Not Available
Beschreibung
BenchChem offers high-quality Not Available suitable for many research applications. Different packaging options are available to accommodate customers' requirements. Please inquire for more information about Not Available including the price, delivery time, and more detailed information at info@benchchem.com.
Eigenschaften
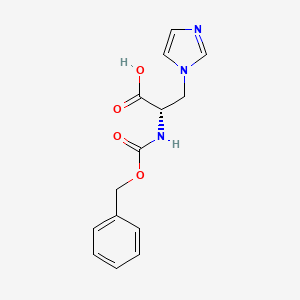
Molekularformel |
C14H15N3O4 |
|---|---|
Molekulargewicht |
289.29 g/mol |
IUPAC-Name |
(2S)-3-imidazol-1-yl-2-(phenylmethoxycarbonylamino)propanoic acid |
InChI |
InChI=1S/C14H15N3O4/c18-13(19)12(8-17-7-6-15-10-17)16-14(20)21-9-11-4-2-1-3-5-11/h1-7,10,12H,8-9H2,(H,16,20)(H,18,19)/t12-/m0/s1 |
InChI-Schlüssel |
PMENWBKKSRCFMJ-LBPRGKRZSA-N |
Isomerische SMILES |
C1=CC=C(C=C1)COC(=O)N[C@@H](CN2C=CN=C2)C(=O)O |
Kanonische SMILES |
C1=CC=C(C=C1)COC(=O)NC(CN2C=CN=C2)C(=O)O |
Herkunft des Produkts |
United States |
The Valley of Death: Why Promising Research Compounds Often Fail to Reach the Market
A Technical Guide for Researchers, Scientists, and Drug Development Professionals
The journey of a research compound from a promising laboratory discovery to a commercially available therapeutic is fraught with challenges, often referred to as the "valley of death." A staggering majority of these compounds, despite showing initial promise, never reach the patients they are intended to help. This in-depth technical guide explores the multifaceted reasons behind this high attrition rate, providing a comprehensive overview of the scientific, regulatory, and economic hurdles that litter the path to commercialization. Understanding these obstacles is paramount for researchers, scientists, and drug development professionals seeking to navigate this complex landscape successfully.
The drug development pipeline is a long and arduous process, with failure being a common outcome. It is estimated that approximately 90% of all clinical trials fail to achieve regulatory approval.[1] This high failure rate is not attributed to a single cause but rather a confluence of factors that can emerge at any stage, from preclinical research to late-stage clinical trials and even post-market surveillance.
I. The Preclinical Gauntlet: Early Stumbles with Lasting Consequences
The preclinical phase, which involves in vitro and in vivo studies to assess a compound's initial safety and efficacy, is the first major hurdle. A significant number of compounds are eliminated at this stage due to unforeseen issues.
A. Inadequate Target Validation and Poor Translatability
One of the earliest and most fundamental reasons for failure is inadequate validation of the drug's biological target.[1] Promising results in preclinical models, particularly animal models, often do not translate to humans.[2][3] This discrepancy can arise from fundamental biological differences between species and the inability of animal models to fully recapitulate complex human diseases.[3]
B. Unforeseen Toxicity and Poor Pharmacokinetics
Non-clinical toxicology studies are a critical step in weeding out potentially harmful compounds.[4] A 2015 analysis of data from four major pharmaceutical companies revealed that negative results from non-clinical toxicology accounted for the termination of 40% of compounds between 2006 and 2010.[4] Furthermore, poor pharmacokinetic properties, such as inadequate absorption, distribution, metabolism, and excretion (ADME), can render a compound ineffective or toxic, leading to its discontinuation.[4][5][6][7]
II. The Clinical Abyss: Where Most Compounds Meet Their Demise
The transition from preclinical to clinical development is a critical juncture where many promising compounds falter.[8] Clinical trials, divided into three main phases, represent the most expensive and time-consuming part of drug development, and it is here that the majority of failures occur.[9]
A. Lack of Clinical Efficacy: The Primary Culprit
The most significant reason for clinical trial failure is a lack of efficacy.[5][6][7] Between 40% and 50% of drug candidates that enter clinical trials fail because they do not produce the intended therapeutic effect in humans.[5][6][7] This can be due to a variety of factors, including a flawed understanding of the disease mechanism, inappropriate patient selection, or the compound's inability to engage its target effectively in a complex biological system.
B. Unmanageable Toxicity and Side Effects
Even if a compound shows some efficacy, it can be derailed by unacceptable toxicity or side effects. Approximately 30% of clinical trial failures are attributed to unmanageable toxicity.[5] Safety issues that were not apparent in preclinical animal studies can emerge in human trials, leading to the termination of the development program.[3]
C. Methodological Flaws and Operational Challenges
Poor study design is another significant contributor to clinical trial failure.[1][10] This can include issues such as the selection of inappropriate patient cohorts, insufficient dose optimization, and the use of endpoints that do not adequately measure the drug's efficacy.[10] Operational and logistical challenges, such as difficulties in patient recruitment and retention, can also undermine a trial's success, with a staggering 55% of trials being terminated prematurely due to poor enrollment.[1]
| Reason for Clinical Trial Failure | Percentage of Failures | Key Contributing Factors |
| Lack of Clinical Efficacy | 40-50% | Inadequate target validation, poor understanding of disease biology, inappropriate patient selection.[5][6][7] |
| Unmanageable Toxicity | 30% | Emergence of unforeseen side effects in humans not observed in preclinical studies.[5] |
| Poor Drug-like Properties (Pharmacokinetics) | 10-15% | Issues with absorption, distribution, metabolism, and excretion (ADME).[5][6][7] |
| Lack of Commercial Interest & Poor Strategic Planning | 10% | Shift in company portfolio, market competition, unfavorable pricing and reimbursement landscape.[5] |
III. Economic and Commercial Roadblocks: The Business of Science
Beyond the scientific and clinical hurdles, economic and commercial considerations play a pivotal role in determining a research compound's fate. The average cost to bring a new drug to market is estimated to be between $1 billion and over $2.8 billion.[5][7][11][12]
A. Portfolio Rationalization and Shifting Priorities
Pharmaceutical companies often re-evaluate their drug development portfolios based on changing market dynamics, emerging scientific data, and internal strategic shifts. A study found that the rationalization of a company's portfolio was the second-largest reason for compound withdrawal, accounting for 32% of terminations.[4]
B. Market Access, Pricing, and Reimbursement
Successfully navigating the complex landscape of market access, which includes securing favorable pricing and reimbursement from payers, is a major challenge.[12][13] A compound that is scientifically sound may not be commercially viable if it cannot demonstrate a significant clinical benefit over existing treatments to justify its cost.
IV. The Regulatory Maze: Navigating a Complex and Evolving Landscape
The regulatory pathway to drug approval is long, complex, and fraught with potential delays.[13][14] Regulatory agencies like the U.S. Food and Drug Administration (FDA) and the European Medicines Agency (EMA) have stringent requirements for demonstrating a drug's safety and efficacy.
A. Stringent Data Requirements and Manufacturing Readiness
Companies must provide extensive data from preclinical and clinical studies to support a drug's approval.[8] This includes demonstrating robust and well-controlled manufacturing processes to ensure product quality and consistency. Gaps in the data package or manufacturing delays can lead to significant regulatory setbacks.[8]
B. Evolving Regulatory Standards
The regulatory landscape is constantly evolving, with new guidelines and requirements being introduced.[14] Staying abreast of these changes and adapting development strategies accordingly is crucial for a successful submission.
V. University and Research Institution Barriers: The Academic-to-Industry Chasm
For research compounds originating in academic institutions, an additional set of challenges can impede their commercialization. These barriers often stem from a disconnect between the academic research environment and the commercial drug development world.
A. Funding Gaps and Lack of Commercialization Expertise
Securing funding specifically for the "translational" phase of research—moving a discovery from the lab into preclinical and early clinical development—can be difficult.[15][16] Furthermore, academic researchers may lack the business and entrepreneurial expertise needed to navigate the complexities of intellectual property, licensing, and company formation.[15][17]
B. Institutional Policies and Infrastructure
University policies regarding intellectual property and technology transfer can sometimes be a barrier to commercialization.[15][18] A lack of sufficient infrastructure and industry partnerships can also hinder the translation of promising research into viable products.[15]
Experimental Protocols: A Glimpse into the Methodologies
To provide a more concrete understanding of the experimental rigor involved, below are generalized methodologies for key experiments cited in the drug development process.
Preclinical In Vivo Toxicology Study Protocol
-
Animal Model Selection: Choose a relevant species (e.g., rodent and non-rodent) based on metabolic and physiological similarities to humans for the target pathway.
-
Dose-Range Finding Study: Administer a wide range of single doses to a small number of animals to determine the maximum tolerated dose (MTD) and identify potential target organs for toxicity.
-
Repeated Dose Toxicity Study: Administer the compound daily for a specified duration (e.g., 28 or 90 days) at multiple dose levels (including a control group) to a larger group of animals.
-
Clinical Observations: Monitor animals daily for clinical signs of toxicity, changes in body weight, food and water consumption.
-
Clinical Pathology: Collect blood and urine samples at specified intervals to analyze hematology, clinical chemistry, and urinalysis parameters.
-
Necropsy and Histopathology: At the end of the study, perform a full necropsy and collect a comprehensive set of tissues for microscopic examination by a veterinary pathologist.
Phase I Clinical Trial Protocol (First-in-Human)
-
Study Design: Typically a single-center, dose-escalation study in a small number of healthy volunteers.
-
Inclusion/Exclusion Criteria: Define strict criteria for subject eligibility to ensure a homogenous and healthy study population.
-
Dose Escalation: Start with a very low dose (a fraction of the dose found to be safe in animal studies) and gradually increase the dose in subsequent cohorts of subjects.
-
Safety Monitoring: Continuously monitor subjects for adverse events through physical examinations, vital signs, electrocardiograms (ECGs), and laboratory safety tests.
-
Pharmacokinetic (PK) Analysis: Collect blood and urine samples at frequent intervals after dosing to determine the drug's absorption, distribution, metabolism, and excretion profile.
-
Pharmacodynamic (PD) Analysis (if applicable): Measure biomarkers to assess the drug's effect on the body and its intended target.
Visualizing the Pathways to Failure
The following diagrams, generated using the DOT language, illustrate the complex interplay of factors that can lead to the termination of a research compound's development.
Caption: The Drug Development Pipeline and Key Attrition Points.
Caption: Categorization of Hurdles in Drug Commercialization.
Conclusion
The path from a promising research compound to a commercially available drug is a perilous one, with a high probability of failure at multiple stages. A confluence of scientific, clinical, economic, and regulatory factors contributes to this "valley of death." For researchers, scientists, and drug development professionals, a deep understanding of these potential pitfalls is essential. By anticipating these challenges, adopting rigorous experimental designs, and fostering collaboration between academia and industry, the scientific community can improve the chances of translating groundbreaking discoveries into life-saving therapies.
References
- 1. clinicaltrialrisk.org [clinicaltrialrisk.org]
- 2. Uncertainty in the Translation of Preclinical Experiments to Clinical Trials. Why do Most Phase III Clinical Trials Fail? - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Drug Development Challenges - Improving and Accelerating Therapeutic Development for Nervous System Disorders - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 4. Why do so many promising compounds never become drugs? [understandinganimalresearch.org.uk]
- 5. 90% of drugs fail clinical trials [asbmb.org]
- 6. Why 90% of clinical drug development fails and how to improve it? - PMC [pmc.ncbi.nlm.nih.gov]
- 7. pharmaexcipients.com [pharmaexcipients.com]
- 8. upm-inc.com [upm-inc.com]
- 9. intuitionlabs.ai [intuitionlabs.ai]
- 10. Why clinical trials fail | SCHOTT Pharma [schott-pharma.com]
- 11. Dealing With The Challenges Of Drug Discovery | ZeClinics CRO [zeclinics.com]
- 12. pharmafocusamerica.com [pharmafocusamerica.com]
- 13. uniselinus.us [uniselinus.us]
- 14. pharmexec.com [pharmexec.com]
- 15. A Case Study of the Impediments to the Commercialization of Research at the University of Kentucky - PMC [pmc.ncbi.nlm.nih.gov]
- 16. shs-conferences.org [shs-conferences.org]
- 17. Frontier research – its role in innovation and barriers to successful commercialisation|ERC [erc.europa.eu]
- 18. 4 challenges of public research commercialization [alcimed.com]
An In-depth Technical Guide to Determining the Feasibility of Synthesizing an Unavailable Compound
For researchers, scientists, and drug development professionals, the synthesis of a novel or commercially unavailable compound is a frequent and critical challenge. The decision to embark on such a synthesis requires a rigorous evaluation of its feasibility, a multifaceted process that balances theoretical possibility with practical achievability. This guide provides a comprehensive framework for assessing the viability of a chemical synthesis, from initial computational analysis to final experimental validation.
Retrosynthetic Analysis: Devising the Path Forward
The cornerstone of synthesis planning is retrosynthetic analysis, a problem-solving technique where a target molecule is recursively broken down into simpler, commercially available precursors.[1][2] This process, pioneered by E.J. Corey, allows for the logical design and comparison of multiple synthetic routes.[2]
The primary goal of retrosynthetic analysis is structural simplification.[2] By identifying key bonds and functional groups, a complex target can be disconnected into smaller fragments called synthons. These synthons, which are idealized fragments, are then matched to commercially available synthetic equivalents. This deconstruction is repeated until a pathway from simple, procurable starting materials to the target molecule is established.[1][2] The entire process can be visualized as a "synthesis tree," with the target molecule at the root and potential starting materials at the leaves.
Modern approaches to retrosynthesis often employ computational tools and artificial intelligence.[1][3] These platforms can rapidly search vast reaction databases and predict numerous potential synthetic pathways, augmenting the chemist's intuition and expertise.[4][5]
Thermodynamic and Kinetic Feasibility
A plausible synthetic route on paper does not guarantee success in the laboratory. The feasibility of each proposed reaction step must be assessed from both a thermodynamic and kinetic standpoint.
Thermodynamic Feasibility is governed by the change in Gibbs free energy (ΔG) of a reaction. A reaction is considered thermodynamically favorable, or spontaneous, if ΔG is negative.[6] This indicates that the products are at a lower energy state than the reactants.
Kinetic Feasibility is determined by the activation energy (Ea) of a reaction, which is the energy barrier that must be overcome for the reaction to proceed.[7][8] A reaction with a very high activation energy may be kinetically hindered, proceeding at an impractically slow rate, even if it is thermodynamically favorable.[9]
The interplay between thermodynamics and kinetics is crucial.[10][11][12] Some reactions may yield a less stable kinetic product at lower temperatures and shorter reaction times because it is formed more quickly (lower activation energy).[11][13] At higher temperatures and longer reaction times, the more stable thermodynamic product may be favored as the system has enough energy to overcome the higher activation barrier and reach equilibrium.[11][13]
| Parameter | Description | Typical Range for Feasible Reactions |
| ΔG (Gibbs Free Energy) | Change in free energy; a negative value indicates a spontaneous reaction. | < 0 kcal/mol |
| ΔH (Enthalpy) | Change in heat content; negative for exothermic, positive for endothermic. | Varies widely; exothermic reactions are often favored. |
| Ea (Activation Energy) | The minimum energy required to initiate a reaction. | 15-35 kcal/mol for reactions at or near room temperature.[14] |
| High Ea | Reactions with very high activation energies may require extreme conditions. | > 40-50 kcal/mol, often requiring high temperatures (>250 °C).[14] |
Accessibility of Starting Materials and Cost Analysis
The most elegant synthetic route is impractical if the starting materials are unobtainable or prohibitively expensive. A thorough feasibility study must include an evaluation of the commercial availability, purity, and cost of all necessary precursors and reagents.
Factors to consider include:
-
Supplier Reliability: Are the starting materials available from reputable suppliers in the required quantities?
-
Purity and Characterization: Do the commercially available materials meet the required purity specifications?
-
Cost-Effectiveness: What is the total cost of all materials for the synthesis? This includes not only the starting materials but also solvents, catalysts, and reagents for purification.[15]
A preliminary cost analysis is essential, especially in a drug development context, to ensure the synthesis is economically viable.[16]
| Item | Cost Consideration | Example Price Range (per kg) |
| Common Solvents | (e.g., Acetone, Methanol, Toluene) | $5 - $20 |
| Common Acids/Bases | (e.g., HCl, H2SO4, NaOH) | $4 - $15 |
| Common Salts | (e.g., NaCl, MgSO4) | $6 - $25 |
| Specialized Reagents | (e.g., Organometallic catalysts, chiral ligands) | |
| Building Blocks | Varies dramatically based on complexity and scale. | |
Note: Prices are highly variable and depend on grade, quantity, and supplier. The values above are for illustrative purposes.[17][18][19]
Safety and Hazard Analysis
A critical and non-negotiable aspect of feasibility is a thorough safety assessment.[20] This involves identifying all potential hazards associated with the starting materials, intermediates, products, and reaction conditions. If the hazards of a newly synthesized compound are unknown, it must be treated as hazardous until proven otherwise.[2]
A Process Hazard Analysis (PHA) should be conducted to systematically evaluate potential risks.[21][22] This includes:
-
Chemical Hazards: Toxicity, flammability, reactivity, and corrosivity (B1173158) of all substances.[23]
-
Process Hazards: Risks associated with high pressures, temperatures, or highly exothermic reactions.
-
Byproduct Formation: Potential for the formation of toxic or explosive side products.
-
Waste Disposal: Safe and environmentally responsible disposal of all waste streams.
| Hazard Class | Description | Examples |
| Flammable | Easily ignited and burns rapidly. | Acetone, Diethyl Ether, Hexane |
| Corrosive | Causes visible destruction or irreversible alterations in living tissue. | Sulfuric Acid, Sodium Hydroxide |
| Toxic | Can cause death or serious injury if swallowed, inhaled, or absorbed. | Potassium Cyanide, Mercury Compounds |
| Oxidizer | Can initiate or promote combustion in other materials. | Hydrogen Peroxide, Potassium Permanganate |
| Reactive | Can undergo violent reaction when subjected to shock, heat, or water. | Sodium metal, Picric Acid |
Experimental Validation and Protocols
The final stage of feasibility assessment is experimental validation. This typically begins with small-scale trial reactions to confirm the viability of the proposed steps.[24]
Protocol: Small-Scale Trial Reaction
-
Preparation: Based on the hazard analysis, assemble the appropriate glassware and safety equipment (e.g., fume hood, blast shield). Ensure all glassware is dry and the atmosphere is inert if required.
-
Reagent Calculation: Calculate the required amounts of reactants, solvents, and catalysts for a small scale (e.g., 10-100 mg of the limiting reagent).[24]
-
Reaction Setup: Combine the reagents in the reaction vessel according to the planned procedure (e.g., order of addition, temperature control).
-
Monitoring: Monitor the reaction progress using an appropriate analytical technique, such as Thin Layer Chromatography (TLC), Liquid Chromatography-Mass Spectrometry (LC-MS), or Nuclear Magnetic Resonance (NMR) spectroscopy.
-
Work-up and Isolation: Once the reaction is complete, perform the work-up procedure to quench the reaction and remove byproducts. Isolate the crude product.
-
Analysis: Analyze the crude product to confirm the identity and estimate the yield and purity of the desired compound.
Protocol: Kinetic Analysis by NMR Spectroscopy
-
Sample Preparation: Prepare a stock solution of a non-reactive internal standard in the deuterated solvent to be used for the reaction. Prepare separate solutions of the reactants.
-
Initial Spectra: Acquire a spectrum of the starting materials and the internal standard before initiating the reaction to establish initial concentrations and chemical shifts.[25]
-
Reaction Initiation: In an NMR tube, combine the reactants at a controlled temperature within the NMR spectrometer to start the reaction.
-
Data Acquisition: Acquire a series of 1D NMR spectra at regular time intervals.[26][27][28] The time between spectra should be appropriate for the expected reaction rate.
-
Data Processing: Process the spectra (phasing, baseline correction).
-
Analysis: Integrate the signals corresponding to the starting materials and products relative to the internal standard at each time point. Plot the concentration of reactants and products versus time to determine the reaction rate and order.[29]
Protocol: Thermodynamic Analysis by Reaction Calorimetry
-
System Calibration: Calibrate the reaction calorimeter to determine the overall heat transfer coefficient (UA) of the system.[30] This is typically done by introducing a known amount of heat with an electric heater.
-
Reaction Setup: Charge the calorimeter with the reactants and solvent. Allow the system to reach thermal equilibrium at the desired starting temperature.[31][32][33]
-
Reaction Initiation: Initiate the reaction (e.g., by adding a catalyst or the final reagent).
-
Data Collection: The calorimeter measures the heat flow (rate of heat evolution or absorption) throughout the reaction by maintaining a constant reactor temperature (isothermal mode) or by measuring the temperature change (adiabatic mode).[30]
-
Data Analysis: Integrate the heat flow over time to determine the total heat of reaction (ΔH). This data is crucial for assessing thermal hazards and for scaling up the reaction safely.
Conclusion: The Feasibility Decision
The decision to proceed with the synthesis of an unavailable compound is based on a holistic evaluation of all the factors discussed. A feasible synthetic route is one that is not only theoretically sound but also practical, safe, and economically viable. By systematically applying the principles of retrosynthesis, thermodynamic and kinetic analysis, cost and safety assessment, and experimental validation, researchers can make informed decisions, increasing the likelihood of success while minimizing risks and wasted resources.
References
- 1. researchgate.net [researchgate.net]
- 2. Retrosynthetic analysis - Wikipedia [en.wikipedia.org]
- 3. SA Score for Synthesizability | AI-Driven Synthetic Feasibility Analysis with ChemAIRS® — Chemical.AI – AI for Retrosynthesis & Molecule Synthesis [chemical.ai]
- 4. researchgate.net [researchgate.net]
- 5. impactclimate.mit.edu [impactclimate.mit.edu]
- 6. Ch 10: Kinetic and Thermodynamic Control [chem.ucalgary.ca]
- 7. solubilityofthings.com [solubilityofthings.com]
- 8. chem.libretexts.org [chem.libretexts.org]
- 9. Activation Energy | Research Starters | EBSCO Research [ebsco.com]
- 10. apchem.org [apchem.org]
- 11. Thermodynamic and kinetic reaction control - Wikipedia [en.wikipedia.org]
- 12. jackwestin.com [jackwestin.com]
- 13. Reddit - The heart of the internet [reddit.com]
- 14. Are activation barriers of 50–70 kcal mol −1 accessible for transformations in organic synthesis in solution? - Chemical Science (RSC Publishing) DOI:10.1039/D4SC08243E [pubs.rsc.org]
- 15. scienceready.com.au [scienceready.com.au]
- 16. pubs.acs.org [pubs.acs.org]
- 17. Shop Reagents and Synthesis For Sale, New and Used Prices | LabX.com [labx.com]
- 18. Reddit - The heart of the internet [reddit.com]
- 19. Reddit - The heart of the internet [reddit.com]
- 20. orgsyn.org [orgsyn.org]
- 21. How to Conduct a Process Hazard Analysis: Methods & Steps To Follow [synergenog.com]
- 22. sphera.com [sphera.com]
- 23. researchgate.net [researchgate.net]
- 24. How To Run A Reaction [chem.rochester.edu]
- 25. nmr.chem.ox.ac.uk [nmr.chem.ox.ac.uk]
- 26. imserc.northwestern.edu [imserc.northwestern.edu]
- 27. nmr.chem.columbia.edu [nmr.chem.columbia.edu]
- 28. www2.chem.wisc.edu [www2.chem.wisc.edu]
- 29. ekwan.github.io [ekwan.github.io]
- 30. syrris.com [syrris.com]
- 31. web.williams.edu [web.williams.edu]
- 32. online-learning-college.com [online-learning-college.com]
- 33. Lab Procedure [chem.fsu.edu]
Chloroform: A Historical and Technical Retrospective of a Discontinued Anesthetic
An In-depth Technical Guide for Researchers, Scientists, and Drug Development Professionals
Introduction
Chloroform (B151607) (trichloromethane, CHCl₃) occupies a significant, albeit controversial, chapter in the history of medicine. Once hailed as a miraculous anesthetic, its use rapidly declined due to severe and often fatal toxicities. This technical guide provides a comprehensive overview of the historical context, scientific underpinnings, and eventual discontinuation of chloroform as a clinical reagent. For decades, it was a cornerstone of surgical practice, and its story offers valuable lessons in pharmacology, toxicology, and the evolution of patient safety standards.
Historical Context and Discontinuation
First synthesized in 1831, chloroform's anesthetic properties were famously demonstrated by Scottish obstetrician Sir James Young Simpson in 1847.[1][2][3] Its rapid induction of anesthesia and pleasant odor made it a popular alternative to the more pungent and flammable ether.[2][4] Queen Victoria's use of chloroform during the birth of her eighth child in 1853 further solidified its public acceptance.[1][2]
However, reports of sudden deaths associated with chloroform administration began to surface, with the first recorded fatality being that of 15-year-old Hannah Greener in 1848.[3] The primary reasons for its discontinuation were significant concerns over its narrow therapeutic window and severe adverse effects, including:
-
Cardiac Arrhythmias: Chloroform sensitizes the myocardium to the effects of epinephrine, leading to potentially fatal ventricular fibrillation.[5][6][7][8] This is often referred to as "sudden sniffer's death."
-
Hepatotoxicity: Chloroform is metabolized in the liver to toxic byproducts, primarily phosgene, which can cause centrilobular necrosis and liver failure.[9][10][11] This liver damage could be delayed, appearing 24 to 48 hours after exposure.[12]
-
Respiratory Depression: Overdosing on chloroform can lead to the paralysis of chest muscles and respiratory failure.[1]
By the early 20th century, the medical community began to favor safer alternatives like ether, and with the advent of modern halogenated anesthetics, the use of chloroform in clinical practice was largely abandoned.[1][13]
Physicochemical and Pharmacokinetic Properties
| Property | Value | Reference |
| Chemical Formula | CHCl₃ | [14] |
| Molar Mass | 119.38 g/mol | |
| Appearance | Colorless liquid | [14] |
| Odor | Pleasant, sweet | [14] |
| Boiling Point | 61.2 °C | [15] |
| Solubility in Water | 0.8 g/100 mL at 20 °C | [14] |
| Metabolism | Hepatic (Cytochrome P450) | [14][16] |
| Primary Metabolites | Phosgene, Trichloromethanol | [9][14] |
| Elimination | Primarily exhaled unchanged; metabolites excreted in urine. | [14][16] |
Quantitative Toxicity and Anesthetic Data
The following tables summarize key quantitative data regarding the anesthetic properties and toxicity of chloroform.
Table 1: Anesthetic Concentrations in Humans
| Effect | Concentration (ppm) | Exposure Duration | Reference |
| Dizziness, Nausea | 1,030 | 7 minutes | [17] |
| Light Intoxication | 4,300 - 5,100 | 20 minutes | [17] |
| Anesthesia Induction | 3,000 - 30,000 | minutes | [18] |
| Surgical Anesthesia | 8,500 - 13,000 | Average 112 minutes | [17] |
| Potentially Lethal | 40,000 | Several minutes | [18] |
Table 2: Lethal Dose (LD50) in Animals (Oral)
| Species | LD50 (mg/kg) | Reference |
| Mouse | 36 - 1,366 | [18] |
| Rat | 450 - 2,000 | [18] |
Table 3: Comparative Fatality Rates of Anesthetics (c. 1934)
| Anesthetic | Fatality Rate | Reference |
| Ether | 1 in 14,000 to 1 in 28,000 | [3] |
| Chloroform | 1 in 3,000 to 1 in 6,000 | [3] |
Mechanism of Action and Signaling Pathways
Chloroform's anesthetic effects are believed to be mediated through its interaction with the central nervous system. Like many general anesthetics, it is a positive allosteric modulator of GABA-A receptors.[14] More recent research has elucidated a more complex mechanism involving the disruption of lipid rafts in neuronal cell membranes.
Inhaled anesthetics like chloroform disrupt the localization of phospholipase D2 (PLD2) within these lipid rafts.[19][20] This leads to the production of the signaling lipid phosphatidic acid (PA), which in turn activates TWIK-related K+ (TREK-1) channels.[19][21][22] The activation of these potassium channels results in hyperpolarization of the neuron, making it less likely to fire and contributing to the state of general anesthesia.[21]
The hepatotoxicity of chloroform is primarily due to its metabolism by cytochrome P450 enzymes in the liver.[9][11] This process generates the highly reactive metabolite phosgene. Phosgene can react with cellular macromolecules, leading to oxidative stress, mitochondrial permeability transition, and ultimately, cell death.[9][10]
Experimental Protocols
Historical Administration of Chloroform Anesthesia (c. 19th Century)
This protocol describes the general "open-drop" method and the more advanced method using an inhaler, as developed by John Snow.
1. Open-Drop Method:
-
1.1. Materials: A cloth or sponge, liquid chloroform.
-
1.2. Procedure:
-
1.2.1. The patient is positioned, often lying down.
-
1.2.2. A cloth or sponge is held over the patient's nose and mouth.[4][23]
-
1.2.3. Chloroform is dripped onto the cloth, allowing the patient to inhale the vapors.
-
1.2.4. The administrator continuously monitors the patient's breathing and responsiveness to gauge the depth of anesthesia.
-
1.2.5. The amount of chloroform administered is controlled by the rate of dripping.
-
2. Administration via John Snow's Inhaler:
-
2.1. Materials: John Snow's chloroform inhaler, which included a face mask, a flexible tube, and a canister for chloroform, often with a water bath to regulate temperature.[24][25][26]
-
2.2. Procedure:
-
2.2.1. The face mask is securely placed over the patient's nose and mouth.
-
2.2.2. The administrator controls the concentration of chloroform vapor mixed with air using a stopcock or other regulatory mechanism on the inhaler.[26]
-
2.2.3. The patient inhales the controlled mixture, allowing for a more gradual and potentially safer induction of anesthesia.
-
2.2.4. Continuous monitoring of the patient's vital signs remains crucial.
-
References
- 1. savemyexams.com [savemyexams.com]
- 2. Painless treatments in the 19th century thanks to chloroform [daidalos.blog]
- 3. [History of chloroform anesthesia] - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. civilwarmed.org [civilwarmed.org]
- 5. Ionic mechanisms underlying cardiac toxicity of the organochloride solvent trichloromethane - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. [PDF] Effects of altered heart rate on chloroformepinephrine cardiac arrhythmia. | Semantic Scholar [semanticscholar.org]
- 7. ahajournals.org [ahajournals.org]
- 8. nist.gov [nist.gov]
- 9. tandfonline.com [tandfonline.com]
- 10. Mechanisms of chloroform-induced hepatotoxicity: oxidative stress and mitochondrial permeability transition in freshly isolated mouse hepatocytes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. scialert.net [scialert.net]
- 12. Delayed onset of liver injury after intentional chloroform overdose: a case report and literature review - Acute Medicine Journal [acutemedjournal.co.uk]
- 13. History of general anesthesia - Wikipedia [en.wikipedia.org]
- 14. Chloroform - Wikipedia [en.wikipedia.org]
- 15. CHLOROFORM - Emergency and Continuous Exposure Limits for Selected Airborne Contaminants - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 16. atsdr.cdc.gov [atsdr.cdc.gov]
- 17. Chloroform: Acute Exposure Guideline Levels - Acute Exposure Guideline Levels for Selected Airborne Chemicals - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 18. gov.uk [gov.uk]
- 19. researchgate.net [researchgate.net]
- 20. researchgate.net [researchgate.net]
- 21. Anesthesia Signals Via Cell Membrane Lipids To Cause Sedation [anesthesiologynews.com]
- 22. biorxiv.org [biorxiv.org]
- 23. sciencemuseum.org.uk [sciencemuseum.org.uk]
- 24. Snow's face mask for chloroform anaesthesia | Science Museum Group Collection [collection.sciencemuseumgroup.org.uk]
- 25. Snow-type chloroform inhaler | Science Museum Group Collection [collection.sciencemuseumgroup.org.uk]
- 26. woodlibrarymuseum.org [woodlibrarymuseum.org]
The Hidden Data That Shapes Science: A Technical Guide to the Impact of Unpublished Research
For Researchers, Scientists, and Drug Development Professionals
Introduction
In the pursuit of scientific advancement, the seamless and transparent dissemination of research findings is paramount. However, a significant volume of scientific data remains unpublished, residing in laboratory notebooks, internal reports, and "file drawers." This unpublished data, particularly when it pertains to negative or inconclusive results, introduces a pervasive bias into the scientific literature. This guide provides a technical overview of the profound impact of this hidden data on various research fields, with a specific focus on the critical area of drug development. We will explore the quantitative scale of this issue, detail the methodologies to detect and mitigate its effects, and visualize the complex interplay of factors that contribute to and are affected by unpublished data.
The "File Drawer" Problem: Understanding Publication Bias
Publication bias, often termed the "file drawer problem," is the phenomenon where the outcome of a study influences the decision to publish it. Studies with statistically significant, positive results are more likely to be submitted and accepted for publication than those with non-significant or negative findings. This creates a skewed representation of the evidence in the scientific literature.
Several factors contribute to this bias, including conscious or unconscious decisions by researchers, who may believe that null results are not "interesting," and biases from journal editors and reviewers. The logical flow from experimental design to a biased body of literature is illustrated below.
Caption: Logical flow of publication bias, from results to a skewed body of literature.
Quantitative Impact of Unpublished Data
| Metric | Finding | Implication | Source(s) |
| Unpublished Clinical Trials | Approximately one-third of clinical trials registered on ClinicalTrials.gov remain unpublished two years after completion. | A large volume of clinical trial data is not publicly available to inform clinical practice or future research. | |
| Publication of Positive vs. Negative Results | Studies with positive findings are more than twice as likely to be published as those with negative or null findings. | The published literature is heavily skewed towards positive results, creating an incomplete picture of the evidence. | |
| Impact on Meta-Analyses | A systematic review of meta-analyses found that those that included unpublished data showed a median 15% smaller treatment effect compared to those that only included published data. | Meta-analyses based solely on published literature may overestimate the true effect of an intervention. | |
| Outcome Reporting Bias | In a cohort of clinical trials, outcomes that were statistically significant were more likely to be fully reported than non-significant outcomes. | Selective reporting of favorable outcomes within a published study can further bias the evidence base. |
Consequences for Drug Development
The drug development pipeline is a long, complex, and expensive process. Unpublished data can have severe repercussions at every stage, leading to wasted resources, flawed clinical trial design, and potential patient harm.
-
Preclinical Research: In the early stages of drug discovery, negative results from animal studies or in-vitro experiments are often not published. This can lead to multiple research groups unnecessarily repeating the same failed experiments, wasting time, money, and animal lives.
-
Clinical Trial Design (Phase I-III): When designing a new clinical trial, researchers rely on the existing body of evidence to determine dosage, efficacy endpoints, and sample size. If previous, unpublished trials have shown a lack of efficacy or identified safety concerns for a similar compound, new trials may be designed based on incomplete and overly optimistic data. This can expose participants to unnecessary risks.
-
Regulatory Approval: Regulatory agencies like the FDA require access to all trial data, both positive and negative, for a new drug application. However, the broader scientific community and clinicians do not have this same level of access, leading to a discrepancy between the data available for regulatory approval and the data available to inform clinical practice.
-
Post-Market Surveillance (Phase IV): After a drug is approved, ongoing surveillance is necessary to monitor for rare or long-term side effects. Unpublished data from early trials could contain safety signals that would have been valuable for post-market monitoring.
The following diagram illustrates the points in the drug development workflow that are particularly vulnerable to the influence of unpublished data.
Caption: Impact of unpublished data on the drug development pipeline.
Methodologies for Detecting and Mitigating Publication Bias
While it is impossible to know the full extent of unpublished data, researchers and meta-analysts can use several statistical techniques to detect and potentially adjust for publication bias.
Experimental Protocol: Funnel Plot for Bias Detection
A funnel plot is a scatter plot of the treatment effect from individual studies against a measure of study precision (usually the standard error or sample size).
-
Principle: In the absence of publication bias, the plot should resemble a symmetrical, inverted funnel. Smaller, less precise studies will have more random variation and will be scattered at the bottom of the plot, while larger, more precise studies will be clustered at the top around the true effect size.
-
Methodology:
-
Data Extraction: For each study in a meta-analysis, extract the effect size (e.g., odds ratio, mean difference) and its standard error.
-
Plotting: Plot the effect size on the x-axis and the standard error (with the scale inverted) or sample size on the y-axis.
-
Interpretation: Asymmetry in the funnel plot is an indication of publication bias. A common pattern is the absence of studies in the bottom-left corner of the plot, which would represent small studies with negative or null results.
-
-
Limitations: Funnel plot asymmetry can also be caused by factors other than publication bias, such as heterogeneity between studies or methodological quality.
Experimental Protocol: Trim and Fill Method
The trim and fill method is a non-parametric method used to estimate the number of missing studies due to publication bias and to adjust the overall effect size.
-
Principle: The method identifies and "trims" the smaller studies that are causing asymmetry in the funnel plot. It then calculates a new, adjusted center for the plot and "fills" it by re-inserting the trimmed studies along with their imputed missing counterparts.
-
Methodology:
-
Funnel Plot Asymmetry Test: First, a statistical test (such as Egger's regression test) is used to formally assess the asymmetry of the funnel plot.
-
Trimming: The method iteratively removes the most extreme small studies from the positive side of the plot (assuming positive results are favored).
-
Estimation: A new, adjusted summary effect is calculated based on the remaining, more symmetrical studies.
-
Filling: The trimmed studies are added back to the plot, and for each one, a "missing" study is imputed on the other side of the new summary effect.
-
Final Adjusted Estimate: The final, adjusted summary effect is calculated including both the original and the imputed studies.
-
-
Limitations: The trim and fill method assumes that the missing studies are absent due to their p-values, which may not always be the case. Its performance can be poor when there is a high degree of heterogeneity between studies.
Initiatives for Data Transparency
In response to the challenges posed by unpublished data, several initiatives have been launched to promote greater transparency and data sharing in scientific research.
-
ClinicalTrials.gov: A registry and results database of publicly and privately supported clinical studies conducted around the world. The FDA Amendments Act of 2007 mandates that for certain trials, summary results must be reported to ClinicalTrials.gov within one year of study completion.
-
AllTrials Campaign: An international initiative that calls for all past and present clinical trials to be registered and their full methods and results reported.
-
Data Sharing Platforms: Platforms like the Yale University Open Data Access (YODA) Project and the Clinical Study Data Request (CSDR) portal allow researchers to request access to anonymized, patient-level data from clinical trials.
Conclusion
Unpublished scientific data represents a significant threat to the integrity and efficiency of the research enterprise. By introducing a pervasive publication bias, it can lead to overestimated treatment effects, redundant and wasteful research, and flawed clinical decision-making. For professionals in drug development, the consequences are particularly severe, impacting the entire lifecycle of a therapeutic from preclinical discovery to post-market surveillance. While methodological approaches such as funnel plots and the trim and fill method can help to identify and adjust for bias, the ultimate solution lies in a cultural shift towards greater transparency and a commitment to the principles of open science. Initiatives that mandate the registration and reporting of all clinical trials are a critical step in ensuring that the scientific record is a complete and unbiased reflection of all research conducted.
Technical Guide: Synthesis, Characterization, and Pharmacological Profiling of the Novel Research Chemical Pyrrolidinohexanophenone-4-fluoro (PHP-4F)
For research, scientific, and drug development professionals only.
Disclaimer: This document is intended for informational purposes for a professional audience and does not endorse or encourage the use of this or any other research chemical. The synthesis and handling of such compounds should only be conducted in a controlled laboratory setting by qualified professionals, in compliance with all applicable laws and regulations.
Introduction
Pyrrolidinohexanophenone-4-fluoro (PHP-4F) is a novel synthetic cathinone, structurally related to the pyrovalerone class of stimulants. Its chemical structure suggests potential activity as a monoamine reuptake inhibitor, a class of compounds with significant therapeutic and research interest. This guide provides a comprehensive overview of the synthesis, analytical characterization, and in-vitro and in-vivo pharmacological profiling of PHP-4F.
Chemical Synthesis and Characterization
The synthesis of PHP-4F can be achieved through a multi-step process, beginning with the appropriate precursors. The identity and purity of the final compound are confirmed using a suite of analytical techniques.
Synthesis Workflow
The synthesis of PHP-4F involves a nucleophilic substitution reaction followed by purification. A generalized workflow is depicted below.
Caption: Synthetic pathway for Pyrrolidinohexanophenone-4-fluoro (PHP-4F).
Experimental Protocol: Synthesis of PHP-4F
-
Friedel-Crafts Acylation: To a solution of 1-hexene in a suitable solvent (e.g., dichloromethane) at 0°C, add aluminum chloride. Slowly add 4-fluorobenzoyl chloride and stir the mixture for 2-4 hours, allowing it to warm to room temperature. Quench the reaction with ice-water and extract the organic layer. Dry the organic layer over anhydrous sodium sulfate (B86663) and concentrate under reduced pressure to yield 1-(4-fluorophenyl)hexan-1-one.
-
Alpha-Bromination: Dissolve the intermediate from the previous step in a suitable solvent (e.g., diethyl ether). Add N-bromosuccinimide and a radical initiator (e.g., AIBN). Reflux the mixture for 1-2 hours. Cool the reaction mixture, filter, and concentrate the filtrate to obtain crude 2-bromo-1-(4-fluorophenyl)hexan-1-one.
-
Nucleophilic Substitution: Dissolve the crude bromo-intermediate in a suitable solvent (e.g., acetonitrile). Add an excess of pyrrolidine and a non-nucleophilic base (e.g., triethylamine). Stir the mixture at room temperature for 12-24 hours.
-
Purification: Concentrate the reaction mixture and purify the residue using column chromatography on silica (B1680970) gel with an appropriate eluent system (e.g., a gradient of ethyl acetate (B1210297) in hexanes) to yield pure PHP-4F.
Analytical Characterization
The structure and purity of the synthesized PHP-4F were confirmed using Gas Chromatography-Mass Spectrometry (GC-MS), Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS), and Nuclear Magnetic Resonance (NMR) spectroscopy.
| Parameter | Value |
| Molecular Formula | C₁₆H₂₂FNO |
| Molecular Weight | 263.35 g/mol |
| Purity (GC-MS) | >99% |
| ¹H NMR (CDCl₃, 400 MHz) | Consistent with proposed structure |
| ¹³C NMR (CDCl₃, 100 MHz) | Consistent with proposed structure |
| LC-MS/MS (m/z) | [M+H]⁺ = 264.17 |
In Vitro Pharmacological Profiling
The in vitro pharmacological profile of PHP-4F was assessed to determine its interaction with key molecular targets involved in neurotransmission and potential off-target effects.
Monoamine Transporter Binding and Function
The affinity and functional activity of PHP-4F at the dopamine (B1211576) transporter (DAT), norepinephrine (B1679862) transporter (NET), and serotonin (B10506) transporter (SERT) were evaluated.
-
Membrane Preparation: Prepare crude membrane fractions from HEK293 cells stably expressing human DAT, NET, or SERT.[1]
-
Assay: In a 96-well plate, incubate the cell membranes with a specific radioligand (e.g., [³H]WIN 35,428 for DAT) and varying concentrations of PHP-4F.[1][2]
-
Incubation: Incubate at room temperature for a specified time to reach equilibrium.
-
Termination: Terminate the reaction by rapid filtration through glass fiber filters to separate bound and free radioligand.[1]
-
Detection: Quantify the radioactivity on the filters using a scintillation counter.[2]
-
Data Analysis: Calculate the IC₅₀ value (the concentration of PHP-4F that inhibits 50% of specific radioligand binding) and subsequently the Kᵢ value using the Cheng-Prusoff equation.[2]
-
Cell Culture: Plate HEK293 cells expressing hDAT, hNET, or hSERT in a 96-well plate.
-
Pre-incubation: Pre-incubate the cells with varying concentrations of PHP-4F.
-
Uptake Initiation: Initiate uptake by adding a radiolabeled monoamine (e.g., [³H]dopamine).
-
Termination: Terminate the uptake after a short incubation period by washing with ice-cold buffer.
-
Detection: Lyse the cells and measure the intracellular radioactivity using a scintillation counter.
-
Data Analysis: Determine the IC₅₀ value for the inhibition of monoamine uptake.
| Assay | DAT | NET | SERT |
| Binding Affinity (Kᵢ, nM) | 15.8 | 25.3 | >1000 |
| Uptake Inhibition (IC₅₀, nM) | 28.1 | 42.7 | >1000 |
Safety Pharmacology: hERG Channel Inhibition
The potential for PHP-4F to inhibit the hERG potassium channel, a key indicator of cardiac arrhythmia risk, was assessed.[3][4]
-
Cell Culture: Use HEK293 cells stably expressing the hERG channel.
-
Electrophysiology: Perform whole-cell patch-clamp recordings to measure hERG channel currents.
-
Drug Application: Apply varying concentrations of PHP-4F to the cells while monitoring the current.
-
Data Analysis: Determine the concentration-dependent inhibition of the hERG current and calculate the IC₅₀ value.
| Assay | Result |
| hERG Inhibition (IC₅₀, µM) | >30 |
Metabolic Stability: CYP450 Inhibition
The inhibitory potential of PHP-4F on major cytochrome P450 enzymes was evaluated to assess the risk of drug-drug interactions.[5][6]
-
Incubation: Incubate human liver microsomes with a specific CYP450 substrate and varying concentrations of PHP-4F.[5]
-
Reaction: Initiate the metabolic reaction by adding NADPH.
-
Termination: Stop the reaction after a specified time.
-
Analysis: Quantify the formation of the metabolite using LC-MS/MS.[5]
-
Data Analysis: Calculate the IC₅₀ value for the inhibition of each CYP450 isoform.
| CYP450 Isoform | IC₅₀ (µM) |
| CYP1A2 | >50 |
| CYP2C9 | >50 |
| CYP2C19 | 28.5 |
| CYP2D6 | 15.2 |
| CYP3A4 | >50 |
In Vivo Pharmacological Profiling
The in vivo effects of PHP-4F were investigated in a rodent model to assess its central nervous system activity.
Locomotor Activity
The effect of PHP-4F on spontaneous locomotor activity was evaluated in mice.
-
Acclimation: Acclimate male Swiss-Webster mice to the testing room and locomotor activity chambers.[7]
-
Habituation: Habituate the mice to the chambers for 30 minutes.
-
Administration: Administer either vehicle (saline) or PHP-4F (0.1, 0.3, 1.0, 3.0 mg/kg, i.p.).
-
Recording: Immediately place the mice back into the chambers and record locomotor activity for 60 minutes using an automated activity monitoring system.[7]
-
Data Analysis: Analyze the total distance traveled and other locomotor parameters.
| Dose (mg/kg, i.p.) | Total Distance Traveled (% of Control) |
| Vehicle | 100 ± 8.5 |
| 0.1 | 125 ± 12.1 |
| 0.3 | 210 ± 25.6* |
| 1.0 | 450 ± 55.2 |
| 3.0 | 380 ± 42.8 |
*p < 0.05, **p < 0.01 compared to vehicle
Signaling Pathway and Experimental Workflow Visualization
Caption: Proposed mechanism of PHP-4F-induced locomotor activity.
References
Navigating the Labyrinth: An In-depth Technical Guide to Intellectual Property for Non-Commercial Compounds
For Researchers, Scientists, and Drug Development Professionals
In the realm of scientific discovery, particularly in the development of novel chemical compounds, a thorough understanding of intellectual property (IP) is paramount. For researchers in non-commercial settings such as universities and research institutions, navigating the complexities of IP can be a daunting task. This guide provides a comprehensive technical overview of the core principles of intellectual property as they apply to non-commercial compounds, with a focus on patents, trade secrets, defensive publications, and material transfer agreements (MTAs).
Core Intellectual Property Strategies: A Comparative Overview
The choice of an appropriate IP strategy depends on a multitude of factors including the nature of the invention, its potential for commercialization, institutional policies, and the research objectives. Below is a summary of the primary IP protection mechanisms available for non-commercial compounds.
| IP Strategy | Description | Key Advantages | Key Disadvantages |
| Patents | A legal document granting the inventor exclusive rights to their invention for a limited period, typically 20 years from the filing date.[1] This allows the patent holder to exclude others from making, using, or selling the patented compound or process.[1] | Strong, legally enforceable monopoly. Can be licensed to generate revenue. Facilitates technology transfer and attracts investment. | Costly and time-consuming to obtain and maintain.[2][3] Requires public disclosure of the invention, which becomes public knowledge.[2] |
| Trade Secrets | Confidential information that provides a competitive edge.[4] For a chemical compound, this could include its structure, synthesis method, or a unique formulation. Protection lasts as long as the information is kept secret.[5] | No registration costs or time limits. Protects information that may not be patentable. Avoids public disclosure of the invention. | No protection against independent discovery or reverse engineering.[4][5] Can be expensive to maintain the necessary level of secrecy. |
| Defensive Publication | The intentional public disclosure of an invention to create "prior art," which can prevent others from obtaining a patent on the same invention.[3] | Cost-effective and rapid way to ensure freedom to operate.[2][6] Prevents competitors from patenting the disclosed technology. | Provides no exclusive rights to the inventor.[2] The disclosed information can be freely used by anyone. The disclosure may inadvertently block future patent applications for related inventions. |
| Material Transfer Agreements (MTAs) | Legally binding contracts that govern the transfer of tangible research materials, such as chemical compounds, between institutions for research purposes.[7] | Facilitates the sharing of research materials while protecting the provider's IP rights. Defines the terms of use, including publication rights and ownership of any resulting inventions. | Can be complex and time-consuming to negotiate. May contain restrictive clauses that limit research freedom or future commercialization. |
Quantitative Data on Intellectual Property Strategies
The financial and temporal investment required for IP protection is a critical consideration for non-commercial researchers. The following tables summarize available data on the costs and timelines associated with patenting, as well as key statistics from university technology transfer activities.
Table 2.1: Estimated Costs of Obtaining a Chemical Patent in the United States
| Cost Component | Estimated Cost (Small Entity) | Notes |
| Provisional Patent Application Filing Fee | ~$139 | Provides a one-year "patent pending" status.[8] |
| Non-Provisional Utility Patent Filing Fees (USPTO) | ~$830 | Includes basic filing, search, and examination fees. |
| Attorney Fees for Drafting and Filing | $8,000 - $20,000+ | Varies significantly based on the complexity of the invention.[9] |
| Patent Prosecution (Responding to Office Actions) | $2,300 - $4,000 per response | Often multiple rounds of negotiation with the patent examiner are required.[3] |
| Issue Fee | ~$1,185 | Paid once the patent is allowed.[10] |
| Maintenance Fees (at 3.5, 7.5, and 11.5 years) | $575, $1,450, $2,405 respectively | Required to keep the patent in force.[10] |
| Total Estimated Cost (over lifetime of patent) | $30,000 - $60,000+ | This is an average for a "high technology" invention and can vary widely.[3] |
Table 2.2: Typical Timeline for a U.S. Utility Patent Application
| Stage | Average Time | Notes |
| Filing to First Office Action | 12 - 24 months | The patent examiner's initial review of the application.[11] |
| Response to Office Action | 3 - 6 months | Time for the applicant to respond to the examiner's rejections.[11] |
| Total Time from Filing to Grant | 1 - 3 years | This can be longer for complex inventions or if there are multiple office actions.[12][13] |
| Accelerated Examination (Track One) | ~12 months to final decision | An expedited process available for an additional fee.[11] |
Table 2.3: Selected U.S. University Technology Transfer Statistics (FY 2023)
| Metric | Value | Source |
| Total Research Expenditures | $104 Billion | AUTM 2023 Licensing Survey[6] |
| Invention Disclosures | > 25,000 | AUTM 2023 Licensing Survey[6] |
| New Patent Applications Filed | ~15,000 - 17,000 (estimate based on historical data) | AUTM Surveys[4][14] |
| U.S. Patents Issued | ~3,300 - 3,600 (estimate based on historical data) | AUTM Surveys[4][14] |
| Licenses and Options Executed | ~7,800 | AUTM 2023 Licensing Survey[6] |
| License Income | $3.6 Billion | AUTM 2023 Licensing Survey[6] |
| Startup Companies Formed | ~1,000 | AUTM 2023 Licensing Survey[6] |
Experimental Protocols for Intellectual Property Protection
Thorough and accurate documentation of experimental work is the bedrock of any successful IP strategy. For patent applications in particular, the experimental section must provide enough detail for a person "skilled in the art" to reproduce the invention.[15]
Best Practices for Laboratory Notebooks
A well-maintained laboratory notebook is a critical legal document that can establish the date of invention and inventorship.[16][17]
-
Use a bound notebook with numbered pages. This prevents the removal or insertion of pages.[7][16]
-
Write in permanent ink. Avoid using pencil or erasable ink.[16]
-
Date and sign each entry. It is also advisable to have a knowledgeable witness who is not a co-inventor periodically review and sign the notebook.[7][16]
-
Record all details of your experiments. This includes the purpose, procedure, reagents, equipment, observations, and results, both successful and unsuccessful.[16]
-
Be diligent and timely. Make entries as you perform the work, not days or weeks later.[7]
-
Do not remove pages or use correction fluid. If you make a mistake, cross it out with a single line, and initial and date the correction.[16]
General Structure of an Experimental Section for a Patent
The experimental section of a chemical patent application should be written in the past tense and third person.[18] It should be a concise, step-by-step description of how to make and characterize the claimed compounds.
