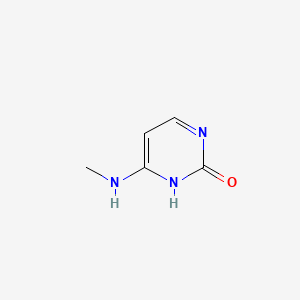
N(4)-methylcytosine
Descripción
Structure
3D Structure
Propiedades
IUPAC Name |
6-(methylamino)-1H-pyrimidin-2-one |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C5H7N3O/c1-6-4-2-3-7-5(9)8-4/h2-3H,1H3,(H2,6,7,8,9) |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
PJKKQFAEFWCNAQ-UHFFFAOYSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
CNC1=CC=NC(=O)N1 |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C5H7N3O |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
DSSTOX Substance ID |
DTXSID40902933 |
Source
|
| Record name | NoName_3509 | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID40902933 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
125.13 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
CAS No. |
6220-47-9 |
Source
|
| Record name | 6-(Methylamino)-2(1H)-pyrimidinone | |
| Source | CAS Common Chemistry | |
| URL | https://commonchemistry.cas.org/detail?cas_rn=6220-47-9 | |
| Description | CAS Common Chemistry is an open community resource for accessing chemical information. Nearly 500,000 chemical substances from CAS REGISTRY cover areas of community interest, including common and frequently regulated chemicals, and those relevant to high school and undergraduate chemistry classes. This chemical information, curated by our expert scientists, is provided in alignment with our mission as a division of the American Chemical Society. | |
| Explanation | The data from CAS Common Chemistry is provided under a CC-BY-NC 4.0 license, unless otherwise stated. | |
| Record name | N(4)-Methylcytosine | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0006220479 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
Biological Significance and Functional Roles of N 4 Methylcytosine
Roles in DNA Replication and Repair
Control of DNA Replication Initiation and Progression
N(4)-methylcytosine plays a critical role in the intricate regulation of DNA replication. In bacterial systems, such as Caulobacter crescentus, DNA methylation, particularly at GANTC sites mediated by the CcrM methyltransferase, is intrinsically linked to the cell cycle and the progression of DNA replication. The methylation status of key regulatory promoters, like that of the dnaA gene, directly influences transcription initiation and, consequently, the initiation of DNA replication. As replication progresses, the resulting hemimethylated DNA serves as a signal, synchronizing the synthesis of other crucial cell cycle regulators, such as CtrA, with the replication fork's movement. Full methylation of the chromosome, completed after replication, is necessary to re-establish the conditions for initiating the next round of DNA replication, thereby acting as a molecular clock for cell cycle progression. While the precise mechanisms in eukaryotes are still under active investigation, the presence of 4mC is recognized to influence DNA replication processes. mdpi.com
Error Correction Mechanisms
The involvement of 4mC in DNA repair and error correction is an area of growing interest. mdpi.com Studies in Deinococcus radiodurans have indicated that cells deficient in 4mC modification exhibit enhanced DNA recombination and transformation efficiency, suggesting a role for 4mC in maintaining genomic fidelity, which is closely related to error correction. Although much of the detailed research on DNA repair mechanisms related to cytosine methylation has focused on 5-methylcytosine (B146107) (5mC) and its associated deamination to thymine (B56734), leading to G:T mismatches that are corrected by pathways like Base Excision Repair (BER) involving enzymes such as Thymine DNA Glycosylase (TDG) and Methyl Binding Domain 4 (MBD4), the fundamental involvement of 4mC in DNA repair processes is acknowledged.
Maintenance of Genome Stability
This compound is recognized for its contribution to the maintenance of genome stability. mdpi.com In the bacterium Deinococcus radiodurans, a known model for DNA repair and genomic stability, the absence of 4mC modification was correlated with a higher spontaneous mutation frequency and increased DNA recombination, underscoring 4mC's role in preserving the integrity of the genome. Furthermore, differential gene expression was observed in 4mC-deficient strains, affecting genes involved in genomic stability. In eukaryotic contexts, the acquisition of bacterial methyltransferases that deposit 4mC has been linked to the suppression of transposon proliferation, a critical mechanism for preventing genomic instability.
Involvement in Cell Cycle Control
The regulation of the cell cycle is significantly influenced by DNA methylation, including 4mC. In bacteria like Caulobacter crescentus, the methyltransferase CcrM plays a central role in cell cycle progression by orchestrating the methylation status of the chromosome. This methylation acts as a temporal regulator, ensuring that critical events such as DNA replication initiation are coordinated with specific phases of the cell cycle, preventing premature re-initiation and ensuring proper genome duplication. The cell cycle-specific activity of CcrM, peaking at the end of S-phase, ensures that newly synthesized DNA is fully methylated, thereby preparing the cell for the subsequent cycle.
Emerging Roles in Eukaryotes
Horizontal Gene Transfer and Epigenetic Innovation
A significant development in the understanding of 4mC is its recognition in eukaryotic genomes, often attributed to the horizontal gene transfer (HGT) of bacterial DNA methyltransferases. researchgate.net For instance, the acquisition of a bacterial amino-methyltransferase, N4CMT, by bdelloid rotifers over 60 million years ago has introduced 4mC modification into these invertebrates. This integration of bacterial epigenetic machinery into eukaryotic genomes represents a form of epigenetic innovation, allowing eukaryotes to co-opt bacterial methylation systems for novel regulatory functions. Similarly, 4mC has been identified in plants like Marchantia polymorpha, where it plays a crucial role in sperm development, suggesting independent or multiple instances of HGT and functional adaptation of 4mC modification in eukaryotes.
