of internal this compound residues within a folded protein.[5][6] This technique utilizes the E2 SUMO-conjugating enzyme, Ubc9, which recognizes a minimal four-residue genetic tag (ΨKXD/E, where Ψ is a hydrophobic residue) engineered into the target protein.[1] Ubc9 then catalyzes the transfer of a ubiquitin-thioester to the this compound residue within this tag, forming a native isopeptide bond.[5][6] A key advantage of LACE is that it bypasses the need for E1 and E3 enzymes, offering greater control and broader applicability.[6]
Chemical Ligation: Native Chemical Ligation (NCL)
Native Chemical Ligation (NCL) is a robust chemical method for synthesizing proteins by joining two unprotected peptide fragments.[7][8][9][10] For site-specific ubiquitination, a synthetic peptide containing the target this compound residue is ligated to a recombinantly expressed ubiquitin C-terminal thioester. The reaction occurs between the N-terminal cysteine of one peptide and the C-terminal thioester of the other, resulting in the formation of a native peptide bond.[7][10] This method allows for the precise installation of ubiquitin at any desired this compound site and can be used to generate ubiquitinated proteins in large quantities. However, it requires expertise in peptide synthesis and protein chemistry.
Orthogonal Ubiquitin Transfer (OUT)
Orthogonal Ubiquitin Transfer (OUT) is a sophisticated protein engineering approach that enables the identification of substrates for a specific E3 ligase within a cellular context.[11][12][13][14] This system involves engineering a mutant ubiquitin (xUB) and a corresponding set of engineered E1, E2, and E3 enzymes (xE1, xE2, xE3) that are mutually specific and do not cross-react with their wild-type counterparts.[11][12][13] By expressing this orthogonal cascade in cells, the engineered ubiquitin is exclusively transferred to the substrates of the engineered E3 ligase, allowing for their specific identification and characterization.[13]
Quantitative Comparison of Site-Specific Ubiquitination Techniques
The following table summarizes the key features of the described techniques to aid in the selection of the most appropriate method for a given application.
| Technique | Principle | Specificity Determinant | Yield | Key Advantages | Key Disadvantages |
| Enzymatic (E3 Ligase) | Reconstitution of the natural E1-E2-E3 cascade with a specific E3 ligase.[1][15] | E3 ligase-substrate recognition.[1][16] | Variable, often low to moderate.[1][2] | Studies the natural ubiquitination process; generates native isopeptide bonds. | Requires a known and active E3 ligase for the target site; can have low catalytic efficiency.[1][2] |
| Chemoenzymatic (LACE) | Ubc9 E2 enzyme recognizes a small genetic tag and transfers a ubiquitin-thioester.[5][6] | Genetically encoded recognition tag (e.g., IKQE). | Moderate to high. | Bypasses the need for E1 and E3 enzymes; high specificity; works on folded proteins.[6] | Requires genetic engineering of the target protein to include the recognition tag. |
| Chemical (NCL) | Chemical ligation of a synthetic peptide containing the target this compound with a ubiquitin-thioester.[7][8][9] | Precise chemical synthesis of peptide fragments. | High. | Precise control over the ubiquitination site; can generate large quantities of ubiquitinated protein.[7] | Requires expertise in peptide synthesis and chemical ligation; may require protein refolding. |
| Orthogonal Ubiquitin Transfer (OUT) | Engineered, mutually specific ubiquitin and E1-E2-E3 enzymes that function orthogonally to the native system.[11][12][13] | Engineered enzyme-substrate pairs.[11][13] | N/A (primarily for substrate identification). | Enables identification of E3 ligase substrates in a cellular context; high specificity.[13] | Technically challenging to engineer the orthogonal components; primarily a discovery tool. |
Experimental Protocols
Protocol 1: In Vitro Enzymatic Site-Specific Ubiquitination
This protocol provides a general framework for the site-specific ubiquitination of a target protein using a recombinant E3 ligase.
Materials:
-
Recombinant Human Ubiquitin Activating Enzyme (E1)
-
Recombinant Human E2 conjugating enzyme (specific for the chosen E3)
-
Recombinant E3 ubiquitin ligase (specific for the target protein and this compound site)
-
Recombinant target protein with a single accessible this compound or a mutant with a single target this compound
-
Wild-type Ubiquitin
-
10X Ubiquitination Reaction Buffer (e.g., 500 mM HEPES pH 7.5, 250 mM MgCl₂, 50 mM DTT)
-
10 mM ATP solution
-
SDS-PAGE loading buffer
-
Deionized water
Procedure:
-
On ice, prepare a 25 µL reaction mixture in a microcentrifuge tube by adding the following components in the order listed:
-
Deionized water to a final volume of 25 µL
-
2.5 µL of 10X Ubiquitination Reaction Buffer
-
1 µL of target protein (to a final concentration of 1-5 µM)
-
1 µL of E1 enzyme (to a final concentration of 50-100 nM)
-
1 µL of E2 enzyme (to a final concentration of 0.5-2 µM)
-
1 µL of E3 ligase (concentration to be optimized, typically 0.1-1 µM)
-
2 µL of Ubiquitin (to a final concentration of 10-50 µM)
-
-
Initiate the reaction by adding 2.5 µL of 10 mM ATP solution.
-
Mix gently by pipetting and incubate the reaction at 37°C for 1-2 hours.
-
Stop the reaction by adding 10 µL of 4X SDS-PAGE loading buffer and boiling at 95°C for 5 minutes.
-
Analyze the reaction products by SDS-PAGE followed by Coomassie staining or Western blotting using antibodies against the target protein or ubiquitin. A successful reaction will show higher molecular weight bands corresponding to the ubiquitinated target protein.
Protocol 2: this compound Acylation using Conjugating Enzymes (LACE)
This protocol outlines the steps for site-specific ubiquitination of a target protein containing a LACE recognition tag.
Materials:
-
Target protein containing a LACE tag (e.g., IKQE)
-
Recombinant Ubc9 enzyme
-
Ubiquitin C-terminal thioester (e.g., ubiquitin-MESNa)
-
LACE Reaction Buffer (e.g., 50 mM HEPES pH 7.5, 150 mM NaCl, 1 mM TCEP)
-
SDS-PAGE loading buffer
-
Deionized water
Procedure:
-
Prepare the ubiquitin-thioester. This can be synthesized chemically or expressed recombinantly.
-
In a microcentrifuge tube, combine the following components:
-
Target protein with LACE tag (to a final concentration of 10-50 µM)
-
Ubc9 enzyme (to a final concentration of 1-5 µM)
-
Ubiquitin-thioester (to a final concentration of 100-500 µM)
-
LACE Reaction Buffer to the final desired volume.
-
-
Incubate the reaction at 37°C for 2-16 hours. The reaction progress can be monitored by taking time points.
-
Terminate the reaction by adding SDS-PAGE loading buffer and heating at 95°C for 5 minutes.
-
Analyze the products by SDS-PAGE and Coomassie staining or Western blotting. The appearance of a higher molecular weight band corresponding to the ubiquitinated target protein indicates a successful reaction.
Visualizations
Caption: The Ubiquitin-E3 Ligase Signaling Pathway.
Caption: Experimental Workflow for In Vitro Enzymatic Ubiquitination.
Caption: Logical Comparison of Site-Specific Ubiquitination Techniques.
References
- 1. Chemical methods for protein site-specific ubiquitination - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Chemical methods for protein site-specific ubiquitination - RSC Chemical Biology (RSC Publishing) [pubs.rsc.org]
- 3. The Chemical Biology of Ubiquitin - PMC [pmc.ncbi.nlm.nih.gov]
- 4. portal.fis.tum.de [portal.fis.tum.de]
- 5. This compound acylation using conjugating enzymes for site-specific modification and ubiquitination of recombinant proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. vanderbilt.edu [vanderbilt.edu]
- 7. scispace.com [scispace.com]
- 8. Native Chemical Ligation of Peptides and Proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Native chemical ligation - Wikipedia [en.wikipedia.org]
- 10. Orthogonal Ubiquitin Transfer through Engineered E1-E2 Cascades for Protein Ubiquitination - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Orthogonal ubiquitin transfer through engineered E1-E2 cascades for protein ubiquitination - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Identifying the ubiquitination targets of E6AP by orthogonal ubiquitin transfer - PMC [pmc.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. Simple Protocol for In Vitro Ubiquitin Conjugation: R&D Systems [rndsystems.com]
- 15. Site-specific ubiquitination: Deconstructing the degradation tag - PMC [pmc.ncbi.nlm.nih.gov]
- 16. chemrxiv.org [chemrxiv.org]
Application Notes & Protocols: Lysine-Based Hydrogel Formation for Tissue Engineering
Audience: Researchers, scientists, and drug development professionals.
Introduction: Lysine, an essential amino acid, serves as a fundamental building block for a versatile class of hydrogels with significant promise for tissue engineering and regenerative medicine.[1] These hydrogels are highly valued for their inherent biocompatibility, biodegradability, and tunable physicochemical properties that can mimic the native extracellular matrix (ECM).[2][3] Their three-dimensional, highly hydrated networks provide an ideal microenvironment to support cell growth, proliferation, and differentiation.[4] this compound-based hydrogels can be formed through various mechanisms, including self-assembly, chemical crosslinking, and enzymatic reactions, allowing for the creation of scaffolds with tailored mechanical strength, degradation rates, and porosity to meet the demands of specific tissue engineering applications, from corneal repair to bone regeneration.[5][6][7]
Hydrogel Formation Mechanisms
The versatility of this compound-based hydrogels stems from the variety of methods available for their formation. The primary amine groups within the this compound structure are key to these crosslinking strategies.
-
Self-Assembly: Certain this compound derivatives, such as Lauroyl this compound, can self-assemble into hydrogels through non-covalent interactions like hydrogen bonding and hydrophobic interactions.[2] This process creates a nanofibrous network that physically entraps water, forming a stable gel structure without the need for chemical crosslinkers.[2]
-
Chemical Crosslinking: Covalent bonds can be formed to create more robust and stable hydrogel networks. Common methods include:
-
Carbodiimide Chemistry: Poly-ε-lysine can be crosslinked with bis-carboxylic acids using agents like 1-Ethyl-3-(3-dimethylaminopropyl)carbodiimide (EDC) in the presence of N-hydroxysuccinimide (NHS).[5][8]
-
Schiff Base Formation: Dynamic and reversible hydrogels can be formed via imine bond formation between the amine groups of this compound and aldehyde groups on another polymer, such as dialdehyde-functionalized polyethylene glycol (PEG).[3][9]
-
Dendrimer/Dendrigraft Crosslinking: Poly-L-lysine dendrigrafts (DGL) possess a high density of terminal amines, allowing them to act as multifunctional crosslinkers with polymers like dicarboxylic-acid PEG, forming stable amide networks.[10][11]
-
-
Enzymatic Crosslinking: Biocatalytic reactions offer a highly specific and biocompatible method for hydrogel formation under physiological conditions.[12] Enzymes like transglutaminase (TG) can catalyze the formation of an amide bond between the ε-amino group of this compound and a glutamine residue.[13] Similarly, oxidases such as lysyl oxidase can be used to facilitate covalent bond formation between this compound-rich molecules.[12][14]
Quantitative Data Summary
The properties of this compound-based hydrogels can be precisely tuned by altering the precursor concentration, crosslinker type, and crosslinking density.
Table 1: Mechanical Properties of Various this compound-Based Hydrogels
| Hydrogel Composition | Crosslinking Method | Property Measured | Value | Source |
|---|---|---|---|---|
| Poly-ε-lysine (pεK) & bis-carboxylic acids | Carbodiimide | Compressive Modulus | 0.05 - 0.65 MPa | [15] |
| Poly-ε-lysine (pεK) & bis-carboxylic acids | Carbodiimide | Tensile Modulus | 20 - 160 kPa | [15] |
| DGL G5 & dicarboxylic acid–PEG | Amide bond formation | Young's Modulus (E) | 8 - >30 kPa | [11] |
| DGL G5 & dicarboxylic acid–PEG | Amide bond formation | Surface E (AFM) | ~15 - >100 kPa | [11] |
| Acrylamide & Methacrylated this compound (LysMA) | Covalent | Tensile Stress | 18.9 ± 2.1 kPa | [4] |
| Acrylamide & Methacrylated this compound (LysMA) | Covalent | Strain at Break | up to 2600% | [4] |
| l-lysine-based dipeptides | Self-assembly | Storage Modulus (G') | > Loss Modulus (G'') |[16][17] |
Table 2: Biocompatibility and Cellular Response
| Hydrogel System | Cell Type | Assay | Result | Source |
|---|---|---|---|---|
| Hyaluronic acid & l-Lysine | Normal Human Dermal Fibroblasts (NHDF) | Live/Dead Staining | Excellent biocompatibility, viable cells with good morphology after 144h. | [8] |
| Poly-ε-lysine & PEG (RGD-functionalized) | Fibroblasts | Metabolic Activity | High metabolic activity and cell proliferation observed. | [3] |
| l-lysine-based dipeptides | Human Embryonic Kidney (HEK 293) | MTT Assay | Hydrogels are compatible with HEK 293 cells. | [16] |
| Poly-ε-lysine (pεK) | Human Corneal Endothelial Cells (HCEC-12) | Cell Culture | Cells attached and grew as confluent monolayers after 7 days. | [18] |
| Poly-ε-lysine (pεK) with RGD | Primary Porcine Corneal Endothelial Cells | Cell Culture | Enhanced cell adhesion and formation of confluent monolayers. |[18] |
Diagrams and Visualizations
Experimental Workflow
The following diagram outlines a typical workflow for the fabrication and analysis of cell-laden this compound-based hydrogels for tissue engineering applications.
Caption: Workflow for this compound hydrogel synthesis, cell encapsulation, and analysis.
Crosslinking Strategies
This compound's amine groups are central to various crosslinking methods used to form stable hydrogel networks.
Caption: Overview of crosslinking strategies for this compound-based hydrogels.
Cell-Hydrogel Interaction Signaling
Functionalizing this compound hydrogels with peptides like RGD promotes cell adhesion through specific signaling pathways.
Caption: Simplified RGD-Integrin signaling for cell adhesion to hydrogels.
Detailed Experimental Protocols
Protocol 1: Synthesis of Poly-ε-Lysine (pεK) Hydrogel via Carbodiimide Chemistry
This protocol is adapted from methodologies for creating pεK hydrogels for corneal tissue engineering.[5][15]
Materials:
-
Poly-ε-lysine (pεK)
-
Bis-carboxylic acid crosslinker (e.g., Octanedioic acid)
-
1-Ethyl-3-(3-dimethylaminopropyl)carbodiimide (EDC)
-
N-hydroxysuccinimide (NHS)
-
Phosphate-buffered saline (PBS), pH 7.4
-
Deionized water
Procedure:
-
Precursor Solution: Prepare a pεK solution at the desired concentration (e.g., 0.07-0.13 g/cm³) in deionized water.
-
Crosslinker Solution: Separately, prepare a solution of the bis-carboxylic acid crosslinker in deionized water.
-
Activation: Add EDC and NHS to the crosslinker solution to activate the carboxylic acid groups. The molar ratio of EDC/NHS to carboxylic acid groups should be optimized, often starting at 2:1 or 1:1.
-
Mixing and Gelation: Combine the activated crosslinker solution with the pεK solution. Mix thoroughly but gently to avoid introducing air bubbles.
-
Casting: Cast the mixture into a mold of the desired shape and thickness (e.g., between two glass plates with a spacer).
-
Curing: Allow the hydrogel to polymerize at room temperature or 37°C for a specified time (typically several hours to overnight) until a stable gel is formed.
-
Purification: After gelation, immerse the hydrogel in a large volume of PBS or deionized water for 2-5 days, changing the solution daily, to remove unreacted chemicals and byproducts.[8]
Protocol 2: Hydrogel Formation and Cell Encapsulation
This protocol describes a general method for encapsulating cells within a this compound-based hydrogel matrix during its formation.[2]
Materials:
-
Sterile this compound-based hydrogel precursor solution (prepared as in Protocol 1, step 1, and filter-sterilized)
-
Sterile crosslinker solution (filter-sterilized)
-
Cells of interest, suspended in sterile serum-free culture medium
-
Sterile multi-well culture plates
Procedure:
-
Cell Preparation: Harvest cells using standard trypsinization, count them, and resuspend the cell pellet in a small volume of serum-free medium to achieve a high cell density (e.g., 1 x 10⁶ to 1 x 10⁷ cells/mL).
-
Pre-Gel Mixture: In a sterile environment (e.g., a biosafety cabinet), gently mix the sterile precursor solution with the cell suspension. Ensure even distribution of cells without causing shear stress.
-
Initiate Gelation: Add the sterile crosslinker solution to the cell-precursor mixture. The final concentration of all components should be calculated based on the desired hydrogel properties and cell density.
-
Dispensing: Immediately but gently pipette the final mixture into the wells of a culture plate. The volume will determine the final thickness of the cell-laden construct.
-
Incubation for Gelation: Place the culture plate in a cell culture incubator (37°C, 5% CO₂) to allow hydrogelation to complete. Gelation time can range from minutes to hours depending on the specific chemistry.
-
Culture: After the hydrogel has solidified, carefully add pre-warmed complete cell culture medium to each well. Culture the constructs under standard conditions, changing the medium every 2-3 days.[2]
Protocol 3: Characterization of Mechanical Properties via Oscillatory Rheology
This protocol outlines the steps to measure the viscoelastic properties (Storage Modulus G' and Loss Modulus G'') of the hydrogel.[16][19]
Equipment:
-
Rheometer with a parallel plate geometry (e.g., 20 mm diameter)
Procedure:
-
Sample Preparation: Prepare a hydrogel sample of a defined thickness (e.g., 1-2 mm) and diameter, either by casting it directly on the rheometer's lower plate or by cutting a disk from a larger hydrogel slab.
-
Loading: Carefully place the sample on the lower plate of the rheometer. Lower the upper plate to the desired gap distance (e.g., 500 µm), ensuring the sample is not over-compressed. A solvent trap should be used to prevent dehydration during the measurement.
-
Strain Sweep: Perform an oscillatory strain sweep at a constant frequency (e.g., 1 Hz) to determine the linear viscoelastic region (LVER). This is the range of strain where G' and G'' are independent of the applied strain.
-
Frequency Sweep: Select a strain value within the LVER determined in the previous step. Perform a frequency sweep (e.g., from 0.1 to 100 Hz) at this constant strain.
-
Data Analysis: Record the storage modulus (G'), which represents the elastic component, and the loss modulus (G''), which represents the viscous component. For a stable gel, G' should be significantly larger than G'' and relatively independent of frequency.[17]
Protocol 4: In Vitro Biocompatibility Assessment (Live/Dead Assay)
This protocol provides a method to visualize the viability of cells encapsulated within the hydrogel.[8]
Materials:
-
Cell-laden hydrogels in a culture plate
-
Live/Dead™ Viability/Cytotoxicity Kit (containing Calcein AM and Ethidium homodimer-1)
-
Phosphate-buffered saline (PBS)
-
Fluorescence microscope
Procedure:
-
Preparation of Staining Solution: Prepare the staining solution by diluting Calcein AM (stains live cells green) and Ethidium homodimer-1 (stains dead cells red) in PBS according to the manufacturer's instructions.
-
Staining: Remove the culture medium from the cell-laden hydrogels and wash them gently with PBS.
-
Incubation: Add enough staining solution to each well to completely cover the hydrogel. Incubate the plate at 37°C for 30-45 minutes, protected from light.
-
Imaging: After incubation, carefully remove the staining solution and replace it with fresh PBS.
-
Microscopy: Immediately visualize the hydrogels using a fluorescence microscope with appropriate filters for green (live cells) and red (dead cells) fluorescence. Acquire images from multiple representative regions of the hydrogel.
-
Quantification (Optional): Use image analysis software (e.g., ImageJ) to count the number of live and dead cells to calculate the percentage of cell viability.
References
- 1. This compound-Triggered Polymeric Hydrogels with Self-Adhesion, Stretchability, and Supportive Properties - PMC [pmc.ncbi.nlm.nih.gov]
- 2. benchchem.com [benchchem.com]
- 3. mdpi.com [mdpi.com]
- 4. This compound-Triggered Polymeric Hydrogels with Self-Adhesion, Stretchability, and Supportive Properties [mdpi.com]
- 5. Characterization of Tunable Poly-ε-Lysine-Based Hydrogels for Corneal Tissue Engineering - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Enzyme-induced dual-network ε-poly-l-lysine-based hydrogels with robust self-healing and antibacterial performance - Chemical Communications (RSC Publishing) [pubs.rsc.org]
- 7. Biomaterials | COLCOM [colcom.eu]
- 8. mdpi.com [mdpi.com]
- 9. research.rug.nl [research.rug.nl]
- 10. Bioactive hydrogels based on this compound dendrigrafts as crosslinkers: tailoring elastic properties to influence hMSC osteogenic differentiation - Journal of Materials Chemistry B (RSC Publishing) DOI:10.1039/D4TB01578A [pubs.rsc.org]
- 11. Bioactive hydrogels based on this compound dendrigrafts as crosslinkers: tailoring elastic properties to influence hMSC osteogenic differentiation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. preprints.org [preprints.org]
- 13. encyclopedia.pub [encyclopedia.pub]
- 14. researchgate.net [researchgate.net]
- 15. researchgate.net [researchgate.net]
- 16. This compound-based non-cytotoxic ultrashort self-assembling peptides with antimicrobial activity - PMC [pmc.ncbi.nlm.nih.gov]
- 17. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
- 18. Poly-ε-lysine based hydrogels as synthetic substrates for the expansion of corneal endothelial cells for transplantation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. Enhancement of the mechanical properties of this compound-containing peptide-based supramolecular hydrogels by chemical cross-linking - Soft Matter (RSC Publishing) DOI:10.1039/D1SM01136G [pubs.rsc.org]
Application Notes and Protocols for Utilizing Lysine Derivatives in Drug Discovery and Development
For Researchers, Scientists, and Drug Development Professionals
Introduction
Lysine, an essential amino acid, is a cornerstone of protein structure and function. Its ε-amino group is a hub for a multitude of post-translational modifications (PTMs), including acetylation, methylation, ubiquitination, and sumoylation. These modifications are critical for regulating protein stability, localization, and interaction with other molecules, thereby governing a vast array of cellular processes. The enzymes that catalyze and reverse these modifications—writers, erasers, and readers of the "this compound code"—have emerged as pivotal targets in drug discovery. Dysregulation of these enzymatic activities is frequently implicated in the pathogenesis of numerous diseases, including cancer, neurodegenerative disorders, and inflammatory conditions.[1][2][3]
This document provides detailed application notes and experimental protocols for the utilization of various classes of this compound derivatives in drug discovery and development. These derivatives serve as powerful tools to probe and modulate the activity of this compound-modifying enzymes and to engineer novel therapeutic modalities.
Key Applications of this compound Derivatives in Drug Discovery
This compound derivatives have found broad applications across several therapeutic areas. Key strategies include:
-
Enzyme Inhibition: Small molecule inhibitors targeting this compound-modifying enzymes are a major focus of drug development. These inhibitors can restore normal cellular function by correcting aberrant epigenetic marks or protein activity.
-
Targeted Protein Degradation: Proteolysis-targeting chimeras (PROTACs) are bifunctional molecules that recruit a target protein to an E3 ubiquitin ligase, leading to the target's degradation. This compound residues on the target protein are often the sites of ubiquitination.[4][5]
-
Antibody-Drug Conjugates (ADCs): The surface-exposed this compound residues of antibodies are commonly used for the conjugation of cytotoxic payloads, creating highly targeted cancer therapies.[6][7]
-
Antiviral Therapy: this compound and its derivatives have been shown to interfere with viral replication, suggesting their potential as broad-spectrum antiviral agents.[8][9]
Application Note 1: Inhibitors of this compound-Modifying Enzymes
A primary strategy in leveraging this compound derivatives is the development of inhibitors for the enzymes that regulate this compound PTMs. These can be broadly categorized into inhibitors of this compound methyltransferases (KMTs), this compound demethylases (KDMs), this compound acetyltransferases (KATs), and this compound deacetylases (KDACs).
This compound Methyltransferase (KMT) and Demethylase (KDM) Inhibitors
This compound methylation is a key regulator of gene expression and protein function.[10] Aberrant methylation patterns are a hallmark of many cancers.[11]
Table 1: Selected KMT and KDM Inhibitors and their Potency
| Inhibitor | Target(s) | IC50/Ki | Disease Area | Reference(s) |
| KMT Inhibitors | ||||
| UNC0638 | G9a/GLP | < 15 nM (G9a), 19 nM (GLP) | Cancer | [12][13] |
| EPZ004777 | DOT1L | 0.4 nM | Leukemia | [14] |
| CPI-1205 | EZH2 | 2 nM | B-cell Lymphoma | [12][13] |
| GSK343 | EZH2 | 1.2 nM (Ki app) | Cancer (in vitro tool) | [12] |
| KDM Inhibitors | ||||
| Compound 19 | LSD1 | 0.89 µM | Cancer | [15] |
| CC-90011 | LSD1 | 0.3 nM | Cancer | [15] |
Methylation of this compound 27 on histone H3 (H3K27me) is a critical epigenetic mark associated with gene repression.[16] Its levels are tightly regulated by the opposing activities of the Polycomb Repressive Complex 2 (PRC2), which contains the methyltransferase EZH2, and the demethylases UTX and JMJD3.[16] Mutations or overexpression of EZH2, or inactivation of UTX, can lead to aberrant H3K27 methylation and oncogenesis.[16]
This compound Acetyltransferase (KAT) and Deacetylase (KDAC) Inhibitors
This compound acetylation, controlled by KATs and KDACs, is another crucial PTM regulating gene expression and protein function.[1][2] Dysregulation of acetylation is implicated in cancer and neurodegenerative diseases.[3][15][17]
Table 2: Selected KAT and KDAC Inhibitors and their Potency
| Inhibitor | Target(s) | IC50 | Disease Area | Reference(s) |
| KAT Inhibitors | ||||
| A-485 | p300/CBP | Low nanomolar | Cancer, Endocrinology | [18] |
| KDAC Inhibitors | ||||
| Vorinostat (SAHA) | Pan-HDAC | - | Cutaneous T-cell lymphoma | [19] |
| Romidepsin | Class I HDACs | - | Cutaneous T-cell lymphoma | [19] |
| Entinostat | Class I HDACs | - | Cancer | [20] |
In neurodegenerative diseases, there is often an imbalance in this compound acetylation. For instance, in Parkinson's disease, exposure to neurotoxins like MPTP can lead to histone hyperacetylation by decreasing the levels of certain HDACs.[21] Conversely, pathogenic proteins like α-synuclein can cause histone hypoacetylation.[21] This dysregulation of gene expression contributes to neuronal dysfunction and death.
Application Note 2: PROTACs Targeting Proteins for Degradation
PROTACs represent a paradigm shift from occupancy-driven inhibition to event-driven pharmacology. They induce the degradation of a target protein of interest (POI) by hijacking the cell's ubiquitin-proteasome system.[4]
Table 3: Example of a PROTAC and its Efficacy
| PROTAC | Target | Degrader Concentration (DC50) | E3 Ligase Recruited | Reference(s) |
| B14 | PI3Kδ | 3.98 nM | VHL | [22][23] |
Validating the efficacy of a PROTAC requires a multi-faceted approach to confirm target degradation and specificity.[4] A typical workflow involves treating cells with the PROTAC, followed by analysis of protein levels.
Experimental Protocols
Protocol 1: In Vitro Histone Acetyltransferase (HAT) Inhibitor Screening Assay (Fluorescence-Based)
This protocol describes a non-radioactive, fluorescence-based assay to measure HAT activity and its inhibition by test compounds. The assay detects the co-product of the acetylation reaction, coenzyme A (CoA-SH).[19][24]
Materials:
-
Recombinant HAT enzyme (e.g., PCAF)
-
Histone peptide substrate (e.g., Histone H3 peptide)
-
Acetyl-Coenzyme A (Acetyl-CoA)
-
Test inhibitor (e.g., Thiazole derivative)
-
HAT Assay Buffer
-
HAT Stop Reagent (Isopropanol)
-
HAT Developer (e.g., 7-diethylamino-3-(4'-maleimidylphenyl)-4-methylcoumarin - CPM)
-
96-well black microplate
-
Fluorescence microplate reader
Procedure:
-
Reagent Preparation:
-
Prepare 1X HAT Assay Buffer from a stock solution.
-
Dilute the HAT enzyme to the desired working concentration in 1X HAT Assay Buffer on ice.
-
Reconstitute the histone peptide to a stock concentration and dilute to the working concentration in 1X Assay Buffer.
-
Prepare a stock solution of Acetyl-CoA and dilute to the working concentration in 1X Assay Buffer.
-
Prepare a stock solution of the test inhibitor in DMSO and create a serial dilution.
-
Prepare the HAT Developer solution immediately before use.
-
-
Assay Plate Setup (in triplicate):
-
100% Activity Control Wells: Add 15 µL of 1X Assay Buffer, 5 µL of Acetyl-CoA, 10 µL of diluted HAT enzyme, and 5 µL of DMSO.
-
Inhibitor Wells: Add 15 µL of 1X Assay Buffer, 5 µL of Acetyl-CoA, 10 µL of diluted HAT enzyme, and 5 µL of the inhibitor at various concentrations.
-
Background Wells: Add 15 µL of 1X Assay Buffer, 5 µL of Acetyl-CoA, 10 µL of diluted HAT enzyme, and 5 µL of DMSO. The histone peptide will be added after the stop reagent.
-
-
Reaction:
-
Initiate the reaction by adding 20 µL of the Histone Peptide solution to all wells except the background wells.
-
Cover the plate and incubate at 37°C for 30 minutes.
-
-
Stopping and Development:
-
Add 50 µL of HAT Stop Reagent to all wells.
-
Add 20 µL of the Histone Peptide solution to the background wells only.
-
Add 100 µL of the diluted HAT Developer to all wells.
-
Cover the plate and incubate at room temperature for 20 minutes, protected from light.
-
-
Measurement:
-
Read the fluorescence intensity using a microplate reader (e.g., excitation at 360-390 nm and emission at 450-470 nm).
-
-
Data Analysis:
-
Subtract the average fluorescence of the background wells from all other readings.
-
Calculate the percent inhibition for each inhibitor concentration relative to the 100% activity control.
-
Plot the percent inhibition versus the inhibitor concentration to determine the IC50 value.
-
Protocol 2: Western Blot Analysis of Histone Modifications
This protocol details the detection of changes in specific histone modifications (e.g., H3K9me2) in cells treated with a this compound-modifying enzyme inhibitor.[25][26]
Materials:
-
Cultured cells (e.g., MOLT-16)
-
Test inhibitor (e.g., A-366 for G9a/GLP)
-
Cell lysis buffer
-
Acid extraction buffer (0.2 N HCl)
-
Neutralization buffer (1 M Tris-HCl, pH 8.0)
-
Protein assay reagent (e.g., BCA)
-
SDS-PAGE gels and running buffer
-
Transfer buffer and PVDF or nitrocellulose membrane
-
Blocking buffer (e.g., 5% BSA in TBST)
-
Primary antibodies (e.g., anti-H3K9me2 and anti-total H3)
-
HRP-conjugated secondary antibody
-
Chemiluminescent substrate (ECL)
-
Imaging system
Procedure:
-
Cell Treatment and Harvesting:
-
Seed cells and allow them to adhere or grow to the desired confluency.
-
Treat cells with various concentrations of the inhibitor or vehicle (DMSO) for the desired time (e.g., 72 hours).
-
Harvest the cells by centrifugation.
-
-
Histone Extraction:
-
Wash the cell pellet with PBS.
-
Lyse the cells and isolate the nuclei.
-
Resuspend the nuclear pellet in 0.2 N HCl and incubate overnight at 4°C with rotation to extract histones.
-
Centrifuge to pellet debris and collect the supernatant containing the histones.
-
Neutralize the histone extract with Tris-HCl.
-
-
Protein Quantification:
-
Determine the protein concentration of the histone extracts using a BCA assay.
-
-
SDS-PAGE and Western Blotting:
-
Prepare protein samples with LDS sample buffer and heat at 95°C for 5 minutes.
-
Load equal amounts of protein per lane onto an SDS-PAGE gel and perform electrophoresis.
-
Transfer the separated proteins to a membrane.
-
Block the membrane with blocking buffer for 1 hour at room temperature.
-
Incubate the membrane with the primary antibody (e.g., anti-H3K9me2) overnight at 4°C.
-
Wash the membrane with TBST.
-
Incubate with the HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Wash the membrane again with TBST.
-
For a loading control, strip the membrane and re-probe with an anti-total H3 antibody, or run a parallel gel.
-
-
Detection and Analysis:
-
Apply the chemiluminescent substrate and capture the signal using an imaging system.
-
Quantify the band intensities and normalize the signal of the modified histone to the total histone signal.
-
Protocol 3: this compound Conjugation for Antibody-Drug Conjugate (ADC) Formation
This protocol describes a general method for conjugating a drug-linker complex to the this compound residues of an antibody using an N-hydroxysuccinimide (NHS) ester.[14][][28]
Materials:
-
Monoclonal antibody (mAb) in a suitable buffer (e.g., PBS)
-
Drug-linker complex with an NHS ester reactive group
-
Reaction buffer (e.g., borate buffer, pH 8.5)
-
Quenching solution (e.g., Tris or this compound solution)
-
Purification system (e.g., size-exclusion chromatography - SEC)
-
Characterization instruments (e.g., UV-Vis spectrophotometer, mass spectrometer)
Procedure:
-
Antibody Preparation:
-
Buffer exchange the mAb into the reaction buffer to remove any primary amine-containing substances.
-
Adjust the mAb concentration to a suitable level (e.g., 5-10 mg/mL).
-
-
Conjugation Reaction:
-
Dissolve the drug-linker-NHS ester in a compatible organic solvent (e.g., DMSO).
-
Add the desired molar excess of the drug-linker solution to the antibody solution with gentle mixing.
-
Incubate the reaction at room temperature or 4°C for a specified time (e.g., 1-4 hours). The reaction conditions (pH, temperature, time, and molar ratio) should be optimized to achieve the desired drug-to-antibody ratio (DAR).
-
-
Quenching the Reaction:
-
Add a quenching solution to stop the reaction by consuming any unreacted NHS ester.
-
-
Purification:
-
Purify the ADC from unconjugated drug-linker and other reaction components using SEC.
-
-
Characterization:
-
Determine the protein concentration and DAR of the purified ADC using UV-Vis spectrophotometry.
-
Confirm the identity and purity of the ADC using techniques such as mass spectrometry and SDS-PAGE.
-
Conclusion
The diverse applications of this compound derivatives in drug discovery, from epigenetic modulation to targeted protein degradation and antibody-drug conjugates, underscore their significance in modern therapeutic development. The protocols and application notes provided herein offer a foundational framework for researchers to explore and harness the potential of these versatile molecules. Rigorous experimental design and validation, as outlined, are crucial for the successful translation of these promising research tools into novel therapeutics.
References
- 1. This compound Acetylation and Deacetylation in Brain Development and Neuropathies | Semantic Scholar [semanticscholar.org]
- 2. A protocol for high-throughput screening of histone this compound demethylase 4 inhibitors using TR-FRET assay - PMC [pmc.ncbi.nlm.nih.gov]
- 3. This compound deacetylases and mitochondrial dynamics in neurodegeneration - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. benchchem.com [benchchem.com]
- 5. researchgate.net [researchgate.net]
- 6. Selective Bioluminogenic HDAC Activity Assays for Profiling HDAC Inhibitors [promega.com]
- 7. youtube.com [youtube.com]
- 8. revvity.com [revvity.com]
- 9. Histone Acetyltransferase Assays in Drug and Chemical Probe Discovery - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 10. Nonhistone this compound Methylation in the Regulation of Cancer Pathways - PMC [pmc.ncbi.nlm.nih.gov]
- 11. academic.oup.com [academic.oup.com]
- 12. revvity.com [revvity.com]
- 13. Measuring Histone Deacetylase Inhibition in the Brain - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Protocols for this compound Conjugation | Springer Nature Experiments [experiments.springernature.com]
- 15. This compound Acetylation and Deacetylation in Brain Development and Neuropathies - PMC [pmc.ncbi.nlm.nih.gov]
- 16. aacrjournals.org [aacrjournals.org]
- 17. Western Analysis of Histone Modifications (Aspergillus nidulans) [bio-protocol.org]
- 18. Site-selective this compound conjugation methods and applications towards antibody–drug conjugates - Chemical Communications (RSC Publishing) [pubs.rsc.org]
- 19. cdn.caymanchem.com [cdn.caymanchem.com]
- 20. A High-Throughput Method to Prioritize PROTAC Intracellular Target Engagement and Cell Permeability Using NanoBRET | Springer Nature Experiments [experiments.springernature.com]
- 21. mdpi.com [mdpi.com]
- 22. chayon.co.kr [chayon.co.kr]
- 23. Epigenetic Changes in the Brain: Measuring Global Histone Modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 24. benchchem.com [benchchem.com]
- 25. Histone western blot protocol | Abcam [abcam.com]
- 26. benchchem.com [benchchem.com]
- 28. This compound based Conjugation Strategy - Creative Biolabs [creative-biolabs.com]
Application Notes and Protocols for Studying Protein-Protein Interactions Using Lysine Cross-Linkers
For Researchers, Scientists, and Drug Development Professionals
Introduction
Chemical cross-linking coupled with mass spectrometry (XL-MS) has become an indispensable technique for the elucidation of protein-protein interactions (PPIs) and the structural analysis of protein complexes.[1][2] By covalently linking interacting proteins, transient or weak interactions can be captured and stabilized for subsequent analysis.[3] Lysine residues, being abundant on protein surfaces and possessing a reactive primary amine, are common targets for cross-linking reagents.[4][5] These application notes provide detailed protocols and quantitative data for utilizing this compound-reactive cross-linkers to study PPIs.
Application Note 1: Overview of Common this compound Cross-Linkers
The choice of cross-linker is critical and depends on the specific application. Key parameters to consider include the spacer arm length, water solubility (membrane permeability), and whether the linker is cleavable by mass spectrometry.[6][7] Homobifunctional N-hydroxysuccinimide (NHS) esters are the most popular class of this compound-reactive cross-linkers.[4] These reagents react with primary amines at a pH range of 7.0-9.0 to form stable amide bonds.[6][8]
Table 1: Properties of Common this compound-Reactive Cross-Linkers
| Cross-Linker | Full Name | Spacer Arm Length (Å) | Membrane Permeable | Key Characteristics |
| DSS | Disuccinimidyl suberate | 11.4 | Yes | Water-insoluble; must be dissolved in an organic solvent like DMSO or DMF.[6][9] Useful for intracellular cross-linking.[6] |
| BS3 | Bis(sulfosuccinimidyl) suberate | 11.4 | No | Water-soluble due to sulfonate groups.[10] Ideal for cell-surface protein cross-linking.[11] |
| DSG | Disuccinimidyl glutarate | 7.7 | Yes | A shorter, non-polar cross-linker.[12] |
| BS2G | Bis(sulfosuccinimidyl) glutarate | 7.7 | No | The water-soluble counterpart to DSG.[12] |
| DSSO | Disuccinimidyl sulfoxide | 10.1 | Yes | An MS-cleavable cross-linker, which simplifies data analysis.[13] |
Experimental Workflow Overview
The general workflow for a this compound cross-linking experiment involves several key stages, from sample preparation to data analysis. The following diagram illustrates a typical process for identifying protein-protein interactions using this compound cross-linkers and mass spectrometry.
Caption: General workflow for protein-protein interaction studies using this compound cross-linking.
