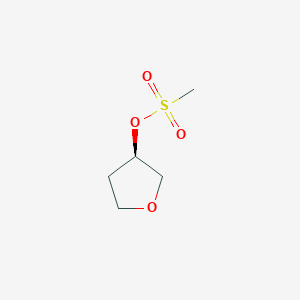
(R)-tetrahydrofuran-3-yl methanesulfonate
Katalognummer B8646396
Molekulargewicht: 166.20 g/mol
InChI-Schlüssel: KHXQGLSTCGSGLW-RXMQYKEDSA-N
Achtung: Nur für Forschungszwecke. Nicht für den menschlichen oder tierärztlichen Gebrauch.
Patent
US08524900B2
Procedure details


The title compound was prepared in the same manner as 4-bromo-1-(cyclobutyl)-1H-pyrazole, but using tetrahydrofuran-3-yl methanesulfonate (prepared according to procedures known in the art).


Name
Identifiers
|
REACTION_CXSMILES
|
[Br:1][C:2]1[CH:3]=[N:4][N:5]([CH:7]2[CH2:10][CH2:9][CH2:8]2)[CH:6]=1.CS(OC1CCOC1)(=O)=[O:13]>>[Br:1][C:2]1[CH:3]=[N:4][N:5]([CH:7]2[CH2:10][CH2:9][O:13][CH2:8]2)[CH:6]=1
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
BrC=1C=NN(C1)C1CCC1
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CS(=O)(=O)OC1COCC1
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
prepared
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
BrC=1C=NN(C1)C1COCC1
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
Patent
US08524900B2
Procedure details
The title compound was prepared in the same manner as 4-bromo-1-(cyclobutyl)-1H-pyrazole, but using tetrahydrofuran-3-yl methanesulfonate (prepared according to procedures known in the art).
Name
Identifiers
|
REACTION_CXSMILES
|
[Br:1][C:2]1[CH:3]=[N:4][N:5]([CH:7]2[CH2:10][CH2:9][CH2:8]2)[CH:6]=1.CS(OC1CCOC1)(=O)=[O:13]>>[Br:1][C:2]1[CH:3]=[N:4][N:5]([CH:7]2[CH2:10][CH2:9][O:13][CH2:8]2)[CH:6]=1
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
BrC=1C=NN(C1)C1CCC1
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CS(=O)(=O)OC1COCC1
|
Conditions
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
prepared
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
BrC=1C=NN(C1)C1COCC1
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
