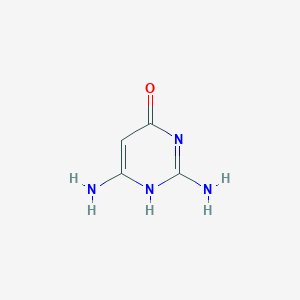
2-Aminoisocytosine
Beschreibung
Structure
3D Structure
Eigenschaften
IUPAC Name |
2,4-diamino-1H-pyrimidin-6-one |
Source


|
|---|---|---|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI |
InChI=1S/C4H6N4O/c5-2-1-3(9)8-4(6)7-2/h1H,(H5,5,6,7,8,9) |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
InChI Key |
SWELIMKTDYHAOY-UHFFFAOYSA-N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Canonical SMILES |
C1=C(N=C(NC1=O)N)N |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Molecular Formula |
C4H6N4O |
Source
|
| Record name | 2,4-diamino-6-hydroxypyrimidine | |
| Source | Wikipedia | |
| URL | https://en.wikipedia.org/wiki/Dictionary_of_chemical_formulas | |
| Description | Chemical information link to Wikipedia. | |
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Related CAS |
58470-85-2 (sulfate) |
Source
|
| Record name | 2-Aminoisocytosine | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0000056064 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
DSSTOX Substance ID |
DTXSID4049038 |
Source
|
| Record name | 2,4-Diamino-6-hydroxypyrimidine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID4049038 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
Molecular Weight |
126.12 g/mol |
Source
|
| Source | PubChem | |
| URL | https://pubchem.ncbi.nlm.nih.gov | |
| Description | Data deposited in or computed by PubChem | |
Physical Description |
Solid |
Source
|
| Record name | 2,4-Diamino-6-hydroxypyrimidine | |
| Source | Human Metabolome Database (HMDB) | |
| URL | http://www.hmdb.ca/metabolites/HMDB0002128 | |
| Description | The Human Metabolome Database (HMDB) is a freely available electronic database containing detailed information about small molecule metabolites found in the human body. | |
| Explanation | HMDB is offered to the public as a freely available resource. Use and re-distribution of the data, in whole or in part, for commercial purposes requires explicit permission of the authors and explicit acknowledgment of the source material (HMDB) and the original publication (see the HMDB citing page). We ask that users who download significant portions of the database cite the HMDB paper in any resulting publications. | |
CAS No. |
100643-27-4, 56-06-4, 143504-99-8 |
Source
|
| Record name | 2,6-Diamino-4-pyrimidinol | |
| Source | CAS Common Chemistry | |
| URL | https://commonchemistry.cas.org/detail?cas_rn=100643-27-4 | |
| Description | CAS Common Chemistry is an open community resource for accessing chemical information. Nearly 500,000 chemical substances from CAS REGISTRY cover areas of community interest, including common and frequently regulated chemicals, and those relevant to high school and undergraduate chemistry classes. This chemical information, curated by our expert scientists, is provided in alignment with our mission as a division of the American Chemical Society. | |
| Explanation | The data from CAS Common Chemistry is provided under a CC-BY-NC 4.0 license, unless otherwise stated. | |
| Record name | 2,4-Diamino-6-hydroxypyrimidine | |
| Source | CAS Common Chemistry | |
| URL | https://commonchemistry.cas.org/detail?cas_rn=56-06-4 | |
| Description | CAS Common Chemistry is an open community resource for accessing chemical information. Nearly 500,000 chemical substances from CAS REGISTRY cover areas of community interest, including common and frequently regulated chemicals, and those relevant to high school and undergraduate chemistry classes. This chemical information, curated by our expert scientists, is provided in alignment with our mission as a division of the American Chemical Society. | |
| Explanation | The data from CAS Common Chemistry is provided under a CC-BY-NC 4.0 license, unless otherwise stated. | |
| Record name | 2-Aminoisocytosine | |
| Source | ChemIDplus | |
| URL | https://pubchem.ncbi.nlm.nih.gov/substance/?source=chemidplus&sourceid=0000056064 | |
| Description | ChemIDplus is a free, web search system that provides access to the structure and nomenclature authority files used for the identification of chemical substances cited in National Library of Medicine (NLM) databases, including the TOXNET system. | |
| Record name | 2,4-Diamino-6-hydroxypyrimidine | |
| Source | DTP/NCI | |
| URL | https://dtp.cancer.gov/dtpstandard/servlet/dwindex?searchtype=NSC&outputformat=html&searchlist=44914 | |
| Description | The NCI Development Therapeutics Program (DTP) provides services and resources to the academic and private-sector research communities worldwide to facilitate the discovery and development of new cancer therapeutic agents. | |
| Explanation | Unless otherwise indicated, all text within NCI products is free of copyright and may be reused without our permission. Credit the National Cancer Institute as the source. | |
| Record name | 2,4-Diamino-6-hydroxypyrimidine | |
| Source | DTP/NCI | |
| URL | https://dtp.cancer.gov/dtpstandard/servlet/dwindex?searchtype=NSC&outputformat=html&searchlist=9302 | |
| Description | The NCI Development Therapeutics Program (DTP) provides services and resources to the academic and private-sector research communities worldwide to facilitate the discovery and development of new cancer therapeutic agents. | |
| Explanation | Unless otherwise indicated, all text within NCI products is free of copyright and may be reused without our permission. Credit the National Cancer Institute as the source. | |
| Record name | 4(3H)-Pyrimidinone, 2,6-diamino- | |
| Source | EPA Chemicals under the TSCA | |
| URL | https://www.epa.gov/chemicals-under-tsca | |
| Description | EPA Chemicals under the Toxic Substances Control Act (TSCA) collection contains information on chemicals and their regulations under TSCA, including non-confidential content from the TSCA Chemical Substance Inventory and Chemical Data Reporting. | |
| Record name | 2,4-Diamino-6-hydroxypyrimidine | |
| Source | EPA DSSTox | |
| URL | https://comptox.epa.gov/dashboard/DTXSID4049038 | |
| Description | DSSTox provides a high quality public chemistry resource for supporting improved predictive toxicology. | |
| Record name | 2,6-diamino-1H-pyrimidin-4-one | |
| Source | European Chemicals Agency (ECHA) | |
| URL | https://echa.europa.eu/substance-information/-/substanceinfo/100.000.232 | |
| Description | The European Chemicals Agency (ECHA) is an agency of the European Union which is the driving force among regulatory authorities in implementing the EU's groundbreaking chemicals legislation for the benefit of human health and the environment as well as for innovation and competitiveness. | |
| Explanation | Use of the information, documents and data from the ECHA website is subject to the terms and conditions of this Legal Notice, and subject to other binding limitations provided for under applicable law, the information, documents and data made available on the ECHA website may be reproduced, distributed and/or used, totally or in part, for non-commercial purposes provided that ECHA is acknowledged as the source: "Source: European Chemicals Agency, http://echa.europa.eu/". Such acknowledgement must be included in each copy of the material. ECHA permits and encourages organisations and individuals to create links to the ECHA website under the following cumulative conditions: Links can only be made to webpages that provide a link to the Legal Notice page. | |
| Record name | 2,6-Diaminopyrimidin-4(3H)-one | |
| Source | European Chemicals Agency (ECHA) | |
| URL | https://echa.europa.eu/information-on-chemicals | |
| Description | The European Chemicals Agency (ECHA) is an agency of the European Union which is the driving force among regulatory authorities in implementing the EU's groundbreaking chemicals legislation for the benefit of human health and the environment as well as for innovation and competitiveness. | |
| Explanation | Use of the information, documents and data from the ECHA website is subject to the terms and conditions of this Legal Notice, and subject to other binding limitations provided for under applicable law, the information, documents and data made available on the ECHA website may be reproduced, distributed and/or used, totally or in part, for non-commercial purposes provided that ECHA is acknowledged as the source: "Source: European Chemicals Agency, http://echa.europa.eu/". Such acknowledgement must be included in each copy of the material. ECHA permits and encourages organisations and individuals to create links to the ECHA website under the following cumulative conditions: Links can only be made to webpages that provide a link to the Legal Notice page. | |
| Record name | 2-AMINOISOCYTOSINE | |
| Source | FDA Global Substance Registration System (GSRS) | |
| URL | https://gsrs.ncats.nih.gov/ginas/app/beta/substances/EDH7CNS75I | |
| Description | The FDA Global Substance Registration System (GSRS) enables the efficient and accurate exchange of information on what substances are in regulated products. Instead of relying on names, which vary across regulatory domains, countries, and regions, the GSRS knowledge base makes it possible for substances to be defined by standardized, scientific descriptions. | |
| Explanation | Unless otherwise noted, the contents of the FDA website (www.fda.gov), both text and graphics, are not copyrighted. They are in the public domain and may be republished, reprinted and otherwise used freely by anyone without the need to obtain permission from FDA. Credit to the U.S. Food and Drug Administration as the source is appreciated but not required. | |
| Record name | 2,4-Diamino-6-hydroxypyrimidine | |
| Source | Human Metabolome Database (HMDB) | |
| URL | http://www.hmdb.ca/metabolites/HMDB0002128 | |
| Description | The Human Metabolome Database (HMDB) is a freely available electronic database containing detailed information about small molecule metabolites found in the human body. | |
| Explanation | HMDB is offered to the public as a freely available resource. Use and re-distribution of the data, in whole or in part, for commercial purposes requires explicit permission of the authors and explicit acknowledgment of the source material (HMDB) and the original publication (see the HMDB citing page). We ask that users who download significant portions of the database cite the HMDB paper in any resulting publications. | |
Melting Point |
286 °C |
Source
|
| Record name | 2,4-Diamino-6-hydroxypyrimidine | |
| Source | Human Metabolome Database (HMDB) | |
| URL | http://www.hmdb.ca/metabolites/HMDB0002128 | |
| Description | The Human Metabolome Database (HMDB) is a freely available electronic database containing detailed information about small molecule metabolites found in the human body. | |
| Explanation | HMDB is offered to the public as a freely available resource. Use and re-distribution of the data, in whole or in part, for commercial purposes requires explicit permission of the authors and explicit acknowledgment of the source material (HMDB) and the original publication (see the HMDB citing page). We ask that users who download significant portions of the database cite the HMDB paper in any resulting publications. | |
Foundational & Exploratory
A Researcher's In-depth Guide to the Structure and Tautomerism of 2-Aminoisocytosine
Prepared by: Gemini, Senior Application Scientist
Abstract
2-Aminoisocytosine (2-AIC), a non-canonical pyrimidine base, is of significant interest in the fields of synthetic biology and medicinal chemistry. Its ability to form alternative base pairs and participate in unique molecular recognition events is fundamentally governed by its tautomeric state. This guide provides a comprehensive technical overview of the structural landscape of 2-AIC, focusing on the critical concept of tautomerism. We will explore the different tautomeric forms, their relative stabilities as determined by computational and experimental methods, and the analytical techniques used for their characterization. This document is intended for researchers, scientists, and drug development professionals who require a deep, mechanistic understanding of 2-AIC to leverage its properties in their work.
Introduction: The Significance of 2-Aminoisocytosine
Isocytosine and its derivatives, such as 2-Aminoisocytosine (also known as 2,5-diamino-4(3H)-pyrimidinone), represent a fascinating class of heterocyclic compounds. Unlike the canonical bases of DNA and RNA, their extended hydrogen-bonding capabilities open new avenues for the creation of synthetic genetic polymers and targeted therapeutic agents. The dynamic equilibrium between different structural isomers, known as tautomers, is a central determinant of their function. Tautomers are constitutional isomers that readily interconvert, typically through the migration of a proton.[1][2] This subtle structural change can dramatically alter a molecule's hydrogen-bonding pattern, and therefore its biological activity. A precise understanding of the dominant tautomeric forms of 2-AIC under physiological conditions is paramount for predicting its pairing behavior and designing effective molecular scaffolds.
The Tautomeric Landscape of 2-Aminoisocytosine
2-Aminoisocytosine can exist in several tautomeric forms due to the migration of protons between its exocyclic amino groups and the endocyclic nitrogen and exocyclic oxygen atoms. These forms are broadly classified based on the amino/imino and keto/enol states.[3][4][5] The four principal tautomers are:
-
Amino-keto form (A): This is generally considered the most stable tautomer under many conditions.
-
Amino-enol form (B): An isomer where the carbonyl oxygen is protonated to form a hydroxyl group.
-
Imino-keto form (C): Characterized by a double bond to one of the exocyclic nitrogen atoms.
-
Imino-enol form (D): Possesses both an imino and an enol group.
The equilibrium between these forms is a dynamic process influenced by factors such as solvent polarity, pH, and temperature.
Sources
A Technical Guide to the Synthesis and Purification of 2-Aminoisocytosine (2-Aminouracil)
Introduction and Significance
2-Aminoisocytosine, also known as 2-aminouracil, is a pivotal molecule in the fields of chemical biology and drug development. As a structural isomer of the natural pyrimidine nucleobase cytosine, it serves as a powerful tool for probing and engineering biological systems.[1] Its unique hydrogen bonding pattern, distinct from the canonical Watson-Crick base pairs, allows for the creation of orthogonal genetic systems. Notably, it forms a stable base pair with isoguanine, a key component in expanded genetic alphabets like the "hachimoji" RNA system.[1]
Beyond synthetic genetics, 2-aminoisocytosine is utilized in physical-chemical studies to investigate metal complex binding, tautomerism, and proton transfer effects within nucleobases.[1] Its derivatives are also explored for their therapeutic potential, making robust and scalable synthesis protocols essential for advancing research in these domains.
This guide provides an in-depth examination of the principal synthetic routes to 2-aminoisocytosine, focusing on the underlying chemical logic, detailed experimental protocols, and rigorous purification strategies designed for researchers and drug development professionals.
Core Synthetic Principle: The Guanidine Condensation
The construction of the 2-aminoisocytosine core universally relies on a cyclocondensation reaction. This foundational strategy involves the reaction of a C1N3 building block, guanidine , with a C3 synthon that possesses electrophilic centers at the 1 and 3 positions. The specific choice of the C3 component dictates the reaction conditions and overall efficiency, leading to several established synthetic pathways. This guide will detail the two most authoritative and practical methods: the condensation with malic acid and the reaction with β-keto esters.
Protocol I: Synthesis via In Situ Decarbonylation of Malic Acid
This classic and reliable method leverages the in situ generation of a highly reactive C3 synthon from an inexpensive and stable starting material.
Principle and Mechanism
The core of this protocol is the acid-catalyzed decarbonylation of malic acid in concentrated sulfuric acid. This process eliminates water and carbon monoxide to generate 3-oxopropanoic acid (malonaldehydic acid) directly in the reaction vessel.[1] This transiently formed intermediate is highly electrophilic and is immediately trapped by guanidine, which is also present in the acidic solution. A double condensation reaction, with the elimination of two water molecules, proceeds to form the stable pyrimidinone ring of 2-aminoisocytosine.[1]
The use of concentrated sulfuric acid is critical; it serves as a catalyst, a dehydrating agent to drive the condensation equilibrium toward the product, and the solvent for the reaction.
Caption: General experimental workflow from reactants to purified product.
Detailed Experimental Protocol
-
Base Preparation: In a round-bottom flask equipped with a reflux condenser and a magnetic stirrer, dissolve 5.6 g of potassium hydroxide in 100 mL of absolute ethanol with gentle heating.