Association with Transposon Silencing
In eukaryotes that have acquired bacterial methyltransferases capable of depositing 4mC, such as the N4CMT in bdelloid rotifers, this modification has been found to be deposited at active transposons and specific tandem repeats. The N4CMT enzyme, through its fused chromodomain, can recognize silent chromatin marks and, in partnership with histone methyltransferases like SETDB1, contributes to a "DNA-read-histone-write" mechanism. This concerted action effectively silences transposable elements, thereby reshaping epigenetic systems to suppress transposon proliferation and maintain genome stability. researchgate.net
Table 1: Key Enzymes in Bacterial DNA Methylation and Cell Cycle Control
| Enzyme | Methylated Base | Primary Role(s) | Organism Example | Citation(s) |
| CcrM | Cytosine (N4) | Cell cycle regulation, DNA replication timing, genome stability | Caulobacter crescentus | |
| Dam | Adenine (B156593) (N6) | DNA replication timing, mismatch repair | E. coli | |
| DraR1 | Cytosine (N4) | Genomic stability, DNA repair | Deinococcus radiodurans | |
| N4CMT | Cytosine (N4) | Transposon silencing, epigenetic innovation in eukaryotes (via HGT) | Bacterial origin, found in Bdelloid rotifers |
Table 2: Mechanisms of DNA Repair Associated with Cytosine Methylation
| Modification | Associated Repair Pathway(s) | Key Enzymes Involved (Examples) | Role/Outcome | Citation(s) |
| 5-methylcytosine (5mC) | Base Excision Repair (BER) | TDG, MBD4, UDG superfamily | Corrects G:T mismatches from 5mC deamination, maintains genetic and epigenetic integrity. | |
| 5-methylcytosine (5mC) | Non-canonical Mismatch Repair (ncMMR) | Not explicitly defined | Can remove 5mC derivatives and distant methylation marks; involved in active DNA demethylation. | |
| N4-methylcytosine (4mC) | DNA Recombination/Transformation Pathways (indirectly) | Not explicitly defined | Deficiency linked to enhanced DNA recombination and transformation efficiency, suggesting a role in maintaining genomic stability. |
Table 3: Horizontal Gene Transfer of DNA Methyltransferases into Eukaryotes
| Transferred Enzyme | Likely Bacterial Origin | Eukaryotic Host/System | Approximate Time of Acquisition | Functional Role in Eukaryote | Citation(s) |
| N4CMT | Bacterial methyltransferase | Bdelloid rotifers | >60 Million years ago | Deposits 4mC, involved in transposon silencing, epigenetic innovation, genome stability | |
| Unspecified N4-MT | Bacterial origin | Marchantia polymorpha (Liverwort) | Ancient (likely) | Deposits 4mC, crucial for sperm development and motility |
Table 4: Eukaryotic Roles of Acquired Bacterial Methyltransferases (Focus on 4mC)
| Eukaryotic Organism/System | Acquired Methyltransferase | Modification Deposited | Primary Role | Citation(s) |
| Bdelloid rotifers | N4CMT | N4-methylcytosine (4mC) | Silencing of transposons, epigenetic innovation, maintenance of genome stability | |
| Marchantia polymorpha | Unspecified N4-methyltransferase | N4-methylcytosine (4mC) | Critical for sperm development |
Interactions with Histone Modifications (e.g., H3K9me3)
This compound (m4C), a DNA base modification traditionally recognized in bacterial systems, has been identified as an epigenetic mark in eukaryotic DNA, notably in bdelloid rotifers . This eukaryotic m4C modification is mediated by an enzyme of bacterial origin, N4CMT, which was acquired through horizontal gene transfer . Research indicates that m4C in eukaryotic genomes is intricately linked with repressive chromatin states, showing a strong association with histone modifications such as H3K9me3 . H3K9me3 is a canonical mark of heterochromatin, instrumental in silencing transposable elements and repetitive DNA sequences, thereby contributing to genome stability .
The N4CMT enzyme, responsible for depositing m4C in bdelloid rotifers, possesses a chromodomain. This domain is key to its ability to recognize and bind to repressive histone marks, specifically H3K9me3 and H3K27me3 . This structural feature establishes a "histone-read-DNA-write" architecture, suggesting that the presence of these repressive histone marks guides N4CMT to specific genomic locations for m4C deposition . The observation of increased m4C levels in silenced transposable elements and tandem repeats further supports its role in heterochromatin formation and gene silencing, aligning with the established functions of H3K9me3 .
The functional interplay between m4C and H3K9me3 is further underscored by reciprocal interactions involving SETDB1, a histone methyltransferase that establishes H3K9me3 . Studies have shown that amplified variants of SETDB1 exhibit a preferential binding affinity for 4mC-modified DNA . This suggests a "DNA-read-histone-write" mechanism, where the presence of m4C on DNA can recruit or enhance the activity of H3K9me3-writing enzymes like SETDB1 . This reciprocal interaction creates a feedback loop that reinforces chromatin-based silencing, contributing to the maintenance of heterochromatin and the suppression of transposable elements .
Summary of this compound and H3K9me3 Interaction
| Component/Modification | Associated Enzyme/Protein | Role in Interaction | Observed Association/Mechanism |
| This compound (m4C) | N4CMT (enzyme) | DNA modification deposition; Chromodomain recognition | Guides N4CMT to H3K9me3-marked regions ("histone-read-DNA-write" architecture) |
| H3K9me3 | SETDB1 (enzyme) | Histone modification deposition; DNA binding | SETDB1 variants preferentially bind 4mC-DNA, reinforcing silencing ("DNA-read-histone-write" partnership) |
| Chromodomain (of N4CMT) | N4CMT | Histone mark recognition | Binds to H3K9me3 and H3K27me3, directing m4C deposition |
| Transposable Elements & Repetitive DNA | H3K9me3, m4C | Target regions for silencing | Excess of 4mC found in these silenced regions, associated with H3K9me3 |
Compound List:
this compound (m4C)
H3K9me3 (Trimethylation of Lysine 9 on Histone H3)
H3K27me3 (Trimethylation of Lysine 27 on Histone H3)
N4CMT (N4-methylcytosine methyltransferase)
SETDB1 (Histone methyltransferase)
5-methylcytosine (5mC)
N6-methyladenine (6mA)
Enzymology of N 4 Methylcytosine
N(4)-Cytosine-Specific DNA Methyltransferases (DNMTs)
N(4)-methylcytosine is generated by specific enzymes known as N(4)-cytosine methyltransferases (N4-CMTs) or DNA methylases (DNMTs) that are cytosine-N4-specific ebi.ac.uk. These enzymes are integral to bacterial defense mechanisms and epigenetic regulation .
The methylation of cytosine at the N4 position is a SAM-dependent reaction, a common mechanism for DNA methyltransferases . S-adenosyl-L-methionine (SAM) serves as the methyl group donor, transferring a methyl (-CH3) group to the amino group at the C4 position of the cytosine ring . This process typically involves the formation of a covalent intermediate between the enzyme and the DNA substrate, facilitating the methyl transfer . The PvuII methyltransferase, for instance, is known to bind two molecules of SAM and transfer a methyl group from SAM to cytosine, generating N4-methylcytosine . N4-CMTs often contain conserved motifs, such as the FxGxG motif, which is crucial for interacting with SAM .
Specific enzymes responsible for N(4)-cytosine methylation have been identified across various organisms, particularly in bacteria and bacteriophages. These enzymes are classified as cytosine-N4-specific DNA methyltransferases ebi.ac.uk. For example, M. Ssp6803II in the cyanobacterium Synechocystis sp. PCC 6803 is responsible for methylating the first cytosine in the GGCC motif, producing N4-methylcytosine (GGm4CC) . In Helicobacter pylori, the methyltransferase M2. HpyAII recognizes the 5′ TCTTC 3′ sequence and methylates the first cytosine residue . Deinococcus radiodurans possesses an N4-methylation methyltransferase, M. DraR1, which recognizes the 5′-CCGCGG-3′ sequence and methylates the second cytosine . These enzymes are often part of restriction-modification (R-M) systems, where they protect the host DNA from cognate restriction endonucleases by methylating specific recognition sequences nih.gov.
Methyltransferases that function independently of a cognate restriction endonuclease are termed "orphan" methyltransferases . These solitary methyltransferases are believed to be primarily involved in regulatory activities within bacterial cells . Global analyses indicate that orphan methyltransferases are present in a significant percentage of bacteria and archaea . While their precise regulatory roles are still being elucidated, they are known to influence gene expression, DNA replication, and DNA repair . For instance, N4-methylcytosine modification has been shown to affect gene expression levels by influencing transcription factor binding and chromatin structure .
Identification and Characterization of Specific 4mC Methyltransferases
Demethylation Pathways of this compound
The removal of the methyl group from this compound, converting it back to cytosine, is a critical process for regulating the epigenetic landscape. However, the demethylation pathways for 4mC are less characterized compared to those for 5mC.
