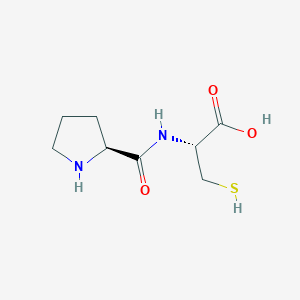
Prolyl-cysteine
Descripción
Structure
3D Structure
Propiedades
Fórmula molecular |
C8H14N2O3S |
|---|---|
Peso molecular |
218.28 g/mol |
Nombre IUPAC |
(2R)-2-[[(2S)-pyrrolidine-2-carbonyl]amino]-3-sulfanylpropanoic acid |
InChI |
InChI=1S/C8H14N2O3S/c11-7(5-2-1-3-9-5)10-6(4-14)8(12)13/h5-6,9,14H,1-4H2,(H,10,11)(H,12,13)/t5-,6-/m0/s1 |
Clave InChI |
HXNYBZQLBWIADP-WDSKDSINSA-N |
SMILES isomérico |
C1C[C@H](NC1)C(=O)N[C@@H](CS)C(=O)O |
SMILES canónico |
C1CC(NC1)C(=O)NC(CS)C(=O)O |
Origen del producto |
United States |
Synthetic Strategies and Methodological Advancements for Prolyl Cysteine
Classical and Solution-Phase Peptide Synthesis Approaches for Prolyl-cysteine
Solution-phase peptide synthesis, while often more labor-intensive than solid-phase methods, offers scalability and flexibility in the synthesis of dipeptides like Prolyl-cysteine. nih.gov This approach involves the coupling of protected proline and cysteine residues in a suitable solvent, followed by deprotection steps. Careful control of reaction conditions is crucial to ensure high yields and prevent side reactions. nih.govbiorxiv.org
Protecting Group Strategies for Prolyl and Cysteine Residues
The success of Prolyl-cysteine synthesis in solution hinges on the judicious selection of protecting groups for the reactive functional groups of both amino acids. These groups must be stable during the coupling reaction and selectively removable without compromising the newly formed peptide bond. hmdb.ca
For the α-amino group of the N-terminal amino acid (either proline or cysteine), the most common protecting groups are tert-Butoxycarbonyl (Boc) and 9-Fluorenylmethyloxycarbonyl (Fmoc). Boc is typically removed under acidic conditions (e.g., with trifluoroacetic acid - TFA), while Fmoc is labile to basic conditions (e.g., with piperidine). nih.gov
The thiol group of the cysteine side chain is highly nucleophilic and prone to oxidation, necessitating robust protection. nih.gov A variety of protecting groups are available, each with distinct deprotection conditions, allowing for orthogonal strategies. Common thiol protecting groups include:
Trityl (Trt): Removed by mild acidolysis (e.g., TFA), often with scavengers like triisopropylsilane (B1312306) (TIS) to prevent side reactions. wikipedia.org
tert-Butyl (tBu): A more acid-stable group, requiring strong acids like hydrogen fluoride (B91410) (HF) for cleavage, though it can be stable to TFA. wikipedia.org
Acetamidomethyl (Acm): Stable to both TFA and HF, and typically removed by treatment with mercury(II) acetate (B1210297) or iodine. wikipedia.org
Benzyl (B1604629) (Bzl): A classic protecting group removed by strong acid (HF) or catalytic hydrogenation. wikipedia.org
The choice of protecting groups for the carboxyl groups of the C-terminal amino acid often involves the formation of esters, such as methyl or benzyl esters, which can be cleaved under specific conditions.
| Protecting Group | Target Functional Group | Common Deprotection Conditions | Strategy Compatibility |
| Boc | α-Amino | Trifluoroacetic Acid (TFA) | Boc/Bzl |
| Fmoc | α-Amino | Piperidine | Fmoc/tBu |
| Trt | Cysteine Thiol | Mild Acid (TFA), Iodine | Fmoc/tBu, Boc/Bzl |
| tBu | Cysteine Thiol | Strong Acid (HF) | Boc/Bzl |
| Acm | Cysteine Thiol | Mercury(II) Acetate, Iodine | Orthogonal to many |
| Bzl | Cysteine Thiol, Carboxyl | Strong Acid (HF), Hydrogenolysis | Boc/Bzl |
Coupling Reagents and Reaction Optimizations for Dipeptide Formation
The formation of the peptide bond between proline and cysteine requires the activation of the carboxyl group of one of the amino acids. Several classes of coupling reagents are employed for this purpose, each with its own mechanism and advantages.
Carbodiimides , such as N,N'-Dicyclohexylcarbodiimide (DCC) and 1-Ethyl-3-(3-dimethylaminopropyl)carbodiimide (EDC), are widely used. nih.govnih.gov DCC is cost-effective for solution-phase synthesis, though its byproduct, dicyclohexylurea (DCU), is poorly soluble and must be removed by filtration. nih.gov EDC is water-soluble, making product purification easier. nih.gov To suppress racemization and improve efficiency, carbodiimide (B86325) reactions are often performed in the presence of additives like 1-Hydroxybenzotriazole (HOBt) or Oxyma Pure. nih.govnih.govnih.gov
Uronium/Guanidinium salts , such as HBTU (O-(Benzotriazol-1-yl)-N,N,N',N'-tetramethyluronium hexafluorophosphate) and HATU (2-(7-Aza-1H-benzotriazole-1-yl)-1,1,3,3-tetramethyluronium hexafluorophosphate), are highly efficient coupling reagents that lead to rapid reactions and minimal side products. nih.govkhanacademy.org They are particularly useful for sterically hindered couplings. nih.gov
Phosphonium salts , like PyBOP (Benzotriazol-1-yl-oxytripyrrolidinophosphonium hexafluorophosphate), are also powerful coupling reagents known for their high reactivity. nih.gov
Optimization of the coupling reaction for Prolyl-cysteine involves careful consideration of the solvent, temperature, and stoichiometry of the reactants. The presence of the bulky and conformationally constrained proline residue can sometimes lead to slower reaction kinetics. youtube.com
| Coupling Reagent | Class | Key Features |
| DCC | Carbodiimide | Cost-effective, insoluble byproduct (DCU). nih.gov |
| EDC | Carbodiimide | Water-soluble byproduct, suitable for aqueous media. nih.gov |
| HBTU/HATU | Uronium/Guanidinium | High efficiency, low racemization, good for hindered couplings. nih.govkhanacademy.org |
| PyBOP | Phosphonium Salt | High reactivity, non-carcinogenic byproducts. nih.gov |
Solid-Phase Peptide Synthesis (SPPS) of Prolyl-cysteine and Derivatives
Solid-Phase Peptide Synthesis (SPPS) has become the method of choice for the routine synthesis of peptides due to its efficiency and amenability to automation. The synthesis of Prolyl-cysteine on a solid support involves the stepwise addition of protected amino acids to a growing peptide chain anchored to an insoluble resin.
Resin Selection and Loading for Prolyl-cysteine Synthesis
The choice of resin is critical in SPPS as it determines the C-terminal functionality of the cleaved peptide and the conditions required for its release. For the synthesis of a Prolyl-cysteine dipeptide with a C-terminal carboxylic acid, Wang resin or 2-Chlorotrityl chloride (2-CTC) resin are commonly used in Fmoc-based strategies. youtube.com Merrifield resin is the classic choice for Boc-based synthesis. youtube.com If a C-terminal amide is desired, Rink Amide or Sieber Amide resins are suitable for Fmoc chemistry, while MBHA resin is used for the Boc strategy. nih.govyoutube.com
Loading the first amino acid onto the resin is a crucial step. For resins like Wang resin, this is typically achieved through esterification, often catalyzed by reagents like DCC or through the use of pre-activated amino acids. When proline is the C-terminal residue, there is a significant risk of diketopiperazine (DKP) formation upon deprotection of the second amino acid's N-terminal protecting group. nih.gov To mitigate this, specialized resins or linkers designed for C-terminal proline, or the coupling of a pre-formed dipeptide, can be employed. nih.govexplorationpub.com
Cleavage and Deprotection Methodologies for Prolyl-cysteine
Once the synthesis of the resin-bound Prolyl-cysteine is complete, the dipeptide must be cleaved from the solid support, and all side-chain protecting groups must be removed. This is typically accomplished in a single step using a "cleavage cocktail."
In Fmoc-based synthesis, the final cleavage is most often performed with a high concentration of Trifluoroacetic Acid (TFA). nih.gov Due to the presence of cysteine, which is susceptible to alkylation by reactive carbocations generated during deprotection, scavengers must be added to the cleavage cocktail. nih.govkhanacademy.org Common scavengers for cysteine-containing peptides include:
Triisopropylsilane (TIS): Effectively scavenges trityl cations. nih.gov
1,2-Ethanedithiol (EDT): A reducing agent that helps to keep the cysteine thiol in its reduced state and prevents disulfide bond formation. khanacademy.org
Water: Acts as a scavenger for tert-butyl cations. nih.gov
Phenol and Thioanisole: Also used to trap reactive species. nih.gov
A common cleavage cocktail for peptides containing sensitive residues like cysteine is "Reagent K," which consists of TFA, phenol, water, thioanisole, and EDT. wikipedia.orgnih.gov The duration of the cleavage reaction is typically a few hours at room temperature. wikipedia.org Following cleavage, the peptide is precipitated from the TFA solution using a cold non-polar solvent like diethyl ether. nih.gov
| Cleavage Reagent | Composition | Purpose |
| Reagent B | TFA/Phenol/Water/TIS (88/5/5/2) | General cleavage, good for scavenging trityl groups. nih.govnih.gov |
| Reagent K | TFA/Phenol/Water/Thioanisole/EDT (82.5/5/5/5/2.5) | For peptides with sensitive residues like Cys, Met, Trp. wikipedia.orgnih.govnih.gov |
| TFA/TIS/H₂O | (95/2.5/2.5) | Standard cleavage for many peptides, but may require additional scavengers for cysteine. nih.gov |
Chemoenzymatic and Biosynthetic Routes to Prolyl-cysteine
The use of enzymes in peptide synthesis offers advantages in terms of specificity and mild reaction conditions. However, specific and well-documented chemoenzymatic or direct biosynthetic routes for the production of the dipeptide Prolyl-cysteine are not extensively reported in the scientific literature. The Human Metabolome Database lists Prolyl-cysteine as an "expected" metabolite but notes that a synthesis reference is not available. hmdb.ca
Research in the field of enzymatic peptide synthesis has explored the use of various proteases and ligases. For instance, proline-specific endopeptidases have been investigated for their potential as catalysts in peptide synthesis, demonstrating the ability to form peptide bonds with proline at the S1 position. nih.gov Furthermore, a mutant of a proline-specific endopeptidase, where the catalytic serine was converted to cysteine, exhibited a dramatically increased peptide ligase activity. nih.gov
Another area of related research involves enzymes that cleave peptide bonds adjacent to proline or cysteine. Post-proline cleaving enzymes (PPCEs) have been shown to also cleave after reduced cysteine residues, suggesting a recognition of both amino acids by the enzyme's active site. nih.gov
While these findings indicate the potential for enzymatic manipulation of peptide bonds involving proline and cysteine, a direct, optimized chemoenzymatic synthesis of Prolyl-cysteine has not been a major focus of reported research. The biosynthesis of dipeptides typically occurs as part of larger protein synthesis on the ribosome or through non-ribosomal peptide synthetases (NRPSs), but specific pathways for the dedicated synthesis of Prolyl-cysteine have not been detailed. One study on a unique peptide synthesis mechanism involving an enzymatic reaction followed by a chemical S to N acyl transfer successfully produced N-(d-alanyl)-l-cysteine, but not Prolyl-cysteine. nih.gov
Future research may yet uncover or engineer enzymes capable of efficiently synthesizing this specific dipeptide, offering a greener and more specific alternative to traditional chemical methods.
Enzyme-Catalyzed Synthesis of Prolyl-cysteine
Chemoenzymatic peptide synthesis offers a green and highly selective alternative to purely chemical methods, avoiding complex protection/deprotection steps and harsh reaction conditions nih.gov. Proteases, which naturally hydrolyze peptide bonds, can be used in reverse to catalyze their formation under non-hydrolytic conditions. This approach, known as kinetically controlled synthesis, relies on using amino acid esters as acyl donors to favor the aminolysis reaction over hydrolysis researchgate.net.
Several classes of enzymes, including serine proteases, cysteine proteases, and aminopeptidases, are suitable for catalyzing the formation of a Prolyl-cysteine bond nih.govresearchgate.net. For instance, proteases like α-chymotrypsin and papain have been successfully employed in the synthesis of various peptides, including those containing cysteine nih.gov. Poly-L-cysteine has been synthesized using α-chymotrypsin in a frozen aqueous medium, demonstrating the enzyme's ability to handle cysteine residues without the need for thiol group protection nih.gov.
A particularly relevant model is the use of aminopeptidases in organic solvents to facilitate dipeptide synthesis. An aminopeptidase (B13392206) from Streptomyces septatus TH-2 has been shown to synthesize various dipeptides with broad specificity in 98% methanol (B129727) (MeOH) asm.orgresearchgate.net. In this system, a free amino acid (e.g., Proline) acts as the acyl donor, and an amino acid methyl ester (e.g., Cysteine-OMe) serves as the acyl acceptor asm.orgresearchgate.net. The high concentration of organic solvent minimizes water activity, shifting the reaction equilibrium towards synthesis rather than hydrolysis. The enzyme from Streptomyces septatus TH-2 demonstrates high stability and efficiency in this non-aqueous environment, reaching over 50% conversion of the limiting substrate to the dipeptide product asm.orgresearchgate.net. This methodology provides a viable route for the stereospecific synthesis of Prolyl-cysteine.
| Parameter | Condition/Value | Rationale/Reference |
|---|---|---|
| Enzyme Class | Aminopeptidase (e.g., from Streptomyces septatus TH-2) | Demonstrated broad specificity and stability for dipeptide synthesis. asm.org |
| Acyl Donor (N-terminus) | Free L-Proline | Enzyme accepts free amino acids for the N-terminal position. asm.org |
| Acyl Acceptor (C-terminus) | L-Cysteine methyl ester (Cys-OMe) | Esterified C-terminus prevents self-polymerization and activates the carboxyl group. asm.orgresearchgate.net |
| Reaction Medium | 90-98% Methanol (MeOH) | Suppresses water-dependent hydrolysis, favoring the synthesis reaction. asm.org |
| Temperature | 25°C | Optimal for enzyme stability and activity in organic solvent. asm.orgresearchgate.net |
| Key Advantage | High stereoselectivity | Enzymes catalyze reactions with specific stereoisomers (L-amino acids), ensuring a stereochemically pure product. nih.gov |
Microbial Fermentation Strategies for Prolyl-cysteine Production
Direct fermentative production of a specific dipeptide like Prolyl-cysteine is not a conventional biotechnological process and presents significant challenges. Typically, microbial fermentation is geared towards producing individual amino acids or complex mixtures of bioactive peptides from protein hydrolysates nih.gov. The targeted synthesis of a single dipeptide requires a sophisticated metabolic engineering approach.
