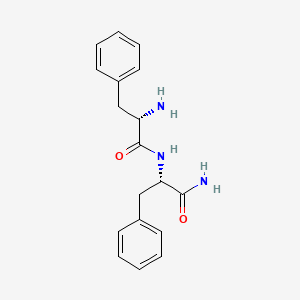
Phenylalanylphenylalanylamide
Beschreibung
Structure
3D Structure
Eigenschaften
CAS-Nummer |
15893-46-6 |
|---|---|
Molekularformel |
C18H21N3O2 |
Molekulargewicht |
311.4 g/mol |
IUPAC-Name |
2-amino-N-(1-amino-1-oxo-3-phenylpropan-2-yl)-3-phenylpropanamide |
InChI |
InChI=1S/C18H21N3O2/c19-15(11-13-7-3-1-4-8-13)18(23)21-16(17(20)22)12-14-9-5-2-6-10-14/h1-10,15-16H,11-12,19H2,(H2,20,22)(H,21,23) |
InChI-Schlüssel |
XXPXQEQOAZMUDD-UHFFFAOYSA-N |
SMILES |
C1=CC=C(C=C1)CC(C(=O)NC(CC2=CC=CC=C2)C(=O)N)N |
Isomerische SMILES |
C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)N)N |
Kanonische SMILES |
C1=CC=C(C=C1)CC(C(=O)NC(CC2=CC=CC=C2)C(=O)N)N |
Aussehen |
Solid powder |
Reinheit |
>98% (or refer to the Certificate of Analysis) |
Haltbarkeit |
>3 years if stored properly |
Löslichkeit |
Soluble in DMSO |
Lagerung |
Dry, dark and at 0 - 4 C for short term (days to weeks) or -20 C for long term (months to years). |
Synonyme |
L-Phe-L-Phe-amide L-phenylalanine-L-phenylalanylamide Phe-Phe-amide phenylalanylphenylalanylamide |
Herkunft des Produkts |
United States |
Biochemical and Mechanistic Investigations of Phenylalanylphenylalanylamide
Enzymatic Interactions and Degradation Pathways
The metabolic fate of Phenylalanylphenylalanylamide is primarily dictated by the action of peptidases, enzymes that catalyze the cleavage of peptide bonds. The stability and breakdown of this dipeptide amide are influenced by the types of peptidases present, the mechanism of their action, and various environmental factors.
Identification and Characterization of Peptidases Acting on Dipeptides
Peptidases are broadly classified as endopeptidases, which cleave internal peptide bonds, and exopeptidases, which act on the terminal amino acids. As this compound is a dipeptide, its degradation is primarily mediated by exopeptidases. These are further categorized into aminopeptidases, which cleave the N-terminal amino acid, and carboxypeptidases, which remove the C-terminal amino acid.
Several peptidases exhibit broad specificity and can hydrolyze a variety of dipeptides. Aminopeptidases, in particular, are known to act on dipeptides with hydrophobic residues. Given the presence of two phenylalanine residues, this compound is a potential substrate for aminopeptidases that show a preference for bulky, aromatic side chains. The amide group at the C-terminus may influence the binding and catalytic efficiency of certain peptidases.
Table 1: General Classes of Peptidases and Their Potential Action on Dipeptides
| Peptidase Class | Site of Action | Potential for this compound Degradation |
| Aminopeptidases | N-terminus | High, especially for those with specificity for hydrophobic residues. |
| Carboxypeptidases | C-terminus | Lower, as the C-terminal carboxyl group is amidated. |
| Dipeptidyl Peptidases | N-terminus (cleave dipeptides) | Dependent on specific enzyme substrate requirements. |
| Dipeptidases | Hydrolyze dipeptides | High, as these enzymes are specialized for dipeptide cleavage. |
Mechanisms of Proteolytic Cleavage (e.g., N-terminal degradation by Dipeptidyl Peptidase IV)
The mechanism of proteolytic cleavage involves a nucleophilic attack on the carbonyl carbon of the peptide bond. For serine proteases like Dipeptidyl Peptidase IV (DPP-IV), a catalytic triad (B1167595) of serine, histidine, and aspartate is typically involved in this process.
DPP-IV is a serine exopeptidase that specifically cleaves dipeptides from the N-terminus of polypeptides, but its primary substrates are those with a proline or alanine (B10760859) residue in the penultimate (P1) position. The substrate specificity of DPP-IV is a critical determinant of its activity. While it shows a strong preference for proline and alanine, it can cleave peptides with other amino acids in the P1 position, albeit with much lower efficiency.
The degradation of this compound by DPP-IV would be atypical. The presence of a phenylalanine residue instead of proline or alanine at the N-terminus would likely result in a significantly lower rate of cleavage, if any. The efficiency of DPP-IV is highly dependent on the interaction of the substrate's N-terminal residues with the enzyme's active site.
Factors Influencing Enzymatic Hydrolysis Rates
The rate of enzymatic hydrolysis of this compound is subject to several influencing factors that are common to most enzyme-catalyzed reactions. These include:
Enzyme Concentration: A higher concentration of the appropriate peptidase will lead to a faster rate of hydrolysis, assuming the substrate is not limiting.
Substrate Concentration: The reaction rate increases with substrate concentration until the enzyme becomes saturated.
Temperature: Enzymatic activity generally increases with temperature up to an optimal point, beyond which the enzyme denatures and loses activity.
pH: Each peptidase has an optimal pH range for its activity. Deviations from this range can alter the ionization states of amino acid residues in the active site and the substrate, thereby affecting binding and catalysis.
Presence of Inhibitors: Various molecules can inhibit peptidase activity, either competitively, non-competitively, or uncompetitively, thus reducing the rate of hydrolysis.
Table 2: Key Factors Affecting the Rate of Enzymatic Hydrolysis
| Factor | Effect on Hydrolysis Rate |
| Enzyme Concentration | Directly proportional (under non-saturating substrate conditions). |
| Substrate Concentration | Increases until enzyme saturation is reached (Michaelis-Menten kinetics). |
| Temperature | Increases to an optimum, then decreases due to denaturation. |
| pH | Optimal activity within a narrow range; activity decreases outside this range. |
| Inhibitors | Decrease the rate of hydrolysis. |
Molecular Recognition and Ligand-Receptor Binding Mechanisms
Beyond enzymatic degradation, dipeptides and their analogs can interact with various cellular receptors, modulating their activity. The potential interaction of this compound with the sigma receptor system is of particular interest.
Elucidation of Binding Sites and Affinities (e.g., Sigma Receptor System)
The sigma receptors, which include the sigma-1 and sigma-2 subtypes, are intracellular proteins primarily located at the endoplasmic reticulum. They are known to bind a wide variety of structurally diverse ligands and are implicated in numerous cellular functions and pathological conditions, including psychiatric and movement disorders, cancer, and neuroprotection.