The precise enzymatic mechanisms for this compound demethylation are not fully understood and are an active area of research. Studies in Escherichia coli suggest that this compound can be converted to cytosine by an as-yet-undetermined demethylase. This cytosine is then converted to uracil (B121893) by the cytosine deaminase CodA, supporting bacterial growth in specific auxotrophic strains . This implies a multi-step process where a specific N4-demethylase acts first, followed by cytosine deaminase activity.
The demethylation of this compound differs significantly from the well-established pathways for 5-methylcytosine (B146107) (5mC) demethylation in eukaryotes. In eukaryotes, 5mC is primarily demethylated through an oxidative pathway mediated by the Ten-Eleven Translocation (TET) family of enzymes (TET1, TET2, TET3) . TET enzymes sequentially oxidize 5mC to 5-hydroxymethylcytosine (B124674) (5hmC), 5-formylcytosine (B1664653) (5fC), and 5-carboxylcytosine (5caC). These oxidized forms are then typically removed by the Base Excision Repair (BER) pathway, often initiated by thymine (B56734) DNA glycosylase (TDG), ultimately restoring cytosine .
While some studies suggest that TET enzymes might possess direct demethylation properties for 4mC , this is distinct from their primary, well-characterized role in the oxidative demethylation of 5mC. The mechanisms for 4mC demethylation in bacteria, such as the proposed action of an unknown demethylase in E. coli, appear to be separate from the TET-mediated oxidative cascade seen for 5mC . Furthermore, the BER pathway, while involved in processing oxidized 5mC derivatives, is not directly implicated in the initial removal of the methyl group from 4mC in the same manner as it is for 5fC and 5caC.
Genomic Distribution and Sequence Context of N 4 Methylcytosine Sites
Genome-Wide Mapping and Analysis of 4mC Sites
Mapping 4mC sites at a single-base resolution across the genome has been challenging due to the limitations of traditional methods. Bisulfite sequencing, commonly used for 5-methylcytosine (B146107) (5mC) detection, is not ideal for distinguishing 4mC from 5mC due to the partial resistance of 4mC to deamination . Techniques like mass spectrometry can quantify 4mC but lack the resolution for genome-wide mapping .
Recent advancements have introduced more effective methods for genome-wide 4mC profiling. The 4mC-Tet-assisted bisulfite-sequencing (4mC-TAB-seq) approach utilizes Tet protein to oxidize 5mC, allowing for differentiation between 5mC and 4mC during bisulfite sequencing . Another innovative method, APOBEC3A-mediated deamination sequencing (4mC-AMD-seq), leverages the differential deamination activity of APOBEC3A on cytosine and 5mC versus 4mC to map 4mC sites at single-base resolution . These methods have enabled the systematic identification and analysis of 4mC distribution across various genomes. For instance, 4mC-AMD-seq was used to map 4mC in Deinococcus radiodurans, identifying 1586 4mC sites . Similarly, Single-Molecule, Real-Time (SMRT) sequencing has also been employed to detect 4mC, though it can be costly and may overestimate modification levels mdpi.com. Computational methods, including machine learning and deep learning algorithms, are also being developed to predict 4mC sites, offering a cost-effective and scalable alternative for large-scale genomic analysis mdpi.com.
Identification of Specific Methylated Motifs
Identifying specific sequence motifs associated with 4mC is crucial for understanding its regulatory mechanisms. Research has indicated that 4mC is not randomly distributed but rather shows preferences for particular sequence contexts.
In Deinococcus radiodurans, genome-wide mapping using 4mC-AMD-seq revealed that 564 out of 1586 identified 4mC sites were located within the CCGCGG motif . The average methylation level in this motif was 70.0%, significantly higher than the 22.8% observed in non-CCGCGG sequences . Studies analyzing sequence preferences for 4mC have identified enriched motifs, often involving specific dinucleotides. For example, in the bdelloid rotifer Adineta vaga, 4mC sites were found to predominantly occur in CpG and CpA dinucleotides, which constituted 74% of the modified dinucleotides . Motif enrichment analysis in this species identified significant motifs associated with CG or CA dinucleotides . Computational prediction models also highlight sequence context as a key factor, with different species showing distinct nucleotide preferences around 4mC sites . For instance, in E. coli, adenosine (B11128) and thymine (B56734) are enriched near 4mC sites, while cytosine and guanine (B1146940) are preferred at non-4mC sites .
Distribution Patterns in Prokaryotic and Eukaryotic Genomes
The distribution patterns of 4mC differ significantly between prokaryotic and eukaryotic organisms. In prokaryotes, 4mC is a common DNA modification, often playing a role in restriction-modification (R-M) systems, which help protect bacteria from foreign DNA such as bacteriophages . It is also implicated in regulating gene expression, DNA replication, and cell cycle progression . Historically, 4mC was thought to be exclusively found in prokaryotes .
However, recent studies have provided evidence for the presence and functional significance of 4mC in certain eukaryotic genomes. In the liverwort Marchantia polymorpha, extensive 4mC methylation has been observed in genic regions, catalyzed by novel methyltransferases, and is essential for sperm function . In bdelloid rotifers, a bacterial DNA methyltransferase captured via horizontal gene transfer appears to catalyze N4-methylcytosine addition, contributing to the suppression of transposon proliferation and acting as an epigenetic mark . Despite these findings, the prevalence and functional roles of 4mC in eukaryotes are still less understood compared to prokaryotes, and its detection can be challenging mdpi.com.
The frequency of cytosine methylation varies widely across species. For example, approximately 14% of cytosines are methylated in Arabidopsis thaliana, while E. coli shows 2.3% methylation, and Caenorhabditis elegans and fungi like Saccharomyces cerevisiae have virtually no detectable cytosine methylation . While 6mA and 5mC are prevalent in many organisms, 4mC is particularly noted in thermophilic bacteria .
Asymmetric Occurrence and Dinucleotide Preferences
The occurrence of 4mC in DNA sequences often exhibits asymmetry and preferences for specific dinucleotide contexts. Unlike the predominantly symmetric methylation patterns of 5mC at CpG sites in many eukaryotes, 4mC and 6mA in some organisms like Adineta vaga show mostly asymmetric patterns, meaning only one strand is typically modified .
Dinucleotide preferences are a key characteristic of 4mC distribution. As noted earlier, CpG and CpA dinucleotides are the most prevalent contexts for 4mC in A. vaga, accounting for 74% of modified dinucleotides . Computational analyses also reveal distinct nucleotide preferences around 4mC sites across different species, underscoring the importance of sequence context in determining methylation patterns . For instance, sequence logos generated from E. coli data show significant enrichment of adenosine and thymine at positions surrounding 4mC sites, contrasting with the preferences observed in Drosophila melanogaster, where guanine and cytosine are enriched around 4mC sites . This suggests that the enzymatic machinery responsible for 4m methylation, as well as the specific sequence recognition, can vary significantly between different organisms.
Research Methodologies for N 4 Methylcytosine Analysis
Experimental Detection Techniques
Several experimental methodologies are employed to identify 4mC sites, including Single-Molecule Real-Time (SMRT) sequencing, 4mC-Tet-assisted bisulfite sequencing (4mC-TAB-seq), mass spectrometry, and methylation-specific PCR. While these techniques have been instrumental in advancing our understanding of 4mC, they can be limited by factors such as cost, throughput, and sensitivity.