A theoretical strategy would involve a microbial chassis, such as Escherichia coli or Corynebacterium glutamicum, engineered to co-overproduce the precursor amino acids, L-proline and L-cysteine. The fermentative production of L-cysteine is particularly challenging due to its cytotoxicity and the tight metabolic regulation of its biosynthesis pathway nih.govnih.gov. Key engineering strategies for L-cysteine overproduction include nih.govresearchgate.net:
Deregulation of Biosynthesis: Overexpression of a feedback-inhibition-insensitive version of serine O-acetyltransferase (SAT), the rate-limiting enzyme in the cysteine pathway nih.gov.
Elimination of Degradation: Knocking out genes that encode L-cysteine desulfhydrases, which degrade cysteine into pyruvate (B1213749) nih.gov.
Enhanced Export: Overexpression of specific exporter proteins to pump cysteine out of the cell, mitigating its toxic effects nih.govresearchgate.net.
Similar strategies would be required to enhance the intracellular pool of L-proline. Once sufficient precursor levels are achieved, a dedicated enzymatic step is needed to ligate them. This could involve the heterologous expression of a dipeptide synthetase or a ligase with specificity for proline and cysteine. The final product, Prolyl-cysteine, would also need to be efficiently transported out of the cell to prevent feedback inhibition or degradation and to facilitate downstream processing.
| Metabolic Target | Strategy | Purpose |
|---|---|---|
| L-Cysteine Supply | Overexpress feedback-insensitive serine O-acetyltransferase (SAT); knockout cysteine desulfhydrases. | Increase intracellular L-cysteine pool and prevent its degradation. nih.gov |
| L-Proline Supply | Deregulation of the proline biosynthesis pathway (e.g., feedback-resistant γ-glutamyl kinase). | Increase intracellular L-proline pool. |
| Dipeptide Formation | Introduce a heterologous peptide ligase or non-ribosomal peptide synthetase (NRPS) module. | Catalyze the specific formation of the Pro-Cys peptide bond. |
| Product Export | Overexpress a broad-substrate peptide efflux pump. | Remove Prolyl-cysteine from the cell to prevent toxicity/degradation and simplify purification. |
| Toxicity Mitigation | Overexpress cysteine exporters (e.g., CefA/CefB) and potentially peptide exporters. | Reduce cellular stress from accumulation of cysteine and the final dipeptide product. nih.gov |
Stereo- and Regioselective Synthesis Considerations for Prolyl-cysteine
In chemical peptide synthesis, controlling stereochemistry and ensuring regioselective bond formation are paramount, particularly when dealing with polyfunctional amino acids like cysteine.
Stereoselectivity: The primary stereochemical challenge is the prevention of racemization at the α-carbon of the amino acids during peptide coupling. Cysteine is particularly susceptible to racemization, especially when it is the C-terminal residue in an activated ester intermediate rsc.orgacs.org. The use of modern coupling reagents and careful control of reaction conditions are essential to maintain the stereochemical integrity of both the proline and cysteine residues.
Regioselectivity: Regioselectivity concerns directing the reaction to the correct functional group. For Prolyl-cysteine, this involves forming the amide bond between proline's α-carboxyl group and cysteine's α-amino group, while preventing unwanted reactions at the cysteine thiol group. The thiol is a potent nucleophile and is easily oxidized to form disulfide bonds peptide.combachem.com. Therefore, protection of the thiol group is mandatory during the amide bond formation step bachem.com.
A wide variety of thiol protecting groups have been developed, which can be cleaved under different conditions. This orthogonality is crucial for the synthesis of more complex peptides containing multiple cysteine residues where specific disulfide bridges need to be formed acs.org. For the synthesis of a simple Prolyl-cysteine dipeptide, a protecting group that is stable during the coupling reaction but can be easily removed afterward is chosen. The trityl (Trt) group, for example, is widely used in Fmoc-based solid-phase peptide synthesis (SPPS) as it is stable to the basic conditions used for Fmoc removal but is cleaved by the final trifluoroacetic acid (TFA) cocktail peptide.com.
| Protecting Group | Abbreviation | Cleavage Condition | Compatibility/Use |
|---|---|---|---|
| Triphenylmethyl | Trt | Highly acid-labile (e.g., 95% TFA, dilute acid). peptide.com | Standard for Fmoc-SPPS; removed during final cleavage. |
| 4-Methoxytrityl | Mmt | Very acid-labile (e.g., 1-3% TFA in DCM). rsc.org | Allows for selective, on-resin deprotection to modify the thiol. |
| Acetamidomethyl | Acm | Iodine (I₂) or mercury(II) acetate; stable to TFA. peptide.com | Orthogonal to Trt/tBu; used for regioselective disulfide bond formation. |
| tert-Butyl | tBu | Stable to TFA; requires stronger acids (e.g., HF) or mercuric salts for removal. peptide.comcreative-peptides.com | Compatible with Fmoc strategy for post-cleavage modifications. |
| Diphenylmethyl | Dpm | Stable to dilute TFA (1-3%), removed with 95% TFA. | Offers an alternative to Trt with slightly different lability. |
Analytical Purity Assessment and Isolation Techniques for Synthetic Prolyl-cysteine
Following synthesis, a rigorous analytical workflow is required to isolate the target Prolyl-cysteine dipeptide and confirm its purity and identity.
Purity Assessment: The primary technique for assessing the purity of synthetic peptides is Reversed-Phase High-Performance Liquid Chromatography (RP-HPLC) nih.govresearchgate.net. This method separates the target peptide from impurities such as unreacted amino acids, deletion sequences, or products of side reactions. A typical system uses a C18 stationary phase and a mobile phase gradient of water and acetonitrile (B52724) containing an ion-pairing agent like trifluoroacetic acid (TFA). The purity is determined by integrating the area of the product peak relative to the total peak area in the chromatogram.
Identity Confirmation: Mass Spectrometry (MS) is the definitive method for confirming the molecular weight and thus the identity of the synthetic peptide researchgate.netnih.gov. Electrospray Ionization (ESI-MS) is commonly coupled with HPLC (LC-MS) to provide mass data for the peaks observed in the chromatogram, confirming that the main peak corresponds to Prolyl-cysteine nih.govresearchgate.net. Tandem mass spectrometry (MS/MS) can be used to fragment the peptide, providing sequence information that confirms the Pro-Cys connectivity. The presence of proline and cysteine residues can specifically influence fragmentation patterns nih.gov.
Isolation Techniques: For purification, preparative RP-HPLC is the most common and effective method. The same principles as analytical RP-HPLC are applied, but on a larger scale to isolate milligram-to-gram quantities of the product. Fractions are collected as they elute from the column, and those containing the pure product (as determined by analytical HPLC and MS) are pooled and lyophilized to yield the final product as a fluffy, white powder. For peptides containing a free N-terminus and a cysteine residue, Immobilized Metal Ion Affinity Chromatography (IMAC) has also been explored as a potential purification tool, although binding is primarily dependent on the α-amino group rather than the thiol nih.gov.
| Technique | Purpose | Key Information Provided |
|---|---|---|
| Analytical RP-HPLC | Purity Assessment | Percentage purity, retention time, detection of impurities. researchgate.net |
| Mass Spectrometry (ESI-MS) | Identity Confirmation | Molecular weight of the synthesized dipeptide. nih.govnih.gov |
| Tandem MS (MS/MS) | Structural Confirmation | Amino acid sequence confirmation through fragmentation patterns. nih.gov |
| Preparative RP-HPLC | Isolation/Purification | Separation of the target dipeptide from synthetic byproducts. nih.gov |
| Lyophilization (Freeze-Drying) | Final Product Formulation | Removal of solvents to yield a stable, dry powder. |
Advanced Structural Elucidation and Conformational Dynamics of Prolyl Cysteine
Spectroscopic Characterization of Prolyl-cysteine Conformations
Spectroscopic methods are indispensable for characterizing the transient and stable conformations of peptides in solution. These techniques offer insights into the local chemical environment, secondary structure, and vibrational states of the peptide backbone and amino acid side chains.
Nuclear Magnetic Resonance (NMR) spectroscopy is a powerful technique for determining the three-dimensional structure and dynamics of molecules in solution. For proline-containing peptides like Prolyl-cysteine, NMR is particularly adept at characterizing the cis-trans isomerization of the peptidyl-prolyl bond. nih.govnih.gov
The rotation around the C-N bond preceding the proline residue is sterically hindered, leading to two distinct and slowly interconverting isomers: the trans and cis conformations. nih.govmdpi.com This slow exchange rate on the NMR timescale allows for the observation of separate signals for each isomer, enabling the quantification of their relative populations. ed.ac.uknih.gov While data for the simple dipeptide is not extensively published, studies on model peptides containing a Pro-Cys motif, such as Ac-LPAAC, show that the percentage of the cis population can be reliably measured. nih.govnih.govresearchgate.net The chemical environment, including the nature of adjacent residues and the solvent, significantly influences the cis/trans equilibrium. imrpress.comnih.gov
Key NMR experiments for analyzing Prolyl-cysteine conformation include:
1D ¹H NMR: Provides initial information on the presence of both cis and trans isomers through distinct chemical shifts of the alpha-protons and proline ring protons. nih.gov
2D NOESY (Nuclear Overhauser Effect Spectroscopy): Distinguishes between the two isomers. In the trans conformation, a strong NOE is observed between the proline δ-protons and the α-proton of the preceding residue (in this case, the cysteine α-proton). Conversely, the cis conformation shows a strong NOE between the proline α-proton and the cysteine α-proton. northwestern.edu
¹³C NMR: The chemical shifts of the proline β-carbon (Cβ) and γ-carbon (Cγ) are highly sensitive to the isomerization state, providing a clear diagnostic tool. nih.gov
| Isomer | Proline Cβ Chemical Shift (ppm) | Proline Cγ Chemical Shift (ppm) | Typical Population |
| trans | ~30.6 | ~25.5 | Favored |
| cis | ~33.1 | ~23.2 | Less Favored |
| Note: Chemical shifts are approximate values for proline residues in peptides and can vary based on neighboring residues and solvent conditions. |
Circular Dichroism (CD) spectroscopy measures the differential absorption of left- and right-circularly polarized light, providing information about the secondary structure of peptides and proteins. nih.gov For a short dipeptide like Prolyl-cysteine, which lacks the length to form stable α-helices or β-sheets, the CD spectrum is typically dominated by contributions from unordered structures and polyproline II (PPII)-like conformations. nih.gov
| Structural Element | Characteristic CD Signal | Wavelength (nm) |
| Polyproline II (PPII) Helix | Strong Negative Band | ~190-200 |
| Polyproline II (PPII) Helix | Weak Positive Band | ~220 |
| Unordered/Random Coil | Strong Negative Band | ~195-200 |
| Cysteine Thiol Group | Can contribute to signals, especially upon derivatization or oxidation | >300 (upon derivatization) sci-hub.ru |
Vibrational spectroscopy techniques, such as Fourier-Transform Infrared (FTIR) and Raman spectroscopy, probe the vibrational modes of chemical bonds. nih.govnih.gov For Prolyl-cysteine, these methods provide specific information about the peptide bond and the unique functional groups of the constituent amino acids.
The most informative region in the IR spectrum of a peptide is the amide region:
Amide I band (1600-1700 cm⁻¹): This band arises primarily from the C=O stretching vibration of the peptide bond. mdpi.com Its exact frequency is highly sensitive to the peptide's secondary structure and hydrogen bonding environment. In Prolyl-cysteine, this band would likely appear in the range typical for disordered or extended structures. Studies on related dipeptides like L-prolyl L-isoleucine show intense bands in this region (e.g., 1683, 1650, and 1614 cm⁻¹). asianpubs.org
Amide II band (1500-1600 cm⁻¹): This band results from a coupling of the N-H in-plane bending and C-N stretching vibrations. mdpi.com
Furthermore, the cysteine side chain provides a unique vibrational marker:
S-H stretch (~2550 cm⁻¹): The stretching vibration of the thiol group in cysteine appears in a region of the IR spectrum that is free from other protein signals, making it a distinct and easily identifiable probe. nih.gov
Raman spectroscopy complements FTIR, as it is particularly sensitive to non-polar bonds and can be used in aqueous solutions. researchgate.netresearchgate.net The S-H stretch and potential S-S disulfide bond vibrations are readily detectable by Raman spectroscopy, offering a way to monitor the redox state of the cysteine residue.
| Vibrational Mode | Typical Wavenumber (cm⁻¹) | Spectroscopic Technique |
| Amide I (C=O stretch) | 1600 - 1700 | FTIR / Raman |
| Amide II (N-H bend, C-N stretch) | 1500 - 1600 | FTIR / Raman |
| S-H Stretch (Cysteine) | ~2550 | FTIR / Raman |
Mechanistic Biochemistry and Molecular Interactions of Prolyl Cysteine
Non-Covalent Interactions of Prolyl-cysteine with Biological Macromolecules
Binding Studies with Proteins and Peptides
Prolyl-cysteine, as a dipeptide, can engage in interactions with larger proteins and peptides, influencing their structure and function. While specific studies detailing the binding of the isolated prolyl-cysteine dipeptide to diverse protein targets are not extensively documented in the provided search results, the general principles of peptide-protein interactions apply. The proline residue, with its cyclic structure, can influence peptide backbone conformation, potentially affecting how the dipeptide fits into protein binding pockets or interacts with peptide sequences. Cysteine, with its reactive thiol group, offers a site for potential covalent modifications or specific non-covalent interactions, such as hydrogen bonding or metal coordination, within protein complexes. The presence of a proline residue adjacent to cysteine can influence the accessibility and reactivity of the thiol group. For instance, in broader contexts of protein sequences, the proximity of proline can affect the local conformation around cysteine residues, which in turn can influence disulfide bond formation or interactions with other molecules rsc.orgwou.eduquora.com.
Interactions with Nucleic Acids and Lipids
The interaction of prolyl-cysteine with nucleic acids and lipids is not extensively detailed in the provided search results. However, based on the properties of its constituent amino acids, general interactions can be inferred. The charged nature of the amino and carboxyl groups, along with the polar nature of the thiol group in cysteine, suggests potential for electrostatic interactions with the negatively charged phosphate (B84403) backbone of nucleic acids (DNA and RNA). Similarly, the amino and carboxyl groups can interact with charged lipid headgroups in cell membranes. The hydrophobic character of the proline ring might also contribute to interactions within lipid bilayers or with hydrophobic regions of biomolecules. One study mentions a cysteine-containing peptide dimer interacting with DNA, studied via optical spectroscopy, indicating that peptides with cysteine can indeed interact with DNA nih.gov.