-
Guanidine Activation: To the ethanolic KOH solution, add 9.5 g of guanidine hydrochloride. Stir the mixture for 20 minutes at room temperature. A precipitate of potassium chloride will form.
-
Reactant Addition: To this slurry, add 11.3 g (or 11.2 mL) of ethyl cyanoacetate via a dropping funnel over 15 minutes.
-
Reaction: Heat the reaction mixture to reflux and maintain it for 6-8 hours. The progress of the reaction can be monitored by Thin Layer Chromatography (TLC) using a mobile phase such as chloroform:methanol (9:1). [2]5. Work-up: After the reaction is complete, cool the mixture to room temperature and filter to remove the precipitated KCl.
-
Precipitation: Concentrate the filtrate under reduced pressure to about one-third of its original volume. Slowly neutralize the concentrated solution with glacial acetic acid. The product will precipitate out of the solution.
-
Isolation and Drying: Cool the mixture in an ice bath for 30 minutes to maximize precipitation. Collect the solid by vacuum filtration, wash with cold ethanol, and dry in a vacuum oven at 60°C.
Comparative Summary of Synthetic Routes
| Parameter | Protocol I: Malic Acid | Protocol II: β-Keto Ester |
| Primary Reactants | Guanidine HCl, L-Malic Acid | Guanidine HCl, Ethyl Cyanoacetate |
| Key Reagent/Catalyst | Concentrated Sulfuric Acid | Potassium Hydroxide (or NaOEt) |
| Solvent | Concentrated Sulfuric Acid | Ethanol |
| Temperature | 75-80°C | Reflux (~78°C) |
| Key Advantages | Uses inexpensive starting materials; straightforward single-pot reaction. | Milder conditions; versatile for synthesizing derivatives; avoids handling large volumes of concentrated acid. |
| Key Challenges | Requires careful handling of large quantities of hot, concentrated H₂SO₄; vigorous work-up. | Requires anhydrous solvent; formation of inorganic salt byproducts that must be filtered. |
| Typical Yield | Moderate to Good | Good to Excellent |
Purification and Characterization
Achieving high purity is critical for downstream applications, especially in drug development and nucleic acid chemistry. The primary method for purifying crude 2-aminoisocytosine is recrystallization.
Detailed Purification Protocol (Recrystallization)
-
Solvent Selection: The choice of solvent is crucial. Water is often a good first choice due to the product's moderate solubility in hot water and poor solubility in cold water. For more stubborn impurities, solvent systems like methanol:chloroform (3:2) or dissolution in chloroform followed by precipitation with petroleum ether can be effective. [2][3]2. Dissolution: Place the crude, dry 2-aminoisocytosine in an Erlenmeyer flask. Add the minimum amount of boiling solvent (e.g., deionized water) required to fully dissolve the solid.
-
Decolorization (Optional): If the solution is colored, add a small amount (1-2% by weight) of activated charcoal and boil for an additional 5-10 minutes. The charcoal will adsorb colored impurities.
-
Hot Filtration: Quickly filter the hot solution through a pre-warmed funnel with fluted filter paper to remove the charcoal and any insoluble impurities. This step must be done rapidly to prevent premature crystallization in the funnel.
-
Crystallization: Allow the clear filtrate to cool slowly to room temperature, then place it in an ice bath for at least one hour to induce maximum crystallization.
-
Isolation and Drying: Collect the pure crystals by vacuum filtration, wash with a small amount of ice-cold solvent, and dry thoroughly in a vacuum oven.
Quality Control and Characterization
The identity and purity of the final product should be rigorously confirmed using standard analytical techniques:
-
Melting Point (m.p.): A sharp melting point is indicative of high purity. The reported melting point for isocytosine is around 276°C. [3]* ¹H and ¹³C NMR Spectroscopy: Provides definitive structural confirmation by showing the expected chemical shifts and couplings for the protons and carbons in the molecule.
-
Mass Spectrometry (MS): Confirms the molecular weight of the compound (C₄H₅N₃O, Molar Mass: 111.10 g·mol⁻¹). [1]* FTIR Spectroscopy: Shows characteristic peaks for the amine (N-H stretch), amide (C=O stretch), and alkene (C=C stretch) functional groups.
Conclusion
The synthesis of 2-aminoisocytosine is readily achievable through well-established chemical principles. The choice between the malic acid and β-keto ester routes depends on the available facilities, scale, and tolerance for specific reagents. The malic acid method is a robust, classic approach suitable for large-scale synthesis, while the β-keto ester method provides greater flexibility under milder conditions. In all cases, a meticulous purification protocol, primarily based on recrystallization, is paramount to obtaining material of sufficient purity for demanding research and development applications. This guide provides the foundational knowledge and practical steps for researchers to confidently synthesize and purify this important nucleobase analogue.
References
- Bares, J. E., et al. (1975). Synthesis of Isocytosine. Journal of the American Chemical Society, 97(15), 4413-4415.
- Wheeler, H. L., & Johnson, T. B. (1903). Synthesis of Isocytosine. American Chemical Journal, 29(6), 492-503.
-
Wikipedia contributors. (2023). Isocytosine. In Wikipedia, The Free Encyclopedia. Retrieved from [Link]
-
Sharma, V., et al. (2013). Synthesis of Cytosine Derivatives and Study of their Alkylation under Mild Conditions. Synthetic Communications, 43(12), 1648-1658. Retrieved from [Link]
-
Singh, P., et al. (2020). Base‐Induced Annulation of Glycal‐Derived α‐iodopyranone with 2‐Aminopyrimidinones: Access to Chiral Imidazopyrimidinones. Chirality, 32(10), 1285-1296. Retrieved from [Link]
-
de Assunção, L. R., Marinho, E. R., & Proença, F. P. (2010). Guanidine: studies on the reaction with ethyl N-(2-amino-1,2-dicyanovinyl)formimidate. ARKIVOC, 2010(5), 82-91. Retrieved from [Link]
Sources
Spectroscopic properties of 2-Aminoisocytosine
An In-Depth Technical Guide to the Spectroscopic Properties of 2-Aminoisocytosine
Authored by a Senior Application Scientist
Abstract
2-Aminoisocytosine, a non-canonical nucleobase analog, serves as a powerful tool in biochemical and biophysical research. Its unique electronic structure, which gives rise to distinct spectroscopic properties, allows it to function as a sensitive probe for nucleic acid structure, dynamics, and interactions. This guide provides a comprehensive exploration of the key spectroscopic characteristics of 2-Aminoisocytosine, including its UV-Visible absorption, fluorescence, Nuclear Magnetic Resonance (NMR), and Infrared (IR) signatures. By detailing the underlying principles, experimental protocols, and data interpretation, this document serves as a critical resource for researchers, scientists, and drug development professionals aiming to leverage this versatile molecule in their work.
Introduction: The Significance of 2-Aminoisocytosine
2-Aminoisocytosine is an isomer of isocytosine and a structural analog of both guanine and cytosine. Its importance stems from its ability to form alternative base pairs and its inherent fluorescence, a property largely absent in natural nucleobases which exhibit extremely low fluorescence quantum yields.[1] This makes it an invaluable reporter molecule for investigating biological systems.
A crucial aspect of 2-Aminoisocytosine's chemistry is its existence in multiple tautomeric forms (amino-oxo, amino-hydroxy, and imino-oxo forms). The equilibrium between these tautomers is sensitive to environmental factors such as solvent polarity and pH, and profoundly influences all of its spectroscopic properties. Understanding this tautomerism is fundamental to the correct interpretation of spectral data. Solid-state NMR studies on the related molecule isocytosine have shown that multiple tautomers can coexist, with distinct chemical shifts for protons in different environments (e.g., hydrogen-bonded vs. free NH).[2]
UV-Visible Absorption Spectroscopy
UV-Visible (UV-Vis) spectroscopy measures the absorption of light by a molecule, corresponding to the promotion of electrons to higher energy orbitals.[3] For aromatic systems like 2-Aminoisocytosine, the dominant absorptions are typically due to π → π* transitions. This technique is fundamental for quantification and for probing the electronic structure of the molecule.[4]
Core Principles & Spectral Features
Like other nucleobases, 2-Aminoisocytosine strongly absorbs UV light, with a primary absorption maximum (λmax) typically around 260-290 nm.[4][5] The precise λmax and molar extinction coefficient (ε) are highly dependent on the solvent, pH, and the dominant tautomeric form in solution. Changes in pH, for instance, can alter the protonation state of the molecule, leading to shifts in the absorption maximum (bathochromic or hypsochromic shifts). These spectral differences between a nucleoside and its corresponding base can be significant enough to allow for their discrimination in a mixture using spectral unmixing algorithms.[6]
Quantitative Data Summary
| Condition | Typical λmax (nm) | Notes |
| Neutral pH (aqueous) | ~285 | Represents the solvated amino-oxo tautomer. |
| Acidic pH | Shifts may occur | Protonation of ring nitrogens alters the chromophore. |
| Basic pH | Shifts may occur | Deprotonation can lead to significant spectral changes. |
| Aprotic Solvent | Varies | Tautomeric equilibrium shifts, affecting the electronic structure. |
Note: Specific values should be determined empirically for the exact experimental conditions used.
Experimental Protocol: UV-Vis Spectrum Acquisition
-
Sample Preparation:
-
Prepare a stock solution of 2-Aminoisocytosine in the desired buffer (e.g., 10 mM phosphate buffer, pH 7.4). A concentration of 0.1 to 0.5 mM is a good starting point.[7]
-
Dilute the stock solution to a final concentration that will yield an absorbance between 0.1 and 1.0 AU to ensure adherence to the Beer-Lambert law.[4]
-
-
Instrument Setup:
-
Use a dual-beam UV-Vis spectrophotometer.
-
Fill a quartz cuvette with the same buffer used for the sample to serve as a blank reference.
-
Place the blank cuvette in the reference beam path and record a baseline spectrum from 220 nm to 350 nm.
-
-
Sample Measurement:
-
Replace the blank cuvette with the sample cuvette.
-
Acquire the absorption spectrum over the same wavelength range. The instrument software will automatically subtract the blank spectrum.
-
-
Data Analysis:
-
Identify the wavelength of maximum absorbance (λmax).
-
If quantifying, use the Beer-Lambert equation (A = εcl), where A is absorbance, ε is the molar extinction coefficient, c is the concentration, and l is the path length.
-
Diagram: UV-Vis Analysis Workflow
Caption: Workflow for UV-Vis spectroscopic analysis.
Fluorescence Spectroscopy
Fluorescence spectroscopy is a highly sensitive technique that provides information about a molecule's electronic excited states and its local environment. Fluorescent nucleobase analogs like 2-Aminoisocytosine are exceptionally useful for studying nucleic acid folding, dynamics, and binding events, often at the single-molecule level.[8][9]
Core Principles & Spectral Features
Upon absorbing a photon and reaching an excited electronic state, a fluorescent molecule can relax to the ground state by emitting a photon. This emitted light is at a longer wavelength (lower energy) than the excitation light, a phenomenon known as the Stokes shift. The fluorescence intensity and emission wavelength of 2-Aminoisocytosine are exquisitely sensitive to its environment. For instance, when incorporated into DNA, its fluorescence is often quenched by base stacking with neighboring purines and pyrimidines, but this quenching can be relieved upon binding to a protein or undergoing a conformational change.[10]
Quantitative Data Summary
| Parameter | Typical Value Range | Influencing Factors |
| Excitation λmax | ~290-310 nm | Correlates with the UV absorption spectrum. |
| Emission λmax | ~350-380 nm | Solvent polarity (solvatochromic shifts), hydrogen bonding. |
| Quantum Yield (ΦF) | 0.1 - 0.6 | Highly dependent on environment; quenched by stacking, enhanced in non-polar environments. |
| Fluorescence Lifetime (τ) | 1 - 10 ns | Sensitive to dynamic quenching processes and local structure. |
Note: These are representative values. The ideal is to use a probe with fluorescence properties that differ from native DNA.[10]
Experimental Protocol: Fluorescence Spectra Acquisition
-
Sample Preparation:
-
Prepare samples in a fluorescence-free quartz cuvette.
-
Use a buffer appropriate for the biological system under study. Ensure the buffer itself is not fluorescent.
-
Concentrations are typically much lower than for UV-Vis, in the micromolar to nanomolar range, to avoid inner filter effects.
-
-
Instrument Setup (Spectrofluorometer):
-
Set the excitation wavelength to the molecule's absorption maximum (e.g., 300 nm).
-
Set the excitation and emission slit widths. Narrower slits (e.g., 2-5 nm) provide better resolution but lower signal; wider slits (e.g., 10 nm) increase signal but reduce resolution.
-
The instrument should be equipped with a thermostatted cell holder to maintain a constant sample temperature.[9]
-
-
Emission Spectrum Measurement:
-
Scan the emission monochromator from a wavelength slightly higher than the excitation wavelength to ~500 nm (e.g., 315 nm to 500 nm).
-
-
Excitation Spectrum Measurement:
-
Set the emission monochromator to the wavelength of maximum emission (e.g., 365 nm).
-
Scan the excitation monochromator from ~230 nm to a wavelength just below the emission setting (e.g., 230 nm to 355 nm). The resulting spectrum should resemble the absorption spectrum.
-
Diagram: Principle of Fluorescence
Caption: Simplified Jablonski diagram of fluorescence.
Nuclear Magnetic Resonance (NMR) Spectroscopy
NMR spectroscopy is an unparalleled technique for determining molecular structure and dynamics in solution. It provides atomic-level information by probing the magnetic properties of atomic nuclei (primarily ¹H, ¹³C, ¹⁵N).[11]
Core Principles & Spectral Features
The chemical shift of a nucleus in an NMR spectrum is determined by its local electronic environment. For 2-Aminoisocytosine, this allows for the unambiguous assignment of signals to specific protons and carbons in the molecule. Key applications include:
-
Structural Elucidation: Confirming the covalent structure.
-
Tautomerism Studies: NMR is particularly powerful for studying tautomeric equilibria. If the exchange between tautomers is slow on the NMR timescale, separate peaks will be observed for each species. If the exchange is fast, a single, population-averaged peak will be seen.[12]
-
Interaction Mapping: Changes in chemical shifts upon binding to another molecule (e.g., a protein or DNA strand) can identify the binding interface.
Representative NMR Data
| Nucleus | Typical Chemical Shift (ppm) | Notes |
| ¹H (H5/H6) | 5.5 - 8.0 | Aromatic protons on the pyrimidine ring. |
| ¹H (NH/NH₂) | 6.5 - 11.0 | Exchangeable protons. Position is highly sensitive to hydrogen bonding and tautomeric form. Broad signals are common. |
| ¹³C (C=O) | 160 - 180 | Carbonyl carbon, sensitive to tautomerism (C=O vs. C-OH). |
| ¹³C (Aromatic) | 90 - 150 | Ring carbons. |
Note: Shifts are referenced to an internal standard (e.g., DSS or TSP for aqueous samples) and are dependent on solvent, pH, and temperature.[11][13]
Experimental Protocol: NMR Sample Preparation
This protocol is critical for acquiring high-quality data.[14]
-
Solute Preparation:
-
Dissolve the required amount of 2-Aminoisocytosine to achieve the target concentration. For ¹H NMR, 2-10 mg is typical, while ¹³C NMR may require 10-50 mg for natural abundance signals.[15][16] A concentration >0.5 mM is recommended for 2D experiments.[13]
-
The sample must be free of paramagnetic impurities and solid particulates.