The binding of ligands to sigma receptors is characterized by specific pharmacophores. For the sigma-1 receptor, high-affinity binding often requires a nitrogen atom that is protonated at physiological pH. While endogenous ligands for sigma receptors have not been definitively identified, various synthetic compounds and some endogenous molecules show affinity for these receptors.
The structure of this compound, with its two phenyl rings and a terminal amide, possesses features that could potentially allow for interaction with the binding sites of sigma receptors. The aromatic rings could engage in hydrophobic interactions within the receptor's binding pocket. However, without experimental data, the affinity and selectivity of this compound for sigma receptor subtypes remain speculative.
Modulatory Effects on Cellular and Sub-Cellular Components
The binding of a ligand to a sigma receptor can modulate the function of the receptor, which in turn can affect various cellular processes. The sigma-1 receptor, for instance, acts as a molecular chaperone and can influence ion channel function, calcium signaling, and the activity of other signaling proteins.
If this compound were to bind to the sigma-1 receptor, it could potentially act as an agonist or an antagonist, leading to a cascade of downstream effects. These could include alterations in cellular proliferation, apoptosis, and neuronal activity. The specific modulatory effects would depend on the nature of the interaction and the cellular context. For example, some sigma receptor ligands have been shown to influence the expression and activity of proteins involved in cholesterol biosynthesis and secretion.
Impact on Ion Channels (e.g., Acid-Sensing Ion Channels)
There is no available research specifically investigating the impact of this compound on ion channels, including acid-sensing ion channels (ASICs). While ASICs are recognized as important therapeutic targets for various neurological conditions due to their role in detecting changes in extracellular pH, the modulatory effects of this compound on these channels have not been documented in the scientific literature reviewed.
Regulation of Kinase Phosphorylation Cascades (e.g., ERK1/ERK2)
The influence of this compound on kinase phosphorylation cascades, such as the ERK1/ERK2 pathway, remains uncharacterized. The ERK1/ERK2 signaling cascade is a crucial pathway involved in cell proliferation, differentiation, and survival. However, no studies were identified that specifically examined the regulatory effects of this compound on this or other related kinase pathways.
Mechanisms of Antioxidant and Radical Scavenging Activities
While peptides and amino acid derivatives can possess antioxidant properties, the specific mechanisms for this compound are not detailed in the current body of scientific research.
Inhibition of Oxidative Reactions
There is a lack of specific studies detailing the capacity of this compound to inhibit oxidative reactions. The ability of a compound to act as an antioxidant is often attributed to its chemical structure, which may allow it to donate electrons or hydrogen atoms to neutralize free radicals. Without experimental data, the specific inhibitory effects of this compound on oxidative processes cannot be confirmed.
Chelation of Metal Ions
The potential for this compound to chelate metal ions has not been specifically investigated. Metal ion chelation is a known mechanism of antioxidant activity, as it can prevent metal ions from participating in redox reactions that generate free radicals. However, no data is available to suggest or confirm this activity for this compound.
Advanced Analytical Techniques for the Characterization and Quantitation of Phenylalanylphenylalanylamide
Chromatographic Separation Methodologies
Chromatographic techniques are fundamental for the separation of Phenylalanylphenylalanylamide from impurities and for the assessment of its purity. The choice of method depends on the specific analytical goal, such as purity determination, structural confirmation, or enantiomeric separation.
High-Performance Liquid Chromatography (HPLC) is a cornerstone technique for the analysis of peptides like this compound. The primary modes of HPLC utilized for peptide separations are reversed-phase (RP-HPLC), ion-exchange (IEX), and size-exclusion chromatography (SEC).
Reversed-Phase HPLC (RP-HPLC): This is the most common HPLC mode for peptide analysis. It separates molecules based on their hydrophobicity. Given that this compound is composed of two hydrophobic phenylalanine residues, it exhibits strong retention on nonpolar stationary phases (e.g., C18). A typical mobile phase consists of an aqueous component with an ion-pairing agent like trifluoroacetic acid (TFA) and an organic modifier such as acetonitrile. The peptide is eluted by a gradient of increasing organic solvent concentration. The purity of this compound can be determined by integrating the peak area of the main compound and any impurities detected, typically by UV absorbance at 210-220 nm, which corresponds to the peptide bond.
Ion-Exchange Chromatography (IEX): This technique separates molecules based on their net charge. The separation mechanism in IEX is based on the electrostatic interactions between the charged peptide and the charged stationary phase. The retention of peptides is influenced by the pH and ionic strength of the mobile phase. For this compound, which has a primary amide at the C-terminus and a free amino group at the N-terminus, its net charge will be pH-dependent. Cation-exchange chromatography can be employed at a pH where the N-terminal amine is protonated, leading to a net positive charge. Elution is typically achieved by increasing the salt concentration or changing the pH of the mobile phase.
Size-Exclusion Chromatography (SEC): SEC separates molecules based on their hydrodynamic volume. This technique is particularly useful for detecting aggregates of this compound. The separation is achieved by the differential permeation of molecules into the pores of the stationary phase. Larger molecules (aggregates) are excluded from the pores and elute earlier, while smaller molecules (the monomeric peptide) can penetrate the pores and have a longer retention time.
A summary of typical HPLC conditions for peptide analysis is presented in the table below.
| HPLC Mode | Stationary Phase | Mobile Phase A | Mobile Phase B | Elution | Detection |
| RP-HPLC | C18, C8 | 0.1% TFA in Water | 0.1% TFA in Acetonitrile | Gradient | UV (210-220 nm) |
| IEX | Strong Cation Exchange (SCX) | Low salt buffer (e.g., 20 mM Phosphate) | High salt buffer (e.g., 1 M NaCl in buffer) | Salt Gradient | UV (210-220 nm) |
| SEC | Silica-based with hydrophilic coating | Isocratic buffer (e.g., Phosphate buffered saline) | - | Isocratic | UV (210-220 nm) |
Gas Chromatography-Mass Spectrometry (GC-MS) is a powerful technique for the analysis of volatile and thermally stable compounds. However, peptides like this compound are non-volatile due to their polar nature and the presence of hydrogen-bonding functional groups. Therefore, derivatization is a mandatory step to increase their volatility and thermal stability for GC-MS analysis.
A common derivatization strategy for peptides is silylation, which involves replacing the active hydrogens in the amino and amide groups with trimethylsilyl (B98337) (TMS) groups. Reagents such as N,O-bis(trimethylsilyl)trifluoroacetamide (BSTFA) or N-methyl-N-(trimethylsilyl)trifluoroacetamide (MSTFA) are frequently used. The resulting TMS derivatives are more volatile and less polar, making them amenable to GC separation.