Hydrogen Bonding Networks and Hydrophobic Interactions
Prolyl-cysteine possesses functional groups capable of forming hydrogen bonds and participating in hydrophobic interactions. The peptide bond itself (-NH-CO-) is a critical site for hydrogen bonding, with the amide nitrogen acting as a hydrogen bond donor and the carbonyl oxygen as an acceptor. The proline ring's secondary amine and the cysteine's thiol (-SH) and carboxyl (-COOH) groups also contribute to potential hydrogen bonding networks. The proline ring, being cyclic and containing non-polar methylene (B1212753) groups, contributes to the hydrophobic character of the dipeptide. The cysteine residue, with its aliphatic side chain and thiol group, also has hydrophobic contributions, though the thiol group can also participate in hydrogen bonding or metal coordination. Studies on dipeptide conformations highlight that hydrogen bonding patterns, particularly head-to-tail interactions involving amino and carboxyl groups, are dominant in crystal structures, forming chains or layers ias.ac.inresearchgate.net. Hydrophobic interactions, driven by non-polar side chains, are crucial for protein folding and stability, and the proline ring is a significant contributor to these forces within the dipeptide structure wou.educhemguide.co.uk.
Enzymatic Catalysis and Substrate Specificity Involving Prolyl-cysteine
Research indicates that enzymes known as post-proline cleaving enzymes (PPCEs) can act on substrates containing proline. Notably, some PPCEs, such as Aspergillus niger prolyl endopeptidase (AnPEP) and neprosin, have been found to exhibit specificity towards reduced cysteine in addition to proline and alanine (B10760859) residues researchgate.netresearchgate.netacs.org. This suggests that prolyl-cysteine dipeptides, or sequences containing this motif, could be substrates for these enzymes. Prolyl endopeptidases (PEPs) are a class of serine proteases that cleave peptide bonds at the C-terminal side of proline residues nih.govnih.gov. Other enzymes that process proline-containing peptides include dipeptidyl peptidases (DPPs) and prolyl oligopeptidases (POPs) nih.govnih.govresearchgate.netmdpi.com. A yeast prolyl aminopeptidase (B13392206) (PAP) was identified that releases proline from the N-terminal position of peptides and shows preference for oligopeptides over dipeptides, but its specific activity on prolyl-cysteine was not detailed nih.gov.
Kinetic data for enzymes acting on prolyl-cysteine specifically are not explicitly provided in the search results. However, kinetic parameters for related enzymes and substrates offer insight. For example, Aspergillus niger prolyl endopeptidase (AnPEP) has been studied, with kinetic parameters such as Km and kcat reported for various peptide substrates. These values are dependent on the specific substrate and reaction conditions, including temperature and pH nih.govacs.org. For instance, a prolyl oligopeptidase (GmPOPB) showed a Km of 51 μM and kcat of 35 min-1 for a 25-mer peptide at 37 °C nih.govacs.org. Dipeptidyl aminopeptidase (DAP) from Pseudomonas sp. strain WO24 exhibited Km values for substrates like Gly-Arg-pNA of 0.25 mM asm.org. While these are not for prolyl-cysteine itself, they illustrate the type of kinetic data obtained for enzymes acting on proline-containing peptides. The specificity of PPCEs for reduced cysteine means that modifications to the thiol group (e.g., alkylation, disulfide bond formation) can block or significantly reduce cleavage researchgate.netresearchgate.netacs.org.
Role of Prolyl-cysteine in Protein Folding and Stability Mechanisms
The role of the prolyl-cysteine dipeptide in protein folding and stability is primarily understood through the properties of its constituent amino acids and their potential influence when adjacent in a peptide chain. Proline is known for its unique cyclic structure, which restricts the rotation around the N-Cα bond and can introduce kinks or turns in polypeptide chains, influencing secondary structure formation wou.educhemguide.co.uknih.govnih.gov. Proline residues can also adopt either cis or trans conformations, with the cis conformation potentially disrupting regular hydrogen bonding patterns and affecting protein folding kinetics nih.govnih.gov. Cysteine's thiol group is crucial for forming disulfide bonds, which are covalent cross-links that significantly stabilize protein tertiary and quaternary structures, particularly in extracellular proteins wou.eduquora.com. The presence of a proline residue adjacent to cysteine could influence the local conformation, affecting the accessibility and reactivity of the thiol group for disulfide bond formation or other modifications. For example, pseudoproline (ΨPro) residues, which mimic proline's conformational properties, have been used to disrupt unwanted secondary structure formation and aggregation by disrupting backbone hydrogen bonding rsc.org. While direct evidence for the isolated prolyl-cysteine dipeptide's role in protein folding is limited in the provided results, its constituent residues play well-established roles in protein structural integrity.
Compound List:
Prolyl-cysteine (Pro-Cys)
Proline
Cysteine
L-Prolyl-L-cysteine
Dipeptides
Glycine
Alanine
Glutamate
Lysine
Methionine
Aspartate
Asparagine
Glutamine
Serine
Threonine
Phenylalanine
Valine
Leucine
Isoleucine
Tryptophan
Tyrosine
L-Captopril
Noopept
Heparin
Heparan sulfate (B86663) proteoglycans
Insulin
Oxytocin
Ziconotide
Brentuximab vedotin
Collagen
Fibronectin
Laminin
Fibulin
Integrin
Amanitins
Glucagon-like peptide 1 (GLP1)
Angiotensin I
Angiotensin II
Bradykinin
Hypoxia-inducible factor 1 (HIF-1)
Epidermal growth factor receptor (EGFR)
Peptidyl-prolyl cis-trans isomerase NIMA-interacting 1 (Pin1)
Forkhead Transcription Factors
Foxg1 protein, mouse
Nerve Tissue Proteins
Core Binding Factor Alpha 1 Subunit
Prolyl-4-hydroxyproline (Pro-Hyp)
Cystathionine
GABA
Dipeptidyl peptidase 4 (DPP4)
Dipeptidyl peptidase II (DPPII)
Dipeptidyl peptidase 7 (DPP7)
Dipeptidyl peptidase 8 (DPP8)
Dipeptidyl peptidase 9 (DPP9)
Fibroblast activation protein
Prolyl endopeptidase (PEP)
Prolyl endopeptidase-like
Prolyl oligopeptidase (POP)
Prolyl tripeptidyl aminopeptidase
Prolyl carboxypeptidase (PRCP)
Prolyl hydroxylase domain 2 (PHD2)
Cysteine dioxygenase (CDO-1)
Cystathionase (CTH)
Threonyl-tRNA synthetase
Tosyl-L-Lys-chloromethyl ketone
Leupeptin
Chymostatin
Methyl group
Thiolactone
Diketopiperazine (DKP)
Thioester
Thiohydroximate
Nitrile oxide
Isoxazole
4,5-dihydrothiazole
Chlorooxime
Palmitic Acid
Biotin
Dansyl
7-methoxycoumarin (B196161) acetic acid
Fluorescein
2,4-Dinitrophenyl
TMTr
Tmob
Trt
Fmoc-aaa-Cys(ΨR,R′pro)-OH
Cys(ΨH,Dmppro)
Cys(ΨMe,Mepro)
Thz
Cys(CAM)
Phosphorylation
Isotope labeled Amino Acids
Spacers
Nitrogen
Oxygen
Sulfur
Carbon
Hydrogen
Zinc
Copper
Iron
Titanium
Chlorine
Sodium
Potassium
Magnesium
Calcium
Phosphorus
Silicon
Aluminum
Boron
Strontium
Vanadium
Chromium
Manganese
Cobalt
Nickel
Gallium
Germanium
Arsenic
Selenium
Bromine
Rubidium
Yttrium
Zirconium
Niobium
Molybdenum
Ruthenium
Rhodium
Palladium
Silver
Cadmium
Indium
Tin
Antimony
Tellurium
Iodine
Cesium
Barium
Lanthanum
Cerium
Praseodymium
Neodymium
Promethium
Samarium
Europium
Gadolinium
Terbium
Dysprosium
Holmium
Erbium
Thulium
Ytterbium
Lutetium
Hafnium
Tantalum
Tungsten
Rhenium
Osmium
Iridium
Platinum
Gold
Mercury
Thallium
Lead
Bismuth
Polonium
Astatine
Radon
Francium
Radium
Actinium
Thorium
Protactinium
Uranium
Neptunium
Plutonium
Americium
Curium
Californium
Einsteinium
Fermium
Mendelevium
Nobelium
Lawrencium
Rutherfordium
Dubnium
Seaborgium
Bohrium
Hassium
Meitnerium
Darmstadtium
Roentgenium
Copernicium
Nihonium
Flerovium
Moscovium
Livermorium
Tennessine
Oganesson
Helium
Neon
Argon
Krypton
Xenon
Radon
Oganesson
Lithium
Beryllium
Sodium
Magnesium
Aluminum
Silicon
Phosphorus
Sulfur
Chlorine
Potassium
Calcium
Scandium
Titanium
Vanadium
Chromium
Manganese
Iron
Cobalt
Nickel
Copper
Zinc
Gallium
Germanium
Arsenic
Selenium
Bromine
Rubidium
Strontium
Yttrium
Zirconium
Niobium
Molybdenum
Ruthenium
Rhodium
Palladium
Silver
Cadmium
Indium
Tin
Antimony
Tellurium
Iodine
Cesium
Barium
Lanthanum
Cerium
Praseodymium
Neodymium
Promethium
Samarium
Europium
Gadolinium
Terbium
Dysprosium
Holmium
Erbium
Thulium
Ytterbium
Lutetium
Hafnium
Tantalum
Tungsten
Rhenium
Osmium
Iridium
Platinum
Gold
Mercury
Thallium
Lead
Bismuth
Polonium
Astatine
Francium
Radium
Actinium
Thorium
Protactinium
Uranium
Neptunium
Plutonium
Americium
Curium
Berkelium
Californium
Einsteinium
Fermium
Mendelevium
Nobelium
Lawrencium
Rutherfordium
Dubnium
Seaborgium
Bohrium
Hassium
Meitnerium
Darmstadtium
Roentgenium
Copernicium
Nihonium
Flerovium
Moscovium
Livermorium
Tennessine
Oganesson
Hydrogen
Helium
Lithium
Beryllium
Boron
Carbon
Nitrogen
Oxygen
Fluorine
Neon
Sodium
Magnesium
Aluminum
Silicon
Phosphorus
Sulfur
Chlorine
Argon
Potassium
Calcium
Scandium
Titanium
Vanadium
Chromium
Manganese
Iron
Cobalt
Nickel
Copper
Zinc
Gallium
Germanium
Arsenic
Selenium
Bromine
Krypton
Rubidium
Strontium
Yttrium
Zirconium
Niobium
Molybdenum
Technetium
Ruthenium
Rhodium
Palladium
Silver
Cadmium
Indium
Tin
Antimony
Tellurium
Iodine
Xenon
Cesium
Barium
Lanthanum
Cerium
Praseodymium
Neodymium
Promethium
Samarium
Europium
Gadolinium
Terbium
Dysprosium
Holmium
Erbium
Thulium
Ytterbium
Lutetium
Hafnium
Tantalum
Tungsten
Rhenium
Osmium
Iridium
Platinum
Gold
Mercury
Thallium
Lead
Bismuth
Polonium
Astatine
Radon
Francium
Radium
Actinium
Thorium
Protactinium
Uranium
Neptunium
Plutonium
Americium
Curium
Berkelium
Californium
Einsteinium
Fermium
Mendelevium
Nobelium
Lawrencium
Rutherfordium
Dubnium
Seaborgium
Bohrium
Hassium
Meitnerium
Darmstadtium
Roentgenium
Copernicium
Nihonium
Flerovium
Moscovium
Livermorium
Tennessine
Oganesson
Pro-Gly
Ala-Gln
Glu-Phe
Phe-Cys
Gly-Gly
Arg-Arg
Gly-Pro-NH-Np
Gly-Arg-pNA
Gly-Phe-pNA
Arg-Arg-4-methoxy-b-naphthylamide
Angiotensins I
Angiotensins II
L-Cysteine, L-prolyl-
Cystine
Pro-Hyp
Ala-Hyp-Gly
Leu-Hyp-Gly
Hyp-Gly
L-prolyl-L-cysteine
DL-prolyl-DL-cysteine
H-Pro-Cys-OH
H-DL-Pro-DL-Cys-OH
PC Dipeptide
P-C Dipeptide
Proline Cysteine dipeptide
L-Cysteine, L-prolyl-
Prolylcysteine
Prolyl-cysteine
L-Prolyl-L-Cysteine
121491-14-3
L-Cysteine, L-prolyl-
Pro-Cys
Prolyl-cysteine
PC dipeptide