-
-
Solvent Selection:
-
Use a high-purity deuterated solvent (e.g., D₂O, DMSO-d₆) to avoid a large interfering solvent signal.
-
For studies in water, a 90% H₂O / 10% D₂O mixture is used. The D₂O provides the deuterium lock signal for the spectrometer.[13]
-
-
Sample Finalization:
-
Dissolve the compound in the chosen solvent, typically 0.5-0.6 mL.[15]
-
Transfer the solution to a high-quality 5 mm NMR tube. Ensure the sample height is adequate (typically >4 cm) to be within the detection coil.[14][15]
-
Add an internal chemical shift reference standard if required (e.g., DSS).
-
Adjust pH using DCl or NaOD for aqueous samples.[9]
-
-
Instrumental Analysis:
-
Acquire standard 1D ¹H and ¹³C spectra.
-
For detailed structural assignment and dynamics, acquire 2D NMR experiments such as COSY (correlates J-coupled protons) and NOESY (correlates protons close in space).[17]
-
Diagram: NMR Sample Preparation Workflow
Caption: Workflow for preparing a high-quality NMR sample.
Infrared (IR) Spectroscopy
Infrared (IR) spectroscopy measures the absorption of infrared radiation, which excites molecular vibrations (stretching, bending). It is an excellent tool for identifying the functional groups present in a molecule.
Core Principles & Spectral Features
Each functional group in 2-Aminoisocytosine has a characteristic vibrational frequency. The IR spectrum provides a "fingerprint" of the molecule, confirming the presence of key structural motifs. Computational studies on cytosine have shown good agreement between calculated and experimental vibrational spectra, allowing for confident assignment of specific bands.[5][18]
Characteristic IR Absorption Bands
| Wavenumber (cm⁻¹) | Vibrational Mode | Intensity | Notes |
| 3500 - 3300 | N-H Stretch | Medium-Strong | From the primary amine (-NH₂) group. Often appears as a doublet. |
| 3300 - 3100 | N-H Stretch | Medium | From the ring N-H group. |
| ~1700 | C=O Stretch | Strong | The carbonyl group stretch is a very prominent and reliable band. Its position is sensitive to hydrogen bonding. |
| 1650 - 1550 | C=C, C=N Stretches | Medium-Strong | Vibrations from the aromatic ring system. |
| ~1620 | N-H Bend | Medium | Scissoring vibration of the -NH₂ group. |
Note: The spectrum of a solid sample (e.g., KBr pellet) will be influenced by intermolecular hydrogen bonding in the crystal lattice.
Experimental Protocol: FTIR Analysis (KBr Pellet)
-
Sample Preparation:
-
Thoroughly grind ~1 mg of dry 2-Aminoisocytosine with ~100 mg of dry, spectroscopic-grade Potassium Bromide (KBr) in an agate mortar.
-
The goal is to produce a fine, homogeneous powder.
-
-
Pellet Formation:
-
Transfer the powder to a pellet press.
-
Apply high pressure (several tons) to form a thin, transparent or translucent pellet.
-
-
Data Acquisition:
-
Place the KBr pellet in the sample holder of an FTIR spectrometer.
-
Acquire a background spectrum of the empty sample compartment.
-
Acquire the sample spectrum. The instrument will ratio the sample spectrum against the background.
-
Diagram: Key Vibrational Modes
Caption: Key functional groups and their IR vibrations. (Conceptual Diagram)
Conclusion: An Integrated Spectroscopic Approach
No single spectroscopic technique tells the whole story. A comprehensive understanding of 2-Aminoisocytosine is achieved by integrating data from multiple methods. UV-Vis provides quantification and basic electronic information. Fluorescence offers unparalleled sensitivity for probing dynamic interactions. NMR delivers definitive structural and tautomeric information at the atomic level, while IR confirms the presence of key functional groups. By skillfully applying these techniques, researchers can fully exploit the capabilities of 2-Aminoisocytosine as a sophisticated probe in molecular biology and drug discovery.
References
- Single-Molecule Fluorescence Using Nucleotide Analogs: A Proof-of-Principle.
- NMR sample prepar
- How to make an NMR sample. Unknown Source.
- How to Prepare an NMR Sample. YouTube.
- NMR Sample Prepar
- NMR Sample Preparation. Cornell University - NMR and Chemistry MS Facilities.
- Fluorescent Nucleoside Analogues as DNA Probes. Unknown Source.
- Single-molecule fluorescence detection of a tricyclic nucleoside analogue. NSF Public Access Repository.
- Isomorphic Fluorescent Nucleosides. PubMed Central.
- Site-specific incorporation of a fluorescent nucleobase analog enhances i-motif stability and allows monitoring of i-motif folding inside cells. Nucleic Acids Research | Oxford Academic.
- A UV/Vis Spectroscopy-Based Assay for Monitoring of Transformations Between Nucleosides and Nucleobases. NIH.
- Nucleic Acid Quantification Methods: A Comprehensive Guide. Blue-Ray Biotech.
- UV-Visible absorption spectroscopy and Z-scan analysis. IOSR Journal.
- UV/Vis Spectroscopy for DNA & Protein Analysis. Unchained Labs.
- SPECTROSCOPIC PROPERTIES OF CYTOSINE: A COMPUTATIONAL INVESTIG
- INFRARED SPECTROSCOPY (IR). Unknown Source.
- Computational analysis of the vibrational spectra and structure of aqueous cytosine. Physical Chemistry Chemical Physics (RSC Publishing).
- The Use of NMR Spectroscopy to Study Tautomerism.
- 1 H NMR spectrum of solid isocytosine acquired at 65 kHz MAS. Two...
- An Introduction to Biological NMR Spectroscopy. PubMed Central.
- UV-Vis Spectroscopy: Principle, Strengths and Limitations and Applic
- UV-Visible Spectroscopy. MSU chemistry.
- Bio NMR spectroscopy. Unknown Source.
Sources
- 1. Isomorphic Fluorescent Nucleosides - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. UV-Visible Spectroscopy [www2.chemistry.msu.edu]
- 4. unchainedlabs.com [unchainedlabs.com]
- 5. bu.ac.bd [bu.ac.bd]
- 6. A UV/Vis Spectroscopy-Based Assay for Monitoring of Transformations Between Nucleosides and Nucleobases - PMC [pmc.ncbi.nlm.nih.gov]
- 7. nmr-bio.com [nmr-bio.com]
- 8. pubs.acs.org [pubs.acs.org]
- 9. academic.oup.com [academic.oup.com]
- 10. ccrod.cancer.gov [ccrod.cancer.gov]
- 11. An Introduction to Biological NMR Spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 12. researchgate.net [researchgate.net]
- 13. facilities.bioc.cam.ac.uk [facilities.bioc.cam.ac.uk]
- 14. NMR Sample Preparation | NMR and Chemistry MS Facilities [nmr.chem.cornell.edu]
- 15. How to make an NMR sample [chem.ch.huji.ac.il]
- 16. m.youtube.com [m.youtube.com]
- 17. chemistry.uoc.gr [chemistry.uoc.gr]
- 18. Computational analysis of the vibrational spectra and structure of aqueous cytosine - Physical Chemistry Chemical Physics (RSC Publishing) [pubs.rsc.org]
The Unnatural Base: A Technical Guide to 2-Aminoisocytosine in Synthetic Biology
Introduction: Expanding the Genetic Alphabet
The central dogma of molecular biology is elegantly simple, relying on the precise pairing of four nucleobases: adenine (A) with thymine (T), and guanine (G) with cytosine (C). This foundational principle of Watson-Crick base pairing governs the storage and transfer of genetic information in all known life. However, the field of synthetic biology seeks to move beyond the confines of nature's design, engineering novel biological parts, devices, and systems. A key frontier in this endeavor is the expansion of the genetic alphabet itself. By introducing artificial, or "unnatural," base pairs, we can augment the information-carrying capacity of DNA and RNA, opening avenues for novel diagnostics, therapeutics, and nanomaterials.[1][2]
This in-depth technical guide focuses on a pioneering unnatural nucleobase: 2-Aminoisocytosine , also known as isocytosine (isoC). We will delve into its historical discovery, the chemical logic behind its design, and the technical methodologies for its synthesis and incorporation into nucleic acids. This guide is intended for researchers, scientists, and drug development professionals who are actively working in or seeking to enter the exciting realm of synthetic genetics.
A Historical Perspective: The Genesis of an Idea
The concept of an expanded genetic alphabet is not a recent one. As early as 1962, the visionary scientist Alexander Rich proposed the possibility of an artificial third base pair formed between isoguanine (isoG) and isocytosine (isoC).[1] This theoretical pairing was predicated on a hydrogen bonding pattern distinct from the canonical A-T and G-C pairs, offering an orthogonal system for information storage.
However, it was not until the late 1980s and early 1990s that the groups of Steven A. Benner and H. P. Rappaport provided the first experimental evidence for the enzymatic incorporation of the isoG-isoC pair into nucleic acids.[1] These seminal studies laid the groundwork for the practical application of 2-aminoisocytosine in synthetic biology. A significant challenge identified in this early work was the chemical instability of isocytosine derivatives, particularly their susceptibility to deamination under the alkaline conditions typically used in automated oligonucleotide synthesis. This observation was a critical driver for the development of improved protecting group strategies for the exocyclic amine of isocytosine, a crucial aspect for its successful chemical synthesis into DNA and RNA strands.
The Molecular Logic: Why 2-Aminoisocytosine?
The design of 2-aminoisocytosine as a partner for isoguanine is a prime example of rational molecular engineering. The pairing relies on a unique hydrogen-bonding pattern that is orthogonal to the Watson-Crick pairs, meaning it does not cross-react with the natural bases.
Diagram: Watson-Crick vs. isoC-isoG Base Pairing
Sources
An In-depth Technical Guide to 2-Aminoisocytosine Analogs and Their Chemical Properties
For Researchers, Scientists, and Drug Development Professionals
Abstract
2-Aminoisocytosine (2-AIC), a non-canonical pyrimidine nucleobase, and its analogs represent a class of heterocyclic compounds with significant potential in medicinal chemistry, chemical biology, and materials science. Their unique structural and electronic properties, particularly their tautomeric behavior and hydrogen bonding capabilities, distinguish them from natural nucleobases and offer a versatile scaffold for the design of novel therapeutic agents and molecular probes. This guide provides a comprehensive overview of the fundamental chemical properties of 2-AIC analogs, including their synthesis, tautomerism, spectroscopic characteristics, and base-pairing interactions. Furthermore, we delve into the biophysical properties of oligonucleotides incorporating these analogs and explore their burgeoning applications in drug development. Detailed experimental protocols and visual workflows are provided to offer both theoretical understanding and practical insights for researchers in the field.
The Core of 2-Aminoisocytosine: Structure and Tautomerism
2-Aminoisocytosine (also known as 2-amino-4-hydroxy-pyrimidine) is an isomer of isocytosine. The placement of the amino group at the 2-position profoundly influences its electronic structure and potential for intermolecular interactions. A critical aspect of the chemistry of 2-AIC and its analogs is their existence in different tautomeric forms. Tautomers are structural isomers that readily interconvert, and their relative populations can be influenced by environmental factors such as solvent polarity and pH.
The primary tautomeric forms of 2-AIC are the amino-oxo and the imino-oxo forms. Computational studies on the related isocytosine molecule suggest that in aqueous solutions, the amino form is generally more stable than the imino form[1]. The dynamic equilibrium between these tautomers is a key determinant of the molecule's function and reactivity.
Caption: Tautomeric equilibrium of 2-Aminoisocytosine.
The ability to control or favor a specific tautomeric form through chemical modification is a powerful strategy in the design of 2-AIC analogs for specific biological targets.
Synthesis of 2-Aminoisocytosine Analogs
The synthesis of 2-AIC analogs can be achieved through various routes in synthetic organic chemistry. A common approach involves the cyclization of a substituted guanidine derivative with a β-ketoester. The specific substituents on the starting materials will determine the final structure of the analog. For instance, multicomponent reactions are also being explored for the efficient, one-pot synthesis of related heterocyclic systems like 2-aminobenzothiazoles[2].
Below is a generalized workflow for the synthesis of a 2-AIC analog. The choice of protecting groups and reaction conditions is critical for achieving high yields and purity.
Caption: Generalized synthetic workflow for 2-AIC analogs.
Experimental Protocol: Synthesis of a Hypothetical 2-AIC Analog
This protocol is a representative example and may require optimization for specific analogs.
-
Reaction Setup: In a flame-dried round-bottom flask under an inert atmosphere (e.g., argon), dissolve the substituted guanidine (1.0 eq) in a suitable anhydrous solvent (e.g., ethanol).
-
Addition of Reagents: Add the corresponding β-ketoester (1.1 eq) and a base (e.g., sodium ethoxide, 1.2 eq) to the reaction mixture.
-
Reaction: Heat the mixture to reflux and monitor the reaction progress by Thin Layer Chromatography (TLC).
-
Workup: Once the reaction is complete, cool the mixture to room temperature and neutralize with a suitable acid (e.g., acetic acid).
-
Extraction: Remove the solvent under reduced pressure and partition the residue between an organic solvent (e.g., ethyl acetate) and water.
-
Purification: Dry the organic layer over anhydrous sodium sulfate, filter, and concentrate. Purify the crude product by column chromatography on silica gel.
-
Characterization: Confirm the structure of the final product using NMR, mass spectrometry, and IR spectroscopy.
Spectroscopic and Physicochemical Properties
The chemical properties of 2-AIC analogs can be thoroughly investigated using a variety of spectroscopic and analytical techniques.
| Property | Technique | Typical Observations |
| UV-Visible Absorption | UV-Vis Spectroscopy | Absorption maxima are typically observed in the range of 260-280 nm, characteristic of pyrimidine-based systems. The exact wavelength and molar absorptivity can be influenced by substituents and solvent.[3] |
| Vibrational Modes | Infrared (IR) Spectroscopy | Characteristic peaks include N-H stretching vibrations from the amino group, C=O stretching from the keto group, and C=N and C=C stretching from the pyrimidine ring.[3] |
| Proton and Carbon Environments | Nuclear Magnetic Resonance (NMR) Spectroscopy | 1H and 13C NMR provide detailed information about the chemical structure. The chemical shifts of the ring protons and carbons are sensitive to the electronic effects of the substituents.[4] |
| Electrochemical Behavior | Cyclic Voltammetry | The oxidation potential of 2-AIC analogs can be determined, providing insight into their electron-donating properties. The presence of an amino group generally lowers the oxidation potential compared to the parent phenothiazine molecule.[5][6] |
Hydrogen Bonding and Base Pairing
A key feature of 2-AIC and its analogs is their ability to form specific hydrogen bond patterns, which is of great interest for applications in synthetic biology and the development of therapeutic oligonucleotides. 2-AIC can act as both a hydrogen bond donor (from the amino group and N-H) and an acceptor (from the ring nitrogens and the carbonyl oxygen).
The unique arrangement of these functional groups allows 2-AIC to potentially form three hydrogen bonds with a complementary partner, such as isoguanine, mimicking the stable G-C base pair.[7][8] This property is crucial for the design of expanded genetic alphabets and for enhancing the binding affinity of therapeutic oligonucleotides to their targets.
Caption: Hydrogen bonding pattern of 2-AIC with a partner.