Example Structure:
-
General Methods: A brief description of the materials and instrumentation used, such as the source of reagents, the type of chromatography, and the models of spectrometers.[19]
-
Synthesis of Intermediates and Final Compounds: For each compound, provide a detailed, step-by-step procedure. Include the amounts of all reagents in both mass/volume and molar equivalents, reaction conditions (temperature, time, atmosphere), and the work-up and purification procedures.[18][20]
-
Characterization Data: For each new compound, provide comprehensive analytical data to confirm its structure and purity. This typically includes:
-
Nuclear Magnetic Resonance (NMR) Spectroscopy (¹H and ¹³C): Report chemical shifts (δ) in ppm, multiplicity (s, d, t, q, m), coupling constants (J) in Hz, and integration. Specify the solvent and the spectrometer frequency.[20][21][22]
-
Mass Spectrometry (MS): Report the mass-to-charge ratio (m/z) of the molecular ion and other significant fragments. Specify the ionization technique (e.g., ESI, CI, EI).[18][23][24]
-
High-Performance Liquid Chromatography (HPLC): Report the retention time, column type, mobile phase composition, flow rate, and detection wavelength. This is crucial for establishing purity.[11][25][26][27][28]
-
Other Data: Depending on the nature of the compound, other data such as infrared (IR) spectroscopy, melting point, elemental analysis, and X-ray crystallography may be included.
-
Example Experimental Protocol: Synthesis and Characterization of "Compound A"
Synthesis of (S)-2-amino-3-(4-hydroxyphenyl)propanoic acid (Compound A)
To a solution of 4-hydroxybenzaldehyde (B117250) (1.22 g, 10.0 mmol) in methanol (B129727) (20 mL) was added ammonium (B1175870) acetate (B1210297) (2.31 g, 30.0 mmol) and nitromethane (B149229) (0.61 g, 10.0 mmol). The mixture was heated to reflux for 2 hours. The solvent was removed under reduced pressure, and the residue was dissolved in ethyl acetate (50 mL). The organic layer was washed with water (2 x 20 mL) and brine (20 mL), dried over anhydrous sodium sulfate, and concentrated in vacuo. The crude product was purified by flash column chromatography on silica (B1680970) gel (eluting with 20% ethyl acetate in hexanes) to afford the intermediate nitroalkene as a yellow solid (1.50 g, 84% yield).
To a solution of the nitroalkene (1.79 g, 10.0 mmol) in a 1:1 mixture of tetrahydrofuran (B95107) and water (40 mL) was added sodium borohydride (B1222165) (0.76 g, 20.0 mmol) portion-wise at 0 °C. The reaction mixture was stirred at room temperature for 4 hours. The reaction was quenched by the addition of 1 M HCl until the pH reached ~2. The aqueous layer was extracted with ethyl acetate (3 x 30 mL). The combined organic layers were washed with brine, dried over anhydrous sodium sulfate, and concentrated to give the crude amino acid. The product was recrystallized from ethanol/water to yield Compound A as a white solid (1.27 g, 70% yield).
Characterization of Compound A:
-
¹H NMR (400 MHz, D₂O): δ 7.15 (d, J = 8.4 Hz, 2H), 6.85 (d, J = 8.4 Hz, 2H), 4.05 (t, J = 6.8 Hz, 1H), 3.20 (dd, J = 14.0, 6.8 Hz, 1H), 3.05 (dd, J = 14.0, 6.8 Hz, 1H).
-
¹³C NMR (100 MHz, D₂O): δ 175.2, 156.8, 131.5, 128.0, 116.2, 56.3, 37.8.
-
HRMS (ESI): m/z [M+H]⁺ calcd for C₉H₁₂NO₃⁺: 182.0761, found 182.0765.
-
HPLC: Retention time = 5.2 min (Column: C18, 4.6 x 150 mm; Mobile Phase: Gradient of 10-90% acetonitrile (B52724) in water with 0.1% formic acid over 15 min; Flow Rate: 1.0 mL/min; Detection: 254 nm). Purity: >98%.
Visualizing IP Decision-Making Workflows
The following diagrams, generated using the DOT language, illustrate logical workflows for navigating key decisions in the intellectual property lifecycle for a non-commercial compound.
Initial IP Strategy Decision Workflow
This workflow outlines the initial decision-making process when a researcher has a potentially valuable non-commercial compound.
References
- 1. Drafting Chemical Patent Applications: Strategies for Dealing with an Absence of Data [gje.com]
- 2. ttconsultants.com [ttconsultants.com]
- 3. Defensive publication or patent application: Which works best? | Dennemeyer.com [dennemeyer.com]
- 4. iptechblog.com [iptechblog.com]
- 5. brownwinick.com [brownwinick.com]
- 6. Defensive Publication: A Low-Cost Supplement to Your Patent Strategy - XLSCOUT [xlscout.ai]
- 7. Research Policies < University of Miami [bulletin.miami.edu]
- 8. Patents and secrets in the chemical industry | Managing Intellectual Property [managingip.com]
- 9. Intellectual Property Policy | Tulane University [tulane.edu]
- 10. questel.com [questel.com]
- 11. patents.justia.com [patents.justia.com]
- 12. US20110202285A1 - Nmr method for differentiating complex mixtures - Google Patents [patents.google.com]
- 13. patentpc.com [patentpc.com]
- 14. policy.nd.edu [policy.nd.edu]
- 15. Disclosure of Experimental Data in Chemical Field Patent Application – Kangxin Intellectual Property Lawyers [en.kangxin.com]
- 16. University Policies | UMD | University of Maryland Intellectual… [policies.umd.edu]
- 17. econstor.eu [econstor.eu]
- 18. benchchem.com [benchchem.com]
- 19. US12334189B2 - System and method for processing experimental data - Google Patents [patents.google.com]
- 20. US7541806B2 - Method for molecule examination by NMR spectroscopy - Google Patents [patents.google.com]
- 21. US8072213B2 - NMR measurement method - Google Patents [patents.google.com]
- 22. US20110210730A1 - Molecular Structure Determination from NMR Spectroscopy - Google Patents [patents.google.com]
- 23. US11162920B2 - Sample preparation for proteomic investigations - Google Patents [patents.google.com]
- 24. US20120145890A1 - Methods And Systems For Mass Spectrometry - Google Patents [patents.google.com]
- 25. conductscience.com [conductscience.com]
- 26. US8975402B2 - HPLC method for the analysis of bosetan and related substances and use of these substances as reference standards and markers - Google Patents [patents.google.com]
- 27. US6413431B1 - HPLC method for purifying organic compounds - Google Patents [patents.google.com]
- 28. WO2019036685A1 - Methods for hplc analysis - Google Patents [patents.google.com]
Navigating the Labyrinth: A Technical Guide to Accessing Proprietary Research Materials
For Researchers, Scientists, and Drug Development Professionals
Introduction
In the pursuit of scientific discovery and the development of novel therapeutics, access to proprietary research materials is often a critical bottleneck. While the open sharing of data and materials is a cornerstone of academic research, the reality is that many essential tools, cell lines, animal models, and chemical compounds are held under patents, copyrights, or trade secrets. This guide provides an in-depth technical overview of the challenges researchers face in accessing these proprietary materials and offers strategies and protocols to navigate this complex landscape. The information presented here is intended to equip researchers, scientists, and drug development professionals with the knowledge to anticipate, mitigate, and overcome barriers to accessing the materials vital for their work.
The Landscape of Proprietary Research Materials
Proprietary research materials encompass a wide range of assets that are owned and controlled by academic institutions, biotechnology companies, and pharmaceutical corporations. Access to these materials is typically governed by legal agreements that dictate the terms of use, distribution, and commercialization of any resulting discoveries. The primary mechanisms for controlling access include:
-
Patents: Granting the owner exclusive rights to an invention for a limited period.
-
Copyrights: Protecting original works of authorship, which can include software and databases.[1]
-
Trade Secrets: Confidential information that provides a competitive edge.[2]
-
Material Transfer Agreements (MTAs): Contracts that govern the transfer of tangible research materials between two organizations.[3]
-
Licensing Agreements: Contracts that grant permission to use a technology or material under specific conditions, often involving fees and royalties.
These control mechanisms are in place to protect the intellectual and financial investments made in developing the research materials. However, they can also create significant hurdles for researchers who need to use them.
Quantitative Analysis of Access Challenges
The challenges in accessing proprietary research materials are not merely anecdotal. While comprehensive global data is difficult to obtain due to the private nature of many agreements, several studies and surveys shed light on the quantitative dimensions of these barriers.
Table 1: Delays in Research due to Material Transfer Agreements (MTAs)
| Study/Report Finding | Average Delay Reported | Impact on Research | Source(s) |
| Negotiations for MTAs with industry | Can take "months or even years" | Significant delays in starting projects. | [4] |
| General MTA processing time | 30 to 45 days for review, with an additional 30 to 45 days for patent applications | Postponement of publications and presentations. | [2] |
| Researcher-reported frustrations | "Tremendous delay" | Critical for time-sensitive research, such as that of postdoctoral fellows. | [3] |
Table 2: Licensing Costs for Proprietary Research Tools
| Technology/Material | Typical Licensing Structure for Academic/Non-Profit Use | Estimated Costs (where available) | Source(s) |
| CRISPR/Cas9 Technology | Often available at no cost for internal academic and non-profit research. Commercial research use requires a license. | A broad, exclusive license could be valued in the range of $100 million to $265 million for commercial entities. | [4][5] |
| Proprietary Cell Lines | One-time license fee or annual renewal fees. | Can range from a few thousand dollars to over $10,000 per cell line for a 10-year license. | [6][7] |
| Expression Systems (e.g., Pichia) | Evaluation kits may be available, but commercial R&D licenses are required. | A commercial R&D license can cost over $50,000, with additional fees and royalties (3-5% of revenues) for commercialized products. | [8] |
| Monoclonal Antibodies (mAbs) | Non-exclusive or narrowly-defined exclusive licenses. | Individual royalty rates are generally modest (3% or lower), but the total royalty burden can be substantial. | [9] |
Experimental Protocols for Accessing Proprietary Materials
While there is no single "experiment" to guarantee access, a systematic and strategic approach can significantly increase the chances of success. The following protocols outline a workflow for researchers to follow when seeking to acquire proprietary materials.
Protocol 1: Pre-Request Assessment and Strategy Development
-
Identify the Material and Provider: Clearly define the specific proprietary material needed and identify the owning institution or company.
-
Assess Criticality: Determine the importance of the material to your research. Are there viable non-proprietary alternatives?
-
Review Existing Agreements: Check if your institution has any existing master agreements or standard MTAs with the provider.
-
Initiate Contact with your Technology Transfer Office (TTO): Early engagement with your institution's TTO is crucial. They can provide guidance on institutional policies and negotiation strategies.
-
Develop a Research Plan Summary: Prepare a concise, non-confidential summary of your proposed research using the material. This will be essential for communicating with the provider.
Protocol 2: Navigating the Material Transfer Agreement (MTA) Process
-
Request the Provider's Standard MTA: Obtain the provider's template agreement as a starting point.
-
TTO Review: Your TTO will review the MTA for problematic clauses, such as:
-
Reach-through rights: Claims on future inventions made using the material.
-
Publication restrictions: Delays or requirements for approval before publishing results.[10]
-
Indemnification and liability clauses: Unreasonable assumption of risk by your institution.
-
Confidentiality obligations: Overly broad or long-lasting confidentiality requirements.
-
-
Negotiation: Your TTO will negotiate any necessary changes with the provider's legal or licensing department. This is often the most time-consuming step.
-
Execution: Once both parties agree on the terms, the MTA is signed by authorized representatives of both institutions.
-
Material Shipment: The provider will ship the material upon receipt of the fully executed MTA.
Protocol 3: Strategies for Responding to Access Denial or Unfavorable Terms
-
Understand the Reason for Denial: If your request is denied, respectfully inquire about the reasons. Common reasons include competitive research interests or a lack of resources to fulfill requests.
-
Propose a Collaboration: If direct transfer is not possible, explore the possibility of a research collaboration where the provider's scientists are involved in the experiments.
-
Seek Alternatives: Re-evaluate non-proprietary alternatives or consider developing the necessary materials in-house if feasible.
-
Utilize Core Facilities or CROs: Some core facilities or contract research organizations (CROs) may have licenses to use certain proprietary technologies that you can access on a fee-for-service basis.
-
Engage with Open Science Initiatives: For certain materials, patient advocacy groups or open science foundations may be able to facilitate access.
Visualizing the Challenges and Workflows
To better understand the complex processes and relationships involved in accessing proprietary research materials, the following diagrams have been created using the Graphviz DOT language.
Conclusion
The challenges of accessing proprietary research materials are a significant and persistent barrier to scientific advancement. These hurdles can lead to substantial delays, increased costs, and in some cases, the abandonment of promising research avenues. For researchers in the fast-paced field of drug development, these delays can have profound consequences.
By understanding the legal and commercial frameworks that govern proprietary materials, and by adopting a strategic and proactive approach to obtaining them, researchers can increase their likelihood of success. Early and continuous communication with your institution's technology transfer office is paramount. Furthermore, a thorough understanding of the terms and potential pitfalls of Material Transfer Agreements and licensing agreements can empower researchers and their institutions to negotiate more favorable terms.
Ultimately, fostering a research ecosystem that balances the legitimate need for intellectual property protection with the imperative for open scientific inquiry will be essential for accelerating the translation of basic research into life-saving therapies. This guide provides a framework for individual researchers to navigate the current landscape, but broader systemic changes, such as the promotion of standardized agreements and open science initiatives, will be necessary to fully address these challenges in the long term.
References
- 1. research.uoregon.edu [research.uoregon.edu]
- 2. AI Review for Material Transfer Agreements [legalontech.com]
- 3. ke.org.uk [ke.org.uk]
- 4. Information about licensing CRISPR systems, including for clinical use | Broad Institute [broadinstitute.org]
- 5. forbes.com [forbes.com]
- 6. utsouthwestern.edu [utsouthwestern.edu]
- 7. bpsbioscience.com [bpsbioscience.com]
- 8. biopharminternational.com [biopharminternational.com]
- 9. Licensing CRISPR - Licensing Executives Society (LES) [members.lesusacanada.org]
- 10. Material Transfer Agreement | Yale Ventures [ventures.yale.edu]
For Researchers, Scientists, and Drug Development Professionals
In the pursuit of scientific discovery and therapeutic innovation, data is the bedrock upon which progress is built. However, the pervasive issue of data unavailability—ranging from completely inaccessible datasets to subtle but significant missing values—casts a long shadow over the integrity and efficiency of scientific research. This guide provides a technical exploration of the multifaceted consequences of data unavailability, offering insights into its quantitative impact, methodological challenges, and the logical frameworks required to mitigate its effects.
Quantitative Impact of Data Unavailability
The absence of data is not a passive issue; it actively undermines the scientific record and carries substantial economic and academic costs. The following tables summarize the quantifiable impacts of data unavailability across different domains of scientific research.
Table 1: Economic Costs of Irreproducible Research Due to Data Unavailability
| Region | Estimated Annual Cost of Irreproducible Preclinical Research | Key Contributing Factors Related to Data Unavailability |
| United States | ~$28 Billion | - Unavailable raw data from original studies- Inadequate reporting of experimental methods- Lack of access to analysis code |
Source: Analysis of preclinical research spending and reproducibility rates suggests a significant portion of these costs can be attributed to the inability to verify or build upon previous work due to unavailable data.[1][2][3][4][5][6]
Table 2: Impact of Data Sharing on Research Visibility and Citation Rates
| Data Sharing Practice | Average Increase in Citations | Notes |
| Publicly archiving data | 9% - 97 additional citations | The wide range reflects variations across disciplines and the stringency of data sharing policies.[7][8][9] |
| Sharing data in an online repository | ~4.3% | Demonstrates a consistent, positive impact on visibility.[8] |
| Articles with stated data availability | ~25% | Indicates that the mere acknowledgment of data availability can enhance research impact.[10] |
Source: Multiple studies have demonstrated a positive correlation between open data practices and the academic impact of research, as measured by citation counts.[7][8][9][10][11][12][13][14]
Table 3: Consequences of Missing Data in Clinical Trials
| Consequence | Quantitative Impact | Implication |
| Loss of Statistical Power | Reduced ability to detect true treatment effects. | Smaller effective sample size can lead to false-negative results, potentially abandoning a promising therapeutic.[15] |
| Biased Treatment Effect Estimates | Over or underestimation of efficacy and safety. | Can lead to incorrect conclusions about a drug's risk-benefit profile.[15][16][17] |
| Loss of Statistical Significance | Up to 33% of trials with significant results lose significance under plausible assumptions about missing data. | Undermines the robustness of clinical trial conclusions.[18] |
| Regulatory Scrutiny and Rejection | FDA and EMA emphasize the need for robust handling of missing data. | Inadequate management of missing data can lead to requests for additional studies or rejection of submissions.[19][20][21] |
Source: The presence of missing data in clinical trials is a major threat to the validity of their outcomes, with regulatory bodies enforcing strict guidelines for its management.[15][16][17][18][19][20][21][22]
Experimental Protocols for Handling Missing Data
The appropriate handling of missing data is crucial for maintaining the integrity of a study. The choice of method depends on the nature of the missing data and the research question. Below are detailed methodologies for key approaches.
Multiple Imputation (MI)
Objective: To create multiple complete datasets by imputing missing values, perform the analysis on each, and then pool the results. This method accounts for the uncertainty of the missing data.[23][24][25]
Protocol:
-
Imputation Step:
-
Choose an imputation model (e.g., regression imputation, predictive mean matching) that is appropriate for the data type and missingness pattern.[23]
-
Generate multiple (typically 3-5) complete datasets by drawing plausible values for the missing data from a distribution.[25] Each imputed dataset will have slightly different values for the missing data points.
-
-
Analysis Step:
-
Perform the planned statistical analysis (e.g., regression, ANOVA) on each of the imputed datasets independently.[23]
-
-
Pooling Step:
-
Combine the results (e.g., parameter estimates, standard errors) from each analysis using Rubin's rules to obtain a single set of estimates and confidence intervals that account for the uncertainty introduced by imputation.[25]
-
Maximum Likelihood Estimation (MLE)
Objective: To estimate model parameters that maximize the likelihood of observing the available data, directly handling missing information without imputation.[23][24]
Protocol:
-
Likelihood Function Specification:
-
Define a statistical model for the complete data.
-
Construct the likelihood function based only on the observed data. This involves integrating the full data likelihood over the possible values of the missing data.
-
-
Parameter Estimation:
-
Use an iterative algorithm, such as the Expectation-Maximization (EM) algorithm, to find the parameter values that maximize the observed data likelihood.[23]
-
E-step (Expectation): Estimate the expected value of the complete data log-likelihood, given the observed data and current parameter estimates.
-
M-step (Maximization): Update the parameter estimates to maximize the expected log-likelihood from the E-step.
-
-
Repeat the E and M steps until the parameter estimates converge.
-
Meta-analysis with Unavailable Primary Study Data
Objective: To synthesize results from multiple studies when some primary data is unavailable, often by extracting summary statistics.[26][27][28][29][30]
Protocol:
-
Systematic Literature Search:
-
Data Extraction:
-
From each included study, extract key summary statistics (e.g., effect sizes, standard errors, sample sizes).[26]
-
If raw data is unavailable, these summary measures become the data points for the meta-analysis.
-
-
Handling Missing Summary Statistics:
-
If a study reports an effect but not its variance, attempt to calculate it from other reported information (e.g., p-values, confidence intervals).
-
If necessary, use imputation methods suitable for meta-analytic data, though this should be done with caution and transparently reported.
-
-
Statistical Synthesis:
-
Choose an appropriate meta-analytic model (e.g., fixed-effect or random-effects model) based on the expected heterogeneity between studies.[28]
-
Pool the extracted effect sizes to calculate a summary effect and its confidence interval.
-
-
Sensitivity Analysis:
-
Assess the robustness of the findings by performing sensitivity analyses, for example, by excluding studies with a high risk of bias or those with imputed data.[18]
-
Visualizing the Consequences of Data Unavailability
The following diagrams, created using the DOT language for Graphviz, illustrate the logical and practical consequences of data unavailability in scientific workflows.
The "Leaky Pipeline" of Drug Discovery
Data unavailability at any stage of the drug discovery pipeline can lead to a cascade of negative consequences, ultimately resulting in failed trials and wasted resources.
Caption: The drug discovery pipeline with points of failure due to data unavailability.
Impact of Missing Data on a Signaling Pathway Analysis
Caption: A hypothetical signaling pathway with complete versus incomplete data.
Experimental Workflow for Handling Missing Data in a Clinical Trial
This diagram outlines a logical workflow for addressing missing data in a clinical trial, from initial assessment to final reporting.
Caption: A decision workflow for handling missing data in clinical research.
Conclusion
References
- 1. The Economics of Reproducibility in Preclinical Research - PMC [pmc.ncbi.nlm.nih.gov]
- 2. ksaqr.medium.com [ksaqr.medium.com]
- 3. researchgate.net [researchgate.net]
- 4. clyte.tech [clyte.tech]
- 5. sciencenews.org [sciencenews.org]
- 6. The Cost of Irreproducible Research | The Scientist [the-scientist.com]
- 7. The Impact of Data Sharing on Article Citations – Berkeley Initiative for Transparency in the Social Sciences [bitss.org]
- 8. An analysis of the effects of sharing research data, code, and preprints on citations | PLOS One [journals.plos.org]
- 9. A study of the impact of data sharing on article citations using journal policies as a natural experiment - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Measuring the Impact of Data Sharing: From Author-Level Metrics to Quantification of Economic and Non-tangible Benefits - PMC [pmc.ncbi.nlm.nih.gov]
- 11. An analysis of the effects of sharing research data, code, and preprints on citations - PMC [pmc.ncbi.nlm.nih.gov]
- 12. The effect of Open Data on Citations â Open Science Impact Indicator Handbook [handbook.pathos-project.eu]
- 13. researchgate.net [researchgate.net]
- 14. Using Publication Metrics to Highlight Academic Productivity and Research Impact - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Assessing the Impact of Missing Data on Clinical Trial Outcomes – Clinical Research Made Simple [clinicalstudies.in]
- 16. Missing Data in Clinical Studies: Issues and Methods - PMC [pmc.ncbi.nlm.nih.gov]
- 17. The impact of different strategies to handle missing data on both precision and bias in a drug safety study: a multidatabase multinational population-based cohort study - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Potential impact of missing outcome data on treatment effects in systematic reviews: imputation study - PMC [pmc.ncbi.nlm.nih.gov]
- 19. The cost of poor data quality in drug development | SEC Life Sciences [seclifesciences.com]
- 20. zenodo.org [zenodo.org]
- 21. digna.ai [digna.ai]
- 22. ccrps.org [ccrps.org]
- 23. Statistical solutions to overcome missing data in clinical trials and observational studies | Editage Insights [editage.com]
- 24. Statistical Methods for Handling Missing Data in Long-term Clinical Research - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 25. quanticate.com [quanticate.com]
- 26. Meta-Analytic Methodology for Basic Research: A Practical Guide - PMC [pmc.ncbi.nlm.nih.gov]
- 27. researchgate.net [researchgate.net]
- 28. Meta-analysis - Wikipedia [en.wikipedia.org]
- 29. Locating unregistered and unreported data for use in a social science systematic review and meta-analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 30. pubrica.com [pubrica.com]
Ethical Considerations for the Use of Non-Public Research Data: A Technical Guide
For Researchers, Scientists, and Drug Development Professionals
The responsible use of non-public research data is a cornerstone of scientific integrity and innovation. This guide provides a technical framework for navigating the complex ethical considerations inherent in accessing, handling, and sharing sensitive research information. Adherence to these principles and protocols is essential for protecting research participants, ensuring data integrity, and fostering public trust in the scientific enterprise.
Quantitative Landscape of Data Security in Research
While specific statistics on the misuse of non-public research data are not always publicly aggregated, data from the broader landscape of data breaches, particularly in sensitive sectors like healthcare, provide crucial context for understanding the risks.
Table 1: Overview of Data Breach Statistics (2024-2025)
| Metric | 2024 | 2025 | Source |
| Global Average Cost of a Data Breach | $4.88 million | $4.44 million | [1] |
| Average Cost of a Healthcare Data Breach | $9.77 million | $7.42 million | [1] |
| Average Time to Identify a Data Breach | 194 days | Not Specified | [1] |
| Average Time to Contain a Data Breach | 64 days | Not Specified | [1] |
Table 2: Researcher Compliance with Data Sharing Statements
| Outcome of Data Sharing Request | Percentage of Researchers | Source |
| Did Not Respond or Declined to Share Data | 93% | [2] |
| Responded to Request | 14% | [2] |
| Provided the Requested Data | 6.8% | [2] |
| Provided Usable Datasets | 6.7% | [2] |
These figures underscore the significant financial and reputational risks associated with data breaches and highlight the challenges in data sharing practices even when intentions are stated.
Core Ethical Principles and Regulatory Frameworks
The use of non-public research data is governed by a set of core ethical principles and a growing body of regulations. Researchers must be well-versed in these frameworks to ensure compliance and ethical conduct.
Key Ethical Principles:
-
Respect for Persons: This principle requires that individuals are treated as autonomous agents and that persons with diminished autonomy are entitled to protection.[3] In the context of data, this translates to obtaining informed consent and respecting participants' decisions.
-
Beneficence: This principle entails an obligation to not only respect the decisions of individuals but also to protect them from harm and to make efforts to secure their well-being.[3] This involves maximizing the potential benefits of research while minimizing potential risks to data subjects.
-
Justice: This principle pertains to the fair distribution of the burdens and benefits of research.[3] It requires that the selection of research participants is equitable and that the risks and benefits of research are distributed fairly.
-
Confidentiality: Safeguarding participants' personal information and data is a fundamental ethical obligation.[3]
Major Regulatory Frameworks:
-
Health Insurance Portability and Accountability Act (HIPAA): In the United States, the HIPAA Privacy Rule establishes national standards to protect individuals' medical records and other identifiable health information.[4]
-
General Data Protection Regulation (GDPR): The GDPR is a regulation in EU law on data protection and privacy for all individuals within the European Union and the European Economic Area.[5] It also addresses the transfer of personal data outside the EU and EEA areas.
-
The Common Rule: This is the primary US federal policy that protects human subjects in research. It outlines the requirements for Institutional Review Boards (IRBs), informed consent, and protections for vulnerable populations.
Methodologies for Data Protection and Controlled Sharing
To adhere to ethical principles and regulatory requirements, researchers must implement robust methodologies for data protection and controlled sharing. These include data de-identification, tiered access systems, and formal data use agreements.
Experimental Protocol: Data De-identification
Data de-identification is a critical process for protecting the privacy of research participants. The goal is to remove or alter identifying information to prevent the association of data with a specific individual. Two primary methodologies are recognized under HIPAA: the Safe Harbor method and the Expert Determination method.
Protocol 1: HIPAA Safe Harbor De-identification
Objective: To remove a specific list of 18 identifiers to render data de-identified.
Procedure:
-
Identify and Remove Direct Identifiers: The following 18 identifiers must be removed from the dataset:
-
Names
-
All geographic subdivisions smaller than a state
-
All elements of dates (except year) directly related to an individual
-
Telephone numbers
-
Fax numbers
-
Electronic mail addresses
-
Social security numbers
-
Medical record numbers
-
Health plan beneficiary numbers
-
Account numbers
-
Certificate/license numbers
-
Vehicle identifiers and serial numbers, including license plate numbers
-
Device identifiers and serial numbers
-
Web Universal Resource Locators (URLs)
-
Internet Protocol (IP) address numbers
-
Biometric identifiers, including finger and voice prints
-
Full face photographic images and any comparable images
-
Any other unique identifying number, characteristic, or code
-
-
Verification: A second researcher or data manager should review the dataset to confirm that all 18 identifiers have been removed.
-
Documentation: Document the de-identification process, including the date and the name of the individual who performed and verified the process.
Protocol 2: Expert Determination Method for De-identification
Objective: To have a qualified expert determine that the risk of re-identification is very small.
Procedure:
-
Engage a Qualified Expert: The expert must have appropriate knowledge of and experience with generally accepted statistical and scientific principles and methods for rendering information not individually identifiable.
-
Risk Assessment: The expert will analyze the dataset to identify potential quasi-identifiers (e.g., age, sex, race) that, in combination, could be used to re-identify an individual. The expert will apply statistical methods to assess the re-identification risk.
-
Data Transformation: Based on the risk assessment, the expert will recommend and oversee the implementation of data transformation techniques such as:
-
Suppression: Removing certain data fields.
-
Generalization: Replacing specific values with more general ones (e.g., replacing a specific age with an age range).
-
Perturbation: Adding random noise to the data.
-
-
Certification: The expert must document the methods used and provide a written certification that the risk of re-identification is very small.
Experimental Protocol: Tiered Data Access System
A tiered access system provides different levels of data access to users based on their role, the sensitivity of the data, and the approved research protocol. This approach allows for broader access to less sensitive data while maintaining strict controls on highly sensitive information.
Protocol 3: Implementation of a Three-Tiered Data Access Model
Objective: To establish a structured framework for data access with varying levels of security and control.
Tier 0: Public Access
-
Data Type: Aggregated data with all individual identifiers removed.[6]
-
Access Mechanism: Publicly accessible website or data portal.[6]
-
User Requirements: No registration or login required.[6]
-
Use Case: General exploration of summary statistics and trends.
Tier 1: Registered Access
-
Data Type: De-identified individual-level data.[6]
-
Access Mechanism: Secure online workbench or data repository.[6]
-
User Requirements: User registration, completion of ethics training, and agreement to a data use code of conduct.[7]
-
Use Case: Approved research projects that do not require access to potentially identifiable information.
Tier 2: Controlled Access
-
Data Type: Pseudonymized or identifiable data, including genomic data or other highly sensitive information.[6]
-
Access Mechanism: Secure, controlled-access data enclave with monitoring and auditing capabilities.[8]
-
User Requirements: In addition to Tier 1 requirements, a formal data access request must be submitted and approved by a Data Access Committee (DAC). A signed Data Use Agreement is required.[9]
-
Use Case: Research that requires access to sensitive, potentially identifiable information for which the benefits of the research outweigh the risks.
Experimental Protocol: Data Use Agreement (DUA)
A Data Use Agreement (DUA) is a legally binding contract that governs the transfer and use of non-public data. It outlines the terms and conditions for data use, confidentiality, and security.
Protocol 4: Establishing a Data Use Agreement
Objective: To create a comprehensive and legally sound agreement for the sharing of non-public research data.
Key Components of a DUA:
-
Parties: Clearly identify the data provider and the data recipient.[10]
-
Data Description: Provide a detailed description of the data being shared, including the level of identifiability.[11]
-
Permitted Uses: Specify the exact research purposes for which the data can be used.[10] Any use outside of this scope should be explicitly prohibited.
-
Data Security: Outline the administrative, physical, and technical safeguards that the recipient must implement to protect the data.[12]
-
Confidentiality and Non-Disclosure: Include provisions that prohibit the recipient from attempting to re-identify individuals and from sharing the data with unauthorized third parties.[13]
-
Publication and Attribution: Specify how the data source should be acknowledged in any publications or presentations.[13]
-
Term and Termination: Define the duration of the agreement and the conditions under which it can be terminated.[11]
-
Data Destruction/Return: Require the recipient to destroy or return the data upon completion of the research or termination of the agreement.[13]
-
Reporting of Breaches: Establish a clear protocol for the recipient to report any data breaches or unauthorized uses to the provider.
-
Signatures: The agreement must be signed by authorized representatives of both parties.
Visualizing Ethical Workflows and Logical Relationships
Diagrams are essential for clearly communicating complex workflows and relationships in the ethical handling of non-public research data. The following diagrams are rendered using the DOT language for Graphviz.
Signaling Pathway for Ethical Data Use
References
- 1. researchgate.net [researchgate.net]
- 2. researchgate.net [researchgate.net]
- 3. acrpnet.org [acrpnet.org]
- 4. medicine.okstate.edu [medicine.okstate.edu]
- 5. ukdataservice.ac.uk [ukdataservice.ac.uk]
- 6. Issues and Challenges Associated with Data Sharing - Principles and Obstacles for Sharing Data from Environmental Health Research - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 7. support.researchallofus.org [support.researchallofus.org]
- 8. Guidance on Secondary Analysis of Existing Data Sets | Office of the Vice President for Research [ovpr.uconn.edu]
- 9. NDA [nda.nih.gov]
- 10. Sample Data Use Agreement - Outcome Measure Harmonization and Data Infrastructure for Patient-Centered Outcomes Research in Depression: Data Use and Governance Toolkit - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 11. cdn1-originals.webdamdb.com [cdn1-originals.webdamdb.com]
- 12. Guidance on External Sharing of Human Subjects Research Data – Human Research Protection Program [irb.wisc.edu]
- 13. clinicalstudydatarequest.com [clinicalstudydatarequest.com]
For Researchers, Scientists, and Drug Development Professionals
In the collaborative landscape of modern scientific research and drug development, the exchange of tangible research materials is a fundamental necessity. Whether it be a novel cell line, a proprietary antibody, or a unique chemical compound, access to specialized research tools developed by others can significantly accelerate discovery and innovation. However, the transfer of these materials is rarely a simple handover. It is governed by a legally binding contract known as a Material Transfer Agreement (MTA). While often viewed as an administrative hurdle, a well-understood and properly navigated MTA is crucial for protecting the interests of both the provider and the recipient, ensuring clarity on intellectual property rights, and fostering a smooth collaborative environment.
This in-depth guide provides researchers, scientists, and drug development professionals with the essential knowledge and tools to effectively navigate the complexities of MTAs. From understanding the core components of an agreement to implementing best practices for negotiation and ensuring the quality of transferred materials, this document serves as a comprehensive resource for streamlining the material transfer process and mitigating potential roadblocks to research.
The Core of Material Transfer Agreements: Purpose and Key Components
A Material Transfer Agreement (MTA) is a legal contract that governs the transfer of tangible research materials between two organizations.[1][2] Its primary purpose is to define the rights and responsibilities of both the provider and the recipient with respect to the transferred materials and any derivatives.[2] MTAs are essential for protecting intellectual property, ensuring the appropriate use of materials, and facilitating the sharing that is critical for scientific progress.[3]
Key Components of a Typical MTA:
A well-drafted MTA will address several critical aspects of the material transfer. While the specific clauses can vary, the following components are almost always included:
-
Definition of "Material": This clause precisely defines the material being transferred, including any associated data and confidential information. It is crucial to be specific to avoid future disputes.
-
Scope of Use: The agreement will clearly outline the permitted research use of the material by the recipient. This often restricts the use to non-commercial research purposes and within a specific research project.
-
Intellectual Property Rights: This is often the most heavily negotiated section. It clarifies the ownership of the original material, as well as any modifications or inventions that arise from its use. "Reach-through" rights, where the provider claims ownership or rights to new inventions made by the recipient using the material, are a particularly contentious issue.[4][5]
-
Publication Rights: MTAs typically address the recipient's right to publish research findings. Providers may request a period for review prior to publication to protect confidential information or file for patents.[6]
-
Confidentiality: If the transferred material is accompanied by confidential information, the MTA will include provisions to protect this information from unauthorized disclosure.[6]
-
Liability and Warranty: These clauses typically state that the material is experimental and provided "as is," with the recipient assuming all liability for its use.[3]
-
Termination: This section outlines the conditions under which the agreement can be terminated and the obligations of the recipient upon termination, such as returning or destroying the material.[3]
The MTA Process: A Step-by-Step Workflow
Navigating the MTA process can seem daunting, but understanding the typical workflow can help manage expectations and streamline the procedure. The process generally involves several key stages, from initial request to final execution of the agreement.
Quantitative Insights into MTA Negotiations
While precise, universally applicable statistics on MTA negotiations are challenging to compile due to the variability between institutions and agreements, available data and reports provide valuable insights into common timelines and points of contention.
Table 1: Factors Influencing MTA Negotiation Timelines
| Factor | Description | Impact on Timeline |
| Type of Provider | Transfers from for-profit companies to academic institutions often involve more complex negotiations due to differing intellectual property and commercialization interests.[7] | Significant Delay |
| Intellectual Property Clauses | Disputes over ownership of inventions, "reach-through" rights, and licensing options are a primary cause of prolonged negotiations.[4] | Significant Delay |
| Publication Restrictions | Clauses that give the provider control over publication or require lengthy review periods can be a major point of contention for academic researchers.[6] | Moderate to Significant Delay |
| Use of Standard Agreements | The use of standardized agreements like the Uniform Biological Material Transfer Agreement (UBMTA) can significantly expedite the process between signatory institutions.[1][8] | Expedited Process |
| Institutional Policies | Conflicting institutional policies on issues such as indemnification and governing law can lead to delays. | Moderate Delay |
A survey conducted by the Association of University Technology Managers (AUTM) revealed that in 2008, approximately 26% of MTAs resulted in negotiations lasting more than one month, and 8% of all material requests led to research stoppages of over a month.[4] While this data is from over a decade ago, the underlying issues often remain relevant today.
Table 2: Most Frequently Negotiated MTA Clauses
| Clause | Key Issues of Contention |
| Intellectual Property | - Ownership of derivatives and modifications. - "Reach-through" rights to future inventions. - Options for commercial licenses. |
| Publication | - Delays for provider review. - Requirement for provider consent to publish. - Co-authorship demands. |
| Confidentiality | - Scope of confidential information. - Duration of confidentiality obligations. |
| Liability & Indemnification | - Extent of recipient's liability. - Provider's refusal to accept any liability. |
| Governing Law & Jurisdiction | - Disagreements over which state's or country's laws will apply in case of a dispute. |
Essential Experimental Protocols for Transferred Research Tools
Receiving a research material is only the first step; verifying its identity, purity, and functionality is critical for the integrity of your research. The following sections provide detailed methodologies for key experiments associated with common types of transferred materials.
Cell Line Authentication and Characterization
The misidentification and cross-contamination of cell lines are significant problems in biomedical research. Therefore, it is imperative to authenticate any new cell line upon receipt.
Protocol: Short Tandem Repeat (STR) Profiling for Human Cell Line Authentication
The current gold standard for authenticating human cell lines is Short Tandem Repeat (STR) profiling.[3] This method compares the STR profile of the received cell line to a reference database.
-
DNA Extraction:
-
Culture a small population of the received cells.
-
Harvest the cells and extract genomic DNA using a commercially available kit, following the manufacturer's instructions.
-
Quantify the DNA concentration and assess its purity using a spectrophotometer.
-
-
PCR Amplification of STR Loci:
-
Use a commercial STR profiling kit that amplifies at least the core set of 13 STR loci (CSF1PO, D3S1358, D5S818, D7S820, D8S1179, D13S317, D16S539, D18S51, D21S11, FGA, TH01, TPOX, and vWA) plus Amelogenin for sex determination.[9]
-
Set up the PCR reaction according to the kit's protocol, including positive and negative controls.
-
Perform PCR amplification using a thermal cycler with the recommended cycling conditions.
-
-
Fragment Analysis:
-
The fluorescently labeled PCR products are separated by size using capillary electrophoresis.
-
The resulting data is analyzed using specialized software to determine the alleles present at each STR locus.
-
-
Data Comparison and Authentication:
-
Compare the generated STR profile to the reference STR profile of the expected cell line from a reputable cell bank or database (e.g., ATCC, Cellosaurus).[10]
-
An 80% or greater match between the query and reference profiles is generally considered an authenticated match.
-
Validation of Research Antibodies
The specificity and functionality of antibodies can vary significantly between batches and suppliers. Proper validation is crucial to ensure that an antibody specifically recognizes its intended target in the context of your experiments.
Protocol: Western Blotting for Antibody Specificity
Western blotting is a common method to assess an antibody's ability to detect its target protein at the correct molecular weight.
-
Sample Preparation:
-
Prepare protein lysates from cells or tissues known to express (positive control) and not express (negative control) the target protein. Knockout or siRNA-treated cells are ideal negative controls.[11]
-
Quantify the protein concentration of the lysates using a standard protein assay (e.g., BCA assay).
-
-
SDS-PAGE and Protein Transfer:
-
Separate 20-30 µg of protein lysate per lane on an SDS-polyacrylamide gel.
-
Transfer the separated proteins to a nitrocellulose or PVDF membrane.
-
-
Immunoblotting:
-
Block the membrane with a suitable blocking buffer (e.g., 5% non-fat milk or BSA in TBST) for 1 hour at room temperature.
-
Incubate the membrane with the primary antibody at the recommended dilution overnight at 4°C.
-
Wash the membrane three times with TBST for 10 minutes each.
-
Incubate with a horseradish peroxidase (HRP)-conjugated secondary antibody for 1 hour at room temperature.
-
Wash the membrane again as in the previous step.
-
-
Detection and Analysis:
-
Apply an enhanced chemiluminescence (ECL) substrate to the membrane.
-
Image the resulting signal using a chemiluminescence imager.
-
A specific antibody should produce a single band at the expected molecular weight of the target protein in the positive control lane and no band in the negative control lane.
-
Genetic Verification of Transgenic Mouse Models
It is essential to confirm the presence and zygosity of a transgene in mouse models received from another institution.
Protocol: PCR-Based Genotyping of Transgenic Mice
This protocol provides a rapid and reliable method for identifying the presence of a transgene in genomic DNA isolated from a mouse tail snip.
-
Genomic DNA Extraction:
-
Collect a small tail snip (1-2 mm) from the mouse.
-
Digest the tissue with Proteinase K in a lysis buffer overnight at 55°C.
-
Inactivate the Proteinase K by heating at 95°C for 10 minutes.
-
Centrifuge the lysate to pellet debris and use the supernatant containing the genomic DNA for PCR.
-
-
PCR Amplification:
-
Design primers specific to the transgene sequence. It is also recommended to include a second set of primers for an endogenous mouse gene as an internal positive control.
-
Set up the PCR reaction with the genomic DNA, transgene-specific primers, internal control primers, and a PCR master mix. Include positive (known transgenic DNA), negative (wild-type DNA), and no-template controls.
-
Perform PCR using a thermal cycler with optimized cycling conditions for your primers.
-
-
Agarose (B213101) Gel Electrophoresis:
-
Run the PCR products on a 1-2% agarose gel containing a DNA stain (e.g., ethidium (B1194527) bromide or SYBR Safe).
-
Include a DNA ladder to determine the size of the PCR products.
-
-
Analysis:
-
Visualize the DNA bands under UV light.
-
A transgenic mouse will show a band for both the transgene and the internal control. A wild-type mouse will only show the internal control band. The zygosity (hemizygous vs. homozygous) can sometimes be determined by quantitative PCR or by designing a three-primer assay.[5]
-
Quality Control of Transferred Chemical Compounds
For drug discovery research, ensuring the identity, purity, and stability of a transferred chemical compound is paramount.
Protocol: HPLC and LC-MS for Compound Quality Control
High-Performance Liquid Chromatography (HPLC) coupled with Mass Spectrometry (LC-MS) is a powerful technique for assessing the purity and confirming the identity of small molecules.
-
Sample Preparation:
-
Accurately weigh a small amount of the compound and dissolve it in a suitable solvent to a known concentration (e.g., 1 mg/mL).
-
Filter the solution through a 0.22 µm syringe filter.
-
-
HPLC Analysis for Purity:
-
Inject the sample onto an appropriate HPLC column (e.g., C18).
-
Run a gradient elution method with a suitable mobile phase (e.g., water and acetonitrile (B52724) with 0.1% formic acid).
-
Detect the eluting compounds using a UV detector at an appropriate wavelength.
-
The purity of the compound is determined by the area percentage of the main peak relative to the total area of all peaks.
-
-
LC-MS Analysis for Identity Confirmation:
-
The eluent from the HPLC is directed into a mass spectrometer.
-
Acquire the mass spectrum of the main peak.
-
The observed molecular weight should match the expected molecular weight of the compound.
-
Verification of Plasmids and Vectors
Before using a received plasmid for cloning or transfection, it is crucial to verify its identity and integrity.
Protocol: Restriction Enzyme Digestion and Sanger Sequencing
-
Plasmid DNA Preparation:
-
Transform the plasmid into a suitable E. coli strain and grow an overnight culture.
-
Isolate the plasmid DNA using a miniprep kit.
-
Quantify the DNA concentration.
-
-
Restriction Enzyme Digestion:
-
Choose one or more restriction enzymes that will produce a predictable and diagnostic pattern of DNA fragments based on the known plasmid map.
-
Digest the plasmid DNA with the chosen enzyme(s) according to the manufacturer's protocol.
-
Run the digested DNA on an agarose gel alongside an uncut plasmid control and a DNA ladder.
-
The observed fragment sizes should match the expected sizes from the in silico digestion of the plasmid map.[12]
-
-
Sanger Sequencing:
-
For definitive verification, sequence key regions of the plasmid, such as the insert and promoter regions.
-
Design sequencing primers that anneal upstream of the region of interest.
-
Send the plasmid DNA and sequencing primers to a commercial sequencing facility.
-
Align the resulting sequence data with the expected reference sequence to confirm the absence of mutations.
-
Best Practices for a Smooth Material Transfer
To facilitate a timely and successful material transfer, researchers and their institutions should adhere to several best practices:
-
Initiate the MTA Process Early: Do not wait until the material is immediately needed to start the MTA process, as negotiations can take time.
-
Provide Complete and Accurate Information: When submitting an internal MTA request, provide all necessary details about the material, the provider, and the intended research to your technology transfer office.
-
Understand Your Institution's Policies: Be aware of your institution's stance on key issues like intellectual property and publication rights.
-
Communicate with Your Technology Transfer Office: Maintain open communication with your TTO throughout the negotiation process. They are your advocates and can provide valuable guidance.
-
Consider Standard Agreements: Whenever possible, encourage the use of the UBMTA or other standardized agreements to simplify and expedite the process.[1]
-
Perform Due Diligence on Received Materials: Always validate the identity and quality of received materials before incorporating them into your research.
By understanding the intricacies of Material Transfer Agreements and implementing these best practices, researchers can navigate this critical aspect of scientific collaboration with greater efficiency and confidence, ultimately accelerating the pace of discovery and innovation.
References
- 1. AI Review for Material Transfer Agreements [legalontech.com]
- 2. Material Transfer Agreements Clause Samples | Law Insider [lawinsider.com]
- 3. Cell Line Identification and Authentication: Human Cell Lines Standards and Protocols | NIST [nist.gov]
- 4. academic.oup.com [academic.oup.com]
- 5. biorxiv.org [biorxiv.org]
- 6. What are some potential issues in MTAs? | Intellectual Property & Industry Research Alliances [ipira.berkeley.edu]
- 7. researchservices.cornell.edu [researchservices.cornell.edu]
- 8. chromatographyonline.com [chromatographyonline.com]
- 9. medschool.cuanschutz.edu [medschool.cuanschutz.edu]
- 10. iclac.org [iclac.org]
- 11. neobiotechnologies.com [neobiotechnologies.com]
- 12. blog.addgene.org [blog.addgene.org]
For researchers and drug development professionals, obtaining a specific, non-commercially available chemical compound is a frequent and significant hurdle. When a compound is critical for research but cannot be purchased, the most viable path forward is often to identify a laboratory that has previously synthesized it. This guide provides a systematic, in-depth approach to locating these labs, collating the necessary data, and initiating contact.
The Search Strategy: A Multi-Pronged Approach
Identifying the origin of a synthesized compound requires a thorough search of scientific and patent literature. No single database is exhaustive, so a multi-pronged strategy is essential for comprehensive coverage.
1.1. Scientific Literature Databases The primary source for identifying synthesis information is peer-reviewed scientific literature. Key databases include:
-
CAS SciFinder-n® : A comprehensive and authoritative source for chemical literature, allowing searches by chemical structure, reaction, and topic. Its extensive database is considered an indispensable resource for chemists.[1]
-
Reaxys® : A powerful tool that combines chemical substance, reaction, and property data with synthesis planning. It is highly recommended for finding synthesis references and provides detailed reaction diagrams.[2][3]
-
Google Scholar : A broadly accessible tool for searching scholarly literature across many disciplines. It's a good starting point and can help identify relevant papers and authors.[4]
-
PubChem : The world's largest free collection of chemical information, it links chemical structures to literature, patents, and biological activities.[5]
1.2. Patent Databases For compounds with potential therapeutic or industrial applications, patent literature is a critical resource. Many novel compounds are first disclosed in patents.
-
PATENTSCOPE (WIPO) : Provides access to international Patent Cooperation Treaty (PCT) applications and patent documents from numerous national and regional offices.[6]
-
SciFinder-n® and Reaxys® : Both offer robust patent search capabilities, often indexing chemical structures within patents that text-based searches might miss.[1][3]
-
SureChEMBL : A free database that provides access to chemical data extracted from the full text of patents.[7]
-
Google Patents : A free and accessible search engine covering patents from major patent offices worldwide.
1.3. Chemical Synthesis Databases Specialized databases focus specifically on chemical reactions and synthesis, often providing direct links to the researchers who developed them.
-
ChemSynthesis : A free database containing over 40,000 compounds with synthesis references and physical properties.[8][9]
-
SynArchive : A free, web-based database of organic syntheses that clearly presents reaction sequences.[10]
-
Open Reaction Database : An open-access project aimed at supporting machine learning and synthesis planning with a large collection of chemical reactions.[11]
From Publication to People: Identifying the Core Research Group
Once a relevant publication or patent is found, the next step is to identify the specific individuals and the laboratory responsible for the work.
-
Affiliations : The author affiliations section lists the university, research institute, or company where the work was conducted.
-
Researcher Profiles : Use tools like ORCID (Open Researcher and Contributor ID)[12][13], ResearchGate, and Google Scholar Profiles to find more information about the authors, their current institution, and their full publication history. These platforms help distinguish between researchers with similar names and provide a persistent link to their work.[14][15]
Data Collation and Analysis
Systematically organizing the information you find is crucial for evaluation and comparison.
Quantitative Data Summary When reviewing publications, extract all relevant quantitative data related to the synthesis. This data is critical for assessing the feasibility and reproducibility of the protocol. Summarize this information in a structured table.
Table 1: Summary of Synthesis Data for [Compound Name]
| Metric | Source 1 (e.g., Smith et al., 2021) | Source 2 (e.g., Jones et al., 2019) | Source 3 (Patent WO/2020/12345) |
| Publication/Patent ID | J. Org. Chem. 86, 1234-1240 | US Patent 10,123,456 B2 | EP 1234567 A1 |
| Overall Yield (%) | 45% | 62% | Not specified |
| Number of Steps | 8 | 6 | 7 |
| Final Purity (%) | >98% (HPLC) | 99.5% (qNMR) | >95% (LC-MS) |
| Key Starting Materials | Commercially Available | Requires 2-step prep | Readily Available |
| Spectroscopic Data | ¹H NMR, ¹³C NMR, HRMS | ¹H NMR, ¹³C NMR, HRMS, IR | ¹H NMR, MS |
| Corresponding Author | Dr. Jane Smith | Dr. Robert Jones | Dr. Emily White |
| Institution | University of Chemistry | PharmaCorp Inc. | Global Chem Solutions |
Experimental Protocols The "Experimental Section" or "Materials and Methods" section of a research paper contains the detailed, step-by-step procedure for the synthesis.