SMRT sequencing, a third-generation sequencing technology, directly detects DNA modifications, including 4mC, during the sequencing process. This is achieved by observing the kinetics of DNA polymerase as it incorporates nucleotides. The presence of a modified base like 4mC can cause a delay in the incorporation of the corresponding nucleotide, a change that is recorded and used to identify the location of the modification. SMRT sequencing offers the advantage of long read lengths and the ability to detect various base modifications simultaneously. However, the cost and the requirement for specialized equipment can be limitations for some research applications. It has been successfully used to identify 4mC sites in various organisms, including bacteria.
Key Features of SMRT Sequencing for 4mC Detection:
| Feature | Description |
|---|---|
| Principle | Detects kinetic variations in DNA polymerase activity caused by modified bases. |
| Advantages | Long read lengths, direct detection of modifications, and high accuracy. |
| Limitations | Higher cost compared to other methods, specialized instrumentation required. |
| Application | Genome-wide mapping of 4mC in various organisms. |
4mC-TAB-seq is a next-generation sequencing method designed to specifically identify 4mC at single-base resolution. This technique builds upon the principles of bisulfite sequencing. In standard bisulfite sequencing, unmethylated cytosines are converted to uracil (B121893) (read as thymine), while 5-methylcytosine (B146107) (5mC) remains unchanged. However, this method cannot distinguish between 5mC and 4mC. 4mC-TAB-seq overcomes this limitation by employing a Ten-eleven translocation (Tet) enzyme. The Tet enzyme oxidizes 5mC to 5-carboxylcytosine (5caC), which is then susceptible to bisulfite conversion and read as thymine (B56734). In contrast, 4mC is resistant to this oxidation and subsequent bisulfite treatment, and is therefore read as cytosine. This allows for the specific identification of 4mC sites.
Comparison of Bisulfite-Based Sequencing Methods:
| Method | Principle | Outcome for 4mC | Outcome for 5mC | Outcome for Cytosine |
|---|---|---|---|---|
| Standard Bisulfite Sequencing | Deamination of unmethylated cytosine. | Read as Cytosine (partially) | Read as Cytosine | Read as Thymine |
| 4mC-TAB-seq | Tet-mediated oxidation of 5mC followed by bisulfite treatment. | Read as Cytosine | Read as Thymine | Read as Thymine |
Tandem mass spectrometry (MS/MS) is a powerful analytical technique used for the sensitive and accurate quantification of modified nucleosides, including 4mC. This method involves the enzymatic digestion of genomic DNA into individual nucleosides, which are then separated by liquid chromatography (LC) and analyzed by a mass spectrometer. By monitoring specific mass-to-charge ratio transitions, MS/MS can distinguish and quantify 4mC, 5mC, and other modified bases. This technique is highly accurate and can provide absolute quantification of the modification. However, it does not provide information about the specific genomic location of the modification.
Methylation-precise PCR is a targeted approach used to investigate the methylation status of specific DNA regions. This method relies on methylation-sensitive restriction enzymes that differentially cleave DNA depending on the presence or absence of methylation at their recognition sites. By designing primers flanking a potential 4mC site within a restriction enzyme recognition sequence, the methylation status can be inferred from the success of PCR amplification after enzyme digestion. If the site is methylated, the enzyme cannot cut, and the PCR product is generated. Conversely, if the site is unmethylated, the enzyme cuts the DNA, preventing amplification. While cost-effective for analyzing a few loci, this method is not suitable for genome-wide analysis.
Methylated DNA Immunoprecipitation (MeDIP) is a technique used to enrich for methylated DNA fragments from a genomic sample. This method utilizes an antibody that specifically binds to a methylated nucleotide, most commonly 5-methylcytosine (5mC). diagenode.com The antibody-bound DNA fragments are then isolated and can be analyzed by various downstream applications, such as qPCR or next-generation sequencing (MeDIP-seq), to identify the enriched methylated regions. While MeDIP is widely used for 5mC analysis, its application for 4mC is dependent on the availability of a highly specific antibody for N(4)-methylcytosine.
A recently developed method, APOBEC3A-mediated deamination sequencing (4mC-AMD-seq), offers single-base resolution mapping of 4mC. This technique leverages the enzymatic activity of the APOBEC3A (A3A) protein, which deaminates cytosine and 5mC to uracil and thymine, respectively. Both of these deaminated bases are read as thymine during sequencing. Crucially, this compound is resistant to this A3A-mediated deamination and is therefore read as cytosine. This differential reactivity allows for the precise identification of 4mC sites throughout the genome. In a study on Deinococcus radiodurans, 4mC-AMD-seq identified 1586 4mC sites, with an average methylation level of 70.0% in CCGCGG motifs and 22.8% in other sequence contexts.
Methylated DNA Immunoprecipitation (MeDIP)
Computational Prediction Methods
The development of computational tools for 4mC site prediction has seen a rapid evolution, moving from initial statistical methods to sophisticated machine learning and deep learning frameworks. These methods typically involve several key steps: compiling a high-quality benchmark dataset of known 4mC and non-4mC sites, extracting relevant features from the DNA sequences, training a classifier to distinguish between the two classes, and rigorously evaluating the model's performance. A variety of feature extraction techniques are employed, including nucleotide composition, physicochemical properties of DNA, and more abstract representations learned directly from the sequence data by deep learning models.
Machine Learning Approaches
Machine learning has become a cornerstone for the computational identification of 4mC sites. These approaches have demonstrated considerable success in building models that can discern the subtle sequence patterns associated with this compound. Researchers have explored a wide array of machine learning algorithms to tackle this classification problem.
A comparative analysis of different machine learning models often involves evaluating their performance on benchmark datasets from various organisms. These evaluations are crucial for selecting the most suitable model for 4mC site prediction.
Deep Learning Models
In recent years, deep learning has emerged as a particularly promising technique for 4mC site prediction due to its ability to automatically learn hierarchical feature representations from raw DNA sequences. This capability often circumvents the need for manual feature engineering, which can be a complex and time-consuming process. Deep learning models, such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs), have been successfully applied to capture sequence patterns and dependencies, leading to accurate identification of 4mC sites.
For instance, the Deep4mC predictor utilizes a deep learning framework and has shown high accuracy and robust performance across multiple species. Another model, DeepTorrent, combines a CNN with a Bidirectional Long Short-Term Memory (BiLSTM) network to effectively learn high-order feature representations from DNA sequences. The adaptability and non-linearity offered by deep learning models make them powerful tools for enhancing our understanding of DNA methylation. A systematic analysis of deep learning architectures for 4mC prediction revealed that a hybrid CNN-RNN model with an attention mechanism achieved strong performance.
| Predictor | Organism | Accuracy | Reference |
|---|---|---|---|
| Deep4mC | A. thaliana | >90% | |
| Deep4mC | C. elegans | >90% | |
| Deep4mC | D. melanogaster | >90% | |
| DeepTorrent | Multiple Species | Not Specified |
Deep Forest Algorithms
A more recent innovation in this field is the application of Deep Forest (DF) algorithms, which represent a non-neural network style of deep learning. This approach has been used to develop predictors for 4mC sites by generating a variety of informative features from DNA sequence fragments and then implementing them into a DF model.
| Organism | Accuracy | Reference |
|---|---|---|
| A. thaliana | 85.0% | |
| C. elegans | 90.0% | |
| D. melanogaster | 87.8% |
Support Vector Machines (SVM)
Support Vector Machines (SVM) are a powerful and widely used machine-learning algorithm in bioinformatics for classification tasks, including the identification of 4mC sites. The fundamental principle of SVM is to find an optimal hyperplane that maximizes the margin between two classes in a high-dimensional feature space.