The energetic contribution of the 2-amino group to the thermodynamic stability of DNA duplexes has been studied using non-canonical nucleotides.[7] These studies reveal that the presence of the 2-amino group can significantly stabilize the duplex, depending on the base pairing partner and the surrounding sequence context.
Biophysical Properties of Oligonucleotides Containing 2-AIC Analogs
The incorporation of 2-AIC analogs into oligonucleotides can impart novel biophysical properties. These modifications are a cornerstone of developing next-generation antisense oligonucleotides (ASOs) and small interfering RNAs (siRNAs).[9]
| Biophysical Property | Impact of 2-AIC Analog Incorporation | Rationale |
| Duplex Thermal Stability (Tm) | Generally increased | The potential for an additional hydrogen bond can enhance the stability of the duplex with its target DNA or RNA strand.[4] |
| Mismatch Discrimination | Improved | The specific hydrogen bonding requirements of the 2-AIC analog can lead to a greater destabilization of duplexes with mismatched bases.[4] |
| Nuclease Resistance | Increased | Modifications to the nucleobase, sugar, or phosphate backbone can sterically hinder the approach of nucleases, thereby increasing the in vivo stability of the oligonucleotide.[10][11] |
Experimental Protocol: Thermal Denaturation of Oligonucleotides
-
Sample Preparation: Dissolve the oligonucleotide containing the 2-AIC analog and its complementary strand in a buffer solution (e.g., 10 mM phosphate buffer with 100 mM NaCl, pH 7.0).
-
Instrumentation: Use a UV-Vis spectrophotometer equipped with a temperature controller.
-
Denaturation and Annealing: Initially, heat the sample to 85-90°C to ensure complete denaturation, then slowly cool to allow for annealing.
-
Melting Curve Acquisition: Increase the temperature at a controlled rate (e.g., 1°C/min) while continuously monitoring the absorbance at 260 nm.
-
Data Analysis: Plot the absorbance versus temperature. The melting temperature (Tm) is the temperature at which 50% of the duplex is dissociated, determined from the first derivative of the melting curve.
Applications in Medicinal Chemistry and Drug Development
The versatile scaffold of 2-AIC and its analogs makes them attractive for a wide range of applications in medicinal chemistry. The 2-amino group can serve as a key pharmacophore, participating in crucial interactions with biological targets. For example, the 2-aminothiazole core is present in several marketed drugs and is a focus of ongoing drug discovery efforts in areas such as oncology and infectious diseases.[12][13]
Potential Therapeutic Applications:
-
Anticancer Agents: 2-AIC analogs can be designed to selectively bind to specific DNA or RNA structures that are overexpressed in cancer cells, such as G-quadruplexes.
-
Antiviral and Antibacterial Agents: By mimicking natural nucleosides, these analogs can be developed as inhibitors of viral or bacterial polymerases. The aminocyclitol moiety, for instance, is a key component in many antiviral and antibacterial drugs.[14]
-
Modulators of Gene Expression: As components of therapeutic oligonucleotides, 2-AIC analogs can enhance target affinity and in vivo stability, leading to more potent and durable gene silencing or splicing modulation.[9]
-
Bioisosteric Replacement: In drug design, a functional group can be replaced by a bioisostere to improve physicochemical properties, metabolic stability, or target affinity.[15][16] 2-AIC analogs can serve as bioisosteres for other heterocyclic systems.
Conclusion and Future Outlook
2-Aminoisocytosine analogs represent a promising class of compounds with tunable chemical and physical properties. Their unique hydrogen bonding capabilities and versatile synthetic accessibility make them valuable tools in supramolecular chemistry, materials science, and particularly in drug discovery and development. Future research will likely focus on the development of more efficient and stereoselective synthetic methods, a deeper understanding of their interactions with biological macromolecules, and the expansion of their applications in targeted therapeutics and diagnostics. The continued exploration of this chemical space is poised to yield novel molecules with significant scientific and clinical impact.
References
-
ResearchGate. Tautomers of 2-pyrimidinamine and of isocytosine. Available from: [Link]
-
PubMed. Synthesis and Biophysical Investigations of Oligonucleotides Containing Galactose-Modified DNA, LNA, and 2'-Amino-LNA Monomers. Available from: [Link]
-
MDPI. Roles of the Amino Group of Purine Bases in the Thermodynamic Stability of DNA Base Pairing. Available from: [Link]
-
MDPI. Weak Interactions in the Structures of Newly Synthesized (–)-Cytisine Amino Acid Derivatives. Available from: [Link]
-
Semantic Scholar. SPECTROSCOPIC PROPERTIES OF CYTOSINE: A COMPUTATIONAL INVESTIGATION. Available from: [Link]
-
Pearson. Base Pairing Explained: Definition, Examples, Practice & Video Lessons. Available from: [Link]
-
MDPI. Chemistry of Therapeutic Oligonucleotides That Drives Interactions with Biomolecules. Available from: [Link]
-
MDPI. Influence of the Solvent on the Stability of Aminopurine Tautomers and Properties of the Amino Group. Available from: [Link]
-
PubMed. Chemoenzymatic synthesis of iminocyclitol derivatives: a useful library strategy for the development of selective fucosyltransfer enzymes inhibitors. Available from: [Link]
-
The Chinese University of Hong Kong. Base pairing. Available from: [Link]
-
Journal of Molecular Biology. Recognition of Nucleic Acid Bases and Base-pairs by Hydrogen Bonding to Amino Acid Side-chains. Available from: [Link]
-
ResearchGate. In vitro and in vivo biophysical properties of oligonucleotides containing 5'-thio nucleosides. Available from: [Link]
-
ResearchGate. The keto–amino/enol tautomerism of cytosine in aqueous solution. A theoretical study using combined discrete/self-consistent reaction field models. Available from: [Link]
-
PubMed. Recent developments of 2-aminothiazoles in medicinal chemistry. Available from: [Link]
-
LabXchange. The DNA Base Pairs in Detail. Available from: [Link]
-
Drug Discovery and Therapeutics. In vitro and in vivo biophysical properties of oligonucleotides containing 5'-thio nucleosides. Available from: [Link]
-
PubMed. Medicinal chemistry of aminocyclitols. Available from: [Link]
-
ResearchGate. Most stable gas-phase tautomers of cytosine. Available from: [Link]
-
PubMed Central. Biophysical and biological properties of splice-switching oligonucleotides and click conjugates containing LNA-phosphothiotriester linkages. Available from: [Link]
-
IntechOpen. Synopsis of Some Recent Tactical Application of Bioisosteres in Drug Design. Available from: [Link]
-
PubMed Central. Efficient Synthesis of Hydroxy-Substituted 2-Aminobenzo[d]thiazole-6-carboxylic Acid Derivatives as New Building Blocks in Drug Discovery. Available from: [Link]
-
MDPI. Synthesis of O-Amino Sugars and Nucleosides. Available from: [Link]
-
YouTube. Tautomerism; Types & Stability of Tautomers. Available from: [Link]
-
ResearchGate. (PDF) Spectroscopic and electrochemical properties of 2-aminophenothiazine. Available from: [Link]
-
SpringerLink. Synthesis of biologically active derivatives of 2-aminobenzothiazole. Available from: [Link]
-
ResearchGate. Recent developments of 2-aminothiazoles in medicinal chemistry. Available from: [Link]
-
PubMed Central. The Influence of Bioisosteres in Drug Design: Tactical Applications to Address Developability Problems. Available from: [Link]
-
PubMed Central. SPECTROSCOPIC AND ELECTROCHEMICAL PROPERTIES OF 2-AMINOPHENOTHIAZINE. Available from: [Link]
-
PubMed. SPECTROSCOPIC AND ELECTROCHEMICAL PROPERTIES OF 2-AMINOPHENOTHIAZINE. Available from: [Link]
Sources
- 1. researchgate.net [researchgate.net]
- 2. Synthesis of biologically active derivatives of 2-aminobenzothiazole - PMC [pmc.ncbi.nlm.nih.gov]
- 3. bu.ac.bd [bu.ac.bd]
- 4. Synthesis and Biophysical Investigations of Oligonucleotides Containing Galactose-Modified DNA, LNA, and 2'-Amino-LNA Monomers - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. SPECTROSCOPIC AND ELECTROCHEMICAL PROPERTIES OF 2-AMINOPHENOTHIAZINE - PMC [pmc.ncbi.nlm.nih.gov]
- 6. SPECTROSCOPIC AND ELECTROCHEMICAL PROPERTIES OF 2-AMINOPHENOTHIAZINE - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. mdpi.com [mdpi.com]
- 8. Base pairing [bch.cuhk.edu.hk]
- 9. mdpi.com [mdpi.com]
- 10. researchgate.net [researchgate.net]
- 11. In vitro and in vivo biophysical properties of oligonucleotides containing 5'-thio nucleosides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Recent developments of 2-aminothiazoles in medicinal chemistry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. Medicinal chemistry of aminocyclitols - PubMed [pubmed.ncbi.nlm.nih.gov]
- 15. researchgate.net [researchgate.net]
- 16. The Influence of Bioisosteres in Drug Design: Tactical Applications to Address Developability Problems - PMC [pmc.ncbi.nlm.nih.gov]
Quantum Chemical Calculations for 2-Aminoisocytosine: A Technical Guide for Researchers
< <
Prepared by: Gemini, Senior Application Scientist
Abstract
This guide provides a comprehensive technical overview of quantum chemical calculations applied to 2-Aminoisocytosine (AIC), a non-canonical nucleobase of significant interest in xenobiology and drug development. We delve into the theoretical underpinnings of computational quantum chemistry, offering a practical, step-by-step workflow for researchers. This document is designed to bridge theoretical concepts with practical application, enabling scientists to leverage computational tools to elucidate the electronic structure, reactivity, and spectroscopic properties of this intriguing molecule.
Part 1: The Significance of 2-Aminoisocytosine (AIC)
2-Aminoisocytosine, also known as isocytosine or 2-amino-4-hydroxypyrimidine, is a pyrimidine nucleobase analog.[1][2] Its structure deviates from the canonical bases that form the alphabet of our genetic code, and it is this deviation that makes it a compelling subject for study. In the realm of drug design, AIC serves as a bioisostere, a compound resulting from the exchange of an atom or a group of atoms with another, broadly similar, atom or group.[3][4][5] This concept is a cornerstone of medicinal chemistry, allowing for the fine-tuning of a molecule's pharmacological and physicochemical properties.
The exploration of non-canonical nucleobases like AIC is also central to the field of xenobiology, which seeks to create synthetic biological systems with expanded genetic alphabets.[6][7][8][9][10] Understanding the hydrogen bonding patterns, stability, and electronic characteristics of AIC is crucial for designing novel base pairs and, ultimately, synthetic life forms.
Quantum chemical calculations offer a powerful lens through which to examine AIC at the subatomic level. These in silico experiments provide insights that are often difficult or impossible to obtain through traditional wet-lab techniques alone. They allow us to predict molecular geometries, understand reaction mechanisms, and interpret spectroscopic data with a high degree of accuracy.
Part 2: Theoretical Foundations of Quantum Chemical Calculations
At its core, quantum chemistry uses the principles of quantum mechanics to calculate the properties of molecules.[11] The foundational equation is the Schrödinger equation, which, for all but the simplest systems, cannot be solved exactly.[11] Thus, a variety of approximation methods have been developed.
Key Methodologies: A Brief Overview
-
Hartree-Fock (HF) Theory: This is a foundational ab initio method that provides a good starting point for more complex calculations. It treats each electron in a molecule as moving in the average field of all other electrons.
-
Density Functional Theory (DFT): DFT has become the workhorse of modern computational chemistry due to its favorable balance of accuracy and computational cost.[12][13][14] Instead of the complex many-electron wavefunction, DFT focuses on the electron density to calculate the energy of a system. The choice of the "functional" (e.g., B3LYP, M06-2X) is critical and depends on the specific properties being investigated.
-
Post-Hartree-Fock Methods: For situations demanding higher accuracy, methods like Møller-Plesset perturbation theory (MP2) and Coupled Cluster (CC) theory can be employed, though at a significantly higher computational expense.[15]
The Role of Basis Sets
A basis set is a set of mathematical functions used to represent the electronic wave function in a molecule.[16][17] The choice of basis set is a critical parameter in any quantum chemical calculation, directly impacting the accuracy and computational cost.
-
Pople-style basis sets (e.g., 6-31G, 6-311+G(d,p)):* These are widely used and offer a good compromise between accuracy and speed.[16][18][19] The notation indicates the number of functions used to describe the core and valence electrons, as well as the inclusion of polarization (*) and diffuse (+) functions, which are important for describing electron distribution in more complex systems.[18]
-
Dunning-style correlation-consistent basis sets (e.g., cc-pVDZ, aug-cc-pVTZ): These are designed to systematically converge towards the complete basis set limit, providing a pathway to highly accurate results.[16]
Part 3: A Practical Workflow for Quantum Chemical Calculations on 2-Aminoisocytosine
This section outlines a robust, step-by-step protocol for performing quantum chemical calculations on AIC. This workflow is designed to be a self-validating system, with each step building upon the previous one to ensure the reliability of the final results.
Step 1: Geometry Optimization
The first step in any quantum chemical study is to determine the most stable three-dimensional structure of the molecule. This is achieved through a process called geometry optimization, which systematically adjusts the positions of the atoms to find the minimum energy conformation on the potential energy surface.
Protocol:
-
Build the initial structure: Construct the 2D structure of 2-Aminoisocytosine and convert it to a 3D model using a molecular editor.
-
Select the level of theory: For a good balance of accuracy and efficiency, a DFT method such as B3LYP with a Pople-style basis set like 6-31G(d) is a reasonable starting point for geometry optimization of heterocyclic compounds.[13]
-
Perform the optimization: Submit the structure for geometry optimization using a quantum chemistry software package (e.g., Gaussian, ORCA). The output will be the optimized Cartesian coordinates of the atoms.
Caption: A simplified workflow for the geometry optimization of 2-Aminoisocytosine.
It is important to consider that 2-Aminoisocytosine can exist in different tautomeric forms.[20][21][22] Separate geometry optimizations should be performed for each plausible tautomer to determine their relative stabilities.[23][24]
Step 2: Vibrational Frequency Analysis
Once the geometry is optimized, a frequency calculation should be performed. This serves two critical purposes:
-
Confirmation of a true minimum: A true minimum energy structure will have no imaginary frequencies. The presence of one or more imaginary frequencies indicates a saddle point on the potential energy surface, and the geometry needs to be further optimized.
-
Thermochemical data: The frequency calculation provides valuable thermochemical data, such as zero-point vibrational energy (ZPVE), enthalpy, and Gibbs free energy. These are essential for comparing the relative stabilities of different tautomers or conformations.
Protocol:
-
Use the optimized geometry: The frequency calculation must be performed on the optimized geometry from the previous step.
-
Same level of theory: It is crucial to use the same level of theory (method and basis set) as the geometry optimization.
-
Analyze the output: Check the output file for the number of imaginary frequencies. If there are none, the structure is a true minimum.
Step 3: Calculation of Molecular Properties
With a validated minimum energy structure, a wealth of molecular properties can be calculated to understand the behavior of 2-Aminoisocytosine.