P-C Dipeptide
Proline Cysteine dipeptide
DL-prolyl-DL-cysteine
H-DL-Pro-DL-Cys-OH
L-Prolyl-L-Cysteine
C8H14N2O3S
Cysteine-containing peptide dimer
DNA
RNA
Polypeptide
Peptide
Protein
Cell membrane
Phospholipids
Lipid bilayers
HepG2 cells
C57BL/6J mice
HEK293 cells
HIF-1
JAK2
STAT5
PepT1
IGF-1
Foxg1
Runx2
Osteoblast
Mesenchymal stem cells
Brown adipocytes
C3H10T1/2 cells
PGC-1α
C/EBPα
PPARγ
UCP-1
ACC1
FASN
MitoTracker
DAPI
EGFR
EGF
ROS
H2O2
PTPN1
PTPRK
Pin1
pSer/Thr-Pro
MDA-MB-231 cells
Tau
APP
AD
Cyclophilin D
Mitochondrial PTP
CYSL-1
EGL-9
RHY-1
CDO-1
CTH-2
CTH
Glutathione
Iron-sulfur cluster
Endoplasmic reticulum
Hormones
Neuropeptides
Trypsin
Elastase
Thrombin
Cathepsins K and G
Caspase 3
Caspase 7
HIV protease 1
Matrix metalloproteinase 2
GluC protease
ProAlanase
Clarity Ferm AnPEP
Proline-7-amido-4-methylcoumarin (Pro-AMC)
Pro-2-naphthylamide
Pro-p-nitroanilide
Gly-Pro-pNA
Ala-Pro-pNA
Gly-Arg-pNA
Gly-Arg-MNA
Arg-Arg-4-methoxy-b-naphthylamide
Z-Ala-Ala-Pro-pNA
FFA
Fmoc-Pro-OH
Fmoc-D-Pro-OH
HBTU/DIEA
H-Pro-Cys-OH
H-DL-Pro-DL-Cys-OH
PC Dipeptide
P-C Dipeptide
Proline Cysteine dipeptide
L-Cysteine, L-prolyl-
Prolylcysteine
Prolyl-cysteine
L-Prolyl-L-Cysteine
C8H14N2O3S
Cystine peptide dimer (Lys-Gly-Val-Cys-Val-N2H2Dns)2
DNA
RNA
Polypeptide
Peptide
Protein
Cell membrane
Phospholipids
Lipid bilayers
HepG2 cells
C57BL/6J mice
HEK293 cells
HIF-1
JAK2
STAT5
PepT1
IGF-1
Foxg1
Runx2
Osteoblast
Mesenchymal stem cells
Brown adipocytes
C3H10T1/2 cells
PGC-1α
C/EBPα
PPARγ
UCP-1
ACC1
FASN
MitoTracker
DAPI
EGFR
EGF
ROS
H2O2
PTPN1
PTPRK
Pin1
pSer/Thr-Pro
MDA-MB-231 cells
Tau
APP
AD
Cyclophilin D
Mitochondrial PTP
CYSL-1
EGL-9
RHY-1
CDO-1
CTH-2
CTH
Glutathione
Iron-sulfur cluster
Endoplasmic reticulum
Hormones
Neuropeptides
Trypsin
Elastase
Thrombin
Cathepsins K and G
Caspase 3
Caspase 7
HIV protease 1
Matrix metalloproteinase 2
GluC protease
ProAlanase
Clarity Ferm AnPEP
Proline-7-amido-4-methylcoumarin (Pro-AMC)
Pro-2-naphthylamide
Pro-p-nitroanilide
Gly-Pro-pNA
Ala-Pro-pNA
Gly-Arg-pNA
Gly-Arg-MNA
Arg-Arg-4-methoxy-b-naphthylamide
Z-Ala-Ala-Pro-pNA
FFA
Fmoc-Pro-OH
Fmoc-D-Pro-OH
HBTU/DIEA
L-Captopril
Noopept
Heparin
Heparan sulfate proteoglycans
Insulin
Oxytocin
Ziconotide
Brentuximab vedotin
Collagen
Fibronectin
Laminin
Fibulin
Integrin
Amanitins
Glucagon-like peptide 1 (GLP1)
Angiotensin I
Angiotensin II
Bradykinin
Hypoxia-inducible factor 1 (HIF-1)
Epidermal growth factor receptor (EGFR)
Peptidyl-prolyl cis-trans isomerase NIMA-interacting 1 (Pin1)
Forkhead Transcription Factors
Foxg1 protein, mouse
Nerve Tissue Proteins
Core Binding Factor Alpha 1 Subunit
Prolyl-4-hydroxyproline (Pro-Hyp)
Cystathionine
GABA
Glutathione
Dipeptidyl peptidase 4 (DPP4)
Dipeptidyl peptidase II (DPPII)
Dipeptidyl peptidase 7 (DPP7)
Dipeptidyl peptidase 8 (DPP8)
Dipeptidyl peptidase 9 (DPP9)
Fibroblast activation protein
Prolyl endopeptidase (PEP)
Prolyl endopeptidase-like
Prolyl oligopeptidase (POP)
Prolyl tripeptidyl aminopeptidase
Prolyl carboxypeptidase (PRCP)
Prolyl hydroxylase domain 2 (PHD2)
Cysteine dioxygenase (CDO-1)
Cystathionase (CTH)
Threonyl-tRNA synthetase
Tosyl-L-Lys-chloromethyl ketone
Leupeptin
Chymostatin
Methyl group
Thiolactone
Diketopiperazine (DKP)
Thioester
Thiohydroximate
Nitrile oxide
Isoxazole
4,5-dihydrothiazole
Chlorooxime
Palmitic Acid
Biotin
Dansyl
7-methoxycoumarin acetic acid
Fluorescein
2,4-Dinitrophenyl
TMTr
Tmob
Trt
Fmoc-aaa-Cys(ΨR,R′pro)-OH
Cys(ΨH,Dmppro)
Cys(ΨMe,Mepro)
Thz
Cys(CAM)
Phosphorylation
Isotope labeled Amino Acids
Spacers
Nitrogen
Oxygen
Sulfur
Carbon
Hydrogen
Zinc
Copper
Iron
Titanium
Chlorine
Sodium
Potassium
Magnesium
Calcium
Phosphorus
Silicon
Aluminum
Boron
Strontium
Vanadium
Chromium
Manganese
Cobalt
Nickel
Gallium
Germanium
Arsenic
Selenium
Bromine
Rubidium
Yttrium
Zirconium
Niobium
Molybdenum
Ruthenium
Rhodium
Palladium
Silver
Cadmium
Indium
Tin
Antimony
Tellurium
Iodine
Cesium
Barium
Lanthanum
Cerium
Praseodymium
Neodymium
Promethium
Samarium
Europium
Gadolinium
Terbium
Dysprosium
Holmium
Erbium
Thulium
Ytterbium
Lutetium
Hafnium
Tantalum
Tungsten
Rhenium
Osmium
Iridium
Platinum
Gold
Mercury
Thallium
Lead
Bismuth
Polonium
Astatine
Radon
Francium
Radium
Actinium
Thorium
Protactinium
Uranium
Neptunium
Plutonium
Americium
Curium
Californium
Einsteinium
Fermium
Mendelevium
Nobelium
Lawrencium
Rutherfordium
Dubnium
Seaborgium
Bohrium
Hassium
Meitnerium
Darmstadtium
Roentgenium
Copernicium
Nihonium
Flerovium
Moscovium
Livermorium
Tennessine
Oganesson
Helium
Neon
Argon
Krypton
Xenon
Radon
Oganesson
Lithium
Beryllium
Sodium
Magnesium
Aluminum
Silicon
Phosphorus
Sulfur
Chlorine
Potassium
Calcium
Scandium
Titanium
Vanadium
Chromium
Manganese
Iron
Cobalt
Nickel
Copper
Zinc
Gallium
Germanium
Arsenic
Selenium
Bromine
Rubidium
Strontium
Yttrium
Zirconium
Niobium
Molybdenum
Ruthenium
Rhodium
Palladium
Silver
Cadmium
Indium
Tin
Antimony
Tellurium
Iodine
Cesium
Barium
Lanthanum
Cerium
Praseodymium
Neodymium
Promethium
Samarium
Europium
Gadolinium
Terbium
Dysprosium
Holmium
Erbium
Thulium
Ytterbium
Lutetium
Hafnium
Tantalum
Tungsten
Rhenium
Osmium
Iridium
Platinum
Gold
Mercury
Thallium
Lead
Bismuth
Polonium
Astatine
Francium
Radium
Actinium
Thorium
Protactinium
Uranium
Neptunium
Plutonium
Americium
Curium
Berkelium
Californium
Einsteinium
Fermium
Mendelevium
Nobelium
Lawrencium
Rutherfordium
Dubnium
Seaborgium
Bohrium
Hassium
Meitnerium
Darmstadtium
Roentgenium
Copernicium
Nihonium
Flerovium
Moscovium
Livermorium
Tennessine
Oganesson
Pro-Gly
Ala-Gln
Glu-Phe
Phe-Cys
Gly-Gly
Arg-Arg
Gly-Pro-NH-Np
Gly-Arg-pNA
Gly-Phe-pNA
Arg-Arg-4-methoxy-b-naphthylamide
Angiotensins I
Angiotensins II
Bradykinin
Hypoxia-inducible factor 1 (HIF-1)
Epidermal growth factor receptor (EGFR)
Peptidyl-prolyl cis-trans isomerase NIMA-interacting 1 (Pin1)
Forkhead Transcription Factors
Foxg1 protein, mouse
Nerve Tissue Proteins
Core Binding Factor Alpha 1 Subunit
Prolyl-4-hydroxyproline (Pro-Hyp)
Cystathionine
GABA
Glutathione
Dipeptidyl peptidase 4 (DPP4)
Dipeptidyl peptidase II (DPPII)
Dipeptidyl peptidase 7 (DPP7)
Dipeptidyl peptidase 8 (DPP8)
Dipeptidyl peptidase 9 (DPP9)
Fibroblast activation protein
Prolyl endopeptidase (PEP)
Prolyl endopeptidase-like
Prolyl oligopeptidase (POP)
Prolyl tripeptidyl aminopeptidase
Prolyl carboxypeptidase (PRCP)
Prolyl hydroxylase domain 2 (PHD2)
Cysteine dioxygenase (CDO-1)
Cystathionase (CTH)
Threonyl-tRNA synthetase
Tosyl-L-Lys-chloromethyl ketone
Leupeptin
Chymostatin
Methyl group
Thiolactone
Diketopiperazine (DKP)
Thioester
Thiohydroximate
Nitrile oxide
Isoxazole
4,5-dihydrothiazole
Chlorooxime
Palmitic Acid
Biotin
Dansyl
7-methoxycoumarin acetic acid
Fluorescein
2,4-Dinitrophenyl
TMTr
Tmob
Trt
Fmoc-aaa-Cys(ΨR,R′pro)-OH
Cys(ΨH,Dmppro)
Cys(ΨMe,Mepro)
Thz
Cys(CAM)
Phosphorylation
Isotope labeled Amino Acids
Spacers
Nitrogen
Oxygen
Sulfur
Carbon
Hydrogen
Zinc
Copper
Iron
Titanium
Chlorine
Sodium
Potassium
Magnesium
Calcium
Phosphorus
Silicon
Aluminum
Boron
Strontium
Vanadium
Chromium
Manganese
Cobalt
Nickel
Gallium
Germanium
Arsenic
Selenium
Bromine
Rubidium
Yttrium
Zirconium
Niobium
Molybdenum
Ruthenium
Rhodium
Palladium
Silver
Cadmium
Indium
Tin
Antimony
Tellurium
Iodine
Cesium
Barium
Lanthanum
Cerium
Praseodymium
Neodymium
Promethium
Samarium
Europium
Gadolinium
Terbium
Dysprosium
Holmium
Erbium
Thulium
Ytterbium
Lutetium
Hafnium
Tantalum
Tungsten
Rhenium
Osmium
Iridium
Platinum
Gold
Mercury
Thallium
Lead
Bismuth
Polonium
Astatine
Radon
Francium
Radium
Actinium
Thorium
Protactinium
Uranium
Neptunium
Plutonium
Americium
Curium
Berkelium
Californium
Einsteinium
Fermium
Mendelevium
Nobelium
Lawrencium
Rutherfordium
Dubnium
Seaborgium
Bohrium
Hassium
Meitnerium
Darmstadtium
Roentgenium
Copernicium
Nihonium
Flerovium
Moscovium
Livermorium
Tennessine
Oganesson
Helium
Neon
Argon
Krypton
Xenon
Radon
Oganesson
Lithium
Beryllium
Sodium
Magnesium
Aluminum
Silicon
Phosphorus
Sulfur
Chlorine
Potassium
Calcium
Scandium
Titanium
Vanadium
Chromium
Manganese
Iron
Cobalt
Nickel
Copper
Zinc
Gallium
Germanium
Arsenic
Selenium
Bromine
Rubidium
Strontium
Yttrium
Zirconium
Niobium
Molybdenum
Ruthenium
Rhodium
Palladium
Silver
Cadmium
Indium
Tin
Antimony
Tellurium
Iodine
Cesium
Barium
Lanthanum
Cerium
Praseodymium
Neodymium
Promethium
Samarium
Europium
Gadolinium
Terbium
Dysprosium
Holmium
Erbium
Thulium
Ytterbium
Lutetium
Hafnium
Tantalum
Tungsten
Rhenium
Osmium
Iridium
Platinum
Gold
Mercury
Thallium
Lead
Bismuth
Polonium
Astatine
Francium
Radium
Actinium
Thorium
Protactinium
Uranium
Neptunium
Plutonium
Americium
Curium
Berkelium
Californium
Einsteinium
Fermium
Mendelevium
Nobelium
Lawrencium
Rutherfordium
Dubnium
Seaborgium
Bohrium
Hassium
Meitnerium
Darmstadtium
Roentgenium
Copernicium
Nihonium
Flerovium
Moscovium
Livermorium
Tennessine
Oganesson
Pro-Gly
Ala-Gln
Glu-Phe
Phe-Cys
Gly-Gly
Arg-Arg
Gly-Pro-NH-Np
Gly-Arg-pNA
Gly-Phe-pNA
Arg-Arg-4-methoxy-b-naphthylamide
Angiotensins I
Angiotensins II
Bradykinin
Hypoxia-inducible factor 1 (HIF-1)
Epidermal growth factor receptor (EGFR)
Peptidyl-prolyl cis-trans isomerase NIMA-interacting 1 (Pin1)
Forkhead Transcription Factors
Foxg1 protein, mouse
Nerve Tissue Proteins
Core Binding Factor Alpha 1 Subunit
Prolyl-4-hydroxyproline (Pro-Hyp)
Cystathionine
GABA
Glutathione
Dipeptidyl peptidase 4 (DPP4)
Dipeptidyl peptidase II (DPPII)
Dipeptidyl peptidase 7 (DPP7)
Dipeptidyl peptidase 8 (DPP8)
Dipeptidyl peptidase 9 (DPP9)
Fibroblast activation protein
Prolyl endopeptidase (PEP)
Prolyl endopeptidase-like
Prolyl oligopeptidase (POP)
Prolyl tripeptidyl aminopeptidase
Prolyl carboxypeptidase (PRCP)
Prolyl hydroxylase domain 2 (PHD2)
Cysteine dioxygenase (CDO-1)
Cystathionase (CTH)
Threonyl-tRNA synthetase
Tosyl-L-Lys-chloromethyl ketone
Leupeptin
Chymostatin
Methyl group
Thiolactone
Diketopiperazine (DKP)
Thioester
Thiohydroximate
Nitrile oxide
Isoxazole
4,5-dihydrothiazole
Chlorooxime
Palmitic Acid
Biotin
Dansyl
7-methoxycoumarin acetic acid
Fluorescein
2,4-Dinitrophenyl
TMTr
Tmob
Trt
Fmoc-aaa-Cys(ΨR,R′pro)-OH
Cys(ΨH,Dmppro)
Cys(ΨMe,Mepro)
Thz
Cys(CAM)
Phosphorylation
Isotope labeled Amino Acids
Spacers
Nitrogen
Oxygen
Sulfur
Carbon
Hydrogen
Zinc
Copper
Iron
Titanium
Chlorine
Sodium
Potassium
Magnesium
Calcium
Phosphorus
Silicon
Aluminum
Boron
Strontium
Vanadium
Chromium
Manganese
Cobalt
Nickel
Gallium
Germanium
Arsenic
Selenium