Once derivatized, the sample is introduced into the GC, where it is separated based on its boiling point and interaction with the stationary phase. The separated components then enter the mass spectrometer, which provides information about their mass-to-charge ratio, allowing for identification. The mass spectrum of a trimethylsilylated dipeptide typically shows characteristic fragmentation patterns, including ions resulting from the cleavage of the peptide bond, which can be used to confirm the amino acid sequence.
A general workflow for the GC-MS analysis of this compound is outlined below.
| Step | Procedure | Purpose |
| 1. Derivatization | Reaction with a silylating agent (e.g., BSTFA in acetonitrile). | Increase volatility and thermal stability. |
| 2. GC Separation | Injection onto a GC column (e.g., OV-1) with a temperature program. | Separate the derivatized peptide from other components. |
| 3. MS Detection | Electron ionization (EI) followed by mass analysis. | Generate a mass spectrum for identification and structural information. |
Liquid Chromatography-Tandem Mass Spectrometry (LC-MS/MS) is an exceptionally sensitive and specific technique for the analysis of peptides. It combines the separation power of HPLC with the mass analysis capabilities of tandem mass spectrometry. This technique is invaluable for both the structural confirmation and quantitative analysis of this compound.
For structural confirmation, the peptide is first separated by RP-HPLC and then introduced into the mass spectrometer, typically using an electrospray ionization (ESI) source. In the first stage of mass analysis (MS1), the protonated molecule (precursor ion) of this compound is selected. This precursor ion is then subjected to collision-induced dissociation (CID), where it fragments in a predictable manner. The resulting product ions are analyzed in the second stage of mass analysis (MS2). The fragmentation of peptides primarily occurs at the peptide bond, producing b- and y-ions. The masses of these fragment ions can be used to deduce the amino acid sequence and confirm the structure of this compound.
For quantitative analysis, a highly selective and sensitive technique called Multiple Reaction Monitoring (MRM) is often employed. In MRM, specific precursor-to-product ion transitions for this compound are monitored. This involves selecting the precursor ion in the first quadrupole, fragmenting it in the collision cell, and then selecting a specific product ion in the third quadrupole. By monitoring these specific transitions, the instrument can quantify the amount of this compound with high precision and accuracy, even in complex matrices.
The table below summarizes key parameters in an LC-MS/MS analysis of a dipeptide like this compound.
| Parameter | Description |
| Ionization Mode | Electrospray Ionization (ESI), positive ion mode |
| Precursor Ion (MS1) | [M+H]⁺ |
| Fragmentation Method | Collision-Induced Dissociation (CID) |
| Product Ions (MS2) | b- and y-ions resulting from peptide bond cleavage |
| Quantitation Mode | Multiple Reaction Monitoring (MRM) |
Supercritical Fluid Chromatography (SFC) is a powerful technique for the separation of chiral compounds and is particularly well-suited for determining the enantiomeric purity of this compound. SFC uses a supercritical fluid, most commonly carbon dioxide, as the mobile phase, often with a small amount of an organic modifier like methanol. This mobile phase has low viscosity and high diffusivity, which can lead to faster and more efficient separations compared to HPLC.
The enantiomeric separation of this compound is achieved using a chiral stationary phase (CSP). CSPs are designed to have stereospecific interactions with the enantiomers, leading to different retention times. Polysaccharide-based CSPs (e.g., cellulose (B213188) or amylose (B160209) derivatives) are widely used for the chiral separation of a broad range of compounds, including peptides.
By analyzing a sample of this compound on an appropriate chiral SFC system, it is possible to separate and quantify the different stereoisomers (e.g., L-Phe-L-Phe-NH₂, D-Phe-L-Phe-NH₂, L-Phe-D-Phe-NH₂, and D-Phe-D-Phe-NH₂). This is crucial for ensuring the stereochemical integrity of the compound.
The table below outlines typical conditions for chiral SFC analysis.
| Parameter | Condition |
| Mobile Phase | Supercritical CO₂ with an organic modifier (e.g., Methanol) |
| Stationary Phase | Chiral Stationary Phase (e.g., polysaccharide-based) |
| Temperature | Typically 30-40 °C |
| Backpressure | Typically 100-200 bar |
| Detection | UV or Mass Spectrometry |
Spectroscopic Characterization Techniques
Spectroscopic techniques are essential for the detailed structural elucidation of this compound, providing information about the connectivity of atoms and the three-dimensional structure of the molecule.
Nuclear Magnetic Resonance (NMR) spectroscopy is arguably the most powerful technique for the complete structural elucidation of organic molecules in solution. Both one-dimensional (1D) and two-dimensional (2D) NMR experiments are employed to unambiguously assign all the proton (¹H) and carbon (¹³C) signals in the this compound molecule.
¹H NMR: The ¹H NMR spectrum provides information about the chemical environment of each proton in the molecule. The chemical shift (δ) of a proton is influenced by the electron density around it. For this compound, distinct signals are expected for the aromatic protons of the two phenylalanine residues, the α-protons, the β-protons, and the amide protons. The integration of the signals corresponds to the number of protons, and the splitting pattern (multiplicity) provides information about the number of neighboring protons.
¹³C NMR: The ¹³C NMR spectrum provides information about the carbon skeleton of the molecule. Each unique carbon atom in this compound will give a distinct signal. The chemical shifts of the carbon atoms are indicative of their chemical environment (e.g., aromatic, aliphatic, carbonyl).
2D NMR: Two-dimensional NMR experiments, such as COSY (Correlation Spectroscopy), HSQC (Heteronuclear Single Quantum Coherence), and HMBC (Heteronuclear Multiple Bond Correlation), are used to establish the connectivity between atoms.
COSY spectra show correlations between protons that are coupled to each other, helping to identify adjacent protons within the same amino acid residue.
HSQC spectra show correlations between protons and the carbon atoms to which they are directly attached.
HMBC spectra reveal correlations between protons and carbons that are separated by two or three bonds, which is crucial for establishing the connectivity between the two phenylalanine residues and the C-terminal amide.