-
Frontier Molecular Orbitals (HOMO and LUMO): The Highest Occupied Molecular Orbital (HOMO) and the Lowest Unoccupied Molecular Orbital (LUMO) are key to understanding a molecule's reactivity.[25][26][27][28] The HOMO energy is related to the ability to donate electrons (nucleophilicity), while the LUMO energy relates to the ability to accept electrons (electrophilicity).[25][27] The HOMO-LUMO energy gap provides an indication of the molecule's chemical stability.[29]
-
Molecular Electrostatic Potential (MEP): The MEP is a 3D map of the electrostatic potential on the electron density surface of a molecule.[30][31][32][33][34] It is an invaluable tool for identifying regions of positive and negative potential, which correspond to sites susceptible to nucleophilic and electrophilic attack, respectively.[13][30]
Caption: The relationship between calculated electronic properties and their interpretation.
-
Infrared (IR) and Raman Spectra: The vibrational frequencies calculated in Step 2 can be used to predict the IR and Raman spectra of 2-Aminoisocytosine. This allows for direct comparison with experimental spectra, aiding in the identification and characterization of the molecule.
-
UV-Vis Spectra: The electronic transitions that give rise to a molecule's UV-Vis spectrum can be calculated using Time-Dependent Density Functional Theory (TD-DFT).[35][36][37][38][39][40] This is a powerful tool for understanding the photophysical properties of AIC and can be particularly useful in the design of fluorescent probes.
Protocol for TD-DFT:
-
Use the optimized ground-state geometry.
-
Select an appropriate functional and basis set: Functionals like B3LYP or CAM-B3LYP are often used for TD-DFT calculations. A basis set with diffuse functions (e.g., 6-31+G(d)) is recommended for describing excited states.
-
Specify the number of excited states to calculate.
-
Consider solvent effects: The inclusion of a solvent model (e.g., the Polarizable Continuum Model, PCM) is often necessary for accurate prediction of UV-Vis spectra in solution.
Part 4: Data Presentation and Interpretation
The results of quantum chemical calculations are typically presented in tables for easy comparison and analysis.
Table 1: Calculated Properties of 2-Aminoisocytosine (Example)
| Property | Value |
| Optimized Geometry | |
| N1-C2 Bond Length (Å) | 1.375 |
| C4-C5 Bond Length (Å) | 1.432 |
| N1-C2-N3 Bond Angle (°) | 120.5 |
| Electronic Properties | |
| HOMO Energy (eV) | -6.25 |
| LUMO Energy (eV) | -1.10 |
| HOMO-LUMO Gap (eV) | 5.15 |
| Dipole Moment (Debye) | 3.45 |
| Thermochemistry | |
| Zero-Point Energy (kcal/mol) | 65.8 |
| Gibbs Free Energy (Hartree) | -415.12345 |
Note: The values in this table are illustrative and will vary depending on the level of theory used.
Interpreting the vast amount of data generated by these calculations is a critical skill. The calculated bond lengths and angles can be compared to experimental crystallographic data to validate the computational model. The HOMO and LUMO energies provide insights into the molecule's potential for participating in chemical reactions. The MEP map visually highlights the most reactive sites on the molecule.
Conclusion
Quantum chemical calculations are an indispensable tool for modern chemical research. This guide has provided a foundational understanding and a practical workflow for applying these methods to the study of 2-Aminoisocytosine. By following these protocols, researchers in drug development and xenobiology can gain deep insights into the properties of this important non-canonical nucleobase, accelerating the pace of discovery and innovation.
References
-
Explicit solvation modeling in the accurate TD-DFT prediction of absorption spectra for natural nucleobases and fluorescent nucl - ChemRxiv. Available at: [Link]
-
Tautomers of 2-pyrimidinamine and of isocytosine. - ResearchGate. Available at: [Link]
-
Kaur, S., & Sharma, P. (2019). Radical pathways for the formation of non-canonical nucleobases in prebiotic environments. RSC Advances, 9(63), 36841-36851. Available at: [Link]
-
Dutta, N., Deb, I., Sarzynska, J., & Lahiri, A. (2022). Quantum chemical and molecular modeling studies of twenty therapeutic nucleosides and nucleoside analogues. ChemRxiv. Available at: [Link]
-
Explicit solvation modeling in the accurate TD-DFT prediction of absorption spectra for natural nucleobases and fluorescent nucleobase analogues - ResearchGate. Available at: [Link]
-
Density Functional Calculations on Heterocyclic Compounds. Part 2. On the Protonation of 4,5-Dichloro-2-methyl-3(2H)-pyridazinone | Semantic Scholar. Available at: [Link]
-
Non-canonical base pairing - Wikipedia. Available at: [Link]
-
How Well Can Density Functional Methods Describe Hydrogen Bonds to π Acceptors? | The Journal of Physical Chemistry B - ACS Publications. Available at: [Link]
-
Quantum Chemistry Calculations for Metabolomics: Focus Review - PMC - PubMed Central. Available at: [Link]
-
Experimental Approach, Computational DFT Investigation and a Biological Activity in the Study of an Organic Heterocyclic Compound - Lupine Publishers. Available at: [Link]
-
Molecular electrostatic potential surface of essential amino acids... - ResearchGate. Available at: [Link]
-
Absorption and normalized emission spectra of the qA analogues at 5 μM... - ResearchGate. Available at: [Link]
-
Rathi, P., et al. (2020). Quantum parameters based study of some heterocycles using density functional theory method: A comparative theoretical study. Journal of The Chinese Chemical Society, 67(2), 263-273. Available at: [Link]
-
Isocytosine | C4H5N3O | CID 66950 - PubChem - NIH. Available at: [Link]
-
Supporting Information: Quantum Chemical Insights into DNA Nucleobase Oxidation: Bridging Theory and Experiment - DOI. Available at: [Link]
-
Modeling noncanonical RNA base pairs by coarse-grained IsRNA2 model - PMC. Available at: [Link]
-
Sponer, J., et al. (2013). Quantum chemical studies of nucleic acids: Can we construct a bridge to the RNA structural biology and bioinformatics communities?. Journal of Biomolecular Structure and Dynamics, 31(10), 1166-1189. Available at: [Link]
-
updated overview of experimental and computational approaches to identify non-canonical DNA/RNA structures with emphasis on G-quadruplexes and R-loops | Briefings in Bioinformatics | Oxford Academic. Available at: [Link]
-
Computational Analysis of Density Functional Theory (DFT method), Thermodynamic Investigations and Molecular Docking Studies on 1-(2'-Thiophen)-3-(2,3,5-trichlorophenyl)-2-propen-1-one - ResearchGate. Available at: [Link]
-
Non-canonical Base Pairing - Wikimedia Commons. Available at: [Link]
-
Basis set (chemistry) - Wikipedia. Available at: [Link]
-
HOMO/LUMO energy levels (E(vac)) of nucleobases relative to the vacuum... - ResearchGate. Available at: [Link]
-
Molecular Modeling Based on Time-Dependent Density Functional Theory (TD-DFT) Applied to the UV-Vis Spectra of Natural Compounds - MDPI. Available at: [Link]
-
TDDFT - Rowan Scientific. Available at: [Link]
-
Basis Sets | Gaussian.com. Available at: [Link]
-
UVVis spectroscopy (UV/Vis) - ORCA 6.0 TUTORIALS - FACCTs. Available at: [Link]
-
Guide to identifying HOMO-LUMO of molecules? : r/OrganicChemistry - Reddit. Available at: [Link]
-
Basis Sets for the Calculation of Core-Electron Binding Energies - University of Nottingham Ningbo China. Available at: [Link]
-
Influence of the Solvent on the Stability of Aminopurine Tautomers and Properties of the Amino Group - MDPI. Available at: [Link]
-
Electrophiles and Nucleophiles; LUMOs and HOMOs - YouTube. Available at: [Link]
-
Molecular electrostatic potential mapped on the isodensity surface of... - ResearchGate. Available at: [Link]
-
Journal of Chemical Information and Modeling - ACS Publications. Available at: [Link]
-
11.2: Gaussian Basis Sets - Chemistry LibreTexts. Available at: [Link]
-
Molecular electrostatic potential in cytosine monohydrate, the... | Download Scientific Diagram - ResearchGate. Available at: [Link]
-
The keto–amino/enol tautomerism of cytosine in aqueous solution. A theoretical study using combined discrete/self-consistent reaction field models - ResearchGate. Available at: [Link]
-
The application of bioisosteres in drug design for novel drug discovery: focusing on acid protease inhibitors - PubMed. Available at: [Link]
-
Introduction to HOMO LUMO Interactions in Organic Chemistry - YouTube. Available at: [Link]
-
9.4.2. Tautomers - Chemistry LibreTexts. Available at: [Link]
-
Computational Study of the Electrostatic Potential and Charges of Multivalent Ionic Liquid Molecules - OSTI.GOV. Available at: [Link]
-
A Revival of Molecular Surface Electrostatic Potential Statistical Quantities: Ionic Solids and Liquids - MDPI. Available at: [Link]
-
Most stable gas-phase tautomers of cytosine. | Download Scientific Diagram - ResearchGate. Available at: [Link]
-
The Influence of Bioisosteres in Drug Design: Tactical Applications to Address Developability Problems - PubMed Central. Available at: [Link]
-
Synopsis of Some Recent Tactical Application of Bioisosteres in Drug Design. Available at: [Link]
Sources
- 1. Isocytosine | C4H5N3O | CID 66950 - PubChem [pubchem.ncbi.nlm.nih.gov]
- 2. Isocytosine | 108-53-2 [chemicalbook.com]
- 3. The application of bioisosteres in drug design for novel drug discovery: focusing on acid protease inhibitors - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. The Influence of Bioisosteres in Drug Design: Tactical Applications to Address Developability Problems - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. Radical pathways for the formation of non-canonical nucleobases in prebiotic environments - RSC Advances (RSC Publishing) [pubs.rsc.org]
- 7. Non-canonical base pairing - Wikipedia [en.wikipedia.org]
- 8. Modeling noncanonical RNA base pairs by coarse-grained IsRNA2 model - PMC [pmc.ncbi.nlm.nih.gov]
- 9. academic.oup.com [academic.oup.com]
- 10. upload.wikimedia.org [upload.wikimedia.org]
- 11. Quantum Chemistry Calculations for Metabolomics: Focus Review - PMC [pmc.ncbi.nlm.nih.gov]
- 12. pubs.acs.org [pubs.acs.org]
- 13. lupinepublishers.com [lupinepublishers.com]
- 14. researchgate.net [researchgate.net]
- 15. Quantum chemical studies of nucleic acids: Can we construct a bridge to the RNA structural biology and bioinformatics communities? - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Basis set (chemistry) - Wikipedia [en.wikipedia.org]
- 17. chem.libretexts.org [chem.libretexts.org]
- 18. gaussian.com [gaussian.com]
- 19. research.nottingham.edu.cn [research.nottingham.edu.cn]
- 20. researchgate.net [researchgate.net]
- 21. chem.libretexts.org [chem.libretexts.org]
- 22. researchgate.net [researchgate.net]
- 23. Influence of the Solvent on the Stability of Aminopurine Tautomers and Properties of the Amino Group [mdpi.com]
- 24. researchgate.net [researchgate.net]
- 25. ossila.com [ossila.com]
- 26. reddit.com [reddit.com]
- 27. youtube.com [youtube.com]
- 28. youtube.com [youtube.com]
- 29. researchgate.net [researchgate.net]
- 30. researchgate.net [researchgate.net]
- 31. researchgate.net [researchgate.net]
- 32. researchgate.net [researchgate.net]
- 33. osti.gov [osti.gov]
- 34. mdpi.com [mdpi.com]
- 35. chemrxiv.org [chemrxiv.org]
- 36. researchgate.net [researchgate.net]
- 37. researchgate.net [researchgate.net]
- 38. mdpi.com [mdpi.com]
- 39. TDDFT | Rowan [rowansci.com]
- 40. UVVis spectroscopy (UV/Vis) - ORCA 6.0 TUTORIALS [faccts.de]
An In-depth Technical Guide to the Solubility of 2-Aminoisocytosine in Aqueous and Organic Solvents
Executive Summary
2-Aminoisocytosine, a pivotal pyrimidine analog and an isomer of the natural nucleobase cytosine, is garnering significant attention within the realms of synthetic biology and drug development. Its unique base-pairing capabilities make it a valuable component in the design of novel therapeutic agents and expanded genetic systems. However, the effective application of 2-Aminoisocytosine is fundamentally governed by its physicochemical properties, paramount among which is its solubility. This in-depth technical guide provides a comprehensive exploration of the solubility of 2-Aminoisocytosine across a spectrum of aqueous and organic solvents. We delve into the core physicochemical principles that dictate its solubility, present available quantitative and qualitative data, and provide detailed, field-proven experimental protocols for researchers, scientists, and drug development professionals to accurately determine solubility in their own laboratory settings.
The Physicochemical Landscape of 2-Aminoisocytosine: Tautomerism and Ionization
The solubility of 2-Aminoisocytosine is intrinsically linked to its complex chemical nature, specifically its tautomeric equilibrium and ionization states. A thorough understanding of these phenomena is critical to interpreting and predicting its behavior in different solvent environments.
Tautomeric Equilibrium: A Dynamic Interplay of Forms
In both solid state and solution, 2-Aminoisocytosine exists as a dynamic equilibrium of multiple tautomeric forms, primarily the amino-oxo, amino-hydroxy, and imino-oxo forms. The relative populations of these tautomers are profoundly influenced by the solvent's polarity, pH, and temperature. The most stable and predominant forms are the amino-oxo tautomers.[1] This equilibrium is crucial as each tautomer presents a different set of hydrogen bonding donors and acceptors, directly impacting its interaction with solvent molecules.
Caption: Tautomeric equilibrium of 2-Aminoisocytosine.
Ionization and pKa: The Key to pH-Dependent Solubility
-
At pH < pKa1 (~4.6): The molecule is expected to be protonated, forming a cationic species. This charged form generally exhibits increased solubility in aqueous solutions due to favorable ion-dipole interactions with water molecules.
-
At pH between pKa1 and pKa2: The molecule exists predominantly in its neutral form. Its solubility in this range is referred to as its intrinsic solubility and is typically at its minimum.
-
At pH > pKa2 (~12.2): The molecule is expected to be deprotonated, forming an anionic species, which again would lead to enhanced aqueous solubility.
This U-shaped solubility profile as a function of pH is a characteristic feature of amphoteric compounds.[3]
Quantitative and Qualitative Solubility Profile
While extensive, peer-reviewed quantitative solubility data for 2-Aminoisocytosine is sparse, a combination of estimated values based on structural analogs and limited experimental data provides a valuable baseline for researchers.
Solubility Data Table
The following table summarizes the available solubility information for 2-Aminoisocytosine in a range of common solvents at ambient temperature. It is critical to note that much of this data is estimated and should be experimentally verified for precise applications.
| Solvent | Type | Polarity | Estimated Solubility (mg/mL) at 25°C | Notes |
| Water (pH 7) | Aqueous (Polar Protic) | High | ~5 - 8[1] | Based on cytosine solubility of ~7-8 mg/mL.[1] |
| Acetic Acid | Organic (Polar Protic) | High | > 50[1] | Soluble with heating.[1] A concrete data point indicates solubility of 50 mg/mL with heat. |
| DMSO | Organic (Polar Aprotic) | High | Moderate[1] | Generally a good solvent for polar organic molecules.[1] |
| Ethanol | Organic (Polar Protic) | Medium | Low (< 1)[1] | Slightly soluble, similar to cytosine.[1] |
| Methanol | Organic (Polar Protic) | Medium | Low (< 1)[1] | Slightly soluble, similar to cytosine.[1] |
| Diethyl Ether | Organic (Nonpolar) | Low | Very Low (< 0.1)[1] | Practically insoluble, similar to cytosine.[1] |
Disclaimer: The solubility values presented are largely estimates and should be used as a guide for initial solvent screening. For critical applications, experimental determination is strongly recommended.
