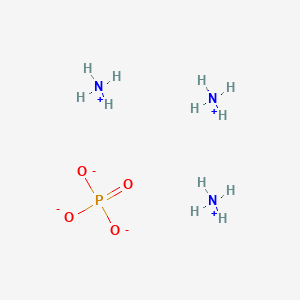
triazanium;phosphate
Katalognummer B3428527
Molekulargewicht: 149.09 g/mol
InChI-Schlüssel: ZRIUUUJAJJNDSS-UHFFFAOYSA-N
Achtung: Nur für Forschungszwecke. Nicht für den menschlichen oder tierärztlichen Gebrauch.
Patent
US03974262
Procedure details


A process for producing particulate ammonium phosphate which comprises reacting the off-gases from a urea production process with phosphoric acid containing at least 35% P3O5 in a stirred reactor at a pressure of from -0.1 to +1.5 kg/cm2 gauge to give a boiling fluid ammonium phosphate having an NH3 :H3PO4 molar ratio of from 0.1:1 to 0.8:1; passing the fluid ammonium phosphate to a pressure reactor operated at from 0.5 to 3.5 kg/cm2 gauge and at 130° to 180°C where it is reacted with gaseous ammonia to give a boiling fluid ammonium phosphate having an NH3 :H3PO4 molar ratio of from 0.95:1 to 1.85:1 and containing from 4 to 20% of water; and expelling the fluid ammonium phosphate into a solidification zone at ambient pressure in which solid particles are formed.


Name
Name
Identifiers
|
REACTION_CXSMILES
|
[NH2:1]C(N)=O.[P:5](=[O:9])([OH:8])([OH:7])[OH:6]>>[P:5]([O-:9])([O-:8])([O-:7])=[O:6].[NH4+:1].[NH4+:1].[NH4+:1].[NH3:1] |f:2.3.4.5|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
NC(=O)N
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
P(O)(O)(O)=O
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
P(=O)([O-])([O-])[O-].[NH4+].[NH4+].[NH4+]
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
N
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
Patent
US03974262
Procedure details
A process for producing particulate ammonium phosphate which comprises reacting the off-gases from a urea production process with phosphoric acid containing at least 35% P3O5 in a stirred reactor at a pressure of from -0.1 to +1.5 kg/cm2 gauge to give a boiling fluid ammonium phosphate having an NH3 :H3PO4 molar ratio of from 0.1:1 to 0.8:1; passing the fluid ammonium phosphate to a pressure reactor operated at from 0.5 to 3.5 kg/cm2 gauge and at 130° to 180°C where it is reacted with gaseous ammonia to give a boiling fluid ammonium phosphate having an NH3 :H3PO4 molar ratio of from 0.95:1 to 1.85:1 and containing from 4 to 20% of water; and expelling the fluid ammonium phosphate into a solidification zone at ambient pressure in which solid particles are formed.
Name
Name
Identifiers
|
REACTION_CXSMILES
|
[NH2:1]C(N)=O.[P:5](=[O:9])([OH:8])([OH:7])[OH:6]>>[P:5]([O-:9])([O-:8])([O-:7])=[O:6].[NH4+:1].[NH4+:1].[NH4+:1].[NH3:1] |f:2.3.4.5|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
NC(=O)N
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
P(O)(O)(O)=O
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
P(=O)([O-])([O-])[O-].[NH4+].[NH4+].[NH4+]
|
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
N
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