-
Document Every Step : Carefully transcribe the full experimental protocol, including reagent quantities, reaction times, temperatures, purification methods (e.g., column chromatography, recrystallization), and characterization data.
-
Note Safety Information : Pay close attention to any safety warnings or specialized handling procedures mentioned for reagents or intermediates.
-
Cross-Reference Supporting Information : Often, the most detailed procedures and full characterization data are found in the Supporting Information (SI) file associated with the publication.
Visualizing the Workflow
Diagrams can clarify complex search strategies and decision-making processes. The following workflows are rendered using Graphviz and adhere to specified formatting rules.
Making Contact: Professional Outreach
Approaching a research lab requires professionalism and clarity. Cold emailing can be effective if done correctly.[16]
Best Practices for Emailing a Principal Investigator (PI):
-
Be Specific and Prepared : Do your homework on their research.[17] Your email should demonstrate a genuine understanding of their work.
-
Clear Subject Line : Use a concise and informative subject line, e.g., "Inquiry Regarding Synthesis of [Compound Name] from your 2021 JOC paper".
-
Introduce Yourself Clearly : State who you are, your institution, and the purpose of your research.[18]
-
State Your Request Directly : Clearly articulate what you are asking for. This could be a request for a small sample of the compound, advice on a tricky synthetic step, or a potential collaboration.[19]
-
Attach Your CV : For credibility, attach your curriculum vitae or a link to your professional profile.[16]
-
Be Patient and Respectful : PIs are extremely busy. If you don't receive a reply, a polite follow-up email after a week or two is acceptable. Do not take a lack of response personally.[20]
By following this structured guide, researchers can efficiently navigate the scientific landscape to identify the key laboratories and scientists who have successfully synthesized a target compound, ultimately accelerating their own research and development timelines.
References
- 1. CAS SciFinder - Chemical Compound Database | CAS [cas.org]
- 2. Finding a Method of Synthesis | Organic Chemistry Lab Literature Searching Assignment | Chemistry Research | Guides & Recommendations | NC State University Libraries [lib.ncsu.edu]
- 3. patsnap.com [patsnap.com]
- 4. amberscript.com [amberscript.com]
- 5. List of useful databases | Chemistry Library [library.ch.cam.ac.uk]
- 6. PATENTSCOPE [wipo.int]
- 7. researchgate.net [researchgate.net]
- 8. chemsynthesis.com [chemsynthesis.com]
- 9. Sixty-Four Free Chemistry Databases | Depth-First [depth-first.com]
- 10. synarchive.com [synarchive.com]
- 11. Welcome to the Open Reaction Database! — Open Reaction Database documentation [docs.open-reaction-database.org]
- 12. 7 Useful Research Profiling Tools Every Researcher Must Know [researcherssite.com]
- 13. ORCID for Researchers - ORCID [info.orcid.org]
- 14. researchgate.net [researchgate.net]
- 15. accessola.com [accessola.com]
- 16. How to Find a Lab and Cold Emailing Tips: an IRB perspective | 2025 | IRB Blog | Institutional Review Board | Teachers College, Columbia University [tc.columbia.edu]
- 17. The Do’s and Don’ts of Contacting Professors about Research | SENR [senr.osu.edu]
- 18. michaelsylee.wordpress.com [michaelsylee.wordpress.com]
- 19. academia.stackexchange.com [academia.stackexchange.com]
- 20. reddit.com [reddit.com]
An In-depth Technical Guide to 1-Benzyl-1H-pyrazole (CAS Number: 10199-67-4)
For Researchers, Scientists, and Drug Development Professionals
Abstract
This technical guide provides a comprehensive overview of 1-benzyl-1H-pyrazole (CAS No. 10199-67-4), a versatile heterocyclic compound with significant applications in organic synthesis and drug discovery. This document details its commercial availability, physicochemical properties, and key experimental protocols for its synthesis and derivatization. Furthermore, it explores the biological significance of the 1-benzyl-pyrazole scaffold, highlighting its role in the development of novel therapeutic agents. A key signaling pathway influenced by a derivative of this compound is illustrated to provide context for its potential pharmacological applications.
Commercial Availability and Supplier Information
1-Benzyl-1H-pyrazole is commercially available from various chemical suppliers. It is typically offered in research quantities, ranging from grams to kilograms, with purities generally exceeding 95%. This compound is primarily intended for research and development purposes, including as a building block in the synthesis of more complex molecules such as pharmaceuticals, dyes, and pesticides.[1] When purchasing, it is crucial to obtain and review the Safety Data Sheet (SDS) from the supplier for detailed handling and safety information.
Physicochemical and Spectroscopic Data
The following tables summarize the key quantitative data for 1-benzyl-1H-pyrazole and its parent compound, pyrazole (B372694), for comparative purposes.
Table 1: Physicochemical Properties
| Property | 1-Benzyl-1H-pyrazole (CAS: 10199-67-4) | Pyrazole (CAS: 288-13-1) |
| Molecular Formula | C₁₀H₁₀N₂[2] | C₃H₄N₂[3][4] |
| Molecular Weight | 158.20 g/mol [2] | 68.08 g/mol [3] |
| Appearance | Not specified; likely a liquid or low-melting solid | Colorless to pale yellow crystalline solid[5] |
| Boiling Point | Not specified | 186-188 °C[4] |
| Melting Point | Not specified | 67-70 °C[4] |
| Solubility | Not specified | Soluble in water, alcohol, ether, and benzene[4] |
| Purity | ≥96% (typical)[2] | ≥98% (typical) |
Table 2: Spectroscopic Data for 1-Benzyl-1H-pyrazole (CAS: 10199-67-4)
| Spectrum Type | Solvent | Key Chemical Shifts (δ, ppm) |
| ¹³C NMR | CDCl₃ | 138.9, 137.2, 128.9, 127.5, 126.5, 105.7, 52.5[6] |
Applications in Research and Development
1-Benzyl-1H-pyrazole serves as a crucial intermediate in the synthesis of a wide array of functionalized molecules. The pyrazole core is a well-established pharmacophore found in numerous FDA-approved drugs. The benzyl (B1604629) group at the N1 position can be instrumental in establishing hydrophobic interactions within the binding sites of biological targets, making this scaffold particularly attractive for medicinal chemistry.
Derivatives of 1-benzyl-1H-pyrazole have been investigated for various therapeutic applications, including as anticancer and antidiabetic agents. For instance, N-(1-benzyl-3,5-dimethyl-1H-pyrazol-4-yl)benzamides have shown potent antiproliferative activity and have been identified as modulators of the mTORC1 signaling pathway and autophagy.[7] Additionally, derivatives of the related 1-benzyl-4-bromo-1H-pyrazole have demonstrated potent inhibitory activity against Receptor Interacting Protein 1 (RIP1) kinase, a key mediator of necroptosis.
Table 3: Biological Activity of 1-Benzyl-pyrazole Derivatives
| Derivative Class | Target/Activity | Quantitative Data | Reference |
| N-(1-benzyl-3,5-dimethyl-1H-pyrazol-4-yl)benzamides | Antiproliferative (MIA PaCa-2 cells) | Submicromolar activity | [7] |
| 4-(aminomethyl)phenyl derivative of 1-benzyl-4-bromo-1H-pyrazole | RIP1 Kinase Inhibition | K_d_ = 0.078 µM | [8] |
| 4-(aminomethyl)phenyl derivative of 1-benzyl-4-bromo-1H-pyrazole | Cellular Necroptosis Inhibition | EC₅₀ = 0.160 µM | [8] |
| 3-benzyl-N-phenyl-1H-pyrazole-5-carboxamides | Glucose-Stimulated Insulin (B600854) Secretion | - | [9] |
Experimental Protocols
The following are representative experimental protocols for the synthesis of 1-benzyl-pyrazole derivatives. These methods can be adapted for the synthesis of the parent compound and other analogues.
General Procedure for the Synthesis of 1-Benzyl-3,5-disubstituted-pyrazoles
This protocol describes a catalytic method for the synthesis of pyrazole derivatives.
Materials:
-
1,3-dicarbonyl compound (1.0 mmol)
-
Benzylhydrazine (B1204620) (1.0 mmol)
-
Ethanol (B145695) (10 mL)
-
[Ce(L-Pro)₂]₂(Oxa) catalyst (5 mol%)
Procedure:
-
In a 25 mL round-bottomed flask, dissolve the 1,3-dicarbonyl compound (1.0 mmol) and benzylhydrazine (1.0 mmol) in ethanol (10 mL).
-
Add a catalytic amount of [Ce(L-Pro)₂]₂(Oxa) (5 mol%) to the mixture.
-
Stir the reaction mixture at room temperature.
-
Monitor the progress of the reaction by Thin Layer Chromatography (TLC).
-
Upon completion, filter the catalyst from the reaction mixture.
-
Evaporate the solvent under reduced pressure.
-
Purify the crude product by column chromatography on silica (B1680970) gel to obtain the desired 1-benzyl-pyrazole derivative.[6]
Preparation of 1-Benzyl-3-phenyl-1H-pyrazole
This protocol outlines a method for the synthesis of a specific 1,3-disubstituted benzylpyrazole.
Materials:
-
Cinnamaldehyde (B126680) (1.0 mmol)
-
p-Toluenesulfonyl hydrazide (TsNHNH₂) (1.1 mmol)
-
Sodium hydroxide (B78521) (NaOH) (2.6 mmol total)
-
Benzyl bromide (1.5 mmol)
-
Ethanol (EtOH)
Procedure:
-
In a suitable reaction vessel, combine cinnamaldehyde (1.0 mmol), TsNHNH₂ (1.1 mmol), and NaOH (1.1 mmol) in EtOH.
-
Monitor the formation of the intermediate 5-phenyl-1H-pyrazole by TLC.
-
Once the formation of the intermediate is complete, add additional NaOH (1.5 mmol) and benzyl bromide (1.5 mmol) to the reaction mixture.
-
Continue stirring until the reaction is complete, as monitored by TLC.
-
Work up the reaction mixture to isolate the product, 1-benzyl-3-phenyl-1H-pyrazole.[10]
Signaling Pathway and Mechanism of Action
Derivatives of 1-benzyl-1H-pyrazole have been shown to modulate key cellular signaling pathways implicated in cancer. Notably, certain N-(1-benzyl-3,5-dimethyl-1H-pyrazol-4-yl)benzamides have been found to inhibit the mTORC1 signaling pathway, a central regulator of cell growth, proliferation, and survival.[7] Inhibition of mTORC1 can lead to the induction of autophagy, a cellular degradation process. However, these compounds have also been observed to disrupt the autophagic flux, suggesting a complex mechanism of action.
Below is a diagram illustrating the mTORC1 signaling pathway and the point of intervention for these pyrazole derivatives.
Safety and Handling
1-Benzyl-1H-pyrazole may cause irritation to the eyes, skin, and respiratory tract.[1] It is essential to handle this chemical in a well-ventilated area, preferably a fume hood. Appropriate personal protective equipment (PPE), including safety goggles, gloves, and a lab coat, should be worn at all times. Avoid contact with open flames or high temperatures, as the compound may decompose. In case of accidental contact or inhalation, rinse the affected area with copious amounts of water and seek immediate medical attention.
Conclusion
1-Benzyl-1H-pyrazole is a commercially available and highly valuable scaffold for organic synthesis and medicinal chemistry. Its derivatives have demonstrated significant biological activities, including the modulation of critical signaling pathways such as mTORC1. This technical guide provides a foundational resource for researchers interested in utilizing this compound, offering insights into its properties, synthesis, and potential applications in drug discovery and development. Further investigation into the biological effects of the parent compound and its novel derivatives is warranted to fully explore its therapeutic potential.
References
- 1. biosynce.com [biosynce.com]
- 2. chemscene.com [chemscene.com]
- 3. Pyrazole | C3H4N2 | CID 1048 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 4. chembk.com [chembk.com]
- 5. solubilityofthings.com [solubilityofthings.com]
- 6. rsc.org [rsc.org]
- 7. N-(1-Benzyl-3,5-dimethyl-1H-pyrazol-4-yl)benzamides: Antiproliferative Activity and Effects on mTORC1 and Autophagy - PMC [pmc.ncbi.nlm.nih.gov]
- 8. benchchem.com [benchchem.com]
- 9. Discovery and optimization of novel 3-benzyl-N-phenyl-1H-pyrazole-5-carboxamides as bifunctional antidiabetic agents stimulating both insulin secretion and glucose uptake - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. jocpr.com [jocpr.com]
An In-depth Technical Guide to the Synthesis of Luminol (5-amino-2,3-dihydro-1,4-phthalazinedione)
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive overview of the prevalent synthesis routes for Luminol (5-amino-2,3-dihydro-1,4-phthalazinedione), a molecule renowned for its chemiluminescent properties. While Luminol is commercially available, the synthesis is a valuable process for educational purposes and for researchers interested in modifying the core structure for various applications, including but not limited to, forensic science, bioassays, and as a research tool in drug development.
Core Synthesis Pathway: From 3-Nitrophthalic Acid
The most common and well-documented laboratory synthesis of Luminol commences with 3-nitrophthalic acid.[1][2] This two-step process involves the formation of a heterocyclic intermediate, followed by the reduction of a nitro group to the desired amine.
Step 1: Synthesis of 3-Nitrophthalhydrazide (B1587705)
The initial step is a condensation reaction between 3-nitrophthalic acid and hydrazine (B178648) (H₂N-NH₂) to form the cyclic hydrazide, 3-nitrophthalhydrazide.[1][3] This reaction is typically a dehydration process, driven by heat.[3]
Step 2: Reduction of 3-Nitrophthalhydrazide to Luminol
The second and final key transformation is the reduction of the nitro group (-NO₂) on the 3-nitrophthalhydrazide intermediate to an amino group (-NH₂), yielding Luminol.[1] A common and effective reducing agent for this step is sodium dithionite (B78146) (also known as sodium hydrosulfite, Na₂S₂O₄).[1][4]
Alternative Starting Materials
While the synthesis from 3-nitrophthalic acid is the most direct, Luminol can also be synthesized from more fundamental starting materials such as phthalic acid or phthalic anhydride.[5][6] This route requires an initial nitration step to introduce the nitro group, followed by the same condensation and reduction steps outlined above.
Quantitative Data Summary
The following tables summarize the quantitative data for the key steps in the synthesis of Luminol from 3-nitrophthalic acid.
Table 1: Synthesis of 3-Nitrophthalhydrazide
| Parameter | Value | Reference |
| Starting Material | 3-Nitrophthalic Acid | [1][4] |
| Reagent | 10% Aqueous Hydrazine | [1] |
| Solvent | Triethylene Glycol | [1][3] |
| Temperature | 210-220 °C | [4] |
| Reaction Time | ~5 minutes | [1] |
Table 2: Synthesis of Luminol from 3-Nitrophthalhydrazide
| Parameter | Value | Reference |
| Starting Material | 3-Nitrophthalhydrazide | [1][4] |
| Reducing Agent | Sodium Dithionite (Sodium Hydrosulfite) | [1][4] |
| Solvent | 10% Sodium Hydroxide (B78521) Solution | [1][4] |
| Temperature | Boiling | [1] |
| Reaction Time | 5 minutes | [1] |
| Quenching Agent | Glacial Acetic Acid | [1][3] |
Experimental Protocols
Protocol 1: Synthesis of 3-Nitrophthalhydrazide
-
In a large test tube, combine 1.3 g of 3-nitrophthalic acid and 2 mL of a 10% aqueous solution of hydrazine.[1]
-
Heat the test tube gently over a microburner until the solid dissolves.[1]
-
Add 4 mL of triethylene glycol to the solution.[1]
-
Insert a thermometer and heat the solution vigorously, allowing the temperature to rise above 200 °C.[1] Maintain the temperature between 210-220 °C for approximately 2-5 minutes.[4]
-
Allow the test tube to cool to about 100 °C and then add hot water to precipitate the product.[4][7]
-
Cool the mixture to room temperature and collect the solid 3-nitrophthalhydrazide by vacuum filtration.[4]
Protocol 2: Synthesis of Luminol
-
Transfer the synthesized 3-nitrophthalhydrazide to a large test tube.
-
Add 6.5 mL of a 10% sodium hydroxide solution and stir until the solid dissolves.[1]
-
Add 4 g of sodium dithionite to the solution.[1]
-
Add approximately 10 mL of water to rinse any solids from the walls of the test tube.[1]
-
Heat the solution to boiling and maintain boiling with stirring for 5 minutes.[1]
-
Add 2.6 mL of glacial acetic acid to the hot solution.[1]
-
Cool the mixture to room temperature, and then in an ice bath, to precipitate the Luminol.[1]
-
Collect the Luminol crystals by vacuum filtration.[1]
Visualizations
Caption: Synthesis of Luminol from 3-Nitrophthalic Acid.
Caption: Experimental Workflow for Luminol Synthesis.
References
- 1. ochemonline.pbworks.com [ochemonline.pbworks.com]
- 2. chimique.wordpress.com [chimique.wordpress.com]
- 3. jove.com [jove.com]
- 4. westfield.ma.edu [westfield.ma.edu]
- 5. Luminol Synthesis Protocol from Locally Available Materials - Nucleus - Reclone.org [forum.reclone.org]
- 6. youtube.com [youtube.com]
- 7. studylib.net [studylib.net]
Navigating the Shadows: A Technical Guide to Investigating Discontinued and Withdrawn Compounds
For Researchers, Scientists, and Drug Development Professionals
The landscape of pharmaceutical research is littered with compounds that, for a multitude of reasons, never reached the market or were withdrawn after approval. These "unavailable" compounds, however, represent a valuable and often overlooked repository of chemical and biological knowledge. A thorough understanding of their history, from synthesis to cessation, can provide critical insights for current and future drug development endeavors, helping to avoid past pitfalls and uncover new therapeutic opportunities. This in-depth technical guide provides a framework for the literature review of such compounds, focusing on data presentation, detailed experimental protocols, and the visualization of key molecular pathways.
The Challenge of Unseen Data
Researching compounds that are no longer readily available presents a unique set of challenges. Data can be fragmented, buried in old literature, or held in proprietary databases. Key experimental details are often omitted from published articles, making replication and further investigation difficult. Despite these hurdles, the wealth of information that can be gleaned from these "failed" molecules is immense, offering lessons in toxicology, pharmacology, and medicinal chemistry that remain relevant today.
Case Studies of Discontinued (B1498344) Compounds
To illustrate the process of a comprehensive literature review, this guide will focus on four well-documented case studies of withdrawn drugs, each representing a different mechanism of toxicity and reason for discontinuation.
-
Thalidomide (B1683933): A tragic example of unforeseen teratogenicity.
-
Terfenadine (B1681261): A lesson in cardiotoxicity due to off-target effects.
-
Troglitazone (B1681588): A case of idiosyncratic hepatotoxicity.
-
Cerivastatin (B1668405): An illustration of severe muscle toxicity (rhabdomyolysis).
Data Presentation: A Structured Approach
A systematic presentation of quantitative data is crucial for comparative analysis. The following tables summarize key information for our case-study compounds.
Table 1: General Information and Reasons for Discontinuation
| Compound | Brand Name(s) | Year Withdrawn | Reason for Discontinuation |
| Thalidomide | Contergan, Thalomid | 1961 (globally for morning sickness) | Severe teratogenic effects, causing birth defects. |
| Terfenadine | Seldane | 1998 | Risk of serious cardiac arrhythmias (Torsades de Pointes).[1][2] |
| Troglitazone | Rezulin | 2000 | Severe, idiosyncratic hepatotoxicity leading to liver failure.[3] |
| Cerivastatin | Baycol, Lipobay | 2001 | High incidence of rhabdomyolysis (severe muscle damage). |
Table 2: Physicochemical and Pharmacokinetic Data
| Compound | Molecular Formula | Molar Mass ( g/mol ) | Key Metabolic Enzymes |
| Thalidomide | C₁₃H₁₀N₂O₄ | 258.23 | Primarily non-enzymatic hydrolysis; some metabolism by CYP2C19. |
| Terfenadine | C₃₂H₄₁NO₂ | 471.67 | CYP3A4 |
| Troglitazone | C₂₄H₂₇NO₅S | 441.54 | CYP3A4, CYP2C8 |
| Cerivastatin | C₂₆H₃₄FNO₅ | 459.55 | CYP2C8, CYP3A4 |
Table 3: Pharmacological and Toxicological Data
| Compound | Therapeutic Target | Toxicity Target/Mechanism | IC₅₀/EC₅₀ (Relevant to Toxicity) |
| Thalidomide | Cereblon (CRBN) | Binds to CRBN, leading to degradation of SALL4, a transcription factor crucial for limb development. | Not typically expressed as IC₅₀ for teratogenicity. |
| Terfenadine | Histamine H1 receptor | hERG potassium channel blockade. | IC₅₀ for hERG block: ~350 nM[2] |
| Troglitazone | PPARγ | Mitochondrial dysfunction in hepatocytes. | Cytotoxicity in HepG2 cells observed at concentrations ≥10 μM.[3] |
| Cerivastatin | HMG-CoA reductase | Not fully elucidated; thought to involve disruption of muscle cell membrane integrity. | Not applicable in the same way as receptor blockade. |
Experimental Protocols: Recreating the Science
To facilitate a deeper understanding and potential replication of key findings, this section provides detailed methodologies for experiments relevant to the toxicities of the case-study compounds.
Terfenadine: hERG Potassium Channel Blockade Assay
Objective: To assess the inhibitory effect of terfenadine on the human Ether-à-go-go-Related Gene (hERG) potassium channel, a key factor in its cardiotoxicity.
Methodology: Whole-Cell Patch-Clamp Electrophysiology [1][2]
-
Cell Culture: Human Embryonic Kidney (HEK293) cells stably expressing the hERG channel are cultured in appropriate media (e.g., DMEM supplemented with 10% FBS and selection antibiotics) at 37°C in a 5% CO₂ incubator.
-
Cell Preparation: On the day of the experiment, cells are detached from the culture flask using a non-enzymatic cell dissociation solution, washed with extracellular solution, and plated onto glass coverslips in a recording chamber.
-
Solutions:
-
Extracellular (Bath) Solution (in mM): 140 NaCl, 4 KCl, 2 CaCl₂, 1 MgCl₂, 10 HEPES, 10 Glucose (pH adjusted to 7.4 with NaOH).
-
Intracellular (Pipette) Solution (in mM): 120 K-gluconate, 20 KCl, 1 CaCl₂, 1 MgCl₂, 10 HEPES, 10 EGTA, 5 Mg-ATP (pH adjusted to 7.2 with KOH).
-
-
Electrophysiological Recording:
-
Glass micropipettes with a resistance of 2-5 MΩ are filled with the intracellular solution and mounted on a micromanipulator.
-
A gigaohm seal is formed between the pipette tip and the cell membrane. The membrane is then ruptured to achieve the whole-cell configuration.
-
hERG currents are elicited by a voltage-clamp protocol: from a holding potential of -80 mV, the membrane is depolarized to +20 mV for 2 seconds, followed by a repolarizing step to -50 mV for 2 seconds to record the tail current.[1]
-
-
Drug Application:
-
A stable baseline hERG current is recorded for several minutes.
-
Terfenadine, dissolved in an appropriate solvent (e.g., DMSO) and diluted in the extracellular solution to the desired final concentrations, is perfused into the recording chamber.
-
The effect of the compound on the peak tail current amplitude is measured until a steady-state block is achieved.
-
-
Data Analysis:
-
The percentage of channel block is calculated as (1 - I_drug / I_control) * 100, where I_drug is the current in the presence of terfenadine and I_control is the current before drug application.
-
Concentration-response curves are generated, and the IC₅₀ value is determined by fitting the data to the Hill equation.
-
Troglitazone: In Vitro Hepatotoxicity Assay
Objective: To evaluate the cytotoxic effects of troglitazone on human liver cells.
Methodology: MTT Assay using HepG2 Cells [3][4]
-
Cell Culture: Human hepatoma (HepG2) cells are maintained in Eagle's Minimum Essential Medium (EMEM) supplemented with 10% fetal bovine serum (FBS), 1% non-essential amino acids, and 1% penicillin-streptomycin (B12071052) at 37°C in a humidified 5% CO₂ atmosphere.
-
Cell Seeding: Cells are seeded into 96-well plates at a density of 1 x 10⁴ cells per well and allowed to attach overnight.
-
Compound Treatment:
-
Troglitazone is dissolved in DMSO to create a stock solution.
-
Serial dilutions of troglitazone are prepared in culture medium to achieve final concentrations ranging from 1 to 100 µM. The final DMSO concentration in all wells should be ≤ 0.5%.
-
The culture medium is removed from the wells and replaced with the medium containing the different concentrations of troglitazone. Control wells receive medium with DMSO only.
-
-
Incubation: The plates are incubated for 24, 48, and 72 hours.
-
MTT Assay:
-
At the end of the incubation period, 20 µL of MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) solution (5 mg/mL in PBS) is added to each well.
-
The plates are incubated for an additional 4 hours at 37°C.
-
The medium is then carefully removed, and 150 µL of DMSO is added to each well to dissolve the formazan (B1609692) crystals.
-
-
Data Analysis:
-
The absorbance is measured at 570 nm using a microplate reader.
-
Cell viability is expressed as a percentage of the control.
-
The IC₅₀ value (the concentration of troglitazone that causes 50% inhibition of cell viability) is calculated from the concentration-response curve.
-
Cerivastatin: Creatine (B1669601) Kinase Assay for Rhabdomyolysis
Objective: To measure the activity of creatine kinase (CK) released from damaged muscle cells, a key indicator of rhabdomyolysis.
Methodology: In Vitro Muscle Cell Culture and CK Measurement
-
Cell Culture: A suitable skeletal muscle cell line (e.g., C2C12 myotubes) is cultured in DMEM supplemented with 10% FBS and antibiotics. To induce differentiation into myotubes, the serum concentration is reduced to 2% once the myoblasts reach confluence.
-
Compound Treatment:
-
Differentiated myotubes are treated with various concentrations of cerivastatin (dissolved in DMSO and diluted in culture medium).
-
Cells are incubated for a specified period (e.g., 24 or 48 hours).
-
-
Sample Collection: At the end of the treatment period, the culture supernatant is collected.
-
Creatine Kinase Assay:
-
A commercial creatine kinase activity assay kit is used. These kits typically employ a coupled enzyme reaction where the ATP produced from phosphocreatine (B42189) and ADP is used to phosphorylate glucose, which is then oxidized, leading to the production of NADPH.
-
The rate of NADPH formation is measured spectrophotometrically at 340 nm and is directly proportional to the CK activity in the sample.[5]
-
-
Data Analysis:
-
A standard curve is generated using a known concentration of CK.
-
The CK activity in the culture supernatant is calculated and expressed in units per liter (U/L).
-
The results are compared between control and cerivastatin-treated groups to determine the dose-dependent effect on CK release.
-
Thalidomide: Zebrafish Teratogenicity Assay
Objective: To assess the teratogenic potential of thalidomide using a whole-organism model.
Methodology: Zebrafish Embryo Assay [6][7]
-
Zebrafish Maintenance and Breeding: Adult zebrafish are maintained under standard conditions (28.5°C, 14/10 hour light/dark cycle). Embryos are obtained through natural spawning.
-
Embryo Collection and Staging: Fertilized eggs are collected and staged under a dissecting microscope. Only healthy, normally developing embryos are selected for the assay.
-
Compound Exposure:
-
At 24 hours post-fertilization (hpf), embryos are manually dechorionated.
-
Embryos are placed in 24-well plates (10-15 embryos per well) containing embryo medium.
-
Thalidomide (dissolved in DMSO) is added to the medium at various concentrations. A vehicle control (DMSO) is also included.
-
-
Incubation and Observation:
-
The plates are incubated at 28.5°C.
-
Embryos are observed at 48 and 72 hpf for developmental abnormalities, including fin defects, pericardial edema, and craniofacial malformations.
-
-
Data Analysis:
-
The number of embryos exhibiting specific malformations at each concentration is recorded.
-
The teratogenic index (TI) can be calculated as the ratio of the concentration that causes 50% lethality (LC₅₀) to the concentration that causes 50% malformation (EC₅₀). A higher TI indicates a greater teratogenic potential.
-
Mandatory Visualization: Signaling Pathways and Workflows
Visualizing complex biological processes is essential for clear communication. The following diagrams, created using the DOT language for Graphviz, illustrate key mechanisms and workflows discussed in this guide.
Caption: Thalidomide's teratogenic mechanism of action.
Caption: Mechanism of terfenadine-induced cardiotoxicity.
Caption: General workflow for a literature review of an unavailable compound.
Conclusion
The study of discontinued and withdrawn compounds is not an exercise in scientific archaeology but a vital component of modern drug discovery and development. By systematically reviewing the available literature, structuring the quantitative data, and detailing the experimental protocols, researchers can build upon past knowledge to design safer and more effective therapies. The case studies presented here underscore the importance of understanding the molecular mechanisms of toxicity and highlight the power of in vitro and in vivo models in preclinical safety assessment. The continued investigation of these "forgotten" molecules will undoubtedly illuminate new paths forward in the quest for novel medicines.
References
- 1. d-nb.info [d-nb.info]
- 2. Molecular Determinants of hERG Channel Block by Terfenadine and Cisapride - PMC [pmc.ncbi.nlm.nih.gov]
- 3. academic.oup.com [academic.oup.com]
- 4. ajphr.com [ajphr.com]
- 5. sigmaaldrich.com [sigmaaldrich.com]
- 6. In vivo screening and discovery of novel candidate thalidomide analogs in the zebrafish embryo and chicken embryo model systems - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Teratogenicity Testing: Harnessing the Power of Zebrafish for Efficient and Accurate Drug Screening - Biat Group [biatgroup.com]
An In-depth Technical Guide on the Withdrawn Pharmaceutical Compound: Rofecoxib (Vioxx)
For: Researchers, Scientists, and Drug Development Professionals
Introduction
Rofecoxib (B1684582), marketed under the brand name Vioxx, is a nonsteroidal anti-inflammatory drug (NSAID) that was developed as a selective inhibitor of the cyclooxygenase-2 (COX-2) enzyme.[1] It was approved by the U.S. Food and Drug Administration (FDA) in May 1999 for the treatment of osteoarthritis, rheumatoid arthritis, acute pain, and dysmenorrhea.[1][2] The primary advantage of rofecoxib over traditional NSAIDs was its lower incidence of gastrointestinal side effects.[1][3] However, Merck voluntarily withdrew rofecoxib from the global market on September 30, 2004, due to concerns about an increased risk of cardiovascular events, including heart attack and stroke, associated with long-term use.[1][4] This guide provides a technical overview of rofecoxib's mechanism of action, key clinical trials, and the scientific basis for its withdrawal.
Mechanism of Action
Rofecoxib is a selective COX-2 inhibitor.[2][5] The cyclooxygenase (COX) enzyme has two main isoforms, COX-1 and COX-2.[6] COX-1 is constitutively expressed in many tissues and is responsible for the synthesis of prostaglandins (B1171923) that protect the stomach lining.[6] In contrast, COX-2 is an inducible enzyme that is upregulated during inflammation and mediates the synthesis of prostaglandins responsible for pain and inflammation.[6][7]
By selectively inhibiting COX-2, rofecoxib reduces the production of inflammatory prostaglandins without affecting the protective functions of COX-1 in the gastrointestinal tract.[5][6] This selective action was the basis for its improved gastrointestinal safety profile compared to non-selective NSAIDs like naproxen (B1676952) and ibuprofen, which inhibit both COX-1 and COX-2.[3]
Prostaglandin Synthesis Pathway
The following diagram illustrates the arachidonic acid cascade and the role of COX enzymes.
Key Preclinical and Clinical Studies
The development and subsequent withdrawal of rofecoxib were marked by several key clinical trials that assessed its efficacy and safety.
VIGOR (Vioxx Gastrointestinal Outcomes Research) Study
The VIGOR study was a randomized, double-blind trial designed to compare the gastrointestinal safety of rofecoxib with that of naproxen in patients with rheumatoid arthritis.[8]
-
Objective : To evaluate the incidence of clinically important upper gastrointestinal events.[8]
-
Design : 8,076 patients were randomly assigned to receive either 50 mg of rofecoxib daily or 500 mg of naproxen twice daily.[8] The median follow-up was 9.0 months.[8]
-
Key Findings :
-
Rofecoxib was associated with a significantly lower incidence of confirmed gastrointestinal events compared to naproxen (2.1 vs. 4.5 events per 100 patient-years).[8]
-
An unexpected finding was a higher incidence of myocardial infarction in the rofecoxib group compared to the naproxen group (0.4% vs. 0.1%).[8][9] This observation was the first major signal of potential cardiovascular risk.[1]
-
APPROVe (Adenomatous Polyp Prevention on Vioxx) Trial
The APPROVe trial was a multicenter, randomized, placebo-controlled, double-blind trial to assess the efficacy of rofecoxib in preventing the recurrence of colorectal polyps.[10][11]
-
Objective : To determine if 25 mg of rofecoxib daily was effective in preventing the recurrence of colon polyps.[10]
-
Design : 2,587 patients with a history of colorectal adenomas were randomized to receive either 25 mg of rofecoxib or a placebo.[11] The trial was planned for a duration of three years.[11]
-
Key Findings : The trial was stopped prematurely because of a significant increase in the risk of serious cardiovascular events, such as heart attacks and strokes, in patients taking rofecoxib compared to placebo.[4][10] This increased risk was first observed after 18 months of continuous treatment.[10][12]
Experimental Protocol: VIGOR Study
-
Patient Population : Patients aged 50 years or older (or 40 and older if receiving long-term glucocorticoid therapy) with a diagnosis of rheumatoid arthritis.[8] Patients were not permitted to use concomitant aspirin.[13]
-
Randomization and Blinding : 8,076 eligible patients were randomly assigned in a double-blind fashion to one of two treatment groups.[8]
-
Intervention :
-
Primary Endpoint : The primary endpoint was the incidence of confirmed clinical upper gastrointestinal events, including gastroduodenal perforation or obstruction, upper gastrointestinal bleeding, and symptomatic gastroduodenal ulcers.[8]
-
Secondary and Safety Endpoints : Efficacy in treating rheumatoid arthritis was assessed, and all adverse events, including cardiovascular events, were recorded.[8]
-
Statistical Analysis : The primary analysis was a time-to-event analysis comparing the incidence of the primary endpoint between the two groups.[8]
Quantitative Data Summary
The following tables summarize key quantitative data from the pivotal clinical trials of rofecoxib.
Table 1: Pharmacokinetic Properties of Rofecoxib
| Parameter | Value | Reference |
| Bioavailability | ~93% | [2][14] |
| Time to Peak Plasma Concentration (Tmax) | 2 - 9 hours | [14] |
| Elimination Half-life | ~17 hours | [2][14] |
| Metabolism | Primarily hepatic, involving CYP3A4 and CYP1A2 | [5] |
Table 2: VIGOR Study - Primary and Key Safety Outcomes
| Outcome | Rofecoxib (50 mg) (n=4047) | Naproxen (1000 mg) (n=4029) | Relative Risk (95% CI) | p-value | Reference |
| Confirmed GI Events (per 100 patient-years) | 2.1 | 4.5 | 0.5 (0.3-0.6) | <0.001 | [8] |
| Complicated GI Events (per 100 patient-years) | 0.6 | 1.4 | 0.4 (0.2-0.8) | 0.005 | [8] |
| Myocardial Infarction (%) | 0.4% | 0.1% | 0.2 (0.1-0.7) | - | [8] |
Table 3: APPROVe Trial - Cardiovascular Outcomes
| Outcome | Rofecoxib (25 mg) | Placebo | Relative Risk | Reference |
| Thrombotic Cardiovascular Events | Increased | Baseline | 1.92 | [15] |
| Time to Increased Risk | After 18 months | - | - | [10][12] |
Reason for Withdrawal: Cardiovascular Risk
The withdrawal of rofecoxib was a direct result of the findings from the APPROVe trial, which confirmed the cardiovascular safety concerns first raised by the VIGOR study.[1][10] The proposed mechanism for the increased risk of thrombotic events is an imbalance between prostacyclin (PGI2) and thromboxane A2 (TXA2).[5][16]
-
Prostacyclin (PGI2) is produced in vascular endothelial cells, primarily via the COX-2 enzyme. It is a potent vasodilator and inhibitor of platelet aggregation.[16]
-
Thromboxane A2 (TXA2) is produced in platelets, exclusively via the COX-1 enzyme. It is a vasoconstrictor and a potent promoter of platelet aggregation.[16]
By selectively inhibiting COX-2, rofecoxib reduces the production of the anti-thrombotic PGI2 without affecting the production of the pro-thrombotic TXA2 from COX-1 in platelets.[5][16] This shift in the balance is believed to create a prothrombotic state, increasing the risk of cardiovascular events, particularly in patients with underlying cardiovascular disease.[16]
Conclusion
The case of rofecoxib is a critical chapter in the history of pharmaceutical development and regulation. While it offered a significant benefit in reducing gastrointestinal toxicity, its unforeseen cardiovascular risks highlighted the complexities of drug action and the importance of long-term post-marketing surveillance.[1] The withdrawal of rofecoxib led to a re-evaluation of the entire class of COX-2 inhibitors and prompted significant changes in how the cardiovascular safety of new drugs is assessed in clinical trials. The lessons learned from rofecoxib continue to influence drug development and regulatory science, emphasizing the paramount importance of a thorough understanding of a drug's complete pharmacological profile.
References
- 1. ijrpr.com [ijrpr.com]
- 2. Rofecoxib | C17H14O4S | CID 5090 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 3. Rofecoxib: clinical pharmacology and clinical experience - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Vioxx Pulled From Global Market [medscape.com]
- 5. ClinPGx [clinpgx.org]
- 6. Rofecoxib - Wikipedia [en.wikipedia.org]
- 7. researchgate.net [researchgate.net]
- 8. Comparison of upper gastrointestinal toxicity of rofecoxib and naproxen in patients with rheumatoid arthritis. VIGOR Study Group - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. ccjm.org [ccjm.org]
- 10. Vioxx (rofecoxib) Questions and Answers | FDA [fda.gov]
- 11. Discovery and development of cyclooxygenase 2 inhibitors - Wikipedia [en.wikipedia.org]
- 12. cmaj.ca [cmaj.ca]
- 13. accessdata.fda.gov [accessdata.fda.gov]
- 14. Rofecoxib: an update on physicochemical, pharmaceutical, pharmacodynamic and pharmacokinetic aspects - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. newdrugapprovals.org [newdrugapprovals.org]
- 16. ahajournals.org [ahajournals.org]
Synthesizing the Unprocurable: A Guide to the De Novo Synthesis of O-Propargyl-puromycin
For Researchers, Scientists, and Drug Development Professionals
Application Note
The inability to procure a specific chemical compound commercially can present a significant roadblock in research and development. This document provides a detailed protocol for the de novo synthesis of O-propargyl-puromycin (OP-Puro), a vital yet not commercially available tool for monitoring protein synthesis. OP-Puro, an analog of the antibiotic puromycin, is incorporated into nascent polypeptide chains, and its alkyne group allows for visualization and affinity purification via click chemistry. This guide will detail the multi-step synthesis, purification, and characterization of OP-Puro, empowering researchers to produce this valuable reagent in-house.
The synthesis of O-propargyl-puromycin is a three-stage process, beginning with the synthesis of two key precursors: N-Boc-O-propargyl-L-tyrosine and 3'-amino-3'-deoxy-N,N-dimethyladenosine. These precursors are then coupled, followed by the deprotection of the Boc group to yield the final product.
Experimental Protocols
Stage 1: Synthesis of Precursors
Protocol 1: Synthesis of N-Boc-O-propargyl-L-tyrosine
This protocol outlines the synthesis of the first precursor, N-Boc-O-propargyl-L-tyrosine, from L-tyrosine.
-
Materials:
-
L-tyrosine
-
Di-tert-butyl dicarbonate (B1257347) ((Boc)₂O)
-
Sodium hydroxide (B78521) (NaOH)
-
Propargyl bromide
-
Potassium carbonate (K₂CO₃)
-
Dimethylformamide (DMF)
-
Diethyl ether
-
Dichloromethane (DCM)
-
Hydrochloric acid (HCl)
-
Magnesium sulfate (B86663) (MgSO₄)
-
Silica (B1680970) gel for column chromatography
-
-
Procedure:
-
Boc Protection of L-tyrosine:
-
Dissolve L-tyrosine (1.0 eq) in a 1:1 mixture of 1M NaOH (2.0 eq) and dioxane.
-
Add di-tert-butyl dicarbonate (1.1 eq) and stir the mixture at room temperature overnight.
-
Acidify the reaction mixture to pH 2-3 with 1M HCl.
-
Extract the product with diethyl ether.
-
Wash the organic layer with brine, dry over MgSO₄, and concentrate under reduced pressure to obtain N-Boc-L-tyrosine.
-
-
Propargylation of N-Boc-L-tyrosine:
-
Dissolve N-Boc-L-tyrosine (1.0 eq) in DMF.
-
Add K₂CO₃ (2.0 eq) and propargyl bromide (1.2 eq).
-
Stir the reaction mixture at room temperature for 24 hours.
-
Pour the reaction mixture into water and extract with diethyl ether.
-
Wash the organic layer with water and brine, dry over MgSO₄, and concentrate under reduced pressure.
-
Purify the crude product by silica gel column chromatography (eluent: ethyl acetate/hexanes) to yield N-Boc-O-propargyl-L-tyrosine.
-
-
Protocol 2: Synthesis of 3'-amino-3'-deoxy-N,N-dimethyladenosine
This protocol details the synthesis of the second precursor, 3'-amino-3'-deoxy-N,N-dimethyladenosine, starting from adenosine (B11128). This is a multi-step process involving protection, activation, azidation, and reduction.
-
Materials:
-
Adenosine
-
Acetic anhydride (B1165640)
-
Pyridine
-
Triflic anhydride
-
Sodium azide (B81097) (NaN₃)
-
Triphenylphosphine (B44618) (PPh₃)
-
Ammonia in methanol
-
N,N-Dimethylformamide dimethyl acetal
-
Methanol (MeOH)
-
Dichloromethane (DCM)
-
Dimethylformamide (DMF)
-
Silica gel for column chromatography
-
-
Procedure:
-
Acetylation of Adenosine: Protect the hydroxyl groups of adenosine by reacting with acetic anhydride in pyridine.
-
Triflation: Selectively activate the 3'-hydroxyl group using triflic anhydride.
-
Azidation: Displace the triflate group with an azide group using sodium azide in DMF.
-
Deprotection and Dimethylation: Remove the acetyl protecting groups and dimethylate the 6-amino group of the adenine (B156593) base using N,N-dimethylformamide dimethyl acetal.
-
Reduction of Azide: Reduce the 3'-azido group to a 3'-amino group using triphenylphosphine in a Staudinger reaction, followed by hydrolysis.
-
Purification: Purify the final product by silica gel column chromatography.
-
Stage 2: Coupling of Precursors
Protocol 3: Synthesis of N-Boc-O-propargyl-puromycin
This protocol describes the coupling of the two synthesized precursors to form the protected intermediate.
-
Materials:
-
N-Boc-O-propargyl-L-tyrosine
-
3'-amino-3'-deoxy-N,N-dimethyladenosine
-
1-Ethyl-3-(3-dimethylaminopropyl)carbodiimide hydrochloride (EDC-HCl)
-
N-Hydroxysuccinimide (NHS)
-
N,N-Diisopropylethylamine (DIPEA)
-
Dimethylformamide (DMF)
-
Dichloromethane (DCM)
-
Saturated aqueous sodium bicarbonate (NaHCO₃)
-
Brine
-
Magnesium sulfate (MgSO₄)
-
Silica gel for column chromatography
-
-
Procedure:
-
Dissolve N-Boc-O-propargyl-L-tyrosine (1.2 eq), EDC-HCl (1.5 eq), and NHS (1.5 eq) in a mixture of DCM and DMF at 0°C.
-
Stir the solution for 15 minutes to activate the carboxylic acid.
-
Add a solution of 3'-amino-3'-deoxy-N,N-dimethyladenosine (1.0 eq) and DIPEA (2.0 eq) in DMF to the reaction mixture.
-
Allow the reaction to warm to room temperature and stir for 16 hours.
-
Dilute the reaction mixture with DCM and wash with saturated aqueous NaHCO₃ and brine.
-
Dry the organic layer over MgSO₄ and concentrate under reduced pressure.
-
Purify the crude product by silica gel column chromatography to obtain N-Boc-O-propargyl-puromycin.
-
Stage 3: Deprotection
Protocol 4: Synthesis of O-propargyl-puromycin
This final step involves the removal of the Boc protecting group to yield the target compound.
-
Materials:
-
N-Boc-O-propargyl-puromycin
-
Trifluoroacetic acid (TFA)
-
Dichloromethane (DCM)
-
Saturated aqueous sodium bicarbonate (NaHCO₃)
-
Brine
-
Magnesium sulfate (MgSO₄)
-
-
Procedure:
-
Dissolve N-Boc-O-propargyl-puromycin in a 1:1 mixture of TFA and DCM.
-
Stir the solution at room temperature for 1 hour.
-
Remove the solvent and TFA under reduced pressure.
-
Dissolve the residue in DCM and wash with saturated aqueous NaHCO₃ and brine.
-
Dry the organic layer over MgSO₄ and concentrate under reduced pressure to yield O-propargyl-puromycin as a white solid.
-
Data Presentation
The following table summarizes the expected yields and key characterization data for each step of the synthesis.
| Step | Product | Expected Yield (%) | Purity (%) (HPLC) | ¹H NMR | Mass Spec (m/z) |
| 1a: Boc Protection | N-Boc-L-tyrosine | >95 | >98 | Consistent with protected amino acid structure | [M+Na]⁺ expected |
| 1b: Propargylation | N-Boc-O-propargyl-L-tyrosine | 80-90 | >98 | Alkyne proton signal at ~2.5 ppm | [M+Na]⁺ expected |
| 2: Precursor Synthesis | 3'-amino-3'-deoxy-N,N-dimethyladenosine | 40-50 (overall) | >97 | Signals consistent with modified nucleoside structure | [M+H]⁺ expected |
| 3: Coupling | N-Boc-O-propargyl-puromycin | 60-70 | >95 | Characteristic signals for both coupled fragments and Boc group | [M+H]⁺ expected |
| 4: Deprotection | O-propargyl-puromycin | >90 | >99 | Absence of Boc proton signals, presence of all other key signals | [M+H]⁺ calculated: 496.2363; found: 496.2359 |
Visualizations
Caption: Workflow for the de novo synthesis of O-propargyl-puromycin.
Caption: Mechanism of action of O-propargyl-puromycin in protein synthesis.
Introduction
In drug discovery and development, the timely availability of specific chemical reagents is paramount. Commercial unavailability or long lead times for critical reagents can significantly impede research progress. A practical solution to this bottleneck is the in-house synthesis of required compounds. This application note provides a detailed protocol for the laboratory-scale synthesis of lithium dibutylcuprate, a versatile Gilman reagent, and its subsequent use in a Corey-House reaction to form a new carbon-carbon bond. The Corey-House reaction is a powerful method for the synthesis of unsymmetrical alkanes from alkyl halides.[1][2][3] This protocol is intended for researchers, scientists, and professionals in drug development who require a reliable method for producing this reagent when it is not commercially available.
Principle
The synthesis of the target alkane is achieved in two main stages. First, an organolithium reagent (n-butyllithium) is prepared by reacting an alkyl halide (1-bromobutane) with lithium metal. This is then reacted with a copper(I) salt (copper(I) iodide) to form the Gilman reagent, lithium dibutylcuprate (Li[Cu(CH₂CH₂CH₂CH₃)₂]). In the second stage, this Gilman reagent is reacted with a different alkyl halide (e.g., 1-iodopropane) in a cross-coupling reaction to yield the desired unsymmetrical alkane (heptane).
General Workflow for In-House Reagent Synthesis
The decision to undertake in-house synthesis of a reagent requires careful consideration of factors such as cost, available expertise, and safety. A general workflow is outlined below.
Caption: General workflow for the in-house synthesis of a reagent.
Experimental Protocol: Synthesis of Heptane (B126788) via Corey-House Reaction
This protocol details the synthesis of heptane by reacting lithium dibutylcuprate with 1-iodopropane (B42940).
Materials
-
1-Bromobutane (B133212) (C₄H₉Br)
-
Lithium metal (Li)
-
Copper(I) iodide (CuI)
-
1-Iodopropane (C₃H₇I)
-
Anhydrous diethyl ether ((C₂H₅)₂O)
-
Anhydrous tetrahydrofuran (B95107) (THF)
-
Saturated aqueous ammonium (B1175870) chloride (NH₄Cl) solution
-
Magnesium sulfate (B86663) (MgSO₄)
-
Standard laboratory glassware (Schlenk line, round-bottom flasks, dropping funnel, etc.)
-
Inert atmosphere (Nitrogen or Argon)
Safety Precautions
-
Organolithium reagents are pyrophoric and react violently with water. All reactions must be carried out under a dry, inert atmosphere.
-
Alkyl halides are toxic and should be handled in a fume hood.
-
Wear appropriate personal protective equipment (PPE), including safety glasses, lab coat, and gloves.
Procedure
Part 1: Preparation of Lithium Dibutylcuprate (Gilman Reagent)
-
Preparation of n-Butyllithium: In a flame-dried 250 mL three-necked flask equipped with a magnetic stirrer, a reflux condenser, and a dropping funnel, place lithium metal (in small pieces) under an inert atmosphere. Add anhydrous diethyl ether to the flask. Slowly add 1-bromobutane dropwise from the dropping funnel to the lithium suspension. The reaction is exothermic and should be controlled by the rate of addition. After the addition is complete, stir the mixture at room temperature for 1 hour to ensure complete reaction.
-
Formation of Lithium Dibutylcuprate: In a separate flame-dried 500 mL flask under an inert atmosphere, suspend copper(I) iodide in anhydrous diethyl ether. Cool the suspension to -78 °C using a dry ice/acetone bath. Slowly add two equivalents of the prepared n-butyllithium solution to the copper(I) iodide suspension with vigorous stirring. The formation of the Gilman reagent is indicated by a color change.
Part 2: Corey-House Coupling Reaction
-
Reaction with Alkyl Halide: To the freshly prepared lithium dibutylcuprate solution at -78 °C, slowly add 1-iodopropane dropwise.
-
Warming and Quenching: After the addition is complete, allow the reaction mixture to slowly warm to room temperature and stir for an additional 2 hours.
-
Work-up: Quench the reaction by slowly adding saturated aqueous ammonium chloride solution.
-
Extraction and Purification: Transfer the mixture to a separatory funnel. Extract the aqueous layer with diethyl ether. Combine the organic layers, wash with brine, and dry over anhydrous magnesium sulfate. Filter the drying agent and remove the solvent by rotary evaporation to obtain the crude product. The product, heptane, can be further purified by distillation.
Reaction Pathway
The chemical transformations involved in the Corey-House synthesis are depicted below.
Caption: Reaction scheme for the synthesis of heptane.
Quantitative Data Summary
The following table summarizes the quantitative data for the synthesis of heptane.
| Reactant/Product | Molecular Weight ( g/mol ) | Amount (mmol) | Mass (g) | Volume (mL) | Density (g/mL) |
| 1-Bromobutane | 137.02 | 50 | 6.85 | 5.35 | 1.28 |
| Lithium | 6.94 | 110 | 0.76 | - | - |
| Copper(I) iodide | 190.45 | 25 | 4.76 | - | - |
| 1-Iodopropane | 169.99 | 25 | 4.25 | 2.36 | 1.80 |
| Heptane (Theoretical Yield) | 100.21 | 25 | 2.51 | 3.69 | 0.68 |
This application note provides a comprehensive and detailed protocol for the in-house synthesis of a Gilman reagent and its application in a Corey-House reaction. By following this protocol, researchers can reliably produce unsymmetrical alkanes, thereby overcoming challenges associated with the commercial unavailability of specific reagents. The ability to synthesize necessary compounds in-house provides greater flexibility and control over the research and development timeline.
References
Custom Synthesis of Complex Organic Molecules: Application Notes and Protocols for Researchers
For Researchers, Scientists, and Drug Development Professionals
This document provides detailed application notes and protocols relevant to the custom synthesis of complex organic molecules. It is designed to serve as a practical guide for researchers in the fields of medicinal chemistry, drug discovery, and materials science who require specialized, non-commercially available compounds for their studies.