The first predictor for 4mC sites, known as iDNA4mC, was based on an SVM model. This model utilized nucleotide chemical properties and frequency as input features. Following this, other SVM-based predictors like 4mCPred and 4mcPred-SVM were developed, which employed more advanced feature encoding and selection techniques to enhance prediction accuracy. For example, 4mCPred used position-specific trinucleotide propensity and electron-ion interaction pseudopotentials as features. The performance of SVM models is often optimized by tuning parameters such as the penalty parameter C and the kernel parameter γ through a grid search approach.
Random Forest (RF)
Random Forest (RF) is another popular machine learning algorithm that has been effectively applied to the prediction of 4mC sites. RF is an ensemble learning method that operates by constructing a multitude of decision trees at training time and outputting the class that is the mode of the classes of the individual trees.
RF has been utilized in various frameworks for 4mC prediction. For example, in the development of the 4mCpred-EL predictor, RF was one of the machine learning algorithms used to generate probabilistic features from different feature encodings. The robustness of RF in handling high-dimensional data and its ability to capture non-linear relationships make it a suitable choice for this bioinformatics problem.
Ensemble Learning Frameworks
Ensemble learning frameworks combine multiple machine learning models to improve predictive performance over a single model. This approach has proven to be highly effective for the identification of 4mC sites.
A notable example is the 4mCpred-EL, a predictor developed specifically for identifying 4mC sites in the mouse genome. This framework utilizes four different machine learning algorithms (Gradient Boosting, Extremely Randomized Trees, SVM, and RF) and a wide range of seven feature encodings. The probabilistic values predicted by these models are then used as a new feature vector, which is fed into another layer of machine learning algorithms to generate the final prediction. This ensemble approach demonstrated significantly improved accuracy compared to individual classifiers. Another ensemble learning model, 4mCBERT, integrates sequence-derived features with chemical information and has shown superior performance on several benchmark datasets.
| Metric | Value | Reference |
|---|---|---|
| Accuracy | 0.795 | |
| MCC (Matthews Correlation Coefficient) | 0.591 |
Feature Engineering for 4mC Site Prediction
Nucleotide Chemical Properties
The four standard deoxyribonucleotides—Adenine (B156593) (A), Cytosine (C), Guanine (B1146940) (G), and Thymine (T)—exhibit distinct chemical properties that can be leveraged for 4mC site prediction. These properties influence the local structure and interactions of the DNA molecule. By encoding these chemical characteristics, machine learning models can capture patterns that may be associated with the presence of a 4mC modification.
Key chemical properties used in feature encoding include:
Ring Structure: Nucleotides are classified based on their ring structure as either purines (Adenine, Guanine) which have a double-ring structure, or pyrimidines (Cytosine, Thymine) which have a single-ring structure.
Hydrogen Bonds: The bonds formed between base pairs (A-T and G-C) are based on the number of hydrogen bonds they can form. Adenine and Thymine form two hydrogen bonds, while Guanine and Cytosine form three.
Functional Group: Nucleotides can also be categorized by their functional groups, such as the amino group or the keto group.
To utilize these properties, a DNA sequence is transformed into a numerical vector. For instance, the tool iDNA4mC uses a combination of these chemical properties to represent a DNA sequence. An analysis of the iDNA4mC predictor showed that features derived from ring structure and hydrogen bonds contributed most significantly to the identification of 4mC sites across multiple species.
Table 1: Example of Encoding Nucleotide Chemical Properties
| Nucleotide | Ring Structure (x) | Hydrogen Bond (y) | Chemical Functionality (z) | Coordinate Representation (x, y, z) |
|---|---|---|---|---|
| Adenine (A) | 1 (Purine) | 1 (Weak H-bond) | 1 (Amino group) | (1, 1, 1) |
| Cytosine (C) | 0 (Pyrimidine) | 0 (Strong H-bond) | 1 (Amino group) | (0, 0, 1) |
| Guanine (G) | 1 (Purine) | 0 (Strong H-bond) | 0 (Keto group) | (1, 0, 0) |
| Thymine (T) | 0 (Pyrimidine) | 1 (Weak H-bond) | 0 (Keto group) | (0, 1, 0) |
Other properties, such as the electron-ion interaction pseudopotential (EIIP) of trinucleotides, have also been used to encode physicochemical characteristics of DNA sequences for 4mC prediction in tools like 4mCPred.
Nucleotide Frequency
Nucleotide frequency is a fundamental feature used in bioinformatics to capture the compositional information of a DNA sequence. For 4mC site prediction, the frequency of nucleotides immediately surrounding the central cytosine is analyzed, as these flanking regions often contain patterns recognized by the methyltransferase enzymes. This type of feature engineering is based on the premise that the nucleotide composition differs between 4mC and non-4mC sites.
Common frequency-based features include:
k-mer Nucleotide Frequency: This represents the frequency of all possible nucleotide subsequences of length k. For example, 2-mer (dinucleotide), 3-mer (trinucleotide), and 4-mer (tetranucleotide) frequencies are often calculated. This results in a feature vector where each element corresponds to the count or frequency of a specific k-mer (e.g., AA, AC, AG, AT for 2-mers).
Nucleotide Density/Sequential Nucleotide Frequency: This measures the frequency of a specific nucleotide appearing up to a certain position in the sequence.
Position-Specific Propensity: This feature captures the propensity of a nucleotide or a group of nucleotides (like trinucleotides) to appear at a specific position relative to the modification site.
Computational Tools and Web Servers (e.g., iDNA4mC, 4mCPred-EL, 4mCPred)
The development of computational tools and web servers has become essential for the high-throughput identification of potential 4mC sites, complementing slower and more expensive experimental methods. These tools utilize various machine learning algorithms and feature engineering strategies to predict 4mC sites directly from DNA sequences.
iDNA4mC: Developed in 2017, iDNA4mC was the first web server for predicting 4mC sites. It is based on a support vector machine (SVM) algorithm. The tool encodes DNA sequences using a combination of nucleotide chemical properties and nucleotide frequency. iDNA4mC demonstrated promising performance in identifying 4mC sites across several species, including C. elegans, D. melanogaster, A. thaliana, E. coli, G. subterraneus, and G. pickeringii. However, subsequent research identified its predictive power as being relatively low compared to newer methods.