The following table provides representative ¹H and ¹³C NMR chemical shifts for a dipeptide with two phenylalanine residues, based on data from closely related compounds.
| Atom | ¹H Chemical Shift (ppm) | ¹³C Chemical Shift (ppm) |
| N-terminal α-CH | ~4.0 - 4.2 | ~55 - 57 |
| N-terminal β-CH₂ | ~2.9 - 3.2 | ~38 - 40 |
| N-terminal Aromatic CH | ~7.2 - 7.4 | ~127 - 130 |
| N-terminal Aromatic C (quaternary) | - | ~136 - 138 |
| Amide NH | ~8.0 - 8.3 | - |
| C-terminal α-CH | ~4.5 - 4.7 | ~54 - 56 |
| C-terminal β-CH₂ | ~3.0 - 3.3 | ~37 - 39 |
| C-terminal Aromatic CH | ~7.1 - 7.3 | ~126 - 129 |
| C-terminal Aromatic C (quaternary) | - | ~135 - 137 |
| Peptide C=O | - | ~170 - 173 |
| Amide C=O | - | ~174 - 176 |
| Amide NH₂ | ~7.0 - 7.5 | - |
Mass Spectrometry (MS) and Time-of-Flight Mass Spectrometry (TOF-MS) for Molecular Weight and Fragmentation Analysis
Mass spectrometry (MS) is an indispensable tool for the precise determination of the molecular weight of this compound and for elucidating its structure through fragmentation analysis. Time-of-Flight Mass Spectrometry (TOF-MS), a specific type of MS, is particularly advantageous due to its high sensitivity and the ability to analyze all ions produced simultaneously.
In a typical MS analysis of this compound, the molecule is first ionized, often using techniques like electrospray ionization (ESI) or matrix-assisted laser desorption/ionization (MALDI). The resulting ions are then separated based on their mass-to-charge ratio (m/z), allowing for the accurate determination of the molecular weight.
Tandem mass spectrometry (MS/MS) is employed to induce fragmentation of the parent ion, providing valuable structural information. The fragmentation patterns of peptides are well-characterized and can be used to confirm the amino acid sequence. For this compound, characteristic fragmentation pathways are expected based on its dipeptide structure containing two phenylalanine residues. Key fragmentation patterns for peptides containing phenylalanine include:
C-terminal Phenylalanine: A significant fragmentation pathway often involves the neutral loss of cinnamic acid.
N-terminal Phenylalanine: Common fragmentation includes the elimination of toluene (B28343) (C7H8) and the formation of a benzyl (B1604629) anion.
The analysis of these fragment ions allows for the unambiguous identification of this compound. TOF-MS analyzers are particularly well-suited for this as they provide high-resolution mass data for both the precursor and fragment ions.
| Ion Type | Description | Expected m/z for this compound |
| [M+H]+ | Protonated molecular ion | 312.16 |
| b-ions | Fragments containing the N-terminus | b1: 120.08, b2: 267.14 |
| y-ions | Fragments containing the C-terminus | y1: 147.09, y2: 294.15 |
| Iminium ions | Characteristic fragment of the amino acid side chain | Phenylalanine iminium ion: 120.08 |
Note: The exact m/z values may vary slightly depending on the ionization method and instrument calibration.
Fourier Transform Infrared (FTIR) Spectroscopy for Functional Group Analysis and Secondary Structure
Fourier Transform Infrared (FTIR) spectroscopy is a powerful non-destructive technique used to identify the functional groups present in this compound and to gain insights into its secondary structure. The infrared spectrum of the dipeptide amide will exhibit characteristic absorption bands corresponding to the vibrations of its constituent chemical bonds.
The most informative regions in the FTIR spectrum of this compound are the amide bands, which arise from the vibrations of the peptide bond:
Amide I Band (1600-1700 cm⁻¹): This band is primarily due to the C=O stretching vibration of the amide group. Its position is sensitive to the secondary structure of the peptide.
Amide II Band (1500-1600 cm⁻¹): This band originates from the in-plane N-H bending and C-N stretching vibrations.
Amide III Band (1200-1300 cm⁻¹): This is a more complex band resulting from a mixture of C-N stretching, N-H bending, and other vibrations.
The presence and positions of these amide bands in the FTIR spectrum confirm the peptide nature of this compound. Furthermore, the aromatic C-H stretching and bending vibrations from the two phenylalanine residues will also be observable.
| Vibrational Mode | Functional Group | **Typical Wavenumber Range (cm⁻¹) ** |
| N-H Stretching | Amide | 3200-3400 |
| C-H Stretching (aromatic) | Phenyl ring | 3000-3100 |
| C=O Stretching (Amide I) | Amide | 1600-1700 |
| N-H Bending (Amide II) | Amide | 1500-1600 |
| C-N Stretching (Amide III) | Amide | 1200-1300 |
| C-H Bending (aromatic) | Phenyl ring | 690-900 |
Ultraviolet-Visible (UV-Vis) Spectroscopy for Monitoring Reactions and Concentration
Ultraviolet-Visible (UV-Vis) spectroscopy is a straightforward and widely used technique for the quantification of peptides and for monitoring chemical reactions involving them. This compound possesses two primary chromophores that absorb in the UV region: the peptide bond and the aromatic side chains of the phenylalanine residues.
The peptide backbone exhibits a strong absorbance in the far-UV region, typically around 190-220 nm. The aromatic rings of the two phenylalanine residues give rise to a distinct absorption maximum at approximately 257 nm. This latter absorbance is particularly useful for concentration determination due to its specificity and lower interference from other components in a solution compared to the far-UV region.
The Beer-Lambert law (A = εbc) forms the basis for quantitative analysis, where A is the absorbance, ε is the molar absorptivity (a constant for a given substance at a specific wavelength), b is the path length of the cuvette, and c is the concentration of the substance. By measuring the absorbance of a this compound solution at 257 nm, its concentration can be accurately determined.
| Chromophore | Wavelength Range (nm) | Application |
| Peptide Bond | 190-220 | General peptide detection |
| Phenylalanine Side Chain | ~257 | Specific quantification of this compound |
Bioanalytical Methodologies for Peptide Detection in Research Models
The detection and quantification of this compound in complex biological matrices, such as brain tissue or plasma, require highly sensitive and selective bioanalytical methods. These methods are crucial for studying its pharmacokinetic and pharmacodynamic properties in research models.
One of the most powerful techniques for this purpose is microdialysis coupled with liquid chromatography-tandem mass spectrometry (LC-MS/MS) . Microdialysis allows for the in vivo sampling of the extracellular fluid in a specific tissue, such as the brain. The collected dialysate, containing the analyte of interest, is then analyzed by LC-MS/MS. This approach offers high specificity and sensitivity, enabling the measurement of low concentrations of neuropeptides and their metabolites.
Due to the often low concentrations of peptides in biological samples, derivatization techniques are sometimes employed to enhance their detection. For instance, pre-column derivatization with a fluorescent tag, such as 6-aminoquinolyl-N-hydroxysuccinimudyl carbamate (B1207046) (AQC) or 4-fluoro-7-nitro-2,1,3-benzoxadiazole (NBD-F) , can significantly improve the sensitivity of detection by high-performance liquid chromatography (HPLC) with a fluorescence detector.