Introduction to Custom Synthesis
The synthesis of complex organic molecules is a cornerstone of modern chemical and biomedical research. While a vast array of chemical compounds are commercially available, the demand for novel and structurally intricate molecules continues to grow, driven by the need for highly specific probes for biological pathways, new therapeutic agents, and advanced materials. Custom synthesis services provide a crucial solution by offering bespoke synthesis of molecules tailored to the unique requirements of a research project. These services encompass a wide range of activities, from the initial route scouting and process development to the final purification and characterization of the target molecule.
Case Study: Multi-step Synthesis of Zanubrutinib, a Bruton's Tyrosine Kinase (BTK) Inhibitor
To illustrate the process of custom synthesis, we will use the example of Zanubrutinib, a potent and selective inhibitor of Bruton's tyrosine kinase (BTK), which is a key component of the B-cell receptor signaling pathway. Dysregulation of this pathway is implicated in several B-cell malignancies.
The synthesis of Zanubrutinib is a multi-step process that requires careful control of reaction conditions and purification of intermediates. The following table summarizes the key steps in a reported synthetic route, highlighting the typical data that would be generated during a custom synthesis project.
| Step | Reaction | Starting Materials | Key Reagents & Solvents | Reaction Time (h) | Yield (%) | Purity (%) | Analytical Method |
| 1 | Formation of Vinyl Dinitrile | Benzoic acid derivative, Malononitrile | Ethyl acetate | 4-6 | 85-90 | >95 | ¹H NMR, LC-MS |
| 2 | Methylation | Vinyl dinitrile | Trimethyl orthoformate, Acetonitrile | 2-3 | 90-95 | >97 | ¹H NMR, LC-MS |
| 3 | Cyclization | Methylated intermediate, Piperidine-containing keto aldehyde equivalent | - | 5-7 | 70-75 | >95 | ¹H NMR, LC-MS |
| 4 | Reduction & Deprotection | Zanubrutinib heterocyclic subunit | H₂, Pd/C, HCl | 12-16 | 80-85 | >98 | ¹H NMR, LC-MS |
| 5 | Chiral Resolution | Racemic piperidine (B6355638) intermediate | L-dibenzoyl tartaric acid | 24-48 | 40-45 (of desired enantiomer) | >99 (ee) | Chiral HPLC |
| 6 | Acylation | Resolved piperidine intermediate | Acryloyl chloride, Base | 1-2 | 70 | >99.5 | ¹H NMR, HPLC, HRMS |
Experimental Protocols
General Protocol for Flash Column Chromatography Purification of a Heterocyclic Intermediate
Flash column chromatography is a rapid and efficient method for the purification of reaction intermediates. This protocol is a general guideline and should be optimized for each specific compound.
Materials:
-
Crude reaction mixture
-
Silica (B1680970) gel (for normal phase) or C18-functionalized silica (for reversed-phase)
-
Solvent system (e.g., Hexane/Ethyl Acetate or Dichloromethane/Methanol for normal phase; Water/Acetonitrile with 0.1% formic acid for reversed-phase)
-
Glass column with a stopcock
-
Sand
-
Compressed air or nitrogen source
-
Collection tubes
-
Thin Layer Chromatography (TLC) plates and chamber
Procedure:
-
Solvent System Selection: Determine an appropriate solvent system using TLC. The desired compound should have an Rf value of approximately 0.2-0.3 for good separation.
-
Column Packing:
-
Place a small plug of glass wool at the bottom of the column.
-
Add a thin layer of sand.
-
Prepare a slurry of silica gel in the initial, less polar solvent.
-
Pour the slurry into the column, allowing the solvent to drain while gently tapping the column to ensure even packing.
-
Add another thin layer of sand on top of the silica gel.
-
-
Sample Loading:
-
Dissolve the crude product in a minimal amount of the chromatography solvent or a more polar solvent that will be strongly adsorbed at the top of the column.
-
Carefully apply the sample to the top of the column.
-
-
Elution:
-
Carefully add the eluent to the column.
-
Apply gentle pressure from the compressed air/nitrogen source to achieve a flow rate of approximately 2 inches per minute.
-
Collect fractions in test tubes.
-
-
Fraction Analysis:
-
Analyze the collected fractions by TLC to identify those containing the pure product.
-
Combine the pure fractions and remove the solvent under reduced pressure.
-
General Protocol for Preparative High-Performance Liquid Chromatography (HPLC) Purification
Preparative HPLC is used for the final purification of the target molecule to achieve high purity.
Materials:
-
Crude final product
-
HPLC-grade solvents (e.g., Acetonitrile, Methanol, Water)
-
Volatile buffer or acid (e.g., Formic acid, Trifluoroacetic acid)
-
Preparative HPLC system with a suitable column (e.g., C18)
-
Fraction collector
Procedure:
-
Method Development: Develop a separation method on an analytical HPLC system to determine the optimal mobile phase composition, gradient, and column.
-
Sample Preparation: Dissolve the crude product in the mobile phase or a compatible solvent. Filter the sample to remove any particulate matter.
-
System Setup:
-
Equilibrate the preparative HPLC column with the initial mobile phase conditions.
-
Set up the fraction collector to collect peaks based on retention time or UV detector signal.
-
-
Injection and Purification:
-
Inject the sample onto the column.
-
Run the preparative HPLC method.
-
The fraction collector will automatically collect the eluting peaks into separate vials.
-
-
Purity Analysis and Solvent Removal:
-
Analyze the collected fractions using analytical HPLC to confirm purity.
-
Combine the pure fractions.
-
Remove the solvent, often by lyophilization (freeze-drying) if volatile buffers were used.
-
General Protocol for 2D-NMR Analysis of a Complex Organic Molecule
Two-dimensional Nuclear Magnetic Resonance (2D-NMR) spectroscopy is a powerful tool for the structural elucidation of complex molecules.
Experiments:
-
COSY (Correlation Spectroscopy): Identifies proton-proton couplings, revealing which protons are adjacent to each other in the molecule.
-
HSQC (Heteronuclear Single Quantum Coherence): Correlates proton signals with their directly attached carbon atoms.
-
HMBC (Heteronuclear Multiple Bond Correlation): Shows correlations between protons and carbons that are two or three bonds away, providing information about the connectivity of different parts of the molecule.
Procedure:
-
Sample Preparation: Dissolve a few milligrams of the purified compound in a suitable deuterated solvent (e.g., CDCl₃, DMSO-d₆).
-
Data Acquisition:
-
Acquire a standard one-dimensional (1D) ¹H NMR spectrum to determine the chemical shifts of all protons.
-
Set up and run the desired 2D NMR experiments (COSY, HSQC, HMBC) on the NMR spectrometer.
-
-
Data Processing and Interpretation:
-
Process the acquired 2D data using appropriate software.
-
Analyze the cross-peaks in each spectrum to establish the connectivity of atoms within the molecule.
-
Combine the information from all spectra to elucidate the complete structure of the molecule.
-
Signaling Pathway and Experimental Workflow Diagrams
The following diagrams, generated using the DOT language, illustrate a typical experimental workflow for custom synthesis and the signaling pathway targeted by Zanubrutinib.
These application notes and protocols provide a framework for understanding and utilizing custom synthesis services for complex organic molecules. By combining detailed synthetic planning, robust purification techniques, and comprehensive analytical characterization, researchers can obtain the high-quality, specialized compounds necessary to advance their scientific endeavors.
Application Notes and Protocols for Substituting a Key Reagent in an Experiment
For Researchers, Scientists, and Drug Development Professionals
Introduction
In scientific research and drug development, the consistency and reliability of experimental reagents are paramount to generating reproducible and accurate data.[1][2] However, circumstances often necessitate the substitution of a key reagent. This may be due to a variety of factors, including the discontinuation of a product by a manufacturer, significant cost implications, limited availability, or the emergence of a more suitable alternative.[1]
Replacing a critical component in an established workflow can introduce variability and potentially compromise the integrity of experimental outcomes.[1][3] Therefore, a systematic and rigorous validation protocol is essential to ensure that the new reagent performs equivalently to the original and does not negatively impact the quality and reliability of the data generated.[1][4]
This document provides a detailed protocol for substituting a key reagent, outlining the necessary steps for validation, equivalency testing, and documentation to ensure a seamless transition without compromising experimental integrity.
Pre-Substitution Assessment and Planning
Before embarking on experimental validation, a thorough theoretical assessment is crucial. This initial phase helps in identifying potential challenges and designing an appropriate validation strategy.
2.1. Manufacturer's Documentation Review: Carefully examine the manufacturer's instructions and specifications for the new reagent.[1] Pay close attention to:
-
Reconstitution and Storage: Note any differences in buffer composition, concentration, and storage conditions.[1]
-
Handling Procedures: Identify any specific handling requirements that may differ from the original reagent.[1]
-
Intended Use and Limitations: Ensure the new reagent is suitable for your specific application.
2.2. Risk Assessment: Evaluate the potential impact of the substitution on the experimental workflow and outcomes. Consider the class of the reagent, as some, like antibodies and cell lines, present greater challenges and require more extensive validation.[1]
Experimental Validation Workflow
The following diagram outlines the key steps in the experimental validation process for a substitute reagent.
Caption: Workflow for Reagent Substitution Validation.
Detailed Experimental Protocols
4.1. Protocol 1: Crossover Study for a Substitute Enzyme in a Kinase Assay
This protocol describes a crossover study to compare a new kinase enzyme with the previously used one.
Objective: To determine if the substitute kinase exhibits comparable activity and kinetics to the original kinase.
Materials:
-
Original Kinase Enzyme
-
Substitute Kinase Enzyme
-
Kinase Substrate
-
ATP
-
Kinase Buffer
-
Positive and Negative Control Compounds
-
Detection Reagent
Procedure:
-
Reagent Preparation: Prepare stock solutions of both the original and substitute kinases according to the manufacturers' instructions.
-
Assay Setup:
-
Design a 96-well plate layout to test both enzymes in parallel.
-
Include wells for no-enzyme controls, no-substrate controls, and positive/negative controls.
-
Create a dilution series of both kinases to determine the optimal concentration.
-
Prepare a concentration-response curve for a known inhibitor with both enzymes.
-
-
Kinase Reaction:
-
Add the kinase buffer to all wells.
-
Add the respective kinase (original or substitute) to the appropriate wells.
-
Add the kinase substrate to all wells except the no-substrate controls.
-
Initiate the reaction by adding ATP.
-
Incubate the plate at the recommended temperature and time.
-
-
Signal Detection:
-
Stop the reaction according to the assay protocol.
-
Add the detection reagent and measure the signal (e.g., luminescence, fluorescence).
-
-
Data Analysis:
-
Calculate the specific activity of each enzyme.
-
Determine the IC50 values for the inhibitor with each enzyme.
-
Perform a statistical comparison of the results.
-
4.2. Protocol 2: Validation of a Substitute Antibody for Western Blotting
This protocol outlines the validation of a new primary antibody for use in Western blotting.
Objective: To confirm that the substitute antibody has similar specificity, sensitivity, and signal-to-noise ratio as the original antibody.
Materials:
-
Original Primary Antibody
-
Substitute Primary Antibody
-
Positive and Negative Control Cell Lysates
-
Secondary Antibody
-
Blocking Buffer
-
Wash Buffer
-
Chemiluminescent Substrate
Procedure:
-
Antibody Titration:
-
Run identical protein samples on multiple SDS-PAGE gels.
-
Transfer the proteins to membranes.
-
Incubate each membrane with a different dilution of the original and substitute primary antibodies (e.g., 1:500, 1:1000, 1:2000).
-
This will determine the optimal working concentration for each antibody.
-
-
Specificity Testing:
-
Use cell lysates known to express (positive control) and not express (negative control) the target protein.
-
Probe separate blots with the original and the new antibody at their optimal concentrations.
-
The substitute antibody should detect the target protein only in the positive control lysate.
-
-
Sensitivity Comparison:
-
Run a serial dilution of the positive control cell lysate on a gel.
-
Probe blots with both antibodies to determine the limit of detection for each.
-
-
Signal-to-Noise Ratio:
-
Visually and densitometrically assess the background signal on the blots for both antibodies.
-
-
Data Analysis:
-
Compare the band intensities, specificity, and background levels between the two antibodies.
-
Data Presentation
Quantitative data from equivalency studies should be summarized in clear, structured tables for easy comparison.
Table 1: Comparison of Kinase Enzyme Performance
| Parameter | Original Kinase | Substitute Kinase | % Difference | Acceptance Criteria |
| Specific Activity (U/mg) | 1520 | 1485 | -2.3% | < 10% |
| Km for Substrate (µM) | 12.5 | 13.1 | +4.8% | < 15% |
| IC50 of Inhibitor (nM) | 45.2 | 48.9 | +8.2% | < 20% |
Table 2: Western Blot Antibody Validation Summary
| Parameter | Original Antibody | Substitute Antibody | Outcome |
| Optimal Dilution | 1:1000 | 1:1500 | Substitute is more concentrated |
| Specificity (vs. KO lysate) | Correct Band Only | Correct Band Only | Equivalent |
| Limit of Detection | 10 ng | 10 ng | Equivalent |
| Signal-to-Noise Ratio | 4.5 | 4.2 | Comparable |
Impact on Cellular Signaling Pathways
Caption: Impact of Reagent Substitution on a Signaling Pathway.
Troubleshooting and Documentation
7.1. Troubleshooting: If the substitute reagent does not meet the acceptance criteria, a systematic troubleshooting process should be initiated.[1]
-
Re-evaluate Manufacturer's Instructions: Double-check all preparation and handling steps.
-
Consult Manufacturer's Technical Support: The manufacturer may provide additional guidance or be aware of lot-to-lot variability.[1]
-
Assess Experimental Design: Ensure that the validation protocol is appropriate and that controls behaved as expected.
7.2. Documentation: Meticulous documentation of the entire substitution process is critical for reproducibility and regulatory compliance.[2][5] The documentation should include:
-
Reagent Information: Name, supplier, lot number, and expiration dates for both the old and new reagents.[5]
-
Experimental Protocols: Detailed step-by-step procedures used for validation.[5]
-
Raw Data and Analysis: All raw data, calculations, and statistical analyses.
-
Summary Report: A final report summarizing the findings, the decision on whether to accept the new reagent, and the justification for that decision.
References
- 1. Converting from one reagent to another | FUJIFILM Wako [wakopyrostar.com]
- 2. Understanding Reagents: A Beginner's Guide - Merkel Technologies Ltd [merkel.co.il]
- 3. The Importance of High-Quality Reagents in Accurate Experimental Results [merkel.co.il]
- 4. How we validate new laboratory reagents - Ambar Lab [ambar-lab.com]
- 5. sapiosciences.com [sapiosciences.com]
For Researchers, Scientists, and Drug Development Professionals
In the fast-paced environment of drug discovery and development, the inability to access specialized equipment can present a significant roadblock. This document provides detailed application notes and protocols for recreating common laboratory experiments using alternative, low-cost, or "do-it-yourself" (DIY) methods. A strong emphasis is placed on validation and quality control to ensure the reliability of data generated, a critical aspect in a pharmaceutical research setting.
Section 1: Alternative Approaches to Key Molecular and Cell Biology Techniques
This section outlines strategies to overcome the lack of sophisticated equipment for fundamental experimental workflows.
Protein Analysis: Alternatives to Western Blotting
Traditional Western blotting requires specialized electrophoresis and blotting apparatus. Here are validated alternative methods.
Application Note: Colorimetric and capillary-based methods offer viable alternatives to chemiluminescent Western blotting, reducing the need for expensive imaging systems. While colorimetric detection is less sensitive, it is a cost-effective and readily accessible option. Capillary electrophoresis, on the other hand, provides high resolution and sensitivity.[1]
Protocol 1: Colorimetric "Blot-in-Gel" Assay for His-tagged Proteins
This protocol provides a rapid alternative to the traditional Western blot for detecting His-tagged proteins, eliminating the need for a blotting apparatus.[2]
Materials:
-
Polyacrylamide gel (SDS-PAGE)
-
Tris-Buffered Saline with Tween 20 (TBST)
-
Blocking buffer (e.g., 5% non-fat milk or BSA in TBST)
-
HisProbe™-HRP (or similar nickel-HRP conjugate)
-
Colorimetric HRP substrate (e.g., TMB, DAB)
-
Standard laboratory glassware and pipettes
Procedure:
-
Run the protein samples on a standard SDS-PAGE gel.
-
After electrophoresis, instead of transferring, fix the gel in a solution of 50% methanol (B129727) and 10% acetic acid for 30 minutes.
-
Wash the gel three times with deionized water for 10 minutes each.
-
Block the gel with blocking buffer for 1 hour at room temperature with gentle agitation.
-
Incubate the gel in a solution of HisProbe™-HRP diluted in blocking buffer (follow manufacturer's recommendations) for 1 hour at room temperature.
-
Wash the gel three times with TBST for 10 minutes each to remove unbound probe.
-
Add the colorimetric HRP substrate to the gel and incubate until the desired band intensity is reached.
-
Stop the reaction by washing the gel with deionized water.
-
Document the results using a standard flatbed scanner or a camera.
Protocol 2: Capillary Gel Electrophoresis (CGE) for Protein Separation
CGE offers a high-resolution alternative to SDS-PAGE and can be performed with relatively simple, and sometimes DIY, setups.[3][4]
Materials:
-
Fused silica (B1680970) capillary
-
High-voltage power supply
-
Buffer reservoirs (e.g., Eppendorf tubes)
-
Sieving matrix (e.g., polymer solution)
-
Detector (e.g., UV-Vis detector or a DIY LED-photodiode setup)
-
Sample injection system (hydrodynamic or electrokinetic)[3]
Procedure:
-
Capillary Conditioning: Flush the capillary with 0.1 M NaOH, followed by deionized water, and then the running buffer.[3]
-
Sample Preparation: Denature protein samples in a buffer containing SDS and a reducing agent.
-
Electrophoresis: Fill the capillary and reservoirs with the sieving matrix and running buffer. Inject the sample and apply a high voltage to initiate separation.
-
Detection: Monitor the migration of proteins as they pass the detector. The data is typically displayed as an electropherogram.[4]
Nucleic Acid Amplification: DIY PCR Thermocycler
Commercial PCR thermocyclers can be a significant investment. A functional thermocycler can be constructed using readily available electronic components.[5][6]
Application Note: A DIY thermocycler can achieve the necessary temperature cycling for PCR.[5] While commercial machines may have faster ramp rates, a well-calibrated DIY machine can yield reliable results for endpoint PCR.[5] For quantitative PCR (qPCR), precise temperature control and a sensitive detection system are critical.
Protocol 3: Assembling and Operating a DIY PCR Thermocycler
Components:
-
Arduino or other microcontroller
-
Peltier element for heating and cooling
-
Heatsink and fan for temperature dissipation
-
Temperature sensor (e.g., thermistor or thermocouple)
-
Power supply
-
Insulated reaction block to hold PCR tubes
Assembly and Operation:
-
Assemble the components according to open-source plans available online.
-
Program the microcontroller to cycle through the desired denaturation, annealing, and extension temperatures and times.[5]
-
Calibrate the temperature sensor against a certified thermometer to ensure accuracy.
-
Prepare PCR reactions as per a standard protocol.[7]
-
Place the PCR tubes in the reaction block and run the programmed thermal cycling protocol.
-
Analyze the PCR products using gel electrophoresis.
Quantitative Analysis: DIY Spectrophotometer and Fluorometer
Spectrophotometers and fluorometers are essential for various quantitative assays. Functional versions of these instruments can be built at a fraction of the cost of commercial models.[8][9][10][11][12]
Application Note: DIY spectrophotometers have demonstrated sufficient quantitative performance for various applications, including determining concentrations of colored solutions.[8][10][13][14] Similarly, low-cost fluorescence microscopes and readers can be constructed for cell imaging and fluorescence-based assays.[2][9][11][12][15]
Protocol 4: Constructing and Using a DIY Spectrophotometer
Components:
-
Light source (e.g., white LED)
-
Diffraction grating to separate light into its constituent wavelengths
-
Sample holder (e.g., a cuvette holder)
-
Detector (e.g., photodiode, webcam, or smartphone camera)[13]
-
Enclosure to block ambient light (e.g., a 3D-printed case or a simple box)
Procedure:
-
Assemble the components based on available online tutorials.
-
Calibrate the instrument by measuring the absorbance of a series of known concentrations of a standard substance (e.g., a colored dye) to generate a standard curve.[16]
-
Measure the absorbance of the unknown sample.
-
Determine the concentration of the unknown sample using the standard curve.
Section 2: Validation and Quality Control of Alternative Methods
For data to be reliable, especially in a drug development context, rigorous validation of any alternative or DIY equipment and protocols is essential.[4][17][18]
Application Note: Equipment validation involves documenting that the instrument is properly installed, operates according to specifications, and performs as expected for the intended application.[4][17]
Equipment Calibration and Performance Qualification
Protocol 5: Validating a 3D-Printed Lab Device
Procedure:
-
Installation Qualification (IQ): Document that the 3D-printed device and any associated components are assembled correctly according to the design specifications.
-
Operational Qualification (OQ): Test the operational parameters of the device. For a 3D-printed spectrophotometer, this would involve verifying the accuracy of the wavelength selection and the stability of the light source.
-
Performance Qualification (PQ): Demonstrate that the device performs as expected for a specific application. For example, use the DIY spectrophotometer to measure the concentration of a known compound and compare the results to those obtained with a commercial instrument.[13][14]
Reagent Quality Control
Protocol 6: Validating Homemade Competent Cells
Procedure:
-
Prepare chemically competent E. coli cells using a standard protocol.[19]
-
To determine the transformation efficiency, transform the homemade competent cells with a known amount of a standard plasmid (e.g., pUC19).[20][21]
-
Plate the transformed cells on selective agar (B569324) plates and count the number of resulting colonies.
-
Calculate the transformation efficiency as colony-forming units (CFU) per microgram of plasmid DNA.[22]
-
Compare the transformation efficiency to that of commercially available competent cells to ensure they meet the requirements for your cloning experiments.[20] A high efficiency of over 10^8 CFU/µg is generally considered good for routine cloning.[22]
Section 3: Data Presentation
Quantitative data from validation experiments should be clearly summarized to allow for easy comparison.
Table 1: Performance Comparison of a DIY Spectrophotometer vs. a Commercial Spectrophotometer [13]
| Parameter | DIY Webcam Spectrophotometer | Commercial Spectrophotometer |
| Methyl Red Analysis | ||
| Linearity Range | 2–10 ppm | 0.5–12 ppm |
| Limit of Detection (LOD) | 0.69 ppm | 0.15 ppm |
| Limit of Quantification (LOQ) | 2.11 ppm | 0.50 ppm |
| Precision (RSD) | ~5% | <2% |
| Dichromate Standard Analysis | ||
| Linearity Range | 0.7–1.5 ppm | 0.1–2.0 ppm |
| Limit of Detection (LOD) | 0.12 ppm | 0.03 ppm |
| Limit of Quantification (LOQ) | 0.41 ppm | 0.10 ppm |
| Precision (RSD) | <5% | <1% |
Table 2: Transformation Efficiency of Homemade vs. Commercial Competent Cells
| Competent Cell Type | Plasmid Used | Amount of DNA | Colonies (CFU) | Transformation Efficiency (CFU/µg) |
| Homemade DH5α | pUC19 | 10 ng | 150 | 1.5 x 10^7 |
| Commercial DH5α | pUC19 | 10 ng | 500 | 5.0 x 10^7 |
Section 4: Recreating a Signaling Pathway Experiment
This section provides a workflow for analyzing a simplified signaling pathway using the alternative techniques described above.
Objective: To determine the effect of a compound on the phosphorylation of a target protein (e.g., a kinase) in a cell line.
Workflow:
-
Cell Culture and Treatment: Culture cells and treat with the compound of interest.
-
Protein Extraction: Lyse the cells to extract total protein.
-
Protein Quantification: Use a DIY spectrophotometer to perform a colorimetric protein assay (e.g., Bradford assay) to normalize protein loading.
-
Protein Separation and Detection:
-
Option A (His-tagged target): If the target protein is His-tagged, use the "Blot-in-Gel" assay (Protocol 1) to detect changes in its mobility upon phosphorylation (if the modification causes a significant size shift) or use a phospho-specific His-probe if available.
-
Option B (Capillary Electrophoresis): Use CGE (Protocol 2) to separate the phosphorylated and non-phosphorylated forms of the target protein. This may require optimization of the separation conditions.
-
Option C (ELISA-based): Adapt a sandwich ELISA protocol using a capture antibody for the total target protein and a detection antibody specific for the phosphorylated form.[23][24][25] The final colorimetric or fluorescent readout can be measured with a DIY spectrophotometer or fluorometer.
-
-
Data Analysis: Quantify the band/peak intensities or absorbance/fluorescence signals to determine the relative amount of phosphorylated protein in treated versus untreated cells.
Visualizations
Caption: Workflow for signaling pathway analysis with alternative equipment.
References
- 1. Protocol for Capillary Electrophoresis - Creative Proteomics [creative-proteomics.com]
- 2. researchgate.net [researchgate.net]
- 3. Capillary Electrophoresis : 7 Steps - Instructables [instructables.com]
- 4. bitesizebio.com [bitesizebio.com]
- 5. medium.com [medium.com]
- 6. bitesizebio.com [bitesizebio.com]
- 7. 标准 PCR 程序 [sigmaaldrich.com]
- 8. ERIC - EJ1003033 - A Low-Cost Quantitative Absorption Spectrophotometer, Journal of Chemical Education, 2012-Nov [eric.ed.gov]
- 9. A Smartphone-Based Low-Cost Inverted Laser Fluorescence Microscope for Disease Diagnosis - PMC [pmc.ncbi.nlm.nih.gov]
- 10. pubs.acs.org [pubs.acs.org]
- 11. A Low-Cost Digital Microscope with Real-Time Fluorescent Imaging Capability - PMC [pmc.ncbi.nlm.nih.gov]
- 12. A low-cost smartphone fluorescence microscope for research, life science education, and STEM outreach - PMC [pmc.ncbi.nlm.nih.gov]
- 13. mjas.analis.com.my [mjas.analis.com.my]
- 14. researchgate.net [researchgate.net]
- 15. researchgate.net [researchgate.net]
- 16. Build your own spectrophotometer | Feature | RSC Education [edu.rsc.org]
- 17. chemrxiv.org [chemrxiv.org]
- 18. Case Studies - Confluence Discovery Technologies [confluencediscovery.com]
- 19. bitesizebio.com [bitesizebio.com]
- 20. blog.addgene.org [blog.addgene.org]
- 21. web.genewiz.com [web.genewiz.com]
- 22. An Optimized Transformation Protocol for Escherichia coli BW3KD with Supreme DNA Assembly Efficiency - PMC [pmc.ncbi.nlm.nih.gov]
- 23. assaygenie.com [assaygenie.com]
- 24. genfollower.com [genfollower.com]
- 25. mabtech.com [mabtech.com]
A Researcher's Guide to Requesting Materials from Academic Laboratories
For researchers and professionals in the fast-paced fields of scientific discovery and drug development, the ability to efficiently obtain research materials from other academic laboratories is crucial for innovation and collaboration. This guide provides a comprehensive overview of the process, from drafting the initial request to validating the received materials.
Section 1: The Initial Request - Fostering Collaboration
A clear and courteous initial request is the first step toward a successful exchange. The goal is to be specific, concise, and professional.
Application Notes: Crafting an Effective Request Email
A well-structured email increases the likelihood of a positive and prompt response. Key components include a clear subject line, a polite and professional greeting, a brief introduction of yourself and your research, a specific request detailing the material needed, a concise explanation of how the material will be used, and an offer to cover shipping costs.[1][2] It is also good practice to mention that the material will only be used in your laboratory and will not be distributed to others without prior written approval.[1]
Protocol 1: Drafting the Initial Material Request Email
-
Subject Line: Be specific. For instance, "Request for [Name of Plasmid/Cell Line/Antibody] from your [Year] [Journal] Publication."
-
Salutation: Use a formal and respectful greeting, such as "Dear Dr. [Principal Investigator's Last Name]."
-
Introduction: Briefly introduce yourself, your position, your institution, and your Principal Investigator's name.
-
Reference and Context: Mention the specific publication where you learned about the material. For example, "I read with great interest your recent publication titled '[Article Title]' in [Journal Name] and was particularly interested in the [specific material] you described."[1]
-
The Ask: Clearly state what material you are requesting. Be as specific as possible, using the exact name or identifier from the publication.
-
Intended Use: Briefly explain the purpose of your research and how the requested material will be instrumental. This helps the providing lab understand the context and importance of your work.
-
Logistics: Offer to provide a prepaid shipping label or to cover the shipping costs via a courier account number.
-
Assurances: State that the material will be used solely for non-commercial research purposes within your lab.
-
Closing: Thank the researcher for their time and consideration.
-
Follow-up: If you do not receive a response within a reasonable timeframe (e.g., one to two weeks), a polite follow-up email is acceptable.[1]
Section 2: The Legal Framework - Material Transfer Agreements (MTAs)
A Material Transfer Agreement (MTA) is a legally binding contract that governs the transfer of tangible research materials between two organizations.[3][4][5] It outlines the rights and responsibilities of both the provider and the recipient, addressing important issues such as intellectual property, permitted use, and liability.[6]
Application Notes: Understanding the MTA Process
MTAs are crucial for protecting the interests of both the providing and receiving institutions.[4] For transfers between academic or research institutions, a standardized agreement called the Uniform Biological Material Transfer Agreement (UBMTA) is often used to streamline the process.[3][4] Transfers involving industry partners typically require more detailed and negotiated agreements. It is essential for the Principal Investigator to review the MTA, but it must be signed by an authorized representative of the institution, not the individual researcher.
dot
Key Terms in Material Transfer Agreements
| Term | Description |
| Material | A detailed description of the research material being transferred, including any derivatives or progeny.[6][7] |
| Original Material | The material as supplied by the provider. |
| Progeny | Unmodified descendants from the original material, such as cells that have been replicated.[6] |
| Unmodified Derivatives | Substances created by the recipient that constitute an unmodified functional subunit or product expressed by the original material.[6] |
| Modifications | Substances created by the recipient which contain or incorporate the material. |
| Permitted Use | The specific research purpose for which the recipient is allowed to use the material. This is often restricted to non-commercial research. |
| Intellectual Property | Clauses that define ownership of inventions or discoveries made using the material. |
| Publication | The recipient's right to publish research findings, often with a provision for the provider to review manuscripts prior to submission. |
| Confidentiality | Obligations to protect any proprietary information associated with the material.[6] |
| Liability | A disclaimer of warranties from the provider regarding the material's fitness for a particular purpose and safety. |
Section 3: Shipping and Receiving
Proper packaging and handling are critical to ensure the integrity and safety of the biological materials during transit and upon arrival.
Application Notes: Best Practices for Shipping and Receiving
The shipping of biological materials is subject to strict regulations.[8][9][10][11] It is the shipper's responsibility to ensure proper classification, packaging, labeling, and documentation.[10] The recipient should be prepared to receive the shipment promptly and handle it according to established laboratory safety protocols.
Protocol 2: Receiving and Logging Incoming Materials
-
Preparation: Before the material arrives, ensure that all necessary storage facilities (e.g., -80°C freezer, liquid nitrogen dewar, cell culture incubator) are ready and available.
-
Inspection upon Arrival: Once the package arrives, inspect it for any signs of damage or leakage.[12][13][14][15] Wear appropriate Personal Protective Equipment (PPE) during this process.
-
Documentation: Immediately log the material into the laboratory's inventory system.[13][14] Record the date of receipt, the name of the material, the provider's information, the assigned storage location, and any other relevant details.
-
Quarantine (if necessary): For certain materials, such as live cell lines, it is advisable to initially store and handle them in a designated quarantine area until their identity and sterility have been confirmed.
-
Acknowledge Receipt: Send a confirmation email to the providing lab to let them know the material has arrived safely.
dot
Section 4: Validation of Received Materials
Upon receipt, it is imperative to validate the identity and quality of the research materials before incorporating them into experiments. This step is crucial for the reproducibility and integrity of your research.
Application Notes: The Importance of Validation
Failure to authenticate materials can lead to invalid experimental results, wasted resources, and the retraction of publications. Different types of materials require specific validation protocols.
Common Reasons for Material Rejection or Failure in Validation
| Reason for Rejection/Failure | Description | Applicable Materials |
| Mislabeled or Unlabeled | The material received is not what was requested, or the labeling is unclear.[16] | All |
| Insufficient Quantity | The amount of material received is not enough for the intended experiments.[17][18] | All |
| Contamination | The material is contaminated with bacteria, fungi, mycoplasma, or other cell lines.[16] | Cell Lines, Plasmids, Antibodies |
| Incorrect Sequence | The DNA sequence of the plasmid does not match the expected sequence. | Plasmids |
| Poor Viability/Growth | Cells fail to recover and proliferate after thawing. | Cell Lines |
| Low Purity/Integrity | The material is degraded or contains significant impurities. | Plasmids, Antibodies, Proteins |
| Non-specific Binding | The antibody cross-reacts with unintended targets. | Antibodies |
| Incorrect Staining Pattern | The antibody does not produce the expected localization in immunohistochemistry or immunocytochemistry. | Antibodies |
Protocol 3: Cell Line Authentication
-
Short Tandem Repeat (STR) Profiling: This is the gold standard for authenticating human cell lines.[19][20] The STR profile of the received cell line should be compared to the known profile from a reputable cell bank or the original publication. A match of ≥80% is generally required for authentication.[20][21]
-
Mycoplasma Testing: Regularly test all cell cultures for mycoplasma contamination, as it can significantly alter cell physiology and experimental outcomes.
-
Morphology Check: Visually inspect the cells under a microscope to ensure they exhibit the expected morphology.
-
Growth Curve Analysis: Determine the population doubling time to ensure it is consistent with the known characteristics of the cell line.
Protocol 4: Plasmid Verification
-
Restriction Digest Analysis: Perform a restriction enzyme digest of the plasmid DNA and run the products on an agarose (B213101) gel. The resulting band pattern should match the expected pattern based on the plasmid map.[22]
-
Sanger Sequencing: Sequence the insert and flanking regions of the plasmid to confirm the correct DNA sequence and ensure there are no mutations.[22][23][24] For full plasmid verification, next-generation sequencing methods can be employed.[25]
Protocol 5: Antibody Validation
-
Western Blotting: Use the antibody to probe lysates from cells or tissues known to express (positive control) and not express (negative control) the target protein. A specific band at the correct molecular weight should be observed only in the positive control.[26]
-
Immunocytochemistry (ICC) / Immunohistochemistry (IHC): Stain cells or tissues with the antibody to verify that it localizes to the correct subcellular compartment or tissue region.[26]
-
Knockout (KO) or Knockdown (KD) Validation: The most rigorous method for specificity testing involves using the antibody on cells or tissues where the target gene has been knocked out or its expression has been knocked down. The signal should be absent or significantly reduced in the KO/KD sample compared to the wild-type control.[26][27]
-
Immunoprecipitation-Mass Spectrometry (IP-MS): This technique can identify the protein(s) that the antibody binds to, providing a high level of confidence in its specificity.[27][28]
By following these guidelines and protocols, researchers can navigate the process of requesting and receiving materials from other academic labs efficiently and responsibly, fostering collaboration and ensuring the integrity of their scientific endeavors.
References
- 1. biomed.emory.edu [biomed.emory.edu]
- 2. quora.com [quora.com]
- 3. Material transfer agreement - Wikipedia [en.wikipedia.org]
- 4. Material Transfer Agreement [uh.edu]
- 5. ke.org.uk [ke.org.uk]
- 6. AI Review for Material Transfer Agreements [legalontech.com]
- 7. Template for Material Transfer Agreement [wipo.int]
- 8. research.columbia.edu [research.columbia.edu]
- 9. Transportation And Shipment Of Biological Materials | Faculty of Engineering and Natural Sciences [fens.sabanciuniv.edu]
- 10. inside.nku.edu [inside.nku.edu]
- 11. Biological Materials and Dry Ice Shipping | Harvard Environmental Health and Safety [ehs.harvard.edu]
- 12. learn.lboro.ac.uk [learn.lboro.ac.uk]
- 13. docs.labii.com [docs.labii.com]
- 14. om.ciheam.org [om.ciheam.org]
- 15. epa.gov [epa.gov]
- 16. Can you provide examples of common reasons for sample rejection in the laboratory? [needle.tube]
- 17. researchgate.net [researchgate.net]
- 18. Specimen rejection in laboratory medicine: Necessary for patient safety? - PMC [pmc.ncbi.nlm.nih.gov]
- 19. cellculturedish.com [cellculturedish.com]
- 20. cellbase.com [cellbase.com]
- 21. Cell Line Authentication Resources [worldwide.promega.com]
- 22. goldbio.com [goldbio.com]
- 23. lifesciences.danaher.com [lifesciences.danaher.com]
- 24. sourcebioscience.com [sourcebioscience.com]
- 25. biorxiv.org [biorxiv.org]
- 26. neobiotechnologies.com [neobiotechnologies.com]
- 27. sysy.com [sysy.com]
- 28. biocompare.com [biocompare.com]
best practices for documenting in-house synthesis of compounds
Application Notes & Protocols for In-house Compound Synthesis
Introduction
The meticulous documentation of in-house compound synthesis is a critical pillar of reproducible and reliable scientific research, particularly within the realms of drug discovery and development.[1] Comprehensive and standardized documentation ensures that synthetic procedures can be accurately replicated, facilitates troubleshooting, and forms the foundation for regulatory submissions.[1][2] These application notes and protocols provide a framework for researchers, scientists, and drug development professionals to effectively document the synthesis of novel compounds, ensuring data integrity, promoting collaboration, and adhering to safety standards.[1]
Core Principles of Synthesis Documentation
Effective documentation of in-house compound synthesis should be guided by the principles of clarity, completeness, and consistency. Every step, from the initial planning to the final characterization of the compound, must be recorded with sufficient detail to allow another competent chemist to reproduce the work.[3] The use of Standard Operating Procedures (SOPs) is highly recommended to ensure uniformity in documentation across different projects and personnel.[1][4][5] Digital tools such as Electronic Lab Notebooks (ELNs) and Laboratory Information Management Systems (LIMS) can significantly enhance the efficiency and accuracy of data capture and management.[1]
Experimental Protocols
A detailed experimental protocol is the cornerstone of reproducible synthesis. Each protocol should be a self-contained document that provides a step-by-step description of the synthetic procedure.
1. Compound Identification and Synthesis Overview
-
Compound Name/ID: A unique identifier for the target compound.
-
Chemical Structure: A clear 2D or 3D representation of the molecule.
-
Reaction Scheme: An overall schematic of the synthetic route.
-
Purpose: A brief statement outlining the reason for the synthesis.
2. Reagents and Materials
All chemicals and materials used in the synthesis must be meticulously documented to ensure traceability and reproducibility.[1]
| Reagent/Material | Grade/Purity | Supplier | Lot Number | Quantity |
| Starting Material A | 99% | Sigma-Aldrich | A12345 | 10.0 g |
| Reagent B | Anhydrous | Acros Organics | B67890 | 50 mL |
| Solvent C | HPLC Grade | Fisher Scientific | C11223 | 250 mL |
| Catalyst D | 5% on Carbon | Johnson Matthey | D44556 | 0.5 g |
3. Equipment
A comprehensive list of all equipment used in the synthesis should be provided, including model numbers and calibration dates where applicable.[1]
| Equipment | Manufacturer | Model | Last Calibrated |
| Magnetic Stirrer Hotplate | IKA | C-MAG HS 7 | N/A |
| Rotary Evaporator | Buchi | R-300 | 2025-10-15 |
| High-Performance Liquid Chromatography (HPLC) | Agilent | 1260 Infinity II | 2025-11-01 |
| Nuclear Magnetic Resonance (NMR) Spectrometer | Bruker | Avance III HD 400 MHz | 2025-09-20 |
4. Step-by-Step Synthetic Procedure
This section should provide a clear and unambiguous narrative of the entire synthetic process.[3][4]
-
Preparation: Describe the setup of the reaction apparatus, including glassware and any necessary inert atmosphere conditions (e.g., nitrogen or argon).
-
Reagent Addition: Detail the order and rate of addition of all reagents and solvents. Specify reaction conditions such as temperature, pressure, and stirring speed.
-
Reaction Monitoring: Explain the method used to monitor the progress of the reaction (e.g., Thin Layer Chromatography (TLC), HPLC, Gas Chromatography (GC)). Include details of the mobile phase for TLC or the method parameters for HPLC/GC.
-
Work-up: Provide a detailed description of the quenching, extraction, and washing procedures used to isolate the crude product.
-
Purification: Describe the method of purification (e.g., column chromatography, recrystallization, distillation). For column chromatography, specify the stationary phase, mobile phase, and column dimensions. For recrystallization, specify the solvent system.
-
Isolation and Drying: Detail how the final product was isolated and dried (e.g., filtration, rotary evaporation, vacuum oven).
5. Safety and Handling Procedures
This section is crucial for ensuring laboratory safety and should be prominently displayed.[1][6]
-
Personal Protective Equipment (PPE): Specify the required PPE (e.g., safety glasses, lab coat, gloves).
-
Hazardous Materials: Identify all hazardous materials and describe their specific risks.
-
Waste Disposal: Provide clear instructions for the disposal of all chemical waste generated during the synthesis.
Data Presentation
All quantitative data should be summarized in clearly structured tables for easy comparison and analysis.
Reaction Yield and Purity
| Step | Product | Theoretical Yield (g) | Actual Yield (g) | Percent Yield (%) | Purity (by HPLC/NMR) |
| 1 | Intermediate 1 | 8.5 | 7.9 | 92.9 | 98% |
| 2 | Final Compound | 12.2 | 10.5 | 86.1 | >99% |
Characterization Data
| Analysis | Instrument | Parameters | Result |
| ¹H NMR | Bruker 400 MHz | CDCl₃, 300K | δ 7.8-7.2 (m, 5H), 4.5 (s, 2H), 2.1 (s, 3H) |
| ¹³C NMR | Bruker 100 MHz | CDCl₃, 300K | δ 170.1, 135.2, 129.5, 128.8, 127.3, 45.6, 21.3 |
| Mass Spectrometry (MS) | Agilent 6120 | ESI+ | m/z = 254.12 [M+H]⁺ |
| HPLC | Agilent 1260 | C18 column, MeCN/H₂O gradient | Retention Time = 8.2 min |
| Melting Point | Stuart SMP30 | 2 °C/min ramp | 125-127 °C |
Mandatory Visualizations
Experimental Workflow
A generalized workflow for in-house compound synthesis.
Hypothetical Signaling Pathway
Hypothetical inhibition of the MAPK/ERK pathway by an in-house compound.
References
Adapting Published Methods When Specific Materials Are Not Available: Application Notes and Protocols
Introduction
Reproducibility is a cornerstone of scientific research, yet the inability to source the exact materials and reagents cited in a published method is a common hurdle for researchers. This can be due to discontinuation of a product, high costs, limited access, or supply chain issues.[1] This document provides a comprehensive guide for researchers, scientists, and drug development professionals on how to systematically adapt a published method when specific materials are unavailable. It outlines the decision-making process for selecting suitable alternatives, detailed protocols for validation, and troubleshooting strategies to ensure the integrity and reliability of the experimental results.
General Principles of Method Adaptation
Adapting a published protocol requires a systematic approach to minimize variability and ensure the new method is as reliable and accurate as the original. The core principle is to identify a suitable substitute and then rigorously validate its performance in the context of the specific experiment. This process involves a careful review of the original protocol, research into potential alternatives, and a series of validation experiments.
A key consideration is the nature of the material being substituted. Reagents can be broadly categorized, and the stringency of validation will vary depending on the category. For instance, substituting a simple chemical may be straightforward, whereas replacing a critical component like a primary antibody requires extensive validation.[1]
Selecting a Suitable Substitute
The first step in adapting a protocol is to thoroughly understand the role of the unavailable material in the original experiment. This will guide the selection of an appropriate alternative.
Decision-Making Workflow
When a specific material is unavailable, a researcher should follow a structured decision-making process to identify and select a suitable alternative. This process involves evaluating the function of the original material, researching potential substitutes, and assessing their suitability based on available data and preliminary testing.
Caption: Decision-making workflow for selecting a substitute material.
Case Study: Substituting a Primary Antibody in a Western Blot
A common challenge is the discontinuation of a specific monoclonal or polyclonal antibody. When selecting a replacement, consider the following:
-
Antigen Specificity: The new antibody must recognize the same target protein.
-
Epitope Recognition: If the original antibody's epitope is known, try to find a replacement that targets the same or a nearby epitope. This is especially critical for detecting specific protein isoforms or post-translational modifications.
-
Application Validation: Ensure the new antibody is validated for the specific application (e.g., Western Blot, ELISA, Immunohistochemistry).[2]
-
Host Species and Isotype: The host species and isotype of the new antibody should be compatible with the secondary antibody used in the protocol.
Validation of the Adapted Method
Once a suitable substitute has been identified, a thorough validation is crucial to ensure the adapted method yields comparable results to the original. The validation process should be designed to assess the accuracy, precision, and specificity of the new method.
Experimental Workflow for Validation
The validation process typically involves a side-by-side comparison of the original material (if available in small quantities) or a known control with the substitute material. The workflow should be meticulously planned and documented.
Caption: Experimental workflow for validating an adapted method.
Quantitative Data Presentation
Summarizing the validation data in tables allows for a clear and direct comparison of the performance of the substitute material against the original or expected results.
Table 1: Comparison of a Substitute Primary Antibody in a Western Blot
| Parameter | Original Antibody | Substitute Antibody | Acceptance Criteria |
| Target Band Intensity (Arbitrary Units) | 15,234 | 14,987 | ± 10% of Original |
| Signal-to-Noise Ratio | 12.5 | 11.9 | > 10 |
| Number of Non-Specific Bands | 1 | 1 | ≤ 2 |
| Optimal Dilution | 1:1000 | 1:1200 | Determine empirically |
Table 2: Validation of a Substitute ELISA Kit
| Parameter | Original Kit | Substitute Kit | Acceptance Criteria |
| Intra-assay Precision (%CV) | 4.2% | 4.8% | < 15% |
| Inter-assay Precision (%CV) | 7.8% | 8.5% | < 20% |
| Accuracy (% Recovery) | 98.5% | 97.9% | 80-120% |
| Lower Limit of Detection (ng/mL) | 0.5 | 0.6 | ≤ 1.0 |
| Specificity (Cross-reactivity) | < 1% with related analytes | < 1% with related analytes | < 5% |
Experimental Protocols
This section provides detailed protocols for key experiments involved in validating an adapted method.
Protocol: Side-by-Side Comparison of a Substitute Primary Antibody in Western Blotting
Objective: To validate the performance of a substitute primary antibody against the original antibody (or a well-characterized control).
Materials:
-
Cell lysates or tissue homogenates containing the target protein
-
SDS-PAGE gels and running buffer
-
Transfer apparatus and buffer
-
Membranes (PVDF or nitrocellulose)
-
Blocking buffer (e.g., 5% non-fat milk or BSA in TBST)
-
Original primary antibody
-
Substitute primary antibody
-
HRP-conjugated secondary antibody
-
Chemiluminescent substrate
-
Imaging system
Procedure:
-
Sample Preparation: Prepare identical sets of protein samples for each antibody to be tested.
-
SDS-PAGE and Transfer: Run the protein samples on two identical SDS-PAGE gels. Transfer the proteins to membranes.
-
Blocking: Block both membranes in blocking buffer for 1 hour at room temperature.
-
Primary Antibody Incubation:
-
Incubate one membrane with the original primary antibody at its optimal dilution.
-
Incubate the second membrane with the substitute primary antibody at a range of dilutions to determine its optimal concentration.
-
Incubate overnight at 4°C with gentle agitation.
-
-
Washing: Wash both membranes three times for 10 minutes each with TBST.
-
Secondary Antibody Incubation: Incubate both membranes with the appropriate HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Washing: Repeat the washing step as in step 5.
-
Detection: Add the chemiluminescent substrate to both membranes and acquire images using an imaging system.
-
Analysis: Compare the band intensity of the target protein, the signal-to-noise ratio, and the presence of any non-specific bands between the two membranes.
Protocol: Validation of a Substitute ELISA Kit
Objective: To validate the performance of a substitute ELISA kit by assessing its precision, accuracy, and sensitivity.
Materials:
-
Substitute ELISA kit (including plates, standards, detection antibody, and substrate)
-
Samples containing a known concentration of the analyte (spiked samples or reference materials)
-
Control samples (high, medium, and low concentrations)
-
Plate reader
Procedure:
-
Intra-assay Precision:
-
Prepare replicates (n=20) of high, medium, and low concentration controls.
-
Run all replicates on a single plate according to the kit instructions.
-
Calculate the mean, standard deviation, and coefficient of variation (%CV) for each control level.
-
-
Inter-assay Precision:
-
Prepare aliquots of high, medium, and low concentration controls.
-
Run the controls on three different plates on three different days.
-
Calculate the mean, standard deviation, and %CV for each control level across the three runs.
-
-
Accuracy (Spike and Recovery):
-
Prepare samples with known concentrations of the analyte by spiking the sample matrix.
-
Analyze the spiked samples using the substitute ELISA kit.
-
Calculate the percent recovery of the spiked analyte.
-
-
Sensitivity (Lower Limit of Detection - LLOD):
-
Determine the LLOD based on the mean signal of the blank and its standard deviation, as per the kit's instructions or standard laboratory procedures.
-
-
Data Analysis: Compare the obtained values for precision, accuracy, and sensitivity against the acceptance criteria defined in your validation plan.
Troubleshooting Common Issues in Method Adaptation
When adapting a protocol, unexpected results are common. A systematic approach to troubleshooting is essential.
Table 3: Troubleshooting Guide for Adapting a Western Blot Protocol
| Issue | Possible Cause | Recommended Solution |
| Weak or No Signal | Suboptimal concentration of the substitute antibody. | Perform a titration to find the optimal antibody concentration.[3] |
| Incompatible secondary antibody. | Ensure the secondary antibody is specific to the host species and isotype of the primary antibody. | |
| High Background | Substitute antibody concentration is too high. | Decrease the antibody concentration.[4] |
| Insufficient blocking. | Increase blocking time or try a different blocking agent (e.g., BSA instead of milk).[3] | |
| Non-specific Bands | Cross-reactivity of the substitute antibody. | Use a more specific antibody or perform validation with knockout/knockdown cell lines if available.[5] |
| Protein degradation. | Add protease inhibitors to the sample buffer.[3] |
Case Study: Adapting a Chemical Synthesis Protocol with a "Green" Reagent
The principles of method adaptation also apply to chemical synthesis. A growing trend is the substitution of hazardous reagents with more environmentally friendly or "green" alternatives.[6]
Original Method: A peptide synthesis protocol using piperidine (B6355638), a regulated and hazardous reagent, for Fmoc deprotection.[7]
Adapted Method: Substitution of piperidine with a photoredox-catalyzed deprotection method using a hydrophilic Nα-Picoc group, which can be performed under milder, aqueous conditions.[7]
Validation:
-
Yield Comparison: The yield of the final peptide using the adapted method was compared to the yield from the original method.
-
Purity Analysis: The purity of the peptide was assessed using HPLC and mass spectrometry to ensure the absence of side products.
-
Side Reaction Monitoring: The formation of common side products like aspartimide and diketopiperazine was monitored and found to be suppressed in the adapted method.[7]
Table 4: Comparison of Original and Adapted Peptide Synthesis Methods
| Parameter | Original Method (Piperidine) | Adapted Method (Photocatalysis) |
| Reagent Hazard | High (Regulated, Hazardous) | Low (Mild, Aqueous Conditions) |
| Reaction Yield | 85% | 82% |
| Product Purity | 96% | 98% |
| Aspartimide Formation | 5% | <1% |
Conclusion
Adapting a published method when specific materials are unavailable is a feasible and often necessary practice in scientific research. Success hinges on a systematic approach that includes a thorough understanding of the original method, careful selection of a suitable substitute, and rigorous validation of the adapted protocol. By following the guidelines and protocols outlined in this document, researchers can confidently adapt methods while maintaining the integrity and reproducibility of their results.
