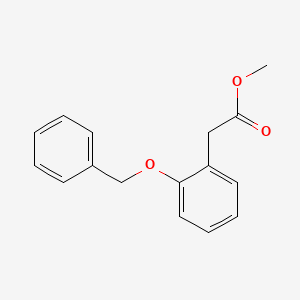
Methyl 2-(2-(benzyloxy)phenyl)acetate
Número de catálogo B1352578
Peso molecular: 256.3 g/mol
Clave InChI: CPIKEDMPXDEUED-UHFFFAOYSA-N
Atención: Solo para uso de investigación. No para uso humano o veterinario.
Patent
US05034388
Procedure details


The crude methyl 3-hydroxy-2-(2'-benzyloxyphenyl)propenoate was dissolved in dry DMF (100 ml) and potassium carbonate (29.0 g) was added in one portion. Dimethyl sulphate (16.00 g) in dry DMF (10 ml) was then added dropwise with stirring. After ninety minutes, water (300 ml) was added and the solution was extracted with ether (2 x 300 ml). After washing with water (3 x 150 ml) and brine, the extracts were dried and concentrated under reduced pressure, and the resulting yellow oil solidified on trituration with ether/petrol. Recrystallization from dry methanol afforded E-methyl 3-methoxy-2-(2'-benzyloxyphenyl)propenoate as a white, crystalline solid (5.44g, 17% yield from methyl 2-benzyloxyphenylacetate), M.P. 76-77° C.; infrared maxima (nujol mull): 1710, 1640 cm-1 ; 1H nmr (CDCl3, 90MHz): delta 3.63 (3H,s), 3.75 (3H,s), 5.05 (2H,s), 6.80-7.40 (9H,m), 7.50 (1H,s)ppm.
Name
methyl 3-hydroxy-2-(2'-benzyloxyphenyl)propenoate
Quantity
0 (± 1) mol
Type
reactant
Reaction Step One


Identifiers
|
REACTION_CXSMILES
|
[OH:1][CH:2]=[C:3]([C:8]1[CH:13]=[CH:12][CH:11]=[CH:10][C:9]=1[O:14][CH2:15][C:16]1[CH:21]=[CH:20][CH:19]=[CH:18][CH:17]=1)[C:4]([O:6][CH3:7])=[O:5].[C:22](=O)([O-])[O-].[K+].[K+].S(OC)(OC)(=O)=O.O>CN(C=O)C>[CH3:22][O:1]/[CH:2]=[C:3](\[C:8]1[CH:13]=[CH:12][CH:11]=[CH:10][C:9]=1[O:14][CH2:15][C:16]1[CH:17]=[CH:18][CH:19]=[CH:20][CH:21]=1)/[C:4]([O:6][CH3:7])=[O:5].[CH2:15]([O:14][C:9]1[CH:10]=[CH:11][CH:12]=[CH:13][C:8]=1[CH2:3][C:4]([O:6][CH3:7])=[O:5])[C:16]1[CH:17]=[CH:18][CH:19]=[CH:20][CH:21]=1 |f:1.2.3|
|
Inputs
Step One
|
Name
|
methyl 3-hydroxy-2-(2'-benzyloxyphenyl)propenoate
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
OC=C(C(=O)OC)C1=C(C=CC=C1)OCC1=CC=CC=C1
|
|
Name
|
|
|
Quantity
|
100 mL
|
|
Type
|
solvent
|
|
Smiles
|
CN(C)C=O
|
Step Two
|
Name
|
|
|
Quantity
|
29 g
|
|
Type
|
reactant
|
|
Smiles
|
C([O-])([O-])=O.[K+].[K+]
|
Step Three
|
Name
|
|
|
Quantity
|
16 g
|
|
Type
|
reactant
|
|
Smiles
|
S(=O)(=O)(OC)OC
|
|
Name
|
|
|
Quantity
|
10 mL
|
|
Type
|
solvent
|
|
Smiles
|
CN(C)C=O
|
Step Four
|
Name
|
|
|
Quantity
|
300 mL
|
|
Type
|
reactant
|
|
Smiles
|
O
|
Conditions
Stirring
|
Type
|
CUSTOM
|
|
Details
|
with stirring
|
|
Rate
|
UNSPECIFIED
|
|
RPM
|
0
|
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
WAIT
|
Type
|
WAIT
|
|
Details
|
After ninety minutes
|
EXTRACTION
|
Type
|
EXTRACTION
|
|
Details
|
the solution was extracted with ether (2 x 300 ml)
|
WASH
|
Type
|
WASH
|
|
Details
|
After washing with water (3 x 150 ml) and brine
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
the extracts were dried
|
CONCENTRATION
|
Type
|
CONCENTRATION
|
|
Details
|
concentrated under reduced pressure
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
Recrystallization from dry methanol
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
CO/C=C(/C(=O)OC)\C1=C(C=CC=C1)OCC1=CC=CC=C1
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C(C1=CC=CC=C1)OC1=C(C=CC=C1)CC(=O)OC
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