Immunoassays , such as the Enzyme-Linked Immunosorbent Assay (ELISA), represent another potential approach for the detection of this compound. However, the development of a specific antibody to a small peptide can be challenging. This often requires the covalent immobilization of the peptide to a carrier protein to elicit a sufficient immune response.
| Methodology | Principle | Advantages | Considerations |
| Microdialysis with LC-MS/MS | In vivo sampling followed by highly selective and sensitive mass spectrometric detection. | High specificity and sensitivity, allows for in vivo monitoring. | Technically demanding, potential for low recovery through the dialysis probe. |
| HPLC with Fluorescence Detection | Chromatographic separation followed by sensitive detection of a fluorescently labeled peptide. | High sensitivity, relatively lower cost than MS. | Requires a derivatization step which can add complexity. |
| Immunoassay (ELISA) | Specific antibody-antigen binding for detection. | High throughput, can be very sensitive. | Development of specific antibodies to small peptides can be difficult. |
Computational Approaches and Molecular Modeling Studies of Phenylalanylphenylalanylamide
Molecular Docking for Ligand-Target Interaction Prediction
Molecular docking is a computational technique used to predict the preferred orientation of one molecule to a second when bound to each other to form a stable complex. This method is instrumental in drug discovery and understanding enzymatic mechanisms.
The identification of potential binding pockets on a target protein is the first step in molecular docking. These pockets are typically indentations on the protein surface with appropriate size, shape, and chemical characteristics to accommodate a ligand. For a dipeptide like Phenylalanylphenylalanylamide, with its aromatic side chains, binding pockets are likely to feature hydrophobic residues that can engage in π-π stacking or hydrophobic interactions.
While specific binding pockets for this compound have not been characterized, studies on similar dipeptides targeting enzymes like Angiotensin-Converting Enzyme (ACE) have identified key interaction sites. For instance, in the docking analysis of the Phe-Tyr dipeptide with ACE, the binding pocket was found to involve interactions with specific amino acid residues of the enzyme researchgate.net. The prediction of binding pockets can be performed using various algorithms that analyze the protein's surface topology and physicochemical properties.
Table 1: Hypothetical Binding Pocket Residues for this compound on a Generic Peptidase
| Residue Type | Potential Interacting Residues | Interaction Type |
| Hydrophobic | Trp, Tyr, Phe, Leu, Val | π-π stacking, Hydrophobic |
| Polar | Ser, Thr, Asn, Gln | Hydrogen bonding |
| Charged | Asp, Glu, Arg, Lys | Electrostatic interactions |
This table is illustrative and based on general principles of peptide-protein interactions. The actual residues would depend on the specific target protein.
Scoring functions are mathematical models used to approximate the binding affinity between a ligand and a protein. They are a critical component of docking algorithms, as they rank different binding poses. The choice of scoring function and docking algorithm can significantly impact the accuracy of the prediction.
In studies involving dipeptides, various docking programs and scoring functions are employed. For example, in the study of hypotensive peptides, the binding energies were calculated to assess the inhibitory potential against ACE and renin nih.gov. The binding energy, typically expressed in kcal/mol or kJ/mol, provides a quantitative measure of the binding affinity, with lower (more negative) values indicating stronger binding.
Table 2: Example of Docking Scores for Dipeptides against a Target Protein
| Dipeptide | Docking Score (kcal/mol) | Predicted Binding Affinity |
| Phe-Phe | -7.5 | High |
| Phe-Tyr | -7.2 | High |
| Gly-Phe | -6.1 | Moderate |
| Ala-Ala | -4.5 | Low |
These values are hypothetical and serve to illustrate the output of a typical docking study.
The evaluation of a docking protocol often involves comparing the predicted binding mode to an experimentally determined structure (if available) and assessing the ability of the scoring function to enrich known binders from a set of non-binders.
Molecular Dynamics (MD) Simulations for Conformational Analysis and Binding Dynamics
Molecular dynamics simulations provide a detailed view of the conformational changes and dynamics of molecules over time. For a flexible molecule like this compound, MD simulations can reveal its preferred shapes and how it interacts with its environment.
An MD simulation generates a trajectory, which is a series of snapshots of the molecule's atomic coordinates over time. Analysis of this trajectory allows for the exploration of the molecule's conformational landscape. For dipeptides containing phenylalanine, simulations have been used to study their self-assembly into nanostructures, a process highly dependent on their conformational preferences nih.gov.
The conformational landscape can be visualized using techniques like Ramachandran plots for the backbone dihedral angles (phi and psi) or by clustering the trajectory to identify the most populated conformational states. Studies on phenylalanine dipeptides have shown that they can adopt various conformations, including extended β-strand and turn-like structures nih.gov.
Table 3: Representative Conformational States of a Phe-Phe Dipeptide from MD Simulations
| Conformer Cluster | Population (%) | Key Dihedral Angles (φ, ψ) | Predominant Secondary Structure |
| 1 | 45 | (~-120°, ~+120°) | Extended (β-sheet like) |
| 2 | 30 | (~-60°, ~-40°) | Turn-like |
| 3 | 15 | (~+60°, ~+60°) | Other |
| 4 | 10 | Various | Random coil |
This table represents a hypothetical distribution of conformations for a Phe-Phe dipeptide in solution.
The Solvent Accessible Surface Area (SASA) is the surface area of a molecule that is accessible to a solvent. It is a useful parameter for understanding a molecule's solubility and its interactions with the surrounding environment. In MD simulations, SASA can be calculated for each frame of the trajectory to monitor changes in solvent exposure.
For peptides, SASA is often analyzed on a per-residue basis to identify which parts of the molecule are buried and which are exposed. The hydrophobic phenylalanine residues in this compound would be expected to have a lower SASA in an aggregated state compared to a monomeric state in an aqueous solution. Studies on protein residues have established standard values for the maximum possible solvent accessible surface area (MaxASA), which can be used to calculate the relative accessible surface area (RSA) wikipedia.org. The analysis of SASA has been used to understand the modification of phenylalanine residues in proteins researchgate.net.
Table 4: Theoretical Maximum and Average Solvent Accessible Surface Area (SASA) for Phenylalanine
| Parameter | Value (Ų) | Reference |
| MaxASA (Theoretical) | 240.0 | Tien et al. 2013 wikipedia.org |
| MaxASA (Empirical) | 228.0 | Tien et al. 2013 wikipedia.org |
| Average SASA in Folded Proteins | Varies | nih.gov |
For a dipeptide like this compound, Rg would be expected to fluctuate as the molecule explores different conformations. In simulations of peptide self-assembly, a decrease in the average Rg of the system can indicate the formation of aggregates. While specific Rg values for this compound are not available, simulations of other peptides provide insight into typical values and their interpretation.