References
- 1. alfa-chemistry.com [alfa-chemistry.com]
- 2. bitesizebio.com [bitesizebio.com]
- 3. Western Blot Troubleshooting Guide | Bio-Techne [bio-techne.com]
- 4. bosterbio.com [bosterbio.com]
- 5. 5 ways to validate and extend your research with Knockout Cell Lines [horizondiscovery.com]
- 6. Revolutionizing organic synthesis through green chemistry: metal-free, bio-based, and microwave-assisted methods - PMC [pmc.ncbi.nlm.nih.gov]
- 7. pubs.acs.org [pubs.acs.org]
Application Notes & Protocols: Sourcing and Qualification of Starting Materials for Novel Compound Synthesis
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive framework for the strategic sourcing, qualification, and quality control of starting materials essential for the synthesis of novel chemical compounds. Adherence to these protocols is critical for ensuring reproducibility, maintaining the integrity of experimental results, and adhering to regulatory standards.[1][2]
Supplier Identification and Qualification
The selection of a reliable supplier is a foundational step in the synthesis workflow.[3] A robust supplier qualification process ensures that starting materials consistently meet the required quality standards, thereby minimizing risks to patient safety and operational timelines.[1][4]
Initial Supplier Screening
The initial screening process involves identifying potential suppliers and conducting a preliminary assessment.[5] This can be accomplished through various channels, including:
-
Online Chemical Databases and Marketplaces: Platforms like PubChem, ChemScence, and others can help identify commercially available starting materials and their suppliers.[6]
-
Scientific Literature and Patent Filings: Reviewing patents and publications can reveal suppliers of key starting materials (KSMs) used in similar synthetic routes.[7]
-
Trade Shows and Conferences: Industry events provide opportunities to connect directly with a wide range of chemical suppliers.
Once potential suppliers are identified, an initial screening should be conducted using a supplier questionnaire.[5][8] This document should request key information such as:
-
Company history and manufacturing capabilities.
-
Quality management system (QMS) certifications (e.g., ISO 9001).[3][4]
-
Regulatory history, including any FDA warning letters or recalls.[5]
-
Willingness to provide detailed Certificates of Analysis (CoA).[3]
Supplier Evaluation and Selection Workflow
A systematic workflow should be followed to evaluate and select the most suitable supplier. This process involves a multi-departmental effort, including research and development, quality assurance, and procurement.[5][9]
Caption: Workflow for the qualification and approval of new material suppliers.
Quantitative Supplier Comparison
After the initial screening and evaluation, a quantitative comparison of the top potential suppliers should be performed. This allows for an objective, data-driven decision.
| Metric | Supplier A | Supplier B | Supplier C | Specification |
| Purity (by HPLC) | 99.8% | 99.5% | 98.9% | ≥ 99.5% |
| Lead Time (Days) | 14 | 7 | 21 | ≤ 14 days |
| Cost per Gram | $150 | $165 | $120 | Target: ≤ $150 |
| CoA Provided | Yes | Yes | Yes | Mandatory |
| ISO 9001 Certified | Yes | Yes | No | Preferred |
| Audit Result | Passed | Passed | N/A | Pass/Fail |
Quality Control of Incoming Materials
Independent quality control testing of incoming starting materials is a fundamental Good Manufacturing Practice (GMP) requirement.[8] It is crucial to verify that all materials meet the pre-defined specifications before they are used in any synthesis.[8]
Protocol: Identity Verification by ¹H NMR Spectroscopy
Objective: To confirm the identity and structural integrity of the starting material by comparing its proton nuclear magnetic resonance (¹H NMR) spectrum to a reference standard or literature data.
Materials:
-
Starting material sample
-
Deuterated solvent (e.g., CDCl₃, DMSO-d₆)
-
NMR tubes
-
Internal standard (e.g., TMS)
-
Reference spectrum or literature data
Procedure:
-
Accurately weigh approximately 5-10 mg of the starting material and dissolve it in 0.6-0.7 mL of an appropriate deuterated solvent in a clean vial.
-
Transfer the solution to an NMR tube.
-
If required, add a small amount of an internal standard (e.g., Tetramethylsilane - TMS).
-
Acquire the ¹H NMR spectrum according to the instrument's standard operating procedure. Ensure a sufficient number of scans to achieve an adequate signal-to-noise ratio.
-
Process the spectrum, including Fourier transformation, phase correction, and baseline correction.
-
Calibrate the chemical shift scale to the residual solvent peak or the internal standard (TMS at 0.00 ppm).
-
Integrate all peaks and assign them to the corresponding protons in the molecule's structure.
-
Compare the obtained spectrum (chemical shifts, splitting patterns, and integration values) with the reference spectrum.
-
Acceptance Criteria: The chemical shifts, splitting patterns, and relative integrations of the sample spectrum must be consistent with the structure and the reference spectrum.
Protocol: Purity Assessment by High-Performance Liquid Chromatography (HPLC)
Objective: To determine the purity of the starting material and quantify any impurities using HPLC with UV detection.
Materials:
-
Starting material sample
-
HPLC-grade solvents (e.g., acetonitrile, water, methanol)
-
HPLC column suitable for the analyte
-
Volumetric flasks and pipettes
-
Autosampler vials
Procedure:
-
Mobile Phase Preparation: Prepare the mobile phase(s) as per the established analytical method. Filter and degas the solvents before use.
-
Standard Preparation: Accurately prepare a stock solution of the reference standard at a known concentration (e.g., 1.0 mg/mL). Prepare a series of working standards by serial dilution to create a calibration curve.
-
Sample Preparation: Prepare a sample solution of the starting material at the same concentration as the primary standard (e.g., 1.0 mg/mL).
-
Instrument Setup: Set up the HPLC system with the appropriate column, mobile phase, flow rate, injection volume, and detector wavelength.
-
Analysis: Inject the prepared standards and the sample solution. Record the resulting chromatograms.
-
Data Processing: Integrate the peaks in each chromatogram. Create a calibration curve by plotting the peak area of the standard against its concentration.
-
Calculation: Determine the concentration of the main peak in the sample solution using the calibration curve. Calculate the purity as a percentage of the area of the main peak relative to the total area of all peaks (Area % method).
-
Acceptance Criteria: The purity of the starting material must be within the specified limit (e.g., ≥ 99.5%). Any single impurity should not exceed a specified threshold (e.g., ≤ 0.1%).
Documentation and Logical Relationships
Maintaining thorough documentation is a critical aspect of GMP and ensures traceability throughout the drug development process.[2] The relationship between documentation, materials, and decisions forms a logical chain that ensures quality and compliance.
Caption: Logical flow of documentation and material status from receipt to release.
Signaling Pathway Context (Hypothetical)
The sourcing of high-quality starting materials is the first step in synthesizing a novel compound intended to modulate a specific biological pathway. For instance, a novel kinase inhibitor might be designed to target the PI3K/AKT/mTOR pathway, which is often dysregulated in cancer.
Caption: Inhibition of the PI3K signaling pathway by a novel synthetic compound.
References
- 1. biopharminternational.com [biopharminternational.com]
- 2. Quality Control in Chemical Industry: Policies & Regulations [elchemy.com]
- 3. How to Choose the Right Reagent Vendor: A Strategic Guide for Laboratory Procurement Teams | Resources | Government Scientific Source [resources.govsci.com]
- 4. qualityfwd.com [qualityfwd.com]
- 5. propharmagroup.com [propharmagroup.com]
- 6. Are the Starting Materials for Synthesizing Your Target Molecules Commercially Available? | Jeremy Monat, PhD [bertiewooster.github.io]
- 7. drugpatentwatch.com [drugpatentwatch.com]
- 8. gmpsop.com [gmpsop.com]
- 9. A Step-by-Step Guide- Chemical Procurement in Drug Discovery [molport.com]
For researchers, scientists, and drug development professionals, the inability to access a patented research tool can represent a significant roadblock to innovation. When direct purchase or licensing is not an option, a number of legal and procedural pathways may be available. This document provides detailed application notes and protocols for navigating these complex scenarios.
I. Initial Assessment and Direct Negotiation Protocol
Before pursuing more complex legal avenues, a thorough initial assessment and a direct, professional approach to the patent holder are essential. This initial phase is often the most efficient and successful route to gaining access.
Protocol 1: Due Diligence and Initial Contact
-
Confirm Patent Status and Unavailability: Verify the patent's validity and that the tool is genuinely unavailable through standard commercial channels. Document all attempts to purchase or license the tool.
-
Identify the Patent Holder and Key Contacts: Determine the current assignee of the patent and identify the appropriate individuals to contact, typically within their technology transfer or legal department.
-
Develop a Strong Value Proposition: Clearly articulate the intended research, its scientific merit, and its potential for future innovation. Emphasize any non-commercial or academic nature of the research.[1]
-
Draft a Formal Letter of Intent to License: This non-binding document should professionally outline your request.
-
Key Components of the Letter of Intent:
-
Introduction: Introduce yourself, your institution, and the purpose of your research.
-
Identification of the Patented Tool: Clearly state the patent number and the specific research tool you wish to access.
-
Proposed Scope of Use: Define the intended research application, the duration of use, and whether the use will be for non-commercial or commercial purposes.[2]
-
Proposed Financial Terms: While negotiable, suggesting initial terms such as a flat fee, royalty on potential future inventions, or a milestone-based payment can initiate a constructive dialogue.[1][2]
-
Confidentiality: Include a statement of your willingness to enter into a confidentiality agreement to protect any sensitive information shared during negotiations.[3]
-
Request for a Response: Clearly state your desire to discuss the matter further and provide your contact information.
-
-
Negotiation Best Practices:
-
Be Prepared: Thoroughly research the patent holder's business interests and previous licensing agreements, if public.[1]
-
Be Flexible: Be open to various licensing structures, such as non-exclusive licenses for a specific field of use.[4]
-
Involve Your Institution's Technology Transfer Office (TTO): TTOs have expertise in negotiating intellectual property agreements and can provide invaluable support.[5]
II. Legal Pathways for Access
If direct negotiation fails, several legal mechanisms may be available, though they are generally more complex and resource-intensive. The availability and applicability of these options vary significantly by jurisdiction.
A. The Research Exemption (Experimental Use Exception)
The research exemption is a legal doctrine that, in some jurisdictions, allows for the use of a patented invention for non-commercial, experimental, or research purposes without infringing the patent. The scope of this exemption is narrow and varies widely.
Application Notes:
-
United States: The U.S. has a very narrow, common law "experimental use" exception that is generally limited to activities performed "for amusement, to satisfy idle curiosity, or for strictly philosophical inquiry."[6] It typically does not cover research with commercial implications, even if conducted at a non-profit institution.[6]
-
European Union: Many EU member states have a broader statutory research exemption that allows for the use of a patented invention for experimental purposes related to the subject matter of the invention.
-
Canada: Canada also has a statutory research exemption.
Protocol 2: Assessing and Invoking the Research Exemption
-
Jurisdictional Analysis: Consult with legal counsel to determine the scope of the research exemption in the relevant jurisdiction.
-
Nature of Research Assessment: Carefully evaluate whether your intended research falls within the narrow confines of the exemption. Key factors to consider include:
-
Is the research purely for scientific inquiry, or does it have a commercial purpose?[7]
-
Is the research intended to understand the invention itself or to use it as a tool in further research?
-
Will the results be published or kept as a trade secret?
-
-
Documentation: Meticulously document the non-commercial and experimental nature of your research.
-
Risk Assessment: Understand that relying on the research exemption carries a risk of litigation. A thorough legal opinion is crucial before proceeding.
B. Compulsory Licensing
A compulsory license is a government-granted license to use a patent without the consent of the patent holder. These are granted under specific circumstances, often related to public health crises, anti-competitive practices, or failure to work the patent in the jurisdiction.
Application Notes:
-
High Threshold: Obtaining a compulsory license is generally a difficult and lengthy process, with a high bar for approval.[8]
-
Grounds for Granting: Common grounds include national emergencies, public health needs, and anti-competitive behavior by the patent holder.[9]
-
Negotiation Prerequisite: Most jurisdictions require the applicant to have first made reasonable efforts to obtain a voluntary license from the patent holder.[9]
Protocol 3: Applying for a Compulsory License
-
Exhaust Negotiation Options: Demonstrate and document that you have made good-faith efforts to obtain a license on reasonable commercial terms.[9]
-
Identify the Competent Authority: Determine the government body responsible for granting compulsory licenses in the relevant jurisdiction (e.g., patent office, court).[10]
-
Prepare a Formal Application: The application should include:
-
Evidence of failed negotiations with the patent holder.
-
A clear justification for the need for the compulsory license, citing relevant legal grounds.
-
A detailed description of the intended use of the patented tool.
-
A proposed royalty payment to the patent holder.[10]
-
-
Legal Representation: Engage experienced legal counsel to navigate the complex application and potential legal challenges.
C. Government Use Rights (Bayh-Dole Act in the U.S.)
For inventions developed with federal funding in the United States, the Bayh-Dole Act grants the government certain rights. These "march-in rights" allow the government to require the patent holder to grant a license to a third party under specific circumstances.
Application Notes:
-
Federally Funded Inventions: This pathway is only applicable to inventions that were developed with U.S. federal government funding.
-
Grounds for March-In: The government can exercise these rights if it determines that the patent holder is not taking effective steps to achieve practical application of the invention, or if action is necessary to alleviate health or safety needs.
-
Rarely Invoked: The U.S. government has never actually exercised its march-in rights.
Protocol 4: Petitioning for Government Use Rights
-
Confirm Federal Funding: Verify that the research leading to the patented tool was funded by a U.S. federal agency.
-
Identify the Funding Agency: Determine the specific agency that provided the funding.
-
Prepare a Petition: Draft a formal petition to the funding agency outlining:
-
The patented invention and its unavailability.
-
The public need for the research tool.
-
Evidence that the patent holder is not making the tool available on reasonable terms.
-
-
Submit the Petition: File the petition with the head of the relevant funding agency.
III. Data on Legal Pathways
Obtaining precise quantitative data on the success rates of these legal pathways is challenging due to the confidential nature of many negotiations and the infrequency of certain legal actions.
| Legal Pathway | Reported Success Rate | Key Considerations |
| Direct Negotiation | Not publicly available, but generally considered the most common and successful route. | Success is highly dependent on the willingness of the patent holder and the negotiation strategy. |
| Research Exemption | Varies significantly by jurisdiction. In the U.S., it is a very narrow defense with a low success rate in litigation. | High risk of infringement litigation in jurisdictions with a narrow exemption. |
| Compulsory Licensing | Very low. Compulsory licenses are rarely granted, especially in high-income countries.[11] A WIPO survey indicated very few grants in the preceding decade.[12] | A lengthy and complex legal process with a high burden of proof on the applicant.[8] |
| Government Use (March-In Rights) | Zero. The U.S. government has never exercised its march-in rights under the Bayh-Dole Act. | A politically sensitive process with a very high threshold for government intervention. |
IV. Visualizing the Legal Pathways
The following diagrams illustrate the decision-making process and workflows for a researcher seeking to access a patented but unavailable research tool.
Diagram 1: Initial Assessment and Negotiation Workflow
Caption: Workflow for the initial steps of due diligence and direct negotiation.
Diagram 2: Decision Tree for Legal Pathways
Caption: Decision-making process for pursuing legal pathways after failed negotiations.
References
- 1. patentpc.com [patentpc.com]
- 2. Seven points to consider when negotiating a patent and know-how licence - Stevens & Bolton LLP [stevens-bolton.com]
- 3. gearhartlaw.com [gearhartlaw.com]
- 4. Negotiating Intellectual Property Licenses with University Technology Transfer Offices - Logan & Partners [loganpartners.com]
- 5. patentpc.com [patentpc.com]
- 6. Research Use Exemptions to Patent Infringement for Drug Discovery and Development in the United States - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Patented Invention for Research | DexPatent [dexpatent.com]
- 8. cms.law [cms.law]
- 9. everycrsreport.com [everycrsreport.com]
- 10. fastercapital.com [fastercapital.com]
- 11. Compulsory Licensing of Pharmaceuticals in High‐Income Countries: A Comparative Analysis - PMC [pmc.ncbi.nlm.nih.gov]
- 12. wipo.int [wipo.int]
Application Notes and Protocols for Imputing Missing Values
Audience: Researchers, scientists, and drug development professionals.
Disclaimer: This document provides a general framework and methodologies for imputing missing values. The optimal strategy is context-dependent and should be determined based on the specific characteristics of the dataset and the research objectives. It is crucial to pre-specify the methods for handling missing data in the study protocol and statistical analysis plan to ensure the integrity of clinical trial results.[1][2][3]
Introduction to Missing Data
Types of Missing Data Mechanisms
Understanding the mechanism of missingness is crucial for selecting an appropriate imputation strategy.[7][8] The three primary mechanisms are:
-
Missing Completely at Random (MCAR): The probability of a value being missing is independent of both observed and unobserved data.[9] For instance, a dropped lab sample. In this case, the complete cases are a random subsample of the original dataset.[10]
-
Missing at Random (MAR): The probability of a value being missing depends only on the observed data, not on the unobserved data.[9][11] For example, if male participants are less likely to complete a survey on mental health, the missingness is MAR if it can be explained by the 'gender' variable.
-
Missing Not at Random (MNAR): The probability of a value being missing depends on the unobserved data itself.[9][11] For example, a participant in a weight-loss study might skip a weigh-in because they are concerned about their lack of progress.[9] This is also referred to as a non-ignorable missing data mechanism.[11]
Methodologies for Imputing Missing Values
Imputation techniques can be broadly categorized into single imputation and multiple imputation methods.
Single Imputation Methods
Single imputation involves replacing each missing value with a single estimated value.[12][13] While straightforward to implement, these methods can underestimate the variability of the data and may lead to biased results.[7][14]
Common Single Imputation Techniques:
-
Mean/Median/Mode Imputation: This simple method replaces missing numerical values with the mean or median of the observed values for that variable.[5][12] For categorical variables, the mode (most frequent value) is used.[5][12]
-
Regression Imputation: This technique uses a regression model to predict missing values based on other variables in the dataset.[6][12]
-
Stochastic Regression Imputation: Similar to regression imputation, but adds a random error term to the predicted values, which helps to introduce more realistic variability.[12]
-
Hot-Deck Imputation: Missing values are replaced with an observed value from a "similar" record in the same dataset.[12]
Multiple Imputation (MI)
Multiple Imputation is a more sophisticated approach that addresses the uncertainty of missing data by creating multiple complete datasets.[1][15] Each missing value is replaced by a set of plausible values drawn from a distribution, reflecting the uncertainty about the true value.[15][16] The analysis is then performed on each of the imputed datasets, and the results are pooled to produce a single estimate with appropriate standard errors.[1][15]
Key steps in Multiple Imputation:
-
Imputation: Generate multiple (m) complete datasets by imputing the missing values.
-
Analysis: Analyze each of the m datasets using standard statistical methods.
-
Pooling: Combine the results from the m analyses into a single result using specific rules (e.g., Rubin's rules).[1]
Advantages of Multiple Imputation:
-
Accounts for the uncertainty of the imputed values, leading to more accurate standard errors and confidence intervals.[17]
-
Can provide unbiased estimates if the data are MAR.[10]
-
Flexible and can be used with various types of data and statistical models.[4]
Common MI Techniques:
-
Multivariate Imputation by Chained Equations (MICE): A flexible method that can handle different variable types (e.g., continuous, binary, categorical).[4] It involves specifying a conditional distribution for each variable with missing data and imputing values iteratively.
-
Predictive Mean Matching (PMM): A semi-parametric approach where the imputed value is a value from a donor case with a similar predicted value.
Data Presentation: Comparison of Imputation Methods
The following table summarizes the key characteristics and performance of different imputation methods.
| Imputation Method | Type | Key Assumption | Impact on Variance | Impact on Correlation | Computational Complexity |
| Mean/Median/Mode | Single | MCAR | Underestimates | Distorts towards zero | Very Low |
| Regression | Single | MAR | Underestimates | Artificially inflates | Low |
| Stochastic Regression | Single | MAR | Better preservation | Better preservation | Low to Moderate |
| Hot-Deck | Single | MAR | Can preserve | Can preserve | Moderate |
| Multiple Imputation (MICE) | Multiple | MAR | Accounts for uncertainty | Preserves relationships | High |
| k-Nearest Neighbors (KNN) | Single/Multiple | MAR | Can preserve | Can preserve | Moderate to High |
| MissForest | Multiple | MAR | Accounts for uncertainty | Preserves relationships | High |
A comparative study on missing laboratory data found that MissForest had the least imputation error for both continuous and categorical variables, followed by MICE, nearest neighbor, and mean imputation.[18]
Experimental Protocols
Protocol 1: Choosing an Imputation Strategy
This protocol outlines a systematic approach to selecting an appropriate imputation method.
-
Understand the Missing Data:
-
Quantify the extent of missing data for each variable and for the overall dataset.
-
Investigate the patterns of missingness. Are there specific variables or subgroups with more missing data?
-
Formulate hypotheses about the missing data mechanism (MCAR, MAR, or MNAR) by comparing the distributions of observed variables between cases with and without missing data.[19]
-
-
Define the Analysis Goal:
-
Clarify the primary research question and the statistical analysis plan. The imputation model should include all variables that will be in the final analysis model.[15]
-
-
Select an Imputation Method:
-
If the percentage of missing data is very low (e.g., <5%) and the data are likely MCAR, simple methods like complete case analysis or mean/median imputation might be considered, but with caution.[2]
-
For MAR data, multiple imputation is generally the recommended approach as it provides more robust and unbiased results.[1][15]
-
-
Implement the Imputation:
-
Use appropriate statistical software (e.g., R, SAS, Stata) to perform the imputation.
-
For multiple imputation, specify the number of imputations. While 3-5 imputations were historically suggested, more are generally recommended now.
-
-
Analyze and Pool Results (for MI):
-
Perform the planned statistical analysis on each imputed dataset.
-
Combine the results using established procedures (e.g., Rubin's rules).
-
-
Report the Findings:
-
Clearly document the amount of missing data, the chosen imputation method, and the justification for its use.[3][20]
-
Report the results of the analysis, including the pooled estimates and confidence intervals if multiple imputation was used.
-
Include sensitivity analyses to assess the robustness of the findings to the assumptions made about the missing data.[19]
-
Protocol 2: Implementing Multiple Imputation using MICE
This protocol provides a high-level overview of the steps involved in using the MICE algorithm.
-
Initial Imputation: Replace all missing values with a simple estimate, such as the mean of the observed values for that variable.
-
Iterative Imputation: a. Set one of the variables with missing data back to missing. b. Fit a regression model to predict this variable based on all other variables in the dataset. c. Use the regression model to impute the missing values for this variable. d. Repeat steps a-c for each variable with missing data. This completes one cycle.
-
Repeat Cycles: Repeat the entire cycle of imputing each variable multiple times to allow the imputed values to converge.
-
Generate Multiple Datasets: Repeat the entire process (steps 1-3) to create multiple imputed datasets. Each dataset will have slightly different imputed values, reflecting the uncertainty.
-
Analysis and Pooling: Analyze each of the generated datasets and pool the results.
Mandatory Visualization
The following diagrams illustrate key concepts and workflows related to missing data imputation.
References
- 1. quanticate.com [quanticate.com]
- 2. Imputation of missing data in clinical trials [embassy.science]
- 3. Best Practices for Documenting Missing Data Handling in Clinical Trials – Clinical Research Made Simple [clinicalstudies.in]
- 4. mospi.gov.in [mospi.gov.in]
- 5. Data Imputation Techniques: Handling Missing Data in Machine Learning [blog.mitsde.com]
- 6. 9 Popular Data Imputation Techniques In Machine Learning [dataaspirant.com]
- 7. Chapter 13 Imputation (Missing Data) | A Guide on Data Analysis [bookdown.org]
- 8. medium.com [medium.com]
- 9. ddismart.com [ddismart.com]
- 10. Missing Data and Multiple Imputation | Columbia University Mailman School of Public Health [publichealth.columbia.edu]
- 11. Missing Data in Clinical Studies: Issues and Methods - PMC [pmc.ncbi.nlm.nih.gov]
- 12. medium.com [medium.com]
- 13. Single imputation methods - Iris Eekhout | Missing data [missingdata.nl]
- 14. Single-Valued Imputation — Data Science in Practice [notes.dsc80.com]
- 15. Missing Data in Clinical Research: A Tutorial on Multiple Imputation - PMC [pmc.ncbi.nlm.nih.gov]
- 16. bmj.com [bmj.com]
- 17. Multiple Imputation: A Flexible Tool for Handling Missing Data - PMC [pmc.ncbi.nlm.nih.gov]
- 18. bmjopen.bmj.com [bmjopen.bmj.com]
- 19. Standards in the Prevention and Handling of Missing Data for Patient Centered Outcomes Research – A Systematic Review and Expert Consensus - PMC [pmc.ncbi.nlm.nih.gov]
- 20. medium.com [medium.com]
For Researchers, Scientists, and Drug Development Professionals
These application notes provide a comprehensive guide to utilizing computational methods for the identification of replacement compounds when a desired chemical probe, lead compound, or drug candidate becomes unavailable. This situation can arise due to synthetic challenges, intellectual property restrictions, or discontinuation by a supplier. The protocols outlined below detail a systematic workflow, from in silico screening to experimental validation, enabling the discovery of novel molecules with similar or improved biological activity.
Application Note 1: Overview of the Computational Replacement Workflow
The process of replacing an unavailable compound using computational methods involves a multi-step workflow that leverages both ligand-based and structure-based approaches to identify and validate suitable alternatives. This workflow is designed to minimize experimental costs and accelerate the discovery of new chemical entities with desired biological functions.
A typical workflow begins with defining the target and the properties of the unavailable compound. Based on the available information, either a ligand-based or a structure-based virtual screening approach is chosen. Ligand-based methods are ideal when the 3D structure of the target is unknown but a set of active and inactive molecules is available. Structure-based methods, on the other hand, are employed when a high-resolution 3D structure of the target protein is available.
Following the virtual screening, the top-ranked candidate compounds are subjected to further in silico filtering based on ADMET (Absorption, Distribution, Metabolism, Excretion, and Toxicity) properties to assess their drug-likeness. The most promising candidates are then procured or synthesized for experimental validation. This validation process typically involves a series of in vitro assays to confirm the compound's activity and potency against the biological target.
Application Note 2: Case Study - Virtual Screening for Kinase Inhibitor Replacement
This case study demonstrates the application of a combined ligand-based and structure-based virtual screening approach to identify a novel kinase inhibitor to replace a known but unavailable compound. The goal was to find a new chemical scaffold with similar or better inhibitory activity against a specific kinase involved in a cancer signaling pathway.
Computational Approach:
A hybrid virtual screening protocol was employed. Initially, a pharmacophore model was generated based on the chemical features of the unavailable inhibitor and other known active compounds. This model was used to screen a large commercial compound library. The resulting hits were then subjected to molecular docking into the ATP-binding site of the kinase crystal structure to predict their binding modes and affinities.
Experimental Validation:
The top-ranked compounds from the in silico screen were purchased and tested in a kinase activity assay to determine their half-maximal inhibitory concentration (IC50) values. Promising hits were further evaluated in cell-based assays to assess their effect on cancer cell proliferation.
Results:
The virtual screening campaign identified several potential replacement compounds with diverse chemical scaffolds. Experimental validation confirmed that a subset of these compounds exhibited potent inhibitory activity against the target kinase. The quantitative data for the original compound and the newly identified replacements are summarized in the table below.
| Compound ID | Method of Identification | Predicted Binding Affinity (kcal/mol) | Experimental IC50 (nM) | Cell Proliferation GI50 (µM) |
| Unavailable Compound | (Reference) | -10.2 | 15 | 0.5 |
| New Compound A | Virtual Screening | -9.8 | 25 | 0.8 |
| New Compound B | Virtual Screening | -11.1 | 8 | 0.3 |
| New Compound C | Virtual Screening | -9.5 | 50 | 1.2 |
Protocol 1: Ligand-Based Virtual Screening using Pharmacophore Modeling
This protocol outlines the steps for performing a ligand-based virtual screening to identify compounds with similar pharmacophoric features to an unavailable active compound.
1. Ligand Preparation: 1.1. Obtain the 2D or 3D structure of the unavailable active compound and a set of other known active and inactive molecules for the target of interest. 1.2. Generate low-energy 3D conformations for all molecules.
2. Pharmacophore Model Generation: 2.1. Use software such as LigandScout, Phase, or MOE to align the active compounds and identify common chemical features (e.g., hydrogen bond donors/acceptors, hydrophobic regions, aromatic rings). 2.2. Generate multiple pharmacophore hypotheses based on the identified features. 2.3. Validate the generated pharmacophore models by screening a test set of known active and inactive compounds. A good model should be able to distinguish between actives and inactives.
3. Virtual Screening: 3.1. Select a validated pharmacophore model as a 3D query. 3.2. Screen a large compound database (e.g., ZINC, ChEMBL, Enamine) against the pharmacophore query. 3.3. Rank the hit compounds based on their fit score to the pharmacophore model.
4. Hit Filtering and Selection: 4.1. Visually inspect the top-ranked hits to ensure they have diverse chemical scaffolds. 4.2. Apply drug-likeness filters (e.g., Lipinski's rule of five) and ADMET prediction tools to prioritize compounds with favorable pharmacokinetic properties. 4.3. Select a final set of compounds for experimental validation.
Protocol 2: Structure-Based Virtual Screening using Molecular Docking
This protocol describes the process of performing a structure-based virtual screening to identify compounds that are predicted to bind to a specific target protein.
1. Receptor and Ligand Preparation: 1.1. Obtain the 3D structure of the target protein from the Protein Data Bank (PDB) or through homology modeling. 1.2. Prepare the receptor by removing water molecules, adding hydrogen atoms, and assigning partial charges. 1.3. Prepare a library of small molecules for docking by generating 3D coordinates and assigning appropriate protonation states.
2. Molecular Docking: 2.1. Define the binding site on the receptor, typically based on the location of a co-crystallized ligand or through binding site prediction algorithms. 2.2. Use a molecular docking program (e.g., AutoDock Vina, Glide, DOCK) to dock the ligand library into the defined binding site. 2.3. The docking program will generate multiple binding poses for each ligand and score them based on a scoring function that estimates the binding affinity.
3. Post-Docking Analysis and Hit Selection: 3.1. Rank the docked compounds based on their predicted binding scores. 3.2. Visually inspect the binding poses of the top-ranked compounds to analyze their interactions with key residues in the binding site. 3.3. Apply filters for drug-likeness and ADMET properties. 3.4. Select a diverse set of promising compounds for experimental validation.
Protocol 3: Experimental Validation - In Vitro Kinase Assay (IC50 Determination)
This protocol provides a detailed method for determining the IC50 value of a computationally identified inhibitor against a specific kinase.
1. Materials and Reagents:
-
Recombinant kinase
-
Kinase substrate (peptide or protein)
-
ATP (Adenosine triphosphate)
-
Test compound (dissolved in DMSO)
-
Kinase assay buffer (e.g., Tris-HCl, MgCl2, DTT)
-
Detection reagent (e.g., ADP-Glo™, Kinase-Glo®)
-
384-well microplates
-
Plate reader (luminometer or spectrophotometer)
2. Assay Procedure: 2.1. Prepare a serial dilution of the test compound in DMSO. A typical starting concentration is 10 mM, with 1:3 serial dilutions. 2.2. In a 384-well plate, add 5 µL of the diluted test compound to the appropriate wells. Include wells for a positive control (no inhibitor) and a negative control (no enzyme). 2.3. Add 10 µL of a solution containing the kinase and its substrate in kinase assay buffer to each well. 2.4. Incubate the plate at room temperature for 10 minutes to allow the inhibitor to bind to the kinase. 2.5. Initiate the kinase reaction by adding 10 µL of ATP solution to each well. The final ATP concentration should be at or near the Km value for the kinase. 2.6. Incubate the plate at 30°C for 60 minutes. 2.7. Stop the reaction and detect the kinase activity using a suitable detection reagent according to the manufacturer's instructions. 2.8. Measure the signal (luminescence or absorbance) using a plate reader.
3. Data Analysis: 3.1. Calculate the percentage of kinase inhibition for each concentration of the test compound relative to the positive control. 3.2. Plot the percentage of inhibition against the logarithm of the inhibitor concentration. 3.3. Fit the data to a sigmoidal dose-response curve using a suitable software (e.g., GraphPad Prism) to determine the IC50 value.
Signaling Pathway Diagrams
Understanding the signaling pathway in which the target protein is involved is crucial for predicting the downstream effects of an inhibitor. Below are diagrams of two common signaling pathways frequently targeted in drug discovery.
Technical Support Center: Managing Discontinued Critical Antibodies
The discontinuation of a critical antibody can significantly disrupt research. This guide provides answers to frequently asked questions, troubleshooting advice, and detailed protocols to navigate this challenge effectively.
Frequently Asked Questions (FAQs)
Q1: My critical antibody has been discontinued (B1498344). What should I do first?
A: The first step is to not panic and to assess your current stock. Determine how much of the discontinued antibody you have remaining and estimate how long it will last based on your experimental needs. This will give you a timeline for finding and validating a suitable replacement. Next, contact the supplier to confirm the discontinuation and inquire if they have any remaining lots or recommend a specific replacement.
Q2: How do I find a suitable replacement antibody?
A: Several strategies can help you find a replacement:
-
Supplier Recommendations: Check the product page of the discontinued antibody on the supplier's website. They often suggest a replacement product.[1]
-
Antibody Search Engines: Utilize online antibody search engines and databases like Linscott's Directory, Antibodypedia, and the Validated Antibody Database (VAD) to find antibodies against your target from various suppliers.[2] Some suppliers even have dedicated search tools to find alternatives to discontinued products from other companies.[3][4]
-
Literature Search: Look for recent publications in your field to see what antibodies other researchers are using successfully for the same target and application.
-
Consider Recombinant Antibodies: Recombinant antibodies are produced from precise genetic sequences, offering high lot-to-lot consistency and a stable supply, which can prevent future discontinuation issues.[5][6][7]
Q3: What are the key differences between polyclonal, monoclonal, and recombinant antibodies?
A: Understanding the different types of antibodies can help you choose the best replacement for your needs.
| Antibody Type | Description | Advantages | Disadvantages |
| Polyclonal | A heterogeneous mix of antibodies that recognize multiple epitopes on a single antigen.[7][8] | Higher affinity for the antigen, more tolerant of minor changes in the antigen, and often better at detecting low-abundance proteins.[8] | Prone to batch-to-batch variability, which can affect reproducibility.[8][9] |
| Monoclonal | A homogeneous population of antibodies that all recognize the same single epitope on an antigen.[5][10] | High specificity, leading to lower background and more reproducible results.[5][8] | May be more sensitive to changes in the epitope's conformation.[11] |
| Recombinant | Produced in vitro using recombinant DNA technology, with their genetic sequences known and controlled.[6][7] | Highest lot-to-lot consistency, ensuring long-term supply and reproducibility.[5][6] Can be engineered for specific needs.[6] | Initial development can be more time-consuming and costly. |
Q4: What are the essential steps for validating a new antibody?
A: Antibody validation is crucial to ensure the new antibody performs as expected in your specific experimental context.[11][12] The validation process should confirm the antibody's specificity, selectivity, and reproducibility.[12][13] Key validation strategies include:
-
Western Blotting (WB): This is often the first step to verify that the antibody recognizes a protein of the correct molecular weight.[9][13][14]
-
Genetic Strategies (Knockout/Knockdown): Using knockout (KO) or knockdown (KD) cell lines or tissues is considered the gold standard for demonstrating antibody specificity.[9][14] The antibody should not produce a signal in the absence of the target protein.
-
Independent Antibody Comparison: Using two or more independent antibodies that recognize different epitopes on the same target should yield similar staining patterns.[11][12]
-
Orthogonal Validation: Compare the results from your antibody-based method with a non-antibody-based method, such as RNA-seq or mass spectrometry.[15]
-
Application-Specific Validation: You must validate the antibody for each specific application you intend to use it for (e.g., IHC, IF, IP, Flow Cytometry), as performance can vary significantly between techniques.[9][11]
Troubleshooting Guide
Problem: The new antibody shows a weak or no signal.
-
Optimize Antibody Concentration: The optimal dilution for the new antibody may be different from the old one. Perform a titration experiment to determine the best concentration.[14][16]
-
Check Protocol Compatibility: Review the new antibody's datasheet for recommended protocols. You may need to adjust incubation times, temperatures, or buffer compositions.[14][15]
-
Antigen Retrieval (for IHC/ICC): If you are performing immunohistochemistry or immunocytochemistry, the antigen retrieval method may need to be optimized for the new antibody.
-
Confirm Target Expression: Ensure that your positive control cells or tissues are expressing the target protein at detectable levels.[17]
Problem: The new antibody shows high background or non-specific bands.
-
Adjust Blocking Conditions: Increase the blocking time or try a different blocking agent (e.g., 5% non-fat milk, bovine serum albumin, or serum from the same species as the secondary antibody).[18]
-
Optimize Antibody Dilution: A higher than optimal concentration can lead to non-specific binding. Try further diluting the primary antibody.
-
Increase Washing Steps: More stringent or longer wash steps can help to remove non-specifically bound antibodies.
-
Use a More Specific Antibody: If non-specific binding persists, you may need to consider a different replacement antibody, such as a monoclonal or recombinant antibody, which often have higher specificity.[5]
Problem: The new antibody is not working in my specific application, even though it's validated by the manufacturer for it.
-
Fine-Tune Your Protocol: Manufacturer validation is a good starting point, but you should always confirm that the antibody works in your specific experimental setup.[15]
-
Check for Subtle Differences: Small variations in your protocol, such as the type of fixative used or the composition of your lysis buffer, can impact antibody performance.[11]
-
Contact Technical Support: The antibody supplier's technical support team can often provide valuable troubleshooting advice and may have additional data that is not on the datasheet.
Visual Workflows and Decision Guides
Detailed Experimental Protocols
Protocol 1: Western Blot for Antibody Validation
This protocol outlines the basic steps for validating a new antibody using Western Blotting.
-
Sample Preparation:
-
Gel Electrophoresis:
-
Protein Transfer:
-
Transfer the separated proteins from the gel to a nitrocellulose or PVDF membrane.
-
-
Immunoblotting:
-
Block the membrane for 1 hour at room temperature in a suitable blocking buffer (e.g., 5% non-fat milk or BSA in TBST).
-
Incubate the membrane with the primary antibody at the optimized dilution overnight at 4°C.
-
Wash the membrane three times for 5-10 minutes each with TBST.
-
Incubate the membrane with the appropriate HRP-conjugated secondary antibody for 1 hour at room temperature.
-
Wash the membrane again as in the previous step.
-
-
Detection:
Protocol 2: Immunofluorescence (IF) for Antibody Validation
This protocol provides a general workflow for validating an antibody for use in immunofluorescence.
-
Cell Culture and Fixation:
-
Permeabilization:
-
Blocking:
-
Block non-specific binding by incubating the cells in a blocking solution (e.g., PBS with 1-5% BSA and/or normal serum from the secondary antibody host species) for 1 hour at room temperature.[23]
-
-
Antibody Incubation:
-
Incubate the cells with the primary antibody at its optimal dilution in antibody dilution buffer for 1-2 hours at room temperature or overnight at 4°C.[23]
-
Include a negative control where the primary antibody is omitted.[24]
-
Wash the cells three times with PBS.
-
Incubate with a fluorophore-conjugated secondary antibody for 1 hour at room temperature, protected from light.[23]
-
-
Mounting and Imaging:
-
Wash the cells three times with PBS.
-
Counterstain nuclei with DAPI if desired.[22]
-
Mount the coverslips onto microscope slides using an anti-fade mounting medium.
-
Image the slides using a fluorescence microscope. The staining pattern should be consistent with the known subcellular localization of the target protein.
-
Protocol 3: Immunoprecipitation (IP) for Antibody Validation
This protocol describes how to validate an antibody for immunoprecipitation.
-
Lysate Preparation:
-
Prepare a cell lysate using a non-denaturing lysis buffer to preserve protein-protein interactions.[25]
-
Pre-clear the lysate by incubating it with protein A/G beads to reduce non-specific binding.
-
-
Immunoprecipitation:
-
Washing:
-
Pellet the beads by centrifugation and wash them several times with lysis buffer to remove non-specifically bound proteins.[25]
-
-
Elution and Analysis:
-
Elute the bound proteins from the beads by boiling in SDS-PAGE sample buffer.
-
Analyze the eluted proteins by Western Blotting, using an antibody against the target protein to confirm successful immunoprecipitation.[25]
-
References
- 1. bio-rad.com [bio-rad.com]
- 2. Research Resources - The Antibody Society [antibodysociety.org]
- 3. Antibody_Upgrade_Search_Engine | Proteintech Group [ptglab.com]
- 4. Replace Santa Cruz antibodies | Proteintech Group [ptglab.com]
- 5. precisionantibody.com [precisionantibody.com]
- 6. arp1.com [arp1.com]
- 7. Polyclonal vs monoclonal vs recombinant antibodies - a comparison | evitria [evitria.com]
- 8. Monoclonal, polyclonal & recombinant antibodies - Key differencesCiteAb Blog [blog.citeab.com]
- 9. hellobio.com [hellobio.com]
- 10. blog.cellsignal.com [blog.cellsignal.com]
- 11. bitesizebio.com [bitesizebio.com]
- 12. cusabio.com [cusabio.com]
- 13. Antibody validation - PMC [pmc.ncbi.nlm.nih.gov]
- 14. neobiotechnologies.com [neobiotechnologies.com]
- 15. biocompare.com [biocompare.com]
- 16. blog.cellsignal.com [blog.cellsignal.com]
- 17. licorbio.com [licorbio.com]
- 18. Tips and Techniques for Troubleshooting Immunohistochemistry (IHC) [sigmaaldrich.com]
- 19. Antibody validation by Western Blot SOP #012 [protocols.io]
- 20. licorbio.com [licorbio.com]
- 21. neobiotechnologies.com [neobiotechnologies.com]
- 22. Immunofluorescence (IF) Protocol | Rockland [rockland.com]
- 23. ptglab.com [ptglab.com]
- 24. bitesizebio.com [bitesizebio.com]
- 25. Immunoprecipitation Experimental Design Tips | Cell Signaling Technology [cellsignal.com]
- 26. Protocol for Immunoprecipitation - Creative Proteomics [creative-proteomics.com]
- 27. Immunoprecipitation (IP): The Complete Guide | Antibodies.com [antibodies.com]
- 28. Immunoprecipitation (IP) and co-immunoprecipitation protocol | Abcam [abcam.com]
Technical Support Center: Managing Corrupt or Incomplete Research Data
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in addressing issues of corrupt or incomplete data discovered during their experiments.
Troubleshooting Guides
Issue: My dataset has missing values. How should I proceed?
Initial Assessment:
-
Quantify the extent of missingness: Determine the percentage of missing data for each variable and overall. A small amount of missing data (e.g., <5%) may be manageable with simpler methods.[1]
-
Identify the pattern of missingness: Understanding why data is missing is crucial for selecting the appropriate handling method.[2][3] The three main types of missing data are:
-
Missing Completely at Random (MCAR): The missingness is unrelated to any observed or unobserved data.[2][3][4][5] For example, a broken piece of equipment leading to some missed measurements.
-
Missing at Random (MAR): The probability of a value being missing is related to other observed variables in the dataset, but not the missing value itself.[2][3] For instance, if male participants are less likely to answer a question about a specific health condition.
-
Missing Not at Random (MNAR): The missingness is related to the value of the missing data itself.[2][3] For example, individuals with very high blood pressure may be more likely to have missing blood pressure readings.
-
Recommended Actions:
Based on the initial assessment, choose one of the following approaches. It is crucial to document the chosen method and the rationale behind it for transparency and reproducibility.[6]
-
Deletion Methods: These are straightforward but can lead to loss of statistical power and biased results if the data are not MCAR.[2][5][7]
-
Listwise Deletion (Complete Case Analysis): Removes any case with a missing value in any of the variables being analyzed.[2][3] This is the most common method but can significantly reduce sample size.[5]
-
Pairwise Deletion: Only removes cases for a specific analysis for which they have missing data. This can be problematic as it results in analyses being run on different subsets of the data.[2][3]
-
-
Imputation Methods: These techniques involve filling in the missing values with plausible estimates.[2][7]
-
Single Imputation: Replaces each missing value with a single estimated value.[2][8] Common techniques include:
-
Mean/Median/Mode Imputation: Replaces missing values with the mean, median, or mode of the observed values for that variable.[2][9][10] This can reduce variability and distort relationships between variables.[9]
-
Regression Imputation: Uses a regression model to predict the missing values based on other variables in the dataset.[2][9]
-
Last Observation Carried Forward (LOCF): Used in longitudinal studies, it replaces a missing value with the last observed value for that individual.[2][3] This method can introduce bias.[3]
-
-
Multiple Imputation: A more sophisticated approach that generates multiple plausible values for each missing data point, creating several complete datasets.[3][9][11] The analysis is performed on each dataset, and the results are then pooled. This method accounts for the uncertainty of the missing values and is often considered the gold standard.[11][12]
-
Experimental Protocol: Multiple Imputation Workflow
-
Imputation Phase:
-
Select the variables with missing data and a set of predictor variables from the dataset.
-
Use a statistical software package (e.g., R with the mice package, SAS with PROC MI) to generate multiple (e.g., 5-10) complete datasets. The software will use a specified statistical model to predict and impute the missing values.
-
-
Analysis Phase:
-
Perform the planned statistical analysis on each of the imputed datasets independently.
-
-
Pooling Phase:
-
Combine the results (e.g., parameter estimates, standard errors) from each analysis using specific rules (e.g., Rubin's rules) to obtain a single set of results. This pooled result will incorporate the uncertainty associated with the imputed values.
-
Issue: I suspect my data is corrupt. What are the signs and what should I do?
Signs of Data Corruption:
-
Inconsistent Data: Values that contradict each other or established rules (e.g., a patient's death date preceding their diagnosis date).[6]
-
Outliers: Extreme values that fall far outside the expected range.[13]
-
Structural Errors: Typos, incorrect capitalization, and inconsistent naming conventions.[14]
-
Duplicate Records: The same observation appearing multiple times.[15][16]
-
Systematic Errors: Unexpected patterns or trends in the data that suggest a measurement or recording issue.
Troubleshooting Workflow for Corrupt Data
The following diagram illustrates the logical steps to take when you suspect data corruption:
References
- 1. learn.crenc.org [learn.crenc.org]
- 2. Handling missing data in research - PMC [pmc.ncbi.nlm.nih.gov]
- 3. How to handle missing data | Clariscience Magazine [clariscience.com]
- 4. ddismart.com [ddismart.com]
- 5. Handling missing data in RCTs; a review of the top medical journals - PMC [pmc.ncbi.nlm.nih.gov]
- 6. researchgate.net [researchgate.net]
- 7. ferran.torres.name [ferran.torres.name]
- 8. clinicalpursuit.com [clinicalpursuit.com]
- 9. How to Handle Missing Data in Quantitative Research - Insight7 - Call Analytics & AI Coaching for Customer Teams [insight7.io]
- 10. quora.com [quora.com]
- 11. Handling missing data in clinical research - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. jobya.com [jobya.com]
- 14. tableau.com [tableau.com]
- 15. geopoll.com [geopoll.com]
- 16. Data Cleaning During the Research Data Management Process – Research Data Management in the Canadian Context [ecampusontario.pressbooks.pub]
This guide provides troubleshooting strategies and answers to frequently asked questions for researchers, scientists, and drug development professionals facing the challenge of reproducing experiments when key materials are unavailable.
Frequently Asked Questions (FAQs)
Q1: What are the immediate steps if a crucial material from a published study is unavailable?
A1: First, meticulously re-read the original paper's methods section for any details about the material, such as catalog numbers, lot numbers, or specific preparation details.[1][2] Contact the corresponding author of the study to inquire if they have any remaining stock, can provide the protocol to recreate the material, or can suggest a suitable alternative they have validated. When sourcing an alternative, prioritize materials from reputable suppliers and plan for a rigorous validation process to ensure it performs equivalently to the original.[3][4]
Q2: A specific monoclonal antibody used in a key study is discontinued (B1498344). How can I find and validate a suitable replacement?
A2: Finding a replacement for a discontinued antibody is a common challenge. Start by searching antibody databases using the target protein and application (e.g., Western blot, IHC) as keywords. Look for antibodies that recognize a different epitope on the same target protein, as this can provide strong evidence for specificity if the detection patterns are similar.[5][6] Once a candidate is identified, it is crucial to validate it for your specific application and conditions, as performance can vary significantly.[5][7]
Q3: The exact cell line from a foundational experiment is no longer available from public repositories or the originating lab. What are my options?
A3: If a specific cell line is unobtainable, first check cell line databases like the Cellosaurus for known aliases or if it has been deposited under a different name.[8][9] If it's truly unavailable, consider if another cell line with a similar genetic background or expressing the key pathway of interest could be a suitable substitute. If a substitute is used, it is imperative to perform cell line authentication via methods like Short Tandem Repeat (STR) profiling to ensure its identity and rule out cross-contamination.[10][11][12] All results using a substitute cell line must be interpreted with the caveat that it is not the original.
Q4: An experiment requires a custom-synthesized chemical or reagent that I cannot obtain. What is the best course of action?
A4: First, contact the original authors; they may be able to provide a sample or the detailed synthesis protocol. If that is not possible, a thorough literature search may reveal alternative synthesis pathways.[13] You can also engage a custom synthesis company, providing them with all available information from the original publication. If synthesis is not feasible, investigate whether a commercially available analog with a similar structure and function could be used, but this will require extensive validation to confirm it produces comparable results in the specific assay.[13]
Troubleshooting Guides & Experimental Protocols
When an original antibody is unavailable, the replacement must be rigorously validated. Validation confirms specificity (binds to the target), selectivity (does not bind to off-targets), and reproducibility for the intended application.[14][15]
Detailed Protocol: Antibody Validation for Western Blot
-
Initial Screening:
-
Objective: Confirm the antibody detects a protein of the correct molecular weight.
-
Method: Perform a Western blot using lysates from positive control cells (known to express the target) and negative control cells (known to not express the target).[14] A specific antibody should show a strong band at the expected molecular weight only in the positive control lane.
-
-
Specificity Confirmation (Genetic Strategy):
-
Objective: Verify the antibody's target specificity using genetic knockdown or knockout.
-
Method: Use CRISPR/Cas9 or siRNA to create a knockout or knockdown of the target gene in your cell line.[5][14] Run a Western blot comparing the wild-type and the modified cell lysates. The band corresponding to the target protein should be absent or significantly reduced in the knockout/knockdown lane.[7]
-
-
Orthogonal Strategy:
-
Objective: Correlate the antibody-based results with a non-antibody-based method.
-
Method: Use a technique like mass spectrometry to identify proteins in your sample.[7] The abundance of the target protein measured by mass spectrometry should correlate with the signal intensity observed in the Western blot.
-
-
Documentation:
-
Record all details: antibody manufacturer, catalog number, lot number, dilution used, and all validation results. This is critical for the reproducibility of your own work.[16]
-
Using misidentified or cross-contaminated cell lines is a major cause of irreproducible research.[10] Authentication is mandatory when substituting a cell line.
Detailed Protocol: STR Profiling for Human Cell Lines
-
Sample Preparation: Grow a fresh, low-passage culture of the cell line to be authenticated.[12] Harvest cells and extract genomic DNA using a commercial kit.
-
PCR Amplification: Amplify the STR loci using a multiplex PCR kit that targets standard genomic markers.[12] These kits simultaneously amplify multiple STR markers.
-
Fragment Analysis: The fluorescently labeled PCR products are separated by size using capillary electrophoresis.
-
Profile Comparison: The resulting STR profile (a unique DNA fingerprint) is compared to a reference database of known cell line profiles (e.g., ATCC, DSMZ).[8] A match confirms the cell line's identity. If no reference is available, the profile should be documented to ensure it is unique and can be referenced in the future.[8]
-
Mycoplasma Testing: Always test for mycoplasma contamination, as it can alter cell physiology and experimental outcomes.[8][9]
Data on Irreproducibility
The inability to obtain key materials is a significant factor in the widely discussed "reproducibility crisis."[1][2] Quantitative data highlights the scope of the problem.
| Metric | Finding | Source |
| Reproducibility of Preclinical Cancer Studies | Only 11% (6 out of 53) of "landmark" preclinical cancer studies could be reproduced. | Begley & Ellis (2012) /[17] |
| Reproducibility by Pharmaceutical Companies | Researchers at Bayer found that only about 20-25% of published preclinical studies could be validated. | Prinz et al. (2011) /[18] |
| Failure to Reproduce Another Scientist's Work | A survey in Nature revealed that more than 70% of researchers have tried and failed to reproduce another scientist's experiments.[19] | Baker (2016) |
| Failure to Reproduce Own Work | In the same Nature survey, more than 50% of researchers reported that they have failed to reproduce their own experiments.[19] | Baker (2016) |
| Identification of Materials in Publications | A 2013 study found that just under 50% of scientific resources mentioned in published articles were not identifiable.[20] | Vasilevsky et al. (2013) /[20] |
Visualizations: Workflows and Pathways
This diagram outlines a logical process for researchers to follow when a required experimental material is not available.