4mCPred-EL: This is an ensemble learning framework specifically designed for identifying 4mC sites in the mouse genome, for which no dedicated predictors were previously available. mdpi.com It generates probabilistic features using four different machine learning algorithms (including support vector machine and random forest) combined with seven distinct feature encoding schemes. mdpi.com These schemes cover a wide range of information, such as binary profiles, k-mer composition, and various physicochemical properties. mdpi.com The resulting probabilistic features are then used to train a final ensemble model, which has been shown to significantly outperform individual classifiers. mdpi.com
Table 2: Comparison of Selected 4mC Prediction Web Servers
| Tool Name | Core Algorithm(s) | Key Features Used | Target Genomes | Web Server Availability |
|---|---|---|---|---|
| iDNA4mC | Support Vector Machine (SVM) | Nucleotide chemical properties, Nucleotide frequency | C. elegans, D. melanogaster, A. thaliana, E. coli, G. subterraneus, G. pickeringii | Available |
| 4mCPred | Support Vector Machine (SVM) | Position-specific trinucleotide propensity (PSTNP), Electron-ion interaction potential (EIIP) | C. elegans, D. melanogaster, A. thaliana, E. coli, G. subterraneus, G. pickeringii | Available |
| 4mCPred-EL | Ensemble Learning (SVM, RF, GB, ERT) | Ensemble of 7 feature types (e.g., K-mer, EIIP, RFHC) mdpi.com | Mouse mdpi.com | Available mdpi.com |
Challenges and Limitations in 4mC Detection and Quantification
Despite advancements in both experimental and computational approaches, the accurate detection and quantification of this compound remain challenging. aimspress.com These difficulties stem from the inherent limitations of the available technologies and the biological complexities of epigenetic modifications. researchgate.net
Cost and Labor Intensiveness of Experimental Methods
The primary driver for the development of computational predictors is the significant practical barriers associated with experimental 4mC detection. worldscientific.com Genome-wide experimental mapping is often hindered by several factors:
High Cost: Techniques like single-molecule real-time (SMRT) sequencing and whole-genome bisulfite sequencing require expensive reagents and sophisticated instrumentation, making large-scale screening projects financially prohibitive. mdpi.com
Time-Consuming and Laborious: The protocols for these methods are often complex, multi-step procedures that demand significant time and manual effort from researchers. For example, bisulfite-cloning is effective but considered a time-consuming protocol. mdpi.com
Low Throughput: Some of the most accurate methods have low throughput, limiting the number of samples that can be processed simultaneously and making them unsuitable for large-scale genomic scanning.
These limitations make it impractical to rely solely on experimental methods for routine, genome-wide 4mC analysis, thereby creating a critical need for efficient and reliable computational alternatives.
Sensitivity and Specificity Issues
Both experimental and computational methods for 4mC analysis face challenges related to their sensitivity and specificity.
Experimental Limitations:
Distinguishing Modifications: Standard bisulfite sequencing, a gold standard for detecting 5-methylcytosine, cannot distinguish between 5mC and 4mC without specialized protocols like 4mC-Tet-assisted-bisulfite-sequencing (4mC-TAB-seq).
Detection Sensitivity: Some methods have restricted detection sensitivity, making it difficult to identify 4mC, especially if it is present at low levels in the genome. For instance, ultra-high-performance liquid chromatography coupled with mass spectrometry (UHPLC-ms/ms) failed to detect 4mC in some species because the levels were below the detection limit.
Technical Artifacts: Experimental procedures can introduce biases. Poor bisulfite conversion rates can lead to an overestimation of methylation levels, while PCR amplification bias can skew the quantification of methylated versus unmethylated sequences. The cutting efficiency of methylation-sensitive restriction enzymes can also be impaired, leading to an underestimation of methylation.
Computational Limitations:
Dependence on Training Data: The performance of machine learning models is fundamentally dependent on the quality of the benchmark datasets used for training. researchgate.net Since these datasets are generated by experimental methods, they inherit the associated inaccuracies and potential for containing false positives. researchgate.net
Predictive Power and Generalizability: While modern predictors show high accuracy, early models like iDNA4mC had relatively low predictive power. Achieving high sensitivity (correctly identifying true 4mC sites) and high specificity (correctly identifying non-4mC sites) simultaneously remains a challenge. nih.gov Furthermore, a model trained on data from one species may not perform as well on another, highlighting issues with generalizability. The performance of various predictors can differ significantly across the same datasets, indicating that there is still substantial room for improvement in the stability and accuracy of these computational tools. researchgate.net
Distinction from Other Cytosine Modifications (e.g., 5mC)
A significant challenge in studying 4mC is distinguishing it from other cytosine modifications, particularly the well-studied 5-methylcytosine (5mC), as they can coexist in the same genome. Standard analytical methods often struggle to differentiate between these two methylated forms.
Standard bisulfite sequencing, a cornerstone for 5mC mapping, is not suitable for accurately differentiating 4mC from 5mC. In this method, unmethylated cytosine (C) is converted to uracil (U), while 5mC remains largely unconverted. However, 4mC is also partially resistant to this conversion, meaning both 4mC and 5mC are read as cytosine, making them indistinguishable. This ambiguity necessitates the development of specialized techniques.
To address this, several advanced methods have been established:
4mC-Tet-assisted-bisulfite-sequencing (4mC-TAB-seq): This method provides a solution to the limitations of standard bisulfite sequencing. It employs Ten-eleven-translocation (TET) enzymes, which can selectively oxidize 5mC but leave 4mC unmodified. In the subsequent bisulfite treatment, unmodified cytosine and the oxidized 5mC derivatives are converted, while the intact 4mC remains as the primary base read as cytosine, allowing for its specific identification.
Engineered Transcription-Activator-Like Effectors (TALEs): TALEs are programmable DNA-binding proteins that can be engineered for the direct and selective detection of epigenetic modifications. Researchers have developed mutant TALE repeats that can selectively bind to 4mC over both unmodified cytosine and 5mC. This approach can be used in affinity enrichment assays to isolate DNA fragments containing 4mC for downstream analysis.
Single-Molecule, Real-Time (SMRT) Sequencing: As mentioned, SMRT sequencing can directly detect 4mC modifications without the need for chemical conversion like bisulfite treatment. This technology identifies base modifications by analyzing the kinetic variations in DNA polymerase activity as it synthesizes a new strand. This provides a direct method to distinguish 4mC from 5mC, although it is not without its own challenges regarding cost and scalability for very large-scale studies.
The table below summarizes the capabilities of different methods in distinguishing between cytosine, this compound, and 5-methylcytosine.
| Method | Distinguishes C from 4mC/5mC | Distinguishes 4mC from 5mC | Principle of Distinction |
|---|---|---|---|
| Standard Bisulfite Sequencing | Yes | No | Converts C to U, but both 4mC and 5mC are resistant and read as C. |
| SMRT Sequencing | Yes | Yes | Directly detects kinetic signature of polymerase during synthesis, which is unique for each modification. |
| 4mC-TAB-seq | Yes | Yes | TET enzyme oxidizes 5mC, which is then susceptible to bisulfite conversion, while 4mC remains intact and resistant. |
| Engineered TALEs | Yes | Yes | Uses engineered proteins with specific binding affinity for 4mC over C and 5mC for enrichment. |
Physical properties can also offer a means of distinction. Studies using ultraviolet (UV) and circular dichroism (CD) spectrometry have shown that while both 4mC and 5mC promote the transition of B-DNA to Z-DNA, this compound uniquely reduces the thermal stability of the DNA double helix when compared to 5-methylcytosine.
N 4 Methylcytosine in Specific Organisms and Biological Contexts
Prokaryotic Models
Prokaryotic organisms utilize DNA methylation, including N(4)-methylcytosine, primarily as a component of restriction-modification (R-M) systems, which serve as a defense mechanism against foreign DNA. However, research increasingly indicates that 4mC also functions as a global epigenetic regulator, influencing gene expression and cellular processes.