Protocol 1: In Vitro Protein Cross-Linking with DSS
This protocol describes the cross-linking of purified proteins in solution using Disuccinimidyl suberate (DSS).
Materials:
-
Purified protein sample
-
Disuccinimidyl suberate (DSS)[9]
-
Dry, amine-free solvent (e.g., DMSO or DMF)[9]
-
Reaction Buffer (amine-free, pH 7-9, e.g., 20 mM sodium phosphate, 150 mM NaCl, pH 7.5)[8][11]
-
Quenching Buffer (e.g., 1 M Tris-HCl, pH 7.5)[8]
-
Desalting column or dialysis equipment[9]
Table 2: Recommended Starting Conditions for DSS Cross-Linking
| Parameter | Recommended Range/Value | Notes |
| DSS Concentration | 0.25 - 5 mM (final) | The optimal concentration is dependent on the protein concentration.[8] |
| Molar Excess of DSS to Protein | 10-fold for > 5 mg/mL protein; 20- to 50-fold for < 5 mg/mL protein | Higher molar excess is needed for more dilute protein solutions.[8][11] |
| Reaction Time | 30 minutes at room temperature or 2 hours on ice | Longer incubation may be required at lower temperatures.[14] |
| Quenching Time | 15 minutes at room temperature | Ensures all unreacted DSS is quenched.[14] |
Procedure:
-
Protein Preparation: Prepare the purified protein sample in the Reaction Buffer. If necessary, perform a buffer exchange to remove any primary amine-containing substances.[8]
-
DSS Preparation: Immediately before use, prepare a stock solution of DSS (e.g., 25 mM) in anhydrous DMSO.[6] For example, dissolve 2 mg of DSS in 216 µL of DMSO.[6]
-
Cross-Linking Reaction: Add the freshly prepared DSS stock solution to the protein sample to achieve the desired final concentration. The final concentration of the organic solvent should not exceed 10% of the total reaction volume.[8]
-
Incubation: Incubate the reaction mixture for 30 minutes at room temperature or for 2 hours on ice.[14] Gentle mixing is recommended.[15]
-
Quenching: Stop the reaction by adding Quenching Buffer to a final concentration of 20-50 mM.[14]
-
Incubation: Incubate for an additional 15 minutes at room temperature to quench any unreacted DSS.[14]
-
Removal of Excess Reagents: Remove unreacted DSS and quenching buffer using a desalting column or dialysis.[9]
-
Analysis: The cross-linked sample is now ready for downstream analysis, such as SDS-PAGE, Western blotting, or mass spectrometry.[14][15]
Protocol 2: Cell Surface Protein Cross-Linking with BS3
This protocol is for cross-linking proteins on the surface of living cells using the water-soluble cross-linker Bis(sulfosuccinimidyl) suberate (BS3).
Materials:
-
Suspension or adherent cells
-
Phosphate-Buffered Saline (PBS), pH 8.0[11]
-
Bis(sulfosuccinimidyl) suberate (BS3)[10]
-
Quenching Buffer (e.g., 1 M Tris-HCl, pH 7.5)[16]
-
Lysis Buffer
Procedure:
-
Cell Preparation:
-
BS3 Preparation: Immediately before use, prepare a stock solution of BS3 in an amine-free buffer (e.g., 25 mM Sodium Phosphate, pH 7.4).[10]
-
Cross-Linking Reaction: Add the BS3 solution to the cells to a final concentration of 1-5 mM.[11]
-
Incubation: Incubate the reaction for 30 minutes at room temperature.[11]
-
Quenching: Add Quenching Buffer to a final concentration of 10-20 mM Tris.[11]
-
Incubation: Incubate for 15 minutes at room temperature to quench the reaction.[11]
-
Cell Lysis: Wash the cells with PBS and then lyse the cells using an appropriate lysis buffer to extract the cross-linked protein complexes.
-
Analysis: The cell lysate containing the cross-linked proteins is ready for further analysis, such as immunoprecipitation followed by mass spectrometry.
Application Note 2: Quantitative Cross-Linking Mass Spectrometry (QCLMS)
QCLMS allows for the quantitative comparison of protein conformations and interactions between different states.[17][18] This is often achieved by using isotopically labeled cross-linkers.[19] For example, a "light" (d0) and a "heavy" (d4 or d12) version of a cross-linker like BS3 or DSS can be used to label two different conformational states of a protein complex.[17][20] After cross-linking, the samples are mixed, digested, and analyzed by mass spectrometry. The relative signal intensities of the light and heavy cross-linked peptide pairs reveal changes in protein structure or interaction.[19]
Caption: Conceptual workflow of a quantitative cross-linking experiment.
Table 3: Interpreting QCLMS Data
| Peak Ratio (Light:Heavy) | Interpretation |
| ~1:1 | No significant conformational change in the region of the cross-link. |
| >>1:1 or <<1:1 | A conformational change has occurred, altering the distance between the cross-linked this compound residues. |
| Singlet Peak (Light or Heavy) | The cross-link is unique to one conformational state.[17] |
Downstream Data Analysis
The identification of cross-linked peptides from complex mass spectra is a significant bioinformatic challenge.[3] Specialized software is required to search the spectral data against protein sequence databases to identify the two linked peptides.
Commonly used software for cross-link identification:
These programs identify cross-linked peptides and assign a confidence score to each identification. The resulting distance constraints can then be used to model the three-dimensional structure of the protein or protein complex.[1][22]
Conclusion
The use of this compound-reactive cross-linkers is a powerful approach for investigating protein-protein interactions and protein structure. The protocols and data presented here provide a foundation for researchers to design and execute successful cross-linking experiments. Careful optimization of reaction conditions and the use of appropriate data analysis tools are crucial for obtaining high-quality, reliable results.
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. This compound-specific chemical cross-linking of protein complexes and identification of cross-linking sites using LC-MS/MS and the xQuest/xProphet software pipeline - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Evaluating protein interactions through cross-linking mass spectrometry: New bioinformatics tools enable the recognition of neighboring amino acids in protein complexes - PMC [pmc.ncbi.nlm.nih.gov]
- 4. biorxiv.org [biorxiv.org]
- 5. Development and Recent Advances in this compound and N-Terminal Bioconjugation for Peptides and Proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 6. benchchem.com [benchchem.com]
- 7. pubs.acs.org [pubs.acs.org]
- 8. benchchem.com [benchchem.com]
- 9. researchgate.net [researchgate.net]
- 10. fnkprddata.blob.core.windows.net [fnkprddata.blob.core.windows.net]
- 11. store.sangon.com [store.sangon.com]
- 12. researchgate.net [researchgate.net]
- 13. Technologies converge on interacting surfaces in protein complexes | EurekAlert! [eurekalert.org]
- 14. benchchem.com [benchchem.com]
- 15. What Are the Specific Steps for DSS Protein Crosslinking? | MtoZ Biolabs [mtoz-biolabs.com]
- 16. Immunoprecipitation Crosslinking | Thermo Fisher Scientific - US [thermofisher.com]
- 17. Quantitative cross-linking/mass spectrometry reveals subtle protein conformational changes - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Quantitative cross-linking/mass spectrometry to elucidate structural changes in proteins and their complexes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. researchgate.net [researchgate.net]
- 20. A comparative cross-linking strategy to probe conformational changes in protein complexes - PMC [pmc.ncbi.nlm.nih.gov]
- 21. This compound-specific chemical cross-linking of protein complexes and identification of cross-linking sites using LC-MS/MS and the xQuest/xProphet software pipeline | Springer Nature Experiments [experiments.springernature.com]
- 22. A General Method for Targeted Quantitative Cross-Linking Mass Spectrometry | PLOS One [journals.plos.org]
Lysine bioconjugation techniques for peptides and proteins
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a detailed overview of common lysine bioconjugation techniques for peptides and proteins. This document includes a comparative analysis of key methods, detailed experimental protocols, and visual representations of workflows to guide researchers in selecting and implementing the most suitable strategy for their specific application, from fluorescent labeling to the development of antibody-drug conjugates (ADCs).
Introduction to this compound Bioconjugation
This compound is a frequently targeted amino acid for bioconjugation due to the high nucleophilicity of its ε-amino group and its common presence on the surface of proteins.[][] This accessibility makes this compound an attractive target for attaching a wide range of molecules, including fluorescent dyes, polyethylene glycol (PEG), and cytotoxic drugs. However, the high abundance of this compound residues can lead to heterogeneous products, making the control of stoichiometry and site of conjugation a critical consideration.[][3]
This document focuses on three widely used this compound bioconjugation methods:
-
N-Hydroxysuccinimide (NHS) Ester Chemistry: Forms a stable amide bond.
-
Isothiocyanate Chemistry: Forms a thiourea bond.
-
Reductive Amination: Forms a secondary amine bond.
Comparative Analysis of this compound Bioconjugation Techniques
The choice of bioconjugation chemistry depends on several factors, including the desired stability of the conjugate, the sensitivity of the protein to reaction conditions, and the required degree of labeling. The following table summarizes the key characteristics of the three main this compound conjugation methods.
| Feature | NHS Ester Chemistry | Isothiocyanate Chemistry | Reductive Amination |
| Target Group | Primary amines (this compound, N-terminus) | Primary amines (this compound, N-terminus) | Primary amines (this compound, N-terminus) |
| Reactive Moiety | Activated Ester | Isothiocyanate | Aldehyde or Ketone |
| Resulting Bond | Amide | Thiourea | Secondary Amine |
| Bond Stability | Highly Stable[4][5] | Less stable than amide bonds[6] | Stable |
| Optimal pH | 7.0 - 8.5[6][7] | 9.0 - 9.5[4] | 6.0 - 9.0[6] |
| Reaction Speed | Fast (minutes to a few hours)[8] | Generally fast | Slower (requires imine formation and reduction) |
| Key Advantages | High stability of amide bond, well-established protocols. | Relatively stable reagents. | Preserves the positive charge of the amine. |
| Key Disadvantages | Susceptible to hydrolysis, potential for heterogeneity.[] | Higher pH may be detrimental to some proteins, thiourea bond can be less stable.[6] | Two-step process, requires a reducing agent. |
Experimental Protocols
NHS Ester-Mediated Labeling of Proteins
This protocol describes a general procedure for labeling proteins using an NHS ester-functionalized molecule (e.g., a fluorescent dye or biotin).
Materials:
-
Protein of interest in an amine-free buffer (e.g., PBS, pH 7.4)
-
NHS ester of the label
-
Anhydrous DMSO or DMF
-
Reaction Buffer: 0.1 M sodium bicarbonate or sodium phosphate buffer, pH 8.0-8.5
-
Quenching Reagent: 1 M Tris-HCl, pH 8.0, or 1 M glycine
-
Desalting column or dialysis equipment
Procedure:
-
Protein Preparation: Dissolve the protein in the Reaction Buffer to a final concentration of 1-10 mg/mL. If the protein is in a buffer containing primary amines (e.g., Tris), exchange it into the Reaction Buffer.
-
NHS Ester Preparation: Immediately before use, dissolve the NHS ester in a minimal amount of anhydrous DMSO or DMF to create a concentrated stock solution (e.g., 10 mg/mL).
-
Conjugation Reaction:
-
Calculate the required volume of the NHS ester stock solution to achieve the desired molar excess (typically 10- to 20-fold molar excess over the protein).
-
Add the NHS ester stock solution to the protein solution while gently vortexing.
-
Incubate the reaction mixture for 1-2 hours at room temperature or overnight at 4°C. Protect from light if using a light-sensitive label.
-
-
Quenching the Reaction: Add the Quenching Reagent to the reaction mixture to a final concentration of 50-100 mM. Incubate for 30 minutes at room temperature to quench any unreacted NHS ester.
-
Purification of the Conjugate: Remove unreacted label and by-products by passing the reaction mixture through a desalting column equilibrated with the desired storage buffer (e.g., PBS). Alternatively, purify the conjugate by dialysis.
-
Characterization: Determine the protein concentration and the degree of labeling (DOL).
Workflow for NHS Ester-Mediated Protein Labeling:
Caption: Workflow for NHS Ester-Mediated Protein Labeling.
Isothiocyanate-Mediated Labeling of Proteins
This protocol outlines the labeling of proteins using an isothiocyanate-functionalized molecule.
Materials:
-
Protein of interest
-
Isothiocyanate reagent
-
Anhydrous DMSO or DMF
-
Reaction Buffer: 0.1 M carbonate-bicarbonate buffer, pH 9.0-9.5
-
Quenching Reagent: 1 M Tris-HCl, pH 8.0
-
Desalting column or dialysis equipment
Procedure:
-
Protein Preparation: Dissolve the protein in the Reaction Buffer to a final concentration of 1-10 mg/mL.
-
Isothiocyanate Preparation: Immediately before use, dissolve the isothiocyanate reagent in a minimal amount of anhydrous DMSO or DMF.
-
Conjugation Reaction:
-
Add the isothiocyanate solution to the protein solution (typically a 10- to 20-fold molar excess).
-
Incubate for 2-4 hours at room temperature, protected from light.
-
-
Quenching the Reaction: Add the Quenching Reagent to stop the reaction.
-
Purification: Purify the conjugate using a desalting column or dialysis to remove unreacted reagents.
-
Characterization: Determine the protein concentration and DOL.
Workflow for Isothiocyanate-Mediated Protein Labeling:
References
- 3. This compound based Conjugation Strategy - Creative Biolabs [creative-biolabs.com]
- 4. benchchem.com [benchchem.com]
- 5. chemistry.stackexchange.com [chemistry.stackexchange.com]
- 6. Developments and recent advancements in the field of endogenous amino acid selective bond forming reactions for bioconjugation - Chemical Society Reviews (RSC Publishing) DOI:10.1039/C5CS00048C [pubs.rsc.org]
- 7. api-docs.rango.exchange [api-docs.rango.exchange]
- 8. benchchem.com [benchchem.com]
Application Notes and Protocols for Targeting Lysine-Modifying Enzymes in Drug Discovery
For Researchers, Scientists, and Drug Development Professionals
These comprehensive application notes and protocols provide a detailed guide to understanding and targeting lysine-modifying enzymes for therapeutic development. This document covers the major families of these enzymes, their roles in disease, relevant inhibitors, and detailed experimental procedures for their study.
Application Note 1: Introduction to this compound-Modifying Enzymes as Drug Targets
Post-translational modifications (PTMs) of proteins are critical regulatory mechanisms in cellular processes. Among these, the modification of this compound residues plays a pivotal role in regulating protein function, stability, and interaction networks. Enzymes that add or remove these modifications—the "writers" and "erasers" of the epigenetic code—are crucial for maintaining cellular homeostasis. Aberrant activity of these enzymes is frequently implicated in a wide range of diseases, including cancer, neurodegenerative disorders, and inflammatory conditions.[1][2] This makes them highly attractive targets for drug discovery.
The primary families of this compound-modifying enzymes include:
-
This compound Acetyltransferases (KATs) and This compound Deacetylases (KDACs/HDACs) : These enzymes control the acetylation state of this compound residues, influencing gene expression and other cellular processes.
-
This compound Methyltransferases (KMTs) and This compound Demethylases (KDMs) : These enzymes regulate the methylation state of lysines, a key modification in chromatin biology and beyond.
Application Note 2: this compound Deacetylases (HDACs) as Therapeutic Targets
Histone Deacetylases (HDACs) are a class of enzymes that remove acetyl groups from this compound residues on histones and other proteins. This deacetylation leads to a more compact chromatin structure, generally resulting in transcriptional repression.[3] Dysregulation of HDAC activity is a hallmark of many cancers, where it can lead to the silencing of tumor suppressor genes.[3] Consequently, HDAC inhibitors have emerged as a promising class of anti-cancer agents.[4] To date, several HDAC inhibitors have received FDA approval for the treatment of various hematological malignancies.[5][6]
Prominent FDA-Approved HDAC Inhibitors:
| Inhibitor | Target Class | FDA-Approved Indication(s) | Reference |
| Vorinostat (SAHA) | Pan-HDAC | Cutaneous T-cell lymphoma (CTCL) | [5] |
| Romidepsin (FK228) | Class I HDAC selective | Cutaneous T-cell lymphoma (CTCL), Peripheral T-cell lymphoma (PTCL) | [6] |
| Belinostat (PXD101) | Pan-HDAC | Peripheral T-cell lymphoma (PTCL) | [6] |
| Panobinostat (LBH589) | Pan-HDAC | Multiple myeloma | [6][7][8][9] |
Selected HDAC Inhibitors and their Potency (IC50)
| Inhibitor | Target HDAC(s) | IC50 (nM) | Reference |
| Trichostatin A | Class I and II | ~1 | [10] |
| Entinostat (MS-275) | HDAC1, HDAC3 | 100-400 | [4] |
| Mocetinostat | HDAC1, HDAC2, HDAC3, HDAC11 | 200-1000 | [11] |
| Ricolinostat (ACY-1215) | HDAC6 | 5 | [12] |
| Pracinostat (SB939) | Pan-HDAC | 40-140 | [11] |
Signaling Pathway: HDACs in Transcriptional Repression
Caption: Role of HATs and HDACs in regulating chromatin state and gene transcription.
Protocol 1: Fluorometric HDAC Activity Assay
This protocol describes a method to measure the activity of HDAC enzymes, which is suitable for screening potential inhibitors.
Materials:
-
HDAC Assay Buffer (50 mM Tris-HCl, pH 8.0, 137 mM NaCl, 2.7 mM KCl, 1 mM MgCl2)
-
Fluorogenic HDAC substrate (e.g., Boc-Lys(Ac)-AMC)
-
Trichostatin A (TSA) as a positive control inhibitor
-
HeLa nuclear extract or purified HDAC enzyme
-
Developer solution (containing a protease that cleaves the deacetylated substrate)
-
96-well black microplate
-
Fluorometric plate reader (Ex/Em = 350-380/440-460 nm)
Procedure:
-
Reagent Preparation:
-
Prepare a stock solution of the HDAC substrate in DMSO.
-
Dilute the HDAC substrate and test compounds to the desired concentrations in HDAC Assay Buffer.
-
Dilute the HeLa nuclear extract or purified HDAC enzyme in HDAC Assay Buffer.
-
-
Assay Reaction:
-
To each well of the 96-well plate, add 50 µL of the diluted enzyme solution.
-
Add 5 µL of the test compound or vehicle control (DMSO).
-
For a positive control, add TSA at a final concentration of 1 µM.
-
Incubate the plate at 37°C for 10 minutes.
-
Initiate the reaction by adding 50 µL of the diluted HDAC substrate to each well.
-
-
Incubation:
-
Incubate the plate at 37°C for 60 minutes, protected from light.
-
-
Development:
-
Stop the enzymatic reaction by adding 100 µL of the developer solution to each well.
-
Incubate the plate at 37°C for 15 minutes.
-
-
Measurement:
-
Data Analysis:
-
Subtract the background fluorescence (wells without enzyme) from all readings.
-
Calculate the percentage of inhibition for each compound concentration relative to the vehicle control.
-
Determine the IC50 value by plotting the percentage of inhibition against the logarithm of the compound concentration and fitting the data to a dose-response curve.
-
Application Note 3: this compound Methyltransferases (KMTs) as Therapeutic Targets
This compound methyltransferases (KMTs) catalyze the transfer of methyl groups from S-adenosylmethionine (SAM) to this compound residues on histones and non-histone proteins.[16] This methylation can involve the addition of one (mono-), two (di-), or three (tri-) methyl groups, leading to a wide range of functional outcomes. Aberrant KMT activity is linked to various cancers.[17][18] For example, EZH2, the catalytic subunit of the Polycomb Repressive Complex 2 (PRC2), is a KMT that trimethylates histone H3 at this compound 27 (H3K27me3), a mark associated with gene silencing.[19] Overexpression or mutation of EZH2 is common in lymphomas and other cancers.
Selected KMT Inhibitors in Clinical Development:
| Inhibitor | Target KMT | Indication(s) in Trials | Reference |
| Tazemetostat | EZH2 | Epithelioid sarcoma, Follicular lymphoma | [20] |
| Pinometostat (EPZ-5676) | DOT1L | MLL-rearranged leukemia | [21] |
| GSK2816126 | EZH2 | Relapsed/refractory solid tumors and lymphomas | [20] |
Selected KMT Inhibitors and their Potency (IC50)
| Inhibitor | Target KMT | IC50 (nM) | Reference |
| EPZ005687 | EZH2 | 24 | [18] |
| GSK126 | EZH2 | 3 | [18] |
| UNC0638 | G9a/GLP | <15 | [4] |
| BIX-01294 | G9a/GLP | 1,900 (G9a), 700 (GLP) | [21] |
| Chaetocin | SUV39H1 | 600 | [21] |
Signaling Pathway: EZH2 in Cancer
Caption: EZH2 signaling pathway leading to cancer cell proliferation.
Protocol 2: In Vitro Histone Methyltransferase Assay
This protocol outlines a radiometric assay to measure the activity of KMTs, such as EZH2.
Materials:
-
Purified recombinant KMT (e.g., EZH2 complex)
-
Histone H3 peptide substrate (or full-length histone H3)
-
S-adenosyl-L-[methyl-³H]-methionine ([³H]-SAM)
-
KMT reaction buffer (e.g., 50 mM Tris-HCl pH 8.5, 5 mM MgCl₂, 4 mM DTT)
-
Scintillation cocktail
-
Phosphocellulose filter paper
-
Scintillation counter
Procedure:
-
Reaction Setup:
-
In a microcentrifuge tube, prepare the reaction mixture containing KMT reaction buffer, the histone substrate (e.g., 1 µg), and the test inhibitor at various concentrations.
-
Pre-incubate the mixture at 30°C for 10 minutes.
-
-
Initiate Reaction:
-
Start the reaction by adding [³H]-SAM (e.g., 1 µCi).
-
Incubate the reaction at 30°C for 60 minutes.
-
-
Stop Reaction and Spot:
-
Stop the reaction by spotting 20 µL of the reaction mixture onto the phosphocellulose filter paper.
-
-
Washing:
-
Wash the filter paper three times for 5 minutes each with 1 M sodium bicarbonate buffer, pH 9.0, to remove unincorporated [³H]-SAM.
-
Rinse the filter paper with ethanol and let it air dry.
-
-
Scintillation Counting:
-
Place the dried filter paper into a scintillation vial.
-
Add 5 mL of scintillation cocktail.
-
Measure the incorporated radioactivity using a scintillation counter.
-
-
Data Analysis:
-
Calculate the percentage of inhibition for each compound concentration compared to the vehicle control.
-
Determine the IC50 value by plotting the percentage of inhibition against the logarithm of the compound concentration.
-
Application Note 4: this compound Demethylases (KDMs) as Therapeutic Targets
This compound demethylases (KDMs) are enzymes that remove methyl groups from this compound residues, acting as "erasers" of methylation marks.[19] They are classified into two main families: the flavin-dependent LSD family (e.g., LSD1/KDM1A) and the JmjC domain-containing family. Dysregulation of KDM activity has been implicated in various cancers by promoting oncogenic gene expression.[19][22] For instance, LSD1 is overexpressed in several cancers and its inhibition has shown therapeutic potential.
Selected KDM Inhibitors:
| Inhibitor | Target KDM | Status |
| Tranylcypromine (and derivatives) | LSD1 | Preclinical/Clinical |
| GSK-J4 | KDM6A/B | Preclinical |
| IOX1 | JmjC KDMs | Preclinical |
Protocol 3: KDM Inhibitor Screening Assay (AlphaScreen)
This protocol describes a high-throughput screening method for identifying KDM inhibitors using AlphaScreen technology.
Materials:
-
Purified recombinant KDM (e.g., KDM5A)
-
Biotinylated histone peptide substrate (e.g., biotin-H3K4me3)
-
Streptavidin-coated donor beads
-
Antibody specific for the demethylated product (e.g., anti-H3K4me2)
-
Protein A-coated acceptor beads
-
KDM reaction buffer
-
384-well microplate
-
AlphaScreen-compatible plate reader
Procedure:
-
Demethylation Reaction:
-
Add the KDM enzyme, biotinylated substrate, and test compound to the wells of a 384-well plate.
-
Incubate at room temperature to allow the demethylation reaction to proceed.
-
-
Detection:
-
Add a mixture of streptavidin-coated donor beads and protein A-coated acceptor beads pre-incubated with the detection antibody.
-
Incubate in the dark at room temperature.
-
-
Measurement:
-
Read the plate on an AlphaScreen reader. A decrease in signal indicates inhibition of the KDM.
-
-
Data Analysis:
-
Calculate the percentage of inhibition for each compound and determine IC50 values.[23]
-
Application Note 5: this compound Acetyltransferases (KATs) as Therapeutic Targets
This compound acetyltransferases (KATs), also known as histone acetyltransferases (HATs), are enzymes that transfer an acetyl group from acetyl-CoA to this compound residues.[24] This modification is generally associated with chromatin relaxation and transcriptional activation. The dysregulation of KATs is involved in the pathology of cancer and other diseases.[24][25] Inhibitors of KATs, such as those targeting p300/CBP, are being explored as potential therapeutics.[13]
Selected KAT Inhibitors:
| Inhibitor | Target KAT | Status |
| A-485 | p300/CBP | Preclinical |
| CCS1477 | p300/CBP | Clinical |
| Anacardic Acid | p300/CBP, PCAF | Preclinical |
Protocol 4: HAT Inhibitor Screening Assay
This protocol provides a fluorescence-based method for screening HAT inhibitors.
Materials:
-
Purified recombinant HAT (e.g., PCAF)
-
Histone H3 peptide substrate
-
Acetyl-CoA
-
HAT assay buffer
-
Developer solution containing a thiol-sensitive fluorescent probe (e.g., CPM)
-
96-well black microplate
-
Fluorescence plate reader
Procedure:
-
HAT Reaction:
-
In a 96-well plate, combine the HAT enzyme, histone H3 peptide substrate, and the test inhibitor.
-
Initiate the reaction by adding acetyl-CoA.
-
Incubate at 37°C.
-
-
Stop and Develop:
-
Stop the reaction (e.g., by adding isopropanol).
-
Add the developer solution to each well. The developer reacts with the coenzyme A (CoA-SH) produced during the HAT reaction to generate a fluorescent signal.
-
-
Measurement:
-
Measure the fluorescence on a plate reader. A decrease in fluorescence indicates HAT inhibition.
-
-
Data Analysis:
Experimental Workflow and Logic Diagrams
Workflow for Screening and Validation of a KMT Inhibitor
Caption: A typical workflow for the discovery and development of KMT inhibitors.
Logical Relationship of Epigenetic "Writers" and "Erasers"
Caption: The dynamic interplay between "writer" and "eraser" enzymes.
References
- 1. researchgate.net [researchgate.net]
- 2. researchgate.net [researchgate.net]
- 3. creative-diagnostics.com [creative-diagnostics.com]
- 4. This compound methyltransferase inhibitors: where we are now - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. mdpi.com [mdpi.com]
- 7. aacrjournals.org [aacrjournals.org]
- 8. researchgate.net [researchgate.net]
- 9. EpiQuik HAT Activity/Inhibition Assay Kit | EpigenTek [epigentek.com]
- 10. Identification of HDAC inhibitors using a cell-based HDAC I/II assay - PMC [pmc.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. researchgate.net [researchgate.net]
- 13. sigmaaldrich.com [sigmaaldrich.com]
- 14. apexbt.com [apexbt.com]
- 15. caymanchem.com [caymanchem.com]
- 16. domainex.co.uk [domainex.co.uk]
- 17. Treating human cancer by targeting EZH2 - PMC [pmc.ncbi.nlm.nih.gov]
- 18. probiologists.com [probiologists.com]
- 19. EZH2 Dysregulation and Its Oncogenic Role in Human Cancers - PMC [pmc.ncbi.nlm.nih.gov]
- 20. aacrjournals.org [aacrjournals.org]
- 21. This compound methyltransferase inhibitors: where we are now - RSC Chemical Biology (RSC Publishing) DOI:10.1039/D1CB00196E [pubs.rsc.org]
- 22. Histone acetyltransferases CBP/p300 in tumorigenesis and CBP/p300 inhibitors as promising novel anticancer agents [thno.org]
- 23. Screen-identified selective inhibitor of this compound demethylase 5A blocks cancer cell growth and drug resistance - PMC [pmc.ncbi.nlm.nih.gov]
- 24. researchgate.net [researchgate.net]
- 25. creative-diagnostics.com [creative-diagnostics.com]
- 26. cdn.caymanchem.com [cdn.caymanchem.com]
- 27. caymanchem.com [caymanchem.com]
Troubleshooting & Optimization
Technical Support Center: Optimizing Lysine NHS-Ester Conjugation
Welcome to the technical support center for lysine N-hydroxysuccinimide (NHS) ester conjugation. This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and frequently asked questions (FAQs) to address common challenges encountered during bioconjugation experiments.
Frequently Asked Questions (FAQs)
Q1: What is the optimal pH for NHS-ester conjugation to this compound residues?
The optimal pH for reacting NHS esters with primary amines, such as the ε-amino group of this compound, is typically in the range of 7.2 to 8.5.[1][2][3][4][5] Many protocols recommend a more specific range of 8.3 to 8.5 to maximize reaction efficiency.[2][5][6][7] This pH range represents a compromise: it is high enough to ensure a sufficient concentration of deprotonated, nucleophilic primary amines for reaction, yet low enough to minimize the rapid hydrolysis of the NHS ester.[3][5] At a lower pH, the amine groups are protonated and thus unreactive, while at a pH above 8.5, the rate of NHS-ester hydrolysis significantly increases, competing with the desired conjugation reaction.[4][5][6]
Q2: Which buffers should I use for the conjugation reaction, and which should I avoid?
It is critical to use buffers that are free of primary amines.[4] Recommended buffers include phosphate-buffered saline (PBS), carbonate-bicarbonate, HEPES, and borate buffers.[1][2][4] Buffers containing primary amines, such as Tris (tris(hydroxymethyl)aminomethane) and glycine, must be avoided as they will compete with the target protein for reaction with the NHS ester, significantly reducing conjugation efficiency.[1][2][8] However, these amine-containing buffers are useful for quenching the reaction.[1][2][9]
Q3: My conjugation yield is low. What are the possible causes and how can I troubleshoot it?
Low conjugation yield is a common issue that can stem from several factors. Here's a systematic approach to troubleshooting:
-
Reagent Quality: Ensure your NHS ester has not been compromised by moisture. It's crucial to allow the reagent vial to warm to room temperature before opening to prevent condensation.[4] Prepare fresh stock solutions in anhydrous DMSO or DMF immediately before use and avoid repeated freeze-thaw cycles.[4][9] If using DMF, ensure it is high-quality and free of dimethylamine, which can react with the NHS ester.[6][10]
-
Suboptimal pH: Verify that the reaction buffer pH is within the optimal 7.2-8.5 range.[3] A pH that is too low will result in unreactive protonated amines, while a higher pH will accelerate the hydrolysis of the NHS ester.[2]
-
Presence of Interfering Substances: Your protein solution may contain substances with primary amines (e.g., Tris, glycine) or other nucleophiles (e.g., sodium azide) that compete with the reaction.[1][8] If present, perform a buffer exchange via dialysis or desalting column.[8]
-
Low Protein Concentration: The labeling efficiency is dependent on the protein concentration. A concentration of at least 2 mg/mL is recommended, as lower concentrations can hinder conjugation efficiency.[4][11]
-
Inaccessible Amine Groups: The primary amines on your protein may be sterically hindered or buried within the protein's structure. Consider using a longer, more flexible crosslinker to improve accessibility.[3][12]
Q4: How does the hydrolysis of the NHS ester affect the reaction, and how can I minimize it?
Hydrolysis is a significant competing reaction where the NHS ester reacts with water, rendering it inactive.[9][13] The rate of hydrolysis is highly pH-dependent, increasing as the pH becomes more alkaline.[1][2][14] For example, the half-life of an NHS ester is 4 to 5 hours at pH 7.0 and 0°C, but this decreases to just 10 minutes at pH 8.6 and 4°C.[1][14] To minimize hydrolysis, prepare the NHS ester solution immediately before use in an anhydrous organic solvent like DMSO or DMF and add it to the aqueous reaction buffer promptly.[9][15] Avoid prolonged storage of NHS esters in aqueous solutions.[13]
Q5: How do I stop (quench) the conjugation reaction?
To stop the reaction, you can add a small molecule containing a primary amine that will react with and cap any remaining active NHS esters.[9][13] Common quenching reagents include Tris, glycine, this compound, and ethanolamine, typically added to a final concentration of 20-100 mM.[9][13][16] An incubation period of 15 to 30 minutes at room temperature is generally sufficient to ensure all unreacted NHS esters are deactivated.[9][13]
Troubleshooting Guide
This table summarizes common issues, their potential causes, and recommended solutions to optimize your this compound NHS-ester conjugation experiments.
| Issue | Potential Cause | Recommended Solution |
| Low or No Conjugation Yield | Hydrolyzed NHS Ester: Reagent compromised by moisture. | Allow reagent vial to warm to room temperature before opening. Prepare fresh stock solutions in anhydrous DMSO or DMF immediately before use.[4][9] |
| Suboptimal Reaction pH: pH is too low (amines are protonated) or too high (hydrolysis is rapid). | Verify and adjust the buffer pH to the optimal range of 7.2-8.5.[2][3] | |
| Presence of Competing Nucleophiles: Buffer contains primary amines (e.g., Tris, glycine) or other interfering substances. | Perform buffer exchange into an amine-free buffer like PBS, HEPES, or borate.[1][2][8] | |
| Low Protein Concentration: Reactant concentrations are too low, reducing reaction efficiency. | Increase the protein concentration, ideally to 2-10 mg/mL.[4][11] | |
| Steric Hindrance: this compound residues are not accessible to the NHS ester. | Use a longer, more flexible PEGylated crosslinker to overcome steric barriers.[3][12] | |
| Protein Aggregation After Conjugation | Conformational Changes: The conjugation process alters the protein's structure. | Optimize the degree of labeling by adjusting the molar ratio of the NHS ester. Use hydrophilic linkers (e.g., PEG) to improve solubility.[3] |
| Inappropriate Buffer Conditions: The buffer composition is not suitable for the protein. | Perform buffer screening to find conditions where the protein is most stable.[3] | |
| Inconsistent Results | Inconsistent Buffer Preparation: Small variations in pH significantly impact efficiency. | Prepare buffers fresh and accurately measure the pH for each experiment.[2] |
| Moisture Contamination of NHS Ester: Leads to variable amounts of active reagent. | Store NHS esters in a desiccated environment and allow them to equilibrate to room temperature before opening.[2][9] |
Quantitative Data Summary
The efficiency of NHS-ester conjugation is influenced by several quantitative parameters. The following tables provide a summary for easy comparison.
Table 1: Effect of pH on NHS-Ester Hydrolysis
| pH | Temperature (°C) | Half-life of NHS-Ester |
| 7.0 | 0 | 4-5 hours[1][14] |
| 8.6 | 4 | 10 minutes[1][14] |
Table 2: Recommended Reaction Conditions
| Parameter | Recommended Range/Value | Notes |
| pH | 7.2 - 8.5 (Optimal: 8.3-8.5)[1][2][6] | Balances amine reactivity and NHS-ester stability. |
| Protein Concentration | 1 - 10 mg/mL[6][15] | Higher concentrations generally lead to better efficiency.[11] |
| Molar Excess of NHS Ester | 5- to 20-fold[4][5][8] | This is a common starting point and should be optimized for the specific protein. |
| Reaction Time | 0.5 - 4 hours at Room Temperature or 4°C[1] | Longer incubation may be needed at lower temperatures. |
| Organic Solvent (for NHS ester) | 0.5 - 10% of total reaction volume[1][9] | Use anhydrous DMSO or DMF.[9] |
| Quenching Reagent Concentration | 20 - 100 mM[9][13][16] | Common quenchers include Tris and glycine. |
Experimental Protocols
Protocol 1: General Procedure for Labeling a Protein with an NHS Ester
-
Prepare the Protein Solution:
-
Prepare the NHS Ester Solution:
-
Perform the Conjugation Reaction:
-
Calculate the volume of the NHS ester stock solution needed to achieve the desired molar excess (a 10- to 20-fold molar excess is a common starting point).[4][8]
-
While gently stirring the protein solution, add the NHS ester stock solution. The final volume of the organic solvent should not exceed 10% of the total reaction volume.[9]
-
Incubate the reaction at room temperature for 1-4 hours or at 4°C overnight.[4] If the label is fluorescent, protect the reaction from light.
-
-
Quench the Reaction:
-
Purify the Conjugate:
Protocol 2: Quenching Unreacted NHS Esters
-
Prepare Quenching Buffer:
-
Prepare a 1 M stock solution of Tris-HCl or glycine, and adjust the pH to approximately 8.0.
-
-
Add Quenching Buffer to Reaction:
-
Incubate for Quenching:
-
Proceed to Purification:
-
After quenching, purify the conjugate from the excess quenching reagent and other byproducts using a desalting column or dialysis.[13]
-
Visualizations
Caption: Experimental workflow for NHS ester-lysine conjugation.
Caption: Troubleshooting workflow for low conjugation yield.
References
- 1. Amine-Reactive Crosslinker Chemistry | Thermo Fisher Scientific - HK [thermofisher.com]
- 2. benchchem.com [benchchem.com]
- 3. benchchem.com [benchchem.com]
- 4. benchchem.com [benchchem.com]
- 5. benchchem.com [benchchem.com]
- 6. lumiprobe.com [lumiprobe.com]
- 7. interchim.fr [interchim.fr]
- 8. benchchem.com [benchchem.com]
- 9. benchchem.com [benchchem.com]
- 10. researchgate.net [researchgate.net]
- 11. biotium.com [biotium.com]
- 12. benchchem.com [benchchem.com]
- 13. benchchem.com [benchchem.com]
- 14. help.lumiprobe.com [help.lumiprobe.com]
- 15. benchchem.com [benchchem.com]
- 16. benchchem.com [benchchem.com]
- 17. glenresearch.com [glenresearch.com]
Preventing non-specific binding in lysine affinity chromatography
This technical support center provides troubleshooting guidance and frequently asked questions to help researchers, scientists, and drug development professionals overcome challenges with non-specific binding in lysine affinity chromatography.
Frequently Asked Questions (FAQs)
Q1: What is the primary cause of non-specific binding in this compound affinity chromatography?
A1: Non-specific binding in this compound affinity chromatography is primarily caused by unintended interactions between proteins in the sample and the chromatography resin. These interactions are typically either electrostatic (ionic) or hydrophobic in nature. The immobilized this compound ligand has both a positive charge (α-amino group) and a negative charge (α-carboxyl group) at physiological pH, which can lead to ionic interactions with charged proteins. Additionally, the hydrocarbon backbone of this compound and the agarose matrix can contribute to hydrophobic interactions.[1]
Q2: How can I reduce non-specific binding during my experiment?
A2: Several strategies can be employed to minimize non-specific binding. These include optimizing the composition of your binding, wash, and elution buffers. Key approaches involve increasing the ionic strength of the buffers, using additives like arginine, and incorporating non-ionic detergents.[2][3]
Q3: What is the role of increased salt concentration in the wash buffer?
A3: Increasing the salt concentration, typically with sodium chloride (NaCl), in the wash buffer helps to disrupt non-specific electrostatic interactions. The salt ions shield the charges on both the contaminant proteins and the this compound ligand, preventing them from binding to each other.[1][4]
Q4: Can additives like arginine improve the purity of my target protein?
A4: Yes, arginine can be a valuable additive to wash buffers to reduce non-specific binding. Arginine can help to solubilize proteins and reduce protein-protein aggregation. It is thought to interfere with both ionic and hydrophobic interactions that cause non-specific binding, leading to a purer final product.[2][3][5]
Q5: When should I consider using non-ionic detergents?