Bromine
Rubidium
Yttrium
Zirconium
Niobium
Molybdenum
Ruthenium
Rhodium
Palladium
Silver
Cadmium
Indium
Tin
Antimony
Tellurium
Iodine
Cesium
Barium
Lanthanum
Cerium
Praseodymium
Neodymium
Promethium
Samarium
Europium
Gadolinium
Terbium
Dysprosium
Holmium
Erbium
Thulium
Ytterbium
Lutetium
Hafnium
Tantalum
Tungsten
Rhenium
Osmium
Iridium
Platinum
Gold
Mercury
Thallium
Lead
Bismuth
Polonium
Astatine
Radon
Francium
Radium
Actinium
Thorium
Protactinium
Uranium
Neptunium
Plutonium
Americium
Curium
Berkelium
Californium
Einsteinium
Fermium
Mendelevium
Nobelium
Lawrencium
Rutherfordium
Dubnium
Seaborgium
Bohrium
Hassium
Meitnerium
Darmstadtium
Roentgenium
Copernicium
Nihonium
Flerovium
Moscovium
Livermorium
Tennessine
Oganesson
Helium
Neon
Argon
Krypton
Xenon
Radon
Oganesson
Lithium
Beryllium
Sodium
Magnesium
Aluminum
Silicon
Phosphorus
Sulfur
Chlorine
Potassium
Calcium
Scandium
Titanium
Vanadium
Chromium
Manganese
Iron
Cobalt
Nickel
Copper
Zinc
Gallium
Germanium
Arsenic
Selenium
Bromine
Rubidium
Strontium
Yttrium
Zirconium
Niobium
Molybdenum
Ruthenium
Rhodium
Palladium
Silver
Cadmium
Indium
Tin
Antimony
Tellurium
Iodine
Cesium
Barium
Lanthanum
Cerium
Praseodymium
Neodymium
Promethium
Samarium
Europium
Gadolinium
Terbium
Dysprosium
Holmium
Erbium
Thulium
Ytterbium
Lutetium
Hafnium
Tantalum
Tungsten
Rhenium
Osmium
Iridium
Platinum
Gold
Mercury
Thallium
Lead
Bismuth
Polonium
Astatine
Francium
Radium
Actinium
Thorium
Protactinium
Uranium
Neptunium
Plutonium
Americium
Curium
Berkelium
Californium
Einsteinium
Fermium
Mendelevium
Nobelium
Lawrencium
Rutherfordium
Dubnium
Seaborgium
Bohrium
Hassium
Meitnerium
Darmstadtium
Roentgenium
Copernicium
Nihonium
Flerovium
Moscovium
Livermorium
Tennessine
Oganesson
Pro-Gly
Ala-Gln
Glu-Phe
Phe-Cys
Gly-Gly
Arg-Arg
Gly-Pro-NH-Np
Gly-Arg-pNA
Gly-Phe-pNA
Arg-Arg-4-methoxy-b-naphthylamide
Angiotensins I
Angiotensins II
Bradykinin
Hypoxia-inducible factor 1 (HIF-1)
Epidermal growth factor receptor (EGFR)
Peptidyl-prolyl cis-trans isomerase NIMA-interacting 1 (Pin1)
Forkhead Transcription Factors
Foxg1 protein, mouse
Nerve Tissue Proteins
Core Binding Factor Alpha 1 Subunit
Prolyl-4-hydroxyproline (Pro-Hyp)
Cystathionine
GABA
Glutathione
Dipeptidyl peptidase 4 (DPP4)
Dipeptidyl peptidase II (DPPII)
Dipeptidyl peptidase 7 (DPP7)
Dipeptidyl peptidase 8 (DPP8)
Dipeptidyl peptidase 9 (DPP9)
Fibroblast activation protein
Prolyl endopeptidase (PEP)
Prolyl endopeptidase-like
Prolyl oligopeptidase (POP)
Prolyl tripeptidyl aminopeptidase
Prolyl carboxypeptidase (PRCP)
Prolyl hydroxylase domain 2 (PHD2)
Cysteine dioxygenase (CDO-1)
Cystathionase (CTH)
Threonyl-tRNA synthetase
Tosyl-L-Lys-chloromethyl ketone
Leupeptin
Chymostatin
Methyl group
Thiolactone
Diketopiperazine (DKP)
Thioester
Thiohydroximate
Nitrile oxide
Isoxazole
4,5-dihydrothiazole
Chlorooxime
Palmitic Acid
Biotin
Dansyl
7-methoxycoumarin acetic acid
Fluorescein
2,4-Dinitrophenyl
TMTr
Tmob
Trt
Fmoc-aaa-Cys(ΨR,R′pro)-OH
Cys(ΨH,Dmppro)
Cys(ΨMe,Mepro)
Thz
Cys(CAM)
Phosphorylation
Isotope labeled Amino Acids
Spacers
Nitrogen
Oxygen
Sulfur
Carbon
Hydrogen
Zinc
Copper
Iron
Titanium
Chlorine
Sodium
Potassium
Magnesium
Calcium
Phosphorus
Silicon
Aluminum
Boron
Strontium
Vanadium
Chromium
Manganese
Cobalt
Nickel
Gallium
Germanium
Arsenic
Selenium
Bromine
Rubidium
Yttrium
Zirconium
Niobium
Molybdenum
Ruthenium
Rhodium
Palladium
Silver
Cadmium
Indium
Tin
Antimony
Tellurium
Iodine
Cesium
Barium
Lanthanum
Cerium
Praseodymium
Neodymium
Promethium
Samarium
Europium
Gadolinium
Terbium
Dysprosium
Holmium
Erbium
Thulium
Ytterbium
Lutetium
Hafnium
Tantalum
Tungsten
Rhenium
Osmium
Iridium
Platinum
Gold
Mercury
Thallium
Lead
Bismuth
Polonium
Astatine
Radon
Francium
Radium
Actinium
Thorium
Protactinium
Uranium
Neptunium
Plutonium
Americium
Curium
Berkelium
Californium
Einsteinium
Fermium
Mendelevium
Nobelium
Lawrencium
Rutherfordium
Dubnium
Seaborgium
Bohrium
Hassium
Meitnerium
Darmstadtium
Roentgenium
Copernicium
Nihonium
Flerovium
Moscovium
Livermorium
Tennessine
Oganesson
Helium
Neon
Argon
Krypton
Xenon
Radon
Oganesson
Lithium
Beryllium
Sodium
Magnesium
Aluminum
Silicon
Phosphorus
Sulfur
Chlorine
Potassium
Calcium
Scandium
Titanium
Vanadium
Chromium
Manganese
Iron
Cobalt
Nickel
Copper
Zinc
Gallium
Germanium
Arsenic
Selenium
Bromine
Rubidium
Strontium
Yttrium
Zirconium
Niobium
Molybdenum
Ruthenium
Rhodium
Palladium
Silver
Cadmium
Indium
Tin
Antimony
Tellurium
Iodine
Cesium
Barium
Lanthanum
Cerium
Praseodymium
Neodymium
Promethium
Samarium
Europium
Gadolinium
Terbium
Dysprosium
Holmium
Erbium
Thulium
Ytterbium
Lutetium
Hafnium
Tantalum
Tungsten
Rhenium
Osmium
Iridium
Platinum
Gold
Mercury
Thallium
Lead
Bismuth
Polonium
Astatine
Francium
Radium
Actinium
Thorium
Protactinium
Uranium
Neptunium
Plutonium
Americium
Curium
Berkelium
Californium
Einsteinium
Fermium
Mendelevium
Nobelium
Lawrencium
Rutherfordium
Dubnium
Seaborgium
Bohrium
Hassium
Meitnerium
Darmstadtium
Roentgenium
Copernicium
Nihonium
Flerovium
Moscovium
Livermorium
Tennessine
Oganesson
Pro-Gly
Ala-Gln
Glu-Phe
Phe-Cys
Gly-Gly
Arg-Arg
Gly-Pro-NH-Np
Gly-Arg-pNA
Gly-Phe-pNA
Arg-Arg-4-methoxy-b-naphthylamide
Angiotensins I
Angiotensins II
Bradykinin
Hypoxia-inducible factor 1 (HIF-1)
Epidermal growth factor receptor (EGFR)
Peptidyl-prolyl cis-trans isomerase NIMA-interacting 1 (Pin1)
Forkhead Transcription Factors
Foxg1 protein, mouse
Nerve Tissue Proteins
Core Binding Factor Alpha 1 Subunit
Prolyl-4-hydroxyproline (Pro-Hyp)
Cystathionine
GABA
Glutathione
Dipeptidyl peptidase 4 (DPP4)
Dipeptidyl peptidase II (DPPII)
Dipeptidyl peptidase 7 (DPP7)
Dipeptidyl peptidase 8 (DPP8)
Dipeptidyl peptidase 9 (DPP9)
Fibroblast activation protein
Prolyl endopeptidase (PEP)
Prolyl endopeptidase-like
Prolyl oligopeptidase (POP)
Prolyl tripeptidyl aminopeptidase
Prolyl carboxypeptidase (PRCP)
Prolyl hydroxylase domain 2 (PHD2)
Cysteine dioxygenase (CDO-1)
Cystathionase (CTH)
Threonyl-tRNA synthetase
Tosyl-L-Lys-chloromethyl ketone
Leupeptin
Chymostatin
Methyl group
Thiolactone
Diketopiperazine (DKP)
Thioester
Thiohydroximate
Nitrile oxide
Isoxazole
4,5-dihydrothiazole
Chlorooxime
Palmitic Acid
Biotin
Dansyl
7-methoxycoumarin acetic acid
Fluorescein
2,4-Dinitrophenyl
TMTr
Tmob
Trt
Fmoc-aaa-Cys(ΨR,R′pro)-OH
Cys(ΨH,Dmppro)
Cys(ΨMe,Mepro)
Thz
Cys(CAM)
Phosphorylation
Isotope labeled Amino Acids
Spacers
Nitrogen
Oxygen
Sulfur
Carbon
Hydrogen
Zinc
Copper
Iron
Titanium
Chlorine
Sodium
Potassium
Magnesium
Calcium
Phosphorus
Silicon
Aluminum
Boron
Strontium
Vanadium
Chromium
Manganese
Cobalt
Nickel
Gallium
Germanium
Arsenic
Selenium
Bromine
Rubidium
Yttrium
Zirconium
Niobium
Molybdenum
Ruthenium
Rhodium
Palladium
Silver
Cadmium
Indium
Tin
Antimony
Tellurium
Iodine
Cesium
Barium
Lanthanum
Cerium
Praseodymium
Neodymium
Promethium
Samarium
Europium
Gadolinium
Terbium
Dysprosium
Holmium
Erbium
Thulium
Ytterbium
Lutetium
Hafnium
Tantalum
Tungsten
Rhenium
Osmium
Iridium
Platinum
Gold
Mercury
Thallium
Lead
Bismuth
Polonium
Astatine
Radon
Francium
Radium
Actinium
Thorium
Protactinium
Uranium
Neptunium
Plutonium
Americium
Curium
Berkelium
Californium
Einsteinium
Fermium
Mendelevium
Nobelium
Lawrencium
Rutherfordium
Dubnium
Seaborgium
Bohrium
Hassium
Meitnerium
Darmstadtium
Roentgenium
Copernicium
Nihonium
Flerovium
Moscovium
Livermorium
Tennessine
Oganesson
Helium
Neon
Argon
Krypton
Xenon
Radon
Oganesson
Lithium
Beryllium
Sodium
Magnesium
Aluminum
Silicon
Phosphorus
Sulfur
Chlorine
Potassium
Calcium
Scandium
Titanium
Vanadium
Chromium
Manganese
Iron
Cobalt
Nickel
Copper
Zinc
Gallium
Germanium
Arsenic
Selenium
Bromine
Rubidium
Strontium
Yttrium
Zirconium
Niobium
Molybdenum
Ruthenium
Rhodium
Palladium
Silver
Cadmium
Indium
Tin
Antimony
Tellurium
Iodine
Cesium
Barium
Lanthanum
Cerium
Praseodymium
Neodymium
Promethium
Samarium
Europium
Gadolinium
Terbium
Dysprosium
Holmium
Erbium
Thulium
Ytterbium
Lutetium
Hafnium
Tantalum
Tungsten
Rhenium
Osmium
Iridium
Platinum
Gold
Mercury
Thallium
Lead
Bismuth
Polonium
Astatine
Francium
Radium
Actinium
Thorium
Protactinium
Uranium
Neptunium
Plutonium
Americium
Curium
Berkelium
Californium
Einsteinium
Fermium
Mendelevium
Nobelium
Lawrencium
Rutherfordium
Dubnium
Seaborgium
Bohrium
Hassium
Meitnerium
Darmstadtium
Roentgenium
Copernicium
Nihonium
Flerovium
Moscovium
Livermorium
Tennessine
Oganesson
Pro-Gly
Ala-Gln
Glu-Phe
Phe-Cys
Gly-Gly
Arg-Arg
Gly-Pro-NH-Np
Gly-Arg-pNA
Gly-Phe-pNA
Arg-Arg-4-methoxy-b-naphthylamide
Angiotensins I
Angiotensins II
Bradykinin
Hypoxia-inducible factor 1 (HIF-1)
Epidermal growth factor receptor (EGFR)
Peptidyl-prolyl cis-trans isomerase NIMA-interacting 1 (Pin1)
Forkhead Transcription Factors
Foxg1 protein, mouse
Nerve Tissue Proteins
Core Binding Factor Alpha 1 Subunit
Prolyl-4-hydroxyproline (Pro-Hyp)
Cystathionine
GABA
Glutathione
Dipeptidyl peptidase 4 (DPP4)
Dipeptidyl peptidase II (DPPII)
Dipeptidyl peptidase 7 (DPP7)
Dipeptidyl peptidase 8 (DPP8)
Dipeptidyl peptidase 9 (DPP9)
Fibroblast activation protein
Prolyl endopeptidase (PEP)
Prolyl endopeptidase-like
Prolyl oligopeptidase (POP)
Prolyl tripeptidyl aminopeptidase
Prolyl carboxypeptidase (PRCP)
Prolyl hydroxylase domain 2 (PHD2)
Cysteine dioxygenase (CDO-1)
Cystathionase (CTH)
Threonyl-tRNA synthetase
Tosyl-L-Lys-chloromethyl ketone
Leupeptin
Chymostatin
Methyl group
Thiolactone
Diketopiperazine (DKP)
Thioester
Thiohydroximate
Nitrile oxide
Isoxazole
4,5-dihydrothiazole
Chlorooxime
Palmitic Acid
Biotin
Dansyl
7-methoxycoumarin acetic acid
Fluorescein
2,4-Dinitrophenyl
TMTr
Tmob
Trt
Fmoc-aaa-Cys(ΨR,R′pro)-OH
Cys(ΨH,Dmppro)
Cys(ΨMe,Mepro)
Thz
Cys(CAM)
Phosphorylation
Isotope labeled Amino Acids
Spacers
Biological Significance and Physiological Roles of Prolyl Cysteine in Model Systems
Regulatory Functions of Prolyl-cysteine in Cellular Signaling Cascades (e.g., enzyme activation/inhibition, pathway modulation)
Phosphorylation and Dephosphorylation Events
Modulation of Protein-Protein Interactions
The prolyl-cysteine motif has been identified within larger peptide structures that play roles in protein-protein interactions. For instance, cyclic peptides containing cysteine-proline sequences have been synthesized and investigated for their biological activities, suggesting that such motifs can contribute to the structural integrity and interaction capabilities of these molecules.