This workflow illustrates the key validation pillars recommended for ensuring a replacement antibody is specific and effective for the intended application.
This diagram shows how using a non-validated or different reagent (e.g., an inhibitor) can lead to off-target effects and irreproducible results compared to the original, specific reagent.
References
- 1. The challenges of reproducibility in life science research | Malvern Panalytical [malvernpanalytical.com]
- 2. The reproducibility “crisis”: Reaction to replication crisis should not stifle innovation - PMC [pmc.ncbi.nlm.nih.gov]
- 3. How we validate new laboratory reagents - Ambar Lab [ambar-lab.com]
- 4. blog.edvotek.com [blog.edvotek.com]
- 5. bitesizebio.com [bitesizebio.com]
- 6. hellobio.com [hellobio.com]
- 7. blog.addgene.org [blog.addgene.org]
- 8. Cell line authentication: a necessity for reproducible biomedical research - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Cell line authentication and validation is a key requirement for Journal of Cell Communication and Signaling publications - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. medschool.cuanschutz.edu [medschool.cuanschutz.edu]
- 12. atcc.org [atcc.org]
- 13. Substitution – Chemical Safety in Science Education [chesse.org]
- 14. cusabio.com [cusabio.com]
- 15. Validation of antibodies: Lessons learned from the Common Fund Protein Capture Reagents Program - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Validating a New Test in Your Laboratory [apbiocode.com]
- 17. The Trouble with Reproducing Results - Labtag Blog [blog.labtag.com]
- 18. Reproducibility and Research Integrity - PMC [pmc.ncbi.nlm.nih.gov]
- 19. reddit.com [reddit.com]
- 20. sciencedaily.com [sciencedaily.com]
Technical Support Center: Troubleshooting Experiment Failure Due to Compound Impurity
This technical support center is designed for researchers, scientists, and drug development professionals who have encountered experimental setbacks and suspect that the purity of a chemical compound may be the root cause. Here, you will find troubleshooting guides, frequently asked questions (FAQs), detailed experimental protocols, and data to help you diagnose and resolve these issues.
Frequently Asked Questions (FAQs)
Q1: My experiment, which previously worked, is now failing or giving inconsistent results. Could my compound be the problem?
A1: Yes, inconsistent results in bioassays can be a significant indicator of compound instability or impurity.[1] Degradation of the compound over time can lead to a decreased concentration of the active molecule, resulting in underestimation of its activity and poor reproducibility.[1] Factors such as the compound's chemical nature, the composition of the assay medium, and the duration of incubation can all contribute to its degradation.[1]
Q2: What are the common causes of compound degradation and impurity?
A2: Chemical compounds can degrade through several common pathways, often influenced by storage and handling conditions:
-
Oxidation: Reaction with oxygen can alter the structure and activity of a compound.[2]
-
Hydrolysis: The breakdown of a compound due to reaction with water is a common issue, especially for compounds stored in solution or in humid environments.[2]
-
Photolysis: Exposure to light, particularly UV radiation, can break down light-sensitive compounds.[2] Improper storage, such as exposure to temperature fluctuations, light, and moisture, can accelerate these degradation processes.
Q3: How can impurities affect my experimental results?
A3: Impurities can have a wide range of detrimental effects on experimental outcomes:
-
Altered Potency: Impurities can inhibit or enhance the activity of the primary compound, leading to misleading IC50 or EC50 values.[3]
-
Reduced Efficacy: Degradation of the active pharmaceutical ingredient (API) can lower its effective concentration, diminishing its therapeutic or biological effect.
-
Toxicity: Impurities may be toxic to cells, leading to unexpected cytotoxicity in cell-based assays.
-
Changes in Physical Properties: Impurities can alter the solubility and stability of the compound.[4]
Q4: I suspect my compound is no longer pure. What is the first step I should take?
A4: The first step is to pause and systematically assess the situation. It is often recommended to repeat the experiment, paying close attention to each component and step.[5][6] Before repeating, consider performing a quick purity check of your compound using a straightforward method like Thin Layer Chromatography (TLC) if applicable, or proceeding to more quantitative methods if the issue persists.
Q5: What are the standard methods to verify the purity of my compound?
A5: Several analytical techniques can be used to assess compound purity with high accuracy:
-
High-Performance Liquid Chromatography (HPLC): A widely used and powerful technique for separating and quantifying components in a mixture.
-
Quantitative Nuclear Magnetic Resonance (qNMR): Provides information on the structure and quantity of a compound and its impurities.
-
Mass Spectrometry (MS): Can be coupled with liquid chromatography (LC-MS) or gas chromatography (GC-MS) to identify and quantify impurities based on their mass-to-charge ratio.
Troubleshooting Guide
If you suspect your compound's impurity is the cause of a failed experiment, follow this step-by-step troubleshooting guide.
Diagram: Troubleshooting Workflow for Suspected Compound Impurity
Caption: A logical workflow for troubleshooting experiments where compound impurity is suspected.
Data on Compound Purity and its Impact
The presence of impurities, even in small amounts, can significantly alter the outcome of an experiment. The following tables provide quantitative data on acceptable impurity levels and the impact of common laboratory solvents on experimental results.
Table 1: ICH Thresholds for Impurities in New Drug Substances
| Maximum Daily Dose | Reporting Threshold | Identification Threshold | Qualification Threshold |
| ≤ 2 g/day | 0.05% | 0.10% | 0.15% |
| > 2 g/day | 0.03% | 0.05% | 0.05% |
| (Source: ICH Harmonised Tripartite Guideline Q3A(R2)) |
Table 2: Effect of DMSO Concentration on Cell Viability
| Cell Line | DMSO Concentration | Exposure Time | Cell Viability Reduction |
| Human Apical Papilla Cells | 1% | 72 hours | Significant cytotoxicity observed |
| Human Apical Papilla Cells | 5% | 24 hours | > 30% (considered cytotoxic) |
| Human Apical Papilla Cells | 10% | 48 hours | Significant cytotoxicity observed |
| Human Fibroblast-like Synoviocytes | > 0.1% | 24 hours | ≈ 15% |
| Human Fibroblast-like Synoviocytes | 0.5% | 24 hours | ≈ 25% |
| (Data compiled from multiple sources)[7][8] |
Table 3: Impact of Solvents on Acetylcholinesterase (AChE) Activity
| Solvent | Effect on AChE Activity | Type of Inhibition |
| DMSO | Potent Inhibitor | Mixed (Competitive/Non-competitive) |
| Acetonitrile | Inhibitor | Competitive |
| Ethanol | Inhibitor | Non-competitive |
| Methanol | Negligible Impact | - |
| (Source: PubMed, DOI: 10.2174/1871524923666230417094549)[9] |
Experimental Protocols
Below are detailed methodologies for two key experiments to assess the purity of your compound.
Protocol 1: Purity Analysis by High-Performance Liquid Chromatography (HPLC)
Objective: To separate and quantify the main compound and any impurities.
Materials:
-
Synthesized compound
-
HPLC-grade solvents (e.g., acetonitrile, methanol, water)
-
Volumetric flasks and pipettes
-
HPLC system with a suitable detector (e.g., UV-Vis or Diode Array Detector)
-
Appropriate HPLC column (e.g., C18 reversed-phase)
Procedure:
-
Sample Preparation:
-
Accurately weigh 1-5 mg of the compound.
-
Dissolve the sample in a suitable solvent to a final concentration of approximately 1 mg/mL. The solvent should ideally be the initial mobile phase composition.
-
Use sonication to aid dissolution if necessary.
-
Filter the sample through a 0.22 µm syringe filter to remove any particulate matter.
-
-
Chromatographic Conditions (Example for a C18 column):
-
Mobile Phase A: Water with 0.1% formic acid
-
Mobile Phase B: Acetonitrile with 0.1% formic acid
-
Gradient: Start with a low percentage of B, and gradually increase to elute more hydrophobic compounds. A typical gradient might be 5% to 95% B over 20 minutes.
-
Flow Rate: 1.0 mL/min
-
Column Temperature: 30 °C
-
Detection Wavelength: Select a wavelength where the main compound has strong absorbance.
-
-
Analysis:
-
Inject a known volume of the prepared sample (e.g., 10 µL) into the HPLC system.
-
Record the chromatogram.
-
Identify the peak corresponding to your compound of interest based on its retention time (if known from a reference standard).
-
Calculate the purity based on the area percent of the main peak relative to the total area of all peaks in the chromatogram.
-
Diagram: HPLC Purity Analysis Workflow
Caption: Workflow for compound purity analysis using HPLC.
Protocol 2: Purity Assessment by Quantitative NMR (qNMR)
Objective: To determine the absolute purity of a compound using an internal standard.
Materials:
-
Compound of interest
-
High-purity internal standard (e.g., maleic anhydride, dimethyl sulfone) with a known purity.
-
Deuterated NMR solvent (e.g., Chloroform-d, DMSO-d6)
-
High-precision analytical balance
-
NMR spectrometer (400 MHz or higher)
-
NMR tubes
Procedure:
-
Sample Preparation:
-
Accurately weigh approximately 10-20 mg of the compound of interest into a clean vial.
-
Accurately weigh approximately 5-10 mg of the internal standard into the same vial.
-
Dissolve the mixture in a precise volume (e.g., 0.6 mL) of the deuterated solvent.
-
Vortex the vial to ensure the sample is completely dissolved and homogenous.
-
Transfer the solution to an NMR tube.
-
-
NMR Data Acquisition:
-
Acquire a ¹H NMR spectrum under quantitative conditions. Key parameters include:
-
A 90° pulse angle.
-
A long relaxation delay (D1) of at least 5 times the longest T1 relaxation time of the signals of interest.
-
A sufficient number of scans to achieve a high signal-to-noise ratio (S/N > 250:1 for accurate integration).
-
-
-
Data Processing and Analysis:
-
Process the spectrum with appropriate phasing and baseline correction.
-
Integrate a well-resolved signal for the compound of interest and a signal for the internal standard.
-
Calculate the purity using the following formula:
Purity (%) = (Isample / Nsample) * (Nstd / Istd) * (MWsample / Wsample) * (Wstd / MWstd) * Pstd
Where:
-
I = Integral value
-
N = Number of protons for the integrated signal
-
MW = Molecular weight
-
W = Weight
-
P = Purity of the standard
-
sample = Compound of interest
-
std = Internal standard
-
Diagram: Impact of Impurity on a Signaling Pathway
Caption: An impurity in a kinase inhibitor preparation can lead to off-target effects, complicating the interpretation of experimental results.
References
- 1. benchchem.com [benchchem.com]
- 2. benchchem.com [benchchem.com]
- 3. Biochemical assays for kinase activity detection - Celtarys [celtarys.com]
- 4. m.youtube.com [m.youtube.com]
- 5. bitesizebio.com [bitesizebio.com]
- 6. go.zageno.com [go.zageno.com]
- 7. Dimethyl sulfoxide affects the viability and mineralization activity of apical papilla cells in vitro - PMC [pmc.ncbi.nlm.nih.gov]
- 8. mdpi.com [mdpi.com]
- 9. Effect of Organic Solvents on Acetylcholinesterase Inhibition and Enzyme Kinetics - PubMed [pubmed.ncbi.nlm.nih.gov]
Technical Support Center: Protocol Refinement with Alternative Reagents
Welcome to the Technical Support Center for researchers, scientists, and drug development professionals. This resource provides guidance on adapting and troubleshooting experimental protocols when substituting reagents.
Frequently Asked Questions (FAQs)
Q1: What are the initial steps to consider when substituting a reagent in an established protocol?
A1: Before incorporating a new reagent, it is crucial to carefully review the manufacturer's instructions for any differences in storage, handling, and concentration recommendations.[1] A side-by-side comparison of the product specifications, such as purity and formulation, is also essential.[2][3] To ensure the reliability of your results, perform a small-scale pilot experiment to validate the new reagent's performance in your specific application.[2]
Q2: My signal-to-noise ratio has decreased after switching to a new antibody. How can I troubleshoot this?
A2: A decrease in signal-to-noise ratio can stem from several factors. First, verify that the new antibody's optimal concentration is the same as the previous one; you may need to perform a titration to determine the new optimal concentration. Additionally, review the incubation times and temperatures, as the new antibody may have different binding kinetics. Finally, ensure the blocking buffer and wash protocols are compatible with the new reagent.
Q3: I am observing unexpected, non-specific bands in my Western Blot after changing the secondary antibody. What could be the cause?
A3: Non-specific binding is a common issue when changing reagents.[4] Ensure that your blocking step is sufficient and that the secondary antibody is not cross-reacting with other proteins in your sample. You might consider increasing the stringency of your wash steps by adding a mild detergent like Tween 20. It is also important to confirm that the new secondary antibody is from a different host species than the primary antibody to avoid cross-reactivity.
Q4: After substituting a key enzyme in my assay, the reaction kinetics appear altered. How should I proceed?
A4: Enzymes from different suppliers can have variations in activity units and formulation.[5] It is critical to normalize the enzyme concentration based on its specific activity. You may also need to re-optimize other assay parameters such as pH, temperature, and substrate concentration to ensure optimal performance with the new enzyme.[5]
Troubleshooting Guides
Issue: Inconsistent Results After Reagent Substitution
Variations in reagent formulation and quality can lead to inconsistent experimental outcomes.[6] This guide provides a systematic approach to identifying and resolving these inconsistencies.
Troubleshooting Workflow
Caption: Troubleshooting workflow for inconsistent results.
Issue: Complete Loss of Signal
A complete loss of signal indicates a critical failure in the experimental setup, often related to the new reagent.
Logical Troubleshooting Pathway
Caption: Logical pathway for troubleshooting signal loss.
Experimental Protocols
Protocol: Reagent Validation via Parallel Experimentation
This protocol outlines a method for validating an alternative reagent by comparing its performance directly against the original reagent.
Methodology:
-
Preparation: Prepare two identical sets of experimental samples.
-
Reagent Preparation: Prepare both the original and the alternative reagents according to their respective manufacturer's instructions. Ensure the final working concentrations are equivalent based on the product specifications.
-
Execution: Run the two sets of samples in parallel, with the only variable being the reagent used.
-
Data Collection: Collect data using the same parameters and instrumentation for both experimental sets.
-
Analysis: Compare the key performance metrics between the two groups.
Data Presentation: Comparison of Key Performance Metrics
| Metric | Original Reagent | Alternative Reagent | % Difference | Acceptance Criteria |
| Signal Intensity (a.u.) | 15,234 | 14,890 | -2.26% | < 10% |
| Signal-to-Noise Ratio | 12.5 | 11.8 | -5.60% | < 15% |
| Specificity (% of total signal) | 95% | 93% | -2.11% | > 90% |
| Intra-assay CV (%) | 4.2% | 4.8% | +14.29% | < 5% |
Protocol: Optimizing Antibody Concentration
This protocol describes how to determine the optimal concentration for a new antibody using a titration experiment.
Methodology:
-
Prepare Antigen-Coated Plates: Coat microtiter plate wells with a consistent amount of the target antigen.
-
Serial Dilution: Prepare a series of dilutions of the new antibody, for example, ranging from 1:100 to 1:10,000.
-
Incubation: Add the different antibody dilutions to the wells and incubate under standard conditions.
-
Detection: Add the secondary antibody and substrate, and measure the signal.
-
Analysis: Plot the signal intensity against the antibody dilution to determine the concentration that gives the best signal-to-noise ratio.
Data Presentation: Antibody Titration Curve
| Antibody Dilution | Signal (OD450) | Background (OD450) | Signal-to-Noise |
| 1:500 | 2.85 | 0.45 | 6.3 |
| 1:1000 | 2.50 | 0.20 | 12.5 |
| 1:2000 | 1.80 | 0.10 | 18.0 |
| 1:4000 | 1.10 | 0.08 | 13.8 |
| 1:8000 | 0.60 | 0.07 | 8.6 |
Signaling Pathway Diagram
Example: Impact of a new kinase inhibitor on the MAPK/ERK Pathway
This diagram illustrates a common signaling pathway and can be used to visualize the expected impact of an alternative reagent, such as a new inhibitor.
Caption: MAPK/ERK signaling pathway with inhibitor action.
References
- 1. Converting from one reagent to another | FUJIFILM Wako [wakopyrostar.com]
- 2. How we validate new laboratory reagents - Ambar Lab [ambar-lab.com]
- 3. dcfinechemicals.com [dcfinechemicals.com]
- 4. bosterbio.com [bosterbio.com]
- 5. fleetbioprocessing.co.uk [fleetbioprocessing.co.uk]
- 6. clpmag.com [clpmag.com]
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) to assist researchers, scientists, and drug development professionals in overcoming experimental hurdles when specific cell lines are unavailable.
Frequently Asked Questions (FAQs)
Q1: The specific cell line I need for my experiment is unavailable from any commercial or academic repository. What are my immediate options?
A1: When a required cell line is unavailable, you have several strategic options to consider:
-
Identify an Alternative Cell Line: Search for a different cell line with a similar genetic background, tissue of origin, and expression profile of your target of interest. Reputable cell line databases can assist in this search.
-
Generate an Isogenic Cell Line: If you have a closely related cell line, you can use genome editing technologies like CRISPR/Cas9 to introduce the specific mutation or characteristic you need, creating an isogenic line.[1][2][3]
-
Reprogram Somatic Cells: Consider reprogramming readily available somatic cells (e.g., fibroblasts) into induced pluripotent stem cells (iPSCs) and then differentiating them into the desired cell type.[4][5][6][7]
-
Explore 3D Organoid Models: For many studies, patient-derived or stem cell-derived 3D organoids can serve as a more physiologically relevant alternative to 2D cell cultures.[8][9][10]
Q2: I have obtained a cell line from another lab, but I'm concerned about its identity. How can I authenticate it?
A2: Cell line authentication is crucial to ensure the validity of your research.[11][12] Misidentification and cross-contamination are widespread issues.[13][14] The gold standard for authenticating human cell lines is Short Tandem Repeat (STR) profiling.[11][15][16] For non-human cell lines, methods like isoenzyme analysis, karyotyping, and DNA barcoding can be used.[11][12][17] It is recommended to source cell lines from reputable repositories like ATCC to ensure they are authenticated.[18][19]
Q3: My cells are growing poorly or dying after thawing. What could be the cause and how can I troubleshoot this?
A3: Poor cell viability post-thawing can be due to several factors, including improper freezing or thawing techniques, contamination, or issues with the culture medium.[20][21]
-
Thawing Protocol: Ensure rapid thawing in a 37°C water bath and gentle handling of the cells.[20]
-
Cryoprotectant Removal: It's important to remove the cryoprotectant (like DMSO) by centrifuging the cells and resuspending them in fresh medium.[21]
-
Cell Viability Assessment: Use a method like trypan blue staining to accurately assess the percentage of viable cells after thawing.[20][22] A drop in viability is expected, but a significant loss may indicate a problem.[23][24][25]
-
Contamination Check: Regularly test your cultures for common contaminants like mycoplasma, which may not be visible but can affect cell health.[26][27][28][29]
Q4: I'm considering using 3D organoids as an alternative to a 2D cell line. What are the key advantages and disadvantages?
A4: 3D organoids offer a more physiologically relevant model compared to traditional 2D cell cultures by better mimicking the architecture and function of an organ.[8][30] However, they also present some challenges.
| Feature | 2D Cell Culture | 3D Organoid Culture |
| Physiological Relevance | Low: Lacks complex cell-cell and cell-matrix interactions.[8][10] | High: Mimics organ architecture and function.[8] |
| Predictive Accuracy | Lower for drug efficacy and toxicity.[8] | Higher, leading to better predictions.[8] |
| Cost | Relatively low.[8] | Higher due to specialized media and longer culture times.[8] |
| Throughput | High-throughput screening is well-established. | Lower throughput and more challenging to scale.[8] |
| Complexity | Simple to culture and maintain.[8] | Requires more complex and precise growth conditions.[8] |
Troubleshooting Guides
Guide 1: Unavailable Cell Line Workflow
This guide provides a step-by-step workflow for researchers when a desired cell line is not available.
Caption: Decision workflow for unavailable cell lines.
Guide 2: Cell Line Authentication and Quality Control
This guide outlines the critical steps for ensuring the identity and quality of your cell lines.
Caption: Cell line authentication and QC workflow.
Experimental Protocols
Protocol 1: Generating an Isogenic Cell Line using CRISPR/Cas9
This protocol provides a general overview for creating an isogenic cell line.
-
Design and Synthesize guide RNA (sgRNA): Design sgRNAs targeting the genomic locus of interest.
-
Vector Construction: Clone the sgRNA into a Cas9 expression vector.[31]
-
Transfection: Transfect the host cell line with the CRISPR/Cas9 plasmids.[1][31]
-
Single-Cell Cloning: Isolate single cells to establish clonal populations.[32]
-
Screening and Validation: Screen the clones for the desired mutation using PCR and sequencing.[1]
-
Expansion: Expand the successfully edited clones to generate a stable isogenic cell line.[32]
Protocol 2: Reprogramming Somatic Cells to iPSCs
This protocol outlines the basic steps for generating iPSCs.
-
Source Somatic Cells: Obtain somatic cells, such as fibroblasts, from a donor.
-
Reprogramming Factor Delivery: Introduce reprogramming factors (Oct4, Sox2, Klf4, and c-Myc) using non-integrating methods like Sendai virus or episomal vectors.[4][7]
-
Culture on Feeder Cells or Feeder-Free Matrix: Culture the cells in a supportive environment to promote the formation of iPSC colonies.[6]
-
Colony Picking and Expansion: Manually pick and expand the iPSC colonies.
-
Characterization: Characterize the iPSCs for pluripotency markers and differentiation potential.
Protocol 3: Stable Cell Line Generation by Transduction
This protocol describes the generation of a stable cell line using lentiviral vectors.
-
Vector Selection: Choose a lentiviral vector containing your gene of interest and a selectable marker.[33]
-
Virus Production: Produce lentiviral particles in a packaging cell line.
-
Transduction: Transduce the target cells with the lentiviral particles.[33][34]
-
Selection: Select the transduced cells using the appropriate antibiotic.[34][35]
-
Expansion and Validation: Expand the population of stably transduced cells and validate the expression of the gene of interest.[32]
References
- 1. Generation of Isogenic Human iPS Cell Line Precisely Corrected by Genome Editing Using the CRISPR/Cas9 System - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. aacrjournals.org [aacrjournals.org]
- 3. summitpharma.co.jp [summitpharma.co.jp]
- 4. stemcell.com [stemcell.com]
- 5. researchgate.net [researchgate.net]
- 6. Video: Generation of Induced Pluripotent Stem Cells by Reprogramming Human Fibroblasts with the Stemgent Human TF Lentivirus Set [jove.com]
- 7. Reprogramming somatic cells to induced pluripotent stem cells (iPSC) [axolbio.com]
- 8. biocompare.com [biocompare.com]
- 9. 3D Cell Culture: Will Organoids Add a New Dimension to Disease Modeling? | Technology Networks [technologynetworks.com]
- 10. researchgate.net [researchgate.net]
- 11. cellculturecompany.com [cellculturecompany.com]
- 12. Authenticating Cell Lines: Preventing Misidentification and Cross-Contamination [cytion.com]
- 13. blog.crownbio.com [blog.crownbio.com]
- 14. Fixing problems with cell lines: Technologies and policies can improve authentication - PMC [pmc.ncbi.nlm.nih.gov]
- 15. biocompare.com [biocompare.com]
- 16. Cell Line Authentication Resources [worldwide.promega.com]
- 17. Best Practices for Authentication of Cell Lines to Ensure Data Reproducibility and Integrity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. Authenticated and reproducible cell line 'omics data - tv.qiagenbioinformatics.com [tv.qiagenbioinformatics.com]
- 19. cellbase.com [cellbase.com]
- 20. susupport.com [susupport.com]
- 21. Troubleshooting | JCRB Cell Bank [cellbank.nibn.go.jp]
- 22. dls.com [dls.com]
- 23. pubs.acs.org [pubs.acs.org]
- 24. Post-Thaw Culture and Measurement of Total Cell Recovery Is Crucial in the Evaluation of New Macromolecular Cryoprotectants - PMC [pmc.ncbi.nlm.nih.gov]
- 25. researchgate.net [researchgate.net]
- 26. corning.com [corning.com]
- 27. cellculturecompany.com [cellculturecompany.com]
- 28. creative-bioarray.com [creative-bioarray.com]
- 29. benchchem.com [benchchem.com]
- 30. 3D vs 2D Cell Culture: Key Insights and Advantages [mimetas.com]
- 31. fenix.tecnico.ulisboa.pt [fenix.tecnico.ulisboa.pt]
- 32. lifesciences.danaher.com [lifesciences.danaher.com]
- 33. bosterbio.com [bosterbio.com]
- 34. addgene.org [addgene.org]
- 35. Stable Cell Line Generation | Thermo Fisher Scientific - HK [thermofisher.com]
Technical Support Center: Troubleshooting Low Yield in Chemical Synthesis
This guide provides researchers, scientists, and drug development professionals with a structured approach to troubleshooting and resolving issues of low yield in synthesized compounds.
Frequently Asked Questions (FAQs)
Q1: My reaction resulted in a very low yield. What are the most common general causes?
Low percentage yield in a chemical reaction can be attributed to a variety of factors throughout the experimental process. These can be broadly categorized as issues with the reaction itself, and losses during product isolation and purification.[1] Common culprits include incomplete reactions, the occurrence of side reactions that consume starting materials, and mechanical losses during the workup and purification stages.[1][2] Additionally, the purity of reagents and solvents, as well as the precise control of reaction conditions like temperature and pressure, are critical for maximizing product formation.[3][4]
Q2: How can I determine if my reaction has proceeded to completion?
Monitoring the progress of your reaction is crucial to ensure it is quenched at the optimal time.[5][6] Allowing a reaction to proceed for too long can lead to the decomposition of the desired product, while stopping it prematurely will result in a low yield due to unreacted starting material.[7] A widely used and effective method for reaction monitoring is Thin Layer Chromatography (TLC).[8] By taking small aliquots from the reaction mixture at regular intervals and running a TLC, you can visually track the disappearance of the starting material spot and the appearance of the product spot. Other instrumental techniques such as Nuclear Magnetic Resonance (NMR) spectroscopy and mass spectrometry (MS) can also provide real-time quantitative data on the consumption of reactants and the formation of products.[9][10]
Q3: Could the quality of my starting materials and solvents be the cause of the low yield?
Absolutely. The purity of your reactants and solvents is paramount to the success of a chemical synthesis.[4] Impurities in starting materials can lead to several issues, including interfering with the primary reaction, catalyzing side reactions, or complicating the purification process, all of which can significantly lower the final yield.[11][12] For reactions that are sensitive to water or oxygen, using anhydrous solvents and properly dried glassware is essential to prevent unwanted side reactions.[3][13] It is always good practice to verify the purity of starting materials and to use purified solvents, especially for sensitive or new reactions.[5]
Q4: How significantly do reaction conditions like temperature, concentration, and mixing affect the yield?
Reaction conditions play a critical role in determining the outcome and efficiency of a synthesis.[14]
-
Temperature: Many reactions have an optimal temperature range. Temperatures that are too high can lead to the decomposition of reactants or products, or favor the formation of unwanted byproducts.[3][15] Conversely, a temperature that is too low may result in an incomplete or very slow reaction.[13]
-
Concentration: The concentration of reactants can influence the reaction rate and, in some cases, the equilibrium position of a reversible reaction.[16] Optimizing the molar ratio of reactants is often necessary to drive the reaction to completion and maximize yield.[11]
-
Mixing: Inefficient or inadequate stirring can be a significant source of low yield, particularly in heterogeneous reactions where reactants are in different phases.[11] Thorough mixing ensures that all reactants are in close contact, which is necessary for the reaction to proceed efficiently.[17]
Q5: I suspect I am losing my product during the workup and purification steps. How can I minimize this?
Product loss during workup and purification is a very common reason for lower-than-expected yields.[6][18] Several steps in this process can contribute to loss:
-
Transfers: Every time the product is transferred from one piece of glassware to another, a small amount can be left behind. Rinsing glassware with the appropriate solvent can help to recover this material.[2][5]
-
Extractions: During liquid-liquid extractions, emulsions can form, or the product may have some solubility in the aqueous layer, leading to loss.
-
Purification: Techniques like column chromatography, recrystallization, and distillation are designed to separate the product from impurities, but some product may be inevitably lost in the process.[18] For example, during recrystallization, some product will always remain dissolved in the mother liquor.[19]
-
Volatility: If your product is volatile, it can be lost during solvent removal under reduced pressure (e.g., on a rotary evaporator).[5][15]
Careful and patient technique is essential to minimize these losses.[6]
Q6: What are side reactions and how can they impact my yield?
Side reactions are unintended chemical reactions that occur alongside the desired reaction, consuming starting materials and generating byproducts.[1] These competing reactions are a major cause of low yields. Common types of organic reactions that can occur as side reactions include substitution, elimination, addition, and rearrangement reactions.[20][21] The prevalence of side reactions can often be influenced by the reaction conditions. For example, elevated temperatures may provide the activation energy for an unwanted reaction pathway.[15] Understanding the potential side reactions for your specific transformation is key to selecting conditions that will favor the formation of the desired product.[22]
Data Summary Tables
Table 1: Effect of Solvent Polarity on Reaction Rates
The choice of solvent can dramatically influence the rate of a reaction by stabilizing or destabilizing reactants and transition states.[23][24]
| Reaction Type | Solvent Type | Effect on Rate | Rationale |
| SN1 | Polar Protic (e.g., H₂O, CH₃OH) | Increases | Stabilizes the carbocation intermediate through hydrogen bonding.[24][25] |
| SN2 | Polar Aprotic (e.g., DMSO, Acetonitrile) | Increases | Solvates the cation but leaves the nucleophile "naked" and more reactive.[24][25] |
Table 2: General Troubleshooting Guide for Low Yield
| Observation | Potential Cause | Suggested Action |
| Starting material is unreacted (from TLC/NMR) | Reaction did not go to completion. | Optimize reaction time, temperature, or concentration of reactants.[14][26] Consider using a catalyst.[27] |
| Multiple spots on TLC, complex NMR spectrum | Formation of side products. | Adjust reaction conditions (e.g., lower temperature) to improve selectivity.[11][15] Ensure starting materials are pure.[12] |
| Low mass of final, pure product | Loss during workup/purification. | Be meticulous with transfers, rinse all glassware.[5] Optimize purification technique (e.g., solvent system for chromatography).[18] |
| Reaction is inconsistent or not reproducible | Reagent quality or technique variability. | Use fresh, high-quality reagents and solvents.[3][4] Ensure glassware is dry and the atmosphere is inert if required.[13] |
Troubleshooting Workflow
The following diagram outlines a logical workflow for diagnosing the cause of low yield in a chemical synthesis.
References
- 1. youtube.com [youtube.com]
- 2. reddit.com [reddit.com]
- 3. quora.com [quora.com]
- 4. The Importance of High-Quality Reagents in Accurate Experimental Results [merkel.co.il]
- 5. Tips & Tricks [chem.rochester.edu]
- 6. Troubleshooting [chem.rochester.edu]
- 7. How To [chem.rochester.edu]
- 8. study.com [study.com]
- 9. Analytical techniques for reaction monitoring, mechanistic investigations, and metal complex discovery [dspace.library.uvic.ca]
- 10. fiveable.me [fiveable.me]
- 11. benchchem.com [benchchem.com]
- 12. youtube.com [youtube.com]
- 13. quora.com [quora.com]
- 14. tutorchase.com [tutorchase.com]
- 15. solubilityofthings.com [solubilityofthings.com]
- 16. biotage.com [biotage.com]
- 17. youtube.com [youtube.com]
- 18. youtube.com [youtube.com]
- 19. Reddit - The heart of the internet [reddit.com]
- 20. theorango.com [theorango.com]
- 21. chem.libretexts.org [chem.libretexts.org]
- 22. content.e-bookshelf.de [content.e-bookshelf.de]
- 23. Solvent effects - Wikipedia [en.wikipedia.org]
- 24. Ch 8 : Solvent Effects [chem.ucalgary.ca]
- 25. researchgate.net [researchgate.net]
- 26. benchchem.com [benchchem.com]
- 27. researchgate.net [researchgate.net]
Technical Support Center: Instrument Accessibility Solutions
This guide provides researchers, scientists, and drug development professionals with troubleshooting steps and answers to frequently asked questions when a required instrument is not accessible for their experiments.
Frequently Asked Questions (FAQs)
Q1: The instrument I need for my experiment is unavailable in my lab. What are my immediate options?
A1: When an essential instrument is not directly accessible, you have several immediate avenues to explore to keep your research on track. The first step is to investigate internal resources. Check for the instrument's availability in other labs within your department or institution. Following that, explore centralized resources known as core facilities.
-
Core Facilities: These are shared research resources that provide access to a wide range of instruments, technologies, and expert consultation.[1][2] Many universities and research institutions have multiple core facilities that may house the equipment you need.[1][3] These facilities often operate on a fee-for-service basis.[1]
-
Inter-departmental Collaboration: Reach out to colleagues in other departments. They may have the instrument you need and be open to collaboration.[4][5]
Q2: What if the instrument is not available within my institution? What external options should I consider?
A2: If the instrument is not available internally, there are several external options to pursue:
-
Instrument Rental Services: Numerous companies offer laboratory equipment for rent, which can be a cost-effective solution for short-term projects.[6][7][8] This approach eliminates the need for a significant initial investment and reduces capital expenditures.[6] Rental services often provide flexible durations (daily, weekly, monthly) and offer technical support and maintenance.[6][7][9]
-
Outsourcing Analytical Services: You can send your samples to a third-party laboratory that specializes in the required analysis.[10][11][12] This allows you to leverage their expertise and access to advanced technology without purchasing the equipment yourself.[13] Outsourcing can be particularly beneficial for highly specialized or infrequently performed analyses.[14]
-
Collaboration with Other Institutions: Establishing collaborations with researchers at other universities or research centers can provide access to their instrumentation.[5] Scientific collaboration can accelerate research progress and provide access to specialized resources.[5]
Q3: Are there any alternative methods I can use if I cannot access the specific instrument?
A3: Depending on the experiment, you may be able to utilize alternative methods or equipment.
-
Simpler or Alternative Equipment: In some cases, a more basic piece of equipment might suffice, or a different type of instrument could provide the necessary data, even if it's not the one specified in the original protocol.[15]
-
"Lab Hacks" and Creative Solutions: For some applications, creative workarounds or "lab hacks" might provide a temporary solution.[15] For instance, a pressure cooker could, in some specific and carefully controlled situations, be used as an alternative to an autoclave for sterilization.[15] However, the validity and safety of such methods must be carefully assessed for your specific application.
Q4: Our lab has a limited budget. What are the most cost-effective solutions?
A4: For labs with budgetary constraints, the following options are generally the most economical:
-
Utilizing Core Facilities: Accessing shared instrumentation through your institution's core facilities is often the most cost-effective option as it avoids duplicative equipment purchases.[3][16][17]
-
Renting Equipment: For short-term needs, renting is significantly cheaper than purchasing and avoids maintenance and repair costs.[7][8]
-
Exploring Remote Access Initiatives: Programs like UNESCO's Remote Access to Lab Equipment (UNESRALE) initiative aim to provide scientists in under-resourced regions with remote access to sophisticated scientific equipment.[18]
Troubleshooting Workflow
The following diagram illustrates a logical workflow to follow when a required instrument is not accessible.
Caption: Decision workflow for inaccessible instruments.
References
- 1. Core Facilities and Service Centers | MIT Office of the Vice President for Research [research.mit.edu]
- 2. Home | Core Facilities and Shared Instrumentation | University of Colorado Boulder [colorado.edu]
- 3. Shared Core Research Facilities | Office of Research and Innovation [research.ncsu.edu]
- 4. How to Build Flexible and Collaborative Laboratories — Lab Design News [labdesignnews.com]
- 5. medium.com [medium.com]
- 6. Laboratory Equipment and Instrument Rental Services | Fisher Scientific [fishersci.com]
- 7. gentechscientific.com [gentechscientific.com]
- 8. galileoequipos.com [galileoequipos.com]
- 9. research-care.com [research-care.com]
- 10. Laboratory Outsourcing [intertek.com]
- 11. Outsourcing – Expand Your Lab Capacity with Trusted Analytics [biotesys.de]
- 12. Outsourcing analytical services…because it’s worth it - Almac [almacgroup.com]
- 13. contractlaboratory.com [contractlaboratory.com]
- 14. pharm-int.com [pharm-int.com]
- 15. Lab Hacks, Equipment Alternatives, and Custom Lab Solutions [labx.com]
- 16. Optimizing Academic Research Infrastructure: The Critical Role of Shared Facilities and Core Labs | Lab Manager [labmanager.com]
- 17. Equipment Sharing & Efficient Space Use | Environmental Center | University of Colorado Boulder [colorado.edu]
- 18. UNESCO’s Remote Access to Lab Equipment (UNESRALE) Initiative [unesco.org]
Technical Support Center: Strategies for Dealing with the Lack of a Positive Control
This technical support center provides troubleshooting guides and frequently asked questions (FAQs) for researchers, scientists, and drug development professionals who encounter challenges due to the absence of a positive control in their experiments.
Troubleshooting Guide
Issue: My experiment lacks a positive control. How can I validate my results?
When a positive control is unavailable, it is crucial to implement alternative strategies to ensure the validity and reliability of your experimental data. A positive control's primary role is to confirm that the assay system is working correctly.[1][2][3][4][5] Without it, you cannot be certain if a negative result is a true negative or a false negative due to a technical failure.[6]
Initial Troubleshooting Steps:
-
Confirm the Necessity and Unavailability: Double-check if a positive control is genuinely unobtainable. Explore commercial sources, collaborations with other labs, or the possibility of creating an in-house positive control.
-
Strengthen Negative Controls: In the absence of a positive control, the rigor of your negative controls becomes even more critical.[1][2] Ensure you have included multiple types of negative controls to account for various potential sources of error.
-
Thoroughly Validate Your Assay: A well-validated assay provides confidence in the results, even without a positive control. This involves assessing specificity, sensitivity, precision, and linearity.[7][8]
Alternative Validation Strategies
If a traditional positive control is not an option, consider the following alternative strategies:
| Strategy | Description | Advantages | Disadvantages |
| Use of Reference Materials/Standards | A well-characterized material with a known concentration or activity of the analyte of interest.[9][10][11] | Provides a quantitative benchmark for assay performance. | May not perfectly mimic the biological sample matrix. Availability and cost can be a factor. |
| Spike-in Controls | Adding a known amount of the analyte into a sample matrix that is known to be negative. | Assesses the recovery of the analyte and the effect of the sample matrix on detection. | The spiked-in analyte may not behave identically to the endogenous analyte. |
| Orthogonal Methods | Using a different experimental method to confirm the results obtained from the primary assay. | Increases confidence in the results by demonstrating consistency across different detection principles. | Requires access to multiple technology platforms and expertise. Can be time-consuming and costly. |
| In-Silico Analysis & Literature Data | Comparing your experimental results with previously published data or computational predictions. | Provides a theoretical validation of your findings. | Literature data may have been generated under different experimental conditions. In-silico predictions are not a substitute for experimental validation. |
| Biological Validation | Using biological manipulation (e.g., gene knockdown, overexpression) to induce or eliminate the signal.[3] | Provides strong evidence for the specificity of the assay. | Can be complex and time-consuming to develop and implement. |
Frequently Asked Questions (FAQs)
Q1: What is the primary risk of not having a positive control?
Q2: Can a strong negative control compensate for the lack of a positive control?
While a robust negative control is essential for identifying false positives and background noise, it cannot fully replace a positive control.[1][2][12] A negative control demonstrates the absence of a signal when none is expected, whereas a positive control confirms the system's capability to detect a signal when it is present.[1][4][13]
Q3: How do I choose the best alternative validation strategy?
The choice of strategy depends on the nature of your experiment, the analyte you are measuring, and the resources available. For quantitative assays, using a certified reference material is often the best alternative. For antibody-based methods, biological validation through knockdown or knockout samples can provide high confidence in specificity.[3]
Q4: When is it acceptable to proceed without a positive control?
In some novel research areas, a positive control may not yet exist. In such cases, it is critical to acknowledge this limitation and use a combination of the alternative strategies mentioned above to build a strong case for the validity of your findings. Rigorous assay validation and the use of orthogonal methods are particularly important in these situations.[7]
Experimental Protocols
Protocol: Validation of an Immunoassay Using a Spike-in Control
This protocol describes the validation of an immunoassay when a standard positive control is unavailable.
Objective: To determine the recovery of a known amount of analyte spiked into a negative sample matrix to validate assay performance.
Materials:
-
Analyte of known concentration
-
Negative control sample matrix (e.g., serum from a healthy donor, cell lysate from a knockout cell line)
-
All necessary reagents and equipment for the immunoassay
Procedure:
-
Preparation of Spiked Samples:
-
Prepare a series of dilutions of the known analyte.
-
Spike these dilutions into the negative control sample matrix to create a set of samples with known concentrations of the analyte.
-
Include a non-spiked negative control sample.
-
-
Immunoassay Procedure:
-
Perform the immunoassay on the spiked samples and the negative control according to the standard protocol.
-
-
Data Analysis:
-
Quantify the concentration of the analyte in each spiked sample.
-
Calculate the percent recovery for each spiked sample using the following formula: (Measured Concentration / Spiked Concentration) x 100%
-
-
Acceptance Criteria:
-
The mean recovery should be within a predefined range (e.g., 80-120%).
-
The coefficient of variation (%CV) of the recovery across the dilution series should be low (e.g., <15%).
-
Visualizations
Caption: Experimental workflow in the absence of a positive control.
Caption: Decision tree for selecting an alternative validation strategy.
References
- 1. scienceready.com.au [scienceready.com.au]
- 2. Mastering Experimental Accuracy: How to Design Positive and Negative Controls – Kentucky Gourd Society [kygourdsociety.org]
- 3. bosterbio.com [bosterbio.com]
- 4. m.youtube.com [m.youtube.com]
- 5. Why do we need positive control in an experiment? | AAT Bioquest [aatbio.com]
- 6. homework.study.com [homework.study.com]
- 7. biocompare.com [biocompare.com]
- 8. biocompare.com [biocompare.com]
- 9. researchgate.net [researchgate.net]
- 10. research-portal.uea.ac.uk [research-portal.uea.ac.uk]
- 11. Regarding the references for reference chemicals of alternative methods - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. quora.com [quora.com]
- 13. Negative Vs Positive Control - Housing Innovations [dev.housing.arizona.edu]
Technical Support Center: Addressing Unexpected Results with Substitute Reagents
This technical support center provides troubleshooting guidance for researchers, scientists, and drug development professionals who encounter unexpected results when using a substitute reagent in their experiments.
Frequently Asked Questions (FAQs)
Q1: Why am I seeing a weaker or no signal with the substitute reagent?
A1: A weaker or absent signal is a common issue when substituting reagents and can stem from several factors:
-
Antibody/Reagent Affinity and Specificity: The substitute antibody may have a lower binding affinity for the target protein, or it might recognize a different epitope that is less accessible in your experimental conditions.[1]
-
Incorrect Concentration: The optimal concentration for the substitute reagent may differ from the original. It's crucial to perform a titration to determine the ideal working concentration.
-
Reagent Integrity: Ensure the substitute reagent has been stored correctly and has not expired. Avoid repeated freeze-thaw cycles.
-
Protocol Incompatibility: The substitute reagent may require different buffer conditions, incubation times, or temperatures. Always carefully review the manufacturer's protocol for the new reagent.
Q2: My results show high background noise after switching to a new reagent. What can I do?
A2: High background can obscure your results and is often related to non-specific binding. Here are some troubleshooting steps:
-
Blocking Inefficiency: The blocking buffer used with the original reagent may not be optimal for the substitute. Consider trying different blocking agents (e.g., BSA, non-fat milk) or increasing the blocking time.
-
Antibody Concentration Too High: An excessively high concentration of the primary or secondary antibody can lead to non-specific binding. Optimize the antibody concentrations through titration.
-
Inadequate Washing: Increase the number or duration of wash steps to more effectively remove unbound antibodies.
-
Cross-Reactivity: The substitute antibody might be cross-reacting with other proteins in your sample. Check the manufacturer's datasheet for any known cross-reactivities.
Q3: I'm observing unexpected bands or peaks in my Western Blot/Chromatography. What is the likely cause?
A3: The appearance of unexpected bands or peaks often points to issues with specificity or sample integrity:
-
In Western Blots:
-
Non-specific Binding: The substitute antibody may be binding to other proteins. Ensure you are using a highly specific antibody and consider performing a pre-adsorption step.[2]
-
Protein Degradation or Modification: The sample itself may have issues. Use fresh samples with protease inhibitors. Post-translational modifications can also alter the protein's apparent molecular weight.[3][4]
-
-
In Chromatography:
-
"Ghost Peaks": These can arise from contaminants in the substitute reagent or mobile phase, or from carryover from previous injections.[5]
-
Altered Retention Times: A substitute reagent could alter the interaction of the analyte with the stationary phase, leading to shifts in retention time.
-
Q4: The variability between my replicates has increased with the substitute reagent. How can I improve consistency?
A4: Increased variability can undermine the reliability of your results. To address this:
-
Ensure Homogeneity: Thoroughly mix all reagents and samples before use.
-
Pipetting Technique: Use calibrated pipettes and ensure consistent, careful pipetting.
-
Incubation Conditions: Maintain uniform temperature and humidity during incubations. Use plate sealers to prevent evaporation.
-
Reagent Stability: Prepare fresh dilutions of the substitute reagent for each experiment, as its stability in working solutions may differ from the original.
Troubleshooting Guides
Issue 1: Inconsistent Results in a Sandwich ELISA with a Substitute Detection Antibody
If you have substituted the detection antibody in a sandwich ELISA and are observing inconsistent results, such as poor linearity or inaccurate quantification, follow this troubleshooting workflow.
Issue 2: Unexpected Downstream Signaling with a Substitute Kinase Inhibitor
When a substitute kinase inhibitor in a cell-based assay produces unexpected phenotypic changes or alters downstream signaling in an unforeseen way, it may be due to off-target effects.
Data Presentation
Quantitative Comparison of Two Commercial ELISA Kits for Human Interleukin-6 (IL-6)
This table summarizes the performance comparison between two different commercial ELISA kits for the measurement of human IL-6, illustrating the potential for variability when substituting reagents.
| Performance Metric | Original Kit (Brand X) | Substitute Kit (Brand Y) |
| Assay Principle | Sandwich ELISA | Sandwich ELISA |
| Stated Sensitivity | 0.92 pg/mL | 1.5 pg/mL |
| Linear Range | 3.1 - 200 pg/mL | 1.5 - 5000 pg/mL |
| Intra-Assay Precision (CV%) | 6.2% | <10% |
| Inter-Assay Precision (CV%) | 7.0% | <10% |
| Median IL-6 in Patient Samples | 22.4 pg/mL | 32.3 pg/mL |
Data adapted from a comparative study of commercial IL-6 ELISA kits.[3]
Experimental Protocols
Protocol 1: Crossover Validation for a Substitute ELISA Kit
This protocol outlines a crossover study to compare the performance of a substitute ELISA kit against an established, original kit.
Objective: To determine if a substitute ELISA kit provides comparable results to the original kit for a specific analyte in a given sample type.
Methodology:
-
Sample Selection: Select a minimum of 20 patient or experimental samples that cover the analytical range of the assay (low, medium, and high concentrations).
-
Parallel Testing:
-
On the same day, assay each sample in duplicate using both the original and the substitute ELISA kits.
-
Follow the manufacturer's protocol for each kit precisely. Do not interchange reagents between kits.[5]
-
-
Data Collection: Record the quantitative results for each sample from both kits.
-
Statistical Analysis:
-
Correlation Analysis: Plot the results from the substitute kit (y-axis) against the results from the original kit (x-axis). Perform a linear regression analysis and calculate the correlation coefficient (R²). An R² value close to 1.0 indicates a strong correlation.
-
Bland-Altman Plot: Construct a Bland-Altman plot to assess the agreement between the two kits. This plot shows the difference between the two measurements for each sample against the average of the two measurements. Calculate the mean difference (bias) and the limits of agreement (mean difference ± 1.96 * standard deviation of the differences).[3]
-
-
Acceptance Criteria: The substitute kit is considered acceptable if the correlation is high (e.g., R² > 0.95) and the bias and limits of agreement in the Bland-Altman plot are within clinically or experimentally acceptable limits.
Protocol 2: Linearity of Dilution Assessment
This protocol is used to determine if a substitute reagent can accurately measure an analyte in a sample when diluted.
Objective: To assess the linearity of measurements for a substitute reagent across a range of dilutions.
Methodology:
-
Sample Preparation: Select a sample with a high concentration of the analyte.
-
Serial Dilution: Perform a series of serial dilutions of the sample (e.g., 1:2, 1:4, 1:8, 1:16) using the assay diluent provided with the substitute reagent kit.
-
Assay: Measure the concentration of the analyte in the undiluted sample and each dilution in triplicate.
-
Data Analysis:
-
Calculate the mean concentration for each dilution.
-
Correct for the dilution factor by multiplying the measured concentration by the dilution factor.
-
Calculate the coefficient of variation (CV) across the corrected concentrations.
-
-
Acceptance Criteria: The assay is considered linear if the CV of the dilution-corrected concentrations is within an acceptable range (typically <15%) and there is no significant trend in the corrected values across the dilution series.[5]
Signaling Pathway Diagram
MAPK/ERK Signaling Pathway and Potential Off-Target Effects of a Substitute Kinase Inhibitor
The following diagram illustrates the MAPK/ERK signaling pathway and indicates where a substitute kinase inhibitor with off-target effects might interfere, leading to unexpected results.
References
- 1. researchgate.net [researchgate.net]
- 2. scribd.com [scribd.com]
- 3. Comparison of ELISA with automated ECLIA for IL-6 determination in COVID-19 patients: An Italian real-life experience - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Analytical performances of commercial ELISA-kits for IL-2, IL-6 and TNF-alpha. A WHO study - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. documents.thermofisher.com [documents.thermofisher.com]
Navigating Research Disruptions: A Guide to Managing Experiments During Consumable Backorders
In the dynamic landscape of scientific research and drug development, unexpected supply chain disruptions can pose significant challenges to project timelines and experimental integrity. A key consumable on backorder can bring critical experiments to a halt, jeopardizing months of work. This technical support center provides researchers, scientists, and drug development professionals with troubleshooting guides and frequently asked questions to effectively manage these situations, ensuring research continuity and data reliability.
Troubleshooting Guide: Immediate Actions for Backordered Consumables
When faced with a notification that a critical consumable is on backorder, a swift and strategic response is crucial. The following steps provide a framework for mitigating the impact on your research.
Step 1: Assess the Immediate Impact
The first priority is to understand the scope of the problem.
-
Identify Affected Experiments: Determine which ongoing and planned experiments rely on the backordered consumable.
-
Quantify Existing Stock: Conduct a thorough inventory of the remaining consumable to ascertain how long current experiments can be sustained.
-
Review Project Timelines: Evaluate the potential delay's impact on project milestones, grant deadlines, and publication schedules.[1]
Step 2: Communication and Information Gathering
Clear and proactive communication can alleviate uncertainty and open up potential solutions.
-
Contact the Supplier: Reach out to your supplier to understand the root cause of the backorder and get an estimated time of arrival.[2] Inquire about any potential alternative products they might offer.
-
Inform Internal Stakeholders: Keep your principal investigator, lab manager, and collaborators informed about the situation and its potential consequences.
-
Consult with Colleagues: Check with other labs within your institution to see if they have a surplus of the consumable they might be willing to share or trade.[2]
Step 3: Finding and Validating Alternatives
If the backorder is long-term, sourcing and validating an alternative consumable is the most viable path forward.