A5: If you suspect that non-specific binding is primarily due to hydrophobic interactions, the addition of a non-ionic detergent (e.g., Triton X-100 or Tween-20) to your buffers can be beneficial. These detergents work by disrupting hydrophobic interactions between contaminant proteins and the chromatography matrix.[1][6]
Troubleshooting Guide
| Problem | Possible Cause | Recommended Solution |
| High levels of contaminating proteins in the eluate. | Non-specific binding of proteins to the resin. | 1. Increase Ionic Strength: Gradually increase the NaCl concentration in the wash buffer (e.g., from 0.1 M to 0.5 M or higher) to disrupt electrostatic interactions.[1] 2. Add Arginine: Include arginine (e.g., 0.1 M to 0.5 M) in the wash buffer to reduce both ionic and hydrophobic non-specific binding.[3][5] 3. Incorporate Non-ionic Detergents: If hydrophobic interactions are suspected, add a low concentration (e.g., 0.1%) of a non-ionic detergent like Triton X-100 to the wash buffer.[1][6] |
| Target protein is eluting during the wash steps. | Wash conditions are too stringent. | 1. Decrease Salt Concentration: If your target protein is weakly bound, reduce the NaCl concentration in the wash buffer. 2. Lower Additive Concentration: If using additives like arginine or detergents, try reducing their concentration. |
| Low yield of the target protein. | Precipitation of the target protein on the column. | 1. Optimize Buffer pH: Ensure the pH of your buffers is optimal for the stability of your target protein. 2. Include Stabilizing Agents: Consider adding stabilizing agents like glycerol to your buffers if your protein is prone to aggregation. |
| Inconsistent results between purification runs. | Incomplete column regeneration. | Ensure the column is thoroughly regenerated between runs to remove any tightly bound contaminants. A typical regeneration protocol involves washing with high and low pH buffers.[1] |
Data Presentation
The following tables provide an illustrative summary of the expected quantitative effects of different additives on the purity of the target protein in this compound affinity chromatography. The exact values will vary depending on the specific protein being purified and the initial sample purity.
Table 1: Effect of NaCl Concentration in Wash Buffer on Final Purity
| NaCl Concentration in Wash Buffer | Expected Purity of Target Protein (%) |
| 0.1 M | 75% |
| 0.25 M | 85% |
| 0.5 M | 92% |
| 1.0 M | 95% |
Table 2: Effect of Arginine in Wash Buffer on Final Purity
| Arginine Concentration in Wash Buffer (with 0.15 M NaCl) | Expected Purity of Target Protein (%) |
| 0 M | 80% |
| 0.1 M | 88% |
| 0.25 M | 94% |
| 0.5 M | 96% |
Experimental Protocols
Protocol: Purification of Plasminogen from Human Plasma using this compound-Sepharose 4B
This protocol is a general guideline for the purification of plasminogen, a common application of this compound affinity chromatography.[1][4][7]
Materials:
-
This compound-Sepharose 4B resin
-
Chromatography column
-
Human plasma (or other sample containing plasminogen)
-
Binding Buffer: 50 mM phosphate buffer, pH 7.5
-
Wash Buffer 1: 50 mM phosphate buffer, pH 7.5
-
Wash Buffer 2: 50 mM phosphate buffer with 0.5 M NaCl, pH 7.5
-
Elution Buffer: 50 mM phosphate buffer with 0.2 M ε-aminocaproic acid, pH 7.5
-
Regeneration Buffer 1: 0.1 M Tris-HCl, 0.5 M NaCl, pH 8.5
-
Regeneration Buffer 2: 0.1 M sodium acetate, 0.5 M NaCl, pH 4.5
Procedure:
-
Column Packing and Equilibration:
-
Pack the this compound-Sepharose 4B resin into a suitable chromatography column according to the manufacturer's instructions.
-
Equilibrate the column with 5-10 column volumes (CV) of Binding Buffer.
-
-
Sample Application:
-
Clarify the sample by centrifugation or filtration (0.45 µm filter) to remove any particulate matter.
-
Apply the clarified sample to the equilibrated column at a flow rate recommended by the resin manufacturer.
-
-
Washing:
-
Wash the column with 5-10 CV of Wash Buffer 1 to remove unbound proteins.
-
Wash the column with 5-10 CV of Wash Buffer 2 to remove non-specifically bound proteins. Monitor the UV absorbance (A280) of the flow-through until it returns to baseline.
-
-
Elution:
-
Elute the bound plasminogen from the column with Elution Buffer.
-
Collect fractions and monitor the protein concentration using UV absorbance at 280 nm.
-
-
Column Regeneration:
-
Wash the column with 3-5 CV of Regeneration Buffer 1.
-
Wash the column with 3-5 CV of Regeneration Buffer 2.
-
Repeat this cycle two more times.
-
Finally, re-equilibrate the column with 5-10 CV of Binding Buffer for immediate reuse or store in a suitable storage solution (e.g., 20% ethanol).
-
Visualizations
References
- 1. cdn.cytivalifesciences.com [cdn.cytivalifesciences.com]
- 2. The effects of arginine on protein binding and elution in hydrophobic interaction and ion-exchange chromatography - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. ijbc.ir [ijbc.ir]
- 5. Impact of arginine addition on protein concentration via ultrafiltration - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Troubleshooting Guide for Affinity Chromatography of Tagged Proteins [sigmaaldrich.com]
- 7. Modifications to the this compound Sepharose method of plasminogen purification which ensure plasmin-free Glu-plasminogen - PubMed [pubmed.ncbi.nlm.nih.gov]
Troubleshooting low yield in lysine-specific enzymatic assays
A Technical Support Center for researchers, scientists, and drug development professionals facing challenges with low yield in lysine-specific enzymatic assays.
Frequently Asked Questions (FAQs)
Q1: My this compound-specific enzymatic assay has a very low or no yield. What are the most common initial culprits?
Low yield in enzymatic assays can typically be traced back to a few key areas. The primary factors to investigate are the integrity and activity of your enzyme and substrates, the composition of your reaction buffer, and the physical reaction conditions. It is also crucial to rule out the presence of any inhibiting compounds.[1][2] A systematic check of these components is the most efficient way to identify the problem.
Q2: How can I determine if my enzyme is inactive or has lost activity?
Enzyme inactivity is a common issue. To diagnose this, first ensure the enzyme has been stored correctly (typically at -80°C in a suitable buffer) and has not been subjected to multiple freeze-thaw cycles.[2] The most direct way to verify activity is to perform a control reaction using a known, well-characterized substrate that has previously worked in your assay. If this control reaction also fails, it strongly indicates a problem with the enzyme's viability.
Q3: What are the critical components of an assay buffer that I should optimize?
The reaction buffer is critical for optimal enzyme performance. The key parameters to optimize include:
-
pH: Most enzymes have a narrow optimal pH range. For example, some this compound demethylases like KDM1A show robust activity at a pH of 8.0.[3][4] It's recommended to test a range of pH values.
-
Ionic Strength: Salt concentration can significantly influence enzyme activity. Some enzymes prefer low salt conditions (e.g., 20 mM NaCl), while others may require higher concentrations.[3]
-
Reducing Agents: For enzymes sensitive to oxidation, the choice of reducing agent is important. For instance, Dithiothreitol (DTT) has been shown to support robust KDM1A activity, while Tris(2-carboxyethyl)phosphine (TCEP) can be inhibitory in some cases.[3]
-
Additives: Some enzymes may require cofactors or metal ions for activity. Check the specific requirements for your enzyme.
Q4: Could my substrate be the source of the low yield?
Yes, the substrate is a frequent source of problems. Ensure you verify the concentration and purity of your substrate stock. For peptide substrates, degradation or incorrect synthesis can be an issue. Additionally, the concentration used in the assay is critical; if it is too far below the Michaelis constant (Km), the reaction rate will be inherently low.[5] It can be beneficial to run a substrate titration curve to determine the optimal concentration.[4]
Q5: How do I know if there is an inhibitor in my reaction?
Inhibitors can be introduced through contaminated reagents or may be present in your test samples. Common interfering substances to avoid include EDTA (>0.5 mM), SDS (>0.2%), and sodium azide (>0.2%).[1] If you suspect an inhibitor, you can perform a dilution experiment with your sample. If the apparent activity increases with dilution, it suggests the presence of an inhibitor being diluted out. Additionally, comparing the reaction with a purified control sample versus your experimental sample can help identify sample-specific inhibition.
Troubleshooting Guide: A Systematic Approach to Low Yield
When faced with low experimental yield, a structured troubleshooting workflow can help isolate and resolve the issue efficiently. Start with initial checks of your reagents and experimental setup before moving to more detailed optimization steps.
References
- 1. docs.abcam.com [docs.abcam.com]
- 2. benchchem.com [benchchem.com]
- 3. researchgate.net [researchgate.net]
- 4. Characterization of this compound Acetyltransferase Activity of Recombinant Human ARD1/NAA10 [mdpi.com]
- 5. Measurement of this compound-specific demethylase-1 activity in the nuclear extracts by flow-injection based time-of-flight mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Enhancing the Stability of Lysine-Containing Peptides in Solution
Welcome to the Technical Support Center for researchers, scientists, and drug development professionals. This resource is designed to provide direct, actionable guidance on improving the stability of lysine-containing peptides in solution. Here you will find troubleshooting guides, frequently asked questions (FAQs), and detailed experimental protocols to address common challenges encountered during your research.
Troubleshooting Guides & FAQs
This section addresses specific issues related to the instability of this compound-containing peptides in a question-and-answer format.
FAQ 1: Peptide Degradation
Q1: What are the primary chemical degradation pathways for this compound-containing peptides in solution?
A1: this compound-containing peptides are susceptible to several chemical degradation pathways in solution. The most common include:
-
Oxidation: The ε-amino group of the this compound side chain can be oxidized, leading to the formation of various degradation products. Methionine and Cysteine residues, if present, are also highly prone to oxidation.[1][2] This process can be accelerated by exposure to atmospheric oxygen, trace metal ions, and light.[1]
-
Deamidation: While more common for asparagine and glutamine residues, deamidation can occur under certain conditions and affect the overall stability of the peptide.[1]
-
Hydrolysis: Peptide bonds can be cleaved via hydrolysis, particularly at acidic or alkaline pH. The presence of certain amino acid sequences can make specific peptide bonds more susceptible to cleavage.
-
Cyclization: The ε-amino group of this compound can react with a C-terminal carboxyl group to form a lactam ring, a process known as cyclization. This intramolecular reaction can lead to a loss of biological activity.
Q2: My this compound-containing peptide is showing signs of aggregation. What are the likely causes and how can I prevent it?
A2: Peptide aggregation is a common issue where peptide molecules self-associate to form larger, often insoluble, complexes.[3] Key causes include:
-
pH at or near the isoelectric point (pI): Peptides are least soluble at their pI, where the net charge is zero, leading to increased aggregation.[4]
-
High peptide concentration: Increased concentration promotes intermolecular interactions.[3]
-
Temperature: Elevated temperatures can increase the rate of aggregation.
-
Ionic strength: The effect of salt concentration can be complex, either shielding charges to reduce repulsion or promoting hydrophobic interactions.[4]
To prevent aggregation:
-
Adjust the pH: Ensure the solution pH is at least one to two units away from the peptide's pI.[4]
-
Optimize concentration: Work with the lowest feasible peptide concentration.
-
Control temperature: Store peptide solutions at recommended low temperatures (e.g., -20°C or -80°C) and avoid repeated freeze-thaw cycles.[5]
-
Use excipients: Certain excipients, such as arginine, can help to reduce aggregation.
-
Gentle handling: Avoid vigorous shaking or stirring which can induce aggregation.[4]
FAQ 2: Formulation and Storage
Q3: What is the optimal pH range for storing this compound-containing peptides?
A3: The optimal pH for storing this compound-containing peptides is highly sequence-dependent. However, a general guideline is to maintain the pH in a slightly acidic range (pH 4-6).[6] This is because:
-
At acidic to neutral pH, the primary and ε-amino groups of this compound are protonated, which can help to maintain solubility and reduce aggregation through electrostatic repulsion.[7]
-
Alkaline conditions (pH > 8) should generally be avoided as they can accelerate the oxidation of the this compound side chain and promote other degradation pathways.[2]
It is crucial to perform a pH stability study for your specific peptide to determine the optimal pH for long-term storage.
Q4: Which excipients are most effective for stabilizing this compound-containing peptides in solution?
A4: Several types of excipients can be used to enhance the stability of peptide formulations:
-
Buffers: Phosphate, citrate, and acetate buffers are commonly used to maintain the optimal pH. The choice of buffer can significantly impact stability, so it is important to screen different buffer systems.[1]
-
Sugars and Polyols: Sucrose, trehalose, and mannitol are often used as cryoprotectants and lyoprotectants during freeze-drying and can also improve stability in solution by promoting a more compact peptide conformation.
-
Amino Acids: Arginine and glycine can act as stabilizers by reducing aggregation and surface adsorption.
-
Antioxidants: If oxidation is a concern, adding antioxidants like methionine or ascorbic acid can be beneficial.
-
Surfactants: Non-ionic surfactants such as polysorbate 20 or 80 can prevent surface adsorption and aggregation.
The effectiveness of an excipient is peptide-specific, and a systematic screening study is recommended to identify the best stabilizer for your formulation.
Q5: Is lyophilization a good strategy to improve the long-term stability of this compound-containing peptides?
A5: Yes, lyophilization (freeze-drying) is an excellent strategy for enhancing the long-term stability of peptides.[5][8] By removing water, it significantly reduces the rates of hydrolytic degradation, oxidation, and other chemical reactions.[8] Lyophilized peptides, when stored properly (at -20°C or -80°C and protected from moisture and light), can be stable for years.[5] It is important to optimize the lyophilization cycle and formulation (including the use of lyoprotectants) to ensure the peptide's integrity is maintained throughout the process.[9][10]
Data Presentation
The following tables summarize quantitative data on factors affecting the stability of this compound-containing peptides.
Table 1: Effect of pH on the Degradation of this compound Hydrochloride in Solution
| pH | Temperature (°C) | Degradation Rate Constant (mg/mL/h) |
| 10.3 | 60 | Data not available in source |
| 10.3 | 80 | ~0.02 |
| 10.3 | 90 | ~0.04 |
| 10.3 | 100 | ~0.08 |
Data derived from graphical representation in the source. The study showed that degradation rates increased with decreasing pH values.[11]
Table 2: Effect of Buffer Type on this compound Glycation Rate in a Monoclonal Antibody
| Buffer Type | Relative Glycation Rate (Normalized to Media) |
| Cell Culture Media | 1.00 |
| HEPES | ~0.95 |
| Citrate | ~0.90 |
| Bicarbonate | >2.50 |
Data qualitatively interpreted from correlation plots. Bicarbonate buffer was shown to have a highly stimulatory effect on this compound glycation.[12][13]
Experimental Protocols
Detailed methodologies for key experiments are provided below.
Protocol 1: HPLC-Based Peptide Stability Assay
This protocol outlines a general method for assessing the chemical stability of a this compound-containing peptide in solution over time.
Objective: To quantify the percentage of intact peptide remaining after incubation under various stress conditions (e.g., different pH, temperature).
Materials:
-
Lyophilized peptide
-
Purified water (HPLC grade)
-
Acetonitrile (HPLC grade)
-
Trifluoroacetic acid (TFA)
-
Buffers of desired pH (e.g., phosphate, citrate, acetate)
-
HPLC system with a UV detector
-
Reversed-phase C18 column (e.g., 4.6 x 250 mm)[6]
Procedure:
-
Peptide Stock Solution Preparation: Dissolve the lyophilized peptide in an appropriate solvent (e.g., purified water) to create a concentrated stock solution.
-
Sample Preparation: Dilute the stock solution into different buffer solutions to the desired final concentration for the stability study.
-
Incubation: Aliquot the peptide solutions into vials and incubate them at the desired temperatures.
-
Time-Point Sampling: At specified time points (e.g., 0, 24, 48, 72 hours), withdraw an aliquot from each sample and immediately quench any ongoing reaction by freezing at -80°C or by adding an equal volume of a quenching solution (e.g., 1% TFA in acetonitrile).
-
HPLC Analysis:
-
Data Analysis:
-
Integrate the peak area of the intact peptide at each time point.
-
Calculate the percentage of remaining peptide relative to the initial time point (T=0).
-
Plot the percentage of remaining peptide versus time for each condition to determine the degradation rate.
-
Protocol 2: Thermal Shift Assay (TSA) for Peptide Stability
This protocol describes a method to assess the thermal stability of a peptide by measuring its melting temperature (Tm) under different formulation conditions.[4][14][15]
Objective: To determine the optimal buffer conditions that enhance the thermal stability of a peptide.
Materials:
-
Peptide of interest
-
SYPRO Orange dye (5000x stock)[4]
-
A panel of buffers at various pH values and ionic strengths
-
96-well PCR plates[4]
Procedure:
-
Prepare Protein-Dye Mixture: Dilute the peptide stock to a final concentration of 5 µM and add SYPRO Orange dye to a final concentration of 2x in a suitable dilution buffer.[4]
-
Set up 96-well Plate:
-
In each well of a 96-well PCR plate, add a specific buffer from your screening panel.
-
Add the protein-dye mixture to each well.
-
The final volume in each well should be consistent (e.g., 20 µL).
-
-
Thermal Denaturation:
-
Place the plate in a real-time PCR instrument.
-
Set up a melt curve experiment with a temperature ramp from 25°C to 95°C, with a ramp rate of 1°C/minute.
-
Monitor the fluorescence of SYPRO Orange at each temperature increment.
-
-
Data Analysis:
-
The instrument software will generate a melt curve (fluorescence vs. temperature).
-
The melting temperature (Tm) is the midpoint of the transition in the melt curve, which can be determined from the peak of the first derivative plot.
-
Compare the Tm values across the different buffer conditions. A higher Tm indicates greater thermal stability.[15]
-
Protocol 3: Mass Spectrometry (MS) for Identification of Degradation Products
This protocol provides a general workflow for identifying the degradation products of a this compound-containing peptide using LC-MS/MS.[8]
Objective: To characterize the chemical modifications and cleavage products resulting from peptide degradation.
Materials:
-
Degraded peptide sample (from a stability study)
-
LC-MS/MS system (e.g., Orbitrap)[16]
-
C18 nano-LC column[16]
-
Formic acid
-
Acetonitrile
-
Protein sequence database search software (e.g., PEAKS, Mascot)[16]
Procedure:
-
Sample Preparation:
-
LC-MS/MS Analysis:
-
Inject the sample onto the nano-LC column.
-
Elute the peptides using a gradient of acetonitrile in 0.1% formic acid.
-
Acquire mass spectra in a data-dependent acquisition (DDA) mode, where the most intense precursor ions are selected for fragmentation (MS/MS).[8]
-
-
Data Analysis:
-
Process the raw data to identify the masses of the parent peptide and any new species.
-
Use database search software to search the MS/MS spectra against the known sequence of the peptide, allowing for common modifications (e.g., oxidation, deamidation, cyclization).
-
Manually inspect the MS/MS spectra to confirm the identity and location of the modifications.
-
Mandatory Visualizations
// Nodes Intact_Peptide [label="Intact this compound-\nContaining Peptide", fillcolor="#4285F4", fontcolor="#FFFFFF"]; Oxidized_Peptide [label="Oxidized Peptide\n(+16 Da)", fillcolor="#EA4335", fontcolor="#FFFFFF"]; Cyclized_Peptide [label="Cyclized Peptide\n(Lactam Formation)", fillcolor="#FBBC05", fontcolor="#FFFFFF"]; Hydrolyzed_Fragments [label="Hydrolyzed\nFragments", fillcolor="#34A853", fontcolor="#FFFFFF"]; Aggregated_Peptide [label="Aggregated\nPeptide", fillcolor="#5F6368", fontcolor="#FFFFFF"];
// Edges Intact_Peptide -> Oxidized_Peptide [label="Oxidizing Agents\n(O2, Metal Ions)"]; Intact_Peptide -> Cyclized_Peptide [label="Intramolecular\nReaction"]; Intact_Peptide -> Hydrolyzed_Fragments [label="pH Extremes\nTemperature"]; Intact_Peptide -> Aggregated_Peptide [label="High Concentration\npH near pI"]; } ` Caption: Key degradation pathways for this compound-containing peptides in solution.
// Connections B -> C; B -> D; B -> E; C -> F; D -> G; E -> H; } ` Caption: A typical experimental workflow for assessing peptide stability.
// Nodes start [label="Peptide Aggregation\nObserved?", shape=ellipse, fillcolor="#4285F4"]; check_pH [label="Is pH far from pI?"]; check_conc [label="Is concentration high?"]; check_temp [label="Are storage conditions\noptimal?"]; adjust_pH [label="Adjust pH to be >1 unit\naway from pI", rect_node=true, fillcolor="#34A853"]; lower_conc [label="Reduce peptide\nconcentration", rect_node=true, fillcolor="#34A853"]; optimize_storage [label="Store at -20°C or -80°C\nAvoid freeze-thaw", rect_node=true, fillcolor="#34A853"]; add_excipients [label="Consider adding\nstabilizing excipients\n(e.g., Arginine)", rect_node=true, fillcolor="#FBBC05"]; end_node [label="Aggregation Minimized", shape=ellipse, fillcolor="#34A853"];
// Edges start -> check_pH; check_pH -> check_conc [label="Yes"]; check_pH -> adjust_pH [label="No"]; adjust_pH -> check_conc; check_conc -> check_temp [label="No"]; check_conc -> lower_conc [label="Yes"]; lower_conc -> check_temp; check_temp -> add_excipients [label="Yes"]; check_temp -> optimize_storage [label="No"]; optimize_storage -> add_excipients; add_excipients -> end_node; } ` Caption: A logical workflow for troubleshooting peptide aggregation issues.
References
- 1. Designing Formulation Strategies for Enhanced Stability of Therapeutic Peptides in Aqueous Solutions: A Review - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Design, synthesis, and structural characterization of this compound covalent BH3 peptides targeting Mcl-1 - PMC [pmc.ncbi.nlm.nih.gov]
- 3. bio-rad.com [bio-rad.com]
- 4. Current Protocols in Protein Science: Analysis of protein stability and ligand interactions by thermal shift assay - PMC [pmc.ncbi.nlm.nih.gov]
- 5. verifiedpeptides.com [verifiedpeptides.com]
- 6. mdpi.com [mdpi.com]
- 7. ri.conicet.gov.ar [ri.conicet.gov.ar]
- 8. benchchem.com [benchchem.com]
- 9. pci.com [pci.com]
- 10. Lyophilization cycle optimization - Why you should use Tempris [tempris.com]
- 11. researchgate.net [researchgate.net]
- 12. Effects of Buffer Composition on Site-Specific Glycation of this compound Residues in Monoclonal Antibodies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. Thermal shift assay - Wikipedia [en.wikipedia.org]
- 15. documents.thermofisher.com [documents.thermofisher.com]
- 16. documents.thermofisher.com [documents.thermofisher.com]
Strategies to minimize lysine side reactions during peptide synthesis
This guide provides researchers, scientists, and drug development professionals with in-depth strategies and troubleshooting advice to minimize side reactions involving lysine residues during solid-phase peptide synthesis (SPPS).
Frequently Asked Questions (FAQs)
Q1: What is the most common side reaction involving this compound during SPPS?
A1: The nucleophilic nature of this compound's ε-amino group makes it susceptible to several side reactions. The most common issues include:
-
Unwanted Acylation: If the side-chain amino group is not properly protected, it can be acylated by the incoming activated amino acid, leading to branched peptides. This is prevented by ensuring the stability of the side-chain protecting group during Nα-Fmoc deprotection.[1]
-
Guanidinylation: When using carbodiimide-based coupling reagents (e.g., DIC), the activated carboxylic acid can react with the ε-amino group of an unprotected or prematurely deprotected this compound to form a guanidinium group, resulting in a +42 Da modification. Using uronium/aminium-based reagents like HBTU or HATU can mitigate this issue.[2]
-
Trifluoroacetylation (TFAcylation): During the final TFA cleavage, trifluoroacetylating species can be generated, which can modify free amino groups, including the this compound side chain.[3] This results in a +96 Da modification. Using scavengers in the cleavage cocktail helps to minimize this.
Q2: I see a mass addition of +56 Da on my this compound-containing peptide. What is the likely cause?
A2: A mass addition of +56 Da corresponds to the tert-butylation of the this compound side chain. The tert-butyl cation is generated during the cleavage of tert-butyl-based protecting groups (like Boc on Lys, or tBu on Ser, Thr, Tyr).[1][4] This highly reactive cation can alkylate nucleophilic residues like this compound if it is not effectively captured by scavengers.
Solution: Ensure your TFA cleavage cocktail contains an adequate amount of scavengers. A common and effective scavenger is triisopropylsilane (TIS), which efficiently quenches the tert-butyl cation. A standard cleavage cocktail is TFA/TIS/H₂O (95:2.5:2.5).[5]
Q3: How do I choose the right protecting group for my this compound side chain?
A3: The choice depends on your synthetic strategy.
-
For standard linear peptides (Fmoc/tBu strategy): Fmoc-Lys(Boc)-OH is the most common and robust choice. The Boc group is stable to the piperidine used for Fmoc removal but is cleanly cleaved by TFA at the end of the synthesis.[6]
-
For on-resin side-chain modification (e.g., labeling, branching, cyclization): An "orthogonal" protecting group is required. These groups can be removed under conditions that do not affect the Nα-Fmoc group, other side-chain protecting groups, or the resin linkage. Popular choices include Mtt, Mmt, Dde, ivDde, and Alloc.[6][7]
Troubleshooting Guide: Orthogonal Protection & Deprotection
Problem: I need to attach a molecule to a specific this compound side chain while the peptide is still on the resin, but I'm not sure which protecting group to use.
Solution: You need an orthogonal protection strategy. This involves using a this compound derivative with a side-chain protecting group that can be removed selectively. The table below compares common orthogonal protecting groups.
Table 1: Comparison of Common Orthogonal Protecting Groups for this compound
| Protecting Group | Chemical Name | Cleavage Condition | Stable To | Notes |
| Boc | tert-Butoxycarbonyl | Strong Acid (e.g., >90% TFA) | Piperidine, Mild Acid, Pd(0) | Standard, non-orthogonal protection.[6] |
| Mtt | 4-Methyltrityl | Mild Acid (e.g., 1% TFA in DCM) | Piperidine, Hydrazine, Pd(0) | Very acid sensitive. Ideal for selective deprotection.[7][8] |
| Mmt | 4-Methoxytrityl | Very Mild Acid (e.g., AcOH/TFE/DCM) | Piperidine, Hydrazine, Pd(0) | More acid-labile than Mtt; useful if Mtt removal is difficult.[7][8] |
| Dde | 1-(4,4-Dimethyl-2,6-dioxocyclohex-1-ylidene)ethyl | 2% Hydrazine in DMF | TFA, Piperidine, Pd(0) | Base-labile; orthogonal to acid-labile groups.[7][9] |
| ivDde | 1-(4,4-Dimethyl-2,6-dioxocyclohex-1-ylidene)-3-methylbutyl | 2% Hydrazine in DMF | TFA, Piperidine, Pd(0) | Similar to Dde but with different steric and electronic properties.[7] |
| Alloc | Allyloxycarbonyl | Pd(0) catalyst (e.g., Pd(PPh₃)₄) | TFA, Piperidine, Hydrazine | Useful when acid- and base-labile groups must be preserved.[6] |
| Tfa | Trifluoroacetyl | Aqueous Base (e.g., 20% Piperidine in H₂O) | Strong Acid (TFA) | Stable to final cleavage; requires a separate basic step for removal.[3][10] |
Workflow for On-Resin this compound Modification
The following diagram illustrates a typical workflow for selectively modifying a this compound side chain using an orthogonal protecting group like Mtt.
Caption: Workflow for orthogonal protection and on-resin this compound modification.
Experimental Protocols
Protocol 1: Selective Deprotection of the Mtt Group
This protocol describes the removal of the 4-Methyltrityl (Mtt) group from a this compound side chain while the peptide is attached to the resin.
Reagents:
-
Deprotection Solution: 1-2% Trifluoroacetic acid (TFA) with 2-5% Triisopropylsilane (TIS) in Dichloromethane (DCM).
-
Washing Solvents: DCM, Dimethylformamide (DMF).
-
Neutralization Solution: 10% N,N-Diisopropylethylamine (DIPEA) in DMF.
Methodology:
-
Swell the peptide-resin in DCM for 20 minutes.
-
Drain the solvent.
-
Add the Deprotection Solution to the resin and gently agitate.
-
Repeat the treatment every 2-3 minutes for a total of 10-20 minutes. Monitor the cleavage by observing the yellow color of the Mtt cation in the solution.
-
Drain the solution and wash the resin thoroughly with DCM (5 times).
-
Wash the resin with the Neutralization Solution (2 times) to remove any residual acid.
-
Wash the resin with DMF (5 times) to prepare for the subsequent coupling reaction.
-
Confirm the presence of a free primary amine using a qualitative test (e.g., Kaiser test).[11]
Protocol 2: Selective Deprotection of the Dde Group
This protocol describes the removal of the 1-(4,4-Dimethyl-2,6-dioxocyclohex-1-ylidene)ethyl (Dde) group.
Reagents:
-
Deprotection Solution: 2% Hydrazine monohydrate in DMF.
-
Washing Solvent: DMF.
Methodology:
-
Swell the peptide-resin in DMF for 20 minutes.
-
Drain the solvent.
-
Add the Deprotection Solution to the resin and agitate for 3 minutes.
-
Drain and repeat the treatment one more time for 7-10 minutes.[7]
-
Drain the solution and wash the resin thoroughly with DMF (5-7 times) to remove all traces of hydrazine.
-
Confirm the presence of a free primary amine using a qualitative test (e.g., Kaiser test).
Troubleshooting Common Impurities
This section provides a logical workflow for identifying the source of unexpected impurities related to this compound.
Table 2: Common this compound-Related Impurities and Mass Shifts
| Mass Shift (Da) | Identity of Adduct | Likely Cause | Prevention Strategy |
| +42 | Acetylation / Guanidinylation | Acetyl capping (from Ac₂O) or reaction with carbodiimide activators.[2] | Use uronium/aminium activators (HBTU, HATU). Avoid acetic anhydride in capping steps if Lys(Boc) is not fully stable. |
| +56 | tert-Butylation | Reaction with t-butyl cations generated during TFA cleavage.[4] | Use scavengers like TIS or EDT in the cleavage cocktail. |
| +96 | Trifluoroacetylation | Reaction with TFA byproducts during cleavage.[3] | Use a well-formulated cleavage cocktail with scavengers (e.g., Reagent K). |
| -1 (or -18) | Lactam Formation | Intramolecular cyclization between a C-terminal Lys and a side-chain carboxylate (Asp/Glu). | Use HMPB or other highly acid-labile resins. Optimize coupling conditions to avoid premature side-chain deprotection. |
Troubleshooting Decision Tree
If you observe an unexpected peak in your HPLC/MS analysis, use this diagram to diagnose the potential issue.
Caption: Decision tree for troubleshooting this compound-related impurities.
References
- 1. peptide.com [peptide.com]
- 2. mesalabs.com [mesalabs.com]
- 3. benchchem.com [benchchem.com]
- 4. peptide.com [peptide.com]
- 5. benchchem.com [benchchem.com]
- 6. benchchem.com [benchchem.com]
- 7. Selecting Orthogonal Building Blocks [sigmaaldrich.com]
- 8. nbinno.com [nbinno.com]
- 9. drivehq.com [drivehq.com]
- 10. benchchem.com [benchchem.com]
- 11. benchchem.com [benchchem.com]
Technical Support Center: Mass Spectrometric Identification of Lysine Modifications
Welcome to the technical support center for researchers, scientists, and drug development professionals. This resource provides troubleshooting guidance and answers to frequently asked questions (FAQs) to help you overcome common challenges in the mass spectrometric (MS) identification of lysine post-translational modifications (PTMs), such as acetylation, ubiquitination, and methylation.
Frequently Asked Questions (FAQs)
Q1: Why are this compound modifications so challenging to identify by mass spectrometry?
A1: The identification of this compound modifications is inherently challenging due to several factors.[1] These modifications often exist at a low stoichiometry, meaning only a small fraction of a specific protein is modified at any given time.[2][3] Furthermore, some modifications, like methylation, introduce very subtle mass changes that require high-resolution mass spectrometers for detection.[4] The labile nature of certain PTMs can lead to their loss during sample preparation or MS analysis.[5] Finally, the vast number of potential modification sites and types creates significant bioinformatics challenges in data analysis.[1]
Q2: My protein digestion with trypsin is inefficient for my protein of interest. What could be the cause?
A2: This is a common issue, particularly with this compound modifications like acetylation. Trypsin, the most commonly used protease, cleaves at the C-terminal side of this compound and arginine residues.[5] However, when a this compound residue is acetylated, its charge is neutralized, which can impair or block tryptic cleavage at that site.[5][6] This leads to incomplete digestion, longer or "miscleaved" peptides, and can complicate database searching.[6] For highly modified proteins like histones, which are rich in this compound, this effect is particularly pronounced, often resulting in peptides that are too short for effective analysis.[5]
Q3: What is the purpose of an enrichment step and when is it necessary?
A3: An enrichment step is crucial for most PTM analyses due to the low abundance of modified peptides in a complex biological sample.[2][3] This process isolates and concentrates the modified peptides, increasing their signal-to-noise ratio and improving the chances of detection by the mass spectrometer.[7] Immunoaffinity enrichment, using antibodies that specifically recognize a PTM (e.g., an anti-acetyl-lysine antibody), is one of the most widely used strategies.[3][8] Enrichment is almost always necessary for comprehensive, proteome-wide PTM studies.
Q4: Which fragmentation method (CID, HCD, ETD) is best for analyzing this compound-modified peptides?
A4: The choice of fragmentation method depends on the specific modification and the peptide's properties.
-
Collision-Induced Dissociation (CID) and Higher-Energy C-trap Dissociation (HCD): These are the most common methods.[9] HCD, particularly on Orbitrap instruments, is widely used as it preserves low-mass diagnostic ions which can be crucial for PTM identification (e.g., the acetyl-lysine immonium ion at m/z 126.1).[2][10][11] However, these methods can sometimes lead to the loss of labile PTMs.[12]
-
Electron Transfer Dissociation (ETD): ETD is a non-ergodic fragmentation technique that is advantageous for analyzing labile PTMs and for sequencing larger, highly charged peptides, which are often generated when tryptic cleavage is blocked by modifications.[6][9][12] It has been shown to identify a higher number of ubiquitinated peptides compared to CID and HCD.[12]
Experimental Workflows & Logical Relationships
The following diagrams illustrate key workflows and decision-making processes in the analysis of this compound modifications.
Caption: General experimental workflow for proteome-wide analysis of this compound modifications.
Caption: Troubleshooting logic for inefficient protein digestion in PTM analysis.
Troubleshooting Guide
| Problem / Observation | Possible Cause(s) | Suggested Solution(s) |
| Low number of identified modified peptides after enrichment | 1. Inefficient Enrichment: Antibody may have low affinity, specificity, or be from a poor batch.[3] 2. Low Abundance PTM: The modification may be extremely rare or transient in your specific sample. 3. Sample Loss: Peptides lost during washing steps of the enrichment protocol. | 1. Test a different antibody or a cocktail of antibodies from different vendors.[5] Consider alternative enrichment methods if available (e.g., methyl-lysine binding domains).[13] 2. Increase the amount of starting material (protein digest) for the enrichment.[14] 3. Optimize washing steps; ensure buffers are fresh and at the correct pH. |
| Confident peptide ID, but ambiguous PTM site localization | 1. Poor Fragmentation: Insufficient fragment ions generated to pinpoint the exact modified residue. 2. Isobaric Modifications: Different modifications with the same nominal mass (e.g., trimethylation vs. acetylation) can be confused without high mass accuracy.[2] 3. Multiple Potential Sites: The identified peptide contains multiple lysines, and the fragmentation data does not distinguish between them. | 1. Re-analyze the sample using an alternative fragmentation method (e.g., if you used HCD, try ETD).[6] 2. Ensure high mass accuracy is used for both precursor and fragment ions. Use a search algorithm that calculates site localization probability (e.g., PTM-Score, Ascore). 3. Use an alternative protease to generate different, overlapping peptides that can confirm the site.[6] |
| High number of unmodified peptides co-eluting with enriched fraction | 1. Non-specific Binding: Peptides are binding to the antibody or beads non-specifically. 2. Antibody Specificity Issues: The antibody may have cross-reactivity with unmodified peptide sequences or motifs.[3][5] | 1. Increase the stringency of the wash buffers (e.g., increase salt concentration). Optimize the number and duration of wash steps. 2. Ensure the antibody has been validated for specificity. If possible, test a different antibody clone. |
| Inconsistent quantification results between replicates | 1. Variable Enrichment Efficiency: Inconsistent antibody-to-peptide ratio or incubation times. 2. Chromatography Issues: Inconsistent LC performance leading to shifts in retention time and peak area. 3. Sample Handling Variation: Inconsistent protein quantification, digestion, or desalting. | 1. Carefully control incubation times and temperatures. Ensure beads are fully resuspended during incubation.[8] Use a stable isotope-labeled internal standard peptide if performing targeted analysis.[15] 2. Perform LC system suitability tests before running samples. 3. Standardize all upstream sample preparation steps. Use robust protein quantification assays. |
Quantitative Data Summary
Table 1: Comparison of Proteolytic Enzymes for Glycated Peptide Identification
This table summarizes the number of unique glycated peptides and proteins identified from a complex mixture using different proteases, highlighting the impact of enzyme choice on PTM analysis. Data is adapted from a study on boronate affinity enrichment of glycated peptides.[16]
| Proteolytic Enzyme | Average Unique Glycated Peptides Identified | Average Unique Glycated Proteins Identified | Key Consideration |
| Trypsin | 135 | 58 | Standard protease; cleavage can be inhibited by some this compound modifications.[5] |
| Lys-C | 142 | 61 | Cleaves at this compound; comparable to trypsin in this study for generating identifiable peptides.[16] |
| Arg-C | 78 | 41 | Cleaves at arginine; useful when trying to avoid cleavage at modified lysines.[6] |
Table 2: Comparison of Fragmentation Methods for PTM Peptide Identification
The choice of fragmentation technique significantly impacts the quality of MS/MS spectra and the confidence of PTM identification.
| Fragmentation Method | Primary Advantage(s) | Primary Disadvantage(s) | Best Suited For |
| CID (Collision-Induced Dissociation) | Fast, robust, and widely available. | Can result in the loss of labile PTMs; low-mass ion cutoff can lose diagnostic ions.[2] | Routine analysis of stable PTMs on smaller, doubly-charged peptides. |
| HCD (Higher-Energy C-trap Dissociation) | Produces high-resolution fragment spectra; no low-mass cutoff, preserving diagnostic ions.[2][9] | Can cause over-fragmentation of highly charged peptides.[2] Slower scan speed than ion trap CID.[9] | Comprehensive identification of stable PTMs, especially when diagnostic ions are critical (e.g., acetylation).[2][10] |
| ETD (Electron Transfer Dissociation) | Preserves labile PTMs; effective for highly-charged and longer peptides.[9][12] | Less efficient for doubly-charged precursors; can result in incomplete fragmentation.[10] | Analysis of labile modifications (e.g., phosphorylation, glycosylation) and for "middle-down" approaches.[6][12] |
Key Experimental Protocol
Detailed Protocol: Immunoaffinity Enrichment of Acetyl-Lysine Peptides
This protocol provides a generalized method for enriching peptides containing acetylated this compound residues from a complex protein digest using modification-specific antibodies.[8]
Materials:
-
Anti-acetyl-lysine antibody conjugated to agarose beads (e.g., PTMScan® Acetyl-Lysine Motif [Ac-K] Immunoaffinity Beads).