Table 5: Hypothetical Radius of Gyration (Rg) for this compound in Different States
| State | Average Rg (nm) | Interpretation |
| Monomer in solution | 0.45 ± 0.05 | Extended conformation |
| Dimer in solution | 0.60 ± 0.07 | Less compact than two separate monomers |
| Within an aggregate | 0.40 ± 0.03 | Compact conformation |
These values are illustrative and would depend on the specific simulation conditions.
Binding Free Energy Calculations (e.g., MM/GBSA)
Understanding the binding affinity of this compound to a biological target, such as a receptor or an enzyme, is fundamental to elucidating its potential biological role. Molecular Mechanics/Generalized Born Surface Area (MM/GBSA) is a popular computational method used to estimate the free energy of binding of a ligand to a macromolecule. This method offers a balance between accuracy and computational cost, making it a valuable tool in drug discovery and molecular biology.
The MM/GBSA approach calculates the binding free energy (ΔG_bind) by combining molecular mechanics (MM) energy calculations with continuum solvation models. The binding free energy is typically decomposed into several components:
ΔE_MM (Molecular Mechanics Energy): This term represents the change in the internal energy of the system upon binding and includes contributions from bonded (bond, angle, and dihedral) and non-bonded (van der Waals and electrostatic) interactions.
ΔG_solv (Solvation Free Energy): This term accounts for the energy change associated with solvating the molecule in a continuum solvent model. It is further divided into a polar component (ΔG_GB), calculated using the Generalized Born (GB) model, and a non-polar component (ΔG_SA), which is proportional to the change in the solvent-accessible surface area (SASA).
-TΔS (Conformational Entropy): This term represents the change in conformational entropy upon binding. Due to its high computational cost, this term is often neglected, especially when comparing the relative binding affinities of similar ligands.
ΔG_bind = ΔE_MM + ΔG_solv - TΔS = ΔE_vdw + ΔE_elec + ΔG_GB + ΔG_SA - TΔS
For a hypothetical study of this compound binding to a target protein, molecular dynamics (MD) simulations would first be performed on the complex to generate a series of conformational snapshots. The MM/GBSA method would then be applied to these snapshots to calculate the average binding free energy and its individual energy components.
| Energy Component | Description | Hypothetical Contribution for this compound Binding |
| ΔE_vdw | van der Waals energy | Favorable (negative) |
| ΔE_elec | Electrostatic energy | Favorable (negative) or Unfavorable (positive) |
| ΔG_GB | Polar solvation energy | Unfavorable (positive) |
| ΔG_SA | Non-polar solvation energy | Favorable (negative) |
| ΔG_bind | Total binding free energy | Favorable (negative) for a stable complex |
This analysis can provide insights into the key energetic contributions driving the binding of this compound, such as the role of hydrophobic interactions from the phenyl rings or electrostatic interactions involving the amide backbone.
Structure-Activity Relationship (SAR) and Quantitative Structure-Activity Relationship (QSAR) Methodologies
Structure-Activity Relationship (SAR) and Quantitative Structure-Activity Relationship (QSAR) studies are cornerstones of medicinal chemistry and drug design. They aim to correlate the chemical structure of a compound with its biological activity.
The fundamental principle of SAR and QSAR is that the biological activity of a molecule is a function of its physicochemical properties, which are in turn determined by its molecular structure. SAR is a qualitative approach that involves systematically modifying a molecule's structure and observing the effect on its activity. QSAR takes this a step further by establishing a mathematical relationship between the structural properties (described by molecular descriptors) and the biological activity.
For this compound, a SAR study might involve synthesizing analogs with modifications to the phenyl rings (e.g., adding substituents) or the peptide backbone and then experimentally measuring their activity. A QSAR study would then use computational methods to quantify the structural features of these analogs and build a predictive model.
Molecular descriptors are numerical values that encode different aspects of a molecule's structure. For a dipeptide like this compound, a wide range of descriptors can be calculated:
Physicochemical Descriptors: These describe properties like hydrophobicity (e.g., LogP), molecular weight, and polar surface area. The two phenyl groups in this compound would contribute significantly to its hydrophobicity.
Topological Descriptors: These are derived from the 2D representation of the molecule and describe its size, shape, and branching. Examples include connectivity indices and Wiener indices.
Electronic Descriptors: These relate to the electronic properties of the molecule, such as dipole moment and the energies of the highest occupied molecular orbital (HOMO) and lowest unoccupied molecular orbital (LUMO). These can be calculated using quantum mechanics methods.
3D Descriptors: These are derived from the 3D conformation of the molecule and include descriptors of molecular shape and volume.
For peptides, specific descriptors derived from the properties of the constituent amino acids are often used. nih.gov These can include descriptors for the van der Waals volume, net charge index, and hydrophobicity of the amino acid side chains. nih.gov
| Descriptor Type | Example Descriptor | Relevance to this compound |
| Physicochemical | LogP | High value due to two phenyl rings, indicating hydrophobicity. |
| Topological | Wiener Index | Relates to the branching and size of the molecule. |
| Electronic | Dipole Moment | Influences electrostatic interactions. |
| Amino Acid Based | Side Chain Volume | Large volume due to the benzyl (B1604629) side chains of phenylalanine. |
Once a dataset of this compound analogs with their corresponding biological activities and calculated molecular descriptors is available, a QSAR model can be developed. This typically involves two main steps:
Model Building: A statistical method is used to find a mathematical equation that relates the descriptors (independent variables) to the biological activity (dependent variable). Common methods include Multiple Linear Regression (MLR), Partial Least Squares (PLS), and various machine learning algorithms.
Model Validation: The predictive power of the QSAR model must be rigorously validated. This is typically done using a test set of compounds that were not used in the model building process. Statistical metrics such as the squared correlation coefficient (R²) for the training set and the predictive squared correlation coefficient (Q²) for the test set are used to assess the model's quality.
A hypothetical QSAR model for an activity of this compound analogs might take the form of a linear equation:
Activity = c0 + c1 * (LogP) + c2 * (Polar Surface Area) + c3 * (Wiener Index)
Where c0, c1, c2, and c3 are coefficients determined by the regression analysis.
Machine learning (ML) has become increasingly important in QSAR modeling, offering the ability to handle large and complex datasets and to capture non-linear relationships between structure and activity. nih.govresearchgate.net For peptide QSAR, ML algorithms such as Support Vector Machines (SVM), Random Forests (RF), and Artificial Neural Networks (ANN) can be employed. researchgate.net
These ML models can be trained on datasets of peptides with known activities to predict the activity of new, untested compounds like novel derivatives of this compound. This can significantly accelerate the discovery of peptides with desired biological properties. nih.gov
In Silico Elucidation of Reaction Pathways and Enzyme Kinetics
Computational methods can also be used to study the chemical reactions that this compound may undergo, such as enzymatic hydrolysis of its peptide bond.