Escherichia coli
Escherichia coli is a well-studied bacterium where DNA methylation plays a role in various cellular processes, including DNA replication timing, mismatch repair, and gene expression. While N6-methyladenine (6mA) is the most prevalent methylation in E. coli, this compound (4mC) has also been identified. Studies have shown that E. coli possesses mechanisms to utilize this compound, as evidenced by its ability to support the growth of uracil (B121893) auxotrophs. This suggests a metabolic pathway where this compound is converted to cytosine and subsequently to uracil, although the direct conversion by CodA cytosine deaminase is not observed. The presence of 4mC in E. coli is associated with its role in restriction-modification systems and potentially in regulating gene expression.
Deinococcus radiodurans
Deinococcus radiodurans, renowned for its exceptional resistance to DNA-damaging agents, also features this compound as a significant DNA modification. Research has identified N(4)-cytosine as the major methylated form in D. radiodurans. A specific methyltransferase, M.DraR1, has been characterized, which recognizes the "CCGCGG" motif and methylates the second cytosine at the N(4) position. This modification is crucial for the bacterium's genomic stability, as strains deficient in 4mC modification exhibit increased spontaneous mutation frequencies and enhanced DNA recombination and transformation efficiencies. The DraI R-M system, involving both M.DraR1 and its cognate restriction endonuclease R.DraR1, plays a role in defending against foreign DNA and maintaining cell viability, particularly under oxidative stress.
Helicobacter pylori
Helicobacter pylori, a human pathogen linked to gastric cancer, also utilizes this compound for epigenetic regulation and pathogenesis. The bacterium possesses a specific methyltransferase, M2.HpyAII, which methylates the first cytosine in the "TCTTC" sequence. Inactivation of this methyltransferase leads to altered phenotypes, including reduced adherence to host cells, diminished potential to induce inflammation and apoptosis, and decreased natural transformation capacity. Genome-wide gene expression analysis revealed that the absence of 4mC modification results in differential expression of genes involved in virulence, ribosome assembly, and cellular components, underscoring 4mC's role as a global epigenetic regulator in H. pylori.
Leptospira interrogans
Leptospira interrogans, the causative agent of leptospirosis, demonstrates the critical role of this compound in virulence and epigenetic regulation. A specific 4mC methyltransferase has been identified that targets the "CTAG" motif. Inactivating this enzyme leads to the complete abrogation of CTAG motif methylation, resulting in genome-wide dysregulation of gene expression. Mutants exhibit growth defects, reduced adhesion to host cells, increased susceptibility to certain antibiotics, and a significant loss of virulence in animal models. This highlights 4mC as a key regulator of L. interrogans physiology and pathogenicity, suggesting similar mechanisms may be employed by other bacterial pathogens.
Thermophilic Bacteria
This compound has been observed in the DNA of thermophilic bacteria, where it appears to offer advantages over 5-methylcytosine (B146107) (5mC). In thermophiles, particularly those with optimal growth temperatures of 60°C or higher, 5mC can be deaminated by heat to thymine (B56734), leading to mismatched base pairs and potential genetic instability due to inefficient repair. this compound, in contrast, chemically stabilizes cytosine against spontaneous deamination, making it a more deamination-resistant modification. This property makes 4mC a preferred modification in high-temperature environments for protecting DNA from restriction enzymes without incurring the same mutational risks associated with 5mC.
Eukaryotic Models
While this compound is primarily a bacterial modification, recent research has revealed its presence and functional role as an epigenetic mark in certain eukaryotes. Bdelloid rotifers, for instance, have acquired a bacterial this compound methyltransferase (N4CMT) through horizontal gene transfer. This enzyme deposits 4mC at active transposons and tandem repeats, working in conjunction with histone modifications to maintain chromatin-based silencing. This finding demonstrates how non-native DNA methyl groups can be integrated into eukaryotic epigenetic systems, driving regulatory innovation and highlighting the potential for cross-kingdom transfer of epigenetic mechanisms.
Broader Epigenetic and Biological Implications of N 4 Methylcytosine
Interplay with Other Epigenetic Marks
N(4)-methylcytosine (4mC) participates in a complex epigenetic landscape, interacting with other well-established epigenetic marks such as 5-methylcytosine (B146107) (5mC), N6-methyladenine (6mA), and various histone modifications. While 5mC is the predominant DNA methylation mark in eukaryotes, 4mC, though less common, has been identified in certain eukaryotic lineages, notably bdelloid rotifers, often acquired through horizontal gene transfer from bacteria . In these rotifers, both 4mC and 6mA modifications show a significant overlap with heterochromatic histone marks, specifically H3K9me3 and H3K27me3, while exhibiting less association with euchromatic H3K4me3 . This suggests a potential role for 4mC in establishing or maintaining repressive chromatin states, similar to its bacterial counterpart .
Furthermore, research indicates a possible "DNA-read-histone-write" partnership involving 4mC. For instance, the amplification of SETDB1, a histone methyltransferase responsible for H3K9 trimethylation, has been observed to yield variants that preferentially bind 4mC-modified DNA. This interaction implies a mechanism where 4mC can recruit histone-modifying machinery to establish heterochromatin and silence gene expression . While direct biochemical cross-talk mechanisms specifically detailing 4mC's interaction with 5mC or 6mA are still emerging, the shared association with heterochromatin points to a broader interplay within the epigenetic regulatory network . General principles of DNA methylation, primarily studied for 5mC, also involve recruitment of methyl-CpG-binding domain (MBD) proteins, which in turn recruit histone deacetylases (HDACs) and histone methyltransferases, thereby altering chromatin structure and mediating gene silencing . It is plausible that 4mC, particularly in contexts where it is found in eukaryotes, might engage in similar cross-talk mechanisms to influence chromatin state and gene regulation.
| Epigenetic Mark | Associated Histone Modifications | Observed in Eukaryotes (e.g., Rotifers) | Potential Role | Citation(s) |
| This compound (4mC) | H3K9me3, H3K27me3 (heterochromatic) | Yes | Associated with repressive chromatin, potential recruitment of histone methyltransferases (e.g., SETDB1) for silencing | |
| N6-methyladenine (6mA) | H3K9me3, H3K27me3 (heterochromatic) | Yes | Associated with repressive chromatin | |
| 5-methylcytosine (5mC) | Gene silencing (recruits MBD proteins, HDACs, HMTs) | Yes (widespread) | Gene silencing, chromatin remodeling |
Evolutionary Significance of 4mC
This compound (4mC) holds significant evolutionary importance, primarily due to its prevalence in prokaryotes and archaea, and its more recent discovery and potential roles in certain eukaryotic lineages. In bacteria and archaea, 4mC is a common DNA modification, often functioning as a key component of restriction-modification (R-M) systems. These systems act as a bacterial immune defense, distinguishing self DNA from foreign DNA by methylating specific recognition sites, thereby preventing the host's own restriction enzymes from cleaving its genome . Beyond R-M systems, 4mC has been implicated in regulating DNA replication, genome stabilization, and recombination processes in prokaryotes .