-
Tryptic peptide digest (desalted), starting with a recommended minimum of 5 mg of total protein.[14]
-
Immunoaffinity Purification (IAP) Buffer (e.g., 50 mM MOPS, pH 7.2, 10 mM sodium phosphate, 50 mM NaCl).
-
Wash Buffer (e.g., IAP Buffer).
-
Water (HPLC-grade).
-
Elution Buffer (e.g., 0.15% Trifluoroacetic Acid, TFA).
-
Microcentrifuge tubes, spinning wheel/rocker.
Methodology:
-
Bead Preparation:
-
Thoroughly resuspend the antibody-bead slurry.
-
Aliquot the required amount of slurry into a new microcentrifuge tube (typically 20-40 µL of bead slurry per 5 mg of peptide digest).
-
Wash the beads: Add 1 mL of IAP buffer, gently mix, centrifuge at 2,000 x g for 30 seconds, and carefully discard the supernatant. Repeat this wash step twice.
-
-
Peptide Binding:
-
Resuspend the lyophilized peptide digest in 200 µL of IAP buffer. Centrifuge to pellet any insoluble material and transfer the supernatant to the tube containing the washed beads.
-
Incubate the peptide-bead mixture for 1-2 hours at 4°C with gentle rocking or rotation to ensure the beads remain in suspension.[8][17]
-
-
Washing:
-
After incubation, centrifuge the tube to pellet the beads and discard the supernatant (this is the unbound fraction).
-
Wash the beads by adding 1 mL of IAP buffer. Gently invert the tube several times, centrifuge, and discard the supernatant. Repeat for a total of three washes with IAP buffer.
-
Perform two additional washes with HPLC-grade water to remove salts from the IAP buffer. Ensure all supernatant is carefully removed after the final wash without disturbing the bead pellet.
-
-
Elution:
-
Add 50-100 µL of Elution Buffer (0.15% TFA) to the bead pellet.
-
Vortex briefly and incubate at room temperature for 5-10 minutes.
-
Centrifuge to pellet the beads and carefully transfer the supernatant, which contains the enriched acetylated peptides, to a new clean tube.
-
Repeat the elution step once more and combine the eluates.
-
-
Post-Elution Cleanup:
-
Immediately desalt the eluted peptides using a C18 StageTip or equivalent micro-elution plate to remove any residual contaminants and prepare the sample for LC-MS/MS analysis.
-
Dry the cleaned peptides in a vacuum centrifuge and resuspend in a suitable buffer for MS injection (e.g., 0.1% formic acid).
-
References
- 1. The challenge of detecting modifications on proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. mdpi.com [mdpi.com]
- 3. Mass Spectrometry for this compound Methylation: Principles, Progress, and Prospects - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Mass Spectrometry for this compound Methylation: Principles, Progress, and Prospects - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. portlandpress.com [portlandpress.com]
- 6. Discovery of this compound post-translational modifications through mass spectrometric detection - PMC [pmc.ncbi.nlm.nih.gov]
- 7. portlandpress.com [portlandpress.com]
- 8. Enrichment of Modified Peptides via Immunoaffinity Precipitation with Modification-Specific Antibodies - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. pubs.acs.org [pubs.acs.org]
- 10. ProteomeTools: Systematic Characterization of 21 Post-translational Protein Modifications by Liquid Chromatography Tandem Mass Spectrometry (LC-MS/MS) Using Synthetic Peptides - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Mass Spectrometric Identification of Novel this compound Acetylation Sites in Huntingtin - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Current Methods of Post-Translational Modification Analysis and Their Applications in Blood Cancers - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Proteome-wide enrichment of proteins modified by this compound methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Quantification and Identification of Post-Translational Modifications Using Modern Proteomics Approaches - PMC [pmc.ncbi.nlm.nih.gov]
- 15. youtube.com [youtube.com]
- 16. Improved Methods for the Enrichment and Analysis of Glycated Peptides - PMC [pmc.ncbi.nlm.nih.gov]
- 17. immunechem.com [immunechem.com]
How to increase the efficiency of lysine labeling in live cells
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to help researchers, scientists, and drug development professionals increase the efficiency of lysine labeling in live cells.
Frequently Asked Questions (FAQs)
Q1: What are the key methods for this compound labeling in live cells?
A1: The primary methods involve the use of non-canonical amino acid tagging (ncAA), where a this compound analog containing a bioorthogonal handle (e.g., an azide or alkyne group) is metabolically incorporated into newly synthesized proteins.[1] This is often referred to as Bio-Orthogonal Non-Canonical Amino Acid Tagging (BONCAT) or fluorescent non-canonical amino acid tagging (FUNCAT).[1][2] Following incorporation, the handle is detected via a "click chemistry" reaction with a complementary probe (e.g., a fluorophore or biotin).[1][3]
Q2: Which "click chemistry" reaction should I choose for live-cell labeling: CuAAC or SPAAC?
A2: The choice depends on the trade-off between reaction speed and biocompatibility.[4]
-
Copper(I)-Catalyzed Azide-Alkyne Cycloaddition (CuAAC): This reaction is very fast and efficient but requires a copper catalyst, which can be toxic to live cells.[4][5] The use of copper-chelating ligands like THPTA or BTTAA is essential to minimize cytotoxicity.[6][7] CuAAC is often preferred for labeling in cell lysates where toxicity is not a concern.[8]
-
Strain-Promoted Azide-Alkyne Cycloaddition (SPAAC): This is a catalyst-free reaction that uses a strained cyclooctyne (e.g., DBCO, BCN) that readily reacts with an azide.[4][6] It is highly biocompatible and the preferred method for long-term live-cell imaging, although its reaction kinetics are generally slower than CuAAC.[4][8]
Q3: How do I determine the optimal concentration of the this compound analog?
A3: The optimal concentration is a balance between maximizing incorporation and minimizing cytotoxicity. It is cell-type dependent and should be determined empirically. Start with a concentration range reported in the literature (e.g., 25-250 µM) and perform a dose-response curve.[9][10] Assess both labeling intensity (via fluorescence or western blot) and cell viability (e.g., using an MTT assay or live/dead staining).[10][11] In some cases, concentrations as low as 10-50 µM can be effective while minimizing cellular stress.[9][12]
Q4: How long should I incubate my cells with the this compound analog?
A4: The incubation time depends on the protein synthesis rate of your cell line and the specific biological question. For rapidly dividing cells, labeling can be detected in as little as 1-4 hours.[2][13] For a more comprehensive labeling of the proteome, longer incubation times (e.g., 24-48 hours) may be necessary. It is crucial to ensure the analog concentration used is not toxic over this period. Shorter, acute exposure times followed by an incorporation phase in fresh media can also mitigate toxicity while maintaining good labeling efficiency.[9][14]
Troubleshooting Guides
This guide provides a systematic approach to troubleshooting common issues encountered during this compound labeling experiments.
Problem 1: Low or No Fluorescent Signal
This is the most frequent issue, indicating inefficient labeling at one or more stages of the workflow.
| Potential Cause | Recommended Solution | Citations |
| Inefficient Analog Incorporation | Optimize this compound Analog Concentration: Perform a dose-response experiment to find the optimal concentration for your cell type. Increase Incubation Time: Extend the labeling period to allow for more protein turnover, but monitor for cytotoxicity. Deplete Natural this compound: Briefly culture cells in this compound-free medium before adding the analog to increase its relative availability. | [9][10] [2][14] [1] |
| Poor Click Reaction Efficiency | Check Reagent Quality: Use fresh, high-quality click chemistry reagents. Prepare sodium ascorbate solution fresh for each CuAAC experiment as it readily oxidizes. Optimize Reagent Concentrations: Titrate the concentration of the fluorescent probe; a 2- to 10-fold molar excess over the incorporated analog is a good starting point. Increase Reaction Time/Temp: For in vitro reactions (lysates), increase incubation time (e.g., up to 2 hours) or temperature. For live cells, this is limited by cell viability. | [6][15] [6] [16] |
| Degraded Reagents | Proper Storage: Store this compound analogs, fluorescent probes, and click chemistry reagents as recommended by the manufacturer, protected from light and moisture. Avoid repeated freeze-thaw cycles. | [9] |
| Probe Inaccessibility | Use Permeabilizing Agents: For intracellular targets in fixed cells, ensure adequate permeabilization (e.g., with Triton X-100 or saponin). Denature Proteins (for lysates): If labeling in lysate, consider adding a denaturant like SDS (e.g., 1%) to unfold proteins and expose the incorporated analog. | [13][17][18] [16][19] |
Problem 2: High Background or Non-Specific Labeling
High background fluorescence can obscure the specific signal from your labeled proteins.
| Potential Cause | Recommended Solution | Citations |
| Non-specific Probe Binding | Increase Wash Steps: After incubating with the fluorescent probe, increase the number and duration of wash steps with PBS or an appropriate buffer to remove unbound probe. Use a Blocking Agent: Add a blocking agent like Bovine Serum Albumin (BSA) to your buffers, especially for fixed-cell staining. Reduce Probe Concentration: High probe concentrations can lead to non-specific binding. Titrate down to the lowest effective concentration. | [9] [17] [9] |
| Interfering Substances | Avoid Tris Buffers for CuAAC: The amine groups in Tris buffer can chelate copper, inhibiting the reaction. Use non-chelating buffers like PBS or HEPES. Remove Thiols: If your lysate contains high concentrations of reducing agents like DTT, remove them via buffer exchange or pre-treat with a thiol-blocking agent like N-ethylmaleimide (NEM). Some cyclooctynes used in SPAAC can also react with thiols. | [6] [5][6] |
| Cellular Autofluorescence | Use Proper Controls: Always include a negative control of unlabeled cells (not treated with the this compound analog) but subjected to the click reaction to determine the baseline autofluorescence. Choose a Brighter Fluorophore: If the specific signal is weak relative to the autofluorescence, switch to a brighter fluorescent probe in a different spectral range (e.g., far-red). | [9] |
Problem 3: Poor Cell Health or Cytotoxicity
Maintaining cell health is critical for accurate and meaningful results.
| Potential Cause | Recommended Solution | Citations |
| This compound Analog Toxicity | Perform Viability Assay: Conduct a cytotoxicity assay (e.g., MTT) to determine the maximum tolerable concentration and incubation time of the this compound analog for your specific cell line. Lower Concentration/Time: Reduce the concentration of the analog or shorten the incubation period. | [11][20] [14] |
| Copper Toxicity (CuAAC) | Use a Chelating Ligand: Always include a copper-stabilizing ligand such as THPTA in your CuAAC reaction mix to reduce its toxicity and improve efficiency. A 5:1 ligand-to-copper ratio is often recommended. Switch to SPAAC: For experiments requiring long-term cell viability, SPAAC is the recommended catalyst-free alternative. | [6][7] [4][8] |
| Suboptimal Culture Conditions | Maintain Healthy Cultures: Ensure cells are healthy and in the logarithmic growth phase before starting the experiment. Do not let cells become over-confluent. | [11] |
Data Presentation
Table 1: Comparison of Live-Cell Click Chemistry Reactions
| Feature | CuAAC (Copper-Catalyzed) | SPAAC (Strain-Promoted) | Citations |
| Reaction Principle | Copper(I) catalyzes the cycloaddition of a terminal alkyne and an azide. | Ring strain in a cyclooctyne drives a catalyst-free reaction with an azide. | [4][6][15] |
| Reaction Kinetics | Very fast (Second-order rate constants: 10² - 10³ M⁻¹s⁻¹) | Fast, but generally slower than CuAAC (Second-order rate constants: up to ~1 M⁻¹s⁻¹) | [6] |
| Biocompatibility | Lower; copper catalyst is cytotoxic. Minimized with chelating ligands. | High; no catalyst required. The preferred choice for in vivo studies. | [4][5] |
| Bioorthogonal Handles | Small (terminal alkyne, azide). | Larger (strained cyclooctyne, azide). | [4][8] |
| Typical Live Cell Use | Short-term labeling; labeling in lysates. | Long-term live-cell imaging; in vivo studies. | [8] |
Table 2: Recommended Starting Concentrations for Labeling Reagents
| Reagent Type | Concentration Range | Typical Incubation Time | Notes | Citations |
| This compound Analog (e.g., AHA, HPG) | 25 - 250 µM | 1 - 48 hours | Optimize for each cell line to balance labeling with cytotoxicity. | [9][13] |
| Fluorescent Probe (CuAAC) | 1 - 25 µM | 30 - 60 minutes | Use fresh sodium ascorbate. Avoid Tris buffers. | [6][7] |
| Fluorescent Probe (SPAAC) | 1 - 10 µM | 30 - 120 minutes | Reaction time is dependent on the specific cyclooctyne used. | [16][21] |
| Copper (II) Sulfate (for CuAAC) | 50 - 200 µM | 30 - 60 minutes | Use with a reducing agent and ligand. | [6] |
| Reducing Agent (e.g., Na Ascorbate) | 1 - 5 mM | 30 - 60 minutes | Must be prepared fresh. | [6][15] |
| Copper Ligand (e.g., THPTA) | 250 - 1000 µM | 30 - 60 minutes | Use at a ~5:1 ratio to copper. | [6] |
Experimental Protocols
Protocol 1: General Metabolic Labeling with a this compound Analog
This protocol describes the incorporation of an azide- or alkyne-containing this compound analog into newly synthesized proteins in cultured mammalian cells.
-
Cell Culture: Plate cells on a suitable vessel (e.g., coverslips for imaging or multi-well plates) and grow to 70-80% confluency in standard complete medium.[18]
-
Prepare Labeling Medium: Prepare complete culture medium lacking natural L-lysine. Supplement this medium with the desired final concentration of the this compound analog (e.g., L-azidohomoalanine, AHA). Note: Using dialyzed fetal bovine serum (FBS) is recommended to minimize the concentration of competing natural amino acids.
-
Starvation (Optional): To enhance incorporation, aspirate the standard medium, wash cells once with pre-warmed sterile PBS, and incubate cells in this compound-free medium for 30-60 minutes.[1]
-
Metabolic Labeling: Remove the starvation medium (if used) or standard medium and replace it with the prepared labeling medium.
-
Incubation: Return cells to the incubator (37°C, 5% CO₂) for the desired labeling period (e.g., 4 to 24 hours). The optimal time will depend on the cell type and experimental goals.[9]
-
Proceed to Fixation and Click Reaction: After incubation, cells are ready for fixation and permeabilization (for imaging) or cell lysis (for biochemical analysis).
Protocol 2: Fluorescent Labeling via Click Chemistry in Fixed Cells (FUNCAT)
This protocol is for visualizing metabolically labeled proteins within fixed cells.
-
Cell Fixation: After metabolic labeling, wash the cells twice with pre-warmed PBS. Fix the cells with 4% paraformaldehyde (PFA) in PBS for 15 minutes at room temperature.[13][17]
-
Washing: Wash the cells twice with PBS.
-
Permeabilization: Permeabilize the cells with 0.25% Triton™ X-100 in PBS for 15 minutes at room temperature.[13]
-
Washing: Wash cells three times with PBS containing 3% BSA.
-
Prepare Click Reaction Cocktail: Prepare the cocktail immediately before use and protect it from light.
-
For CuAAC: In a compatible buffer (e.g., PBS), combine the copper (II) sulfate (e.g., 100 µM final), fluorescent azide/alkyne probe (e.g., 5 µM final), and a copper-chelating ligand (e.g., 500 µM THPTA final). Initiate the reaction by adding freshly prepared sodium ascorbate (e.g., 2 mM final).[7][17]
-
For SPAAC: In a compatible buffer (e.g., PBS), add the fluorescent probe containing the complementary cyclooctyne/azide (e.g., 5 µM final).[16]
-
-
Click Reaction: Aspirate the wash buffer from the cells and add the click reaction cocktail. Incubate for 30-60 minutes at room temperature, protected from light.[16]
-
Final Washes: Wash the cells three times with PBS.
-
Imaging: If desired, perform counterstaining (e.g., with DAPI for nuclei). Mount the coverslips and image using an appropriate fluorescence microscope.[17]
Protocol 3: Labeling in Cell Lysate for Biochemical Analysis
This protocol is for performing the click reaction on total protein from cell lysates.
-
Cell Harvesting: After metabolic labeling, wash cells twice with ice-cold PBS. Scrape cells into a microcentrifuge tube and pellet by centrifugation (e.g., 500 x g for 5 minutes).
-
Lysis: Resuspend the cell pellet in a lysis buffer (e.g., RIPA buffer or 1% SDS in PBS) containing protease inhibitors.[19]
-
Clarify Lysate: Centrifuge the lysate at high speed (e.g., >12,000 x g) for 20 minutes at 4°C to pellet cell debris. Transfer the supernatant to a new tube.
-
Protein Quantification: Determine the total protein concentration of the lysate using a standard method (e.g., BCA assay).
-
Click Reaction (CuAAC Recommended): In a microcentrifuge tube, dilute the protein lysate to a final concentration of 1-2 mg/mL. Add the click chemistry reagents as described in Protocol 2 (CuAAC).
-
Incubation: Incubate the reaction for 1-2 hours at room temperature with gentle agitation, protected from light.[16]
-
Downstream Analysis: The labeled proteins in the lysate are now ready for downstream analysis, such as SDS-PAGE with in-gel fluorescence scanning or affinity purification followed by mass spectrometry.[10]
Visualizations
Caption: General experimental workflow for this compound labeling in live cells.
Caption: Cellular factors influencing this compound labeling efficiency.
References
- 1. info.gbiosciences.com [info.gbiosciences.com]
- 2. Visualizing Changes in Protein Synthesis | FUNCAT Method- Oxford Instruments [imaris.oxinst.com]
- 3. BONCAT: Metabolic Labeling, Click Chemistry, and Affinity Purification of Newly Synthesized Proteomes | Springer Nature Experiments [experiments.springernature.com]
- 4. benchchem.com [benchchem.com]
- 5. Frontiers | A Genetically Encoded Picolyl Azide for Improved Live Cell Copper Click Labeling [frontiersin.org]
- 6. benchchem.com [benchchem.com]
- 7. jenabioscience.com [jenabioscience.com]
- 8. Copper-catalyzed click reaction on/in live cells - PMC [pmc.ncbi.nlm.nih.gov]
- 9. biorxiv.org [biorxiv.org]
- 10. A click chemistry-based biorthogonal approach for the detection and identification of protein this compound malonylation for osteoarthritis research - PMC [pmc.ncbi.nlm.nih.gov]
- 11. In Vitro Evaluation of Cytotoxicity and Permeation Study on this compound- and Arginine-Based Lipopeptides with Proven Antimicrobial Activity - PMC [pmc.ncbi.nlm.nih.gov]
- 12. biorxiv.org [biorxiv.org]
- 13. documents.thermofisher.com [documents.thermofisher.com]
- 14. Optimizing Bio-Orthogonal Non-Canonical Amino acid Tagging (BONCAT) for low-disruption labeling of Arabidopsis proteins in vivo - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. interchim.fr [interchim.fr]
- 16. Differential Translation Activity Analysis Using Bioorthogonal Noncanonical Amino Acid Tagging (BONCAT) in Archaea - Ribosome Biogenesis - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 17. Metabolic Labeling with Noncanonical Amino Acids and Visualization by Chemoselective Fluorescent Tagging - PMC [pmc.ncbi.nlm.nih.gov]
- 18. High-throughput Assessment of Mitochondrial Protein Synthesis in Mammalian Cells Using Mito-FUNCAT FACS - PMC [pmc.ncbi.nlm.nih.gov]
- 19. protocols.io [protocols.io]
- 20. chirurgie.uk-erlangen.de [chirurgie.uk-erlangen.de]
- 21. pubs.acs.org [pubs.acs.org]
Technical Support Center: Best Practices for Quenching Lysine Cross-Linking Reactions
This guide provides researchers, scientists, and drug development professionals with best practices, troubleshooting advice, and frequently asked questions regarding the critical step of quenching lysine-targeted cross-linking reactions, particularly those using formaldehyde.
Frequently Asked Questions (FAQs)
Q1: What is the purpose of quenching in a cross-linking experiment?
Quenching is a crucial step to stop the cross-linking reaction. It involves adding a small molecule with a reactive primary amine, such as Tris or glycine, to the reaction mixture. This "quencher" consumes any excess cross-linking agent (e.g., formaldehyde), preventing further, uncontrolled cross-linking of proteins and other macromolecules.[1][2] This ensures that the captured interactions represent a specific point in time.
Q2: What are the most common quenching reagents for formaldehyde cross-linking?
The two most widely used quenching reagents are Glycine and Tris (tris(hydroxymethyl)aminomethane).[1][3] Both contain primary amines that react with and neutralize free formaldehyde.[2][4]
Q3: Which quenching reagent is more efficient, Tris or Glycine?
Evidence suggests that Tris is a more efficient quencher than glycine.[2][3][5] The chemical structure of Tris allows it to form a stable cyclic product after reacting with formaldehyde, which makes the quenching reaction more favorable.[2][4][6] In contrast, glycine's reaction with formaldehyde can be less complete under standard conditions.[7]
Q4: Can the choice of quenching reagent affect my downstream applications, like ChIP-seq?
Yes. Incomplete quenching can lead to continued cross-linking even after the intended reaction time, which can increase background signal in sensitive downstream applications like Chromatin Immunoprecipitation sequencing (ChIP-seq).[7] Conversely, some quenching conditions, particularly high concentrations of Tris, have the potential to reverse existing cross-links, which could lead to a loss of signal for the interactions you are trying to study.[2][8]
Q5: What concentration of quenching reagent should I use?
Standard protocols frequently recommend a final concentration of 125 mM glycine .[9][10] However, studies have shown this concentration may be sub-stoichiometric to the amount of formaldehyde used (e.g., 1%) and might not fully stop the reaction.[7] For Tris, a concentration that provides a molar excess over the formaldehyde is recommended for efficient quenching. For example, for a 1% formaldehyde solution, a final Tris concentration of approximately 750 mM has been suggested.[5]
Troubleshooting Guide
| Issue | Potential Cause | Recommended Solution |
| High background in ChIP-seq or Co-IP | Incomplete Quenching: The cross-linking reaction may not have been fully stopped, leading to non-specific cross-links. | 1. Switch to Tris: Consider using Tris instead of glycine for more efficient quenching.[2][5] 2. Increase Quencher Concentration: If using glycine, you may need to increase the concentration beyond the standard 125 mM.[7] Ensure the quencher is in molar excess to the formaldehyde. 3. Optimize Quenching Time: Ensure the quenching incubation is sufficient (e.g., 5-15 minutes at room temperature).[9][11] |
| Low yield or loss of signal | Cross-link Reversal: High concentrations of Tris can potentially reverse established cross-links.[2][8] Over-cross-linking: Excessive cross-linking can mask antibody epitopes or make chromatin difficult to shear, reducing immunoprecipitation efficiency.[9] | 1. Titrate Tris Concentration: If you suspect cross-link reversal, try reducing the concentration of Tris while still ensuring it's in molar excess. 2. Optimize Cross-linking Time: The optimal duration of cross-linking varies. Test different incubation times (e.g., 5, 10, 20 minutes) to find the sweet spot for your protein of interest and cell type.[9] |
| High molecular weight smear at the top of an SDS-PAGE gel | Over-cross-linking: The proteins have formed large, insoluble aggregates that cannot enter the gel matrix.[12] | 1. Reduce Cross-linking Time/Concentration: Shorten the incubation time with formaldehyde or decrease its final concentration.[9] 2. Ensure Rapid and Efficient Quenching: Immediately add a sufficient concentration of quencher at the end of the incubation period to prevent further reaction. |
| Protein degradation | Improper sample handling: Lysis and subsequent steps were not performed under conditions that inhibit protease activity. | 1. Work quickly and on ice: Keep samples cold at all times following quenching.[9] 2. Use Protease Inhibitors: Add protease inhibitors to your lysis buffer immediately before use.[9] |
Data Presentation: Quenching Efficiency Comparison
The following table summarizes experimental results comparing the effectiveness of different quenching strategies in a ChIP experiment. A higher ChIP signal after a longer quenching incubation suggests that cross-linking was not effectively stopped at the beginning of the quenching period.
| Quenching Condition | Incubation Time | Relative ChIP Signal (% Input DNA) | Interpretation |
| 125 mM Glycine | 1 min | ~0.0006% | Initial cross-linking level. |
| 125 mM Glycine | 5 min | ~0.0008% | Signal increases, suggesting incomplete quenching and continued cross-linking.[7] |
| 125 mM Glycine | 10 min | ~0.0010% | Signal continues to increase, confirming inefficient quenching.[7] |
| 750 mM Tris | 1 min | ~0.0005% | Signal is slightly lower than the initial glycine point, indicating rapid and effective quenching.[7] |
| 750 mM Tris | 5 min | ~0.0005% | Signal remains stable, confirming the cross-linking reaction was stopped.[7] |
| 750 mM Tris | 10 min | ~0.0005% | Signal remains stable over time.[7] |
| No Quencher | 6 min | ~0.0012% | Control showing the extent of cross-linking without any quenching agent.[7] |
Data adapted from bioRxiv, doi: 10.1101/838388.[7] The values are illustrative of the trends observed.
Experimental Protocols
Protocol 1: Quenching Formaldehyde Cross-linking with Glycine
-
Perform Cross-linking: Complete your formaldehyde cross-linking step according to your established protocol (e.g., 1% final concentration of formaldehyde for 10 minutes at room temperature).[9]
-
Prepare Quenching Solution: Prepare a stock solution of 1.25 M Glycine in PBS or water.
-
Add Quencher: To quench the reaction, add the 1.25 M Glycine stock solution to your cell culture media or cell suspension to a final concentration of 125 mM (this is typically a 1/10th volume addition).[9][10]
-
Incubate: Gently mix and incubate for 5 minutes at room temperature.[9][10]
-
Wash: Proceed to wash the cells to remove residual formaldehyde and glycine. Typically, this involves pelleting the cells by centrifugation and washing twice with ice-cold PBS.[1]
-
Downstream Processing: The cell pellet is now ready for lysis and downstream applications.[1]
Protocol 2: Quenching Formaldehyde Cross-linking with Tris-HCl
-
Perform Cross-linking: Complete your formaldehyde cross-linking step (e.g., 1% final concentration of formaldehyde, which is ~333 mM).
-
Prepare Quenching Solution: Prepare a stock solution of 1 M Tris-HCl, pH 8.0.
-
Add Quencher: Add the 1 M Tris-HCl stock solution to your reaction to a final concentration sufficient to provide a molar excess. For a 1% formaldehyde cross-linking, a final concentration of ~750 mM Tris is effective (a ~2.25-fold molar excess).[5][7]
-
Incubate: Gently mix and incubate for 10-15 minutes at room temperature.[11]
-
Wash: Pellet the cells by centrifugation and wash twice with ice-cold PBS to remove unreacted reagents.
-
Downstream Processing: The quenched cells are ready for subsequent steps like cell lysis.
Visualizations
Experimental Workflow
Caption: A generalized workflow for protein cross-linking experiments.
Logical Relationships
Caption: Troubleshooting logic for optimizing quenching protocols.
Signaling Pathways (Chemical Reactions)
Caption: Quenching reactions of formaldehyde with Glycine and Tris.
References
- 1. How to Handle Samples After Adding Crosslinkers in Protein Crosslinking | MtoZ Biolabs [mtoz-biolabs.com]
- 2. Formaldehyde Crosslinking: A Tool for the Study of Chromatin Complexes - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. researchgate.net [researchgate.net]
- 5. researchgate.net [researchgate.net]
- 6. Item - Quenching of formaldehyde cross-linking by Tris. - Public Library of Science - Figshare [plos.figshare.com]
- 7. biorxiv.org [biorxiv.org]
- 8. Second-generation method for analysis of chromatin binding with formaldehyde–cross-linking kinetics - PMC [pmc.ncbi.nlm.nih.gov]
- 9. bosterbio.com [bosterbio.com]
- 10. docs.abcam.com [docs.abcam.com]
- 11. benchchem.com [benchchem.com]
- 12. Protein Labeling, Crosslinking, and Modification Support—Troubleshooting | Thermo Fisher Scientific - US [thermofisher.com]
Avoiding lysine degradation during acid hydrolysis of proteins
Troubleshooting Guide & FAQs: Avoiding Lysine Degradation During Acid Hydrolysis
This guide addresses common issues researchers face regarding the stability of this compound during the acid hydrolysis of proteins for amino acid analysis.
Frequently Asked Questions (FAQs)
Q1: Why is this compound prone to degradation during acid hydrolysis?
A1: this compound possesses a reactive primary amino group (ε-amino group) on its side chain.[1] While generally stable during standard acid hydrolysis of pure proteins, this group can react with other molecules, particularly reducing sugars, in a process known as the Maillard reaction.[2][3] This is especially problematic in samples that have been heat-processed or are not highly purified.[2][4]
Q2: What is the Maillard reaction and how does it affect this compound quantification?
A2: The Maillard reaction is a non-enzymatic browning reaction between an amino acid and a reducing sugar.[1] In the initial stage, the ε-amino group of this compound reacts with a sugar to form an Amadori compound, such as fructosyl-lysine.[1] Some of these early-stage Maillard products are acid-labile and can revert to this compound during hydrolysis, leading to an overestimation of available this compound.[2][4] However, advanced Maillard reaction products are stable and will not regenerate this compound, causing a net loss of quantifiable this compound.[1]
Q3: My this compound recovery is low. What are the potential causes and solutions?
A3: Low this compound recovery can stem from several factors:
-
Presence of Reducing Sugars: If your sample contains carbohydrates, the Maillard reaction is a likely cause of this compound loss.
-
Solution: Consider using alternative hydrolysis methods that are less harsh or are performed under conditions that minimize this reaction. Methanesulfonic acid (MSA) hydrolysis can be a better option in such cases.
-
-
Incomplete Hydrolysis: While less common for this compound compared to hydrophobic amino acids, incomplete cleavage of peptide bonds can lead to lower yields.
-
Oxidative Damage: Although less susceptible than methionine or cysteine, this compound can still be subject to some oxidative degradation if oxygen is not adequately removed from the hydrolysis vessel.
Q4: When should I choose an alternative to the standard 6M HCl hydrolysis?
A4: The standard 6M HCl liquid-phase hydrolysis is a robust method for many applications. However, you should consider alternatives under the following circumstances:
-
Analysis of Tryptophan: Tryptophan is almost completely destroyed by 6M HCl. MSA or alkaline hydrolysis is required for its quantification.[4]
-
Presence of Carbohydrates: To avoid the Maillard reaction and subsequent this compound degradation, MSA hydrolysis is a preferable choice.
-
Highly Sensitive Samples: For very small amounts of highly purified protein, vapor-phase HCl hydrolysis can reduce contamination from the acid reagent itself.[5][6]
Quantitative Data on Amino Acid Recovery
The choice of hydrolysis method can significantly impact the recovery of amino acids. While this compound is relatively stable under standard conditions for pure proteins, the presence of interfering substances or the need to preserve other, more labile amino acids may necessitate alternative protocols. The following table summarizes typical recovery rates for selected amino acids, including this compound, under different hydrolysis conditions.
| Amino Acid | Standard 6M HCl Hydrolysis | 4M Methanesulfonic Acid (MSA) Hydrolysis | Notes |
| This compound | ~95-100% | ~95-100% | Recovery can be significantly lower in the presence of reducing sugars with HCl hydrolysis. |
| Tryptophan | ~0% | >85% | Tryptophan is destroyed by HCl but preserved by MSA, especially with a scavenger like tryptamine.[6] |
| Methionine | Variable (~60-90%) | >90% | Methionine is susceptible to oxidation during HCl hydrolysis. MSA provides better protection.[6] |
| Cysteine/Cystine | Variable (~50-80%) | >90% | These sulfur-containing amino acids are also better recovered with MSA hydrolysis.[6] |
Note: Recovery percentages are approximate and can vary depending on the protein sequence, sample matrix, and specific experimental conditions.
Experimental Protocols
Below are detailed methodologies for three common protein hydrolysis techniques.
Protocol 1: Standard Liquid-Phase 6M HCl Hydrolysis
This is the most common method for general protein hydrolysis.
Materials:
-
Protein sample (0.1–10 µg)
-
6M HCl containing 0.1-1.0% phenol
-
Hydrolysis tubes (e.g., 6 x 50 mm)
-
Heating block or oven capable of maintaining 110°C
-
Vacuum system and nitrogen source
Procedure:
-
Place the protein sample into a hydrolysis tube. If in solution, dry the sample completely under vacuum.
-
Add a sufficient volume of 6M HCl with phenol to the tube to cover the sample.
-
Carefully flush the tube with dry nitrogen for 30-60 seconds to displace all oxygen.
-
Immediately seal the tube under vacuum.
-
Place the sealed tube in an oven or heating block at 110°C for 24 hours.[2]
-
After 24 hours, remove the tube and allow it to cool to room temperature.
-
Break the seal and dry the HCl under vacuum.
-
The dried hydrolysate is now ready for amino acid analysis.
Protocol 2: Vapor-Phase 6M HCl Hydrolysis
This method is preferred for small, pure protein samples to minimize contamination.
Materials:
-
Protein sample (0.5–20 µg)
-
Constant-boiling 6M HCl containing 0.5% phenol
-
Hydrolysis tubes (e.g., 6 x 50 mm)
-
Vacuum vial or desiccator
-
Oven or heating block capable of maintaining 112-116°C
-
Vacuum system and nitrogen source
Procedure:
-
Dry the protein sample in a 6 x 50 mm hydrolysis tube.
-
Place the open tubes containing the samples into a larger vacuum vial or desiccator.
-
Add approximately 200 µL of 6M HCl with phenol to the bottom of the vacuum vial, ensuring it does not touch the sample tubes.[4]
-
Seal the vial and perform at least three cycles of vacuum application followed by nitrogen flushing to ensure all oxygen is removed.[4]
-
Seal the vial under a final vacuum.
-
Place the entire vial in an oven at 112-116°C for 24 hours.[4]
-
After 24 hours, remove the vial and let it cool completely.
-
Vent the vial, remove the sample tubes, and dry them under vacuum to remove any residual acid.
Protocol 3: Methanesulfonic Acid (MSA) Hydrolysis
This method is recommended for the recovery of labile amino acids like tryptophan.
Materials:
-
Dried protein sample
-
4M Methanesulfonic acid (MSA) containing 0.2% (w/v) tryptamine HCl
-
4M KOH for neutralization
-
Hydrolysis tubes (e.g., 6 x 50 mm)
-
Oven or heating block capable of maintaining 110°C
-
Vacuum system
Procedure:
-
To the dried sample in a hydrolysis tube, add 20 µL of 4M MSA containing 0.2% tryptamine HCl.[4]
-
Place the tube in a larger reaction vial. Add approximately 100 µL of water to the bottom of the outer vial to maintain a humid atmosphere.
-
Seal the vial under vacuum.
-
Hydrolyze at 110°C for 20-24 hours.[4]
-
After cooling, open the vial and carefully add 22 µL of 4M KOH to neutralize the acid.[4]
-
Dry the neutralized sample under vacuum.
-
The sample is now ready for derivatization and analysis.
Visualizations
Workflow for Protein Hydrolysis Method Selection
The following diagram illustrates a decision-making workflow for choosing the appropriate protein hydrolysis method based on the sample type and analytical goals.
Caption: Decision tree for selecting a protein hydrolysis method.
The Maillard Reaction Pathway Leading to this compound Degradation
This diagram shows a simplified pathway of the initial stages of the Maillard reaction, which can lead to the loss of quantifiable this compound.
Caption: Initial steps of the Maillard reaction involving this compound.
References
- 1. Absolute quantitative analysis of intact and oxidized amino acids by LC-MS without prior derivatization - PMC [pmc.ncbi.nlm.nih.gov]
- 2. keypublishing.org [keypublishing.org]
- 3. researchgate.net [researchgate.net]
- 4. mdpi.com [mdpi.com]
- 5. Accurate and efficient amino acid analysis for protein quantification using hydrophilic interaction chromatography coupled tandem mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 6. repo.uni-hannover.de [repo.uni-hannover.de]
Optimizing buffer pH for selective modification of lysine's epsilon-amino group
This technical support center provides troubleshooting guidance and frequently asked questions for researchers, scientists, and drug development professionals working on the selective modification of lysine's ε-amino group.
Frequently Asked Questions (FAQs)
Q1: What is the key principle for selectively modifying the ε-amino group of this compound over the N-terminal α-amino group?
The selective modification of this compound's ε-amino group is primarily achieved by controlling the reaction buffer's pH. This exploits the difference in the acidity constant (pKa) between the N-terminal α-amino group and the this compound ε-amino group.[1][2][3]
Q2: What are the typical pKa values for the α- and ε-amino groups of this compound?
The pKa of the N-terminal α-amino group is typically in the range of 6.0-8.0, while the ε-amino group of the this compound side chain has a pKa of around 10.5.[2][3][4][5][] This difference is fundamental to achieving selectivity.
Q3: At what pH is the selective modification of this compound's ε-amino group most effective?
To selectively target the ε-amino group, the reaction should be performed at a pH range of 8.5 to 9.5.[2] At this pH, a significant fraction of the ε-amino groups are deprotonated and thus nucleophilic, while the majority of N-terminal α-amino groups are also deprotonated. However, the higher intrinsic nucleophilicity of the ε-amino group can be exploited.[7]
Q4: What happens if I perform the modification at a lower pH (e.g., pH 7.0-7.5)?
At a near-physiological pH of 7.0-7.5, the N-terminal α-amino group is more nucleophilic than the this compound side chain.[2] This is because the more basic ε-amino group is more likely to be protonated (and thus unreactive) at this pH.[2] Therefore, lower pH ranges favor N-terminal modification.
Q5: Can the microenvironment of a protein affect the pKa of a specific this compound residue?
Yes, the local microenvironment within a protein's three-dimensional structure can significantly alter the pKa of a this compound residue.[2] Factors such as proximity to other charged residues can make a particular this compound more or less reactive than others.