In silico elucidation of reaction pathways often involves quantum mechanics (QM) or combined quantum mechanics/molecular mechanics (QM/MM) methods. These methods can be used to:
Map the Reaction Pathway: By calculating the energy of the system as the reaction progresses, a reaction coordinate diagram can be constructed. This allows for the identification of transition states and intermediates.
Calculate Activation Energies: The height of the energy barrier (activation energy) determines the rate of the reaction. QM/MM calculations can provide estimates of these barriers.
Simulate Enzyme Kinetics: By combining the calculated energetic information with simulation techniques, it is possible to model the kinetics of the enzymatic reaction. This can provide insights into the catalytic mechanism of the enzyme and how it interacts with its substrate, this compound.
For example, a QM/MM study of the hydrolysis of this compound by a protease would treat the reacting atoms (the scissile peptide bond and the catalytic residues of the enzyme) with a high level of QM theory, while the rest of the protein and solvent would be treated with the more computationally efficient MM force field. This approach can reveal detailed information about the bond-breaking and bond-forming events during catalysis.
Advanced Research Applications and Future Directions in Phenylalanylphenylalanylamide Studies
Design and Engineering of Phenylalanylphenylalanylamide-Based Peptidomimetics
Peptidomimetics are small, protein-like chains designed to mimic peptides, offering advantages such as improved metabolic stability, better bioavailability, and enhanced receptor affinity. longdom.org The this compound motif serves as a valuable scaffold in this field. The design of peptidomimetics is broadly approached in two ways: a medicinal chemistry approach involving the successive replacement of peptide parts with non-peptide elements, and a biophysical approach where chemical moieties are hung on diverse scaffolds to mimic the peptide's bioactive conformation. benthamscience.com
The this compound structure is particularly amenable to modification. Its two phenyl rings provide a structural backbone ripe for functionalization, while the amide bond can be replaced with more stable isosteres to resist enzymatic degradation. Researchers have successfully synthesized novel phenylalanine derivatives and peptidomimetics for various therapeutic targets. For instance, phenylalanine-containing peptidomimetics have been developed as novel binders for the HIV-1 capsid protein, demonstrating the therapeutic potential of such designs. nih.gov Engineering efforts focus on modulating the compound's conformational flexibility and peptide character to optimize its interaction with biological targets. longdom.org By modifying the core dipeptide structure, scientists can create libraries of compounds with tailored properties for drug discovery and development.
Integration of this compound in Biomaterial Synthesis
The unique self-assembly properties of this compound and its close analogs, like diphenylalanine (L-Phe-L-Phe), make it a cornerstone for the bottom-up fabrication of novel biomaterials. These materials are finding applications in tissue engineering, drug delivery, and the creation of functional nanodevices.
The self-assembly of peptides containing phenylalanine is a well-documented phenomenon, driven by a combination of non-covalent interactions, including hydrogen bonding between peptide backbones and π–π stacking interactions between the aromatic phenyl rings. acs.orgnih.gov This process leads to the spontaneous formation of highly ordered and stable nanostructures. Depending on environmental conditions such as solvent, pH, and temperature, this compound and its derivatives can assemble into a diverse array of morphologies. nih.gov
Studies on the closely related diphenylalanine peptide show that it can form discrete, hollow, and well-ordered nanotubes, as well as nanofibers, nanorods, and hydrogels. nih.govnih.gov The formation of these structures is often templated by the initial organization of the dipeptides into larger supramolecular architectures, such as cyclic hexamers that stack to form tubes. nih.gov The resulting materials are mechanically rigid and can be used as scaffolds for cell culture or as templates for creating other nanomaterials. nih.gov The steric hindrance and hydrophobic interactions provided by the two phenylalanine moieties are critical drivers for this material aggregation. nih.gov
| Peptide Motif | Observed Nanostructures | Primary Driving Forces | Potential Applications |
|---|---|---|---|
| Diphenylalanine (FF) | Nanotubes, Nanofibers, Hydrogels, Nanorods nih.govnih.gov | π–π stacking, Hydrogen bonding acs.org | Tissue engineering, Drug delivery, Nanodevices nih.gov |
| Triphenylalanine (FFF) | Planar nanoplates with β-sheet content nih.gov | β-sheet formation, Hydrophobic interactions | Biomaterial synthesis, Nanofabrication nih.gov |
| Fmoc-Diphenylalanine | Supramolecular hydrogels, Nanofiber networks nih.gov | Enhanced π–π stacking from Fmoc group | 3D cell culture, Regenerative medicine rsc.org |
Sol-gel polymerization is a versatile process for creating solid materials from small molecules, involving the transition of a system from a liquid "sol" into a solid "gel" phase. Dipeptides like this compound are being explored as building blocks in novel hybrid sol-gel processes that combine molecular self-assembly with covalent bond formation. rsc.org
In a pioneering approach, researchers have silylated diphenylalanine by attaching a triethoxysilane group to its N-terminus. This modified dipeptide acts as a precursor in a one-pot synthesis method. Under aqueous acidic conditions, the molecular recognition and self-assembly of the dipeptide units bring the silanol groups into close proximity, driving and templating the sol-gel condensation reaction to form a stable siloxane network. rsc.org This method allows for the creation of structured materials, such as rod-shaped and spherical particles, where the morphology is directed by the peptide's intrinsic self-assembly behavior. rsc.org Furthermore, the sol-gel transition of hydrogels based on phenylalanine and its derivatives can be triggered by various stimuli, including pH and temperature, making them suitable for applications like injectable hydrogels for targeted drug delivery. nih.govacs.orgnih.gov
Exploration of this compound in Advanced Peptide Design and Engineering
The this compound motif is not only a standalone component but also a powerful module for incorporation into larger, more complex peptide designs. Its strong tendency to induce aggregation and form stable secondary structures, such as β-sheets, can be harnessed to engineer peptides with specific functionalities. nih.gov
Future Research Directions in this compound Chemistry and Biochemistry
The foundational research into this compound has paved the way for numerous future avenues of investigation. The continued exploration of its unique chemical and biochemical properties promises to yield transformative technologies.
Smart Biomaterials: Future work will likely focus on creating "smart" biomaterials that respond to specific biological cues. By functionalizing the dipeptide with responsive chemical groups, researchers can design hydrogels and nanostructures that release therapeutic agents or change their physical properties in response to disease markers like specific enzymes or pH changes.