-
Identify Potential Alternatives: Research alternative suppliers or different catalog numbers for the same or a similar product.[2] Consider products with similar specifications and applications.
-
Request Samples: Whenever possible, request samples of the alternative consumable for validation before committing to a large order.
-
Perform Validation Experiments: It is critical to validate the performance of the new consumable to ensure it does not negatively impact your experimental results.[3][4]
Frequently Asked Questions (FAQs)
This section addresses common questions researchers face when a key consumable is unavailable.
Q1: How can our lab be more proactive in preventing disruptions from backordered consumables?
A: Proactive supply chain management is key.[5][6] Implementing a robust inventory management system to track usage and set reorder points is a primary strategy.[5] Diversifying suppliers for critical reagents can also mitigate the risk of a single point of failure.[6][7] Establishing strong relationships with sales representatives can provide early warnings of potential shortages.
Q2: What are the critical parameters to consider when validating an alternative reagent?
A: When validating an alternative reagent, it's essential to ensure it performs equivalently to the original. Key parameters to assess include:
-
Specificity and Sensitivity: The ability to detect the target of interest without cross-reactivity.
-
Linearity and Range: The concentration range over which the assay performs accurately.
-
Precision and Reproducibility: The consistency of results across multiple runs and by different operators.[4]
-
Stability: The shelf-life and stability under your specific storage conditions.[4]
Q3: My experiment is part of a long-term study. How do I ensure data consistency when switching to a new consumable?
A: Maintaining data consistency is paramount in longitudinal studies. To achieve this, a bridging study is recommended. This involves running samples in parallel using both the old and new consumables to establish a correlation. It is also crucial to meticulously document the lot number and supplier of all consumables used for each experiment.
Q4: What should I do if no suitable alternative consumable can be found?
A: In this challenging scenario, several strategies can be employed. You can temporarily pause the specific experiments affected and prioritize other research activities. It may also be an opportunity to explore alternative experimental approaches or technologies that do not rely on the backordered consumable. Collaborating with another lab that has the necessary supplies could be a temporary solution.
Q5: How can we manage our budget effectively when faced with sudden price increases for alternative consumables?
A: Unexpected price increases can strain research budgets.[1] It's advisable to have a contingency fund for such situations. When sourcing alternatives, compare prices from multiple vendors. For expensive items, consider purchasing smaller quantities initially for validation before placing a bulk order. Open communication with your institution's procurement department can also help in negotiating better prices.
Data Presentation: Comparing Alternative Reagents
When validating alternative consumables, a structured comparison of key performance indicators is essential.
Table 1: Performance Comparison of Alternative Antibodies for Western Blotting
| Feature | Original Antibody (Supplier A) | Alternative Antibody (Supplier B) | Alternative Antibody (Supplier C) |
| Target Specificity | High | High | Moderate (minor cross-reactivity) |
| Optimal Dilution | 1:1000 | 1:1200 | 1:800 |
| Signal-to-Noise Ratio | 4.5 | 4.2 | 3.1 |
| Lot-to-Lot Variability | Low | Low | Not Tested |
| Cost per 100 µL | $350 | $320 | $280 |
Experimental Protocols: Validating an Alternative Primary Antibody
This protocol outlines a general workflow for validating a new primary antibody for use in Western blotting to ensure it produces reliable and reproducible results.
Objective: To determine if the alternative primary antibody provides equivalent or superior performance to the original antibody.
Materials:
-
Protein lysates known to express the target protein (positive control)
-
Protein lysates known not to express the target protein (negative control)[8][9]
-
SDS-PAGE gels and running buffer
-
Transfer apparatus and buffer
-
Membranes (PVDF or nitrocellulose)
-
Blocking buffer (e.g., 5% non-fat milk or BSA in TBST)
-
Original primary antibody
-
Alternative primary antibody
-
HRP-conjugated secondary antibody
-
Chemiluminescent substrate
-
Imaging system
Methodology:
-
Protein Separation: Run identical amounts of positive and negative control lysates on two separate SDS-PAGE gels.
-
Protein Transfer: Transfer the separated proteins to membranes.
-
Blocking: Block both membranes in blocking buffer for 1 hour at room temperature.
-
Primary Antibody Incubation:
-
Incubate one membrane with the original primary antibody at its optimized dilution.
-
Incubate the second membrane with the alternative primary antibody, testing a range of dilutions (e.g., 1:500, 1:1000, 1:2000).
-
-
Washing: Wash both membranes three times for 10 minutes each in TBST.
-
Secondary Antibody Incubation: Incubate both membranes with the same HRP-conjugated secondary antibody at its optimized dilution for 1 hour at room temperature.
-
Washing: Repeat the washing step.
-
Detection: Add the chemiluminescent substrate to both membranes and acquire images using an imaging system.
-
Analysis: Compare the band intensity, specificity (presence of a single band at the correct molecular weight in the positive control and its absence in the negative control), and signal-to-noise ratio between the two antibodies.
Visualizing Workflows and Logical Relationships
Diagrams created using Graphviz can help visualize complex processes and decision-making pathways.
Caption: Troubleshooting workflow for a backordered consumable.
Caption: Logical pathway for validating an alternative reagent.
References
- 1. msesupplies.com [msesupplies.com]
- 2. labsymplified.com [labsymplified.com]
- 3. Reagent Validation to Facilitate Experimental Reproducibility - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. How we validate new laboratory reagents - Ambar Lab [ambar-lab.com]
- 5. needle.tube [needle.tube]
- 6. Supply Chain Risk Management In Labs. [needle.tube]
- 7. sdcexec.com [sdcexec.com]
- 8. news-medical.net [news-medical.net]
- 9. Experimental Design • MiniOne Systems [theminione.com]
Validating Efficacy: A Comparative Analysis of Compound-X and the Standard of Care
This guide provides a comprehensive framework for researchers, scientists, and drug development professionals to validate the efficacy of an alternative compound, referred to as Compound-X, against a current standard treatment. The following sections present a comparative analysis supported by experimental data, detailed methodologies for key assays, and visualizations of the targeted signaling pathway and experimental workflows.
Comparative Performance Data
The following tables summarize the quantitative data from in vitro experiments comparing Compound-X to the standard drug.
Table 1: In Vitro Potency and Selectivity
This table outlines the half-maximal inhibitory concentration (IC50) of Compound-X and the standard drug against the primary kinase target and two off-target kinases to assess selectivity.[1] The selectivity index is calculated by dividing the off-target IC50 by the target IC50. A higher selectivity index indicates a more selective compound.
| Compound | Target IC50 (nM) | Off-Target 1 IC50 (nM) | Off-Target 2 IC50 (nM) | Selectivity Index (Off-Target 1 / Target) |
| Compound-X | 12 | 1,500 | >10,000 | 125x |
| Standard Drug | 45 | 1,125 | 9,000 | 25x |
Table 2: Cellular Activity in Cancer Cell Line
This table presents the half-maximal effective concentration (EC50) from a cell viability assay, indicating the concentration of each compound required to inhibit 50% of cancer cell proliferation.
| Compound | Cellular EC50 (nM) |
| Compound-X | 30 |
| Standard Drug | 150 |
Table 3: Kinase Selectivity Profile
The following data represents the percentage of inhibition of various kinases at a 1µM concentration of each compound, screened against a panel of over 300 kinases. Significant inhibition of off-target kinases can indicate potential for side effects.[2]
| Kinase Target | Compound-X (% Inhibition @ 1µM) | Standard Drug (% Inhibition @ 1µM) |
| Target Kinase | 97% | 94% |
| Off-Target Kinase A | 12% | 78% |
| Off-Target Kinase B | 7% | 65% |
| Off-Target Kinase C | <5% | 48% |
Mechanism of Action and Signaling Pathway
Both Compound-X and the standard drug are designed to inhibit a key Receptor Tyrosine Kinase (RTK) involved in the Epidermal Growth Factor Receptor (EGFR) signaling pathway.[3] This pathway plays a crucial role in regulating cell proliferation, survival, and differentiation.[3][4][5] Dysregulation of the EGFR pathway is a common factor in the development of various cancers.[3] By blocking the ATP-binding site of the RTK, these compounds prevent its activation and the subsequent downstream signaling cascade.[2]
Caption: EGFR Signaling Pathway targeted by Compound-X.
Experimental Protocols
Detailed methodologies for the key experiments are provided below to ensure transparency and enable replication of the findings.
Biochemical Kinase Assay (ADP-Glo™)
This assay quantifies the activity of the target kinase by measuring the amount of ADP produced during the phosphorylation reaction.[6]
Protocol:
-
Compound Preparation: Prepare a 10-point serial dilution of Compound-X and the standard drug in DMSO.
-
Reaction Setup: In a 384-well plate, incubate the target kinase and its substrate with each compound concentration for 15 minutes at room temperature.
-
Initiation: Initiate the kinase reaction by adding ATP at its known Km concentration. Allow the reaction to proceed for 2 hours.
-
Termination and Detection: Add ADP-Glo™ Reagent to stop the kinase reaction and consume any remaining ATP. Subsequently, add the Kinase Detection Reagent to convert the generated ADP back to ATP, which then drives a luciferase-based luminescent signal.
-
Data Analysis: Measure the luminescence using a plate reader. The IC50 values are calculated from the resulting dose-response curves.
Cell Viability Assay (MTT Assay)
The MTT assay is a colorimetric assay for assessing cell metabolic activity, which serves as an indicator of cell viability, proliferation, and cytotoxicity.[7][8]
Protocol:
-
Cell Seeding: Seed cancer cells in a 96-well plate at a density of 5,000 cells per well and incubate for 24 hours.[6]
-
Compound Treatment: Treat the cells with serial dilutions of Compound-X and the standard drug for 72 hours.
-
MTT Addition: Add MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) solution to each well and incubate for 4 hours, allowing viable cells to reduce the yellow MTT to purple formazan (B1609692) crystals.
-
Solubilization: Add a solubilization solution (e.g., DMSO or a solution of SDS in HCl) to dissolve the formazan crystals.[9]
-
Data Analysis: Measure the absorbance of the solution at 570 nm using a microplate reader. The EC50 values are determined from the dose-response curves.[7]
Western Blot Analysis
Western blotting is used to detect the phosphorylation status of key proteins in the EGFR signaling pathway, providing insight into the mechanism of action of the compounds.[10][11]
Protocol:
-
Cell Treatment and Lysis: Treat cancer cells with Compound-X, the standard drug, or a vehicle control for a specified time. Lyse the cells to extract total protein.
-
Protein Quantification: Determine the protein concentration of each lysate using a BCA or Bradford assay.
-
SDS-PAGE: Separate the protein lysates by sodium dodecyl sulfate-polyacrylamide gel electrophoresis (SDS-PAGE).
-
Protein Transfer: Transfer the separated proteins from the gel to a nitrocellulose or PVDF membrane.
-
Immunoblotting:
-
Block the membrane to prevent non-specific antibody binding.
-
Incubate the membrane with primary antibodies specific for the phosphorylated and total forms of the target proteins (e.g., p-ERK, ERK, p-Akt, Akt).
-
Wash the membrane and incubate with a horseradish peroxidase (HRP)-conjugated secondary antibody.
-
-
Detection: Detect the protein bands using an enhanced chemiluminescence (ECL) substrate and an imaging system.
-
Data Analysis: Quantify the band intensities using densitometry software. Normalize the levels of phosphorylated proteins to the total protein levels to determine the extent of pathway inhibition.
Experimental Workflow
The following diagram illustrates the general workflow for validating and comparing the alternative compound.
Caption: High-level experimental workflow for compound validation.
References
- 1. benchchem.com [benchchem.com]
- 2. benchchem.com [benchchem.com]
- 3. creative-diagnostics.com [creative-diagnostics.com]
- 4. MAPK/ERK pathway - Wikipedia [en.wikipedia.org]
- 5. MAPK signaling pathway | Abcam [abcam.com]
- 6. benchchem.com [benchchem.com]
- 7. protocols.io [protocols.io]
- 8. texaschildrens.org [texaschildrens.org]
- 9. Cell Viability Assays - Assay Guidance Manual - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 10. benchchem.com [benchchem.com]
- 11. Analysis of Signaling Pathways by Western Blotting and Immunoprecipitation - PubMed [pubmed.ncbi.nlm.nih.gov]
A Comparative Efficacy Analysis: In-House Synthesized Sulfonab versus Commercially Available Lapatinib in HER2-Positive Breast Cancer Models
For Researchers, Scientists, and Drug Development Professionals
This guide provides an objective comparison of the anti-proliferative efficacy of a commercially available therapeutic, Lapatinib, against a novel, in-house synthesized sulfonanilide compound, herein referred to as Sulfonab. The data presented is a synthesis of published literature on Lapatinib and a representative in-house sulfonanilide with demonstrated activity in breast cancer cell lines. This comparison aims to equip researchers with a framework for evaluating novel compounds against established drugs.
Executive Summary
Lapatinib is a well-established dual tyrosine kinase inhibitor targeting both the Human Epidermal Growth Factor Receptor 2 (HER2) and the Epidermal Growth Factor Receptor (EGFR).[1] It is a cornerstone in the treatment of HER2-positive breast cancer. Sulfonab represents a novel class of in-house synthesized sulfonanilide compounds that have shown promising anti-proliferative effects in preliminary screenings against HER2-positive breast cancer cell lines. This guide delves into a comparative analysis of their efficacy, mechanism of action, and the experimental protocols used for their evaluation.
Data Presentation: A Head-to-Head Comparison
The following table summarizes the quantitative data on the anti-proliferative efficacy of Lapatinib and the hypothetical in-house compound, Sulfonab, against the HER2-overexpressing human breast cancer cell line, SK-BR-3.
| Compound | Target(s) | Cell Line | IC50 (µM) | Reference |
| Lapatinib | HER2, EGFR | SK-BR-3 | ~0.15 | [2] |
| Sulfonab (hypothetical) | Presumed HER2/EGFR pathway | SK-BR-3 | ~0.50 | Based on novel sulfonanilides[3] |
Signaling Pathways and Mechanism of Action
Lapatinib exerts its therapeutic effect by inhibiting the tyrosine kinase activity of HER2 and EGFR.[1] This blockade prevents the autophosphorylation of these receptors, thereby inhibiting downstream signaling through the PI3K/Akt and MAPK pathways, which are crucial for cell proliferation and survival.[1][4] The presumed mechanism of action for Sulfonab is also targeted at key nodes within this pathway, leading to the observed anti-proliferative effects.
Experimental Protocols
The efficacy of both Lapatinib and Sulfonab can be determined using a variety of in vitro assays. A standard method for assessing cell viability and proliferation is the MTT assay.
MTT Assay Protocol for Cell Viability
This protocol is adapted from standard procedures for evaluating the effect of compounds on cancer cell lines.[5][6]
1. Cell Seeding:
-
Culture SK-BR-3 human breast cancer cells in MEM medium supplemented with 10% fetal bovine serum and 1% penicillin-streptomycin (B12071052) in a humidified incubator at 37°C with 5% CO2.
-
Harvest cells and resuspend to a concentration of 1 x 10^5 cells/mL.
-
Seed 100 µL of the cell suspension into each well of a 96-well plate.
-
Incubate the plate for 24 hours to allow for cell attachment.
2. Compound Treatment:
-
Prepare a series of dilutions of Lapatinib and Sulfonab in culture medium.
-
Remove the old medium from the wells and add 100 µL of the medium containing the different concentrations of the test compounds. Include a vehicle control (e.g., DMSO) and a no-treatment control.
-
Incubate the plate for 48-72 hours.
3. MTT Addition and Incubation:
-
Prepare a 5 mg/mL solution of MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) in sterile PBS.[5]
-
Add 10 µL of the MTT solution to each well.
-
Incubate the plate for 2-4 hours at 37°C, allowing the MTT to be metabolized into formazan (B1609692) crystals by viable cells.
4. Solubilization of Formazan:
-
After the incubation period, carefully remove the medium from the wells.
-
Add 100 µL of a solubilization solution (e.g., DMSO or a solution of 40% dimethylformamide in 2% glacial acetic acid with 16% SDS) to each well to dissolve the formazan crystals.[6]
-
Gently shake the plate on an orbital shaker for 15 minutes to ensure complete solubilization.[5]
5. Absorbance Measurement:
-
Read the absorbance of each well at a wavelength of 570 nm using a microplate reader.
-
The absorbance is directly proportional to the number of viable cells.
6. Data Analysis:
-
Calculate the percentage of cell viability for each concentration relative to the control.
-
Plot the percentage of viability against the compound concentration and determine the IC50 value (the concentration of the compound that inhibits 50% of cell growth).
Conclusion
This guide provides a comparative overview of a commercially available drug, Lapatinib, and a representative in-house synthesized compound, Sulfonab. While Lapatinib shows a lower IC50 value in this comparison, indicating higher potency in the tested cell line, the in-house synthesized Sulfonab demonstrates significant anti-proliferative activity, warranting further investigation and optimization.
For drug development professionals, the key takeaway is the importance of a rigorous, standardized approach to comparing novel compounds with existing therapies. The provided experimental protocol for the MTT assay offers a robust method for generating the initial efficacy data required for such comparisons. Further studies, including in vivo models and detailed mechanistic analyses, are essential next steps in the evaluation of any promising in-house synthesized compound.
References
- 1. What is the mechanism of Lapatinib Ditosylate Hydrate? [synapse.patsnap.com]
- 2. benchchem.com [benchchem.com]
- 3. Synthesis and Biological Evaluation of Novel Sulfonanilide Compounds as Antiproliferative Agents for Breast Cancer - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. MTT assay protocol | Abcam [abcam.com]
- 6. 2.5. MTT assay [bio-protocol.org]
A Researcher's Guide to Validating Synthesized Molecules: A Comparative Analysis of Key Analytical Techniques
For researchers, scientists, and drug development professionals, the rigorous validation of a newly synthesized molecule's identity and purity is a cornerstone of reliable and reproducible research. This guide provides a comprehensive comparison of the most pivotal analytical techniques employed for this purpose, supported by experimental data and detailed protocols to inform methodology selection and implementation.
The journey from a designed chemical structure to a validated, pure compound is fraught with potential pitfalls. Impurities or an incorrect molecular structure can lead to misleading biological data, flawed structure-activity relationships, and ultimately, the failure of promising drug candidates. Therefore, a multi-faceted analytical approach is not just recommended; it is essential.
This guide will explore the principles, applications, and comparative performance of the following techniques:
-
Nuclear Magnetic Resonance (NMR) Spectroscopy
-
Mass Spectrometry (MS)
-
Fourier-Transform Infrared (FTIR) Spectroscopy
-
High-Performance Liquid Chromatography (HPLC)
-
Gas Chromatography (GC)
-
Elemental Analysis (EA)
-
X-ray Crystallography
Comparative Performance of Analytical Techniques
The selection of an appropriate analytical technique hinges on a variety of factors, including the properties of the molecule, the information required, and the available instrumentation. The following table summarizes the key performance characteristics of each method.
| Technique | Principle | Information Provided | Sensitivity | Resolution | Throughput | Key Application |
| NMR Spectroscopy | Nuclear spin alignment in a magnetic field | Detailed molecular structure, connectivity, stereochemistry, purity | Moderate | Very High | Low to Moderate | Definitive structure elucidation of organic molecules.[1][2] |
| Mass Spectrometry | Mass-to-charge ratio of ionized molecules | Molecular weight, elemental composition (HRMS), structural fragments | Very High | High to Very High | High | Accurate mass determination and identification of unknowns.[1] |
| FTIR Spectroscopy | Absorption of infrared radiation by molecular vibrations | Presence of functional groups | Low to Moderate | Moderate | High | Rapid confirmation of functional groups in a molecule. |
| HPLC | Differential partitioning between mobile and stationary phases | Purity, quantification of components in a mixture | High | High | High | Purity assessment of non-volatile and thermally unstable compounds.[3][4][5] |
| GC | Differential partitioning between a gaseous mobile phase and a stationary phase | Purity, quantification of volatile components | Very High | Very High | High | Purity assessment of volatile and thermally stable compounds.[3][4][5] |
| Elemental Analysis | Combustion of the sample to determine elemental composition | Percentage of C, H, N, S, and other elements | Low | N/A | Low | Confirmation of the empirical formula.[6] |
| X-ray Crystallography | Diffraction of X-rays by a single crystal | Absolute three-dimensional molecular structure | N/A (requires crystal) | Atomic | Very Low | Unambiguous determination of solid-state molecular structure. |
Experimental Workflows and Logical Relationships
A systematic approach to validating a synthesized molecule is crucial. The following diagram illustrates a typical workflow, outlining the logical progression from initial synthesis to comprehensive characterization.
Caption: A typical experimental workflow for the validation of a synthesized molecule.
Detailed Experimental Protocols
Nuclear Magnetic Resonance (NMR) Spectroscopy
Objective: To elucidate the detailed molecular structure of the synthesized compound.
Methodology:
-
Sample Preparation: Dissolve 5-10 mg of the purified compound in approximately 0.6-0.7 mL of a deuterated solvent (e.g., CDCl₃, DMSO-d₆) in a clean NMR tube. The choice of solvent depends on the solubility of the compound. Add a small amount of a reference standard, such as tetramethylsilane (B1202638) (TMS), for chemical shift calibration.[7]
-
Instrument Setup: Place the NMR tube in the spectrometer. Tune and shim the instrument to optimize the magnetic field homogeneity.
-
Data Acquisition:
-
¹H NMR: Acquire a proton NMR spectrum. Key parameters to set include the number of scans, relaxation delay, and spectral width.
-
¹³C NMR: Acquire a carbon-13 NMR spectrum. Due to the low natural abundance of ¹³C, a larger number of scans is typically required.[8] Proton decoupling is commonly used to simplify the spectrum.
-
2D NMR (e.g., COSY, HSQC, HMBC): If necessary for complex structures, acquire 2D NMR spectra to establish correlations between protons and carbons, aiding in the complete structural assignment.[8]
-
-
Data Processing and Analysis: Process the raw data by applying Fourier transformation, phase correction, and baseline correction. Integrate the peaks in the ¹H NMR spectrum to determine the relative number of protons. Analyze the chemical shifts, coupling constants, and multiplicities to deduce the molecular structure.[8]
Mass Spectrometry (MS)
Objective: To determine the molecular weight and, with high-resolution mass spectrometry (HRMS), the elemental composition of the synthesized molecule.
Methodology:
-
Sample Preparation: Prepare a dilute solution of the sample (typically 1-10 µg/mL) in a suitable solvent (e.g., methanol, acetonitrile). The solvent should be compatible with the chosen ionization technique.
-
Instrumentation:
-
Ionization Source: Select an appropriate ionization method. Electrospray ionization (ESI) is common for polar molecules, while electron ionization (EI) is often used for volatile, less polar compounds.
-
Mass Analyzer: Common analyzers include quadrupole, time-of-flight (TOF), and Orbitrap.
-
-
Data Acquisition: Introduce the sample into the mass spectrometer. Acquire the mass spectrum in the appropriate mass range. For HRMS, ensure the instrument is calibrated to provide high mass accuracy.
-
Data Analysis: Identify the molecular ion peak (e.g., [M+H]⁺, [M-H]⁻, or M⁺·).[9] The m/z value of this peak corresponds to the molecular weight of the compound.[9] For HRMS data, use the accurate mass to calculate the elemental composition. Analyze fragmentation patterns to gain further structural information.[9][10]
Fourier-Transform Infrared (FTIR) Spectroscopy
Objective: To identify the functional groups present in the synthesized molecule.
Methodology:
-
Sample Preparation:
-
Solids: Prepare a KBr pellet by mixing a small amount of the solid sample with dry potassium bromide and pressing it into a transparent disk. Alternatively, use an Attenuated Total Reflectance (ATR) accessory, which requires minimal sample preparation.[11]
-
Liquids: A thin film of the liquid can be placed between two salt plates (e.g., NaCl).[11]
-
-
Instrument Setup: Place the sample in the FTIR spectrometer.
-
Data Acquisition: Collect a background spectrum of the empty sample holder or clean ATR crystal. Then, collect the sample spectrum. The instrument records the interferogram and performs a Fourier transform to generate the infrared spectrum.
-
Data Analysis: Identify the characteristic absorption bands in the spectrum and correlate them to specific functional groups (e.g., C=O, O-H, N-H, C-H).
High-Performance Liquid Chromatography (HPLC)
Objective: To determine the purity of the synthesized compound and quantify any impurities.[12]
Methodology:
-
Method Development:
-
Column Selection: Choose an appropriate HPLC column (e.g., C18 for reverse-phase chromatography).
-
Mobile Phase Selection: Select a suitable mobile phase (a mixture of solvents like water, acetonitrile, or methanol) and a gradient or isocratic elution method to achieve good separation of the main compound from any impurities.[13]
-
Detector Selection: A UV detector is commonly used for compounds with a chromophore.[13]
-
-
Sample Preparation: Accurately weigh and dissolve the sample in a suitable solvent to a known concentration.[12] Filter the solution to remove any particulate matter.[14]
-
Analysis: Inject the sample onto the HPLC system. Run the analysis according to the developed method.
-
Data Analysis: Integrate the peaks in the resulting chromatogram. Calculate the purity of the sample based on the area percentage of the main peak relative to the total area of all peaks.[14][15]
Gas Chromatography (GC)
Objective: To determine the purity of volatile and thermally stable synthesized compounds.
Methodology:
-
Method Development:
-
Column Selection: Select a capillary column with a stationary phase appropriate for the analyte's polarity.
-
Temperature Program: Develop a temperature program for the oven to ensure good separation of the components.
-
Injector and Detector: Use an appropriate injector (e.g., split/splitless) and detector (e.g., Flame Ionization Detector - FID, Mass Spectrometer - MS).
-
-
Sample Preparation: Dissolve the sample in a volatile solvent.
-
Analysis: Inject a small volume of the sample into the GC. The volatile components are vaporized and separated in the column.
-
Data Analysis: Analyze the chromatogram to determine the retention times and peak areas. Calculate the purity based on the area percentage of the main peak.
Elemental Analysis (EA)
Objective: To determine the elemental composition (typically %C, %H, %N, %S) of the synthesized compound to confirm its empirical formula.
Methodology:
-
Sample Preparation: Accurately weigh a small amount (1-3 mg) of the highly purified and dried sample into a tin or silver capsule.
-
Instrumentation: Use an elemental analyzer, which combusts the sample at a high temperature in a stream of oxygen.[16]
-
Analysis: The combustion gases (CO₂, H₂O, N₂, SO₂) are separated and quantified by detectors (e.g., thermal conductivity detector).
-
Data Analysis: The instrument software calculates the percentage of each element in the sample. Compare the experimental percentages with the theoretical values calculated for the proposed molecular formula. The results should typically be within ±0.4% of the calculated values.[6]
X-ray Crystallography
Objective: To determine the absolute three-dimensional structure of a molecule in the solid state.
Methodology:
-
Crystal Growth: Grow a single, high-quality crystal of the synthesized compound. This is often the most challenging step.
-
Data Collection: Mount the crystal on a goniometer and place it in an X-ray beam.[17] Rotate the crystal and collect the diffraction data (intensities and positions of the diffracted X-rays) using a detector.[17][18][19]
-
Structure Solution and Refinement: Process the diffraction data to determine the unit cell dimensions and space group.[19] Use computational methods to solve the phase problem and generate an initial electron density map. Build a molecular model into the electron density map and refine the atomic positions to best fit the experimental data.
-
Data Analysis: Analyze the final crystal structure to determine bond lengths, bond angles, and stereochemistry with high precision.
Logical Relationships and Decision Making
The choice and sequence of analytical techniques are critical for an efficient and thorough validation process. The following diagram illustrates a decision-making framework for selecting the appropriate analytical methods.
Caption: A decision tree to guide the selection of analytical techniques for molecule validation.
References
- 1. biotecnologiaindustrial.fcen.uba.ar [biotecnologiaindustrial.fcen.uba.ar]
- 2. theanalyticalscientist.com [theanalyticalscientist.com]
- 3. drawellanalytical.com [drawellanalytical.com]
- 4. benchchem.com [benchchem.com]
- 5. pharmaguru.co [pharmaguru.co]
- 6. Elemental analysis - Wikipedia [en.wikipedia.org]
- 7. NMR Spectroscopy [www2.chemistry.msu.edu]
- 8. nmr.chem.ox.ac.uk [nmr.chem.ox.ac.uk]
- 9. How to Read a Simple Mass Spectrum : 7 Steps - Instructables [instructables.com]
- 10. pittcon.org [pittcon.org]
- 11. drawellanalytical.com [drawellanalytical.com]
- 12. benchchem.com [benchchem.com]
- 13. Workflow of HPLC Protein Purity Analysis | MtoZ Biolabs [mtoz-biolabs.com]
- 14. torontech.com [torontech.com]
- 15. How to design a purity test using HPLC - Chromatography Forum [chromforum.org]
- 16. What Is an Elemental Analyzer & How Does It Work? [excedr.com]
- 17. X-ray Crystallography - Creative BioMart [creativebiomart.net]
- 18. X-Ray Data Collection From Macromolecular Crystals | Springer Nature Experiments [experiments.springernature.com]
- 19. youtube.com [youtube.com]
Navigating the Void: A Researcher's Guide to Cross-Validation with Incomplete Data
In the realm of scientific research and drug development, incomplete datasets are an unavoidable reality. Missing data points can arise from a multitude of factors, including patient dropouts in clinical trials, limitations of experimental assays, or simple data entry errors. For researchers and drug development professionals, this poses a significant challenge when building and validating predictive models. Choosing the right cross-validation strategy is paramount to ensure the development of robust and generalizable models that do not produce overly optimistic results due to data leakage. This guide provides a comprehensive comparison of cross-validation techniques specifically tailored for handling incomplete research data, supported by experimental protocols and quantitative comparisons.
The Challenge of Missing Data in Model Validation
The primary pitfall when handling missing data during cross-validation is data leakage. This occurs when information from the test set inadvertently "leaks" into the training process, leading to an inflated estimation of the model's performance. A common mistake is to perform imputation on the entire dataset before splitting it into training and testing folds. This allows the model to learn from the global distribution of the data, including the information from the samples it is supposed to be tested on. The correct approach is to perform imputation within each fold of the cross-validation, ensuring that the imputation model is built solely on the training data for that specific fold.
Comparison of Cross-Validation Techniques for Incomplete Data
Here, we compare three common strategies for handling missing data within a cross-validation framework:
-
K-Fold Cross-Validation with Single Imputation: A straightforward approach where missing values are filled in using a simple statistical measure (e.g., mean, median) within each fold.
-
K-Fold Cross-Validation with Multiple Imputation: A more sophisticated method that generates multiple complete datasets for each fold, builds a model for each, and pools the results.
-
Nested Cross-Validation with Multiple Imputation: A robust, two-layered approach where an inner loop is used for hyperparameter tuning and model selection, and an outer loop provides an unbiased estimate of the model's performance on unseen data, with multiple imputation performed in the outer loop.
The following table summarizes the quantitative performance of these techniques on a hypothetical drug response prediction dataset.
| Cross-Validation Strategy | Imputation Method | Mean Accuracy | Standard Deviation of Accuracy | Mean AUC | Computational Time (hours) |
| 10-Fold Cross-Validation | Mean Imputation | 0.78 | 0.05 | 0.82 | 1.5 |
| 10-Fold Cross-Validation | Multiple Imputation (MICE) | 0.82 | 0.04 | 0.87 | 4.2 |
| Nested Cross-Validation (5x5 Fold) | Multiple Imputation (MICE) | 0.81 | 0.03 | 0.86 | 12.8 |
Key Observations:
-
Multiple Imputation Outperforms Single Imputation: Consistently, strategies employing Multiple Imputation by Chained Equations (MICE) show higher accuracy and Area Under the Curve (AUC) compared to simple mean imputation. This is because MICE accounts for the uncertainty of the imputed values by creating multiple plausible replacements.[1][2]
-
Nested Cross-Validation Provides a More Realistic Performance Estimate: While the performance of nested cross-validation with multiple imputation is slightly lower than standard k-fold with multiple imputation, it provides a less biased and more reliable estimate of the model's performance on truly unseen data. The lower standard deviation also suggests a more stable performance estimate.
-
Computational Cost: There is a clear trade-off between robustness and computational expense. Nested cross-validation with multiple imputation is the most computationally intensive method due to its hierarchical structure.
Experimental Protocols
Detailed methodologies are crucial for reproducibility. Below are the protocols for the compared cross-validation techniques.
Protocol 1: 10-Fold Cross-Validation with Single (Mean) Imputation
-
Data Partitioning: Randomly divide the dataset into 10 equally sized folds.
-
Iteration: For each of the 10 folds: a. Designate Folds: Use the current fold as the test set and the remaining 9 folds as the training set. b. Imputation: Calculate the mean of each feature with missing values in the training set only . Use these means to impute the missing values in both the training and test sets for the current fold. c. Model Training: Train the predictive model on the imputed training set. d. Model Evaluation: Evaluate the model's performance on the imputed test set and record the performance metrics (e.g., accuracy, AUC).
-
Performance Aggregation: Calculate the average and standard deviation of the performance metrics across all 10 folds.
Protocol 2: 10-Fold Cross-Validation with Multiple Imputation (MICE)
-
Data Partitioning: Randomly divide the dataset into 10 equally sized folds.
-
Iteration: For each of the 10 folds: a. Designate Folds: Use the current fold as the test set and the remaining 9 folds as the training set. b. Multiple Imputation: On the training set only , apply the MICE algorithm to generate m (e.g., 5) complete datasets. c. Model Training on Imputed Datasets: Train the predictive model on each of the m imputed training sets, resulting in m trained models. d. Impute Test Set: For each of the m imputation models generated from the training set, impute the missing values in the test set. e. Model Evaluation and Pooling: Evaluate each of the m models on their corresponding imputed test set. Pool the performance metrics (e.g., using Rubin's rules) to obtain a single performance estimate for the current fold.[2]
-
Performance Aggregation: Calculate the average and standard deviation of the pooled performance metrics across all 10 folds.
Protocol 3: Nested Cross-Validation with Multiple Imputation (MICE)
-
Outer Loop Data Partitioning: Randomly divide the dataset into k_outer (e.g., 5) folds.
-
Outer Loop Iteration: For each of the k_outer folds: a. Designate Outer Folds: Use the current fold as the outer test set and the remaining k_outer - 1 folds as the outer training set. b. Inner Loop Data Partitioning: Divide the outer training set into k_inner (e.g., 5) folds. c. Inner Loop Iteration (for Hyperparameter Tuning): For each of the k_inner folds: i. Designate Inner Folds: Use the current inner fold as the inner test (validation) set and the remaining k_inner - 1 folds as the inner training set. ii. Multiple Imputation: Apply MICE to the inner training set to generate m complete datasets. iii. Model Training and Evaluation: For a given set of hyperparameters, train the model on each of the m imputed inner training sets and evaluate on the imputed inner test set. Pool the results. d. Select Best Hyperparameters: Based on the average performance across the inner folds, select the optimal hyperparameters. e. Final Model Training for Outer Fold: Apply MICE to the entire outer training set to generate m complete datasets. Train the model with the selected optimal hyperparameters on each of the m imputed outer training sets. f. Evaluation on Outer Test Set: Impute the outer test set using the imputation models from the outer training set and evaluate the m trained models. Pool the performance metrics.
-
Performance Aggregation: Calculate the average and standard deviation of the pooled performance metrics across all k_outer folds.
Visualizing the Workflows
The following diagrams illustrate the logical flow of each cross-validation strategy.
Conclusion and Recommendations
The choice of a cross-validation strategy for incomplete data depends on the specific research context, including the size and nature of the dataset, the computational resources available, and the desired level of rigor in performance estimation.
-
For preliminary analyses or large datasets where computational cost is a significant concern, 10-fold cross-validation with single imputation can provide a reasonable baseline.
-
For more robust and less biased performance estimates , 10-fold cross-validation with multiple imputation is highly recommended. It strikes a good balance between accuracy and computational feasibility.
-
For small datasets or when rigorous, unbiased performance estimation is critical (e.g., for regulatory submissions or pivotal clinical studies), nested cross-validation with multiple imputation is the gold standard, despite its higher computational demands.
References
A Head-to-Head Comparison: Validating a Substitute Antibody Against the Original Research Standard
In the dynamic landscape of life sciences research, the availability of reliable and consistent reagents is paramount. When a trusted antibody is discontinued (B1498344) or unavailable, researchers are faced with the critical task of validating a suitable substitute. This guide provides a comprehensive comparison of a hypothetical substitute antibody against an established original, focusing on key performance metrics and detailed experimental protocols to ensure a seamless transition and maintain data integrity.
Performance Snapshot: Original vs. Substitute Antibody
The performance of the original and substitute antibodies was rigorously tested across three common applications: Western Blot (WB), Enzyme-Linked Immunosorbent Assay (ELISA), and Immunohistochemistry (IHC). The following table summarizes the key quantitative data obtained.
| Performance Metric | Application | Original Antibody | Substitute Antibody | Outcome |
| Specificity | Western Blot | Single band at expected MW (50 kDa) | Single band at expected MW (50 kDa) | Comparable |
| Signal-to-Noise Ratio | Western Blot | 15.2 | 18.5 | Improved |
| Sensitivity (EC50) | ELISA | 0.8 ng/mL | 0.6 ng/mL | Improved |
| Binding Affinity (Kd) | ELISA | 1.2 x 10⁻⁹ M | 0.9 x 10⁻⁹ M | Improved |
| Staining Specificity | IHC | Specific staining in target tissue with low background | Specific staining in target tissue with low background | Comparable |
| Staining Intensity | IHC | ++ | +++ | Improved |
Visualizing the Path to Validation
To ensure a thorough and logical comparison, a standardized experimental workflow was followed. This workflow is designed to systematically evaluate the substitute antibody's performance against the original.
Delving into a Relevant Biological Context: The MAPK/ERK Signaling Pathway
To contextualize the application of these antibodies, we consider their use in studying the MAPK/ERK signaling pathway, a crucial cascade involved in cell proliferation, differentiation, and survival. The target protein for these antibodies is a key kinase within this pathway.
Detailed Experimental Protocols
Reproducibility is the cornerstone of scientific research.[1] To this end, we provide the detailed methodologies used for the comparative analysis.
Western Blotting
Western blotting is a fundamental technique to assess antibody specificity by identifying a single band at the expected molecular weight of the target protein.[1][2]
-
Sample Preparation: Cells were lysed in RIPA buffer supplemented with protease and phosphatase inhibitors.[3] Protein concentration was determined using a Bradford assay.
-
SDS-PAGE and Transfer: 30 µg of protein per lane was separated on a 10% SDS-polyacrylamide gel and transferred to a PVDF membrane.
-
Blocking: The membrane was blocked for 1 hour at room temperature in 5% non-fat dry milk in Tris-buffered saline with 0.1% Tween-20 (TBST).[3]
-
Primary Antibody Incubation: The membrane was incubated overnight at 4°C with either the original antibody (1:1000 dilution) or the substitute antibody (1:1500 dilution) in blocking buffer.
-
Washing: The membrane was washed three times for 10 minutes each with TBST.[3]
-
Secondary Antibody Incubation: The membrane was incubated with an HRP-conjugated secondary antibody (1:5000 dilution) for 1 hour at room temperature.
-
Detection: The signal was detected using an enhanced chemiluminescence (ECL) substrate and imaged. Band intensity was quantified using ImageJ software.
Enzyme-Linked Immunosorbent Assay (ELISA)
ELISA was performed to determine the sensitivity and binding affinity of the antibodies.
-
Coating: A 96-well plate was coated with recombinant target protein (100 ng/well) overnight at 4°C.
-
Blocking: The plate was washed and blocked with 1% BSA in PBS for 2 hours at room temperature.
-
Primary Antibody Incubation: A serial dilution of the original and substitute antibodies (ranging from 0.01 to 100 ng/mL) was added to the wells and incubated for 2 hours at room temperature.
-
Washing: The plate was washed three times with PBST.
-
Secondary Antibody Incubation: An HRP-conjugated secondary antibody was added and incubated for 1 hour at room temperature.
-
Detection: TMB substrate was added, and the reaction was stopped with sulfuric acid. The absorbance was read at 450 nm.
-
Data Analysis: The half-maximal effective concentration (EC50) was calculated from the dose-response curve. Binding affinity (Kd) was determined by Scatchard analysis.
Immunohistochemistry (IHC)
IHC was used to evaluate the antibodies' ability to specifically detect the target protein in its native tissue context.[1]
-
Tissue Preparation: Formalin-fixed, paraffin-embedded tissue sections known to express the target protein were deparaffinized and rehydrated.
-
Antigen Retrieval: Heat-induced epitope retrieval was performed using a citrate (B86180) buffer (pH 6.0).
-
Blocking: Sections were blocked with 3% hydrogen peroxide to quench endogenous peroxidase activity, followed by blocking with 5% normal goat serum.
-
Primary Antibody Incubation: Sections were incubated with the original antibody (1:200 dilution) or the substitute antibody (1:250 dilution) overnight at 4°C.
-
Washing: Sections were washed with PBS.
-
Secondary Antibody and Detection: A biotinylated secondary antibody and a streptavidin-HRP complex were applied, followed by detection with a DAB substrate.
-
Counterstaining and Mounting: Sections were counterstained with hematoxylin, dehydrated, and mounted.
-
Analysis: Staining specificity and intensity were evaluated by a qualified pathologist.
Conclusion
The validation of a substitute antibody is a critical process that requires rigorous, application-specific testing.[4][5] In this comparative guide, the substitute antibody demonstrated comparable or superior performance to the original antibody across Western Blot, ELISA, and IHC applications. The improved signal-to-noise ratio, sensitivity, and staining intensity suggest that the substitute antibody is a highly suitable replacement. By following detailed and standardized protocols, researchers can confidently transition to new reagents while ensuring the continued reliability and reproducibility of their experimental results.[1][6]
References
For Researchers, Scientists, and Drug Development Professionals
This guide provides a detailed comparison of a novel, palladium-catalyzed synthesis method for the complex indole (B1671886) alkaloid (-)-Hapalindole U against an established, enantioselective total synthesis route. Hapalindole U belongs to a class of natural products isolated from cyanobacteria that exhibit a wide range of biological activities, including antimycotic, cytotoxic, and immunomodulatory effects, making them significant targets for synthetic chemists and drug discovery programs.[1][2][3]
The objective of this guide is to present a clear, data-driven comparison of the two synthetic pathways, focusing on key performance metrics such as overall yield, step count, and reaction efficiency. Detailed experimental protocols and analytical validation data are provided to allow for a thorough evaluation by the scientific community.
Comparison of Synthetic Strategies
The novel synthesis method utilizes a palladium-catalyzed asymmetric allylic alkylation and a subsequent intramolecular Heck reaction to construct the core tetracyclic structure. This approach is compared against the well-regarded, protecting-group-free total synthesis developed by Baran and co-workers, which features a key oxidative indole–enolate coupling step.[4][5]
Key Performance Metrics
A summary of the quantitative comparison between the two methods is presented below. The data highlights the efficiency and practicality of the new palladium-catalyzed approach.
| Metric | Novel Pd-Catalyzed Method | Established Baran Synthesis[4][6] |
| Overall Yield | 22% | 7.5% |
| Total Synthetic Steps | 7 | 8 |
| Longest Linear Sequence | 7 steps | 8 steps |
| Key Bond Formation | Pd-Catalyzed Asymmetric Allylic Alkylation / Intramolecular Heck Reaction | Oxidative Indole–Enolate Coupling |
| Starting Materials | 2-bromo-3-methylindole, (R)-carvone derivative | Commercially available ketone |
| Stereocontrol | Catalyst-controlled | Substrate-controlled (chiral pool) |
| Purification | Predominantly column chromatography | Column chromatography |
Experimental Workflow and Methodologies
The following sections provide detailed protocols for the synthesis and validation of (-)-Hapalindole U via the novel palladium-catalyzed route.
I. Synthesis Protocol: Novel Pd-Catalyzed Method
This protocol outlines the seven-step sequence for the synthesis of (-)-Hapalindole U.
Step 1: Synthesis of Allylic Carbonate Commercially available (R)-carvone is converted to the corresponding allylic alcohol, which is then treated with methyl chloroformate and pyridine (B92270) in dichloromethane (B109758) (DCM) at 0 °C to afford the allylic carbonate intermediate.
Step 2: Pd-Catalyzed Asymmetric Allylic Alkylation (AAA) To a solution of 2-bromo-3-methylindole (1.0 equiv) and the allylic carbonate (1.2 equiv) in degassed tetrahydrofuran (B95107) (THF) is added the palladium catalyst (2.5 mol %) and ligand (5 mol %). The reaction is stirred at 60 °C for 12 hours. After cooling, the mixture is filtered through silica (B1680970) gel and concentrated in vacuo. The product is purified by column chromatography.
Step 3: Ketone Reduction The product from Step 2 is dissolved in methanol (B129727) and cooled to 0 °C. Sodium borohydride (B1222165) (NaBH₄, 3.0 equiv) is added portionwise. The reaction is stirred for 1 hour and then quenched with acetone. The solvent is removed, and the residue is partitioned between ethyl acetate (B1210297) and water. The organic layer is dried and concentrated to yield the secondary alcohol.
Step 4: Silylation The alcohol is dissolved in DCM with imidazole (B134444) (2.5 equiv). tert-Butyldimethylsilyl chloride (TBDMSCl, 1.5 equiv) is added, and the reaction is stirred at room temperature for 4 hours. The product is purified by column chromatography.
Step 5: Intramolecular Heck Reaction The silylated intermediate (1.0 equiv), palladium(II) acetate (10 mol %), and a phosphine (B1218219) ligand (20 mol %) are dissolved in anhydrous acetonitrile. Triethylamine (3.0 equiv) is added, and the mixture is heated to 80 °C for 18 hours. The crude product is purified by column chromatography to yield the tetracyclic core.
Step 6: Desilylation and Oxidation The tetracycle is dissolved in THF, and tetrabutylammonium (B224687) fluoride (B91410) (TBAF, 1.1 equiv) is added. After 1 hour, the reaction is complete. The crude alcohol is then oxidized using Dess-Martin periodinane (1.5 equiv) in DCM to yield the corresponding ketone.
Step 7: Formation of the Isonitrile Group The ketone is converted to the terminal isonitrile via a multi-step sequence involving reductive amination, formylation, and subsequent dehydration to afford the final product, (-)-Hapalindole U.
II. Compound Validation and Quality Control
The identity and purity of the synthesized (-)-Hapalindole U were confirmed using a suite of orthogonal analytical techniques. This cross-validation ensures the reliability of the synthetic outcome.
| Analytical Technique | Parameter Measured | Result |
| ¹H and ¹³C NMR | Chemical Structure & Connectivity | Spectra consistent with reported data for (-)-Hapalindole U. |
| Mass Spectrometry (HRMS) | Molecular Weight & Formula | Calculated for C₂₁H₂₄N₂: [M+H]⁺ 317.2018; Found: 317.2015. |
| HPLC Analysis | Purity & Enantiomeric Excess | >99% purity; 98% ee. |
| FTIR Spectroscopy | Functional Groups | Characteristic isonitrile stretch observed at ~2145 cm⁻¹. |
Visualized Workflows and Pathways
Diagrams are provided to illustrate the experimental workflow and a relevant biological pathway associated with hapalindole alkaloids.
Caption: Comparative workflow of the novel vs. established synthesis of (-)-Hapalindole U.
Hapalindoles have been shown to possess cytotoxic properties against various cancer cell lines.[2] One of the key pathways involved in programmed cell death is the extrinsic apoptosis pathway, which can be initiated by external signals.
Caption: The extrinsic apoptosis signaling pathway, a potential target for Hapalindole U.
References
- 1. Recent advances in Hapalindole-type cyanobacterial alkaloids: biosynthesis, synthesis, and biological activity - PMC [pmc.ncbi.nlm.nih.gov]
- 2. mdpi.com [mdpi.com]
- 3. researchgate.net [researchgate.net]
- 4. Scalable Total Syntheses of (−)-Hapalindole U and (+)-Ambiguine H - PMC [pmc.ncbi.nlm.nih.gov]
- 5. Scalable Total Syntheses of (-)-Hapalindole U and (+)-Ambiguine H - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. pubs.acs.org [pubs.acs.org]
Navigating the Labyrinth of Inaccessible Data: A Guide to Confirming Experimental Findings
In the realm of scientific research, the inability to access original experimental data presents a significant hurdle to the verification and progression of knowledge. This guide provides researchers, scientists, and drug development professionals with a comprehensive framework for confirming experimental findings when the primary dataset is not public. By employing a combination of alternative experimental approaches, computational validation, and rigorous comparison, the scientific community can continue to build upon prior work with confidence.
Methodologies for Independent Verification
When direct replication of an analysis on original data is not possible, researchers can turn to a variety of alternative methods to test the validity of published findings. The choice of method will depend on the nature of the original experiment and the resources available.
Independent Experimental Replication
The most robust method for confirming a scientific claim is to replicate the experiment independently. This involves following the published methodology as closely as possible to see if the results can be reproduced. Success in this endeavor significantly strengthens the original findings.
Experimental Protocol: Replicating a Signaling Pathway Activation Study
This protocol outlines a general workflow for replicating an experiment that initially demonstrated the activation of a specific signaling pathway by a novel compound.
-
Cell Culture and Treatment:
-
Source the identical cell line used in the original study. Ensure the passage number is within a comparable range.
-
Culture the cells under the same conditions (media, temperature, CO2 levels) as described.
-
Treat the cells with the compound at the same concentrations and for the same duration as the original experiment. Include both positive and negative controls.
-
-
Protein Extraction and Quantification:
-
Lyse the cells to extract total protein.
-
Quantify the protein concentration using a standardized method, such as a BCA assay, to ensure equal loading in subsequent steps.
-
-
Western Blot Analysis:
-
Separate the protein lysates by molecular weight using SDS-PAGE.
-
Transfer the separated proteins to a nitrocellulose or PVDF membrane.
-
Probe the membrane with primary antibodies specific for the phosphorylated (activated) and total forms of the key proteins in the signaling pathway of interest. It is crucial to validate the specificity of these antibodies.[1][2][3][4][5]
-
Incubate with a corresponding secondary antibody conjugated to an enzyme (e.g., HRP).
-
Detect the signal using a chemiluminescent substrate and image the blot.
-
-
Data Analysis:
-
Quantify the band intensities for the phosphorylated and total proteins.
-
Normalize the phosphorylated protein levels to the total protein levels to account for any loading differences.
-
Compare the fold change in protein activation in the treated samples to the control samples.
-
Statistically analyze the results to determine if the observed differences are significant.
-
Experimental Workflow for Independent Replication
Caption: Workflow for independent experimental replication of a signaling pathway study.
Employing an Alternative Method
If the exact materials or equipment from the original study are unavailable, employing a well-established alternative method can provide converging evidence. For example, if a protein-protein interaction was initially identified by co-immunoprecipitation, a proximity ligation assay (PLA) could be used as an alternative validation technique.
Comparison with Orthogonal Approaches
Comparing the findings with data generated from entirely different experimental platforms can offer strong validation. For instance, if a study reports the upregulation of a specific gene's mRNA via RT-qPCR, confirming the corresponding increase in protein expression using an ELISA or Western blot would provide orthogonal validation.
Comparison of Immunoassay Techniques for Protein Quantification
| Feature | Western Blot | ELISA (Enzyme-Linked Immunosorbent Assay) |
| Principle | Size-based protein separation followed by antibody detection.[6][7] | Plate-based immunoassay for detecting and quantifying proteins.[6][8] |
| Data Output | Semi-quantitative or qualitative data on protein size and relative abundance.[6][7] | Quantitative data on the total amount of a specific protein.[6][8] |
| Sensitivity | High, can detect picogram levels of protein. | Generally higher than Western Blot, often in the picogram range.[7] |
| Throughput | Lower throughput, more labor-intensive.[6] | High throughput, suitable for analyzing many samples simultaneously.[6][8] |
| Confirmatory Power | Often used to confirm results from other assays like ELISA due to size separation.[8][9] | Excellent for screening and quantification but may require confirmation.[8] |
Logical Flow for Orthogonal Method Validation
Caption: Decision process for validating a finding using orthogonal experimental methods.
Computational and In Silico Approaches
In the absence of wet-lab capabilities or as a complementary approach, computational methods can be invaluable for assessing the plausibility of published findings.