Troubleshooting Guides
Issue 1: Low Yield of this compound Modification
| Potential Cause | Recommended Solution |
| Suboptimal pH | Ensure the buffer pH is within the optimal range of 8.5-9.5 for targeting the ε-amino group.[2] Verify the pH of your buffer with a calibrated pH meter. |
| Insufficient Reagent | Increase the molar excess of the modifying reagent. An empirical titration may be necessary to find the optimal ratio.[8] |
| Reagent Instability | Some reagents, like N-hydroxysuccinimide (NHS) esters, are susceptible to hydrolysis, especially at higher pH.[] Prepare fresh solutions of the reagent and add it to the reaction mixture immediately. |
| Protein Aggregation | The modification process can sometimes lead to protein precipitation.[8][9] See the troubleshooting guide for "Protein Precipitation during Modification" below. |
| Inaccessible this compound Residues | The target this compound residues may be buried within the protein structure and inaccessible to the modifying reagent.[4] Consider performing the reaction under partially denaturing conditions, if compatible with your protein's stability and function. |
Issue 2: Lack of Selectivity (Modification at N-terminus or other residues)
| Potential Cause | Recommended Solution |
| Incorrect pH | If you are observing significant N-terminal modification, your pH may be too low. Increase the pH to the 8.5-9.5 range to favor ε-amino group reactivity.[2] |
| Reagent Reactivity | Some reagents are inherently more reactive and less selective. For example, NHS esters can sometimes react with serine, tyrosine, and histidine residues.[][7] Consider using a reagent with higher chemoselectivity for amines. |
| High Reagent Concentration | A large excess of the modifying reagent can lead to non-specific modifications.[9] Reduce the molar ratio of the reagent to your protein. |
| Reaction Time | Prolonged reaction times can sometimes lead to side reactions. Optimize the reaction time by taking aliquots at different time points and analyzing the modification. |
Issue 3: Protein Precipitation during Modification
| Potential Cause | Recommended Solution |
| Change in Protein Charge | Modification of this compound residues neutralizes their positive charge, which can alter the protein's isoelectric point (pI) and reduce its solubility.[8][9] |
| Hydrophobic Nature of the Label | Attaching a bulky, hydrophobic label can lead to aggregation and precipitation.[9] |
| Buffer Composition | The buffer components themselves might contribute to insolubility. Ensure your buffer is compatible with your protein and the modification chemistry. |
| Over-modification | Attaching too many labels to the protein can significantly alter its properties and lead to precipitation.[9] Reduce the molar excess of the labeling reagent. |
Quantitative Data Summary
Table 1: pKa Values of Ionizable Groups in this compound
| Ionizable Group | Typical pKa Range |
| α-carboxyl group | ~2.18[10] |
| α-amino group | ~8.95[10] |
| ε-amino group (side chain) | ~10.53[10] |
Table 2: Recommended pH Ranges for Selective Amine Modification
| Target Group | Recommended pH Range | Rationale |
| N-terminal α-amino group | 6.5 - 7.5 | At this pH, the α-amino group is more nucleophilic than the protonated ε-amino group.[1][2] |
| This compound ε-amino group | 8.5 - 9.5 | In this range, a significant portion of ε-amino groups are deprotonated and highly reactive.[2][11] |
Experimental Protocols
Protocol 1: General Procedure for Selective this compound ε-Amino Group Modification with an NHS Ester
-
Protein Preparation:
-
Dissolve or dialyze the protein into an appropriate buffer at the desired concentration. A common choice is a phosphate or borate buffer.
-
Ensure the buffer does not contain primary amines (e.g., Tris), as these will compete with the this compound residues for the NHS ester.[8]
-
-
Buffer Preparation:
-
Prepare a 0.1 M sodium borate buffer and adjust the pH to 8.5 using a calibrated pH meter.
-
-
Reagent Preparation:
-
Immediately before use, dissolve the NHS ester reagent in a dry, aprotic solvent like DMSO or DMF to the desired stock concentration.
-
-
Modification Reaction:
-
Add the calculated amount of the NHS ester stock solution to the protein solution while gently vortexing. The final concentration of the organic solvent should typically be less than 10% to avoid protein denaturation.
-
The molar excess of the NHS ester will need to be optimized for each protein but a starting point of 10- to 20-fold molar excess is common.[11]
-
Incubate the reaction at room temperature or 4°C for 1-2 hours. The optimal time may vary.
-
-
Quenching the Reaction:
-
Add a small molecule with a primary amine (e.g., Tris, glycine, or hydroxylamine) to a final concentration of 20-50 mM to quench any unreacted NHS ester.
-
-
Purification:
-
Remove the excess, unreacted reagent and byproducts by size-exclusion chromatography, dialysis, or tangential flow filtration.
-
Protocol 2: Verifying the Extent of Modification by Mass Spectrometry
-
Sample Preparation:
-
Take an aliquot of the purified, modified protein.
-
If necessary, perform a buffer exchange into a volatile buffer (e.g., ammonium bicarbonate).
-
-
Protein Digestion:
-
Reduce the protein with DTT and alkylate with iodoacetamide.
-
Digest the protein into peptides using a protease such as trypsin.
-
-
LC-MS/MS Analysis:
-
Analyze the peptide mixture using liquid chromatography-tandem mass spectrometry (LC-MS/MS).
-
-
Data Analysis:
-
Search the MS/MS data against the protein sequence to identify modified peptides.
-
The mass shift corresponding to the modification will be observed on this compound-containing peptides.
-
Quantify the ratio of modified to unmodified peptides to determine the efficiency of the labeling reaction.
-
Visualizations
Caption: Relationship between pH and the protonation state of amino groups.
Caption: Experimental workflow for selective this compound modification.
References
- 1. Selective N-terminal modification of peptides and proteins: Recent progresses and applications [ccspublishing.org.cn]
- 2. Development and Recent Advances in this compound and N-Terminal Bioconjugation for Peptides and Proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Selectivity and stability of N-terminal targeting protein modification chemistries - RSC Chemical Biology (RSC Publishing) DOI:10.1039/D2CB00203E [pubs.rsc.org]
- 4. Amino Acids - this compound [biology.arizona.edu]
- 5. Exploiting Protein N-Terminus for Site-Specific Bioconjugation - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Selective this compound modification of native peptides via aza-Michael addition - Organic & Biomolecular Chemistry (RSC Publishing) DOI:10.1039/C7OB01866E [pubs.rsc.org]
- 8. Protein Labeling, Crosslinking, and Modification Support—Troubleshooting | Thermo Fisher Scientific - HK [thermofisher.com]
- 9. Labeling Chemistry Support—Troubleshooting | Thermo Fisher Scientific - SG [thermofisher.com]
- 10. iscabiochemicals.com [iscabiochemicals.com]
- 11. researchgate.net [researchgate.net]
Technical Support Center: Reducing Background in Lysine Acetylation Western Blots
This guide provides researchers, scientists, and drug development professionals with detailed troubleshooting strategies and answers to frequently asked questions to minimize background signal and achieve high-quality results in lysine acetylation western blots.
Troubleshooting Guide
This section addresses the most common background issues encountered during acetyl-lysine western blotting.
❓ Why do I have a high, uniform background across my entire blot?
A high, uniform background is often a result of non-specific antibody binding across the membrane. This can obscure the detection of your target protein by decreasing the signal-to-noise ratio.[1] The most common causes and their solutions are outlined below.
-
Inadequate Blocking: The blocking step is critical to prevent antibodies from binding directly to the membrane.[2][3] If blocking is insufficient, both primary and secondary antibodies can bind non-specifically.
-
Incorrect Blocking Agent: For post-translational modification (PTM) detection, the choice of blocking agent is crucial. Non-fat dry milk contains casein, a phosphoprotein, which can cross-react with PTM-specific antibodies.[1][7]
-
Antibody Concentration is Too High: Using excessive amounts of primary or secondary antibody is a primary cause of high background.[2][4]
-
Solution: Optimize antibody concentrations by performing a titration. Start with the manufacturer's recommended dilution and perform a dot blot or test blot with a series of further dilutions to find the optimal concentration that maximizes signal while minimizing background.[2][4][8] For secondary antibodies, dilutions of 1:5000 to 1:10000 may be necessary.[9]
-
-
Insufficient Washing: Washing steps are essential for removing unbound and weakly bound antibodies.[10][11]
-
Membrane Dried Out: Allowing the membrane to dry at any point during the process can cause irreversible and non-specific antibody binding, leading to high background.[1][13]
❓ Why does my blot have a speckled or spotty background?
A speckled background, often appearing as black dots or random spots, is typically caused by particulates or aggregates in the solutions or on the membrane.[14][15]
-
Aggregated Antibodies: Antibodies, particularly secondary conjugates, can form aggregates over time.
-
Solution: Filter the secondary antibody solution through a 0.2 µm filter before use.[15] It is also good practice to centrifuge the antibody vial briefly before taking an aliquot.
-
-
Contaminated or Poorly Dissolved Buffers: Particulates from undissolved blocking agents or bacterial contamination in buffers can settle on the membrane.[14][16][17]
-
Contaminated Equipment or Handling: Dust, fibers, or residues from unclean forceps or incubation trays can transfer to the membrane.[13][15][17]
Below is a troubleshooting decision tree to help diagnose the source of background issues.
Frequently Asked Questions (FAQs)
❓ Why is sample preparation so important for detecting this compound acetylation?
This compound acetylation is a dynamic and reversible post-translational modification regulated by two opposing enzyme families: Histone Acetyltransferases (HATs) and Histone Deacetylases (HDACs).[19] Once cells are lysed, HDACs can rapidly remove acetyl groups from proteins, leading to a loss of signal.
Therefore, it is mandatory to add HDAC inhibitors to the lysis buffer to preserve the acetylation state of your proteins of interest.[20][21] Common broad-spectrum HDAC inhibitors include Trichostatin A (TSA) and Nicotinamide (NAM).[20][21][22]
❓ Which membrane is better for acetyl-lysine blots, PVDF or nitrocellulose?
Both membranes can be used successfully. However, PVDF membranes generally have a higher protein binding capacity, which can increase sensitivity but may also lead to higher background compared to nitrocellulose.[2] If your target protein is abundant and you are struggling with high background on PVDF, switching to a nitrocellulose membrane may help reduce non-specific signal.[1][2]
❓ How do I optimize my antibody dilutions?
Optimizing antibody concentration is a critical step to reduce background.[18]
-
Primary Antibody: Start with the dilution recommended on the antibody datasheet (e.g., 1:1000).[23][24] If the background is high, perform a titration by testing several more dilute concentrations (e.g., 1:2000, 1:5000).
-
Secondary Antibody: High secondary antibody concentration is a very common source of background.[8] Always run a secondary-only control (a blot incubated with only the secondary antibody) to ensure it is not binding non-specifically.[1][2] Often, you can significantly dilute the secondary antibody (e.g., 1:10,000 or higher) and compensate by increasing incubation time to maintain a strong signal.[9]
| Antibody Type | Starting Dilution Range | Key Consideration |
| Pan-Acetyl-Lysine Primary | 1:1000 – 1:2000 | Datasheet recommendations are a starting point; empirical testing is required.[23][24] |
| HRP-conjugated Secondary | 1:5000 – 1:10000 | Higher dilutions reduce non-specific binding. Always run a secondary-only control.[1][8][9] |
❓ What is the best blocking buffer for detecting acetylated proteins?
For detecting PTMs like acetylation, a blocking buffer containing 3-5% BSA in TBST or PBST is generally recommended.[7][25] Non-fat dry milk should be avoided because it contains proteins that can be recognized by PTM-specific antibodies, leading to cross-reactivity and high background.[1][7]
| Blocking Agent | Concentration | Advantages | Disadvantages |
| BSA | 3-5% in TBST/PBST | Recommended for PTMs; compatible with most detection systems.[7][25] | More expensive than milk; may result in less complete blocking in some cases.[25] |
| Non-fat Dry Milk | 3-5% in TBST/PBST | Inexpensive and effective for many non-PTM targets.[25] | Not recommended for acetylation; contains phosphoproteins that can cause cross-reactivity.[1][7] |
Experimental Protocols & Workflow
Adhering to an optimized protocol is key for reproducible, low-background western blots.
Protocol 1: Preparation of Lysis Buffer for Acetylation Analysis
This protocol is for a modified RIPA (Radioimmunoprecipitation assay) buffer designed to preserve protein acetylation.
-
Prepare 100 mL of 1x RIPA Buffer:
-
50 mM Tris-HCl, pH 7.4
-
150 mM NaCl
-
1% NP-40
-
0.5% Sodium deoxycholate
-
0.1% SDS
-
1 mM EDTA
-
-
Store at 4°C. Immediately before use, supplement the required volume of RIPA buffer with a fresh cocktail of inhibitors.
-
Add Inhibitors (to 1 mL of RIPA buffer):
Note: Always keep the lysis buffer and cell lysates on ice to minimize enzymatic activity.[26]
Protocol 2: Optimized Western Blotting for Acetyl-Lysine
This protocol assumes that protein transfer to a membrane has already been completed.
-
Blocking:
-
Prepare a fresh solution of 5% BSA in 1x TBST (Tris-Buffered Saline with 0.1% Tween-20).
-
Incubate the membrane in the blocking solution for at least 1 hour at room temperature with gentle agitation.[2]
-
-
Primary Antibody Incubation:
-
Washing I:
-
Secondary Antibody Incubation:
-
Dilute the HRP-conjugated secondary antibody in 5% BSA in TBST to its optimal concentration (e.g., 1:10,000).
-
Incubate the membrane for 1 hour at room temperature with gentle agitation.
-
-
Washing II:
-
Repeat the washing step as described in step 3. This step is critical for removing unbound secondary antibody.[12]
-
-
Detection:
-
Incubate the membrane with an enhanced chemiluminescence (ECL) substrate according to the manufacturer's instructions.
-
Capture the signal using a digital imager or film. If the background is high, try reducing the exposure time.[5]
-
References
- 1. sinobiological.com [sinobiological.com]
- 2. 5 Tips for Reducing Non-specific Signal on Western Blots - Nordic Biosite [nordicbiosite.com]
- 3. azurebiosystems.com [azurebiosystems.com]
- 4. Western Blot Troubleshooting: High Background | Proteintech Group [ptglab.com]
- 5. arp1.com [arp1.com]
- 6. 5 Quick Tips for Improving Your Western Blocking Solution - Advansta Inc. [advansta.com]
- 7. researchgate.net [researchgate.net]
- 8. How to Minimize Non Specific Binding of Secondary Antibody during Western Blotting - Precision Biosystems-Automated, Reproducible Western Blot Processing and DNA, RNA Analysis [precisionbiosystems.com]
- 9. bitesizebio.com [bitesizebio.com]
- 10. m.youtube.com [m.youtube.com]
- 11. clyte.tech [clyte.tech]
- 12. licorbio.com [licorbio.com]
- 13. What are the possible causes and solutions for background issues (high, uneven, or speckled)? | AAT Bioquest [aatbio.com]
- 14. bio-rad.com [bio-rad.com]
- 15. sinobiological.com [sinobiological.com]
- 16. Unusual gel or band apperance in Western blot | Abcam [abcam.com]
- 17. researchgate.net [researchgate.net]
- 18. azurebiosystems.com [azurebiosystems.com]
- 19. Pan Acetyl-Lysine Polyclonal Antibody - Elabscience® [elabscience.com]
- 20. benchchem.com [benchchem.com]
- 21. researchgate.net [researchgate.net]
- 22. An Alternative Strategy for Pan-acetyl-lysine Antibody Generation - PMC [pmc.ncbi.nlm.nih.gov]
- 23. PTM BIO [ptmbio.com]
- 24. static.abclonal.com [static.abclonal.com]
- 25. bosterbio.com [bosterbio.com]
- 26. Choosing The Right Lysis Buffer | Proteintech Group [ptglab.com]
Technical Support Center: Enrichment Strategies for Low-Abundance Lysine-Modified Peptides
This technical support center provides researchers, scientists, and drug development professionals with comprehensive troubleshooting guides, frequently asked questions (FAQs), and detailed protocols for the enrichment of low-abundance lysine-modified peptides.
Frequently Asked Questions (FAQs)
Q1: Why is enrichment necessary for analyzing this compound-modified peptides by mass spectrometry?
A1: Post-translational modifications (PTMs) on this compound residues, such as acetylation, ubiquitination, and methylation, are often present at very low stoichiometry compared to their unmodified counterparts.[1][2] Without enrichment, the signals from these low-abundance modified peptides are often masked by the vast number of unmodified peptides in a complex biological sample, hindering their detection and identification by mass spectrometry.[3][4] Enrichment strategies are crucial to increase the concentration of modified peptides, reduce sample complexity, and enhance the sensitivity and reliability of the analysis.[3]
Q2: What are the most common strategies for enriching this compound-modified peptides?
A2: The most prevalent methods are antibody-based affinity enrichment (immunoaffinity purification or immunoprecipitation) and, to a lesser extent, chemical-based strategies.[3]
-
Antibody-Based Enrichment: This approach utilizes antibodies that specifically recognize a particular this compound modification (e.g., an anti-acetylthis compound antibody) or a modification-induced remnant motif (like the di-glycine remnant from ubiquitinated proteins, K-ε-GG).[5][6][7] These antibodies are typically immobilized on beads (e.g., agarose or magnetic beads) to capture and isolate the target peptides from a complex mixture.[8][9]
-
Chemical Derivatization: These strategies involve chemically modifying the PTM to introduce an affinity tag (e.g., biotin), which can then be used for enrichment with streptavidin-coated beads.[3]
Q3: Should I enrich at the protein or peptide level?
A3: For proteomics studies aiming to identify specific modification sites, enrichment at the peptide level after proteolytic digestion (e.g., with trypsin) is generally preferred.[3][10] This is because digested peptides are more accessible to the antibodies, as they lack the complex secondary and tertiary structures of intact proteins.[10] Enrichment at the protein level can be challenging due to the low affinity of some pan-specific PTM antibodies and the possibility that the modification site is buried within the protein's structure.[10]
Q4: How can I improve the number of identified ubiquitination sites?
A4: To increase the yield of ubiquitinated peptides, you can treat cells with a proteasome inhibitor (e.g., MG-132 or bortezomib) for a few hours before cell lysis.[6] This blocks the degradation of ubiquitinated proteins, leading to their accumulation. Additionally, performing a crude offline fractionation of the peptide mixture by high-pH reversed-phase chromatography before the immunoaffinity enrichment can significantly reduce sample complexity and increase the number of identified K-ε-GG sites.[5][6][11]
Q5: Can I enrich for multiple different this compound modifications from the same sample?
A5: Yes, this is possible through either "serial" or "one-pot" enrichment strategies. In serial enrichment, the flow-through from the first PTM enrichment is used for a subsequent enrichment of a different PTM.[12] In a "one-pot" approach, antibodies against different PTMs (e.g., acetylthis compound and succinylthis compound) are combined to enrich for multiple modifications simultaneously from a single sample.[12] This approach can be more time- and sample-efficient.[12]
Troubleshooting Guides
This section addresses common problems encountered during the enrichment of this compound-modified peptides.
Problem 1: Low Yield or No Signal of Enriched Peptides
Q: I am not detecting my target modified peptides, or the signal is very weak. What could be the cause?
A: Low yield is a frequent issue stemming from several potential problems in the workflow. Follow this guide to diagnose the issue.
Possible Causes and Solutions:
-
Low Abundance of Target Modification:
-
Solution: Increase the starting amount of protein lysate. For many PTMs, starting with 1-5 mg of protein is recommended, and for very low-level modifications, up to 20 mg might be necessary.[2][13][14] For ubiquitination studies, consider treating cells with a proteasome inhibitor to increase the amount of ubiquitinated proteins.[6]
-
-
Inefficient Protein Lysis and Digestion:
-
Solution: Ensure your lysis buffer is effective and contains protease and phosphatase inhibitors to prevent degradation.[15][16] For complete digestion, verify that the urea concentration is lowered to approximately 1-2 M before adding trypsin.[12] You can check for complete digestion by running a small aliquot of the lysate before and after digestion on an SDS-PAGE gel.[17]
-
-
Poor Antibody-Peptide Binding:
-
Solution: Check that the pH of your peptide solution and binding buffer (IAP buffer) is within the optimal range for antibody binding (typically pH 7.5-8.0).[18] Ensure you are using the recommended amount of antibody-conjugated beads for your amount of starting material. Optimize incubation time; overnight incubation at 4°C is often recommended for low-abundance PTMs.[15][18]
-
-
Loss of Peptides During Washing Steps:
-
Inefficient Elution:
Problem 2: High Background of Non-specific Peptides
Q: My mass spectrometry results show a high number of unmodified peptides. How can I increase the specificity of my enrichment?
A: High background from non-specifically bound peptides can obscure the signal from your low-abundance targets.
Possible Causes and Solutions:
-
Non-specific Binding to Beads:
-
Solution: Pre-clear your lysate by incubating it with beads that do not have the antibody conjugated before performing the actual immunoprecipitation. This will remove proteins that non-specifically bind to the bead matrix itself.[21] Also, consider blocking the antibody-conjugated beads with a protein like BSA before adding your sample.[22]
-
-
Insufficient or Inadequate Washing:
-
Solution: Increase the number of washes after peptide binding (e.g., from 3 to 5 times).[15] You can also try using more stringent wash buffers. For example, after washing with the IAP buffer, include additional washes with PBS or even plain water to remove residual detergents and non-specifically bound peptides.[6][20]
-
-
Too Much Antibody or Starting Material:
-
Antibody Quality and Specificity:
-
Solution: The specificity of the antibody is critical.[10] Not all commercial antibodies perform equally well. If possible, test antibodies from different vendors or different lots. Some studies have shown that monoclonal antibodies or cocktails of antibodies can provide better specificity and coverage.[23][24]
-
Troubleshooting Workflow Diagram
Quantitative Data: Comparison of Enrichment Reagents
The performance of antibody-based enrichment can vary significantly between different reagents. Below is a summary of data comparing different antibodies for this compound-acetylated (Ac-K) and this compound-ubiquitinated (K-ε-GG) peptide enrichment.
Table 1: Performance Comparison of Two Anti-Acetyl-Lysine (Ac-K) Antibodies
| Metric | Antibody 1 (Monoclonal, CST) | Antibody 2 (Polyclonal, ICP) | Reference |
| Identified Ac-K Peptides | 1,592 | 1,306 | [23] |
| Enrichment Specificity | ~50% | ~18% | [23] |
| Uniquely Enriched Peptides | 319 | Not specified | [23] |
| Commonly Enriched Peptides | 510 | 510 | [23] |
| Data from enrichment of tryptic peptides from mouse liver tissue. Specificity is defined as the percentage of identified peptides that were acetylated. |
Table 2: Number of Identified Ubiquitination (diGly) Sites in Various Studies
| Study/Method | Starting Material | Number of Identified diGly Sites | Reference |
| Wagner et al., 2011 | Human cells | 11,054 | [25] |
| Kim et al., 2011 | Human cells | ~19,000 | [26] |
| Akimov et al., 2018 | Rice young panicles | 1,638 | [25] |
| Bezstarosti et al., 2020 | HeLa cells + proteasome inhibitor | >23,000 | [11] |
| The number of identified sites depends heavily on the sample type, starting amount, enrichment protocol, and mass spectrometry instrumentation. |
Experimental Protocols
Protocol 1: Immunoaffinity Enrichment of Acetyl-Lysine (Ac-K) Peptides
This protocol is a general guideline for the enrichment of acetylated peptides from a complex protein digest using anti-acetyl-lysine antibody-conjugated beads.
Materials:
-
Protein lysate (1-5 mg)
-
DTT (1.25 M stock)
-
Iodoacetamide (freshly prepared solution)
-
Trypsin
-
Anti-Acetyl-Lysine Agarose Beads
-
IAP (Immunoaffinity Purification) Buffer (e.g., 50 mM MOPS/NaOH pH 7.2, 10 mM Na2HPO4, 50 mM NaCl)
-
Wash Buffers (e.g., IAP Buffer, PBS, Water)
-
Elution Buffer (e.g., 0.15% TFA in water)
-
C18 StageTips for desalting
Procedure:
-
Protein Digestion:
-
Lyse cells or tissue in a denaturing buffer (e.g., 8 M urea buffer).
-
Reduce cysteine bonds with DTT and alkylate with iodoacetamide.[17]
-
Dilute the lysate to <2 M urea and digest with trypsin overnight at room temperature.[17]
-
Stop the digestion by acidification (e.g., with TFA) and desalt the resulting peptide mixture using a C18 solid-phase extraction cartridge.
-
Lyophilize the peptides to dryness.
-
-
Bead Preparation:
-
Transfer the desired amount of anti-acetyl-lysine agarose bead slurry (e.g., 40 µL) to a new microcentrifuge tube.
-
Wash the beads three times with 1 mL of IAP buffer, centrifuging at 1,000 x g for 1 minute between washes.[18]
-
-
Immunoaffinity Purification:
-
Washing:
-
Elution:
-
Add 50-100 µL of Elution Buffer (0.15% TFA) to the beads.
-
Vortex briefly and incubate for 5-10 minutes at room temperature.
-
Centrifuge at 2,000 x g for 1 minute and carefully collect the supernatant.
-
Repeat the elution step and pool the eluates.[20]
-
-
Sample Cleanup:
-
Desalt the eluted peptides using C18 StageTips.
-
Dry the purified peptides in a vacuum concentrator and store at -80°C until LC-MS/MS analysis.
-
Protocol 2: Enrichment of Ubiquitin Remnant (K-ε-GG) Peptides
This protocol describes the specific enrichment of peptides containing the di-glycine remnant of ubiquitin.
Materials:
-
Protein digest (10-20 mg)
-
Anti-K-ε-GG Motif Antibody conjugated to Protein A Agarose beads
-
IAP Buffer
-
Wash Buffers (IAP Buffer, PBS, Water)
-
Elution Buffer (0.15% TFA)
Procedure:
-
Sample Preparation and Digestion:
-
Immunoaffinity Purification:
-
Washing:
-
Elution and Cleanup:
Visualization of Key Processes
General Workflow for PTM Peptide Enrichment
Principle of Antibody-Based PTM Enrichment
References
- 1. This compound acetylation stoichiometry and proteomics analyses reveal pathways regulated by sirtuin 1 in human cells - PMC [pmc.ncbi.nlm.nih.gov]
- 2. High-Resolution Mass Spectrometry to Identify and Quantify Acetylation Protein Targets - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Modification-specific proteomics: Strategies for characterization of post-translational modifications using enrichment techniques - PMC [pmc.ncbi.nlm.nih.gov]
- 4. m.youtube.com [m.youtube.com]
- 5. Detection of Protein Ubiquitination Sites by Peptide Enrichment and Mass Spectrometry [jove.com]
- 6. Large-Scale Identification of Ubiquitination Sites by Mass Spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 7. m.youtube.com [m.youtube.com]
- 8. Automated Immunoprecipitation Workflow for Comprehensive Acetylome Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Automated Immunoprecipitation Workflow for Comprehensive Acetylome Analysis | Springer Nature Experiments [experiments.springernature.com]
- 10. Generation of acetylthis compound antibodies and affinity enrichment of acetylated peptides - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Detection of Protein Ubiquitination Sites by Peptide Enrichment and Mass Spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Simultaneous Quantification of the Acetylome and Succinylome by ‘One‐Pot’ Affinity Enrichment - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Quantification and Identification of Post-Translational Modifications Using Modern Proteomics Approaches - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Proteome-wide enrichment of proteins modified by this compound methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 15. hycultbiotech.com [hycultbiotech.com]
- 16. Enrichment of histone tail methylated this compound residues via cavitand-decorated magnetic nanoparticles for ultra-sensitive proteomics - PMC [pmc.ncbi.nlm.nih.gov]
- 17. media.cellsignal.com [media.cellsignal.com]
- 18. immunechem.com [immunechem.com]
- 19. Immunoprecipitation of Acetyl-lysine And Western Blotting of Long-chain acyl-CoA Dehydrogenases and Beta-hydroxyacyl-CoA Dehydrogenase in Palmitic Acid Treated Human Renal Tubular Epithelial Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Video: Detection of Protein Ubiquitination Sites by Peptide Enrichment and Mass Spectrometry [jove.com]
- 21. Proteome-wide enrichment of proteins modified by this compound methylation | Semantic Scholar [semanticscholar.org]
- 22. Immunoprecipitation Troubleshooting | Antibodies.com [antibodies.com]
- 23. researchgate.net [researchgate.net]
- 24. Quantitative Acetylomics Reveals Dynamics of Protein this compound Acetylation in Mouse Livers During Aging and Upon the Treatment of Nicotinamide Mononucleotide - PMC [pmc.ncbi.nlm.nih.gov]
- 25. Ubiquitinome Profiling Reveals the Landscape of Ubiquitination Regulation in Rice Young Panicles - PMC [pmc.ncbi.nlm.nih.gov]
- 26. Systematic and quantitative assessment of the ubiquitin modified proteome - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Improving Resolution of Lysine Derivatives in Reverse-Phase HPLC
Welcome to the technical support center for the analysis of lysine derivatives by reverse-phase high-performance liquid chromatography (RP-HPLC). This resource is designed for researchers, scientists, and drug development professionals to provide troubleshooting guidance and answers to frequently asked questions to help you optimize your chromatographic separations.
Frequently Asked Questions (FAQs)
Q1: Why is derivatization often necessary for analyzing this compound by RP-HPLC?
This compound is a highly polar and hydrophilic amino acid, which results in poor retention on non-polar stationary phases like C18, commonly used in RP-HPLC.[1] Derivatization is employed to increase the hydrophobicity of the this compound molecule, thereby improving its retention and interaction with the stationary phase. This leads to better separation from other sample components and enhanced detection sensitivity, especially when using UV or fluorescence detectors.[2] Common derivatization reagents for amino acids include Dansyl Chloride, o-Phthalaldehyde (OPA), and 9-fluorenylmethyl chloroformate (FMOC-Cl).[2][3][4]
Q2: Which derivatization reagent should I choose for my this compound analysis?
The choice of derivatization reagent depends on several factors, including the detection method, the complexity of the sample matrix, and the desired sensitivity.
-
Dansyl Chloride: Reacts with primary and secondary amino groups to form stable, fluorescent derivatives that also absorb UV light.[5][6] The derivatization process is straightforward but may require heating and longer reaction times.[5]
-
o-Phthalaldehyde (OPA): Reacts rapidly with primary amino acids in the presence of a thiol to form highly fluorescent isoindole derivatives.[7][8] This method is fast and sensitive but the derivatives can be unstable.[7][8]
-
9-fluorenylmethyl chloroformate (FMOC-Cl): Reacts with both primary and secondary amino acids to produce stable, fluorescent adducts.[3][4]
The following table summarizes key characteristics of common derivatization reagents:
| Derivatization Reagent | Target Amines | Detection Method | Derivative Stability | Key Advantages | Key Disadvantages |
| Dansyl Chloride | Primary & Secondary | Fluorescence, UV | Good | Stable derivatives, good for quantification.[9] | Slower reaction, may require heating.[5] |
| o-Phthalaldehyde (OPA) | Primary | Fluorescence | Less Stable | Fast reaction, high sensitivity.[7][8] | Derivatives can be unstable.[7] |
| FMOC-Cl | Primary & Secondary | Fluorescence | Good | Reacts with both primary and secondary amines.[3][4] | Reagent is moisture-sensitive.[4] |
Q3: How does mobile phase pH affect the resolution of this compound derivatives?
The pH of the mobile phase is a critical parameter that influences the retention and peak shape of ionizable compounds like this compound derivatives.[10] By adjusting the pH, you can control the ionization state of the analyte and any residual silanol groups on the silica-based stationary phase.
-
For basic compounds like this compound derivatives: Lowering the mobile phase pH (e.g., to pH 2-4) protonates the residual silanol groups on the column, minimizing secondary interactions that can cause peak tailing.[10][11] This leads to sharper, more symmetrical peaks and improved resolution.
-
Operating near the pKa of the analyte should be avoided as it can lead to inconsistent ionization and asymmetrical peaks.[12] It is recommended to work at a pH at least one unit away from the pKa of the analyte for robust and reproducible results.[9]
Q4: What is the role of the organic modifier in the mobile phase?
The organic modifier (e.g., acetonitrile or methanol) in the mobile phase controls the retention time and selectivity of the separation in RP-HPLC.
-
Solvent Strength: Increasing the percentage of the organic modifier decreases the polarity of the mobile phase, which reduces the retention time of the analytes. Conversely, decreasing the organic content increases retention.[13]
-
Selectivity: Different organic modifiers can offer different selectivities. For instance, switching from acetonitrile to methanol can alter the elution order of compounds in a mixture, potentially improving the resolution of co-eluting peaks.[13]
Troubleshooting Guides
This section provides a systematic approach to troubleshooting common issues encountered during the analysis of this compound derivatives by RP-HPLC.
Issue 1: Poor Resolution
Poor resolution, where two adjacent peaks are not well separated, is a common problem.
Caption: A logical workflow for troubleshooting poor resolution in HPLC.
| Potential Cause | Recommended Solution |
| Incorrect mobile phase composition | Optimize the mobile phase by adjusting the percentage of the organic modifier or changing the pH.[13] A lower percentage of organic solvent will generally increase retention and may improve separation.[13] |
| Inappropriate column chemistry | If resolution is not achieved by modifying the mobile phase, consider a column with a different stationary phase (e.g., phenyl-hexyl) to alter selectivity. |
| Column degradation | Over time, columns can lose efficiency. If performance does not improve with mobile phase optimization, consider replacing the column. |
| High flow rate | A lower flow rate can sometimes enhance separation, although it will increase the analysis time.[13] |
Issue 2: Peak Tailing
Peak tailing, where the back of the peak is broader than the front, can compromise resolution and quantification.
Caption: A systematic approach to troubleshooting peak tailing.
| Potential Cause | Recommended Solution |
| Secondary interactions with silanol groups | For basic analytes like this compound derivatives, secondary interactions with ionized silanol groups on the silica support are a primary cause of tailing.[11][14] Lowering the mobile phase pH to around 3.0 or below will protonate the silanols and minimize these interactions.[11] |
| Column overload | Injecting too much sample can saturate the stationary phase and lead to peak distortion.[14] To check for this, dilute your sample and re-inject. If the peak shape improves, reduce the sample concentration or injection volume.[14] |
| Column bed deformation or contamination | A void at the column inlet or accumulation of particles on the frit can cause peak tailing.[14] If the problem persists after addressing other potential causes, consider replacing the guard column or the analytical column.[14] |
| Inappropriate mobile phase pH | Operating near the pKa of the analyte can lead to mixed ionization states and result in tailing.[12] Ensure the mobile phase pH is at least one unit away from the analyte's pKa. |
Issue 3: Peak Broadening
Broad peaks can obscure smaller adjacent peaks and reduce the overall resolution of the chromatogram.
| Potential Cause | Recommended Solution |
| Extra-column volume | Excessive tubing length or large internal diameter tubing between the injector, column, and detector can cause band broadening.[12] Use tubing with a small internal diameter and keep the length to a minimum. |
| Poor column efficiency | An old or poorly packed column will exhibit reduced efficiency. If you observe a general loss of peak sharpness for all components, the column may need to be replaced.[13] |
| High flow rate | An excessively high flow rate may not allow for proper partitioning of the analyte between the mobile and stationary phases, leading to broader peaks.[13] Try reducing the flow rate. |
| Sample solvent incompatibility | If the sample is dissolved in a solvent much stronger than the mobile phase, it can cause peak distortion. Whenever possible, dissolve the sample in the initial mobile phase.[15] |
Issue 4: Inconsistent Retention Times
Fluctuations in retention times can make peak identification and quantification unreliable.
| Potential Cause | Recommended Solution |
| Fluctuations in mobile phase composition or flow rate | Ensure the mobile phase is well-mixed and degassed.[16] Check the HPLC pump for any leaks or pressure fluctuations.[16] |
| Changes in column temperature | Inconsistent column temperature can lead to shifts in retention times. Use a column oven to maintain a stable temperature.[16] |
| Column equilibration | Ensure the column is properly equilibrated with the mobile phase before starting a sequence of injections. Inadequate equilibration can cause retention time drift.[17] |
| Mobile phase degradation | Some mobile phase components can degrade over time. Prepare fresh mobile phase regularly.[16] |
Experimental Protocols
Protocol 1: Dansyl Chloride Derivatization of this compound
This protocol is a general guideline for the pre-column derivatization of this compound with Dansyl Chloride.[6][9]
Materials:
-
This compound standard or sample solution
-
0.04 M Lithium Carbonate (Li₂CO₃) buffer, pH 9.5
-
Dansyl Chloride solution (e.g., 9.6 M in acetonitrile)
-
10% Methylamine solution in Li₂CO₃ buffer
-
Acetonitrile (HPLC grade)
Procedure:
-
If necessary, dilute the sample 1:1 in 0.04 M Li₂CO₃ buffer (pH 9.5).
-
To 50 µL of the sample solution, add 100 µL of the Dansyl Chloride solution.
-
Vortex the mixture and incubate for 30 minutes at 60°C in a water bath, protected from light.
-
After incubation, add 10 µL of 10% methylamine solution to quench the reaction by consuming the excess Dansyl Chloride.
-
The derivatized sample is now ready for HPLC analysis.
Protocol 2: OPA Derivatization of this compound
This protocol describes a rapid, automated pre-column derivatization of primary amino acids like this compound using OPA.[7][8]
Materials:
-
This compound standard or sample solution
-
Derivatization reagent: Dissolve 10 mg of o-Phthalaldehyde (OPA) in 0.2 mL of methanol, then add 1.8 mL of 200 mmol/L potassium tetraborate buffer (pH 9.5) and 10 µL of 3-mercaptopropionic acid (3-MPA).[8]
Procedure (can be automated using an autosampler):
-
Mix 50 µL of the derivatization reagent with 50 µL of the sample solution.
-
Allow the mixture to react for a short, optimized time (e.g., 30 seconds to 1 minute).[7][18]
-
Inject the derivatized sample directly onto the HPLC column.
Data Presentation
Table 1: Effect of Mobile Phase pH on Retention Time of a this compound Derivative
The following table illustrates the typical effect of mobile phase pH on the retention time of a basic this compound derivative in RP-HPLC. As the pH decreases, the retention time generally increases due to the suppression of secondary interactions with silanol groups.
| Mobile Phase pH | Retention Time (min) | Peak Asymmetry (Tailing Factor) |
| 7.0 | 3.5 | 2.1 |
| 5.0 | 4.2 | 1.8 |
| 3.0 | 6.8 | 1.2 |
| 2.5 | 7.5 | 1.1 |
Note: These are representative values and will vary depending on the specific this compound derivative, column, and other chromatographic conditions.
Table 2: Effect of Acetonitrile Percentage on Resolution
This table demonstrates how the percentage of acetonitrile in the mobile phase can impact the resolution of two closely eluting this compound derivatives.
| Acetonitrile (%) | Retention Time - Peak 1 (min) | Retention Time - Peak 2 (min) | Resolution (Rs) |
| 50 | 4.1 | 4.5 | 1.2 |
| 45 | 5.8 | 6.5 | 1.8 |
| 40 | 8.2 | 9.3 | 2.5 |
| 35 | 12.5 | 14.2 | 2.9 |
Note: These are representative values. The optimal organic solvent percentage needs to be determined empirically for each specific separation.
Table 3: HPLC Method Validation Parameters for this compound Analysis
This table presents typical validation parameters for an HPLC method for the quantification of a this compound derivative.[19][20]
| Parameter | Typical Value |
| Linearity (r²) | > 0.999 |
| Limit of Detection (LOD) | 0.1 - 1.5 µM |
| Limit of Quantification (LOQ) | 0.4 - 4.5 µM |
| Accuracy (% Recovery) | 92% ± 2% |
| Precision (RSD%) | < 2% |
| Resolution (Rs) | > 2.0 |
| Tailing Factor | < 1.6 |
Note: These values are examples and the acceptance criteria may vary depending on the application and regulatory requirements.
Signaling Pathways and Workflows
Experimental Workflow: Sample Preparation to HPLC Analysis
Caption: A general workflow for the analysis of this compound derivatives by RP-HPLC.