Advanced Drug Delivery Systems: The self-assembling nature of this dipeptide can be further exploited to create more sophisticated drug encapsulation and delivery vehicles. Research into controlling the size, shape, and surface chemistry of the resulting nanoparticles will enable highly targeted delivery to specific cells or tissues, minimizing off-target effects.
Bioelectronics and Biosensing: The ordered, crystalline nature of self-assembled dipeptide nanostructures makes them candidates for applications in bioelectronics. Future studies may explore their use as conductive nanowires or as matrices for immobilizing enzymes in biosensors.
Complex Tissue Engineering: Moving beyond simple cell scaffolds, future research will aim to use this compound-based materials to construct complex, multi-layered tissues that mimic the architecture of natural organs. This could involve 3D printing techniques using dipeptide-based "bio-inks." 5z.com
Computational Design and AI: The use of artificial intelligence and machine learning will accelerate the discovery of new this compound derivatives with optimized properties. rsc.orgnih.gov These computational tools can screen vast virtual libraries of compounds to identify candidates with enhanced stability, bioactivity, and self-assembly characteristics for specific applications.
Q & A
Basic Research Questions
Q. What are the established protocols for synthesizing phenylalanylphenylalanylamide, and how can purity be validated?
- Methodological Answer : Synthesis typically employs solid-phase peptide synthesis (SPPS) using Fmoc-protected phenylalanine residues. Post-synthesis, reverse-phase HPLC with a C18 column and a gradient of acetonitrile/water (0.1% TFA) is recommended for purification . Purity validation requires tandem mass spectrometry (MS/MS) for molecular weight confirmation and NMR (¹H/¹³C) to verify backbone structure and absence of side-chain modifications. Quantify impurities via HPLC-UV at 214 nm, ensuring ≥95% purity for experimental reproducibility .
Q. Which spectroscopic techniques are critical for characterizing this compound’s structural properties?
- Methodological Answer : Use circular dichroism (CD) to assess secondary structure in aqueous solutions, particularly for identifying β-sheet or random coil conformations. FT-IR spectroscopy (amide I band at 1600–1700 cm⁻¹) complements CD data. For crystallographic studies, X-ray diffraction requires high-purity crystals grown via vapor diffusion in solvents like 20% PEG 3350 .
Q. How should researchers design stability studies for this compound under physiological conditions?
- Methodological Answer : Incubate the compound in phosphate-buffered saline (PBS, pH 7.4) at 37°C. Sample aliquots at 0, 12, 24, and 48 hours, then analyze degradation products via LC-MS. Compare degradation kinetics using Arrhenius plots for accelerated shelf-life predictions. Include controls with protease inhibitors (e.g., PMSF) to distinguish enzymatic vs. non-enzymatic breakdown .
Advanced Research Questions
Q. What strategies resolve contradictions in reported bioactivity data for this compound across studies?
- Methodological Answer : Conduct a systematic review using PRISMA guidelines to identify confounding variables (e.g., assay type, cell lines, compound batches). Validate key findings through independent replication:
- In vitro : Compare IC₅₀ values in HEK293 vs. HeLa cells using standardized MTT assays.
- In silico : Perform molecular docking (AutoDock Vina) to assess binding consistency across protein isoforms .
- Publish negative results to address publication bias .
Q. How can conformational dynamics of this compound be analyzed to explain its membrane interaction mechanisms?
- Methodological Answer : Employ molecular dynamics (MD) simulations (GROMACS/AMBER) with lipid bilayer models (e.g., POPC). Key parameters:
- Simulation time : ≥100 ns to capture peptide insertion.
- Metrics : Hydrogen bonding, solvent-accessible surface area (SASA), and lipid tail order parameters.
- Validate with experimental Surface plasmon resonance (SPR) for binding affinity and fluorescence quenching to monitor membrane penetration depth .
Q. What experimental frameworks are recommended for studying this compound’s role in protein misfolding diseases?
- Methodological Answer : Use thioflavin T (ThT) assays to quantify amyloid aggregation kinetics. Pair with TEM to visualize fibril morphology. For cellular models, transfect SH-SY5Y cells with α-synuclein-GFP and measure aggregation via fluorescence microscopy. Include negative controls (e.g., scrambled peptide) and statistical analysis (ANOVA with Tukey’s post-hoc test) .
Q. How can researchers integrate fragmented literature on this compound into a cohesive mechanistic model?
- Methodological Answer : Utilize bibliometric tools (VOSviewer, CiteSpace) to map keyword co-occurrence networks from PubMed and Scopus. Identify knowledge gaps (e.g., understudied pathways like autophagy modulation) and design hypothesis-driven studies:
- Multi-omics : Combine transcriptomics (RNA-seq) and proteomics (TMT labeling) in treated vs. untreated models.
- Pathway enrichment : Use DAVID or STRING for cross-study pathway analysis .
Methodological Notes
- Data Reproducibility : Adhere to FAIR principles (Findable, Accessible, Interoperable, Reusable). Share raw NMR/HPLC files via repositories like Zenodo .
- Statistical Rigor : For bioactivity studies, power analysis (G*Power) ensures adequate sample size. Report effect sizes (Cohen’s d) alongside p-values .
- Ethical Compliance : Obtain institutional approval for animal/human tissue studies, citing protocol numbers in publications .
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes




Featured Recommendations
| Most viewed |


|
|
|---|---|---|
| Most popular with customers |
|
Haftungsausschluss und Informationen zu In-Vitro-Forschungsprodukten
Bitte beachten Sie, dass alle Artikel und Produktinformationen, die auf BenchChem präsentiert werden, ausschließlich zu Informationszwecken bestimmt sind. Die auf BenchChem zum Kauf angebotenen Produkte sind speziell für In-vitro-Studien konzipiert, die außerhalb lebender Organismen durchgeführt werden. In-vitro-Studien, abgeleitet von dem lateinischen Begriff "in Glas", beinhalten Experimente, die in kontrollierten Laborumgebungen unter Verwendung von Zellen oder Geweben durchgeführt werden. Es ist wichtig zu beachten, dass diese Produkte nicht als Arzneimittel oder Medikamente eingestuft sind und keine Zulassung der FDA für die Vorbeugung, Behandlung oder Heilung von medizinischen Zuständen, Beschwerden oder Krankheiten erhalten haben. Wir müssen betonen, dass jede Form der körperlichen Einführung dieser Produkte in Menschen oder Tiere gesetzlich strikt untersagt ist. Es ist unerlässlich, sich an diese Richtlinien zu halten, um die Einhaltung rechtlicher und ethischer Standards in Forschung und Experiment zu gewährleisten.