One notable example is the peptide Cysteinyl-leucyl-glutamyl-glutamyl-prolyl-cysteine cyclic disulfide (CLGGPC-CD) . This peptide, characterized by its cyclic structure stabilized by a disulfide bond, has been explored for potential antioxidant and anti-inflammatory properties. The cyclic nature, facilitated by the cysteine residues and potentially influenced by the proline residue's conformational effects, contributes to the peptide's stability and its capacity to interact with biological targets ontosight.ai. Similarly, cyclic RGD peptides incorporating a cysteinyl-prolyl-cysteine sequence have been synthesized, indicating that these motifs can be integral to peptides that mediate interactions, such as those involving integrins peptide-soc.jp. These findings suggest that the prolyl-cysteine sequence, when part of a larger peptide structure, can influence molecular recognition and binding events.
Prolyl-cysteine in Stress Response Pathways in Organismal Models
Information regarding the specific role of prolyl-cysteine in stress response pathways within model organisms such as C. elegans, Drosophila, or rodent in vivo studies is limited. However, its detection as a metabolite in various biological contexts provides indirect clues.
Studies investigating the effects of dietary supplements like α-lipoic acid (α-LA) have detected prolyl-cysteine as a metabolite in urine samples from both humans and animals mountainscholar.orgnih.gov. α-LA is known for its antioxidant properties and its ability to restore oxidative balance by enhancing antioxidant defenses. While prolyl-cysteine was present in these studies, its direct contribution to the organism's response to oxidative stress has not been elucidated. Glutathione (B108866), a tripeptide containing cysteine, is a well-established key molecule in cellular detoxification and protection against reactive oxygen species au.dkau.dk. This highlights the general importance of cysteine in antioxidant defense, but does not specifically implicate prolyl-cysteine.
Direct research detailing prolyl-cysteine's role in adaptations to environmental toxins in animal models is not evident in the current literature. While cysteine-containing molecules like glutathione play a significant role in detoxification pathways, a specific function for the prolyl-cysteine dipeptide in xenobiotic metabolism or adaptation to environmental insults has not been established.
Prolyl-cysteine as a Potential Biosignal or Communication Molecule
The potential of prolyl-cysteine to act as a biosignal or communication molecule is suggested by general observations about dipeptides and its presence in biologically active peptides. Some dipeptides are known to possess physiological or cell-signaling effects hmdb.ca. Furthermore, the prolyl-cysteine motif is present in peptides that exhibit potential biological activities, such as the cyclic peptide CLGGPC-CD, which has been explored for antioxidant and anti-inflammatory properties ontosight.ai. The ACE inhibitor Captopril, known for its role in regulating the renin-angiotensin system, is also noted as an analog of prolyl-cysteine mit.edu. This analogy suggests a potential link to signaling pathways, although it is not a direct demonstration of prolyl-cysteine's own signaling capacity.
Data Tables
Table 1: Detection of Prolyl-Cysteine as a Metabolite in Biological Samples
| Metabolite Name | Detected In | Study Context | P-value (if available) | Reference |
| Prolyl-Cysteine | Urine (Pigs) | Metabolomics study in miniature Yucatan pigs; down-regulated in cloned animals | P < 0.05 (for related changes) | au.dkau.dk |
| Prolyl-Cysteine | Urine (Humans) | Metabolomics study of α-lipoic acid/eicosapentaenoic acid supplementation | Not specified | mountainscholar.orgnih.gov |
| Prolyl-Cysteine | Putative | Identified in metabolomics analysis of beer ingredients (barley) | P < 0.05 | mountainscholar.org |
Table 2: Prolyl-Cysteine Motifs in Biologically Active Peptides
| Peptide Name/Sequence | Associated Biological Activity | Role of Prolyl-Cysteine Motif | Reference |
| Cysteinyl-leucyl-glutamyl-glutamyl-prolyl-cysteine cyclic disulfide (CLGGPC-CD) | Potential antioxidant, anti-inflammatory properties | Contributes to cyclic structure and stability | ontosight.ai |
| Cyclic RGD peptides with cysteinyl prolyl cysteine sequence | Involved in interactions (e.g., integrin binding) | Structural component influencing activity | peptide-soc.jp |
Compound List
Prolyl-cysteine
Cysteine
Proline
Glutathione
Captopril
Cysteinyl-leucyl-glutamyl-glutamyl-prolyl-cysteine cyclic disulfide (CLGGPC-CD)
Advanced Analytical Methodologies for Prolyl Cysteine Quantification and Detection
High-Resolution Mass Spectrometry (HRMS) for Prolyl-cysteine Metabolomics and Proteomics
High-Resolution Mass Spectrometry (HRMS) stands as a powerful tool for the analysis of small molecules like prolyl-cysteine due to its exceptional mass accuracy and resolving power. These features enable the confident identification and differentiation of analytes from complex biological matrices.
Targeted and Untargeted Approaches for Prolyl-cysteine Detection
Untargeted Metabolomics: In an untargeted approach, HRMS is employed to screen a biological sample for all detectable metabolites without a preconceived list of targets. This discovery-phase methodology could potentially identify prolyl-cysteine in samples where its presence is unknown. The process involves acquiring high-resolution mass spectra of the sample and then retrospectively analyzing the data to identify features corresponding to the accurate mass of prolyl-cysteine. While powerful for discovery, this approach is generally less sensitive than targeted methods.
Targeted Metabolomics: A targeted approach focuses specifically on the detection and quantification of known compounds, in this case, prolyl-cysteine. This method offers higher sensitivity and selectivity. It involves optimizing the mass spectrometer to detect the specific mass-to-charge ratio (m/z) of prolyl-cysteine and its characteristic fragment ions. This targeted analysis is ideal for studies where the presence of prolyl-cysteine is hypothesized, and precise quantification is required.
Isotope Dilution Mass Spectrometry for Absolute Quantification
Isotope dilution mass spectrometry is the gold standard for accurate and precise quantification of molecules in complex mixtures. This technique involves spiking a sample with a known amount of a stable isotope-labeled version of the analyte of interest (e.g., ¹³C- or ¹⁵N-labeled prolyl-cysteine). The isotopically labeled internal standard is chemically identical to the endogenous prolyl-cysteine and will co-elute during chromatographic separation and co-ionize in the mass spectrometer. By measuring the ratio of the signal intensity of the native analyte to the isotopically labeled standard, a precise and accurate concentration can be determined, correcting for any sample loss during preparation and for matrix effects during analysis.
Chromatographic Separation Techniques for Prolyl-cysteine Analysis
Prior to mass spectrometric analysis, chromatographic separation is essential to reduce the complexity of the biological sample and to separate prolyl-cysteine from other isomeric and isobaric compounds.
High-Performance Liquid Chromatography (HPLC) with Various Detection Modes
High-Performance Liquid Chromatography (HPLC) is a cornerstone technique for the separation of peptides and amino acids. For prolyl-cysteine, reversed-phase HPLC (RP-HPLC) would be a common choice, separating molecules based on their hydrophobicity.
| HPLC Column Type | Mobile Phase Example | Detection Mode | Principle |
| Reversed-Phase C18 | Acetonitrile (B52724)/Water with 0.1% Formic Acid | UV-Vis | Detection based on the absorbance of the peptide bond at low UV wavelengths (e.g., 210-220 nm). |
| Reversed-Phase C18 | Acetonitrile/Water with 0.1% Formic Acid | Mass Spectrometry (MS) | Provides high selectivity and sensitivity, allowing for definitive identification and quantification based on mass-to-charge ratio. |
| Hydrophilic Interaction Liquid Chromatography (HILIC) | Acetonitrile/Water with buffer | Fluorescence | Requires derivatization with a fluorescent tag to enhance sensitivity. |
Gas Chromatography-Mass Spectrometry (GC-MS) of Derivatized Prolyl-cysteine
Gas Chromatography-Mass Spectrometry (GC-MS) is a powerful analytical technique, but it requires analytes to be volatile and thermally stable. Dipeptides like prolyl-cysteine are not inherently volatile. Therefore, a crucial step for GC-MS analysis is derivatization. This chemical modification process converts the non-volatile dipeptide into a more volatile and thermally stable compound suitable for GC analysis.
Common derivatization strategies for amino acids and peptides involve esterification of the carboxyl group followed by acylation of the amino and thiol groups. For prolyl-cysteine, this would involve a two-step process to modify its functional groups. The resulting derivative can then be separated by GC and detected by MS. The mass spectrum of the derivatized prolyl-cysteine would provide a unique fragmentation pattern, allowing for its identification.
| Derivatization Reagent | Target Functional Group | Resulting Derivative |
| Methanol (B129727)/HCl | Carboxyl group | Methyl ester |
| Pentafluoropropionic anhydride (B1165640) (PFPA) | Amino and Thiol groups | Pentafluoropropionyl amide and thioester |
Capillary Electrophoresis (CE) for Prolyl-cysteine Separation
Capillary Electrophoresis (CE) is a high-resolution separation technique that separates molecules based on their charge-to-size ratio in a capillary filled with an electrolyte solution. CE offers advantages such as high efficiency, short analysis times, and low sample and reagent consumption.
For the analysis of prolyl-cysteine, different CE modes could be employed:
Capillary Zone Electrophoresis (CZE): This is the simplest form of CE, where ions are separated in a background electrolyte. The separation is based on the different electrophoretic mobilities of the analytes.
Micellar Electrokinetic Chromatography (MEKC): This technique uses surfactants (micelles) in the background electrolyte to separate both charged and neutral molecules. This could be advantageous for separating prolyl-cysteine from other neutral or similarly charged species.
Detection in CE can be achieved using UV-Vis absorbance, typically at low wavelengths for peptides, or by coupling the capillary to a mass spectrometer (CE-MS) for more sensitive and specific detection.
Electrochemical and Biosensor-Based Detection of Prolyl-cysteine
The electrochemical properties of the thiol group in the cysteine residue of prolyl-cysteine allow for direct detection using various electrochemical techniques. These methods are often characterized by high sensitivity, rapid response, and the potential for miniaturization.
Voltammetric Techniques for Thiol Quantification
Voltammetry measures the current response of an electroactive species, such as the thiol group in prolyl-cysteine, to an applied potential. The oxidation of the thiol group at an electrode surface generates a current that is proportional to its concentration. Various voltammetric techniques can be employed for the quantification of thiols, and by extension, prolyl-cysteine.
Cyclic Voltammetry (CV): This technique is often used to characterize the redox properties of thiols. By scanning the potential and observing the resulting current, the oxidation potential of the prolyl-cysteine thiol group can be determined. While primarily a qualitative and diagnostic tool, under certain conditions, the peak current in a cyclic voltammogram can be related to the concentration of the analyte.
Differential Pulse Voltammetry (DPV) and Square-Wave Voltammetry (SWV): These are more sensitive techniques than CV for quantification. They employ potential pulses to discriminate against the background charging current, thereby enhancing the faradaic current from the analyte's redox reaction. This results in well-defined peaks with heights that are directly proportional to the concentration of the thiol compound. These methods offer low detection limits, often in the micromolar (µM) to nanomolar (nM) range. For instance, studies on cysteine have demonstrated detection limits down to 0.14 µM using a palladium nanoparticle-modified electrode khanacademy.org.
Anodic Stripping Voltammetry (ASV): ASV is an extremely sensitive technique for trace analysis. It involves a two-step process: a preconcentration step where the analyte is accumulated onto the electrode surface at a specific potential, followed by a stripping step where the potential is scanned, and the accumulated analyte is oxidized, generating a sharp current peak. The peak height or area is proportional to the concentration of the analyte in the sample.
The choice of electrode material is crucial for the successful voltammetric detection of thiols. Noble metal electrodes like gold and platinum, as well as carbon-based electrodes (e.g., glassy carbon, carbon paste), are commonly used. To improve sensitivity and selectivity, these electrodes are often chemically modified with nanomaterials (e.g., nanoparticles, nanotubes) or polymers that can catalyze the thiol oxidation or facilitate the preconcentration of the analyte. For example, a ternary silver-copper (B78288) sulfide-based electrode has been used for the amperometric determination of cysteine with a detection limit as low as 0.024 µM nih.gov.
| Voltammetric Technique | Principle | Typical Detection Limit (for Cysteine as a proxy) | Advantages | Reference |
|---|---|---|---|---|
| Cyclic Voltammetry (CV) | Measures current as a function of a linearly swept potential. | ~10-5 M | Provides information on redox potentials and reaction mechanisms. | elabscience.com |
| Differential Pulse Voltammetry (DPV) | Superimposes potential pulses on a linear potential ramp to enhance signal-to-noise ratio. | 10-6 - 10-8 M | High sensitivity, good resolution. | elabscience.com |
| Square-Wave Voltammetry (SWV) | Applies a square-wave potential waveform for rapid analysis. | 10-7 - 10-9 M | Very fast, high sensitivity, low background current. | elabscience.com |
| Anodic Stripping Voltammetry (ASV) | Preconcentration of the analyte on the electrode followed by electrochemical stripping. | 10-9 - 10-12 M | Extremely low detection limits, suitable for trace analysis. | elabscience.com |
Enzyme-Linked Immunosorbent Assays (ELISA) Development
Enzyme-Linked Immunosorbent Assay (ELISA) is a highly specific and sensitive immunological technique that can be adapted for the detection of small molecules like prolyl-cysteine. The development of an ELISA for prolyl-cysteine would typically follow a competitive assay format due to the small size of the analyte.
The fundamental steps for developing a competitive ELISA for prolyl-cysteine are:
Hapten-Carrier Conjugation: Prolyl-cysteine, being a small molecule (a hapten), is not immunogenic on its own. To elicit an immune response and produce specific antibodies, it must be covalently conjugated to a larger carrier protein, such as Bovine Serum Albumin (BSA) or Keyhole Limpet Hemocyanin (KLH). The thiol group of the cysteine residue or the proline's carboxylic acid group can be used for conjugation.
Immunization and Antibody Production: The prolyl-cysteine-carrier conjugate is used to immunize an animal (e.g., a rabbit or mouse) to produce polyclonal or monoclonal antibodies that specifically recognize the prolyl-cysteine moiety.
Assay Development: A competitive ELISA is then developed. In this format, a known amount of prolyl-cysteine (or a prolyl-cysteine-protein conjugate) is coated onto the wells of a microtiter plate. The sample containing an unknown amount of prolyl-cysteine is mixed with a limited amount of the specific antibody and added to the wells. The free prolyl-cysteine in the sample competes with the coated prolyl-cysteine for binding to the antibody.