References
- 1. Understanding Peak Tailing in HPLC | Phenomenex [phenomenex.com]
- 2. uhplcs.com [uhplcs.com]
- 3. Optimizing Sample Preparation for Accurate this compound Measurement - Creative Proteomics [metabolomics.creative-proteomics.com]
- 4. benchchem.com [benchchem.com]
- 5. scribd.com [scribd.com]
- 6. researchgate.net [researchgate.net]
- 7. jascoinc.com [jascoinc.com]
- 8. Simple and rapid quantitative high-performance liquid chromatographic analysis of plasma amino acids - PMC [pmc.ncbi.nlm.nih.gov]
- 9. mdpi.com [mdpi.com]
- 10. moravek.com [moravek.com]
- 11. elementlabsolutions.com [elementlabsolutions.com]
- 12. chromtech.com [chromtech.com]
- 13. Advanced Guide to HPLC Troubleshooting: solve 7 common issues like a pro! [pharmacores.com]
- 14. gmpinsiders.com [gmpinsiders.com]
- 15. benchchem.com [benchchem.com]
- 16. jetir.org [jetir.org]
- 17. ccc.chem.pitt.edu [ccc.chem.pitt.edu]
- 18. diva-portal.org [diva-portal.org]
- 19. Development and Validation of New HPLC Method for Simultaneous Estimation of L-Lysine Hydrochloride and L-Carnitine-L-Tartrate in Pharmaceutical Dosage Form - PMC [pmc.ncbi.nlm.nih.gov]
- 20. Validation of a Simple HPLC-Based Method for this compound Quantification for Ruminant Nutrition - PMC [pmc.ncbi.nlm.nih.gov]
Validation & Comparative
Validating Lysine Methylation Sites: A Comparative Guide to Site-Directed Mutagenesis and Other Techniques
The post-translational modification of lysine residues through methylation is a critical regulatory mechanism in a vast array of cellular processes, including chromatin remodeling, gene expression, and protein-protein interactions.[1][2] Identifying and validating these methylation sites are crucial steps in understanding the functional consequences of this modification. Site-directed mutagenesis (SDM) serves as a powerful tool for functional validation, allowing researchers to probe the role of a specific this compound residue. This guide provides a comparative overview of SDM for validating this compound methylation sites against other common techniques, complete with experimental protocols and data presentation.
Site-Directed Mutagenesis: Probing Functional Significance
Site-directed mutagenesis involves the specific alteration of an amino acid residue within a protein to study its impact on protein function.[3] To validate the importance of a this compound methylation event, the target this compound is typically mutated to an amino acid that cannot be methylated. The functional consequences of this mutation can then be assessed through various assays.
Two common substitutions for this compound in this context are arginine and alanine.
-
This compound to Arginine (K-to-R) Mutation : This is often the preferred mutation as arginine is also a positively charged, basic amino acid, similar to this compound.[4] This substitution helps to preserve the local electrostatic environment of the protein, allowing researchers to investigate the specific role of the methyl group, rather than the loss of positive charge. The guanidinium group of arginine can form a greater number of electrostatic interactions compared to this compound.[4]
-
This compound to Alanine (K-to-A) Mutation : Alanine scanning involves replacing a residue with alanine, which has a small, chemically inert methyl group.[3] This mutation removes the this compound side chain beyond the β-carbon, resulting in the loss of both the positive charge and the potential for methylation. This can lead to more significant structural and functional perturbations but is useful for determining the overall importance of the this compound residue itself.[5][6]
The following table summarizes hypothetical quantitative data from an experiment designed to validate a methylation site on "Protein X," a hypothetical enzyme whose activity is regulated by methylation.
| Construct | Relative Methylation Level (%) | Enzyme Activity (U/mg) | Protein Stability (Tm, °C) |
| Wild-Type (WT) | 100 | 500 | 55 |
| K125R Mutant | 0 | 450 | 54.5 |
| K125A Mutant | 0 | 150 | 50 |
Data Interpretation: The K125R mutant, which cannot be methylated but retains a positive charge, shows only a slight decrease in enzyme activity, suggesting the positive charge is important but methylation provides an additional layer of regulation. The K125A mutant, lacking both methylation and a positive charge, exhibits a drastic reduction in activity, indicating the crucial role of the this compound residue at this position.
Alternative Validation and Identification Methods
While SDM is a gold standard for functional validation, other techniques are indispensable for the initial identification and characterization of this compound methylation sites.
-
Mass Spectrometry (MS) : Mass spectrometry is the cornerstone for identifying and quantifying post-translational modifications, including this compound methylation.[7][8] Tandem mass spectrometry (LC-MS/MS) can pinpoint the exact location of methylation on a peptide sequence and even distinguish between mono-, di-, and tri-methylation states.[7][9] This high-throughput technique is essential for global profiling of this compound methylation across the proteome.[9][10]
-
Antibody-Based Methods : Antibodies that specifically recognize methylated this compound are widely used in various applications.[11]
-
Pan-methyl-lysine antibodies can detect methylated this compound residues regardless of the surrounding protein sequence.[12]
-
Methyl-state specific antibodies can differentiate between mono-, di-, and tri-methylated lysines.[12]
-
Site-specific antibodies are highly specific to a methylated this compound at a particular position within a protein.[12]
-
These antibodies are employed in techniques such as Western Blotting, ELISA, Immunoprecipitation (IP), and Immunohistochemistry (IHC) to detect and quantify protein methylation.[11]
Comparison of Validation Methods
| Method | Primary Purpose | Specificity | Throughput | Key Advantages | Key Disadvantages |
| Site-Directed Mutagenesis (SDM) | Functional validation | High (for the targeted site) | Low | Directly assesses the functional role of a specific methylation event. | Does not identify new sites; can be time-consuming. |
| Mass Spectrometry (MS) | Identification and quantification | High (can pinpoint exact site and methylation state) | High | Unbiased, proteome-wide discovery of methylation sites.[7][9] | Can be expensive; may have difficulty with low-stoichiometry modifications.[7][8] |
| Antibody-Based Methods | Detection and quantification | Variable (depends on antibody quality) | Medium to High | Relatively inexpensive and accessible methods (e.g., Western Blot). | Antibody specificity can be an issue (cross-reactivity, sequence bias).[13] |
Visualizing the Workflow and Method Comparison
Caption: Workflow for identifying and validating a this compound methylation site.
Caption: Relationship and comparison of validation methods.
Experimental Protocols
This protocol outlines a standard procedure for introducing a point mutation into a plasmid DNA.
-
Primer Design : Design two complementary oligonucleotide primers, typically 25-45 bases in length, containing the desired mutation (e.g., changing a this compound codon AAG to an arginine codon AGG). The melting temperature (Tm) should be ≥78°C.
-
PCR Amplification :
-
Set up a PCR reaction containing the template plasmid DNA, the designed mutagenic primers, a high-fidelity DNA polymerase, and dNTPs.
-
Perform thermal cycling, typically 12-18 cycles, to amplify the entire plasmid, incorporating the primers.
-
-
Template Digestion : Digest the PCR product with a methylation-sensitive restriction enzyme, such as DpnI. This enzyme will specifically cleave the methylated parental DNA template, leaving the newly synthesized, unmethylated mutant plasmid intact.
-
Transformation : Transform the DpnI-treated DNA into competent E. coli cells.
-
Selection and Sequencing : Plate the transformed cells on a selective agar medium. Isolate plasmid DNA from the resulting colonies and verify the presence of the desired mutation by DNA sequencing.
-
Protein Expression and Functional Analysis : Once the mutation is confirmed, express the mutant protein and compare its function to the wild-type protein.[5]
This is a generalized workflow for identifying this compound methylation sites.
-
Protein Extraction and Digestion : Lyse cells to extract total protein.[9] Digest the proteins into smaller peptides using a protease like trypsin.[9]
-
Peptide Enrichment (Optional but Recommended) : To improve detection of low-abundance methylated peptides, perform an immunoprecipitation step using pan-specific anti-methyl this compound antibodies to enrich for these peptides.[9][10]
-
LC-MS/MS Analysis : Analyze the peptide mixture using liquid chromatography coupled to tandem mass spectrometry (LC-MS/MS).[9][14] The mass spectrometer will measure the mass-to-charge ratio of the peptides and then fragment them to determine their amino acid sequence.
-
Data Analysis : Use specialized software to search the acquired MS/MS spectra against a protein database.[14] The software identifies peptides and can pinpoint post-translational modifications, such as methylation, based on the mass shift of the modified residue.
-
Protein Separation : Separate proteins from cell lysates by size using SDS-PAGE.
-
Protein Transfer : Transfer the separated proteins from the gel to a nitrocellulose or PVDF membrane.
-
Blocking : Block the membrane with a protein-rich solution (e.g., non-fat milk or BSA) to prevent non-specific antibody binding.
-
Primary Antibody Incubation : Incubate the membrane with a primary antibody specific for the methylated this compound of interest.
-
Secondary Antibody Incubation : After washing, incubate the membrane with a secondary antibody conjugated to an enzyme (e.g., HRP) that recognizes the primary antibody.
-
Detection : Add a chemiluminescent substrate that reacts with the enzyme on the secondary antibody to produce light. Detect the signal using an imaging system to visualize the protein of interest. Compare the signal between wild-type and mutant samples.
References
- 1. Anti-Methylated this compound Antibody (SPC-158) Rabbit Polyclonal | StressMarq Biosciences Inc. [stressmarq.com]
- 2. Mass spectrometry-based identification and characterisation of this compound and arginine methylation in the human proteome - Molecular BioSystems (RSC Publishing) [pubs.rsc.org]
- 3. Alanine scanning - Wikipedia [en.wikipedia.org]
- 4. A study on the effect of surface this compound to arginine mutagenesis on protein stability and structure using green fluorescent protein - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. digitalcommons.morris.umn.edu [digitalcommons.morris.umn.edu]
- 6. "Site-Directed Mutagenesis of this compound 125 in Malate Dehydrogenase" by Taylor Prieve and Cathryn Wallmow [digitalcommons.morris.umn.edu]
- 7. Mass Spectrometry for this compound Methylation: Principles, Progress, and Prospects [mdpi.com]
- 8. Mass Spectrometry for this compound Methylation: Principles, Progress, and Prospects - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Quantitative analysis of global protein this compound methylation by mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Quantitative analysis of global protein this compound methylation by mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Anti-Methylated this compound Antibodies | Invitrogen [thermofisher.com]
- 12. creative-biolabs.com [creative-biolabs.com]
- 13. Global this compound methylome profiling using systematically characterized affinity reagents - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Proteome-wide enrichment of proteins modified by this compound methylation - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Analysis of Lysine versus Arginine in Enhancing Protein Stability
For researchers, scientists, and drug development professionals, understanding the nuanced effects of excipients on protein stability is paramount. Among the commonly used amino acids, lysine and arginine are frequently employed to mitigate aggregation and enhance the shelf-life of therapeutic proteins. This guide provides an objective comparison of their performance, supported by experimental data, to aid in the rational selection of these crucial formulation components.
Executive Summary
Both this compound and arginine, as positively charged amino acids, play significant roles in stabilizing proteins in solution, albeit through different primary mechanisms. Arginine is widely recognized for its potent ability to suppress aggregation, particularly during protein refolding, largely attributed to its unique guanidinium group that can engage in cation-π interactions and act as a "neutral crowder" to reduce protein-protein association. This compound, with its primary ε-amino group, contributes to stability through the formation of salt bridges and hydrogen bonds.
Experimental evidence suggests that the choice between this compound and arginine is context-dependent, with factors such as protein characteristics, concentration, and specific stresses influencing their efficacy. Notably, at higher concentrations (above 100 mM), this compound has been observed to be less destabilizing than arginine for certain proteins. Conversely, strategic substitution of surface lysines with arginines has been shown to enhance stability against chemical denaturation in other proteins.
Data Presentation: Quantitative Comparison
The following tables summarize quantitative data from various studies comparing the effects of this compound and arginine on protein stability.
| Protein Model | Experimental Technique | Metric | Condition | This compound Effect | Arginine Effect | Reference |
| Myoglobin, BSA, Lysozyme | Differential Scanning Calorimetry (DSC) | Change in Melting Temperature (ΔTm) | >100 mM excipient concentration | Less destabilizing | More destabilizing | [1] |
| Single-Chain Variable Fragment (scFv) | Aggregation Assay | Aggregation Rate | Denaturing conditions | N/A (mutated to from Arginine) | N/A (mutated from to this compound) | [2] |
| Green Fluorescent Protein (GFP) | Chemical Denaturation | Stability against Urea | N/A (wild-type) | N/A (mutant with Lys->Arg substitutions) | Increased stability in mutant |
Note: This table is a synthesis of data from multiple sources and direct quantitative comparison should be made with caution, considering the different protein models and experimental conditions.
Mechanisms of Action
The stabilizing effects of this compound and arginine stem from their distinct chemical structures and modes of interaction with protein molecules.
This compound: The primary mechanism of this compound's stabilizing effect is through its terminal ε-amino group. This group can participate in:
-
Electrostatic Interactions: Forming salt bridges with negatively charged residues (e.g., aspartate, glutamate) on the protein surface, which can stabilize the native conformation.
-
Hydrogen Bonding: Acting as a hydrogen bond donor, interacting with electronegative atoms on the protein or with surrounding water molecules, contributing to the hydration shell.
Arginine: Arginine's stabilizing properties are more complex and are largely attributed to its guanidinium group. The proposed mechanisms include:
-
Cation-π Interactions: The planar and delocalized positive charge of the guanidinium group can interact favorably with the electron-rich π systems of aromatic residues like tryptophan, tyrosine, and phenylalanine.
-
"Neutral Crowder" Effect: Arginine is thought to be preferentially excluded from the protein-protein interface during the formation of an encounter complex, thereby increasing the energetic barrier for association and slowing down aggregation kinetics.[3]
-
Multiple Hydrogen Bonds: The guanidinium group can act as a donor for multiple hydrogen bonds, allowing for complex and stabilizing interactions with the protein surface.
dot
References
- 1. eprints.whiterose.ac.uk [eprints.whiterose.ac.uk]
- 2. Arginine to this compound Mutations Increase the Aggregation Stability of a Single-Chain Variable Fragment through Unfolded-State Interactions - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. Role of arginine in the stabilization of proteins against aggregation - PubMed [pubmed.ncbi.nlm.nih.gov]
A Researcher's Guide to Cross-Validating Lysine Ubiquitination Sites Using Different Antibodies
For researchers, scientists, and professionals in drug development, the accurate identification and validation of lysine ubiquitination sites is paramount. This guide provides an objective comparison of various antibodies used for this purpose, supported by experimental data and detailed protocols. The goal is to equip researchers with the knowledge to select the most appropriate antibodies and techniques for their specific needs.
Understanding the Tools: A Comparison of Anti-Ubiquitin Antibodies
The choice of antibody is critical for the successful detection and validation of ubiquitinated proteins. Antibodies with different specificities are available, each suited for particular applications. This section compares commonly used anti-ubiquitin antibodies for Western Blotting (WB) and Immunoprecipitation (IP), as well as the specialized antibody for mass spectrometry-based ubiquitin remnant profiling.
Antibodies for Western Blotting and Immunoprecipitation
The validation of ubiquitination often involves immunoprecipitating a protein of interest and then detecting its ubiquitinated forms by Western blotting. Alternatively, ubiquitinated proteins can be enriched from a lysate using an anti-ubiquitin antibody, followed by detection of a specific protein. The specificity of the anti-ubiquitin antibody is a key consideration. Some antibodies recognize both free ubiquitin and ubiquitinated proteins, while others are specific for polyubiquitin chains or do not bind to free ubiquitin.
| Antibody Clone | Supplier Examples | Specificity | Validated Applications & Recommended Dilutions | Key Characteristics |
| P4D1 | Santa Cruz Biotechnology, Cell Signaling Technology, Bio-Rad, Abcam, MilliporeSigma | Recognizes both free ubiquitin and mono- and poly-ubiquitinated proteins.[1][2][3] | WB: 1:100 - 1:1000[1][4], IHC-P, Flow Cytometry (Intra)[5], IP[6] | A versatile antibody for general detection of ubiquitinated proteins. May cross-react with NEDD8.[2] |
| FK1 | Enzo Life Sciences, MilliporeSigma | Recognizes only polyubiquitin chains.[1][7][8] Does not recognize monoubiquitinated proteins or free ubiquitin.[7][8] | WB: 1:500 - 1:1000[1][4], IHC[8], ELISA, Immunoaffinity Chromatography[7] | Ideal for specifically studying polyubiquitination. Can be used in conjunction with FK2 to distinguish between mono- and polyubiquitination.[3] |
| FK2 | Enzo Life Sciences, MilliporeSigma, MBL Life Science | Recognizes both mono- and polyubiquitinated proteins.[1][7] Does not recognize free ubiquitin.[7][9] | WB, IP: 1:50[10], ELISA, IF, Immunoaffinity Chromatography[7] | Useful for enriching all ubiquitinated forms of a protein without capturing free ubiquitin. |
| Ubi-1 | Merck Millipore | Detects ubiquitin. | WB: 1:1000, IHC[11] | |
| VU101, U5379, AP1228a, P4G7-H11 | Various | General anti-ubiquitin antibodies. | WB: 1:100 - 1:2000 (U5379), 1:1000 (others)[4][12] | Performance can vary significantly between different antibodies and experimental conditions.[4][12] |
| K63-linkage specific | Bio-Rad | Specific for K63-linked polyubiquitin chains. | WB, FCM, IF, IHC[6] | Essential for studying non-degradative ubiquitin signaling pathways. |
Note: Antibody performance can be influenced by factors such as the blocking reagent used (e.g., BSA vs. non-fat milk) and the denaturation of the sample.[12][13] It is always recommended to validate the antibody in your specific experimental setup.
Antibody for Mass Spectrometry: The K-ε-GG Remnant Antibody
For unambiguous identification of ubiquitination sites by mass spectrometry (MS), a specialized antibody that recognizes the di-glycine (K-ε-GG) remnant of ubiquitin is employed.[14][15][16] After trypsin digestion of a protein lysate, ubiquitinated this compound residues are left with this signature remnant. Immunoaffinity enrichment of these K-ε-GG containing peptides dramatically improves the detection of endogenous ubiquitination sites.[14][17][18]
| Antibody | Specificity | Application | Key Advantages |
| Anti-K-ε-GG (di-glycine remnant) | Recognizes the K-ε-GG remnant on this compound residues after tryptic digestion.[15][16] | Immunoaffinity enrichment of ubiquitinated peptides for LC-MS/MS analysis.[19][20] | Enables the identification and quantification of thousands of endogenous ubiquitination sites in a single experiment.[14][17][18] High specificity reduces the misassignment of other modifications.[21] |
Experimental Workflows and Logical Relationships
The following diagrams illustrate the key experimental workflows for the cross-validation of this compound ubiquitination sites.
Detailed Experimental Protocols
This section provides detailed methodologies for the key experiments involved in the cross-validation of this compound ubiquitination sites.
Protocol 1: Immunoprecipitation of Ubiquitinated Proteins
This protocol describes the immunoprecipitation of a target protein to assess its ubiquitination status, or the enrichment of all ubiquitinated proteins from a cell lysate.
1. Cell Lysis:
-
Harvest cells and wash with ice-cold PBS.
-
Lyse cells in a suitable lysis buffer (e.g., RIPA buffer) supplemented with protease and deubiquitinase inhibitors (e.g., NEM, PR-619).
-
Incubate on ice and then centrifuge to pellet cell debris. Collect the supernatant.
2. Pre-clearing (Optional but Recommended):
-
Add Protein A/G agarose beads to the cell lysate and incubate with rotation at 4°C to reduce non-specific binding.
-
Centrifuge and collect the supernatant.
3. Immunoprecipitation:
-
Add the primary antibody (either against the protein of interest or an anti-ubiquitin antibody like FK2) to the pre-cleared lysate.
-
Incubate with rotation at 4°C.
-
Add Protein A/G agarose beads and continue the incubation to capture the antibody-protein complexes.
4. Washing:
-
Pellet the beads by centrifugation and discard the supernatant.
-
Wash the beads multiple times with wash buffer to remove non-specifically bound proteins.
5. Elution:
-
Elute the immunoprecipitated proteins from the beads by adding SDS-PAGE sample buffer and boiling.
-
The eluate is now ready for Western blot analysis.
Protocol 2: Western Blotting for Ubiquitinated Proteins
This protocol details the detection of ubiquitinated proteins following immunoprecipitation or in a total cell lysate.
1. SDS-PAGE and Transfer:
-
Load the eluted samples from the IP or total cell lysates onto an SDS-PAGE gel and perform electrophoresis.
-
Transfer the separated proteins to a PVDF or nitrocellulose membrane.
2. Blocking:
-
Block the membrane with a suitable blocking buffer (e.g., 5% non-fat milk or BSA in TBST) to prevent non-specific antibody binding.
3. Antibody Incubation:
-
Incubate the membrane with the primary antibody (e.g., anti-ubiquitin P4D1 or an antibody against the protein of interest) diluted in blocking buffer.
-
Wash the membrane with TBST.
-
Incubate with a horseradish peroxidase (HRP)-conjugated secondary antibody.
4. Detection:
-
Wash the membrane again with TBST.
-
Add an enhanced chemiluminescence (ECL) substrate and visualize the protein bands using an imaging system. A ladder-like pattern of higher molecular weight bands is indicative of polyubiquitination.
Protocol 3: Ubiquitin Remnant Immunoaffinity Profiling for Mass Spectrometry
This protocol outlines the enrichment of ubiquitinated peptides for subsequent identification of ubiquitination sites by mass spectrometry.
1. Protein Extraction and Digestion:
-
Lyse cells in a urea-containing buffer to denature proteins.
-
Reduce and alkylate the cysteine residues.
-
Digest the proteins into peptides using trypsin.
2. Peptide Purification:
-
Purify the resulting peptides using a solid-phase extraction method (e.g., C18 desalting).
3. Immunoaffinity Enrichment:
-
Incubate the purified peptides with anti-K-ε-GG antibody-conjugated beads to capture the ubiquitin remnant-containing peptides.
-
Wash the beads extensively to remove non-modified peptides.
4. Elution and Desalting:
-
Elute the enriched peptides from the antibody beads using a low pH buffer.
-
Desalt the eluted peptides using a micro-C18 tip.
5. LC-MS/MS Analysis:
-
Analyze the enriched peptides by liquid chromatography-tandem mass spectrometry (LC-MS/MS).
-
The resulting data is then searched against a protein database to identify the ubiquitinated proteins and the specific this compound residues that were modified.
By carefully selecting antibodies based on their specificity and application, and by employing rigorous experimental protocols, researchers can confidently and accurately cross-validate this compound ubiquitination sites, paving the way for a deeper understanding of the roles of ubiquitination in health and disease.
References
- 1. Using Antiubiquitin Antibodies to Probe the Ubiquitination State Within rhTRIM5α Cytoplasmic Bodies - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Ubiquitin (P4D1) Mouse Monoclonal Antibody | Cell Signaling Technology [cellsignal.com]
- 3. bio-rad-antibodies.com [bio-rad-antibodies.com]
- 4. Western Blotting Inaccuracies with Unverified Antibodies: Need for a Western Blotting Minimal Reporting Standard (WBMRS) | PLOS One [journals.plos.org]
- 5. Anti-Ubiquitin antibody [P4D1] Mouse monoclonal (ab303664) | Abcam [abcam.com]
- 6. biocompare.com [biocompare.com]
- 7. Production of antipolyubiquitin monoclonal antibodies and their use for characterization and isolation of polyubiquitinated proteins - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Anti-Ubiquitinylated proteins Antibody, clone FK1 clone FK1, Upstate®, from mouse | Sigma-Aldrich [sigmaaldrich.com]
- 9. merckmillipore.com [merckmillipore.com]
- 10. biocompare.com [biocompare.com]
- 11. merckmillipore.com [merckmillipore.com]
- 12. researchgate.net [researchgate.net]
- 13. Optimising methods for the preservation, capture and identification of ubiquitin chains and ubiquitylated proteins by immunoblotting - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Refined Preparation and Use of Anti-diglycine Remnant (K-ε-GG) Antibody Enables Routine Quantification of 10,000s of Ubiquitination Sites in Single Proteomics Experiments - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Global analysis of this compound ubiquitination by ubiquitin remnant immunoaffinity profiling - PMC [pmc.ncbi.nlm.nih.gov]
- 16. researchgate.net [researchgate.net]
- 17. Refined preparation and use of anti-diglycine remnant (K-ε-GG) antibody enables routine quantification of 10,000s of ubiquitination sites in single proteomics experiments - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. researchgate.net [researchgate.net]
- 19. PTMScan® Pilot Ubiquitin Remnant Motif (K-epsilon-GG) Kit | Cell Signaling Technology [cellsignal.com]
- 20. Global Mass Spectrometry-Based Analysis of Protein Ubiquitination Using K-ε-GG Remnant Antibody Enrichment - PubMed [pubmed.ncbi.nlm.nih.gov]
- 21. Proteomic Identification of Protein Ubiquitination Events - PMC [pmc.ncbi.nlm.nih.gov]
A Functional Comparison of Lysine Acetylation and Methylation on Histones: A Guide for Researchers
For Researchers, Scientists, and Drug Development Professionals
The post-translational modification of histone proteins, particularly the acetylation and methylation of lysine residues, plays a pivotal role in regulating chromatin structure and gene expression. Understanding the distinct and sometimes overlapping functions of these two modifications is crucial for deciphering the epigenetic code and for the development of novel therapeutic strategies targeting chromatin-modifying enzymes. This guide provides an objective comparison of this compound acetylation and methylation on histones, supported by experimental data and detailed protocols.
Core Functional Comparison: Acetylation vs. Methylation
Histone this compound acetylation and methylation are dynamic marks that are "written," "erased," and "read" by specific sets of enzymes and effector proteins. While both modifications target the same amino acid, their biochemical properties and downstream functional consequences are markedly different.
Acetylation , the addition of an acetyl group, neutralizes the positive charge of the this compound side chain. This charge neutralization is thought to weaken the electrostatic interactions between the histone tails and the negatively charged DNA backbone, leading to a more open and accessible chromatin structure, a state generally associated with transcriptional activation.[1][2][3][4]
Methylation , the addition of one, two, or three methyl groups, does not alter the charge of the this compound residue.[5] Instead, its functional impact is highly context-dependent and is determined by the specific this compound residue that is methylated and the degree of methylation (mono-, di-, or tri-methylation).[1][6] Histone methylation can be associated with both transcriptional activation and repression.[6][7]
Data Presentation: A Quantitative Look at the Two Modifications
The following tables summarize key quantitative and qualitative differences between histone this compound acetylation and methylation.
Table 1: General Characteristics of this compound Acetylation and Methylation
| Feature | This compound Acetylation | This compound Methylation |
| Biochemical Change | Addition of an acetyl group (COCH₃) | Addition of one, two, or three methyl groups (CH₃, (CH₃)₂, (CH₃)₃) |
| Charge Alteration | Neutralizes the positive charge of this compound | No change in charge |
| Effect on Chromatin | Generally leads to chromatin relaxation (euchromatin)[2][8] | Can lead to either chromatin relaxation or condensation (heterochromatin)[6][8] |
| Primary Role in Transcription | Predominantly associated with gene activation[3][9] | Associated with both gene activation and repression, depending on the site and degree of methylation[6][7] |
| Key Activating Marks | H3K9ac, H3K27ac, H4K16ac[3][10] | H3K4me1/2/3, H3K36me3, H3K79me3[1][6] |
| Key Repressive Marks | Generally not associated with repression | H3K9me2/3, H3K27me3, H4K20me3[1][6] |
Table 2: The Enzymatic Machinery: Writers, Erasers, and Readers
| Role | This compound Acetylation | This compound Methylation |
| Writers | Histone Acetyltransferases (HATs) - e.g., p300/CBP, GCN5, Tip60[11] | Histone this compound Methyltransferases (KMTs/HMTs) - e.g., MLL/SET family, Suv39h1, EZH2[12] |
| Erasers | Histone Deacetylases (HDACs) - e.g., HDAC1, HDAC2, SIRT1[11] | Histone this compound Demethylases (KDMs) - e.g., LSD1, JMJD family[12] |
| Readers | Proteins with Bromodomains (e.g., BRD4, TAF1)[13][14] | Proteins with Chromodomains, PHD fingers, Tudor domains (e.g., HP1, Polycomb proteins)[13][15] |
Table 3: Comparison of Reader Domain Binding Affinities
| Reader Domain | Modification Recognized | Typical Dissociation Constant (Kd) |
| Bromodomain | Acetyl-lysine | Micromolar (µM) range (relatively weak and transient)[16] |
| Chromodomain | Methyl-lysine (e.g., H3K9me3) | Nanomolar (nM) to low micromolar (µM) range (can be higher affinity) |
| PHD Finger | Methyl-lysine (e.g., H3K4me3) | Low micromolar (µM) range |
Mandatory Visualization
The following diagrams illustrate key concepts and workflows related to histone acetylation and methylation.
Caption: Signaling pathways for histone this compound acetylation and methylation.
Caption: A generalized workflow for Chromatin Immunoprecipitation Sequencing (ChIP-seq).
Caption: Logical relationship of histone acetylation versus methylation in gene regulation.
Experimental Protocols
Detailed methodologies for key experiments are provided below. These protocols are generalized and may require optimization for specific cell types and antibodies.
Chromatin Immunoprecipitation Sequencing (ChIP-seq) Protocol for Histone Modifications
This protocol outlines the major steps for performing a ChIP-seq experiment to map the genome-wide localization of a specific histone modification.[17][18]
-
Cell Cross-linking and Lysis:
-
Culture cells to the desired confluency.
-
Add formaldehyde to a final concentration of 1% to cross-link proteins to DNA. Incubate for 10 minutes at room temperature.
-
Quench the cross-linking reaction by adding glycine to a final concentration of 125 mM.
-
Harvest cells and wash with ice-cold PBS.
-
Lyse cells to release nuclei.
-
-
Chromatin Sonication:
-
Resuspend the nuclear pellet in a suitable lysis buffer.
-
Sonicate the chromatin to shear the DNA into fragments of 200-700 base pairs. The sonication conditions (power, duration, cycles) must be optimized.
-
Centrifuge to pellet cellular debris and collect the supernatant containing the sheared chromatin.
-
-
Immunoprecipitation:
-
Pre-clear the chromatin with protein A/G beads.
-
Incubate the pre-cleared chromatin with a specific antibody against the histone modification of interest (e.g., anti-H3K27ac or anti-H3K9me3) overnight at 4°C with rotation.
-
Add protein A/G beads to capture the antibody-chromatin complexes. Incubate for 2-4 hours at 4°C.
-
Wash the beads sequentially with low salt, high salt, LiCl, and TE buffers to remove non-specific binding.
-
-
Elution and Reverse Cross-linking:
-
Elute the chromatin from the beads.
-
Reverse the cross-links by incubating at 65°C overnight with the addition of NaCl.
-
Treat with RNase A and Proteinase K to remove RNA and protein.
-
-
DNA Purification:
-
Purify the ChIP DNA using a PCR purification kit or phenol-chloroform extraction followed by ethanol precipitation.
-
-
Library Preparation and Sequencing:
-
Perform end-repair, A-tailing, and adapter ligation to prepare the DNA for sequencing.
-
Amplify the library by PCR.
-
Perform size selection of the library.
-
Sequence the library on a high-throughput sequencing platform.
-
-
Data Analysis:
-
Align the sequencing reads to a reference genome.
-
Perform peak calling to identify regions of enrichment for the histone modification.
-
Annotate peaks to genomic features (promoters, enhancers, etc.).
-
Perform downstream analysis such as differential binding analysis and pathway analysis.
-
Mass Spectrometry-Based Analysis of Histone Modifications
This protocol provides a general workflow for the quantitative analysis of histone post-translational modifications (PTMs) using bottom-up mass spectrometry.[1][19][20]
-
Histone Extraction:
-
Isolate nuclei from cells or tissues.
-
Extract histones from the nuclei using acid extraction (e.g., with sulfuric acid).
-
Precipitate the histones with trichloroacetic acid (TCA).
-
Wash the histone pellet with acetone and air dry.
-
-
Histone Derivatization and Digestion:
-
To enable efficient digestion by trypsin, which cleaves after this compound and arginine, the this compound residues are first chemically modified (e.g., by propionylation) to block cleavage at these sites.
-
Digest the derivatized histones with trypsin, which will now only cleave after arginine residues, generating longer peptides that are more suitable for analysis.
-
-
Peptide Desalting:
-
Desalt the digested peptides using a C18 StageTip or a similar solid-phase extraction method to remove salts and other contaminants that can interfere with mass spectrometry.
-
-
LC-MS/MS Analysis:
-
Analyze the desalted peptides by liquid chromatography-tandem mass spectrometry (LC-MS/MS).
-
The peptides are separated by reverse-phase liquid chromatography and then introduced into the mass spectrometer.
-
The mass spectrometer acquires precursor ion scans (MS1) to determine the mass-to-charge ratio of the peptides and then fragments selected peptides to obtain tandem mass spectra (MS2) that reveal the amino acid sequence and the location and type of PTMs.
-
-
Data Analysis:
-
Use specialized software to search the acquired MS/MS spectra against a database of histone sequences to identify the peptides and their modifications.
-
Quantify the relative abundance of different modified forms of a peptide by comparing the areas of their corresponding precursor ion peaks in the MS1 scans.
-
Perform statistical analysis to identify significant changes in histone PTMs between different experimental conditions.
-
Conclusion and Future Directions
The functional interplay between histone this compound acetylation and methylation is a cornerstone of epigenetic regulation. While acetylation is a relatively straightforward mark of active chromatin, methylation presents a more complex "code" that can signal either activation or repression. The continued development of high-resolution techniques like ChIP-seq and mass spectrometry is providing ever-deeper insights into the dynamic nature of these modifications and their roles in health and disease. For professionals in drug development, the enzymes that write, erase, and read these marks represent a rich landscape of therapeutic targets for a variety of diseases, including cancer and inflammatory disorders.[21][22][23] Future research will likely focus on understanding the combinatorial complexity of these and other histone modifications, their crosstalk with other epigenetic mechanisms, and the development of more specific and potent inhibitors for therapeutic intervention.
References
- 1. Complete Workflow for Analysis of Histone Post-translational Modifications Using Bottom-up Mass Spectrometry: From Histone Extraction to Data Analysis [jove.com]
- 2. Protein Interaction Domain: Bromodomain [s2.smu.edu]
- 3. The Key Role of DNA Methylation and Histone Acetylation in Epigenetics of Atherosclerosis - PMC [pmc.ncbi.nlm.nih.gov]
- 4. byjus.com [byjus.com]
- 5. chemsysbio.stanford.edu [chemsysbio.stanford.edu]
- 6. researchgate.net [researchgate.net]
- 7. Workflow of Histone Post-Translational Modification Analysis | MtoZ Biolabs [mtoz-biolabs.com]
- 8. researchgate.net [researchgate.net]
- 9. Linking histone acetylation to transcriptional regulation - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. mdpi.com [mdpi.com]
- 11. researchgate.net [researchgate.net]
- 12. Epigenetic Writers and Erasers of Histone H3 | Cell Signaling Technology [cellsignal.com]
- 13. The Role of Bromodomain Proteins in Regulating Gene Expression - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Structures of protein domains that create or recognize histone modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 15. youtube.com [youtube.com]
- 16. Structural Insights into Acetylated-Histone H4 Recognition by the Bromodomain-PHD Finger Module of Human Transcriptional Co-Activator CBP - PMC [pmc.ncbi.nlm.nih.gov]
- 17. A Semiautomated ChIP-Seq Procedure for Large-scale Epigenetic Studies - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Using ChIP-Seq Technology to Generate High-Resolution Profiles of Histone Modifications - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Complete Workflow for Analysis of Histone Post-translational Modifications Using Bottom-up Mass Spectrometry: From Histone Extraction to Data Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 20. [PDF] Complete Workflow for Analysis of Histone Post-translational Modifications Using Bottom-up Mass Spectrometry: From Histone Extraction to Data Analysis | Semantic Scholar [semanticscholar.org]
- 21. benchchem.com [benchchem.com]
- 22. mdpi.com [mdpi.com]
- 23. Histone deacetylase inhibitors: molecular mechanisms of action and clinical trials as anti-cancer drugs - PMC [pmc.ncbi.nlm.nih.gov]
A Researcher's Guide to Lysine-Targeting Cross-Linking Reagents: A Comparative Analysis
For researchers, scientists, and drug development professionals, the selection of an appropriate cross-linking reagent is a critical step in unraveling protein interactions and structure. This guide provides a comprehensive comparison of commonly used lysine-reactive cross-linking agents, supported by experimental data, detailed protocols, and visualizations to facilitate an informed decision-making process.
The covalent modification of this compound residues is a widely employed strategy to capture and analyze protein-protein interactions, stabilize protein complexes for structural studies, and create antibody-drug conjugates. The primary amine on the side chain of this compound is a readily accessible and nucleophilic target for a variety of reactive chemical groups. This guide focuses on the performance of different classes of this compound-reactive cross-linkers, offering a comparative overview of their reactivity, specificity, and efficiency.
Performance Comparison of this compound-Reactive Cross-linkers
The choice of a cross-linking reagent is dictated by several factors, including the desired spacer arm length, solubility, cleavability, and the specific application. Below is a summary of quantitative data comparing the performance of several popular this compound-reactive cross-linkers.
| Cross-linker | Type | Spacer Arm Length (Å) | Solubility | Key Features | Number of Cross-links Identified (Model System) | Reference |
| DSS (Disuccinimidyl suberate) | Homobifunctional, Non-cleavable | 11.4 | Insoluble in water (requires organic solvent) | Membrane permeable, widely used for intracellular cross-linking. | 22 (on a mixture of 7 proteins) | [1] |
| BS3 (Bis(sulfosuccinimidyl) suberate) | Homobifunctional, Non-cleavable | 11.4 | Water-soluble | Membrane impermeable, ideal for cell-surface cross-linking.[2][3] Essentially identical reactivity to DSS.[2] | Similar to DSS | [2] |
| DSG (Disuccinimidyl glutarate) | Homobifunctional, Non-cleavable | 7.7 | Insoluble in water (requires organic solvent) | Shorter spacer arm than DSS, useful for probing closer interactions. | 10 (on a mixture of 7 proteins) | [1] |
| BS2G (Bis(sulfosuccinimidyl) glutarate) | Homobifunctional, Non-cleavable | 7.7 | Water-soluble | Water-soluble analog of DSG.[2] | Not specified | |
| DSSO (Disuccinimidyl sulfoxide) | Homobifunctional, MS-cleavable | 10.1 | Insoluble in water (requires organic solvent) | Cleavable in the gas phase during mass spectrometry, aiding in the identification of cross-linked peptides.[2] | Fewer than DSS/BS3 with CID/HCD, but more with MS2-MS3 methods | [2] |
| DSSBU (Disulfodisuccinimidyl dibutyric urea) | Homobifunctional, MS-cleavable | Not specified | Water-soluble | A novel water-soluble, MS-cleavable cross-linker. | Surpasses its non-cleavable analog BS3 in performance. | [3] |
Experimental Protocols
Detailed methodologies are crucial for reproducible and reliable cross-linking experiments. Below are protocols for key experiments cited in this guide.
Protocol 1: General Protein Cross-linking with NHS Esters (DSS/BS3)
This protocol provides a general procedure for cross-linking proteins using N-hydroxysuccinimide (NHS) ester-based reagents like DSS and BS3.
Materials:
-
Purified protein sample in an amine-free buffer (e.g., PBS, HEPES, Borate) at a concentration of 1-10 mg/mL.
-
DSS or BS3 cross-linker.
-
Anhydrous DMSO or DMF (for DSS).
-
Quenching buffer: 1 M Tris-HCl, pH 7.5.
-
Reaction buffer: Phosphate-buffered saline (PBS), pH 7.2-8.0.
Procedure:
-
Sample Preparation: Ensure the protein sample is in an amine-free buffer. Buffers containing primary amines, such as Tris, will compete with the cross-linking reaction.
-
Cross-linker Preparation: Immediately before use, dissolve DSS in DMSO or DMF to a stock concentration of 10-25 mM. For BS3, dissolve it directly in the reaction buffer to a similar stock concentration.
-
Cross-linking Reaction: Add the cross-linker solution to the protein sample to achieve the desired molar excess of cross-linker to protein (e.g., 20- to 50-fold molar excess).
-
Incubation: Incubate the reaction mixture for 30-60 minutes at room temperature or for 2 hours on ice. The optimal time and temperature may need to be determined empirically.