The presence of 4mC in eukaryotes is a more recent finding, notably identified in bdelloid rotifers. This occurrence is attributed to horizontal gene transfer (HGT) from bacteria, suggesting that eukaryotes can acquire and integrate bacterial epigenetic machinery . In bdelloid rotifers, the acquired bacterial DNA methyltransferases (N4CMT) catalyze N4-methylcytosine addition, which plays a role in silencing transposons and potentially driving regulatory innovation within the eukaryotic genome . This acquisition highlights the dynamic nature of epigenetic systems and how horizontal gene transfer can introduce novel regulatory mechanisms into eukaryotic genomes, influencing their evolution . While 5-methylcytosine (5mC) is ubiquitously found across all domains of life, and N6-methyladenine (6mA) is common in bacteria and found in some lower eukaryotes, 4mC's evolutionary narrative is characterized by its bacterial origins and its sporadic, yet significant, appearance in eukaryotes through HGT, suggesting a role in adapting to new genomic environments or managing mobile genetic elements .
| DNA Methylation Mark | Prevalence in Prokaryotes | Prevalence in Eukaryotes | Primary Known Roles | Evolutionary Significance | Citation(s) |
| This compound (4mC) | Common | Rare (e.g., bdelloid rotifers via HGT) | Restriction-modification systems, DNA replication, genome stabilization, transposon silencing | Acquisition via HGT, potential for regulatory innovation | |
| 5-methylcytosine (5mC) | Common | Widespread | Gene expression regulation, development, disease | Ubiquitous epigenetic mark across life | |
| N6-methyladenine (6mA) | Common | Present in some lineages (e.g., fungi, plants, invertebrates) | DNA repair, stress tolerance, gene regulation | Found in diverse organisms, potential regulatory roles |
This compound in RNA
Extensive research has identified numerous post-transcriptional chemical modifications in RNA, contributing to the diversity of RNA functions. Common RNA modifications include N6-methyladenosine (m6A), 5-methylcytosine (m5C), N1-methyladenosine (m1A), N7-methylguanosine (m7G), and pseudouridine (B1679824) (Ψ) . While cytosine can be modified in RNA, the prevalent modifications reported at the cytosine base are 5-methylcytosine (m5C) and N4-acetylcytidine (ac4C) . Searches for this compound as a modification occurring on RNA molecules did not yield results indicating its presence. Instead, the modifications identified at the N4 position of cytosine in RNA are acetylated, not methylated . Therefore, based on current scientific literature, this compound is not recognized as a modification of RNA.
Q & A
Q. What experimental methods are recommended for detecting N(4)-methylcytosine (4mC) in genomic DNA?
To detect 4mC, single-molecule real-time (SMRT) sequencing is the gold standard due to its ability to resolve methylation at single-nucleotide resolution without bisulfite conversion, which cannot distinguish 4mC from other cytosine modifications like 5-methylcytosine (5mC) . Complementary methods include mass spectrometry for quantitative analysis of bulk 4mC levels and antibody-based techniques (e.g., immunoprecipitation followed by sequencing) for locus-specific identification. Controls should include unmethylated DNA and validation with orthogonal methods to address false positives .
Q. How does 4mC differ functionally and structurally from 5-methylcytosine (5mC) in epigenetic regulation?
Unlike 5mC, which is enriched in eukaryotic genomes and associated with gene silencing, 4mC is prevalent in prokaryotes and some eukaryotes (e.g., C. elegans) where it plays roles in restriction-modification systems and DNA replication timing. Structurally, 4mC modifies the exocyclic amine at position 4 of cytosine, altering hydrogen bonding and DNA-protein interactions, whereas 5mC modifies the carbon at position 4. Methodologically, distinguishing these requires sequencing technologies like SMRT or enzymatic approaches tailored to 4mC-specific recognition .
Q. What are the key considerations for designing probes or primers to study 4mC-enriched regions?
Probe design must account for the thermal stability of DNA duplexes containing 4mC. Adjustments to annealing temperatures are necessary, as methylation can alter melting temperatures (Tm) by ~0.5–1.5°C per modified base. Computational tools like MethSMRT’s pipeline can predict Tm shifts based on methylation patterns. Additionally, avoid regions with secondary structures or repetitive elements to ensure specificity .
Advanced Research Questions
Q. How can researchers resolve contradictions in 4mC detection between bisulfite sequencing and SMRT sequencing?
Bisulfite sequencing converts unmethylated cytosines to uracil but fails to distinguish 4mC from unmodified cytosine, leading to false negatives. When discrepancies arise, validate findings using SMRT sequencing or enzymatic methods (e.g., McrBC endonuclease digestion, which cleaves 4mC-containing DNA). Cross-referencing with mass spectrometry data for bulk methylation levels can also clarify technical vs. biological variability .
Q. What mechanisms regulate the dynamic deposition and removal of 4mC in eukaryotic systems?
While prokaryotic 4mC is maintained by DNA methyltransferases (e.g., M.MspI), eukaryotic regulation is less understood. Hypothesized mechanisms include passive loss during replication or active demethylation via putative oxidases. Experimental approaches to study dynamics include pulse-chase labeling with stable isotope tracers (e.g., ¹³C-methionine) coupled with mass spectrometry, and CRISPR-based knockout screens targeting candidate methyltransferases .
Q. What challenges arise in genome-wide mapping of 4mC, and how can they be mitigated?
Challenges include low abundance in eukaryotes, sequencing depth requirements, and SMRT sequencing’s high cost. To address this, combine SMRT with enrichment strategies (e.g., immunoprecipitation) or use computational imputation models trained on high-confidence 4mC loci. Normalize data against input controls to correct for sequencing bias .
Q. How does 4mC interact with histone modifications or other epigenetic marks in chromatin organization?
Investigate co-localization using sequential ChIP-seq (e.g., 4mC immunoprecipitation followed by histone mark ChIP). For example, in C. elegans, 4mC correlates with H3K9me3 at heterochromatic regions. Use genetic knockouts of methyltransferases to assess causality in 3D chromatin conformation changes via Hi-C .
Q. What experimental models are suitable for studying 4mC’s role in development or disease?
Use prokaryotic models (e.g., E. coli with 4mC-deficient mutants) to study restriction-modification systems. In eukaryotes, C. elegans or zebrafish are tractable for developmental studies. For disease contexts, profile 4mC in cancer cell lines with dysregulated DNA repair pathways. Ensure models are validated with methylation-sensitive restriction digestions to confirm 4mC presence .
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes





Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Descargo de responsabilidad e información sobre productos de investigación in vitro
Tenga en cuenta que todos los artículos e información de productos presentados en BenchChem están destinados únicamente con fines informativos. Los productos disponibles para la compra en BenchChem están diseñados específicamente para estudios in vitro, que se realizan fuera de organismos vivos. Los estudios in vitro, derivados del término latino "in vidrio", involucran experimentos realizados en entornos de laboratorio controlados utilizando células o tejidos. Es importante tener en cuenta que estos productos no se clasifican como medicamentos y no han recibido la aprobación de la FDA para la prevención, tratamiento o cura de ninguna condición médica, dolencia o enfermedad. Debemos enfatizar que cualquier forma de introducción corporal de estos productos en humanos o animales está estrictamente prohibida por ley. Es esencial adherirse a estas pautas para garantizar el cumplimiento de los estándares legales y éticos en la investigación y experimentación.