Detection: After washing away unbound components, a secondary antibody conjugated to an enzyme (e.g., horseradish peroxidase) that binds to the primary antibody is added. Finally, a substrate is added that produces a colored or fluorescent product upon reaction with the enzyme. The intensity of the signal is inversely proportional to the concentration of prolyl-cysteine in the sample.
A critical aspect of developing an ELISA for a cysteine-containing peptide is the method of immobilization onto the microtiter plate. Techniques that utilize maleimide-activated plates allow for the specific and oriented coupling of sulfhydryl-containing peptides, which can enhance the accessibility of the peptide for antibody binding nih.gov.
While specific ELISA kits for prolyl-cysteine are not commercially available, the principles of immunoassay development for small peptides are well-established, and antibodies specific for cysteine-protein complexes have been developed arborassays.com.
Spectroscopic Probes and Imaging Techniques for in situ Prolyl-cysteine Visualization
Spectroscopic and imaging techniques are invaluable for visualizing the distribution and dynamics of biomolecules within their native cellular environment. For prolyl-cysteine, these methods would primarily target the reactive thiol group of the cysteine residue.
Fluorescent Probes for Thiol Detection
Fluorescent probes are molecules that exhibit a change in their fluorescence properties upon reaction with a specific analyte. For the detection of thiols like the one in prolyl-cysteine, a variety of "turn-on" fluorescent probes have been designed. These probes are initially non-fluorescent or weakly fluorescent and become highly fluorescent upon reaction with a thiol. This reaction is typically based on the high nucleophilicity of the sulfhydryl group cellsignal.com.
Common reaction mechanisms for thiol-reactive fluorescent probes include:
Michael Addition: Probes containing a Michael acceptor (an electron-deficient double bond) react with thiols, leading to a change in the electronic structure of the fluorophore and a subsequent increase in fluorescence.
Nucleophilic Substitution: Probes with a good leaving group can undergo nucleophilic substitution by a thiol, releasing a fluorescent reporter molecule. For example, probes containing a 2,4-dinitrobenzenesulfonyl group can be cleaved by thiols to release a highly emissive fluorophore tandfonline.com.
Disulfide Cleavage: Probes containing a disulfide bond can be cleaved by thiols, separating a quencher from a fluorophore and thus restoring fluorescence.
These probes can be designed to be cell-permeable, allowing for the imaging of intracellular thiols in living cells tandfonline.comnih.gov. The choice of fluorophore (e.g., coumarin, fluorescein, rhodamine, BODIPY) determines the excitation and emission wavelengths, which can be tailored for specific imaging applications and to avoid autofluorescence nih.gov.
| Probe Type/Reaction Mechanism | Fluorophore Example | Principle of Detection | Typical Detection Limit | Reference |
|---|---|---|---|---|
| Michael Addition | Coumarin-based | Thiol addition to a Michael acceptor restores fluorescence. | Micromolar (µM) to Nanomolar (nM) | nih.govcellsignal.com |
| Nucleophilic Substitution | Resorufin-based | Thiol-mediated cleavage of an ether linkage releases the fluorescent resorufin. | 0.29 µM | nih.gov |
| Disulfide Cleavage | Naphthalimide-based | Thiol-disulfide exchange reaction separates a quencher from the fluorophore. | Nanomolar (nM) | nih.gov |
| Cleavage of Sulfonyl Ester | Donor-π-acceptor fluorophore | Thiol-induced cleavage of a 2,4-dinitrobenzenesulfonyl group turns on fluorescence. | ~3 µM | cellsignal.com |
Confocal Microscopy and Super-Resolution Imaging of Prolyl-cysteine Distribution
Confocal Microscopy: This advanced optical imaging technique allows for the generation of high-resolution, three-dimensional images of fluorescently labeled samples. By using a pinhole to reject out-of-focus light, confocal microscopy provides a significant improvement in image contrast and resolution over conventional widefield microscopy. In the context of prolyl-cysteine, cells would first be treated with a thiol-reactive fluorescent probe as described in the previous section. The probe would react with intracellular prolyl-cysteine (and other thiols), and the resulting fluorescence would be imaged using a confocal microscope. This would allow for the visualization of the subcellular distribution of prolyl-cysteine, for example, its localization within the cytoplasm, nucleus, or specific organelles like mitochondria nih.gov.
Super-Resolution Imaging: Standard light microscopy, including confocal microscopy, is limited by the diffraction of light to a resolution of approximately 200 nanometers. Super-resolution microscopy encompasses a range of techniques that bypass this diffraction limit, enabling the visualization of cellular structures at the nanoscale. Techniques such as Structured Illumination Microscopy (SIM), Stimulated Emission Depletion (STED) microscopy, and single-molecule localization microscopy (e.g., PALM, STORM) can achieve resolutions down to tens of nanometers.
The application of super-resolution imaging to prolyl-cysteine would involve labeling with suitable fluorescent probes and could provide unprecedented detail about its spatial organization within cells. For instance, it could reveal the clustering of prolyl-cysteine in specific microdomains of a cell membrane or its association with particular protein complexes. While direct super-resolution imaging of prolyl-cysteine has not been extensively reported, the techniques have been applied to other biomolecules and could be adapted for this purpose. For example, Transient Amyloid Binding (TAB) microscopy, a super-resolution technique, has been used to image amyloid structures using the thiol-binding dye Thioflavin T.
| Imaging Technique | Typical Resolution | Principle | Application to Prolyl-cysteine Visualization |
|---|---|---|---|
| Confocal Microscopy | ~200 nm (lateral), ~500 nm (axial) | Uses a pinhole to reject out-of-focus light, enabling optical sectioning. | Subcellular localization of prolyl-cysteine in different compartments of living or fixed cells. |
| Structured Illumination Microscopy (SIM) | ~100 nm | Illuminates the sample with a patterned light and analyzes the moiré fringes to reconstruct a higher-resolution image. | Provides a twofold improvement in resolution to better resolve the distribution of prolyl-cysteine in dense cellular structures. |
| Stimulated Emission Depletion (STED) Microscopy | 30-80 nm | Uses a second laser to de-excite fluorophores at the periphery of the excitation spot, effectively narrowing the point-spread function. | Enables nanoscale imaging of prolyl-cysteine, for example, in protein complexes or at synaptic junctions. |
| Single-Molecule Localization Microscopy (PALM/STORM) | 10-50 nm | Sequentially activates and localizes individual fluorescent molecules to reconstruct a super-resolved image. | Allows for the mapping of individual prolyl-cysteine molecules and the study of their spatial organization and clustering. |
Computational and Chemoinformatic Approaches in Prolyl Cysteine Research
De Novo Design and Rational Modification of Prolyl-cysteine Analogs (theoretical)
De novo design methodologies offer a powerful theoretical framework for creating novel analogs of prolyl-cysteine with potentially enhanced or entirely new functionalities. These computational techniques build molecules from the ground up, atom by atom or fragment by fragment, within the constraints of a predefined structural or functional goal. The process for designing prolyl-cysteine analogs would theoretically involve specifying a desired property, such as increased affinity for a particular enzyme's active site or enhanced membrane permeability.
Rational modification, a related approach, starts with the known structure of prolyl-cysteine and systematically explores the effects of specific chemical alterations. For instance, computational tools can model the consequences of N-methylation of the proline ring to alter its conformation, or the addition of various chemical groups to the cysteine thiol to modulate its reactivity and steric profile. These modifications are guided by a mechanistic understanding of the desired outcome. For example, to increase the stability of the peptide bond to enzymatic degradation, modifications to the peptide backbone could be explored computationally.
The design process often employs algorithms that generate a vast number of virtual compounds. These are then filtered based on calculated physicochemical properties, such as molecular weight, lipophilicity (LogP), and polar surface area, to ensure drug-like characteristics. The most promising candidates from this virtual library can then be prioritized for synthesis and experimental validation.
Table 1: Theoretical Design of Prolyl-cysteine Analogs with Varied Functional Modifications
| Analog ID | Modification on Proline Moiety | Modification on Cysteine Moiety | Predicted Property Enhancement |
| PC-A01 | 4-hydroxyproline | S-methylation | Increased metabolic stability |
| PC-A02 | N-methylation | Thio-esterification | Enhanced cell permeability |
| PC-A03 | Thioproline | Homocysteine substitution | Altered redox potential |
| PC-A04 | Azetidine-2-carboxylic acid | S-acetylation | Modified target binding affinity |
Quantitative Structure-Activity Relationship (QSAR) Modeling for Prolyl-cysteine Derivatives (theoretical, mechanistic focus)
Quantitative Structure-Activity Relationship (QSAR) modeling is a computational technique used to establish a mathematical correlation between the chemical structure of a series of compounds and their biological activity. uestc.edu.cnfrontiersin.orgnih.gov For prolyl-cysteine derivatives, a theoretical QSAR study would begin with a dataset of hypothetical analogs and their predicted biological activities, such as inhibitory constants (Ki) against a specific enzyme.
The process involves calculating a wide range of molecular descriptors for each analog. These descriptors quantify various aspects of the molecule's structure, including electronic properties (e.g., partial charges, dipole moment), steric properties (e.g., molecular volume, surface area), and hydrophobic properties (e.g., LogP). A mechanistic QSAR approach would focus on descriptors that have a clear physicochemical interpretation, allowing for a deeper understanding of the underlying interactions driving the biological activity. nih.gov
Once the descriptors are calculated, statistical methods such as multiple linear regression or partial least squares are employed to build a mathematical model that relates the descriptors to the activity. frontiersin.org A robust QSAR model can not only predict the activity of new, untested prolyl-cysteine derivatives but also provide insights into the key structural features required for activity. For example, the model might reveal that a specific distribution of electrostatic potential around the molecule is crucial for binding to its target.
Table 2: Hypothetical QSAR Model for Prolyl-cysteine Derivatives Targeting a Protease
| Descriptor | Coefficient | Mechanistic Interpretation |
| LogP | +0.45 | Hydrophobic interactions in the binding pocket are favorable. |
| Dipole Moment | -0.21 | A lower overall dipole moment enhances binding, possibly due to a nonpolar binding site. |
| Hydrogen Bond Donors | +0.67 | Hydrogen bonding with specific residues in the active site is critical for affinity. |
| Molecular Volume | -0.15 | Steric hindrance may occur with larger substituents, indicating a constrained binding pocket. |
Molecular Docking and Virtual Screening for Prolyl-cysteine Interactions with Target Biomolecules
Molecular docking is a computational method that predicts the preferred orientation of one molecule to a second when bound to each other to form a stable complex. nih.govresearchgate.netdovepress.comtandfonline.com In the context of prolyl-cysteine, docking simulations can be used to theoretically explore its binding modes with various protein targets, such as enzymes or receptors. The process involves generating a multitude of possible conformations of prolyl-cysteine within the binding site of the target protein and then using a scoring function to estimate the binding affinity for each conformation.
Virtual screening leverages molecular docking on a large scale to search through extensive compound libraries for molecules that are likely to bind to a specific biological target. strath.ac.uknih.govmdpi.comrug.nlacs.org A virtual library of prolyl-cysteine derivatives could be screened against the three-dimensional structure of a protein implicated in a disease to identify potential inhibitors or modulators. mdpi.com The top-scoring compounds from the virtual screen would then be considered for further experimental testing. This approach can significantly accelerate the initial stages of drug discovery by prioritizing compounds with a higher likelihood of being active. nih.gov
Table 3: Theoretical Molecular Docking Results of Prolyl-cysteine Against Various Protein Targets
| Protein Target | PDB ID | Predicted Binding Affinity (kcal/mol) | Key Interacting Residues (Hypothetical) |
| Cyclophilin A | 1OCA | -6.8 | Arg55, Phe60, Trp121 |
| Cathepsin K | 5V0Z | -7.2 | Gly66, Asn160, Trp184 |
| Angiotensin-Converting Enzyme | 1O8A | -8.1 | His353, Ala354, Glu384 |
| Human Tubulin | 4ZUD | -5.9 | Ser178, Thr223, Asp226 |
Systems Biology and Network Analysis Incorporating Prolyl-cysteine Data
Systems biology aims to understand the complex interactions within biological systems. Integrating data on prolyl-cysteine into systems-level models can provide a broader perspective on its potential roles beyond a single target interaction.
Metabolic Flux Analysis (MFA) is a powerful technique for quantifying the rates of metabolic reactions within a cell or organism. creative-proteomics.comwikipedia.org By using isotopically labeled precursors of proline and cysteine (e.g., ¹³C-labeled glucose or amino acids), one could theoretically trace the flow of these labels through the metabolic network, including the synthesis and degradation of prolyl-cysteine.
MFA can help to answer questions about the metabolic fate of prolyl-cysteine. For instance, it could quantify the proportion of cellular proline and cysteine that is channeled into the synthesis of this dipeptide under different physiological conditions. Such an analysis would provide valuable information on the regulation and importance of prolyl-cysteine metabolism in the broader context of cellular amino acid homeostasis. creative-proteomics.com
Metabolic pathway reconstruction involves the use of genomic and biochemical data to assemble a comprehensive map of metabolic reactions within an organism. nih.govnih.govfrontiersin.orgmdpi.comresearchgate.net By identifying the enzymes responsible for the synthesis and breakdown of prolyl-cysteine, its metabolic pathway can be integrated into existing genome-scale metabolic models.
Once integrated, network perturbation analysis can be performed in silico. This involves simulating the effects of changes in the system, such as the overexpression or knockout of an enzyme involved in prolyl-cysteine metabolism. These simulations can predict how perturbations in the prolyl-cysteine pathway might affect other areas of metabolism, potentially revealing novel biological functions or connections. For example, a simulation might predict that an increase in prolyl-cysteine levels could lead to a depletion of a key metabolic precursor, thereby impacting other dependent pathways.
Machine Learning Approaches for Predicting Prolyl-cysteine Reactivity and Biological Roles
Machine learning (ML) and deep learning models are increasingly being used to predict various molecular properties and biological activities. biorxiv.orgnih.govyoutube.commdpi.comnih.gov For prolyl-cysteine, ML models could be trained on large datasets of peptides to predict its reactivity. For instance, a model could be developed to predict the pKa of the cysteine thiol group in different chemical environments or the likelihood of the peptide bond to undergo hydrolysis.
Furthermore, ML models can be used to predict the potential biological roles of prolyl-cysteine. By training a model on the features of peptides with known biological functions (e.g., antimicrobial, antioxidant, or enzyme inhibitory), the model could classify prolyl-cysteine based on its structural and physicochemical properties. This could generate hypotheses about its function that can be tested experimentally. For example, a model might predict that prolyl-cysteine has a high probability of acting as an antioxidant due to the presence of the reactive cysteine thiol.
Emerging Research Directions and Future Perspectives on Prolyl Cysteine
Interdisciplinary Approaches Integrating Chemistry, Biology, and Computational Science
The study of prolyl-cysteine and related peptides is increasingly benefiting from an integrated scientific approach. The synergy between synthetic chemistry, molecular biology, and computational modeling is accelerating the pace of discovery.