-
Quenching: Stop the reaction by adding the quenching buffer to a final concentration of 20-50 mM. The primary amines in the quenching buffer will react with any excess cross-linker. Incubate for 15 minutes at room temperature.
-
Analysis: The cross-linked sample is now ready for analysis by SDS-PAGE, mass spectrometry, or other downstream applications.
Protocol 2: Quantitative Cross-linking Mass Spectrometry (qXL-MS)
This protocol outlines a general workflow for the quantitative analysis of cross-linked peptides using mass spectrometry, often employing isotopically labeled cross-linkers.
Materials:
-
Biological samples under different conditions (e.g., treated vs. untreated).
-
"Light" and "heavy" isotopically labeled cross-linkers (e.g., BS3-d0 and BS3-d4).
-
Standard proteomics reagents for protein digestion (e.g., DTT, iodoacetamide, trypsin).
-
LC-MS/MS system.
-
Data analysis software capable of identifying and quantifying cross-linked peptides (e.g., Skyline, xQuest).
Procedure:
-
Differential Cross-linking: Cross-link the protein samples from the different conditions separately, one with the "light" cross-linker and the other with the "heavy" cross-linker, following a protocol similar to Protocol 1.
-
Sample Combination: After quenching the reactions, combine the "light" and "heavy" cross-linked samples in a 1:1 ratio.
-
Protein Digestion: Reduce, alkylate, and digest the combined protein sample with a protease (e.g., trypsin) to generate peptides.
-
Enrichment of Cross-linked Peptides (Optional but Recommended): Use techniques like size-exclusion chromatography (SEC) or strong cation exchange (SCX) to enrich for the larger, cross-linked peptides.
-
LC-MS/MS Analysis: Analyze the enriched peptide mixture using a high-resolution mass spectrometer. The instrument should be operated in a data-dependent acquisition mode to acquire both MS1 survey scans and MS/MS fragmentation spectra.
-
Data Analysis: Use specialized software to identify the cross-linked peptide pairs based on their mass and fragmentation patterns. The relative quantification of the "light" and "heavy" forms of each cross-linked peptide will reveal changes in protein conformation or interaction between the different sample conditions.
Visualizing Cross-linking Concepts and Workflows
Diagrams are essential for understanding complex biological processes and experimental designs. The following visualizations were created using the DOT language.
Caption: General mechanism of this compound-reactive cross-linking.
Caption: Experimental workflow for protein cross-linking.
Caption: Workflow for quantitative cross-linking mass spectrometry.
References
A Head-to-Head Comparison: Colorimetric vs. Fluorometric Assays for Lysine Quantification
For researchers, scientists, and drug development professionals, the accurate quantification of lysine is crucial in a multitude of fields, from nutritional analysis to the study of protein modifications and metabolic diseases. The choice of analytical method can significantly impact the quality and reliability of experimental data. This guide provides an objective, side-by-side comparison of the two most common methods for this compound detection: colorimetric and fluorometric assays. We will delve into their underlying principles, performance characteristics, and experimental workflows, supported by experimental data to inform your selection process.
Principle of Detection
Both colorimetric and fluorometric assays for this compound often rely on the same initial enzymatic reaction. L-lysine is specifically oxidized by this compound oxidase, producing 6-amino-2-oxohexanoate, ammonia (NH3), and hydrogen peroxide (H₂O₂). The key difference between the two methods lies in the subsequent detection of the hydrogen peroxide byproduct.
-
Colorimetric Assay: In the presence of horseradish peroxidase (HRP), the generated H₂O₂ reacts with a chromogenic probe to produce a colored product. The intensity of the color, which is directly proportional to the this compound concentration, is measured using a spectrophotometer at a specific wavelength (typically between 540-570 nm).[1]
-
Fluorometric Assay: Similarly, HRP catalyzes the reaction between H₂O₂ and a fluorogenic probe.[2] This reaction yields a highly fluorescent product. The fluorescence intensity is measured with a fluorescence microplate reader at specific excitation and emission wavelengths (e.g., Ex/Em = 538/587 nm), providing a quantifiable signal corresponding to the this compound concentration.[3]
Performance Characteristics: A Quantitative Comparison
The selection of an appropriate assay often hinges on key performance metrics such as sensitivity, dynamic range, and specificity. The following table summarizes these parameters for typical colorimetric and fluorometric this compound assays based on commercially available kit data.
| Feature | Colorimetric Assay | Fluorometric Assay |
| Detection Principle | Absorbance of colored product | Emission of fluorescent product |
| Detection Limit | ~1.56 µM[1] | < 5 µM[3] (some kits report ~1.56 µM[2]) |
| Dynamic Range | 1.56 µM - 100 µM | 1.56 µM - 100 µM |
| Equipment Required | Spectrophotometer / Microplate Reader | Fluorescence Microplate Reader |
| Specificity | High for L-lysine | High for L-lysine; not significantly affected by other physiological amino acids[3] |
| Common Interferences | NADH > 10 µM, Glutathione > 50 µM[1] | NADH > 10 µM, Glutathione > 50 µM[2] |
| Cost | Generally lower | Generally higher |
Experimental Workflows
The general workflows for both assays are similar, involving sample preparation, reaction setup, incubation, and signal detection. However, there are subtle differences in the reaction components and detection steps.
Caption: Workflow for a typical colorimetric this compound assay.
Caption: Workflow for a typical fluorometric this compound assay.
Detailed Experimental Protocols
Below are representative protocols for conducting colorimetric and fluorometric this compound assays. Note that specific details may vary between commercial kits, and it is essential to follow the manufacturer's instructions.
Colorimetric this compound Assay Protocol
1. Reagent Preparation:
-
1X Assay Buffer: Dilute the provided 10X Assay Buffer with deionized water.
-
This compound Standards: Prepare a standard curve by performing serial dilutions of the this compound standard (e.g., 10 mM stock) in 1X Assay Buffer to obtain concentrations from 1.56 µM to 100 µM.[1]
-
Reaction Mix: For each reaction, prepare a mix containing the colorimetric probe, HRP, and this compound oxidase in 1X Assay Buffer.[1]
-
Control Mix: Prepare a similar mix as the Reaction Mix but without the this compound oxidase to measure background absorbance in samples.[1]
2. Assay Procedure:
-
Add 50 µL of each this compound standard and unknown sample into separate wells of a 96-well microtiter plate. For each unknown sample, prepare two wells: one for the reaction and one for the background control.[1]
-
Add 50 µL of the Reaction Mix to the wells containing the standards and the "reaction" set of the unknown samples.[1]
-
Add 50 µL of the Control Mix to the "background control" set of the unknown samples.[1]
-
Mix the contents of the wells thoroughly and incubate for 10-30 minutes at room temperature, protected from light.[1]
-
Measure the absorbance of each well using a microplate reader at a wavelength between 540-570 nm.[1]
-
Subtract the absorbance of the blank (0 µM standard) from all standard and sample readings. For unknown samples, subtract the background control reading from the reaction reading.
-
Plot the corrected absorbance values for the standards against their concentrations to generate a standard curve.
-
Determine the this compound concentration in the unknown samples from the standard curve.
Fluorometric this compound Assay Protocol
1. Reagent Preparation:
-
This compound Assay Buffer: Prepare as per the kit instructions (e.g., ready to use or diluted).
-
This compound Standards: Reconstitute and serially dilute the L-lysine standard to prepare a standard curve and a spiking solution (e.g., 100 µM).
-
Reaction Mix: Prepare a reaction mix containing the fluorogenic probe, this compound enzyme mix, and developer solution according to the kit's protocol.[3]
-
Sample Background Mix: For samples requiring background correction, a separate mix without the enzyme may be needed.
2. Sample Preparation:
-
Biological Fluids (Serum, Plasma): Deproteinize samples using a 10 kDa spin column.[3]
-
Tissues or Cells: Homogenize in ice-cold this compound Assay Buffer, centrifuge to pellet debris, and collect the supernatant. Deproteinization is recommended.[3]
3. Assay Procedure:
-
Add 2-20 µL of your samples into designated wells of a black, flat-bottom 96-well plate. For accurate quantification, prepare three wells per sample: Sample Background Control (SBC), Sample (S), and Spiked Sample (SS).[3]
-
Add a known amount of this compound standard (e.g., 400 pmoles) to the "SS" wells.
-
Adjust the volume in all wells to 60 µL with this compound Assay Buffer.
-
Add 40 µL of the appropriate Reaction Mix to the "S" and "SS" wells. Add a background control mix (if applicable) to the "SBC" wells.
-
Incubate the plate for 45 minutes at 25°C, protected from light.[3]
-
Measure the fluorescence intensity of each well using a fluorescence microplate reader at Ex/Em = 538/587 nm.[3]
-
Subtract the SBC reading from the S and SS readings.
-
Calculate the this compound concentration in the samples based on the fluorescence of the unspiked and spiked samples.[3]
Conclusion: Which Assay is Right for You?
The choice between a colorimetric and a fluorometric assay for this compound quantification depends on the specific requirements of your research.
Choose a colorimetric assay if:
-
You are working with relatively high concentrations of this compound.
-
Cost-effectiveness and readily available equipment (spectrophotometer) are primary considerations.[4]
-
High sensitivity is not a critical requirement for your application.
Choose a fluorometric assay if:
-
You need to detect low concentrations of this compound in your samples.[4]
-
Your sample volume is limited, necessitating a more sensitive method.
-
You have access to a fluorescence microplate reader.
-
You require a wider dynamic range for your measurements.[5][6]
Both methods offer high specificity for L-lysine due to the enzymatic nature of the reaction. By carefully considering the factors outlined in this guide, researchers can confidently select the most appropriate assay to achieve accurate and reproducible quantification of this compound in their experimental samples.
References
A Researcher's Guide to Surface Charge Engineering: Lysine vs. Other Amino Acids
For researchers, scientists, and drug development professionals, optimizing protein characteristics such as solubility, stability, and bioactivity is a critical endeavor. Surface charge engineering, the targeted modification of ionizable residues on a protein's exterior, has emerged as a powerful strategy to achieve these goals. This guide provides an objective comparison of lysine with other key amino acids—arginine, aspartic acid, and glutamic acid—for this purpose, supported by experimental data and detailed methodologies.
Positively Charged Residues: The this compound vs. Arginine Dichotomy
At physiological pH, both this compound (Lys, K) and arginine (Arg, R) carry a positive charge and are predominantly found on the protein surface. While they share this fundamental property, their distinct side-chain structures lead to significant differences in their impact on protein behavior.
Impact on Protein Solubility
A substantial body of computational and experimental evidence indicates that a higher ratio of this compound to arginine (K/R ratio) is correlated with increased protein solubility.[1][2][3] this compound's simpler, more flexible side chain is less prone to forming the intricate intermolecular interactions that can lead to aggregation at high concentrations. This makes this compound a preferred choice when engineering proteins intended for high-concentration formulations, a common requirement in therapeutic applications.[1][2][3]
Impact on Protein Stability
Conversely, arginine often contributes more significantly to a protein's structural stability.[4][5] The guanidinium group of arginine's side chain is planar and can form a greater number of electrostatic interactions, including salt bridges and hydrogen bonds, compared to this compound's primary amine.[4][5][6][7][8] This enhanced network of interactions can increase a protein's resistance to chemical denaturants and extreme pH conditions.
However, it is crucial to note that substituting surface lysines with arginines can sometimes negatively affect protein folding and reduce the yield of the functional protein.[4][5][6]
Quantitative Comparison: this compound vs. Arginine in Green Fluorescent Protein (GFP)
A study by Sokalingam et al. (2012) provides a clear experimental comparison of the effects of mutating surface lysines to arginines on the stability of Green Fluorescent Protein (GFP). In this study, a GFP variant (GFP14R) was created where 14 surface-exposed lysines were replaced by arginines.
| Property | Control GFP (GFPcon) | GFP Variant (GFP14R) | Outcome of Lys to Arg Mutation |
| Chemical Stability (Urea Denaturation Midpoint) | ~3.5 M Urea | ~4.5 M Urea | Increased stability against chemical denaturation. |
| pH Stability (Relative fluorescence at pH 13) | Lower | Higher | Increased stability at alkaline pH.[4][5] |
| Thermal Stability (Melting Temperature, Tm) | No significant change | No significant change | Did not affect thermal stability in this case.[6][7][8] |
| Number of Salt Bridges | 11 | 16 | Increased number of stabilizing electrostatic interactions.[4] |
| Number of Hydrogen Bonds | Maintained 24 of original | Gained 15 new hydrogen bonds | Enhanced hydrogen bond network.[4] |
Negatively Charged Residues: Aspartic Acid vs. Glutamic Acid
Aspartic acid (Asp, D) and glutamic acid (Glu, E) are the primary choices for introducing negative charges on a protein surface. Both are potent stabilizing agents, largely due to their favorable interactions with water molecules, which can lead to a significant increase in a protein's thermal stability.
While structurally very similar (glutamic acid has one additional methylene group in its side chain), this small difference can influence local conformation. Some studies suggest that glutamates have a higher propensity to support helical structures, while aspartates may favor more extended conformations.
Quantitative Comparison: The Stabilizing Effect of Aspartate and Glutamate
Research on Ribonuclease A (RNase A) has demonstrated the profound stabilizing effect of potassium aspartate (KAsp) and potassium glutamate (KGlu).
| Condition | Melting Temperature (Td) of RNase A | Change in Td |
| Aqueous Buffer | 63.5 °C | - |
| 1 M Potassium Aspartate (KAsp) | 72.7 °C | +9.2 °C |
| 1 M Potassium Glutamate (KGlu) | 72.3 °C | +8.8 °C |
These results highlight that both aspartate and glutamate are highly effective at increasing protein thermostability.
Experimental Protocols
The following sections outline the general methodologies for the key experiments involved in surface charge engineering of proteins.
Site-Directed Mutagenesis
This is the foundational technique used to introduce specific amino acid changes into a protein's sequence.
Principle: A plasmid containing the gene of the target protein is used as a template. Primers containing the desired mutation are used to amplify the entire plasmid via PCR. The parental, methylated template DNA is then digested with the DpnI enzyme, leaving the newly synthesized, mutated plasmids. These are then transformed into competent E. coli for replication.
Generalized Protocol:
-
Primer Design: Design forward and reverse primers (~25-45 bases in length) that are complementary to the template plasmid, with the desired mutation incorporated in the middle. The melting temperature (Tm) should be ≥ 78°C.
-
PCR Amplification:
-
Combine the template DNA plasmid (~5-50 ng), forward and reverse primers (~125 ng each), dNTPs, reaction buffer, and a high-fidelity DNA polymerase (e.g., PfuUltra).
-
Perform PCR with an initial denaturation step, followed by 12-18 cycles of denaturation, annealing, and extension. The extension time depends on the plasmid size (typically ~2 minutes/kb).
-
-
DpnI Digestion: Add DpnI restriction enzyme directly to the amplification reaction and incubate at 37°C for 1 hour to digest the parental template DNA.
-
Transformation: Transform the DpnI-treated plasmid into high-efficiency competent E. coli cells.
-
Selection and Sequencing: Plate the transformed cells on a selective agar plate (e.g., containing an antibiotic). Isolate plasmid DNA from the resulting colonies and verify the desired mutation through DNA sequencing.
Protein Expression and Purification
Once the mutated plasmid is confirmed, the engineered protein needs to be produced and purified. This typically involves expressing the protein in a suitable host system (e.g., E. coli, yeast, mammalian cells) followed by purification using chromatography techniques (e.g., affinity, ion-exchange, size-exclusion).
Protein Solubility Assessment
Principle: The solubility of a protein can be quantified by determining the concentration at which it remains in solution under specific conditions. A common method involves using a precipitant to induce phase separation.
Generalized Protocol (PEG-Induced Precipitation):
-
Prepare a series of solutions with a constant protein concentration and varying concentrations of a precipitant like polyethylene glycol (PEG).
-
Incubate the samples to allow them to reach equilibrium.
-
Centrifuge the samples to pellet the precipitated protein.
-
Carefully remove the supernatant and measure the protein concentration (e.g., by measuring absorbance at 280 nm).
-
The solubility is determined from the protein concentration in the supernatant at different precipitant concentrations.
Protein Stability Analysis
Principle: The stability of a protein can be determined by monitoring its unfolding as a function of increasing concentrations of a chemical denaturant (e.g., urea or guanidinium chloride). The midpoint of the unfolding transition provides a measure of the protein's conformational stability.
Generalized Protocol (Urea Denaturation using Circular Dichroism):
-
Prepare a series of protein samples in a suitable buffer, each containing a different concentration of urea (e.g., 0 to 8 M).
-
Allow the samples to equilibrate.
-
Measure the circular dichroism (CD) signal at a wavelength sensitive to the protein's secondary structure (e.g., 222 nm for alpha-helical proteins).
-
Plot the CD signal as a function of urea concentration.
-
Fit the data to a two-state unfolding model to determine the midpoint of the transition (Cm) and the free energy of unfolding in the absence of denaturant (ΔG°H₂O).
Principle: This method measures the melting temperature (Tm) of a protein by monitoring the fluorescence of a dye that binds to hydrophobic regions exposed as the protein unfolds with increasing temperature.
Generalized Protocol:
-
Mix the purified protein with a fluorescent dye (e.g., SYPRO Orange) in a suitable buffer.
-
Place the mixture in a real-time PCR instrument.
-
Apply a thermal ramp, gradually increasing the temperature (e.g., from 25°C to 95°C).
-
Monitor the fluorescence intensity at each temperature increment.
-
The melting temperature (Tm) is the midpoint of the resulting sigmoidal curve of fluorescence versus temperature.
Visualizing Workflows and Concepts
Conclusion
The choice between this compound and other charged amino acids for surface charge engineering is context-dependent and should be guided by the desired outcome for the protein of interest.
-
For enhancing solubility, particularly for high-concentration applications, increasing the this compound content and the overall K/R ratio is a well-supported strategy.
-
To improve stability against chemical denaturants or alkaline pH, arginine is often the superior choice due to its ability to form a more extensive network of electrostatic interactions.
-
For a significant boost in thermal stability, the introduction of negatively charged residues, either aspartic or glutamic acid, is a highly effective approach.
By leveraging the distinct properties of these amino acids and employing rigorous experimental validation, researchers can effectively engineer proteins with tailored characteristics for a wide range of applications in research and drug development.
References
- 1. researchgate.net [researchgate.net]
- 2. A New Method for Estimating Protein Stability: the Work of Nick Pace - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Determining the conformational stability of a protein using urea denaturation curves - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. pubs.acs.org [pubs.acs.org]
- 5. Surface effects on aggregation kinetics of amyloidogenic peptides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. A study on the effect of surface this compound to arginine mutagenesis on protein stability and structure using green fluorescent protein - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. A Study on the Effect of Surface this compound to Arginine Mutagenesis on Protein Stability and Structure Using Green Fluorescent Protein - PMC [pmc.ncbi.nlm.nih.gov]
- 8. A Study on the Effect of Surface this compound to Arginine Mutagenesis on Protein Stability and Structure Using Green Fluorescent Protein | PLOS One [journals.plos.org]
A Researcher's Guide to Lysine Methylation: Comparing the Effects of Mono-, Di-, and Tri-methylation
For researchers, scientists, and drug development professionals, understanding the nuanced differences between mono-, di-, and tri-methylation of lysine residues is critical for deciphering complex cellular signaling pathways and developing targeted therapeutics. This guide provides an objective comparison of these three methylation states, supported by experimental data and detailed protocols.
This compound methylation, a key post-translational modification (PTM), involves the addition of one (mono-), two (di-), or three (tri-) methyl groups to the ε-amino group of a this compound residue. This seemingly subtle alteration has profound effects on protein function, stability, and interaction networks. The degree of methylation acts as a precise signaling switch, recognized by a host of specialized "reader" proteins that translate these marks into specific downstream biological outcomes. This dynamic process is tightly regulated by this compound methyltransferases (KMTs or "writers") and this compound demethylases (KDMs or "erasers").
Functional Distinctions: A Tale of Three Methyls
The functional consequences of this compound methylation are highly dependent on the specific this compound residue, the protein substrate, and, crucially, the degree of methylation. While mono-methylation is often associated with transcriptional activation, di- and tri-methylation are more commonly linked to transcriptional repression, though numerous exceptions exist.[1][2] These distinct roles are largely determined by the specific reader proteins that are recruited to each methylation state.
Key Biological Roles Associated with Different this compound Methylation States:
-
Mono-methylation (me1): Frequently observed on both histone and non-histone proteins, mono-methylation is often a mark of active chromatin and has been implicated in DNA repair processes. For instance, mono-methylation of H3K9 is linked to transcriptionally active euchromatin.[1]
-
Di-methylation (me2): This state can be either activating or repressive depending on the context. Di-methylation of H3K9 is a hallmark of facultative heterochromatin and is associated with gene silencing. Conversely, H3K36me2 is found in the body of actively transcribed genes.
-
Tri-methylation (me3): Often a more stable and definitive mark, tri-methylation is strongly associated with transcriptional repression, as exemplified by H3K9me3 and H3K27me3, which are hallmarks of constitutive heterochromatin. However, H3K4me3 is a well-established mark of active gene promoters.
Quantitative Comparison of Reader Domain Binding Affinities
The specific recognition of each methylation state is mediated by "reader" domains, which contain aromatic "cages" that accommodate the methylated this compound. The geometry and chemical environment of this cage determine the specificity for mono-, di-, or tri-methylated this compound. Isothermal Titration Calorimetry (ITC) is a powerful technique used to quantify these binding affinities, providing the dissociation constant (Kd). A lower Kd value indicates a stronger binding affinity.
| Reader Domain | Histone Peptide | Methylation State | Dissociation Constant (Kd) (μM) | Reference |
| HP1β Chromodomain | H3K9 | me1 | Weak/No Binding | [3] |
| me2 | Weak/No Binding | [3] | ||
| me3 | ~1.0 | [4] | ||
| L3MBTL1 (MBT repeats) | H4K20 | me1 | 1.8 | [5] |
| me2 | 2.1 | [5] | ||
| me3 | No Binding | [5] | ||
| BPTF PHD Finger | H3K4 | me2 | 5.0 | [6] |
| me3 | 2.7 | [6] | ||
| 53BP1 Tudor Domain | H4K20 | me2 | 18 | [7][8] |
| JMJD2A Tudor Domain | H3K4 | me3 | High Affinity | [9][10] |
| H4K20 | me3 | High Affinity | [9][10] |
Enzymatic Regulation: Writers and Erasers
The establishment and removal of this compound methylation marks are catalyzed by this compound methyltransferases (KMTs) and this compound demethylases (KDMs), respectively. These enzymes often exhibit specificity for the degree of methylation they catalyze or remove.
This compound Methyltransferases (KMTs)
KMTs transfer a methyl group from S-adenosylmethionine (SAM) to the this compound residue. They are broadly classified into SET domain-containing and non-SET domain-containing enzymes. Their activity can be processive (adding multiple methyl groups in a single binding event) or distributive (dissociating after each methyl addition). For example, SETD7 is a mono-methyltransferase, while SUV39H1 is a tri-methyltransferase.[11]
This compound Demethylases (KDMs)
KDMs remove methyl groups and are categorized into two main families: the flavin-dependent LSD family and the Fe(II) and α-ketoglutarate-dependent JmjC domain-containing family. LSD1 (KDM1A) can only demethylate mono- and di-methylated lysines, while many JmjC domain-containing enzymes can also remove tri-methylation.[12][13] For instance, UTX and JMJD3 are H3K27-specific demethylases that can remove tri-methyl marks.[14][15]
Signaling Pathways and Experimental Workflows
To illustrate the intricate regulatory networks governed by this compound methylation, we present diagrams of key signaling pathways and experimental workflows using the DOT language for Graphviz.
Caption: Overview of this compound Methylation Dynamics.
Caption: Chromatin Immunoprecipitation (ChIP) Workflow.
Experimental Protocols
Detailed methodologies for key experiments are provided below to facilitate the study of this compound methylation.
Protocol 1: Chromatin Immunoprecipitation (ChIP) for Histone Methylation
This protocol is a generalized procedure for the immunoprecipitation of chromatin to analyze histone methylation at specific genomic loci.
Materials:
-
Formaldehyde (16% solution)
-
Glycine
-
Cell lysis buffer
-
Nuclei lysis buffer
-
ChIP dilution buffer
-
Antibody specific to the histone methylation mark of interest (e.g., anti-H3K9me3)
-
Protein A/G magnetic beads
-
Wash buffers (low salt, high salt, LiCl)
-
Elution buffer
-
Proteinase K
-
Phenol:chloroform:isoamyl alcohol
-
Ethanol
Procedure:
-
Cross-linking: Treat cells with 1% formaldehyde for 10 minutes at room temperature to cross-link proteins to DNA. Quench the reaction with glycine.
-
Cell Lysis: Harvest and lyse the cells to release the nuclei.
-
Chromatin Shearing: Resuspend the nuclear pellet in nuclei lysis buffer and shear the chromatin to fragments of 200-1000 bp using sonication or enzymatic digestion (e.g., MNase).
-
Immunoprecipitation: Dilute the sheared chromatin and pre-clear with protein A/G beads. Incubate overnight at 4°C with an antibody specific to the methylation state of interest.
-
Immune Complex Capture: Add protein A/G beads to capture the antibody-chromatin complexes.
-
Washing: Wash the beads sequentially with low salt, high salt, and LiCl wash buffers to remove non-specific binding.
-
Elution: Elute the chromatin from the beads.
-
Reverse Cross-linking: Reverse the formaldehyde cross-links by incubating at 65°C overnight with the addition of NaCl.
-
DNA Purification: Treat with RNase A and Proteinase K, then purify the DNA using phenol:chloroform extraction and ethanol precipitation or a commercial kit.
-
Analysis: Analyze the purified DNA by qPCR for specific gene targets or by high-throughput sequencing (ChIP-seq) for genome-wide analysis.
Protocol 2: In Vitro Histone Methyltransferase (HMT) Assay using Radiolabeled SAM
This assay measures the activity of a specific KMT on a histone substrate.[16]
Materials:
-
Purified recombinant KMT
-
Histone substrate (e.g., recombinant histone H3 or peptide)
-
S-adenosyl-L-[methyl-³H]methionine ([³H]SAM)
-
HMT reaction buffer (e.g., 50 mM Tris-HCl pH 8.5, 5 mM MgCl₂, 4 mM DTT)
-
P81 phosphocellulose paper
-
Scintillation fluid and counter
Procedure:
-
Reaction Setup: In a microcentrifuge tube, combine the HMT reaction buffer, histone substrate, and purified KMT.
-
Initiate Reaction: Start the reaction by adding [³H]SAM.
-
Incubation: Incubate the reaction at the optimal temperature for the KMT (typically 30-37°C) for a defined period (e.g., 30-60 minutes).
-
Stop Reaction: Spot a portion of the reaction mixture onto a P81 phosphocellulose paper to stop the reaction.
-
Washing: Wash the P81 paper multiple times with a wash buffer (e.g., 50 mM NaHCO₃, pH 9.0) to remove unincorporated [³H]SAM.
-
Quantification: Place the dried P81 paper in a scintillation vial with scintillation fluid and measure the incorporated radioactivity using a scintillation counter. The counts are proportional to the KMT activity.
Protocol 3: AlphaLISA Demethylase Assay
This is a high-throughput, no-wash immunoassay to measure the activity of KDMs.[17][18][19]
Materials:
-
Purified recombinant KDM
-
Biotinylated methylated histone peptide substrate
-
KDM reaction buffer
-
AlphaLISA Acceptor beads conjugated to an antibody that recognizes the demethylated product
-
Streptavidin-coated Donor beads
-
AlphaLISA assay buffer
-
Microplate reader capable of AlphaLISA detection
Procedure:
-
Enzymatic Reaction: In a 384-well microplate, incubate the KDM with the biotinylated methylated histone peptide substrate in the KDM reaction buffer.
-
Stop Reaction and Detection: Stop the reaction by adding AlphaLISA Acceptor beads. The beads will bind to the demethylated peptide product.
-
Bead Association: Add Streptavidin-coated Donor beads, which will bind to the biotinylated end of the peptide substrate.
-
Signal Generation: If the substrate has been demethylated, the Acceptor and Donor beads are brought into close proximity. Upon excitation at 680 nm, the Donor beads release singlet oxygen, which travels to the nearby Acceptor beads, triggering a chemiluminescent signal at 615 nm.
-
Measurement: Read the plate on an AlphaLISA-compatible microplate reader. The signal intensity is directly proportional to the amount of demethylated product and thus to the KDM activity.
Conclusion
The differential effects of mono-, di-, and tri-methylation on this compound residues represent a sophisticated layer of cellular regulation. By employing the quantitative techniques and detailed protocols outlined in this guide, researchers can more effectively dissect the complexities of this compound methylation signaling, paving the way for new discoveries in basic science and the development of novel therapeutic strategies.
References
- 1. Di- and Tri- but Not Monomethylation on Histone H3 this compound 36 Marks Active Transcription of Genes Involved in Flowering Time Regulation and Other Processes in Arabidopsis thaliana - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Distinct transcriptional outputs associated with mono- and di-methylated histone H3 arginine 2 - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Methylation of this compound 9 in Histone H3 Directs Alternative Modes of Highly Dynamic Interaction of Heterochromatin Protein hHP1β with the Nucleosome - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Dynamic and flexible H3K9me3 bridging via HP1β dimerization establishes a plastic state of condensed chromatin - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Structural Basis for Lower this compound Methylation State-Specific Readout by MBT Repeats of L3MBTL1 and an Engineered PHD Finger - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Chemical and Biochemical Perspectives of Protein this compound Methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Quantitative Assessment of Protein Interaction with Methyl-Lysine Analogues by Hybrid Computational and Experimental Approaches - PMC [pmc.ncbi.nlm.nih.gov]
- 8. pubs.acs.org [pubs.acs.org]
- 9. Tudor, MBT and chromo domains gauge the degree of this compound methylation - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Tudor: a versatile family of histone methylation ‘readers’ - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Histone this compound Methylation Dynamics: Establishment, Regulation, and Biological Impact - PMC [pmc.ncbi.nlm.nih.gov]
- 12. GR and LSD1/KDM1A-Targeted Gene Activation Requires Selective H3K4me2 Demethylation at Enhancers - PMC [pmc.ncbi.nlm.nih.gov]
- 13. LSD1-Mediated Demethylation of H3K4me2 Is Required for the Transition from Late Progenitor to Differentiated Mouse Rod Photoreceptor - PMC [pmc.ncbi.nlm.nih.gov]
- 14. pnas.org [pnas.org]
- 15. ovid.com [ovid.com]
- 16. In Vitro Histone Methyltransferase Assay - PMC [pmc.ncbi.nlm.nih.gov]
- 17. resources.revvity.com [resources.revvity.com]
- 18. Development of AlphaLISA high throughput technique to screen for small molecule inhibitors targeting protein arginine methyltransferases - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Development of an AlphaLisa assay for Screening Histone Methyltransferase Inhibitors (NB-SC107) – NOVATEIN BIOSCIENCES [swzbio.com]
Validation of lysine succinylation as a novel post-translational modification
A Comparative Guide for Researchers
The discovery of lysine succinylation has expanded the landscape of post-translational modifications (PTMs), revealing a crucial link between cellular metabolism and protein function. This guide provides a comprehensive comparison of this compound succinylation with other well-known PTMs and details the experimental methodologies used for its validation, supported by key experimental data.
This compound, a frequently modified amino acid residue, can undergo various PTMs, including methylation, acetylation, and ubiquitination.[1] The addition of a succinyl group to a this compound residue, termed succinylation, is a naturally occurring PTM that has a significant impact on protein structure and function due to the transfer of a relatively large and negatively charged moiety.[2][3] This modification is evolutionarily conserved and has been identified in a wide range of organisms, from bacteria to humans.[4][5]
Comparison of this compound Succinylation with Other PTMs
This compound succinylation introduces unique biochemical changes to proteins compared to other common this compound modifications. The addition of a succinyl group results in a mass shift of +100.0186 Da and changes the charge of the this compound residue from +1 to -1 at physiological pH.[6][7] This alteration is more substantial than that caused by acetylation (+42.0106 Da, charge change from +1 to 0) or methylation (+14.0157 Da for monomethylation, no charge change).[8][9]
| Feature | This compound Succinylation | This compound Acetylation | This compound Methylation |
| Mass Shift (Da) | +100.0186[6] | +42.0106[9] | +14.0157 (mono), +28.0313 (di), +42.0470 (tri) |
| Charge Change | From +1 to -1[3] | From +1 to 0 | No change |
| Size of Added Group | Large[3] | Small | Smallest |
| Donor Molecule | Succinyl-CoA[10] | Acetyl-CoA | S-adenosylmethionine (SAM)[11] |
| Key Regulatory Enzymes | SIRT5 (de-succinylase), KAT2A (succinyltransferase)[2][3] | Histone Acetyltransferases (HATs), Histone Deacetylases (HDACs) | Histone Methyltransferases (HMTs), Histone Demethylases (HDMs) |
Experimental Validation of this compound Succinylation
The validation of this compound succinylation as a genuine PTM relies on a combination of rigorous experimental approaches.
Workflow for Validation of this compound Succinylation
Caption: A typical workflow for the validation of this compound succinylation.
Mass Spectrometry
The initial identification of this compound succinylation was achieved through mass spectrometry.[1][4] High-resolution MS analysis of tryptic digests of proteins reveals a mass shift of 100.0186 Da on this compound residues, corresponding to the addition of a succinyl group.[6] Tandem mass spectrometry (MS/MS) is then used to pinpoint the exact site of modification.[9]
Experimental Protocol: Nano-HPLC-MS/MS Analysis [9]
-
Protein Digestion: Proteins are digested with trypsin.
-
Peptide Enrichment (Optional): Succinylated peptides can be enriched using anti-succinyl-lysine antibodies.[6]
-
Chromatography: The peptide mixture is separated using nano-high-performance liquid chromatography (nano-HPLC).
-
Mass Spectrometry:
-
Data Analysis: The MS/MS data is analyzed using software that can identify PTMs based on mass shifts.
HPLC Co-elution with Synthetic Peptides
To confirm the identity of the modification, the in vivo-derived succinylated peptide is compared with a synthetically generated peptide of the same sequence.[9] The gold standard for confirmation is the co-elution of the in vivo and synthetic peptides in a single peak during HPLC analysis.[4][9] This method also helps to distinguish succinylation from its isomer, methylmalonylation, as the two modified peptides will have different retention times.[9]
Experimental Protocol: HPLC Co-elution [9]
-
Synthesize Peptides: Synthesize a succinylthis compound peptide and, if necessary, a methylmalonylthis compound peptide with the same sequence as the in vivo identified peptide.
-
HPLC Analysis:
-
Analyze the in vivo-derived peptide digest by nano-HPLC-MS/MS.
-
Analyze the synthetic succinylthis compound peptide.
-
Analyze a mixture of the in vivo digest and the synthetic succinylthis compound peptide.
-
Analyze the synthetic methylmalonylthis compound peptide.
-
-
Compare Chromatograms: The in vivo and synthetic succinylthis compound peptides, and their mixture, should show a single, co-eluting peak with the same retention time. The methylmalonylthis compound peptide should have a different retention time.[9]
Western Blot Analysis with Pan-Anti-Succinyl-Lysine Antibodies
The development of pan-specific antibodies that recognize succinylthis compound residues has been instrumental in validating this PTM.[4][9] Western blotting with these antibodies can detect succinylated proteins in cell lysates and purified protein samples.[4][9] The specificity of the antibody is confirmed through competition assays using a peptide library containing a fixed succinylthis compound.[4][9]
Experimental Protocol: Western Blot Analysis [4][9]
-
Protein Extraction: Extract total protein from cells or tissues.
-
SDS-PAGE and Transfer: Separate proteins by SDS-PAGE and transfer them to a nitrocellulose or PVDF membrane.
-
Blocking: Block the membrane with a suitable blocking buffer (e.g., 3% nonfat dry milk in TBST).
-
Primary Antibody Incubation: Incubate the membrane with a pan-anti-succinyl-lysine antibody.
-
Secondary Antibody Incubation: Incubate with an HRP-conjugated secondary antibody.
-
Detection: Detect the signal using an enhanced chemiluminescence (ECL) kit.
-
Competition Assay (for specificity): Pre-incubate the primary antibody with a peptide library containing succinylthis compound to show that the signal can be competed away.[4]
Signaling Pathway Implication
Caption: Regulation and functional consequences of this compound succinylation.
Functional Consequences of this compound Succinylation
The addition of a bulky, negatively charged succinyl group can significantly alter a protein's structure and function.[3] This modification has been shown to regulate enzyme activity, protein stability, and protein-protein interactions.[2][12] For instance, succinylation of enzymes involved in metabolic pathways like the TCA cycle and fatty acid metabolism can modulate their activity.[2][13] Site-directed mutagenesis, where the succinylated this compound is replaced with an arginine (to maintain positive charge) or a glutamate (to mimic the negative charge of succinylation), is a common technique to study the functional impact of this PTM.[9]
References
- 1. experts.umn.edu [experts.umn.edu]
- 2. This compound succinylation, the metabolic bridge between cancer and immunity - PMC [pmc.ncbi.nlm.nih.gov]
- 3. scienceopen.com [scienceopen.com]
- 4. scispace.com [scispace.com]
- 5. na01.alma.exlibrisgroup.com [na01.alma.exlibrisgroup.com]
- 6. Comprehensive Analysis of the this compound Succinylome and Protein Co-modifications in Developing Rice Seeds - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Protein post-translational modification by this compound succinylation: Biochemistry, biological implications, and therapeutic opportunities - PMC [pmc.ncbi.nlm.nih.gov]
- 8. The dawn of succinylation: a posttranslational modification - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Identification of this compound succinylation as a new post-translational modification - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Identification of this compound succinylation as a new post-translational modification - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. Frontiers | The metabolic-epigenetic interface: this compound succinylation orchestrates bidirectional crosstalk in neurodegenerative disorders [frontiersin.org]
- 12. Protein Succinylation: A Key Post-Translational Modification - MetwareBio [metwarebio.com]
- 13. Frontiers | Protein succinylation: regulating metabolism and beyond [frontiersin.org]
A Head-to-Head Comparison of Lysine Deacetylase Inhibitors: Vorinostat, Romidepsin, and Entinostat
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive, data-driven comparison of three prominent lysine deacetylase (KDAC) inhibitors: the pan-inhibitor Vorinostat and the class I-selective inhibitors Romidepsin and Entinostat. By examining their selectivity, preclinical efficacy, clinical outcomes, and underlying mechanisms of action, this document aims to serve as a critical resource for informed decision-making in research and drug development.