Experimental Determination of Solubility: A Practical Guide
To address the need for precise and reliable solubility data, this section provides a detailed, step-by-step protocol for the experimental determination of the thermodynamic (equilibrium) solubility of 2-Aminoisocytosine using the gold-standard shake-flask method.
The Shake-Flask Method: A Protocol for Thermodynamic Solubility
This method measures the equilibrium solubility of a compound, which is the concentration of the solute in a saturated solution in equilibrium with the solid compound.
Principle: An excess amount of the solid compound is agitated in the solvent of interest for a prolonged period to ensure equilibrium is reached. The resulting saturated solution is then filtered, and the concentration of the dissolved compound is determined analytically.
Caption: Workflow for the Shake-Flask Solubility Determination Method.
Materials and Equipment:
-
2-Aminoisocytosine (solid)
-
Selected solvents (e.g., water, buffered solutions at various pH, ethanol, DMSO)
-
Scintillation vials or other suitable sealed containers
-
Orbital shaker or rotator with temperature control
-
Syringe filters (e.g., 0.22 µm PTFE or PVDF)
-
Volumetric flasks and pipettes
-
Analytical balance
-
High-Performance Liquid Chromatography (HPLC) system with a UV detector or a UV-Vis spectrophotometer
Step-by-Step Protocol:
-
Preparation: Add an excess amount of 2-Aminoisocytosine to a series of vials containing a known volume of the test solvents. The excess solid should be clearly visible.
-
Equilibration: Seal the vials and place them on an orbital shaker in a temperature-controlled environment (e.g., 25°C or 37°C). Agitate the samples for a sufficient period (typically 24-48 hours) to ensure equilibrium is reached.
-
Sample Collection and Filtration: After equilibration, allow the vials to stand undisturbed for a short period to allow the excess solid to settle. Carefully withdraw an aliquot of the supernatant and immediately filter it through a syringe filter to remove any undissolved particles.
-
Dilution: Accurately dilute the filtered supernatant with a suitable solvent to a concentration that falls within the linear range of the analytical method.
-
Analysis: Determine the concentration of 2-Aminoisocytosine in the diluted samples using a validated analytical method, such as HPLC-UV or UV-Vis spectrophotometry.
-
Calculation: Calculate the solubility of 2-Aminoisocytosine in the original solvent, taking into account the dilution factor. Express the solubility in appropriate units (e.g., mg/mL or mol/L).
Factors Influencing the Solubility of 2-Aminoisocytosine
Several factors can significantly impact the solubility of 2-Aminoisocytosine. A comprehensive understanding of these is essential for effective formulation and experimental design.
-
pH: As discussed, the ionization state of 2-Aminoisocytosine is pH-dependent, leading to significant changes in its aqueous solubility. For drug development, solubility should be assessed across a physiologically relevant pH range (e.g., pH 1.2, 4.5, and 6.8).
-
Temperature: The dissolution of most solid compounds is an endothermic process, meaning that solubility tends to increase with temperature. This can be leveraged to prepare supersaturated solutions, although the stability of the compound at elevated temperatures should be considered.
-
Solvent Polarity: The principle of "like dissolves like" is a useful guide. The polar nature of 2-Aminoisocytosine, with its multiple hydrogen bond donors and acceptors, suggests higher solubility in polar solvents like water (at appropriate pH), DMSO, and to a lesser extent, lower alcohols. Its solubility is expected to be poor in nonpolar solvents like diethyl ether and hydrocarbons.[1]
-
Crystal Polymorphism: Different crystalline forms (polymorphs) of a compound can exhibit different solubilities. It is important to characterize the solid form of 2-Aminoisocytosine being used in solubility studies.
Conclusion and Future Perspectives
The solubility of 2-Aminoisocytosine is a multifaceted property governed by its inherent chemical structure and the surrounding solvent environment. This guide has provided a foundational understanding of the key factors influencing its solubility, presented the best available quantitative data, and offered a robust experimental protocol for its determination. For researchers and drug development professionals, a thorough and experimentally verified understanding of the solubility of 2-Aminoisocytosine is not merely a preliminary step but a critical determinant for the successful advancement of novel therapeutics and synthetic biological systems. Future research should focus on generating comprehensive, publicly available experimental data on the solubility and pKa of 2-Aminoisocytosine to fill the current knowledge gaps and accelerate its application in science and medicine.
References
-
PubChem. Isocytosine | C4H5N3O | CID 66950. National Institutes of Health. [Link]
-
Merck Index. Cytosine. Royal Society of Chemistry. [Link]
-
Yamauchi, T., et al. (1979). Physicochemical properties of amphoteric beta-lactam antibiotics. II: Solubility and dissolution behavior of aminocephalosporins as a function of pH. Journal of Pharmaceutical Sciences, 68(3), 308-11. [Link]
Sources
An In-Depth Technical Guide to the NMR Chemical Shifts of 2-Aminoisocytosine
For Researchers, Scientists, and Drug Development Professionals
Authored by: [Your Name/Gemini], Senior Application Scientist
Date: January 7, 2026
Abstract
This technical guide provides a comprehensive analysis of the Nuclear Magnetic Resonance (NMR) chemical shifts of 2-Aminoisocytosine. As a crucial nucleobase analog in medicinal chemistry and biochemical research, a thorough understanding of its spectral properties is paramount for its identification, structural elucidation, and the study of its interactions. This document delves into the intricacies of its ¹H and ¹³C NMR spectra, the profound influence of tautomerism and solvent effects, and provides detailed experimental protocols for acquiring high-quality NMR data.
Introduction: The Significance of 2-Aminoisocytosine
2-Aminoisocytosine, a structural isomer of guanine, is a heterocyclic amine that has garnered significant interest in the fields of medicinal chemistry and molecular biology. Its ability to form alternative base pairs and participate in various biological processes makes it a valuable tool in the design of novel therapeutic agents and molecular probes. Nuclear Magnetic Resonance (NMR) spectroscopy is an indispensable technique for the unambiguous characterization of 2-Aminoisocytosine, providing detailed information about its molecular structure, dynamics, and interactions in solution. A comprehensive understanding of its chemical shifts is fundamental to leveraging this powerful analytical tool.
Tautomerism: The Key to Understanding the NMR Spectrum of 2-Aminoisocytosine
A critical aspect influencing the NMR spectrum of 2-Aminoisocytosine is its existence in multiple tautomeric forms. Tautomers are constitutional isomers of organic compounds that readily interconvert. This dynamic equilibrium is sensitive to environmental factors such as solvent polarity and pH. For 2-Aminoisocytosine, the primary tautomeric equilibrium exists between the amino-oxo and the imino-oxo forms, with potential contributions from other tautomers.
The interconversion between these tautomers can be fast or slow on the NMR timescale, leading to either averaged signals or distinct sets of peaks for each species. In many common NMR solvents, the exchange is rapid, resulting in a single set of averaged chemical shifts. However, the position of these averaged signals is dictated by the relative populations of the contributing tautomers.
Diagram: Tautomeric Equilibrium of 2-Aminoisocytosine
Caption: Workflow for structural elucidation using 1D and 2D NMR techniques.
Experimental Protocol for Acquiring High-Quality NMR Spectra
To obtain reliable and reproducible NMR data for 2-Aminoisocytosine, a standardized experimental protocol is essential.
Step-by-Step Methodology:
-
Sample Preparation:
-
Accurately weigh approximately 5-10 mg of 2-Aminoisocytosine.
-
Dissolve the sample in 0.6-0.7 mL of high-purity deuterated solvent (e.g., DMSO-d₆, 99.9 atom % D).
-
To ensure complete dissolution, gentle warming or sonication may be applied.
-
Filter the solution through a small plug of glass wool in a Pasteur pipette directly into a clean, dry 5 mm NMR tube to remove any particulate matter.
-
-
Instrument Setup:
-
Use a high-field NMR spectrometer (e.g., 400 MHz or higher) for optimal signal dispersion and sensitivity.
-
Tune and match the probe for the appropriate nucleus (¹H or ¹³C).
-
Lock the spectrometer on the deuterium signal of the solvent.
-
Shim the magnetic field to achieve high homogeneity, aiming for a narrow and symmetrical solvent peak.
-
-
¹H NMR Acquisition:
-
Acquire a standard 1D proton spectrum using a 90° pulse.
-
Set the spectral width to cover the expected range of chemical shifts (typically 0-12 ppm).
-
Use a sufficient number of scans (e.g., 16-64) to achieve a good signal-to-noise ratio.
-
Apply a relaxation delay of at least 5 times the longest T₁ relaxation time to ensure quantitative integration.
-
-
¹³C NMR Acquisition:
-
Acquire a proton-decoupled ¹³C spectrum.
-
Set the spectral width to encompass the full range of expected carbon chemical shifts (e.g., 0-200 ppm).
-
A larger number of scans will be required for ¹³C NMR due to its lower natural abundance and sensitivity.
-
Employ techniques like DEPT (Distortionless Enhancement by Polarization Transfer) to differentiate between CH, CH₂, and CH₃ groups.
-
-
2D NMR Acquisition:
-
For each 2D experiment (COSY, HSQC, HMBC, NOESY), use standard pulse programs provided by the spectrometer manufacturer.
-
Optimize the acquisition parameters, such as the number of increments in the indirect dimension and the number of scans per increment, to achieve the desired resolution and signal-to-noise in a reasonable amount of time.
-
-
Data Processing:
-
Apply Fourier transformation to the acquired free induction decays (FIDs).
-
Phase correct the spectra to obtain pure absorption lineshapes.
-
Perform baseline correction to ensure accurate integration.
-
Reference the spectra using the residual solvent peak (e.g., DMSO at 2.50 ppm for ¹H and 39.52 ppm for ¹³C) or an internal standard like tetramethylsilane (TMS).
-
Conclusion
The NMR chemical shifts of 2-Aminoisocytosine are a rich source of information about its structure, tautomeric state, and interactions. A thorough understanding of the factors that influence these shifts, coupled with the application of advanced NMR techniques, is crucial for researchers in drug discovery and chemical biology. This guide provides a foundational framework for the acquisition and interpretation of high-quality NMR data for this important heterocyclic compound, enabling its effective use in a wide range of scientific applications.
References
-
General NMR Sample Preparation
- Title: NMR Sample Prepar
- Source: University of California, Riverside - Department of Chemistry
-
URL: [Link]
-
Tautomerism in Heterocyclic Compounds
- Title: Tautomerism Detected by NMR
- Source: Encyclopedia.pub
-
URL: [Link]
-
Chemical Shifts in ¹H NMR Spectroscopy
- Title: Chemical Shifts in ¹H NMR Spectroscopy
- Source: Chemistry LibreTexts
-
URL: [Link]
-
¹³C NMR Chemical Shifts
- Title: 13C NMR Chemical Shifts
- Source: University of Wisconsin-Madison - Department of Chemistry
-
URL: [Link]
-
2D NMR Spectroscopy
- Title: A Step-By-Step Guide to 1D and 2D NMR Interpret
- Source: Emery Pharma
-
URL: [Link]
-
pH-dependent NMR studies
- Title: In Situ Light‐driven pH Modul
- Source: PubMed Central (PMC)
-
URL: [Link]
-
NMR of Cytosine Derivatives
- Title: Unusual behavior of cytosine amino group signal in 1H NMR spectra in DMSO depending on its concentr
- Source: ResearchG
-
URL: [Link]
-
Solid-State NMR of Isocytosine
- Title: Solid-State NMR Studies of Nucleic Acid Components
- Source: ResearchG
-
URL: [Link]
-
NMR Spectral Databases
- Title: Spectral D
- Source: National Institute of Advanced Industrial Science and Technology (AIST), Japan
-
URL: [Link]
-
NMR of Heterocyclic Amines
- Title: Synthesis and NMR Spectral Analysis of Amine Heterocycles: The Effect of Asymmetry on the 1H and 13C NMR Spectra of N,O-Acetals
- Source: Journal of Chemical Educ
-
URL: [Link]
A Senior Application Scientist's Guide to the Crystal Structure of 2-Aminoisocytosine Derivatives
Authored for Researchers, Scientists, and Drug Development Professionals
Introduction: The Architectural Blueprint of a Unique Nucleobase Analog
In the landscape of molecular biology and medicinal chemistry, the quest for molecules that can mimic or modulate the fundamental interactions of life is paramount. 2-Aminoisocytosine, a derivative of cytosine, stands out as a compelling scaffold. Its strategic placement of hydrogen bond donors and acceptors allows it to form highly stable, self-assembled structures, most notably Watson-Crick-like base pairs.[1] This capacity for predictable and robust self-assembly makes its derivatives powerful platforms for supramolecular chemistry and the rational design of novel therapeutics.[2] Understanding the three-dimensional crystal structure of these derivatives is not merely an academic exercise; it is the critical step in unlocking their potential. The precise arrangement of atoms in the solid state, dictated by a delicate balance of intermolecular forces, governs a molecule's physical properties, its stability, and, crucially, its biological activity.[3] This guide provides an in-depth exploration of the methodologies and considerations essential for determining and interpreting the crystal structures of 2-aminoisocytosine derivatives, offering a field-proven perspective on leveraging this structural knowledge for drug discovery and materials science.
The Supramolecular Chemistry of 2-Aminoisocytosine: A Game of Tautomers and Hydrogen Bonds
The supramolecular behavior of 2-aminoisocytosine derivatives is dominated by two key chemical features: their hydrogen bonding capabilities and the potential for tautomerism. A thorough grasp of these concepts is essential before embarking on any crystallization experiments.
Hydrogen Bonding: The Driving Force of Self-Assembly
Like their natural counterparts, guanine and cytosine, 2-aminoisocytosine derivatives can engage in multiple hydrogen bonds to form highly organized assemblies.[4] The primary interaction is the formation of a self-dimer through a Watson-Crick-like pairing, creating a thermodynamically stable, eight-membered ring motif, often designated as an R2(2)(8) graph set.[5][6] This robust pairing is a cornerstone of their use in supramolecular chemistry. The 2-amino group, in particular, contributes significantly to the stability of these interactions.[7] However, other hydrogen bonding patterns can and do emerge, depending on the nature of the substituents on the core ring. These alternative interactions can lead to the formation of chains, ribbons, or more complex three-dimensional networks.[8]
Tautomerism: A Critical Consideration
Tautomers are structural isomers that readily interconvert, and for 2-aminoisocytosine, this typically involves the migration of a proton.[9] The molecule can exist in several tautomeric forms, with the amino-oxo and imino-oxo forms being the most common. The specific tautomer that crystallizes is highly sensitive to the solvent environment, pH, and the electronic nature of any substituents.[10] Misinterpretation of the dominant tautomeric form can lead to an incorrect understanding of the molecule's hydrogen bonding potential and, consequently, its biological function. Therefore, careful analysis of the crystal structure is required to unambiguously determine the tautomeric state.