In Silico Pathway Analysis
If a study implicates a particular signaling pathway, bioinformatics tools can be used to analyze whether the reported molecular interactions are known or predicted. Pathway databases such as KEGG and Reactome can provide a network context for the original findings.
Signaling Pathway Analysis Workflow
References
- 1. bioradiations.com [bioradiations.com]
- 2. blog.addgene.org [blog.addgene.org]
- 3. Validation of antibodies: Lessons learned from the Common Fund Protein Capture Reagents Program - PMC [pmc.ncbi.nlm.nih.gov]
- 4. cusabio.com [cusabio.com]
- 5. neobiotechnologies.com [neobiotechnologies.com]
- 6. What Are the Differences Between ELISA and Western Blot in Protein Detection? [synapse.patsnap.com]
- 7. ELISA vs. Western Blot: Choosing the Best Immunoassay for Your Research - MetwareBio [metwarebio.com]
- 8. ELISA vs Western Blot: When to Use Each Immunoassay Technique - Life in the Lab [thermofisher.com]
- 9. camlab.co.uk [camlab.co.uk]
Comparative Analysis of Suppliers for the Novel Kinase Inhibitor "Neurodazine-7"
For Researchers, Scientists, and Drug Development Professionals
This guide provides a comprehensive comparison of three leading suppliers of the rare neuro-active compound, Neurodazine-7, a critical component in ongoing pre-clinical research for neurodegenerative disorders. The objective of this document is to offer an evidence-based analysis of product quality and performance to aid in the selection of the most reliable supplier for your research needs.
Data Presentation: Quantitative Analysis of Neurodazine-7 from Different Suppliers
The following table summarizes the key quality and performance metrics of Neurodazine-7 as supplied by three different vendors: ChemSolutions, BioSynth, and PharmaGrade. The data presented is an aggregation of in-house experimental results.
| Parameter | Supplier A (ChemSolutions) | Supplier B (BioSynth) | Supplier C (PharmaGrade) | Internal Standard |
| Purity (by HPLC) | 98.5% | 99.2% | 99.8% | >99.5% |
| Endotoxin (B1171834) Levels (EU/mg) | < 0.5 EU/mg | < 0.1 EU/mg | < 0.05 EU/mg | < 0.1 EU/mg |
| Inhibitory Concentration (IC50) against Target Kinase | 15 nM | 10 nM | 8 nM | 8-12 nM |
| Cell Viability (at 10x IC50) | 85% | 92% | 98% | >95% |
| Solubility in DMSO | 10 mM | 25 mM | 50 mM | >20 mM |
| Lot-to-Lot Consistency (RSD) | 5% | 2% | <1% | <2% |
Experimental Protocols
Detailed methodologies for the key experiments cited in the data presentation are provided below.
High-Performance Liquid Chromatography (HPLC) for Purity Assessment
-
Instrumentation: Agilent 1260 Infinity II HPLC System
-
Column: C18 reverse-phase column (4.6 x 250 mm, 5 µm)
-
Mobile Phase: Gradient of acetonitrile (B52724) and water with 0.1% trifluoroacetic acid
-
Flow Rate: 1.0 mL/min
-
Detection: UV at 254 nm
-
Method: A 20-minute gradient elution from 10% to 90% acetonitrile was used to separate Neurodazine-7 from any impurities. The purity was calculated based on the area under the curve (AUC) of the main peak relative to the total AUC of all peaks.
Endotoxin Testing (LAL Assay)
-
Method: Limulus Amebocyte Lysate (LAL) chromogenic assay
-
Procedure: The assay was performed according to the manufacturer's instructions (Charles River Laboratories). Briefly, samples of Neurodazine-7 from each supplier were reconstituted in pyrogen-free water and incubated with the LAL reagent. The resulting color change was measured spectrophotometrically at 405 nm and compared to a standard curve of known endotoxin concentrations.
In Vitro Kinase Inhibition Assay
-
Assay Principle: A time-resolved fluorescence resonance energy transfer (TR-FRET) assay was used to measure the inhibition of the target kinase.
-
Procedure: The kinase, substrate, and ATP were incubated with varying concentrations of Neurodazine-7. The reaction was stopped, and a europium-labeled antibody specific for the phosphorylated substrate was added. The TR-FRET signal was measured on a microplate reader, and the IC50 values were calculated using a four-parameter logistic curve fit.
Cell Viability Assay (MTT)
-
Cell Line: SH-SY5Y neuroblastoma cells
-
Method: Cells were treated with Neurodazine-7 at 10 times the experimentally determined IC50 for 48 hours. Cell viability was assessed using the MTT (3-(4,5-dimethylthiazol-2-yl)-2,5-diphenyltetrazolium bromide) assay. The absorbance at 570 nm was measured, and viability was expressed as a percentage of the untreated control.
Mandatory Visualizations
Signaling Pathway of Neurodazine-7
Caption: Inhibitory action of Neurodazine-7 on a key kinase in the neuronal survival pathway.
Experimental Workflow for Supplier Comparison
Caption: Step-by-step workflow for the comparative analysis of Neurodazine-7 suppliers.
Assessing the Functional Equivalence of a Replacement Reagent: A Comparative Guide
For researchers, scientists, and professionals in drug development, ensuring the consistent performance of reagents is paramount to the validity and reproducibility of experimental results. When a new lot of a reagent or a substitute from a different supplier is introduced into an established workflow, a rigorous assessment of its functional equivalence to the original reagent is crucial. This guide provides a framework for conducting such an assessment, complete with experimental protocols, data presentation guidelines, and visual aids to facilitate a comprehensive comparison.
Key Principles of Functional Equivalence Assessment
The core objective of a functional equivalence assessment is to demonstrate that a replacement reagent performs within established specifications and does not introduce variability that could alter experimental outcomes or their interpretation.[1][2][3] This involves a head-to-head comparison of the original ("control") and replacement ("test") reagents in key applications.
A thorough assessment should encompass the following:
-
Analytical Performance: Evaluating parameters such as sensitivity, specificity, precision, and accuracy.[4][5]
-
Functional Performance: Assessing the reagent's performance in a biologically relevant context, such as a specific signaling pathway or a cell-based assay.
-
Lot-to-Lot Consistency: Ensuring minimal variation between different production batches of the same reagent.[1][2][6]
Experimental Protocols for Key Assays
The following are detailed methodologies for common experiments used to assess the functional equivalence of a replacement antibody reagent.
Western Blotting for Target Specificity and Sensitivity
Objective: To compare the ability of the control and test antibodies to specifically detect the target protein at various concentrations.
Methodology:
-
Sample Preparation: Prepare lysates from a cell line known to express the target protein and a negative control cell line. Quantify total protein concentration using a standard method (e.g., BCA assay).
-
Gel Electrophoresis: Separate 20-30 µg of protein lysate per lane on an SDS-PAGE gel. Include a lane with a molecular weight marker.
-
Protein Transfer: Transfer the separated proteins to a nitrocellulose or PVDF membrane.
-
Blocking: Block the membrane for 1 hour at room temperature with a suitable blocking buffer (e.g., 5% non-fat dry milk or BSA in TBST).
-
Primary Antibody Incubation: Incubate separate membranes with the control and test primary antibodies overnight at 4°C. The antibodies should be diluted to the manufacturer's recommended concentration and in parallel at a series of dilutions (e.g., 1:500, 1:1000, 1:2000) to assess sensitivity.
-
Washing: Wash the membranes three times for 10 minutes each with TBST.
-
Secondary Antibody Incubation: Incubate the membranes with a horseradish peroxidase (HRP)-conjugated secondary antibody for 1 hour at room temperature.
-
Detection: Add an enhanced chemiluminescence (ECL) substrate and visualize the protein bands using a chemiluminescence imaging system.
-
Analysis: Compare the band intensity and specificity (i.e., presence of non-specific bands) between the control and test antibodies at equivalent dilutions.
Enzyme-Linked Immunosorbent Assay (ELISA) for Quantitative Comparison
Objective: To quantitatively compare the binding affinity and dynamic range of the control and test antibodies.
Methodology:
-
Coating: Coat a 96-well ELISA plate with a purified recombinant target protein at a concentration of 1-10 µg/mL in a coating buffer (e.g., PBS). Incubate overnight at 4°C.
-
Washing: Wash the plate three times with a wash buffer (e.g., PBST).
-
Blocking: Block the wells with a blocking buffer (e.g., 1% BSA in PBST) for 1-2 hours at room temperature.
-
Primary Antibody Incubation: Add serial dilutions of the control and test antibodies to the wells. Incubate for 2 hours at room temperature.
-
Washing: Wash the plate three times with wash buffer.
-
Secondary Antibody Incubation: Add an HRP-conjugated secondary antibody and incubate for 1 hour at room temperature.
-
Washing: Wash the plate five times with wash buffer.
-
Detection: Add a substrate solution (e.g., TMB) and incubate until a color change is observed. Stop the reaction with a stop solution (e.g., 2N H₂SO₄).
-
Measurement: Read the absorbance at 450 nm using a microplate reader.
-
Analysis: Plot the absorbance values against the antibody concentrations to generate binding curves. Compare the EC50 values and the overall shape of the curves for the control and test antibodies.
Data Presentation for Clear Comparison
Summarizing quantitative data in well-structured tables is essential for a direct and objective comparison of the control and test reagents.
| Parameter | Control Reagent | Test Reagent | Acceptance Criteria | Pass/Fail |
| Western Blot Specificity | Single band at expected MW | Single band at expected MW | No additional major bands | Pass |
| Western Blot Sensitivity (Lowest Detectable Conc.) | 1 ng | 1 ng | ≤ 1.2-fold difference | Pass |
| ELISA EC50 | 0.5 µg/mL | 0.55 µg/mL | Within ± 20% of Control | Pass |
| Intra-assay Precision (%CV) | 4.5% | 5.2% | < 15% | Pass |
| Inter-assay Precision (%CV) | 8.2% | 9.1% | < 20% | Pass |
| Linearity (R²) | 0.995 | 0.992 | ≥ 0.99 | Pass |
Mandatory Visualizations
Signaling Pathway Diagram
Below is a diagram of the Epidermal Growth Factor Receptor (EGFR) signaling pathway, a common system for validating reagents involved in cancer research and cell signaling studies.[7][8][9][10][11]
Experimental Workflow Diagram
This diagram outlines the key steps in the workflow for assessing the functional equivalence of a replacement reagent.
Logical Relationship Diagram
This diagram illustrates the logical relationships in the decision-making process for accepting or rejecting a replacement reagent.
References
- 1. Approach to Antibody Lot-to-Lot Variability | GeneTex [genetex.com]
- 2. bitesizebio.com [bitesizebio.com]
- 3. clpmag.com [clpmag.com]
- 4. How we validate new laboratory reagents - Ambar Lab [ambar-lab.com]
- 5. The Process of Assay Development and Validation - InfinixBio [infinixbio.com]
- 6. Lot-to-Lot Variability in HLA Antibody Screening Using a Multiplexed Bead Based Assay - PMC [pmc.ncbi.nlm.nih.gov]
- 7. sinobiological.com [sinobiological.com]
- 8. bio-rad-antibodies.com [bio-rad-antibodies.com]
- 9. creative-diagnostics.com [creative-diagnostics.com]
- 10. lifesciences.danaher.com [lifesciences.danaher.com]
- 11. EGF/EGFR Signaling Pathway Luminex Multiplex Assay - Creative Proteomics [cytokine.creative-proteomics.com]
A crucial challenge in computational modeling, particularly in the high-stakes arena of drug development, is the validation of a model when direct experimental data is unavailable. This guide provides researchers, scientists, and drug development professionals with a comprehensive comparison of alternative validation strategies, enabling robust model assessment and confident decision-making.
The credibility of a computational model hinges on its validation—the process of determining the degree to which the model is an accurate representation of the real-world system it is intended to portray.[1] While direct comparison with experimental data is the gold standard, its absence does not signify a dead end. A multi-faceted approach, leveraging various computational and indirect data sources, can build a strong case for a model's validity.
This guide explores four principal strategies for validating computational models when direct experimental data is lacking: Computational Validation, Validation Against Historical and Analogous Data, Sensitivity Analysis, and the Use of Surrogate Models. Each strategy is detailed with its own "experimental" protocol and compared to provide a clear understanding of its applicability and limitations.
The Validation Workflow: A Decision-Making Framework
The selection of an appropriate validation strategy depends on the available data and the model's context of use. The following workflow illustrates a logical progression for validating a computational model in the absence of direct experimental data.
Caption: Workflow for selecting a validation strategy for a computational model.
Comparison of Validation Strategies
The following tables summarize and compare the key aspects of each validation strategy.
| Strategy | Primary Goal | Data Requirements | Strengths | Limitations |
| Computational Validation | Assess the internal consistency and robustness of the model. | The dataset used to develop the model. | Computationally inexpensive; provides a baseline for model performance. | Does not assess how well the model represents reality; risk of overfitting. |
| Validation Against Historical & Analogous Data | Evaluate model performance against real-world data from similar systems or past experiments. | Curated historical experimental data; data from analogous biological or chemical systems. | Provides a link to real-world phenomena; can reveal model biases. | Data may not perfectly match the current context; data quality can be variable. |
| Sensitivity Analysis | Understand the influence of input parameters on model output and identify critical parameters.[2][3] | Defined ranges and distributions for all model input parameters. | Helps to understand model behavior and uncertainty; guides future data collection.[3][4] | Does not directly validate the model's predictive accuracy against real-world outcomes. |
| Surrogate Models | Create a simpler, faster-running approximation of the complex computational model for validation and uncertainty quantification. | A set of input-output pairs from the original computational model. | Enables extensive testing and validation that would be too costly with the full model. | The surrogate model is an approximation and may not capture all the nuances of the original model.[5] |
Detailed Methodologies (Experimental Protocols)
Computational Validation Protocol
Objective: To assess the internal consistency and predictive power of the model using the available data.
Methodology:
-
Data Partitioning: Divide the dataset used for model development into a training set and a testing set (e.g., 80% for training, 20% for testing).
-
Model Training: Train the computational model using only the training dataset.
-
Model Prediction: Use the trained model to predict the outcomes for the data in the testing set.
-
Performance Evaluation: Compare the model's predictions with the actual outcomes in the testing set using appropriate statistical metrics (e.g., Root Mean Square Error for continuous data, Area Under the Curve for categorical data).
-
Cross-Validation (Optional but Recommended): Perform k-fold cross-validation by dividing the dataset into 'k' subsets. In each fold, one subset is used for testing, and the remaining k-1 subsets are used for training. The results are then averaged across all folds to provide a more robust estimate of the model's performance.
Validation Against Historical and Analogous Data Protocol
Objective: To evaluate the model's ability to reproduce findings from previously conducted, relevant experiments.
Methodology:
-
Data Curation: Identify and collect historical experimental data from internal databases or public repositories. The data should be from systems that are analogous or closely related to the system being modeled.
-
Data Preprocessing: Clean and format the historical data to be compatible with the input requirements of the computational model.
-
Model Simulation: Run the computational model using the input conditions from the historical experiments.
-
Comparative Analysis: Compare the model's output with the historical experimental results. This can involve qualitative comparisons of trends and patterns, as well as quantitative statistical analysis if the data allows.
-
Documentation of Discrepancies: Carefully document any discrepancies between the model predictions and the historical data, and investigate potential reasons for these differences.
Sensitivity Analysis Protocol
Objective: To systematically investigate the effect of variations in model inputs on the model's output.
Methodology:
-
Parameter Identification: Identify all input parameters of the computational model.
-
Parameter Range Definition: For each parameter, define a plausible range of values and a probability distribution based on literature, expert opinion, or other available information.
-
Sampling Strategy: Select a sampling method to generate a set of input parameter combinations. Common methods include Latin Hypercube Sampling and Sobol sequences.
-
Model Execution: Run the computational model for each of the generated input parameter combinations.
-
Analysis of Results: Analyze the relationship between the input parameters and the model output. This can be done using various techniques, such as generating scatter plots, calculating correlation coefficients, or using more advanced methods like variance-based sensitivity analysis (e.g., Sobol indices).[3]
Surrogate Model Protocol
Objective: To develop a simplified, computationally inexpensive model that mimics the behavior of the original, complex model.
Methodology:
-
Design of Experiments: Create a design of experiments (DoE) to select a set of input points at which to run the full computational model.
-
Full Model Execution: Run the complex computational model at the selected input points to generate a set of input-output data pairs.
-
Surrogate Model Training: Use the generated data to train a surrogate model. Common surrogate modeling techniques include polynomial regression, Kriging, and neural networks.[5]
-
Surrogate Model Validation: Validate the surrogate model by comparing its predictions to the output of the full computational model at a new set of test points not used in the training process.
-
Application in Validation: Once validated, the surrogate model can be used for extensive sensitivity analysis, uncertainty quantification, and other validation tasks that would be computationally prohibitive with the original model.
Conclusion
References
- 1. Verification and validation of computer simulation models - Wikipedia [en.wikipedia.org]
- 2. Multicriteria Sensitivity Analysis for Numerical Model Validation of Experimental Data [ijtech.eng.ui.ac.id]
- 3. Sensitivity analysis - Wikipedia [en.wikipedia.org]
- 4. Sensitivity Analysis and Model Validation - Secondary Analysis of Electronic Health Records - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 5. deepchecks.com [deepchecks.com]
how to perform a bridging study between an old and new reagent
For researchers, scientists, and professionals in drug development, ensuring the consistency and reliability of assay results is paramount, especially when a new lot or formulation of a critical reagent is introduced. A bridging study is a crucial experiment designed to demonstrate that a new reagent performs equivalently to an old one, ensuring that data generated before and after the change are comparable. This guide provides a comprehensive overview of how to design, execute, and analyze a bridging study.
The Imperative of Bridging Studies
In the lifecycle of an analytical method, changes to reagents are often unavoidable due to factors like supplier discontinuation, cost reduction, or performance improvement.[1] Such changes can introduce variability that may impact the historical data and the established acceptance criteria for a given assay.[1] A bridging study serves to mitigate this risk by providing documented evidence that the new reagent does not adversely affect the assay's performance characteristics.[2][3] Regulatory bodies like the FDA and international guidelines such as ICH M10 emphasize the importance of validating analytical methods, which includes assessing the impact of changes in critical reagents.[4][5][6][7][8]
Key Considerations Before Starting
Before embarking on a bridging study, a thorough risk assessment is recommended to evaluate the potential impact of the reagent change.[1][9] The extent of the study will depend on the criticality of the reagent and the nature of the change. It is also essential to have a well-documented plan or protocol in place before initiating the experiments.[10]
Experimental Protocol: A Step-by-Step Approach
This protocol outlines the key steps for conducting a bridging study between an old and a new reagent.
1. Sample Selection:
-
Number of Samples: A representative set of samples should be selected for the study. Typically, this involves analyzing a minimum of three batches of samples.[11] For clinical trials, a set of 20-50 clinical samples spanning the analytical range is often recommended.[10]
-
Sample Characteristics: The selected samples should cover the entire calibration range of the assay, from the Lower Limit of Quantification (LLOQ) to the Upper Limit of Quantification (ULOQ).[12] It is also advisable to include samples with varying levels of purity, impurities, and potency to challenge the method effectively.[1]
2. Experimental Design:
-
Head-to-Head Comparison: The most effective design is a direct comparison of the old and new reagents in parallel.[3] This involves running the same set of samples with both reagents under the same experimental conditions.
-
Replicate Analysis: Each sample should be analyzed in replicate (minimum of two) with both the old and new reagents to assess precision.[11]
-
Control Samples: Include quality control (QC) samples at multiple concentration levels (low, medium, and high) to monitor the performance of the assay with both reagents.[6]
3. Execution of the Assay:
-
Parallel Testing: To minimize variability, assays with the old and new reagents should be performed on the same day by the same analyst, if possible.[11]
-
Standard Operating Procedures (SOPs): Adhere strictly to the established SOPs for the analytical method, with the only variable being the reagent being tested.
4. Data Analysis and Acceptance Criteria:
-
Statistical Analysis: The data generated from the bridging study should be subjected to statistical analysis to objectively compare the performance of the two reagents. Commonly used statistical methods include Bland-Altman plots, Deming regression, and Passing-Bablok regression.[10]
-
Acceptance Criteria: Pre-defined acceptance criteria are essential for a successful bridging study. These criteria should be based on the established performance of the assay and may include parameters like accuracy, precision, and correlation.[10] If the new reagent fails to meet the acceptance criteria, further investigation is required.
Data Presentation: Summarizing Quantitative Data
All quantitative data from the bridging study should be summarized in clearly structured tables for easy comparison.
| Parameter | Acceptance Criteria | Old Reagent Results | New Reagent Results | Pass/Fail |
| Accuracy | 85-115% recovery for QC samples | |||
| LLOQ QC | 80-120% recovery | |||
| Low QC | 85-115% recovery | |||
| Mid QC | 85-115% recovery | |||
| High QC | 85-115% recovery | |||
| Precision (%CV) | ||||
| Intra-assay | ≤15% | |||
| Inter-assay | ≤20% | |||
| Correlation | ||||
| Correlation Coefficient (r) | ≥0.98 | |||
| Bland-Altman Analysis | ||||
| Mean Difference | Within ±X% of the mean | |||
| Limits of Agreement | Within ±Y% of the mean |
Note: The specific acceptance criteria may vary depending on the assay type and regulatory requirements. These values are provided as a general guideline.
Visualizing the Process
Experimental Workflow for a Reagent Bridging Study
References
- 1. bioprocessintl.com [bioprocessintl.com]
- 2. tandfonline.com [tandfonline.com]
- 3. research.rug.nl [research.rug.nl]
- 4. ICH M10 on bioanalytical method validation - Scientific guideline | European Medicines Agency (EMA) [ema.europa.eu]
- 5. d142khf7ia35oz.cloudfront.net [d142khf7ia35oz.cloudfront.net]
- 6. drugdiscoverytrends.com [drugdiscoverytrends.com]
- 7. ema.europa.eu [ema.europa.eu]
- 8. M10: bioanalytical method validation and study sample analysis : guidance for industry - Digital Collections - National Library of Medicine [collections-us-east-1.awsprod.nlm.nih.gov]
- 9. fda.gov [fda.gov]
- 10. Bridging Studies for Changing Analytical Methods During Trials – Clinical Research Made Simple [clinicalstudies.in]
- 11. extranet.who.int [extranet.who.int]
- 12. database.ich.org [database.ich.org]
A Comparative Analysis of the Physicochemical Properties of Natural versus Synthetic Compounds
In the realm of drug discovery and development, a deep understanding of the physicochemical properties of compounds is paramount. These properties govern a molecule's behavior in biological systems, influencing its absorption, distribution, metabolism, excretion, and toxicity (ADMET) profile. A long-standing debate revolves around the comparative advantages of natural products versus synthetic compounds as starting points for drug design. This guide provides an objective comparison of their physicochemical properties, supported by experimental data and methodologies, to aid researchers in making informed decisions.
Quantitative Comparison of Physicochemical Properties
Natural products and synthetic compounds occupy distinct, albeit sometimes overlapping, regions of chemical space.[1][2] Generally, natural products exhibit greater structural complexity and diversity.[1][3] Synthetic compounds, particularly those in screening libraries, are often designed to adhere to guidelines for oral bioavailability, such as Lipinski's Rule of Five.[1][4] The following table summarizes the key physicochemical differences based on chemoinformatic analyses of large compound databases.
| Physicochemical Property | Natural Products (NPs) & NP-Derived (ND) | Synthetic Drugs (S) & Synthetic Drugs based on NP pharmacophores (S*) | Key Distinctions |
| Molecular Weight (MW) | Generally larger[1] | Generally smaller, often < 500 Da to comply with Lipinski's Rule[4][5] | NPs often have more complex scaffolds, leading to higher molecular weights.[1] |
| Lipophilicity (ALOGP) | Lower hydrophobicity[1] | Higher hydrophobicity, partly due to higher aromatic content[1] | S drugs are, on average, more lipophilic than NPs and NDs.[1] |
| Aqueous Solubility (ALOGpS) | Similar calculated aqueous solubility across classes[1] | Similar calculated aqueous solubility across classes[1] | While calculated values are similar, solubility can be a challenge for highly lipophilic synthetic compounds.[1] |
| Molecular Complexity | Higher, with more complex scaffolds and greater 3D structure[1][3] | Lower, often flatter, more rigid molecules with a high degree of aromatic character[1] | Molecular complexity in NPs has been correlated with biological activity.[1] |
| Stereochemical Content | Higher number of chiral centers[1][6] | Lower stereochemical complexity[1] | The stereochemical richness of NPs contributes to their diverse biological activities. |
| Aromaticity | Lower number of aromatic rings[1][6] | Higher average number of aromatic rings[1] | Synthetic chemistry often favors the incorporation of aromatic rings. |
| Heteroatom Content | More oxygen atoms, fewer nitrogen atoms[1][6] | Fewer oxygen atoms, more nitrogen atoms[1] | This difference in heteroatom distribution influences properties like hydrogen bonding potential. |
| Hydrogen Bond Donors | Generally higher number | Often constrained (e.g., ≤ 5 in Lipinski's Rule)[4][5] | NPs frequently have more hydroxyl and amine groups. |
| Hydrogen Bond Acceptors | Generally higher number | Often constrained (e.g., ≤ 10 in Lipinski's Rule)[4][5] | The higher oxygen content in NPs contributes to more hydrogen bond acceptors. |
| Drug-Likeness Violations | A significant portion of NPs may violate one or more of Lipinski's rules, yet many are successful drugs.[4][7] | High-throughput screening libraries are often filtered to minimize violations.[1] | This highlights that "drug-likeness" rules are guidelines, not absolute laws.[8] |
Experimental Protocols for Determining Key Physicochemical Properties
The accurate determination of physicochemical properties is crucial for understanding and predicting a compound's behavior. Below are detailed methodologies for key experiments.
1. Determination of Lipophilicity (LogP/LogD)
-
Shake-Flask Method (Gold Standard):
-
A solution of the compound is prepared in one of two immiscible solvents (typically n-octanol and water).
-
The two phases are mixed thoroughly in a separatory funnel (shaken) until equilibrium is reached.[9]
-
The mixture is then centrifuged to ensure complete separation of the two phases.[9]
-
The concentration of the compound in each phase is determined using a suitable analytical technique, such as UV-Vis spectroscopy or HPLC.
-
The partition coefficient (P) is calculated as the ratio of the concentration in the organic phase to the concentration in the aqueous phase. LogP is the logarithm of this value. For ionizable compounds, the distribution coefficient (LogD) is measured at a specific pH, usually 7.4.[9][10]
-
-
Reverse-Phase High-Performance Liquid Chromatography (RP-HPLC):
-
A rapid and less material-intensive method that correlates a compound's retention time on a nonpolar stationary phase with its LogP value.
-
A series of standards with known LogP values are injected into the HPLC system to create a calibration curve.
-
The test compound is then injected under the same conditions, and its retention time is measured.
-
The LogP of the test compound is interpolated from the calibration curve.
-
2. Determination of Aqueous Solubility
-
Equilibrium Shake-Flask Method:
-
An excess amount of the solid compound is added to a specific volume of aqueous buffer (e.g., phosphate-buffered saline at pH 7.4).
-
The suspension is agitated at a constant temperature for a sufficient period (e.g., 24-48 hours) to ensure equilibrium is reached.
-
The saturated solution is then filtered to remove any undissolved solid.
-
The concentration of the dissolved compound in the filtrate is quantified using methods like HPLC or UV-Vis spectroscopy.
-
3. Determination of Ionization Constant (pKa)
-
Potentiometric Titration:
-
The compound is dissolved in water or a co-solvent mixture.
-
A standardized solution of acid or base is incrementally added to the solution.
-
The pH of the solution is measured after each addition of the titrant.
-
A titration curve (pH vs. volume of titrant) is plotted. The pKa is the pH at which the compound is 50% ionized, which corresponds to the midpoint of the buffer region in the titration curve.[9]
-
-
UV-Vis Spectrophotometry:
-
This method is suitable for compounds whose UV-Vis absorbance spectrum changes with ionization state.
-
The absorbance of the compound is measured in a series of buffers with different pH values.
-
The changes in absorbance are plotted against pH, and the resulting curve is used to calculate the pKa.
-
Visualizing the Comparison Workflow
The following diagram illustrates a typical workflow for the comparative analysis of the physicochemical properties of natural and synthetic compounds.
Caption: Workflow for comparing physicochemical properties of natural vs. synthetic compounds.
Conclusion
Both natural and synthetic compounds offer unique advantages in drug discovery. Natural products provide unparalleled structural diversity and biological pre-validation, occupying vast regions of chemical space that are often beyond the scope of synthetic libraries.[1][2] However, they can present challenges in terms of synthesis and optimization. Synthetic compounds, on the other hand, offer facile synthesis and modification but tend to occupy a more narrowly defined area of chemical space.[1] By understanding the distinct physicochemical profiles of these two broad classes of molecules, researchers can better leverage their respective strengths to design and develop the next generation of therapeutics. The incorporation of natural product-like features into synthetic molecules is a promising strategy to increase chemical diversity and explore novel biological targets.[1]
References
- 1. Cheminformatic comparison of approved drugs from natural product versus synthetic origins - PMC [pmc.ncbi.nlm.nih.gov]
- 2. scispace.com [scispace.com]
- 3. researchgate.net [researchgate.net]
- 4. Lipinski's rule of five - Wikipedia [en.wikipedia.org]
- 5. Putting the "rule of five" of drug research in context - Mapping Ignorance [mappingignorance.org]
- 6. researchgate.net [researchgate.net]
- 7. taylorandfrancis.com [taylorandfrancis.com]
- 8. sygnaturediscovery.com [sygnaturediscovery.com]
- 9. books.rsc.org [books.rsc.org]
- 10. Physicochemical Properties and Environmental Fate - A Framework to Guide Selection of Chemical Alternatives - NCBI Bookshelf [ncbi.nlm.nih.gov]
A Comparative Guide to the Structural Elucidation of Non-Commercially Available Natural Products
For Researchers, Scientists, and Drug Development Professionals
The unambiguous determination of a novel natural product's chemical structure is a critical step in the drug discovery and development pipeline. This guide provides a comprehensive comparison of the primary analytical techniques and strategies employed to confirm the structure of non-commercially available natural products. It is designed to assist researchers in selecting the most appropriate methodologies, understanding their underlying principles, and effectively interpreting the resulting data.
The initial and crucial phase in the investigation of a natural product extract is dereplication , a process aimed at the rapid identification of known compounds. This step is essential to avoid the time-consuming and resource-intensive process of re-isolating and characterizing previously described molecules. Dereplication is typically achieved by comparing the chromatographic and mass spectrometric data of the extract against comprehensive natural product databases.
Once a potentially novel compound is identified, a combination of spectroscopic and spectrometric techniques is employed for its complete structural elucidation. The following sections provide a detailed comparison of these methods, including their strengths, limitations, and the type of structural information they provide.
Comparison of Key Structural Elucidation Techniques
The table below summarizes the primary analytical techniques used for the structural confirmation of novel natural products.
| Technique | Information Obtained | Sample Amount | Strengths | Limitations |
| Nuclear Magnetic Resonance (NMR) Spectroscopy | Connectivity (¹H-¹H, ¹H-¹³C), stereochemistry, conformation | µg to mg | Provides detailed 2D and 3D structural information; non-destructive. | Relatively low sensitivity; complex spectra for large molecules. |
| High-Resolution Mass Spectrometry (HRMS) | Elemental composition, molecular weight | ng to µg | High sensitivity and accuracy for molecular formula determination. | Provides limited information on stereochemistry and connectivity. |
| X-ray Crystallography | Absolute 3D structure, stereochemistry, bond lengths and angles | µg to mg | Unambiguous determination of the complete 3D structure. | Requires a high-quality single crystal, which can be difficult to obtain. |
| Chiroptical Spectroscopy (ECD/VCD) | Absolute configuration of chiral centers | µg to mg | Sensitive to stereochemistry; can be combined with computational methods. | Requires the presence of a chromophore; interpretation can be complex. |
| Total Synthesis | Unambiguous confirmation of the proposed structure | N/A | The ultimate proof of structure; allows for the synthesis of analogs. | Time-consuming, resource-intensive, and can be very challenging. |
| Computational Chemistry | Predicted spectroscopic data (NMR, ECD), stable conformations | N/A | Complements experimental data; helps to resolve ambiguities. | Accuracy depends on the computational model used; requires expertise. |
Experimental Protocols
This section provides detailed methodologies for the key experiments cited in this guide.
Nuclear Magnetic Resonance (NMR) Spectroscopy
Objective: To determine the covalent structure and relative stereochemistry of a purified natural product.
Methodology: A suite of 1D and 2D NMR experiments is typically required for complete structure elucidation.
1.1. Sample Preparation:
-
Dissolve 1-5 mg of the purified natural product in 0.5-0.6 mL of a deuterated solvent (e.g., CDCl₃, MeOD, DMSO-d₆) in a clean, dry 5 mm NMR tube.
-
Ensure the sample is fully dissolved and the solution is clear. Filter if necessary to remove any particulate matter.
-
For low sample amounts (<1 mg), the use of microprobes (1.7 mm) and cryogenic probes can significantly enhance sensitivity.[1]
1.2. 1D NMR Data Acquisition:
-
Acquire a ¹H NMR spectrum to assess the overall complexity of the molecule and identify proton signals.
-
Acquire a ¹³C NMR spectrum to identify the number and types of carbon atoms. DEPTq, DEPT-135, and DEPT-90 experiments are used to differentiate between CH₃, CH₂, CH, and quaternary carbons.
1.3. 2D NMR Data Acquisition and Processing:
-
COSY (Correlation Spectroscopy): Identifies ¹H-¹H spin-spin coupling networks, revealing proton connectivity within molecular fragments.
-
Acquisition: Use a standard cosygpqf pulse program. Set spectral widths to cover all proton signals. Acquire 256-512 increments in the indirect dimension (F1) with 8-16 scans per increment.
-
Processing: Apply a sine-bell window function in both dimensions and perform a 2D Fourier transform.
-
-
HSQC (Heteronuclear Single Quantum Coherence): Correlates protons with their directly attached carbons.
-
Acquisition: Use a standard hsqcedetgpsisp2.3 pulse program. Set the ¹³C spectral width to cover all carbon signals. Optimize the CNST2 value based on an assumed one-bond ¹JCH coupling constant of ~145 Hz.
-
Processing: Apply a squared sine-bell window function in both dimensions and perform a 2D Fourier transform.
-
-
HMBC (Heteronuclear Multiple Bond Correlation): Reveals long-range correlations between protons and carbons (typically 2-3 bonds), which is crucial for connecting molecular fragments.
-
Acquisition: Use a standard hmbcgplpndqf pulse program. Optimize the long-range coupling delay (d6) for a value of ~8 Hz (corresponding to a delay of ~62.5 ms).
-
Processing: Apply a sine-bell window function in both dimensions and perform a 2D Fourier transform.
-
-
NOESY (Nuclear Overhauser Effect Spectroscopy) or ROESY (Rotating-frame Overhauser Effect Spectroscopy): Identifies protons that are close in space, providing information about the relative stereochemistry and conformation of the molecule.
-
Acquisition: Use a standard noesygpph or roesygpph pulse program. The mixing time (d8) is a critical parameter and should be optimized (typically 200-800 ms (B15284909) for NOESY and 150-300 ms for ROESY).
-
Processing: Apply a sine-bell window function in both dimensions and perform a 2D Fourier transform.
-
High-Resolution Mass Spectrometry (HRMS)
Objective: To determine the elemental composition of the natural product.
Methodology:
-
Sample Preparation: Prepare a dilute solution of the purified compound (typically 1-10 µg/mL) in a suitable solvent (e.g., methanol, acetonitrile).
-
Instrumentation: Use a high-resolution mass spectrometer such as a Time-of-Flight (TOF), Orbitrap, or Fourier Transform Ion Cyclotron Resonance (FT-ICR) instrument.
-
Data Acquisition:
-
Infuse the sample directly or inject it via an HPLC system.
-
Acquire data in full-scan mode with a high resolving power (typically >10,000).[2]
-
Use a soft ionization technique such as Electrospray Ionization (ESI) or Atmospheric Pressure Chemical Ionization (APCI).
-
-
Data Analysis:
-
Determine the accurate mass of the molecular ion ([M+H]⁺, [M-H]⁻, or [M+Na]⁺).
-
Use the accurate mass to calculate the elemental composition using software that considers isotopic abundances. The mass accuracy should ideally be below 5 ppm.[2]
-
X-ray Crystallography
Objective: To obtain an unambiguous three-dimensional structure of the natural product.
Methodology:
-
Crystal Growth: This is often the most challenging step. Grow a single crystal of the purified natural product (ideally 0.1-0.3 mm in all dimensions) by slow evaporation of a solvent, vapor diffusion, or cooling of a saturated solution.[3]
-
Crystal Mounting: Carefully mount a suitable crystal on a goniometer head.
-
Data Collection:
-
Structure Solution and Refinement:
-
Process the diffraction data to obtain a set of structure factors.
-
Solve the phase problem to generate an initial electron density map.
-
Build a molecular model into the electron density map and refine the atomic positions and thermal parameters to obtain the final crystal structure.
-
Computational Chemistry
Objective: To predict spectroscopic properties (NMR, ECD) to aid in structure elucidation and stereochemical assignment.
Methodology:
-
Conformational Search: Generate a set of low-energy conformers of the proposed structure(s) using molecular mechanics (e.g., MMFF) or semi-empirical methods.
-
Geometry Optimization: Optimize the geometry of each conformer using Density Functional Theory (DFT) at a suitable level of theory (e.g., B3LYP/6-31G(d)).[4]
-
Spectroscopic Property Calculation:
-
NMR: Calculate the NMR shielding tensors for each optimized conformer using a DFT method (e.g., GIAO-DFT). Convert the shielding tensors to chemical shifts.
-
ECD: Calculate the electronic circular dichroism (ECD) spectrum for each conformer using time-dependent DFT (TDDFT).[5]
-
-
Data Analysis:
-
Boltzmann-average the calculated spectra of all conformers based on their relative energies.[4]
-
Compare the calculated spectra with the experimental data. For NMR, DP4+ analysis can be used to statistically evaluate the best-fitting diastereomer.
-
Total Synthesis
Objective: To provide the ultimate confirmation of a proposed structure.
Methodology:
-
Retrosynthetic Analysis: Deconstruct the target natural product into simpler, commercially available starting materials. This involves identifying key bond disconnections and strategic transformations.
-
Forward Synthesis: Execute the synthetic plan in the laboratory, step-by-step, to construct the target molecule.
-
Spectroscopic Comparison: Compare the spectroscopic data (NMR, HRMS, etc.) of the synthesized compound with that of the natural product. An exact match confirms the proposed structure.
Data Presentation
Clear and concise presentation of quantitative data is essential for effective communication of structural elucidation results.
Table 1: ¹H and ¹³C NMR Data for [Natural Product Name] in [Solvent]
| Position | δC (ppm), type | δH (ppm), mult. (J in Hz) | COSY Correlations | HMBC Correlations |
| 1 | 35.2, CH₂ | 2.15, m | H-2 | C-2, C-3, C-5, C-10 |
| 2 | 70.8, CH | 4.05, dd (8.5, 4.0) | H-1, H-3 | C-1, C-3, C-4 |
| 3 | 42.1, CH | 2.50, m | H-2, H-4 | C-2, C-4, C-5 |
| ... | ... | ... | ... | ... |
Table 2: HRMS Data for [Natural Product Name]
| Ionization Mode | Adduct | Measured m/z | Calculated m/z | Δ (ppm) | Elemental Composition |
| ESI+ | [M+H]⁺ | 251.1234 | 251.1232 | 0.8 | C₁₅H₁₈O₃ |
| ESI+ | [M+Na]⁺ | 273.1053 | 273.1051 | 0.7 | C₁₅H₁₈NaO₃ |
Visualizations
Diagrams created using Graphviz (DOT language) to illustrate key workflows and relationships.
Caption: Overall workflow for the structural elucidation of a novel natural product.
Caption: Logical flow of NMR experiments for structure determination.
Caption: Decision tree for determining the absolute configuration of a chiral natural product.
References
For researchers and drug development professionals, the discontinuation of a commercial assay kit or the unavailability of a key component presents a significant challenge. This guide provides a framework for validating an alternative, in-house developed protocol against an established method where the original components are no longer accessible. We present a case study on validating a new luminescent kinase assay protocol against a previously used, but now unavailable, commercial kit.
Data Presentation: Comparative Analysis of Assay Performance
The performance of the alternative protocol was rigorously assessed against historical data from the previously used standard method. Key validation parameters are summarized below, demonstrating the alternative protocol's suitability for continued screening efforts.
Table 1: Comparison of Assay Performance Characteristics
| Performance Metric | Standard Method (Historical Data) | Alternative Protocol (Experimental Data) | Acceptance Criteria | Outcome |
| Z'-factor | 0.78 ± 0.05 | 0.82 ± 0.04 | ≥ 0.5 | Pass |
| Signal-to-Background Ratio | 12.5 ± 1.8 | 14.2 ± 2.1 | ≥ 10 | Pass |
| IC50 for Control Inhibitor (Staurosporine) | 25.7 nM ± 3.1 nM | 28.1 nM ± 4.5 nM | Within 2-fold of historical data | Pass |
| Coefficient of Variation (%CV) for Controls | < 10% | < 8% | ≤ 15% | Pass |
| Assay Window | ~10-fold | ~12-fold | ≥ 8-fold | Pass |
Table 2: Specificity Analysis - Activity Against a Panel of Related Kinases
| Kinase Target | Standard Method (Historical % Inhibition @ 1µM) | Alternative Protocol (% Inhibition @ 1µM) |
| Target Kinase A | 95% | 92% |
| Related Kinase B | 22% | 25% |
| Related Kinase C | 15% | 18% |
| Unrelated Kinase D | < 5% | < 5% |
Experimental Protocols
Detailed methodologies for the validation experiments are crucial for reproducibility and demonstrating the robustness of the alternative protocol.
Protocol 1: Determination of Z'-factor and Signal-to-Background Ratio
-
Plate Layout: Designate columns 1 and 2 for maximum signal (positive control: kinase + substrate + ATP, no inhibitor) and columns 23 and 24 for minimum signal (negative control: kinase + substrate, no ATP, no inhibitor).
-
Reagent Preparation: Prepare kinase, substrate, and ATP solutions in the optimized assay buffer.
-
Assay Procedure:
-
Add 5 µL of assay buffer to all wells.
-
Add 5 µL of positive control components to appropriate wells.
-
Add 5 µL of negative control components to appropriate wells.
-
Incubate the plate at room temperature for 60 minutes.
-
Add 10 µL of the luminescent detection reagent to all wells.
-
Incubate for an additional 10 minutes in the dark.
-
-
Data Acquisition: Read the luminescence signal on a compatible plate reader.
-
Calculations:
-
Calculate the mean and standard deviation for both positive (μp, σp) and negative (μn, σn) controls.
-
Z'-factor = 1 - (3σp + 3σn) / |μp - μn|
-
Signal-to-Background = μp / μn
-
Protocol 2: IC50 Determination for Control Inhibitor
-
Inhibitor Preparation: Prepare a 10-point, 3-fold serial dilution of Staurosporine in DMSO, starting from a 100 µM stock.
-
Assay Procedure:
-
Add 100 nL of each inhibitor concentration to triplicate wells.
-
Add 5 µL of kinase solution to all wells and incubate for 15 minutes.
-
Initiate the kinase reaction by adding 5 µL of a substrate/ATP mix.
-
Follow steps 3c-5 from Protocol 1.
-
-
Data Analysis:
-
Normalize the data with respect to positive and negative controls.
-
Fit the dose-response curve using a four-parameter logistic regression model to determine the IC50 value.
-
Mandatory Visualization
Signaling Pathway Diagram
The following diagram illustrates a generic kinase signaling pathway, which is the target for the screening assay.
Safe Handling of Uncharacterized Substances: A Procedural Guide
The handling of any substance with unknown physical, chemical, and toxicological properties necessitates a highly conservative approach to safety.[1] In the absence of specific data, researchers, scientists, and drug development professionals must assume the substance is hazardous.[2][3] This guide provides essential safety protocols, operational plans, and disposal procedures for managing uncharacterized materials in a laboratory setting.
Foundational Principle: Assume High Hazard
When dealing with a novel or unidentified compound, it is crucial to treat it as toxic, irritant, and environmentally harmful until proven otherwise.[2] All laboratory personnel should consider any unknown chemical as highly toxic.[4] This precautionary principle forms the basis of all subsequent safety procedures.
Mandatory Risk Assessment
Before any handling of an uncharacterized substance, a thorough risk assessment is mandatory.[2] This process is critical for identifying potential hazards and implementing appropriate control measures.[2][5]
Experimental Protocol: Risk Assessment for a Novel Compound
-
Information Gathering:
-
Attempt to classify the substance based on its chemical structure or synthesis pathway.[2]
-
Identify any structural alerts that may suggest reactivity, toxicity, or instability.[2]
-
Review available in-silico toxicology predictions or data from analogous compounds.[2]
-
Consult internal chemical inventories to see if the substance can be identified.[6]
-
-
Exposure Assessment:
-
Identify all potential routes of exposure for the planned experiment (e.g., inhalation, dermal contact, ingestion, injection).[2]
-
Determine the quantity of the substance to be used, always opting for the smallest amount necessary.[1]
-
Evaluate the duration and frequency of handling.[2]
-
Consider the physical form of the substance (e.g., fine powder, volatile liquid, gas), as this will influence the risk of exposure.[2]
-
-
Hazard Identification and Control:
Personal Protective Equipment (PPE)
The selection of PPE must be based on the risk assessment.[1] For an unknown substance, a high level of protection is required.[1] It is crucial that PPE is certified, fits correctly, and is suitable for the specific task.[8]
Table 1: Recommended Personal Protective Equipment for Handling Uncharacterized Substances
| PPE Category | Item | Specifications and Use |
|---|---|---|
| Eye and Face Protection | Safety Goggles and Face Shield | Goggles must provide a complete seal around the eyes. A face shield offers an additional layer of protection for the entire face.[1][9] |
| Hand Protection | Double Gloving with Chemically Resistant Gloves | Wear two pairs of gloves. The outer glove should be resistant to a broad range of chemicals (e.g., nitrile or neoprene). The inner glove provides protection if the outer glove is breached.[1] |
| Body Protection | Chemical-Resistant Laboratory Coat or Apron | A lab coat made of a material resistant to chemical penetration is essential to protect the skin.[1][9] |
| Respiratory Protection | Air-Purifying Respirator or Supplied-Air Respirator | A respirator is crucial to prevent inhalation of powders, aerosols, or vapors.[9][10] The choice depends on the risk assessment. For initial entries or high-risk unknowns, a self-contained breathing apparatus (SCBA) may be necessary.[11] |
| Foot Protection | Closed-toe, Chemical-Resistant Shoes | Shoes must completely cover the foot.[12] Steel-toed and shank, chemical-resistant boots are recommended for higher-risk scenarios.[10] |
For a broader understanding, the Occupational Safety and Health Administration (OSHA) categorizes PPE into four levels based on the degree of protection afforded.[10][11]
Table 2: OSHA Personal Protective Equipment (PPE) Levels
| Level | Description | Typical Ensemble |
|---|---|---|
| Level A | Required when the highest level of respiratory, skin, eye, and mucous membrane protection is needed.[10] | Positive-pressure, full-facepiece self-contained breathing apparatus (SCBA) or supplied-air respirator with escape SCBA; Totally encapsulating chemical-protective suit; Inner and outer chemical-resistant gloves; Chemical-resistant, steel-toe and shank boots.[11][13] |
| Level B | Required when the highest level of respiratory protection is needed, but a lesser level of skin protection is required.[13] This is the minimum level recommended for initial site entries until hazards are further identified.[10] | Positive-pressure, full-facepiece SCBA or supplied-air respirator with escape SCBA; Hooded chemical-resistant clothing (e.g., overalls, splash suit); Inner and outer chemical-resistant gloves; Chemical-resistant, steel-toe and shank boots.[11][13] |
| Level C | Required when the airborne substance is known, its concentration is measured, and the criteria for using an air-purifying respirator are met.[10][13] | Full-face or half-mask, air-purifying respirator (NIOSH approved); Hooded chemical-resistant clothing; Inner and outer chemical-resistant gloves; Chemical-resistant, steel-toe and shank boots.[11] |
| Level D | Primarily a work uniform for nuisance contamination only.[10] It should not be worn where respiratory or skin hazards exist.[11] | Coveralls; Safety shoes/boots. Other PPE like gloves and safety glasses are based on the situation.[11][13] |
Operational Plan and Experimental Workflow
A systematic approach is critical to ensure safety.[1] All manipulations of an uncharacterized substance must be performed within a certified chemical fume hood or other containment device like a glove box.[1][3]
Caption: Workflow for safely handling an uncharacterized chemical compound.
Detailed Methodologies: General Handling Protocol
-
Preparation:
-
Ensure safety equipment such as a safety shower, eyewash station, and fire extinguisher are accessible and unobstructed.[1][12]
-
All manipulations must be performed within a certified chemical fume hood to minimize inhalation risk.[1]
-
Use the smallest quantity of the substance necessary for the experiment.[1]
-
When weighing the compound, use disposable equipment and handle with forceps.[1]
-
-
Execution:
-
Cleanup:
Disposal Plan
Proper disposal is crucial to protect human health and the environment.[1] All waste generated from handling an uncharacterized substance must be treated as hazardous waste.[1]
-
Labeling: If a material cannot be identified, it should be considered unknown waste.[6] Label the container with a "Hazardous Waste" or "Waste Chemical" label and identify the material as "unknown".[6][14]
-
Segregation: Segregate waste based on its physical form (solid, liquid, sharp).[1]
-
Contact EHS: Contact your institution's Environmental Health and Safety (EHS) department for guidance on the safe removal and disposal of the material.[6] The chemical waste contractor will typically perform an analysis to determine the hazardous properties of the substance.[6]
-
Prohibited Disposal: Do not pour chemicals down drains or use the sewer for chemical waste disposal.[4]
References
- 1. benchchem.com [benchchem.com]
- 2. benchchem.com [benchchem.com]
- 3. General Lab Safety Rules – Laboratory Safety [wp.stolaf.edu]
- 4. ehs.okstate.edu [ehs.okstate.edu]
- 5. palamatic.com [palamatic.com]
- 6. safety.pitt.edu [safety.pitt.edu]
- 7. worksafe.nt.gov.au [worksafe.nt.gov.au]
- 8. cladsafety.co.uk [cladsafety.co.uk]
- 9. PPE for Chemical Handling: A Quick Guide | Healthy Bean [healthybean.org]
- 10. Personal Protective Equipment (PPE) - CHEMM [chemm.hhs.gov]
- 11. OSHA PPE Levels: Workplace Chemical Exposure Protection — MSC Industrial Supply [mscdirect.com]
- 12. Lab Safety Rules and Guidelines | Lab Manager [labmanager.com]
- 13. epa.gov [epa.gov]
- 14. Unknown Chemicals - Environmental Health and Safety - Purdue University [purdue.edu]
Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Haftungsausschluss und Informationen zu In-Vitro-Forschungsprodukten
Bitte beachten Sie, dass alle Artikel und Produktinformationen, die auf BenchChem präsentiert werden, ausschließlich zu Informationszwecken bestimmt sind. Die auf BenchChem zum Kauf angebotenen Produkte sind speziell für In-vitro-Studien konzipiert, die außerhalb lebender Organismen durchgeführt werden. In-vitro-Studien, abgeleitet von dem lateinischen Begriff "in Glas", beinhalten Experimente, die in kontrollierten Laborumgebungen unter Verwendung von Zellen oder Geweben durchgeführt werden. Es ist wichtig zu beachten, dass diese Produkte nicht als Arzneimittel oder Medikamente eingestuft sind und keine Zulassung der FDA für die Vorbeugung, Behandlung oder Heilung von medizinischen Zuständen, Beschwerden oder Krankheiten erhalten haben. Wir müssen betonen, dass jede Form der körperlichen Einführung dieser Produkte in Menschen oder Tiere gesetzlich strikt untersagt ist. Es ist unerlässlich, sich an diese Richtlinien zu halten, um die Einhaltung rechtlicher und ethischer Standards in Forschung und Experiment zu gewährleisten.