Introduction to this compound Deacetylase Inhibitors
This compound deacetylases (KDACs), also known as histone deacetylases (HDACs), are a class of enzymes that play a pivotal role in the epigenetic regulation of gene expression. They remove acetyl groups from this compound residues on both histone and non-histone proteins, leading to a more condensed chromatin structure and transcriptional repression.[1] In various cancers, the aberrant activity of KDACs contributes to the silencing of tumor suppressor genes, promoting cancer cell proliferation and survival.[1] KDAC inhibitors counteract this process, inducing hyperacetylation, which relaxes the chromatin structure and reactivates the expression of silenced genes.[1] This can lead to cell cycle arrest, differentiation, and apoptosis in cancer cells.[1]
The first generation of these drugs, known as pan-KDAC inhibitors, target multiple KDAC isoforms simultaneously. While several have been approved for treating hematological malignancies, their broad activity can lead to significant off-target effects.[1] This has prompted the development of class-selective inhibitors, which offer a more targeted therapeutic approach with a potentially improved safety profile.[1]
Comparative Analysis of Inhibitor Selectivity and Potency
The selectivity and potency of KDAC inhibitors are critical determinants of their therapeutic efficacy and toxicity profiles. Vorinostat is a pan-HDAC inhibitor, demonstrating activity against multiple KDAC isoforms in both Class I and II.[2] In contrast, Romidepsin and Entinostat exhibit greater selectivity for Class I KDACs.[3][4] The half-maximal inhibitory concentration (IC50) values presented in the table below, compiled from various preclinical studies, illustrate these distinct selectivity profiles.
| Inhibitor | Type | HDAC1 (nM) | HDAC2 (nM) | HDAC3 (nM) | HDAC4 (nM) | HDAC6 (nM) | HDAC8 (nM) |
| Vorinostat | Pan-Inhibitor | ~10 | ~20 | ~10 | - | ~50 | ~410 |
| Romidepsin | Class I-Selective | ~3.6 | ~4.7 | - | ~510 | ~14,000 | - |
| Entinostat | Class I-Selective | ~130 | ~160 | ~200 | >10,000 | >10,000 | - |
Note: IC50 values can vary depending on the specific assay conditions and are presented here for comparative purposes.[5]
Preclinical Efficacy: A Head-to-Head Look
Preclinical studies in various cancer cell lines highlight the differential effects of these inhibitors on cell viability and apoptosis.
In Vitro Cytotoxicity
The cytotoxic effects of Vorinostat, Romidepsin, and Entinostat have been evaluated in numerous cancer cell lines. The half-maximal inhibitory concentration (IC50) for growth inhibition varies depending on the cell line and the inhibitor's selectivity. For example, in the Sezary syndrome-derived HUT78 cell line, Romidepsin was found to be significantly more potent than Vorinostat, with IC50 values for growth inhibition of 1.22 ± 0.24 nM and 675 ± 214 nM, respectively.[3]
| Inhibitor | Cancer Type | Cell Line | IC50 (Growth Inhibition) |
| Vorinostat | Cutaneous T-Cell Lymphoma | HUT78 | 675 ± 214 nM[3] |
| Romidepsin | Cutaneous T-Cell Lymphoma | HUT78 | 1.22 ± 0.24 nM[3] |
| Entinostat | Acute Lymphocytic Leukemia | Jurkat | Varies with combination |
Induction of Apoptosis
Both pan- and class I-selective KDAC inhibitors induce apoptosis in cancer cells. In acute lymphocytic leukemia (ALL) cell lines, both Entinostat and Vorinostat, when combined with adaphostin, synergistically induce apoptotic DNA fragmentation.[6] This is preceded by an increase in superoxide levels, a reduction in mitochondrial membrane potential, and activation of caspase-9.[6] Studies have also found Romidepsin to be a more effective inducer of apoptosis than Vorinostat in certain contexts.[7]
Clinical Trial Outcomes: A Comparative Overview
Clinical trials have demonstrated the efficacy of these KDAC inhibitors, particularly in hematological malignancies. However, direct head-to-head comparative trials are limited.
| Inhibitor | Cancer Type | Key Clinical Trial Findings |
| Vorinostat | Cutaneous T-Cell Lymphoma (CTCL) | Overall response rates of 24%-30% in refractory advanced patients.[7] Approved by the FDA for the treatment of CTCL in patients with progressive, persistent, or recurrent disease on or following two systemic therapies.[2] |
| Romidepsin | Cutaneous T-Cell Lymphoma (CTCL) & Peripheral T-Cell Lymphoma (PTCL) | Overall response rates of 34%-35% in CTCL.[7] Approved by the FDA for the treatment of CTCL in patients who have received at least one prior systemic therapy and for the treatment of PTCL.[2][8] |
| Entinostat | Various Cancers | In clinical development for various cancers, often in combination with other therapies. Has shown promise in breast cancer and lung cancer.[4] |
Differential Effects on Gene Expression and Signaling Pathways
The distinct selectivity profiles of pan- and class I-selective KDAC inhibitors lead to differential effects on gene expression and cellular signaling pathways.
Gene Expression
While there is an overlap in the genes regulated by different KDAC inhibitors, significant differences exist.[9] For instance, a study comparing Vorinostat and Panobinostat (another pan-HDAC inhibitor) in gastric cancer cells showed that while both drugs altered the expression of numerous genes, Panobinostat led to a notable upregulation of most class II and IV HDAC genes, a phenomenon not observed with Vorinostat.[10] Class I-selective inhibitors, by virtue of their targeted action, are thought to modulate a more specific set of genes, which may contribute to their different therapeutic and toxicity profiles.[11]
Signaling Pathways
KDAC inhibitors exert their anti-cancer effects by modulating various signaling pathways that control cell survival, proliferation, and apoptosis.[10]
-
PI3K/Akt Pathway: Both Entinostat and Vorinostat can modulate the PI3K/Akt pathway. For example, Entinostat in combination with lapatinib in HER2-overexpressing breast cancer cells leads to the downregulation of phosphorylated Akt.[6]
-
MAPK Pathway: Vorinostat has been shown to modify the signaling of the MAPK pathway in cutaneous T-cell lymphoma cells.[6]
-
NF-κB Pathway: Pan-HDAC inhibitors like Vorinostat can inhibit the NF-κB pathway, a key regulator of HIV transcription. This is a distinguishing feature from class I-selective inhibitors.[12]
The following diagrams, generated using the DOT language, illustrate a general mechanism of KDAC inhibition and a simplified representation of key signaling pathways affected.
Experimental Protocols
Detailed methodologies are crucial for the reproducibility of experimental findings. Below are summaries of key experimental protocols used to evaluate KDAC inhibitors.
KDAC Activity Assay (Fluorometric)
This assay quantifies the inhibitory activity of a compound against a specific KDAC isoform.
-
Compound Preparation: Serially dilute the test compound in assay buffer.
-
Enzyme and Substrate Preparation: Prepare a solution of recombinant human KDAC enzyme and a separate solution of a fluorogenic KDAC substrate.
-
Reaction Initiation: In a 96-well plate, combine the enzyme, substrate, and varying concentrations of the inhibitor.
-
Incubation: Incubate the plate at 37°C for a specified period.
-
Development: Add a developer solution to stop the reaction and generate a fluorescent signal from the deacetylated substrate.
-
Measurement: Read the fluorescence intensity using a microplate reader. The IC50 value is calculated from the dose-response curve.
Cell Viability (MTT) Assay
This colorimetric assay assesses the effect of a compound on cell metabolic activity, which is an indicator of cell viability.
-
Cell Seeding: Seed cancer cells in a 96-well plate and allow them to adhere overnight.
-
Compound Treatment: Treat the cells with various concentrations of the KDAC inhibitor for a specified duration (e.g., 48-72 hours).
-
MTT Addition: Add MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) solution to each well and incubate for 3-4 hours. Viable cells with active mitochondria will reduce MTT to purple formazan crystals.
-
Solubilization: Remove the medium and add a solubilizing agent (e.g., DMSO) to dissolve the formazan crystals.
-
Measurement: Measure the absorbance at a specific wavelength (e.g., 570 nm) using a microplate reader. The percentage of cell viability is calculated relative to untreated control cells.
Western Blot for Histone Acetylation
This technique is used to detect changes in the acetylation status of histone proteins following treatment with KDAC inhibitors.
-
Cell Treatment and Lysis: Treat cells with the KDAC inhibitor, then harvest and lyse the cells to extract proteins.
-
Protein Quantification: Determine the protein concentration of each lysate using a protein assay (e.g., BCA assay).
-
SDS-PAGE: Separate the protein lysates by size using sodium dodecyl sulfate-polyacrylamide gel electrophoresis (SDS-PAGE).
-
Protein Transfer: Transfer the separated proteins from the gel to a membrane (e.g., PVDF or nitrocellulose).
-
Blocking: Block the membrane with a blocking buffer (e.g., 5% non-fat milk or BSA) to prevent non-specific antibody binding.
-
Primary Antibody Incubation: Incubate the membrane with a primary antibody specific for an acetylated histone (e.g., anti-acetyl-Histone H3) and a loading control (e.g., anti-β-actin or anti-GAPDH).
-
Secondary Antibody Incubation: Wash the membrane and incubate with a secondary antibody conjugated to an enzyme (e.g., HRP).
-
Detection: Add a chemiluminescent substrate and visualize the protein bands using an imaging system. The intensity of the acetylated histone band is normalized to the loading control to quantify changes in acetylation.
Conclusion
The choice between a pan-KDAC inhibitor like Vorinostat and a class I-selective inhibitor such as Romidepsin or Entinostat is highly dependent on the specific therapeutic context. Pan-inhibitors offer broad epigenetic modulation, which can be advantageous in cancers with dysregulation of multiple KDACs. However, this broad activity comes with a higher risk of off-target effects. Class I-selective inhibitors provide a more targeted approach, potentially leading to an improved safety profile and allowing for the dissection of the specific roles of Class I KDACs in disease pathogenesis. Further head-to-head clinical trials are needed to fully elucidate the comparative efficacy and safety of these agents across a wider range of malignancies. This guide provides a foundational framework for researchers to navigate the complexities of KDAC inhibitor selection and development.
References
- 1. benchchem.com [benchchem.com]
- 2. uspharmacist.com [uspharmacist.com]
- 3. The histone deacetylase inhibitors vorinostat and romidepsin downmodulate IL-10 expression in cutaneous T-cell lymphoma cells - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Frontiers | Inhibition of histone deacetylases attenuates tumor progression and improves immunotherapy in breast cancer [frontiersin.org]
- 5. benchchem.com [benchchem.com]
- 6. benchchem.com [benchchem.com]
- 7. rjptonline.org [rjptonline.org]
- 8. Histone deacetylase inhibitors: emerging mechanisms of resistance - PMC [pmc.ncbi.nlm.nih.gov]
- 9. benchchem.com [benchchem.com]
- 10. benchchem.com [benchchem.com]
- 11. A toolbox for class I HDACs reveals isoform specific roles in gene regulation and protein acetylation | PLOS Genetics [journals.plos.org]
- 12. Isoform-Selective Versus Nonselective Histone Deacetylase Inhibitors in HIV Latency Reversal - PMC [pmc.ncbi.nlm.nih.gov]
A Researcher's Guide to Assessing the Specificity of Lysine-Targeting Chemical Probes
For Researchers, Scientists, and Drug Development Professionals
The development of chemical probes that covalently target lysine residues has opened new avenues for interrogating protein function and discovering novel therapeutics. Unlike cysteine, which is less abundant, this compound is frequently found in functional binding sites, making it an attractive target. However, the inherent reactivity of this compound-targeting electrophiles necessitates a rigorous assessment of their specificity to ensure that observed biological effects are truly due to the modulation of the intended target. This guide provides a comparative overview of common this compound-targeting chemotypes, details key experimental protocols for specificity assessment, and presents workflows to guide your research.
Data Presentation: Comparing this compound-Targeting Electrophiles
The choice of the electrophilic "warhead" is critical in determining the specificity of a this compound-targeting probe. Different electrophiles exhibit distinct intrinsic reactivities and preferences for other nucleophilic amino acids. The following tables summarize quantitative data from large-scale chemoproteomic studies, comparing the proteome-wide reactivity and ligandability of common this compound-targeting electrophiles.
Table 1: Proteome-Wide Amino Acid Selectivity of Common Electrophiles
This table provides a direct comparison of the amino acid residues targeted by various electrophilic probes in proteomic experiments. Data is compiled from studies that analyzed probe reactivity across the entire proteome.[1][2][3] This information is crucial for anticipating potential off-target liabilities.
| Electrophile Class | Primary Target | Common Off-Targets | Notes |
| Sulfonyl Fluoride (SF) | Lys, Tyr | Ser, His, Cys, Thr | Privileged warhead with broad reactivity; context-dependent selectivity.[4][5] |
| N-Hydroxysuccinimide (NHS) Ester | Lys | Ser, Thr, Tyr, Cys | Highly reactive, often used for broad this compound profiling but can have significant off-targets.[6][7] |
| Acrylamide | Cys | Lys (less reactive) | Primarily a cysteine-targeting warhead, but can react with hyper-reactive lysines.[8] |
| Dicarboxaldehyde | Lys | - | Serve as effective "scout" fragments for broadly mapping ligandable lysines.[6] |
| Salicylaldehyde | Lys | - | Forms a reversible iminoboronate conjugate, offering a different kinetic profile.[9][10] |
Table 2: Comparison of Covalent Inhibitor Kinetic Parameters
The efficiency and specificity of a covalent probe are best described by the kinetic parameter kinact/KI. A higher kinact/KI value indicates more efficient inactivation of the target protein. This table presents illustrative data from studies optimizing this compound-targeting covalent inhibitors for Heat Shock Protein 72 (HSP72).[8]
| Inhibitor Warhead | Target Protein | Reversible Affinity (Ki, µM) | Inactivation Rate (kinact, min-1) | Covalent Efficiency (kinact/KI, M-1s-1) |
| Acrylamide | HSP72-NBD | 1.8 | 0.005 | 46 |
| Aryl-Sulfonyl Fluoride (Aryl-SF) | HSP72-NBD | 1.0 | 0.115 | 1917 |
| Activated Phenolic Ester | HSP72-NBD | 1.1 | <0.001 | Inactive |
Data is illustrative and serves to compare the relative efficiency of different warheads against the same target. NBD = Nucleotide-Binding Domain.
Visualizing the Assessment of Probe Specificity
Understanding the workflows for specificity assessment is key to designing robust experiments. The following diagrams, generated using Graphviz, illustrate the overarching strategy and the mechanisms of two critical experimental techniques.
References
- 1. chemrxiv.org [chemrxiv.org]
- 2. escholarship.org [escholarship.org]
- 3. chemrxiv.org [chemrxiv.org]
- 4. Advances in sulfonyl exchange chemical biology: expanding druggable target space - Chemical Science (RSC Publishing) DOI:10.1039/D5SC02647D [pubs.rsc.org]
- 5. Sulfonyl fluorides as privileged warheads in chemical biology - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Reactive chemistry for covalent probe and therapeutic development - PMC [pmc.ncbi.nlm.nih.gov]
- 7. researchgate.net [researchgate.net]
- 8. Kinetic Optimization of this compound-Targeting Covalent Inhibitors of HSP72 - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Development of this compound-reactive covalent inhibitors and chemoproteomic probes [escholarship.org]
- 10. pubs.acs.org [pubs.acs.org]
Navigating the Acetylome: A Comparative Guide to Lysine Acetylation Across Diverse Cell Types
For researchers, scientists, and drug development professionals, understanding the nuances of post-translational modifications (PTMs) is paramount. Among these, lysine acetylation, a reversible modification, has emerged as a critical regulator of protein function, impacting everything from gene expression to metabolic pathways.[1][2] This guide provides a comparative overview of the this compound acetylome across different cell types, supported by quantitative proteomic data and detailed experimental protocols.
This compound acetylation is a dynamic process governed by the interplay of this compound acetyltransferases (KATs) and this compound deacetylases (KDACs).[1] Its study on a proteome-wide scale, known as acetylomics, has been revolutionized by high-resolution mass spectrometry, enabling the identification and quantification of thousands of acetylated sites.[3][4] These comprehensive analyses reveal that the acetylome is not static but varies significantly across different cell types and in response to cellular stimuli, highlighting its role in cellular identity and function.
Quantitative Comparison of this compound Acetylomes
The extent of this compound acetylation can differ substantially between cell types, reflecting their unique biological functions and metabolic states. The following tables summarize quantitative data from proteomic studies, showcasing the number of identified acetylated this compound (Kac) sites and proteins in various cellular contexts. These studies typically employ techniques like Stable Isotope Labeling by Amino acids in Cell culture (SILAC), isobaric tags for relative and absolute quantitation (iTRAQ), or tandem mass tags (TMT) for accurate comparison.[5][6]
| Cell Type/Tissue | Number of Identified Kac Proteins | Number of Identified Kac Sites | Key Findings & Regulators | Reference |
| Human Jurkat T-cells | > 3,000 | > 10,000 | Deep coverage of the acetylome was achieved, with quantification of changes upon treatment with a histone deacetylase inhibitor (HDACi).[5] | [5] |
| Human Cervical (SiHa), Lung (A549), and Colon (CaCo-2) Cancer Cell Lines | > 1,300 per cell line | Not explicitly stated | Higher abundance of SIRT1 deacetylase correlated with lower overall acetylation. SIRT1 inhibition affected ribosomal protein levels and metabolic pathways.[7] | [7] |
| Mouse Liver Mitochondria | 136 (SIRT3-regulated) | 283 (SIRT3-regulated) | SIRT3 was identified as a global regulator of mitochondrial protein acetylation, impacting fatty acid oxidation, the urea cycle, and the TCA cycle.[8] | [8] |
| Naive vs. T Follicular Helper (Tfh) CD4+ T Cells | 187 (total identified) | 281 (total identified) | 22 acetylated proteins were upregulated and 26 were downregulated in Tfh cells, indicating a role for acetylation in T cell differentiation.[9] | [9] |
| Arabidopsis thaliana (various organs) | 2,887 | 5,929 | This compound acetylation targets core metabolic pathways and stress response proteins, with some organ-specific patterns observed.[3] | [3] |
| Bacillus subtilis | 3,159 | 4,893 | Extensive acetylation was observed, covering 75% of the theoretical proteome and suggesting broad regulatory roles in this bacterium.[10][11] | [10] |
Experimental Protocols: A Closer Look
The foundation of comparative acetylomics lies in robust and reproducible experimental workflows. Below are detailed methodologies for the key steps involved in a typical quantitative acetylome study.
Cell Culture, Lysis, and Protein Digestion
-
Cell Culture and Treatment: Cells of interest are cultured under standard or specific experimental conditions (e.g., with or without a drug treatment). For quantitative proteomics using SILAC, cells are grown in media containing "heavy" or "light" isotopic forms of arginine and this compound.
-
Cell Lysis: Cells are harvested and lysed in a buffer containing urea to denature proteins and inhibitors of proteases and deacetylases (e.g., trichostatin A and nicotinamide) to preserve the acetylation state.[12]
-
Protein Digestion: The protein concentration is determined, and proteins are reduced with dithiothreitol (DTT) and alkylated with iodoacetamide (IAA). Proteins are then digested into peptides, typically using an enzyme like trypsin.[13]
Acetylated Peptide Enrichment
Due to the low stoichiometry of most this compound acetylation events, enrichment of acetylated peptides is a critical step.[7][14]
-
Antibody-Based Immunoaffinity Purification: This is the most common method for enriching acetylated peptides.[15][16]
Mass Spectrometry and Data Analysis
-
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS): The enriched peptides are separated by reverse-phase liquid chromatography and analyzed by a high-resolution mass spectrometer.[7] The mass spectrometer fragments the peptides and measures the mass-to-charge ratio of the fragments to determine the peptide sequence and the location of the acetylation.
-
Data Analysis: The resulting MS data is processed using software like MaxQuant.[12] This involves peptide identification, protein inference, and quantification of the relative abundance of acetylated peptides between different samples. Bioinformatic analyses are then performed to identify enriched pathways and protein networks.[10]
Visualizing the Workflow and a Key Signaling Pathway
To better illustrate the processes described, the following diagrams were generated using the DOT language.
Caption: A generalized workflow for comparative acetylome proteomics.
Caption: Regulation of cellular processes by the deacetylase SIRT1.
Conclusion
The comparative analysis of this compound acetylomes across different cell types provides invaluable insights into the regulatory landscape of cellular processes. As technologies for mass spectrometry and data analysis continue to advance, we can expect even deeper and more comprehensive explorations of the acetylome, furthering our understanding of its role in health and disease and paving the way for novel therapeutic strategies targeting the enzymes that govern this critical post-translational modification.
References
- 1. tandfonline.com [tandfonline.com]
- 2. Frontiers | Comprehensive Proteomic Analysis of this compound Acetylation in the Foodborne Pathogen Trichinella spiralis [frontiersin.org]
- 3. Acetylproteomics analyses reveal critical features of this compound-ε-acetylation in Arabidopsis and a role of 14-3-3 protein acetylation in alkaline response - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Quantitative Profiling of this compound Acetylation Reveals Dynamic Crosstalk between Receptor Tyrosine Kinases and this compound Acetylation - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Deep, Quantitative Coverage of the this compound Acetylome Using Novel Anti-acetyl-lysine Antibodies and an Optimized Proteomic Workflow - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Deep, Quantitative Coverage of the this compound Acetylome Using Novel Anti-acetyl-lysine Antibodies and an Optimized Proteomic Workflow - PMC [pmc.ncbi.nlm.nih.gov]
- 7. This compound acetylation stoichiometry and proteomics analyses reveal pathways regulated by sirtuin 1 in human cells - PMC [pmc.ncbi.nlm.nih.gov]
- 8. pnas.org [pnas.org]
- 9. Comparative Analysis of Global Proteome and this compound Acetylome Between Naive CD4+ T Cells and CD4+ T Follicular Helper Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 10. pubs.acs.org [pubs.acs.org]
- 11. Recent Contributions of Proteomics to Our Understanding of Reversible Nε-Lysine Acylation in Bacteria - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Quantitative Acetylomics Reveals Dynamics of Protein this compound Acetylation in Mouse Livers During Aging and Upon the Treatment of Nicotinamide Mononucleotide - PMC [pmc.ncbi.nlm.nih.gov]
- 13. High-Resolution Mass Spectrometry to Identify and Quantify Acetylation Protein Targets - PMC [pmc.ncbi.nlm.nih.gov]
- 14. How to Enrich Acetylated Peptides Before Mass Spectrometry? | MtoZ Biolabs [mtoz-biolabs.com]
- 15. Acetylated Peptide Enrichment Service - Creative Proteomics [creative-proteomics.com]
- 16. Automated Immunoprecipitation Workflow for Comprehensive Acetylome Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 17. PTMScan® Acetyl-Lysine Motif [Ac-K] Kit | Cell Signaling Technology [cellsignal.com]
The Arginine-to-Lysine Ratio: A Guiding Principle for Enhancing Protein Solubility and Expression
For researchers, scientists, and professionals in drug development, achieving high yields of soluble and functional proteins is a cornerstone of success. The propensity of a protein to aggregate during overexpression is a significant bottleneck, leading to wasted resources and project delays. While numerous factors influence protein solubility, a growing body of evidence points to a simple yet powerful predictor: the ratio of arginine to lysine residues in a protein's sequence.
This guide provides a comprehensive comparison of the arginine-to-lysine (Arg/Lys) ratio as a predictive tool for protein solubility and expression. We will delve into the experimental data supporting this principle, compare it with other prediction methods, and provide detailed protocols for its practical application in your research.
The Arg/Lys Ratio: A Key Determinant of Protein Behavior
Computational analyses and experimental studies have revealed a consistent trend: a higher this compound-to-arginine (Lys/Arg or KR) ratio is correlated with increased protein solubility and higher expression levels.[1][2][3] This observation suggests that while both are positively charged amino acids, their contributions to a protein's overall biophysical properties are not interchangeable.
The underlying reasons for this difference are multifaceted. Arginine's guanidinium group, with its capacity for multi-directional hydrogen bonds and cation-pi interactions, has a greater propensity to form intermolecular contacts that can lead to aggregation.[1] Conversely, this compound's simpler amino group appears to be more effective at maintaining a favorable hydration shell, thus promoting solubility.
A pivotal study on E. coli proteins demonstrated a significant correlation between a higher KR-ratio and increased solubility.[1][2] This research established a threshold KR-ratio of 1.2, above which proteins were more likely to be soluble.[1][2] These findings have been influential in the development of protein solubility prediction tools and protein engineering strategies.
Comparing Solubility Predictors: The Role of the Arg/Lys Ratio
Several computational tools are available to predict protein solubility. While many employ complex machine learning algorithms trained on large datasets, the Arg/Lys ratio stands out for its simplicity and interpretability. The Protein-Sol web server, for instance, incorporates the difference between this compound and arginine content (K-R) as one of its key features, highlighting the importance of this parameter.[4]
Here is a comparison of some popular protein solubility predictors:
| Predictor | Methodology | Key Features Considered | Role of Arg/Lys Ratio |
| Arg/Lys Ratio (KR-Ratio) | Simple sequence-based calculation (Number of Lysines / Number of Arginines). | The relative abundance of this compound and arginine. | Primary predictor. A higher ratio suggests better solubility. |
| Protein-Sol | Linear model based on 35 sequence-based properties.[4] | Amino acid composition (including K-R), isoelectric point, hydropathy, and predicted disorder.[4] | Explicitly included as a key feature (K-R). [4] |
| SOLart | Structure-based method using a statistical potential. | Surface properties, including hydrophobicity and charge distribution, derived from the 3D structure. | Not an explicit, primary feature, but the overall charge distribution is considered. |
| ccSOL | Support Vector Machine (SVM) classifier. | Physicochemical properties like hydrophobicity, secondary structure propensity, and coil/disorder regions. | Not explicitly highlighted as a primary feature. |
| PROSO II | Two-layer model combining sequence similarity and k-mer composition. | Sequence homology and amino acid composition patterns. | Not a direct input, but the overall amino acid composition is a factor. |
| Solubility-Weighted Index (SWI) | Based on global structural flexibility modeled by normalized B-factors.[5][6] | The inherent flexibility of the amino acid sequence.[5][6] | Not a direct input. |
While more complex models may offer higher accuracy in some cases, the Arg/Lys ratio provides a valuable and easily calculable first-pass assessment of a protein's likely solubility. Its inclusion as a core feature in successful predictors like Protein-Sol underscores its significance.
Experimental Validation of the Arg/Lys Ratio Hypothesis
The following section outlines a generalized experimental workflow to test the hypothesis that increasing the Arg/Lys ratio of a target protein can improve its solubility and expression.
Experimental Protocols
1. Site-Directed Mutagenesis to Increase Arg/Lys Ratio:
-
Objective: To create variants of a target protein with an increased number of lysines and a decreased number of arginines, while minimizing disruption to the protein's structure and function.
-
Protocol:
-
Identify arginine residues on the protein surface that are not involved in critical functions (e.g., active sites, protein-protein interaction interfaces) using structural modeling software (e.g., PyMOL, Chimera).
-
Design primers for site-directed mutagenesis to substitute selected arginine codons (e.g., CGU, CGC, CGA, CGG, AGA, AGG) with this compound codons (AAA, AAG).
-
Perform site-directed mutagenesis using a high-fidelity DNA polymerase and a suitable expression vector containing the gene of interest.
-
Sequence the mutated plasmids to confirm the desired Arg-to-Lys substitutions.
-
2. Recombinant Protein Expression:
-
Objective: To express the wild-type and mutated proteins in a suitable host system, typically E. coli.
-
Protocol:
-
Transform a suitable E. coli expression strain (e.g., BL21(DE3)) with the plasmids containing the wild-type and mutated genes.
-
Grow the transformed cells in a suitable culture medium (e.g., LB or TB broth) at 37°C to an optimal optical density (OD600 of 0.6-0.8).
-
Induce protein expression with an appropriate concentration of isopropyl β-D-1-thiogalactopyranoside (IPTG) (e.g., 0.1-1 mM).
-
Continue to culture the cells at a lower temperature (e.g., 18-25°C) for an extended period (e.g., 16-24 hours) to promote proper protein folding.
-
3. Assessment of Protein Solubility:
-
Objective: To quantify the proportion of soluble and insoluble protein for both the wild-type and the mutants.
-
Protocol:
-
Harvest the cells by centrifugation.
-
Resuspend the cell pellet in a lysis buffer (e.g., 50 mM Tris-HCl pH 8.0, 150 mM NaCl, 1 mM DTT) and lyse the cells by sonication or high-pressure homogenization.
-
Separate the soluble and insoluble fractions by centrifugation at high speed (e.g., 15,000 x g for 30 minutes at 4°C).
-
Carefully collect the supernatant (soluble fraction). Resuspend the pellet (insoluble fraction) in an equal volume of lysis buffer, potentially containing a denaturant like urea or guanidinium chloride to solubilize the inclusion bodies.
-
Analyze equal volumes of the total cell lysate, soluble fraction, and insoluble fraction by SDS-PAGE.
-
Visualize the protein bands by Coomassie blue staining or Western blotting using an antibody specific to the target protein or a purification tag.
-
4. Quantification of Protein Expression and Solubility:
-
Objective: To quantitatively compare the expression levels and solubility of the wild-type and mutant proteins.
-
Protocol:
-
Perform densitometry on the protein bands from the SDS-PAGE gel or Western blot using image analysis software (e.g., ImageJ).
-
Total Expression: Measure the band intensity of the target protein in the total cell lysate.
-
Soluble Expression: Measure the band intensity of the target protein in the soluble fraction.
-
Solubility Percentage: Calculate the percentage of soluble protein as: (Intensity of soluble fraction / Intensity of total cell lysate) x 100.
-
Compare the total expression levels and solubility percentages between the wild-type and the Arg-to-Lys mutants.
-
Visualizing the Concepts
To further clarify the principles and workflows discussed, the following diagrams are provided.
Caption: Structural differences between arginine and this compound side chains and their impact on protein interactions.
Caption: Experimental workflow for validating the effect of the Arg/Lys ratio on protein solubility.
Caption: The logical relationship between the Arg/Lys ratio and protein solubility outcomes.
Conclusion
The arginine-to-lysine ratio is a simple, yet effective, sequence-based feature for predicting the solubility and expression of recombinant proteins. While not a standalone solution for all protein expression challenges, it provides a valuable guiding principle for protein engineering and construct design. By strategically increasing the this compound content and reducing the arginine content on the protein surface, researchers can significantly improve the chances of obtaining high yields of soluble, functional protein. This data-driven approach, combined with established experimental protocols, empowers scientists to overcome common hurdles in protein production and accelerate their research and development efforts.
References
- 1. pubs.acs.org [pubs.acs.org]
- 2. This compound and Arginine Content of Proteins: Computational Analysis Suggests a New Tool for Solubility Design - PMC [pmc.ncbi.nlm.nih.gov]
- 3. This compound and arginine content of proteins: computational analysis suggests a new tool for solubility design - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Protein–Sol: a web tool for predicting protein solubility from sequence - PMC [pmc.ncbi.nlm.nih.gov]
- 5. biorxiv.org [biorxiv.org]
- 6. academic.oup.com [academic.oup.com]
Safety Operating Guide
Lysine proper disposal procedures
Proper disposal of lysine is crucial for maintaining laboratory safety and ensuring environmental compliance. While L-lysine is not generally classified as a hazardous substance, adherence to established disposal protocols is a fundamental aspect of good laboratory practice.[1][2][3][4] This guide provides detailed, step-by-step procedures for the safe handling and disposal of this compound waste.
Immediate Safety and Handling
Before any disposal procedures, it is imperative to handle this compound with the appropriate personal protective equipment (PPE). In the event of a spill, immediate and correct action is necessary to prevent contamination and exposure.
Personal Protective Equipment (PPE):
-
Eye Protection: Wear safety glasses.[5]
-
Hand Protection: Use protective gloves, such as Nitrile Rubber.[5]
-
Skin Protection: Wear a lab coat or suitable protective clothing.[5][6]
-
Respiratory Protection: If dust is generated, use a dust mask or an approved respirator.[7]
Spill Response Protocol:
-
Avoid Dust Generation: For solid this compound, use dry clean-up procedures to prevent dust from becoming airborne.[6][8]
-
Containment: Prevent the substance from entering drains or water courses.[1][6][9]
-
Clean-up:
-
Collection: Place the collected residue into a suitable, sealed, and clearly labeled container for disposal.[5][8][9]
-
Decontamination: Wash the affected area thoroughly with water.[8]
Step-by-Step Disposal Protocol
The disposal of this compound must comply with all federal, state, and local environmental regulations.[5][10] The following steps provide a comprehensive guideline for its proper disposal.
-
Consult the Safety Data Sheet (SDS): Always begin by referring to the manufacturer-specific SDS for the most accurate and detailed disposal instructions.[6]
-
Waste Characterization: Determine if the this compound waste is classified as hazardous according to local regulations. While not typically regulated as a dangerous good for transport, waste generators must consult local hazardous waste regulations for a complete and accurate classification.[1][6]
-
Container Management:
-
Keep waste this compound in suitable, closed containers.[5] Whenever possible, use the original container.[6]
-
Ensure the container is clearly and accurately labeled.
-
Do not mix this compound waste with other chemical waste.[1][6]
-
Handle uncleaned, empty containers as you would the product itself.[1][6]
-
-
Select a Disposal Method:
-
Licensed Waste Disposal Service: The most recommended method is to offer surplus and non-recyclable solutions to a licensed professional waste disposal company.[5][6]
-
Incineration: An alternative is to dissolve or mix the material with a combustible solvent and burn it in a chemical incinerator equipped with an afterburner and scrubber.[6][7] This should only be performed by qualified personnel in a permitted facility.
-
Authorized Landfill: In some jurisdictions, solid this compound residue may be buried in an authorized landfill.[8] Consult your local State Land Waste Management Authority for guidance.[8]
-
Drain Disposal (for dilute aqueous solutions only): This method is contingent upon approval from your institution's Environmental Health and Safety (EHS) department. If approved, the solution must be heavily diluted with water before being slowly poured down the drain with a continuous flow of water.[2]
-
-
Documentation: Maintain detailed records of all disposal activities, including the date, quantity, method of disposal, and any manifests from waste disposal services.[6]
Environmental Impact Data
Understanding the ecological impact of a substance is critical for proper disposal. The following table summarizes aquatic toxicity data for L-lysine.
| Parameter | Species | Result | Exposure Time | Guideline |
| LC50 (Toxicity to fish) | Oryzias latipes (Japanese rice fish) | > 103 mg/l | 96 h | OECD Test Guideline 203[1] |
| EC50 (Toxicity to daphnia) | Daphnia magna (Water flea) | > 106 mg/l | 48 h | OECD Test Guideline 202[1] |
| ErC50 (Toxicity to algae) | Pseudokirchneriella subcapitata | > 100 mg/l | 72 h | OECD Test Guideline 201[1] |
| EC50 (Toxicity to bacteria) | Activated sludge | > 100 mg/l | 3 h | OECD Test Guideline 209[1] |
This compound is readily biodegradable, with a result of 83% after 28 days under aerobic conditions.[1]
This compound Disposal Workflow
The following diagram illustrates the decision-making process for the proper disposal of this compound waste in a laboratory setting.
Caption: this compound Disposal Decision Workflow.
References
- 1. uprm.edu [uprm.edu]
- 2. benchchem.com [benchchem.com]
- 3. tedpella.com [tedpella.com]
- 4. carlroth.com [carlroth.com]
- 5. formedium.com [formedium.com]
- 6. benchchem.com [benchchem.com]
- 7. bioshopcanada.com [bioshopcanada.com]
- 8. store.apolloscientific.co.uk [store.apolloscientific.co.uk]
- 9. sds.metasci.ca [sds.metasci.ca]
- 10. datasheets.scbt.com [datasheets.scbt.com]
Essential Safety and Operational Guidance for Handling Lysine
For researchers, scientists, and drug development professionals, adherence to stringent safety protocols is paramount for a secure laboratory environment. This guide provides immediate and essential information for the safe handling of Lysine, outlining the necessary personal protective equipment (PPE), procedural steps for its use, and appropriate disposal plans. While this compound is an amino acid and generally considered to have low toxicity, proper handling is crucial to minimize any potential risks, particularly when in powdered form which can be inhaled.[1][2]
Personal Protective Equipment (PPE) Recommendations
A thorough risk assessment of specific laboratory procedures is necessary to determine the full scope of required PPE. However, the following table summarizes the minimum recommended PPE for handling this compound in both solid and solution forms.
| PPE Category | Recommendation | Standard Compliance |
| Eye/Face Protection | Safety glasses with side shields or chemical splash goggles.[3][4] A face shield may be required for tasks with a significant splash hazard.[3] | NIOSH (US) or EN 166 (EU) |
| Hand Protection | Disposable nitrile gloves are recommended.[3][4] Other suitable materials for dry solids include polychloroprene, butyl rubber, and PVC.[1] | EN 374 |
| Body Protection | A standard laboratory coat is required.[3] For larger quantities or increased risk of exposure, chemical-resistant clothing may be necessary.[5] | N/A |
| Respiratory Protection | An N95 or P1 dust mask should be worn when handling solid this compound, especially if not in a chemical fume hood or well-ventilated area.[3][4] | NIOSH (US) or EN 149 (EU) |
Occupational Exposure Limits
While most safety data sheets indicate that there are no specific occupational exposure limit values established for L-Lysine, it is best practice to minimize dust generation.[4][5][6] In the absence of specific limits, the Oregon Permissible Exposure Limits (PELs) for "Particulates Not Otherwise Regulated" (PNOR) can be used as a guideline for airborne dust.[1]
| Substance | Limit Type | Exposure Limit (mg/m³) |
| Particulates Not Otherwise Regulated (Total Dust) | TWA (8-hr) | 10 |
| Particulates Not Otherwise Regulated (Respirable Fraction) | TWA (8-hr) | 5 |
Experimental Protocols: Handling, Emergency Procedures, and Disposal
Standard Operating Procedure for Handling this compound
-
Preparation : Before handling, ensure that the work area is clean and that all necessary PPE is readily available. If working with powdered this compound, ensure adequate ventilation or perform the work in a chemical fume hood.[4]
-
Donning PPE :
-
Put on a lab coat and ensure it is fully buttoned.
-
Put on safety glasses or goggles.
-
If required, put on a respirator.
-
Wash and dry hands thoroughly before putting on gloves.
-
-
Handling :
-
Doffing PPE :
-
Remove gloves first, peeling them off from the cuff to the fingertips to avoid touching the outer surface.
-
Remove the lab coat.
-
Remove eye and respiratory protection.
-
Wash hands again thoroughly.
-
Emergency Procedures
-
Eye Contact : Immediately flush eyes with plenty of water for at least 15 minutes, occasionally lifting the upper and lower eyelids. Seek medical attention if irritation persists.[2]
-
Skin Contact : Remove contaminated clothing and wash the affected skin area with soap and plenty of water.[4]
-
Inhalation : If dust is inhaled, move the person to fresh air. If breathing is difficult, provide oxygen.[2]
-
Ingestion : Rinse the mouth with water. Do not induce vomiting. Never give anything by mouth to an unconscious person.[2][4]
Disposal Plan
-
Solid Waste : Dispose of contaminated materials such as gloves, weigh boats, and paper towels in a designated hazardous waste container.[3][4]
-
Chemical Waste : Unused this compound should be offered to a licensed disposal company. Do not dispose of it down the drain.[4]
-
Contaminated Packaging : Dispose of contaminated packaging as you would the unused product.[4]
Visual Workflow for Safe Handling of this compound
The following diagram outlines the logical workflow for the safe handling of this compound, from the initial assessment and preparation to the final disposal of waste.
Caption: A flowchart illustrating the procedural steps for the safe handling of this compound.
References
Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Avertissement et informations sur les produits de recherche in vitro
Veuillez noter que tous les articles et informations sur les produits présentés sur BenchChem sont destinés uniquement à des fins informatives. Les produits disponibles à l'achat sur BenchChem sont spécifiquement conçus pour des études in vitro, qui sont réalisées en dehors des organismes vivants. Les études in vitro, dérivées du terme latin "in verre", impliquent des expériences réalisées dans des environnements de laboratoire contrôlés à l'aide de cellules ou de tissus. Il est important de noter que ces produits ne sont pas classés comme médicaments et n'ont pas reçu l'approbation de la FDA pour la prévention, le traitement ou la guérison de toute condition médicale, affection ou maladie. Nous devons souligner que toute forme d'introduction corporelle de ces produits chez les humains ou les animaux est strictement interdite par la loi. Il est essentiel de respecter ces directives pour assurer la conformité aux normes légales et éthiques en matière de recherche et d'expérimentation.