Caption: Tautomeric equilibrium in 2-aminoisocytosine.
An Experimental Guide to Crystal Structure Determination
The journey from a synthesized powder to a refined crystal structure is a multi-step process that demands precision and patience. The quality of the final structure is entirely dependent on the quality of the initial crystals.
Synthesis of 2-Aminoisocytosine Derivatives
The synthesis of 2-aminoisocytosine derivatives often begins with commercially available starting materials, such as isocytosine or 2-amino-4,6-dihydroxypyrimidine. Standard organic chemistry transformations can then be employed to introduce the desired functional groups.
Exemplary Protocol: Synthesis of an N-Substituted Derivative
-
Reaction Setup: To a solution of 2-aminoisocytosine (1.0 eq) in a suitable aprotic solvent (e.g., dimethylformamide), add a base such as potassium carbonate (1.2 eq).
-
Addition of Electrophile: Slowly add the desired alkyl or aryl halide (1.1 eq) to the reaction mixture.
-
Reaction Monitoring: Heat the reaction to an appropriate temperature (e.g., 60-80 °C) and monitor its progress by thin-layer chromatography (TLC).
-
Workup: Once the reaction is complete, cool the mixture, and pour it into water to precipitate the product.
-
Purification: Collect the solid by filtration, wash with water, and then purify by recrystallization or column chromatography to obtain the pure derivative.
Rationale: The choice of an aprotic solvent prevents interference from solvent molecules with the nucleophilic substitution reaction. The base is necessary to deprotonate the isocytosine ring, making it more nucleophilic.
The Art and Science of Crystallization
Growing single crystals suitable for X-ray diffraction is often the most challenging step.[3] The goal is to allow the molecules to slowly and orderly arrange themselves into a crystalline lattice. For organic compounds like 2-aminoisocytosine derivatives, several techniques are commonly employed.[11]
Common Crystallization Techniques
| Technique | Description | Best For |
| Slow Evaporation | A solution of the compound is left undisturbed, allowing the solvent to evaporate slowly, thereby increasing the concentration until crystals form.[12] | Compounds that are moderately soluble and thermally stable. |
| Vapor Diffusion | A concentrated solution of the compound is placed in a small vial, which is then placed in a larger sealed container with a more volatile "anti-solvent" in which the compound is insoluble. The anti-solvent vapor slowly diffuses into the compound's solution, inducing crystallization.[12] | Growing high-quality crystals from small amounts of material. |
| Solvent Layering | A less dense anti-solvent is carefully layered on top of a more dense solution of the compound. Crystals form at the interface as the solvents slowly mix.[13] | Thermally sensitive compounds. |
| Slow Cooling | A saturated solution of the compound at an elevated temperature is allowed to cool slowly, reducing the solubility and causing crystallization.[13] | Compounds with a significant temperature-dependent solubility. |
Field Insights: From experience, a binary solvent system often yields the best results for this class of compounds. A solvent in which the compound is reasonably soluble (e.g., methanol, ethanol, or DMF) mixed with an anti-solvent in which it is poorly soluble (e.g., diethyl ether, hexane, or water) can provide the fine control over solubility needed for slow, ordered crystal growth.
X-ray Crystallography: From Diffraction to Structure
Once a suitable single crystal is obtained, X-ray crystallography provides the definitive method for determining its three-dimensional structure.[3]
Caption: Workflow for Crystal Structure Determination.
Step-by-Step Methodology for Single-Crystal X-ray Diffraction:
-
Crystal Mounting: A high-quality single crystal (typically 0.1-0.3 mm in size) is carefully selected under a microscope and mounted on a goniometer head.
-
Data Collection: The mounted crystal is placed in an X-ray diffractometer. A beam of monochromatic X-rays is directed at the crystal, which diffracts the X-rays in a specific pattern based on its internal atomic arrangement. The crystal is rotated during data collection to capture a complete diffraction pattern.
-
Structure Solution: The collected diffraction data is used to solve the "phase problem" and generate an initial electron density map of the unit cell.
-
Structure Refinement: An atomic model is built into the electron density map. The positions and thermal parameters of the atoms are then refined against the experimental data to achieve the best possible fit.[14]
-
Validation: The final structure is validated using software tools to check for geometric consistency and overall quality.
For materials where single crystals cannot be obtained, Powder X-ray Diffraction (PXRD) can be a valuable alternative for determining the crystal structure, although it is generally more challenging for complex organic molecules.[15]
Interpreting the Crystal Structure: From Data to Insights
The final output of a crystal structure determination is a Crystallographic Information File (CIF), which contains a wealth of information.
Key Crystallographic Parameters
A comparative analysis of crystallographic data from different derivatives can reveal subtle structural changes that have significant implications for their properties.
Table of Exemplary Crystallographic Data
| Parameter | Derivative A | Derivative B | Derivative C |
| Formula | C10H12N4O | C12H10N4O2 | C11H11N5O |
| Crystal System | Monoclinic | Orthorhombic | Triclinic |
| Space Group | P2(1)/c | P2(1)2(1)2(1) | P-1 |
| Unit Cell a (Å) | 8.54 | 6.57 | 7.21 |
| Unit Cell b (Å) | 12.32 | 12.21 | 9.87 |
| Unit Cell c (Å) | 10.11 | 22.08 | 11.05 |
| Key H-Bond (Å) | N-H···O (2.85) | N-H···N (2.91) | N-H···O (2.88) |
| π-π Stacking (Å) | 3.65 | N/A | 3.79 |
Note: Data is hypothetical for illustrative purposes.
Beyond Hydrogen Bonds: Other Intermolecular Interactions
While hydrogen bonds are often the primary organizing force, other non-covalent interactions play a crucial role in stabilizing the crystal lattice.[16] These include:
-
π-π Stacking: The aromatic rings of 2-aminoisocytosine derivatives can stack on top of each other, contributing to the overall stability of the crystal packing.[8]
-
van der Waals Forces: These weak, non-specific interactions are present between all atoms and contribute to the cohesive energy of the crystal.
-
Halogen Bonding: If the derivative contains a halogen atom, it can act as a Lewis acid and interact with a Lewis base, providing an additional directional interaction.
A comprehensive analysis of all these interactions is necessary to fully understand the crystal packing and its influence on the material's properties.
Applications in Drug Development and Materials Science
The detailed structural information obtained from X-ray crystallography is invaluable in several high-impact research areas.
Rational Drug Design
In drug discovery, understanding how a molecule binds to its biological target (e.g., an enzyme or receptor) is key to developing more potent and selective drugs.[17] Crystal structures of 2-aminoisocytosine derivatives can:
-
Inform Structure-Activity Relationships (SAR): By comparing the crystal structures of a series of derivatives with their biological activities, researchers can understand how specific structural features influence efficacy.
-
Guide Lead Optimization: The precise bond lengths, angles, and conformations observed in the crystal structure provide a starting point for computational modeling and the design of new analogs with improved binding properties.[18][19]
-
Identify Pharmacophoric Features: The three-dimensional arrangement of hydrogen bond donors and acceptors, and hydrophobic groups is critical for molecular recognition.
Crystal Engineering and Materials Science
The predictable self-assembly of 2-aminoisocytosine derivatives makes them excellent building blocks for the construction of novel supramolecular materials.[20] By modifying the substituents on the core structure, it is possible to tune the intermolecular interactions and control the resulting crystal packing, leading to materials with tailored properties such as:
-
Porosity: For applications in gas storage and separation.
-
Non-linear Optical Properties: For use in optoelectronics.
-
Chirality: For enantioselective separations and catalysis.
Conclusion and Future Perspectives
The study of the crystal structure of 2-aminoisocytosine derivatives provides a fascinating window into the principles of molecular recognition and self-assembly. The ability of these molecules to form robust, predictable hydrogen-bonded networks makes them highly attractive for both medicinal chemistry and materials science. As synthetic methods become more sophisticated and crystallographic techniques continue to advance, the opportunities to design and create novel 2-aminoisocytosine-based compounds with tailored structures and functions will undoubtedly expand. The insights gained from these structural studies will continue to be a driving force in the development of new therapeutics and advanced materials.
References
-
Liu, M., & Wei, J. (2025). Synthetic Strategies of Guanine Derivatives for Self‐Assembly in Supramolecular Chemistry. ResearchGate. Available from: [Link]
-
(n.d.). Guanine and cytosine‐containing acrylic supramolecular networks | Request PDF. ResearchGate. Available from: [Link]
-
Lachicotte, R. J. (n.d.). How To: Grow X-Ray Quality Crystals. University of Rochester Department of Chemistry. Available from: [Link]
-
Yu, M., et al. (2010). Supramolecular Porous Network Formed by Molecular Recognition between Chemically Modified Nucleobases Guanine and Cytosine. Miao Yu Lab. Available from: [Link]
-
Swart, M., et al. (2004). Supramolecular switches based on the guanine-cytosine (GC) Watson-Crick pair: effect of neutral and ionic substituents. PubMed. Available from: [Link]
-
Davis, J. T., & Spada, G. P. (2007). Supramolecular architectures generated by self-assembly of guanosine derivatives. Chemical Society Reviews. Available from: [Link]
-
Warwick, T. (2024). How to grow crystals for X-ray crystallography. IUCr Journals. Available from: [Link]
-
David, W. I. F., et al. (2025). A good-practice guide to solving and refining molecular organic crystal structures from laboratory powder X-ray diffraction data. PubMed Central. Available from: [Link]
-
Deschamps, J. R. (2008). X-Ray Crystallography of Chemical Compounds. PubMed Central. Available from: [Link]
-
Dinger, M. (2015). Crystal Growing Tips. University of Florida Center for Xray Crystallography. Available from: [Link]
-
(n.d.). Fig. 6 Tautomers of 2-pyrimidinamine and of isocytosine. ResearchGate. Available from: [Link]
-
Jebas, N. J., et al. (2016). Crystal structure of 2-aminopyridinium 6-chloronicotinate. PubMed Central. Available from: [Link]
-
Wawrzyniak, R., et al. (2021). Weak Interactions in the Structures of Newly Synthesized (–)-Cytisine Amino Acid Derivatives. MDPI. Available from: [Link]
-
Gurbanov, A. V., et al. (2021). Crystal structure and Hirshfeld surface analysis of 2-amino-6-[(1-phenylethyl)amino]-4-(thiophen-2-yl)pyridine-3,5-dicarbonitrile. IUCrData. Available from: [Link]
-
Ben-Salah, A., et al. (2022). Synthesis, crystal structure and Hirshfeld surface analysis of (2-amino-1-methylbenzimidazole-κN3)aquabis(4-oxopent-2-en-2-olato-κ2O,O′)nickel(II) ethanol monosolvate. PubMed Central. Available from: [Link]
-
Shimoni, L., & Glusker, J. P. (1995). Hydrogen bonding motifs of protein side chains: descriptions of binding of arginine and amide groups. PubMed Central. Available from: [Link]
-
Shimoni, L., & Glusker, J. P. (1995). Hydrogen bonding motifs of protein side chains: descriptions of binding of arginine and amide groups. PubMed. Available from: [Link]
-
Sugimoto, N., et al. (2000). Roles of the Amino Group of Purine Bases in the Thermodynamic Stability of DNA Base Pairing. MDPI. Available from: [Link]
-
Chemistry For Everyone. (2025). How Do Amino Acids Form Hydrogen Bonds?. YouTube. Available from: [Link]
-
Kulkarni, S. A. (2022). What impact does tautomerism have on drug discovery and development?. PubMed Central. Available from: [Link]
-
Warwick, T. (2024). Hydrogen bonds: A Simple Explanation of Why They Form. Bitesize Bio. Available from: [Link]
-
Gurbanov, A. V., et al. (2023). Crystal structure and Hirshfeld surface analysis of 1,6-diamino-2-oxo-4-(thiophen-2-yl). IUCrData. Available from: [Link]
-
Vamathevan, J., et al. (2019). Applications of machine learning in drug discovery and development. PubMed Central. Available from: [Link]
-
The Organic Chemistry Tutor. (2016). Keto Enol Tautomerism - Acidic & Basic Conditions. YouTube. Available from: [Link]
-
Smietanski, M., et al. (2025). Multi-Criteria Decision Analysis in Drug Discovery. MDPI. Available from: [Link]
-
Smith, D. A. (2009). Applying science to drug discovery. PubMed. Available from: [Link]
-
Organic Chemistry Tutor. (2024). Keto-Enol Tautomerism. YouTube. Available from: [Link]
-
Fleming, N. (2025). Artificial Intelligence in Small-Molecule Drug Discovery: A Critical Review of Methods, Applications, and Real-World Outcomes. MDPI. Available from: [Link]
-
Kumar, A., et al. (2023). AI in drug discovery and its clinical relevance. PubMed Central. Available from: [Link]
Sources
- 1. miaoyulab.com [miaoyulab.com]
- 2. researchgate.net [researchgate.net]
- 3. X-Ray Crystallography of Chemical Compounds - PMC [pmc.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 5. Hydrogen bonding motifs of protein side chains: descriptions of binding of arginine and amide groups - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Hydrogen bonding motifs of protein side chains: descriptions of binding of arginine and amide groups - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. mdpi.com [mdpi.com]
- 8. Crystal structure and Hirshfeld surface analysis of 2-amino-6-[(1-phenylethyl)amino]-4-(thiophen-2-yl)pyridine-3,5-dicarbonitrile - PMC [pmc.ncbi.nlm.nih.gov]
- 9. What impact does tautomerism have on drug discovery and development? - PMC [pmc.ncbi.nlm.nih.gov]
- 10. researchgate.net [researchgate.net]
- 11. How To [chem.rochester.edu]
- 12. Crystal Growing Tips » The Center for Xray Crystallography » University of Florida [xray.chem.ufl.edu]
- 13. journals.iucr.org [journals.iucr.org]
- 14. Synthesis, crystal structure and Hirshfeld surface analysis of (2-amino-1-methylbenzimidazole-κN3)aquabis(4-oxopent-2-en-2-olato-κ2O,O′)nickel(II) ethanol monosolvate - PMC [pmc.ncbi.nlm.nih.gov]
- 15. A good-practice guide to solving and refining molecular organic crystal structures from laboratory powder X-ray diffraction data - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Crystal structure of 2-aminopyridinium 6-chloronicotinate - PMC [pmc.ncbi.nlm.nih.gov]
- 17. Applying science to drug discovery - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. Applications of machine learning in drug discovery and development - PMC [pmc.ncbi.nlm.nih.gov]
- 19. mdpi.com [mdpi.com]
- 20. Supramolecular architectures generated by self-assembly of guanosine derivatives - Chemical Society Reviews (RSC Publishing) [pubs.rsc.org]
Methodological & Application
Application Notes and Protocols for the Incorporation of 2-Aminoisocytosine into Oligonucleotides
For Researchers, Scientists, and Drug Development Professionals
Authored by a Senior Application Scientist
Abstract
This comprehensive guide provides a detailed technical overview and practical protocols for the incorporation of the modified nucleobase, 2-Aminoisocytosine (also referred to as 7-amino-1H-pyrazolo[4,3-d]pyrimidin-5(4H)-one or its tautomers), into synthetic oligonucleotides. As a key component of expanded genetic alphabets and a tool for enhancing the therapeutic and diagnostic potential of nucleic acids, the successful integration of 2-Aminoisocytosine demands a nuanced understanding of its unique chemical properties. This document delineates the synthesis of the requisite 2-Aminoisocytosine phosphoramidite, optimized coupling parameters for solid-phase synthesis, and robust deprotection and purification strategies. Furthermore, it explores the impact of 2-Aminoisocytosine incorporation on oligonucleotide stability and enzymatic recognition, and details its applications in the development of high-affinity aptamers and specific diagnostic probes.
