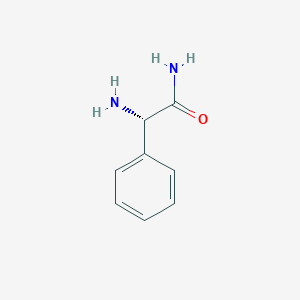
(S)-2-amino-2-phenylacetamide
Katalognummer B031664
Molekulargewicht: 150.18 g/mol
InChI-Schlüssel: KIYRSYYOVDHSPG-ZETCQYMHSA-N
Achtung: Nur für Forschungszwecke. Nicht für den menschlichen oder tierärztlichen Gebrauch.
Patent
US06949658B2
Procedure details


In accordance with the process described in JP Patent Application Laying Open (Kokai) No. 62-55097, Enterobacter cloacae N-7901 (FERM BP-873) was cultured. This culture solution, 100 mL, was centrifuged, and the wet cells were then suspended in distilled water to prepare a 270 g cell suspension. D, L-phenylglycine amide, 30 g, was dissolved in this suspension, and the mixture was then allowed to react at 40° C. for 18 hours. After the reaction, cells were removed by centrifugation and 295 g of an aqueous solution containing 5.0% by mass each of L-phenylglycine and D-phenylglycine amide was obtained.


Identifiers
|
REACTION_CXSMILES
|
[CH:1]1[CH:6]=[CH:5][C:4]([C@H:7]([NH2:11])[C:8]([NH2:10])=[O:9])=[CH:3][CH:2]=1>O>[CH:1]1[CH:2]=[CH:3][C:4]([CH:7]([NH2:11])[C:8]([NH2:10])=[O:9])=[CH:5][CH:6]=1
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C1=CC=C(C=C1)[C@@H](C(=O)N)N
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
O
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
to prepare a 270 g cell suspension
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
to react at 40° C. for 18 hours
|
|
Duration
|
18 h
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
After the reaction, cells
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
were removed by centrifugation and 295 g of an aqueous solution
|
ADDITION
|
Type
|
ADDITION
|
|
Details
|
containing 5.0% by mass each of L-phenylglycine
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C1=CC=C(C=C1)C(C(=O)N)N
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
Patent
US06949658B2
Procedure details
In accordance with the process described in JP Patent Application Laying Open (Kokai) No. 62-55097, Enterobacter cloacae N-7901 (FERM BP-873) was cultured. This culture solution, 100 mL, was centrifuged, and the wet cells were then suspended in distilled water to prepare a 270 g cell suspension. D, L-phenylglycine amide, 30 g, was dissolved in this suspension, and the mixture was then allowed to react at 40° C. for 18 hours. After the reaction, cells were removed by centrifugation and 295 g of an aqueous solution containing 5.0% by mass each of L-phenylglycine and D-phenylglycine amide was obtained.
Identifiers
|
REACTION_CXSMILES
|
[CH:1]1[CH:6]=[CH:5][C:4]([C@H:7]([NH2:11])[C:8]([NH2:10])=[O:9])=[CH:3][CH:2]=1>O>[CH:1]1[CH:2]=[CH:3][C:4]([CH:7]([NH2:11])[C:8]([NH2:10])=[O:9])=[CH:5][CH:6]=1
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C1=CC=C(C=C1)[C@@H](C(=O)N)N
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
O
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
to prepare a 270 g cell suspension
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
to react at 40° C. for 18 hours
|
|
Duration
|
18 h
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
After the reaction, cells
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
were removed by centrifugation and 295 g of an aqueous solution
|
ADDITION
|
Type
|
ADDITION
|
|
Details
|
containing 5.0% by mass each of L-phenylglycine
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C1=CC=C(C=C1)C(C(=O)N)N
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
Patent
US06949658B2
Procedure details
In accordance with the process described in JP Patent Application Laying Open (Kokai) No. 62-55097, Enterobacter cloacae N-7901 (FERM BP-873) was cultured. This culture solution, 100 mL, was centrifuged, and the wet cells were then suspended in distilled water to prepare a 270 g cell suspension. D, L-phenylglycine amide, 30 g, was dissolved in this suspension, and the mixture was then allowed to react at 40° C. for 18 hours. After the reaction, cells were removed by centrifugation and 295 g of an aqueous solution containing 5.0% by mass each of L-phenylglycine and D-phenylglycine amide was obtained.
Identifiers
|
REACTION_CXSMILES
|
[CH:1]1[CH:6]=[CH:5][C:4]([C@H:7]([NH2:11])[C:8]([NH2:10])=[O:9])=[CH:3][CH:2]=1>O>[CH:1]1[CH:2]=[CH:3][C:4]([CH:7]([NH2:11])[C:8]([NH2:10])=[O:9])=[CH:5][CH:6]=1
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C1=CC=C(C=C1)[C@@H](C(=O)N)N
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
solvent
|
|
Smiles
|
O
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
to prepare a 270 g cell suspension
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
to react at 40° C. for 18 hours
|
|
Duration
|
18 h
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
After the reaction, cells
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
were removed by centrifugation and 295 g of an aqueous solution
|
ADDITION
|
Type
|
ADDITION
|
|
Details
|
containing 5.0% by mass each of L-phenylglycine
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C1=CC=C(C=C1)C(C(=O)N)N
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