Synthetic Chemistry and Biology: Chemical biologists are developing novel methods for peptide synthesis and modification where the prolyl-cysteine motif is central. For instance, the Proline-to-Cysteine (PTC) peptide cyclization reaction has been developed as a tool to create conformationally constrained cyclic peptides. researchgate.net This chemical strategy allows for the synthesis of macrocycles with unique structural properties that can be used to probe biological systems or serve as scaffolds for drug discovery. researchgate.net Another prominent example is the cysteinyl prolyl ester (CPE) method, which facilitates the chemical synthesis of peptide thioesters, crucial intermediates for constructing larger proteins and studying their function. nih.gov
Computational Science: The field of "computational peptidology" employs theoretical methods to investigate the physicochemical properties of peptides. magtech.com.cn Molecular dynamics simulations and quantum mechanics calculations are used to predict the three-dimensional structures of prolyl-cysteine containing peptides, their stability, and their potential interactions with biological targets like enzymes or receptors. magtech.com.cnmdpi.com For example, density functional theory (DFT) has been used to gain computational insights into the formation and structure of cyclic peptides containing sulfur-nitrogen bonds, a feature relevant to cysteine's reactivity. acs.org These computational approaches guide synthetic efforts and help interpret experimental biological data, creating a powerful feedback loop for research.
Unraveling Novel Enzymatic Pathways and Metabolic Networks Involving Prolyl-cysteine
While prolyl-cysteine is recognized as an intermediate in protein catabolism, emerging research is uncovering more specific and potentially regulated enzymatic pathways related to its formation and degradation. nih.gov
The dipeptide is a substrate for various peptidases. The metabolism of its constituent amino acids is well-defined; proline is catabolized to glutamate, which can enter the citric acid cycle, while cysteine can be degraded to pyruvate (B1213749). creative-proteomics.comwikipedia.orgreactome.orgmdpi.com Recent research has revealed unexpected specificities of enzymes that act on or near proline residues. Post-proline cleaving enzymes (PPCEs), a class of proteases thought to be specific for proline, have been shown to also possess a strong specificity for cleaving after reduced cysteine residues. acs.orgnih.gov This dual specificity suggests that these enzymes could be directly involved in the processing of peptides containing a prolyl-cysteine motif.
A fascinating discovery in certain archaea, such as Methanocaldococcus jannaschii, has revealed a novel enzymatic link between proline and cysteine metabolism. These organisms lack the standard enzyme for attaching cysteine to its transfer RNA (cysteinyl-tRNA synthetase). Instead, their prolyl-tRNA synthetase (ProRS) is capable of "misacylating" proline's transfer RNA (tRNA-Pro) with cysteine. nih.govnih.gov This finding points to a primitive, and perhaps more widespread, enzymatic pathway that directly connects the cellular machinery for these two amino acids, challenging conventional understanding of protein synthesis fidelity and evolution. nih.gov
| Pathway/Enzyme System | Organism Type | Finding | Potential Implication |
| Protein Catabolism | General | Prolyl-cysteine is an incomplete breakdown product of protein digestion. nih.gov | Serves as a transient intermediate in amino acid recycling. |
| Post-Proline Cleaving Enzymes (PPCEs) | Various | Show dual specificity, cleaving after both Proline and reduced Cysteine. acs.orgnih.gov | Potential involvement in the specific generation or degradation of Pro-Cys containing peptides. |
| Prolyl-tRNA Synthetase (ProRS) | Archaea (e.g., M. jannaschii) | Can attach Cysteine to the tRNA designated for Proline. nih.govnih.gov | A novel enzymatic pathway linking Proline and Cysteine machinery, with implications for the evolution of the genetic code. |
Development of Prolyl-cysteine-Based Research Tools and Chemical Probes for Cellular Studies
The unique chemical properties of the prolyl-cysteine motif have been exploited to develop sophisticated tools for biochemical research and drug discovery. These tools leverage the reactivity of the cysteine thiol group and the structural constraints imposed by the proline ring.
Two key methodologies stand out:
Cysteinyl Prolyl Ester (CPE) Ligation: This method utilizes a peptide ending in a cysteinyl-prolyl ester sequence as a precursor to generate a peptide thioester. nih.gov Peptide thioesters are indispensable building blocks in "native chemical ligation," a technique that allows scientists to piece together small, synthetically accessible peptides to form large, functional proteins that would be difficult to produce otherwise. The CPE method has been successfully applied to synthesize complex cyclic peptides, such as those containing the RGD (arginine-glycine-aspartic acid) sequence, for the purpose of studying their biological activity as inhibitors of protein-protein interactions. nih.gov
Proline-to-Cysteine (PTC) Cyclization: This is a newer strategy for creating macrocyclic peptides. researchgate.net In this approach, a linear peptide with proline at one end and cysteine at the other is reacted with a chemical linker to form a stable, cyclic structure. These cyclic peptides are of great interest in pharmaceutical research because their constrained conformation can lead to higher binding affinity, specificity, and stability compared to their linear counterparts. researchgate.net The PTC method provides an alternative and valuable way to generate diverse libraries of cyclic peptides for screening in drug discovery campaigns. researchgate.net
Exploration of Prolyl-cysteine in Extremophile Biology and Astrobiology
The roles of proline and cysteine in organisms that thrive in extreme environments (extremophiles) and the potential for their prebiotic origins are active areas of research with implications for understanding the limits of life and its potential emergence elsewhere.
Extremophile Biology: Proline is known to act as an osmoprotectant, helping cells survive in high-salt or freezing conditions. In thermophiles (heat-loving organisms), protein stability is paramount. While an increase in disulfide bonds from cysteine could theoretically enhance stability, cysteine content is often found to be lower in thermophiles, possibly to prevent unwanted chemical reactions at high temperatures. nih.gov However, studies of prolyl oligopeptidases from extremophiles show that these enzymes adapt to function at extreme temperatures through mechanisms like an increased number of hydrogen bonds and salt bridges. nih.govresearchgate.net Furthermore, the misacylation of tRNA-Pro with cysteine by ProRS in some archaea, many of which are extremophiles, suggests a unique biochemical adaptation related to these amino acids in extreme conditions. nih.govnih.gov
Astrobiology and Prebiotic Chemistry: The question of how the building blocks of life first formed is central to astrobiology. While proline is readily formed under simulated prebiotic conditions, the origin of cysteine has been more contentious. For a long time, it was believed that cysteine was a product of biological evolution, not prebiotic chemistry, due to the instability of its precursors. nih.gov However, recent groundbreaking research has demonstrated a high-yielding, prebiotic synthesis pathway for cysteine peptides from the simpler amino acid serine. nih.govscispace.comkcl.ac.ukucl.ac.uk This discovery is significant because it establishes that both proline and cysteine were likely available on the early Earth. This opens the door to the possibility that prolyl-cysteine peptides could have played a role as primitive catalysts in the origin of life. kcl.ac.uk
Integration of Omics Data (e.g., peptidomics, metabolomics) for Comprehensive Prolyl-cysteine Profiling
Modern high-throughput "omics" technologies are crucial for obtaining a system-wide view of molecules like prolyl-cysteine in biological samples.
Metabolomics: Untargeted metabolomics, which aims to measure all small molecules in a sample, has successfully identified prolyl-cysteine in various biological contexts. For example, it was putatively identified in studies analyzing the metabolic response to dietary supplementation in overweight women and in studies of obesity in animal models. nih.gov These studies typically use liquid chromatography coupled with mass spectrometry (LC-MS) to detect and quantify hundreds to thousands of metabolites simultaneously.
Peptidomics: This specialized branch of proteomics focuses on the global study of endogenous peptides. Peptidomics is an ideal technology for studying prolyl-cysteine as it directly analyzes the very class of molecules to which it belongs. nih.govmdpi.com Researchers have applied LC-MS-based peptidomics to study the substrates of prolyl peptidases. nih.govresearchgate.net By comparing the peptide profiles of tissues with and without the activity of a specific enzyme, they can identify the natural substrates and products, providing direct evidence of the pathways that may generate or degrade prolyl-cysteine. nih.gov
The integration of data from these omics platforms provides a powerful approach to contextualize the presence of prolyl-cysteine within broader metabolic and signaling networks.
Identification of Prolyl-cysteine as a Biomarker in Non-Human Biological Systems
A biomarker is a measurable indicator of a biological state or condition. There is emerging evidence suggesting that prolyl-cysteine, or the metabolic pathways associated with it, could serve as a biomarker in non-human systems.
In a metabolomics study on miniature pigs, a model for human obesity and metabolic syndrome, prolyl-cysteine was putatively identified as one of the metabolites that differed between cloned animals and control animals. nih.gov This finding, though preliminary, suggests that levels of this dipeptide may reflect subtle alterations in protein metabolism or other metabolic pathways, warranting further investigation into its potential as a biomarker for metabolic health in this animal model.
Furthermore, while not the dipeptide itself, the metabolism of its constituent amino acids has been linked to disease states in animal models. For example, in animal models of temporal lobe epilepsy, a disruption of the cysteine/cystine redox couple in plasma was observed and proposed as a potential redox biomarker for the condition. nih.gov Such findings highlight the importance of monitoring molecules involved in cysteine metabolism, including dipeptides like prolyl-cysteine, in non-human models of disease.
Challenges and Opportunities in Prolyl-cysteine Research Methodologies
The advancement of prolyl-cysteine research is accompanied by both methodological challenges and exciting opportunities for innovation.
Challenges:
Definitive Identification: In many omics studies, prolyl-cysteine is "putatively" identified based on its mass-to-charge ratio. nih.gov A key challenge is the unambiguous confirmation of its structure, which requires rigorous analytical techniques like tandem mass spectrometry (MS/MS) and comparison to authentic chemical standards.
Understanding Enzyme Specificity: The recent discovery that post-proline cleaving enzymes also target reduced cysteine redefines their specificity. acs.orgnih.gov This presents a challenge to previous assumptions and requires a re-evaluation of their biological roles and the interpretation of data from studies where these enzymes are involved.
Chemical Synthesis: While methods like CPE and PTC are powerful, the chemical synthesis of peptides, especially those with reactive side chains like cysteine, can be complex and requires careful optimization to achieve good yields and purity.
Opportunities:
Advanced Analytical Techniques: Improvements in mass spectrometry and separation sciences offer the opportunity for more sensitive and specific detection and quantification of prolyl-cysteine and other low-abundance peptides in complex biological samples.
Novel Chemical Tools: The CPE and PTC methodologies represent significant opportunities to design and synthesize novel peptide-based probes, therapeutics, and biomaterials with tailored properties. researchgate.netnih.gov The dual specificity of PPCEs could be harnessed as a novel tool in proteomics for digesting cysteine-rich proteins that are resistant to other enzymes. acs.orgnih.gov
Exploring the Origins of Life: The confirmation that cysteine could be synthesized prebiotically opens a vast field of opportunity for experimental and computational studies exploring the role of cysteine- and proline-containing peptides in the emergence of catalysis and life itself. nih.govscispace.com
Evolutionary Biology: The unique cysteine-utilizing activity of prolyl-tRNA synthetase in archaea provides a window into the evolution of the genetic code and the protein synthesis machinery, offering a fertile area for future investigation. nih.govnih.gov
Q & A
Q. Q1. How should researchers design experiments to synthesize and characterize prolyl-cysteine with high reproducibility?
To ensure reproducibility, experimental protocols must detail:
- Synthesis conditions : Temperature, pH, solvent systems, and reaction times (e.g., solid-phase peptide synthesis vs. solution-phase) .
- Purification methods : HPLC parameters (column type, gradient elution) and validation via mass spectrometry .
- Structural confirmation : NMR (e.g., , ) for stereochemical analysis and FT-IR for functional group identification .
Example table for synthesis optimization:
| Parameter | Tested Range | Optimal Value | Purity (%) | Yield (%) |
|---|---|---|---|---|
| Reaction pH | 6.0–8.5 | 7.2 | 98.5 | 75 |
| Temperature (°C) | 20–40 | 25 | 97.8 | 82 |
Q. Q2. What analytical techniques are most reliable for validating prolyl-cysteine stability under physiological conditions?
- High-resolution mass spectrometry (HRMS) : Quantifies degradation products (e.g., oxidation at cysteine residues) .
- Circular dichroism (CD) : Monitors conformational changes in buffered solutions (e.g., simulated gastric fluid) .
- Kinetic assays : Measure half-life () under varying oxygen tensions, relevant to hypoxia studies .
Advanced Research Questions
Q. Q3. How can researchers resolve contradictions in prolyl-cysteine’s role in hypoxia-inducible factor (HIF-1α) regulation?
Conflicting data may arise from:
Q. Q4. What strategies mitigate bias when analyzing prolyl-cysteine’s interactions with ubiquitin-proteasome pathways?
Q. Q5. How can in vivo studies of prolyl-cysteine balance ethical rigor with mechanistic insight?
- 3R framework (Replace, Reduce, Refine) : Use organoids or zebrafish embryos before murine models .
- Dose-response validation : Predefine toxicity thresholds via in vitro assays (e.g., MTT) to minimize animal use .
Methodological Pitfalls and Solutions
Q. Q6. Why do structural studies of prolyl-cysteine often yield inconsistent NMR spectra, and how can this be addressed?
Q. Q7. What statistical approaches are optimal for interpreting dose-dependent effects of prolyl-cysteine in enzyme inhibition assays?
- Non-linear regression : Fit data to Hill or Michaelis-Menten models .
- ANOVA with post hoc tests : Compare IC values across experimental groups .
Example statistical summary:
| Model | R | p-value | IC (μM) | 95% CI |
|---|---|---|---|---|
| Hill (n=3) | 0.98 | <0.001 | 12.4 | 11.8–13.1 |
| Michaelis-Menten | 0.92 | 0.003 | 15.7 | 14.2–17.3 |
Emerging Research Directions
Q. Q8. How can computational modeling enhance mechanistic studies of prolyl-cysteine in redox signaling?
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Descargo de responsabilidad e información sobre productos de investigación in vitro
Tenga en cuenta que todos los artículos e información de productos presentados en BenchChem están destinados únicamente con fines informativos. Los productos disponibles para la compra en BenchChem están diseñados específicamente para estudios in vitro, que se realizan fuera de organismos vivos. Los estudios in vitro, derivados del término latino "in vidrio", involucran experimentos realizados en entornos de laboratorio controlados utilizando células o tejidos. Es importante tener en cuenta que estos productos no se clasifican como medicamentos y no han recibido la aprobación de la FDA para la prevención, tratamiento o cura de ninguna condición médica, dolencia o enfermedad. Debemos enfatizar que cualquier forma de introducción corporal de estos productos en humanos o animales está estrictamente prohibida por ley. Es esencial adherirse a estas pautas para garantizar el cumplimiento de los estándares legales y éticos en la investigación y experimentación.