Introduction: The Significance of 2-Aminoisocytosine in Oligonucleotide Chemistry
The canonical four-letter genetic alphabet (A, T, G, C) has been the foundation of molecular biology. However, the pursuit of novel functionalities in nucleic acids for therapeutic and diagnostic purposes has led to the development of expanded genetic alphabets. 2-Aminoisocytosine (isoC) is a synthetic purine analogue that, in conjunction with its complementary partner isoguanine (isoG), forms a third, stable base pair. This expanded genetic information system opens up new avenues for the creation of oligonucleotides with tailored properties.
The incorporation of 2-Aminoisocytosine into DNA and RNA oligonucleotides can confer several advantageous characteristics:
-
Enhanced Specificity: The unique hydrogen bonding pattern of the isoC-isoG pair, distinct from the natural A-T and G-C pairs, allows for highly specific recognition and binding events. This is particularly valuable in the design of diagnostic probes and antisense oligonucleotides where off-target effects are a primary concern.
-
Increased Thermal Stability: The isoC-isoG pair typically forms three hydrogen bonds, contributing to a higher melting temperature (Tm) of the resulting duplex. This enhanced stability is beneficial for applications requiring robust hybridization under stringent conditions.
-
Novel Catalytic and Binding Properties: The introduction of a non-natural base pair expands the chemical diversity of oligonucleotides, enabling the selection of aptamers and DNAzymes with novel binding affinities and catalytic activities that are not achievable with the standard four bases.
This guide will provide the necessary technical foundation and step-by-step protocols to empower researchers to harness the potential of 2-Aminoisocytosine in their oligonucleotide-based applications.
The Chemistry of 2-Aminoisocytosine Phosphoramidite Synthesis
The successful incorporation of 2-Aminoisocytosine into an oligonucleotide chain via automated solid-phase synthesis necessitates the preparation of a stable and reactive phosphoramidite building block. This process involves the synthesis of the 2-Aminoisocytosine nucleoside followed by the strategic application of protecting groups and phosphitylation.
Synthesis of the 2-Aminoisocytosine Nucleoside
The synthesis of the 2-Aminoisocytosine deoxyribonucleoside is a multi-step process that typically starts from a commercially available purine derivative. While several synthetic routes have been described in the literature, a common approach involves the construction of the pyrazolopyrimidine core followed by glycosylation with a protected deoxyribose sugar.
Protecting Group Strategy: A Critical Consideration
The exocyclic amino group of 2-Aminoisocytosine is nucleophilic and requires protection to prevent side reactions during oligonucleotide synthesis. The choice of protecting group is critical and must be compatible with the conditions of phosphoramidite chemistry and subsequent deprotection steps. A commonly employed protecting group for the N2-amino group of 2-Aminoisocytosine is the isobutyryl (iBu) group. This group provides adequate protection during synthesis and can be removed under standard ammoniacal deprotection conditions.
The 5'-hydroxyl group of the deoxyribose is protected with the acid-labile dimethoxytrityl (DMT) group, which is standard practice in phosphoramidite chemistry. The 3'-hydroxyl group is phosphitylated to introduce the reactive phosphoramidite moiety.
Phosphitylation of the Protected Nucleoside
The final step in preparing the phosphoramidite building block is the phosphitylation of the 3'-hydroxyl group of the N2-isobutyryl-5'-O-DMT-2'-deoxy-2-Aminoisocytosine. This is typically achieved by reacting the protected nucleoside with 2-cyanoethyl N,N-diisopropylchlorophosphoramidite in the presence of a non-nucleophilic base, such as N,N-diisopropylethylamine (DIPEA).
Incorporation of 2-Aminoisocytosine into Oligonucleotides: A Step-by-Step Protocol
The incorporation of the 2-Aminoisocytosine phosphoramidite into a growing oligonucleotide chain follows the standard cycle of automated solid-phase DNA synthesis. However, optimization of certain parameters is recommended to ensure high coupling efficiency.
The Solid-Phase Synthesis Cycle
The synthesis is performed on a solid support, typically controlled pore glass (CPG), and proceeds in the 3' to 5' direction. Each cycle of nucleotide addition consists of four main steps:
-
Deblocking (Detritylation): Removal of the 5'-DMT protecting group with a mild acid (e.g., trichloroacetic acid in dichloromethane) to expose the 5'-hydroxyl group for the next coupling reaction.
-
Coupling: Activation of the incoming 2-Aminoisocytosine phosphoramidite with an activator (e.g., 5-(ethylthio)-1H-tetrazole) and its subsequent reaction with the free 5'-hydroxyl group of the support-bound oligonucleotide chain.[1]
-
Capping: Acetylation of any unreacted 5'-hydroxyl groups to prevent the formation of deletion mutants in the final product.[2]
-
Oxidation: Conversion of the unstable phosphite triester linkage to a stable phosphate triester using an oxidizing agent (e.g., iodine in a THF/pyridine/water mixture).[2]
dot
Caption: The four-step cycle of phosphoramidite-based oligonucleotide synthesis.
Optimized Coupling Conditions for 2-Aminoisocytosine
While standard coupling protocols can be effective, for modified phosphoramidites like that of 2-Aminoisocytosine, extending the coupling time can improve incorporation efficiency.
| Parameter | Standard Conditions | Recommended for 2-Aminoisocytosine |
| Phosphoramidite Conc. | 0.1 M | 0.1 M |
| Activator | 5-(Ethylthio)-1H-tetrazole | 5-(Ethylthio)-1H-tetrazole |
| Coupling Time | 30-60 seconds | 90-120 seconds |
Rationale for Extended Coupling Time: Modified phosphoramidites can sometimes exhibit slightly slower reaction kinetics compared to their canonical counterparts. Increasing the coupling time ensures that the reaction goes to completion, maximizing the yield of the full-length oligonucleotide.
Deprotection and Purification of 2-Aminoisocytosine-Containing Oligonucleotides
Following synthesis, the oligonucleotide is cleaved from the solid support, and all protecting groups are removed. The final product is then purified to remove any truncated sequences or byproducts.
Deprotection Protocol
A standard deprotection protocol using concentrated ammonium hydroxide is generally effective for oligonucleotides containing 2-Aminoisocytosine protected with an isobutyryl group. However, milder conditions can also be employed.
Standard Deprotection:
-
Reagent: Concentrated ammonium hydroxide.
-
Temperature: 55°C.
-
Time: 8-12 hours.
Mild Deprotection (for sensitive modifications):
-
Reagent: A mixture of aqueous ammonia and methylamine (AMA).
-
Temperature: Room temperature to 55°C.
-
Time: 1-2 hours.
It is crucial to ensure complete removal of all protecting groups, which can be verified by mass spectrometry.
Purification by High-Performance Liquid Chromatography (HPLC)
Reverse-phase HPLC (RP-HPLC) is a highly effective method for purifying synthetic oligonucleotides.[3] The separation is based on the hydrophobicity of the oligonucleotide, and "DMT-on" purification is often preferred.
DMT-on RP-HPLC Purification Workflow:
-
The final 5'-DMT group is left on the oligonucleotide after synthesis.
-
The crude, deprotected oligonucleotide is injected onto an RP-HPLC column (e.g., C18).
-
The DMT-on, full-length product is more hydrophobic and elutes later than the "DMT-off" failure sequences.
-
The fraction containing the DMT-on product is collected.
-
The DMT group is removed by treatment with a mild acid (e.g., 80% acetic acid).
-
The detritylated oligonucleotide is desalted.
dot
Caption: Workflow for DMT-on reverse-phase HPLC purification of synthetic oligonucleotides.
Properties of 2-Aminoisocytosine-Containing Oligonucleotides
Thermal Stability
The incorporation of 2-Aminoisocytosine, when paired with isoguanine, generally leads to an increase in the thermal stability of the DNA or RNA duplex. The melting temperature (Tm) is a key parameter for assessing this stability.
Experimental Protocol for Thermal Denaturation Studies:
-
Sample Preparation: Anneal equimolar amounts of the 2-Aminoisocytosine-containing oligonucleotide and its complementary strand (containing isoguanine) in a suitable buffer (e.g., 10 mM sodium phosphate, 100 mM NaCl, pH 7.0).
-
UV-Vis Spectrophotometry: Use a UV-Vis spectrophotometer equipped with a temperature controller to monitor the absorbance of the sample at 260 nm as the temperature is increased at a constant rate (e.g., 1°C/minute).
-
Data Analysis: The Tm is determined as the temperature at which 50% of the duplex has dissociated into single strands, which corresponds to the midpoint of the melting curve.[4]
A comparative analysis with an unmodified duplex of the same sequence will quantify the stabilizing effect of the isoC-isoG pair.
Enzymatic Recognition
The ability of DNA and RNA polymerases to recognize and incorporate 2-Aminoisocytosine triphosphate (isoCTP) is crucial for applications involving enzymatic synthesis and amplification. Studies have shown that some polymerases can incorporate isoCTP opposite an isoG template with varying degrees of efficiency and fidelity.[3]
Protocol for In Vitro DNA Polymerase Incorporation Assay:
-
Reaction Setup: Prepare a reaction mixture containing a primer-template duplex with an isoG in the template strand, a DNA polymerase (e.g., Klenow fragment), the four standard dNTPs, and isoCTP.
-
Reaction Incubation: Incubate the reaction at the optimal temperature for the polymerase.
-
Product Analysis: Analyze the reaction products by denaturing polyacrylamide gel electrophoresis (PAGE) to visualize the full-length product, indicating successful incorporation of isoC.
The fidelity of incorporation can be assessed by including mismatched dNTPs in the reaction and quantifying the relative amounts of correct versus incorrect incorporation.
Applications of 2-Aminoisocytosine-Containing Oligonucleotides
The unique properties of 2-Aminoisocytosine make it a valuable tool in various research and development areas.
High-Affinity Aptamers
Aptamers are short, single-stranded oligonucleotides that can fold into specific three-dimensional structures to bind to a target molecule with high affinity and specificity. The expanded chemical space offered by the inclusion of 2-Aminoisocytosine in the aptamer library can lead to the selection of aptamers with superior binding properties.
Aptamer Selection (SELEX) with an Expanded Alphabet:
-
Library Synthesis: Synthesize a random oligonucleotide library containing 2-Aminoisocytosine in place of or in addition to the standard bases.
-
Selection: Incubate the library with the target molecule and partition the bound sequences from the unbound sequences.
-
Amplification: Amplify the bound sequences using a polymerase capable of recognizing the isoC-isoG pair.
-
Iterative Rounds: Repeat the selection and amplification steps for several rounds to enrich for high-affinity aptamers.
Specific Diagnostic Probes
The high specificity of the isoC-isoG base pair can be leveraged to design highly specific diagnostic probes for the detection of target nucleic acid sequences. A probe containing 2-Aminoisocytosine will only hybridize to a target sequence containing the complementary isoguanine, thereby reducing the likelihood of false-positive signals from off-target hybridization.
Conclusion
The incorporation of 2-Aminoisocytosine into oligonucleotides represents a significant advancement in nucleic acid chemistry, offering enhanced properties and expanded functionalities. By following the detailed protocols and considering the specific chemical characteristics outlined in this guide, researchers can successfully synthesize and utilize 2-Aminoisocytosine-modified oligonucleotides to push the boundaries of therapeutic and diagnostic innovation.
References
- Coupling Pathways and Activation Mechanisms in Phosphoramidite Reactions. (URL not provided)
- RP-HPLC Purification of Oligonucleotides. Mass Spectrometry Research Facility. (URL not provided)
-
Oligonucleotide duplexes containing 2'-amino-2'-deoxycytidines: thermal stability and chemical reactivity. Nucleic Acids Research. (URL: [Link])
-
Protecting Groups in Oligonucleotide Synthesis. Springer Nature Experiments. (URL: [Link])
-
Understanding the Fidelity and Specificity of DNA Polymerase I. PMC - NIH. (URL: [Link])
-
What Is DNA Polymerase Fidelity? - Chemistry For Everyone. YouTube. (URL: [Link])
-
The A, B, C, D's of replicative DNA polymerase fidelity. PubMed Central - NIH. (URL: [Link])
-
Decreased fidelity of DNA polymerase activity during N-2-fluorenylacetamide hepatocarcinogenesis. PubMed. (URL: [Link])
-
On the fidelity of DNA polymerase alpha: the influence of alpha-thio dNTPs, Mn2+ and mismatch repair. PubMed. (URL: [Link])
-
Solid-phase oligonucleotide synthesis. ATDBio. (URL: [Link])
-
Protocol for the Solid-phase Synthesis of Oligomers of RNA Containing a 2'-O-thiophenylmethyl Modification and Characterization via Circular Dichroism. NIH. (URL: [Link])
-
Development of Cell-Specific Aptamers: Recent Advances and Insight into the Selection Procedures. NIH. (URL: [Link])
-
Phosphoramidite Chemistry for DNA Synthesis. Twist Bioscience. (URL: [Link])
-
Coupling Activators for the Oligonucleotide Synthesis via Phosphoramidite Approach. ResearchGate. (URL: [Link])
- Rapid Thermal Stability Screening of Oligonucleotides Using the TA Instruments RS-DSC. (URL not provided)
-
Phosphoramidite Chemistry. Eurofins Genomics. (URL: [Link])
-
Chemical synthesis of oligonucleotides|Phosphoramidite Method|. YouTube. (URL: [Link])
- Preparation of nucleoside phosphoramidites and oligonucleotide synthesis.
-
A comparative study of the thermal stability of oligodeoxyribonucleotides containing 5-substituted 2'-deoxyuridines. PubMed. (URL: [Link])
-
Development of aptamers specific for potential diagnostic targets in Burkholderia pseudomallei. PubMed. (URL: [Link])
-
Optimization of parameters for semiempirical methods VI: More modifications to the NDDO approximations and re-optimization of parameters. ResearchGate. (URL: [Link])
- Comparative Thermal Stability of Oligonucleotides Containing 5'-Amino-5'-deoxyuridine: A Guide for Researchers. Benchchem. (URL: not available)
-
Small-Molecule Binding Aptamers: Selection Strategies, Characterization, and Applications. ResearchGate. (URL: [Link])
-
Development of dual aptamers-functionalized c-MET PROTAC degraders for targeted therapy of osteosarcoma. Theranostics. (URL: [Link])
-
New insight into clinical development of nucleic acid aptamers. Semantic Scholar. (URL: [Link])
-
A comparative study of the thermal stability of oligodeoxyribonucleotides containing 5-substituted 2'-deoxyuridines. PMC - NIH. (URL: [Link])
Sources
- 1. New Protecting Group Strategies for the Solid-Phase Synthesis and Modification of Peptides, Oligonucleotides, and Oligosaccharides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. quod.lib.umich.edu [quod.lib.umich.edu]
- 3. Understanding the Fidelity and Specificity of DNA Polymerase I - PMC [pmc.ncbi.nlm.nih.gov]
- 4. pdf.benchchem.com [pdf.benchchem.com]
Protocols for using 2-Aminoisocytosine phosphoramidite
An Application Guide to the Synthesis of Oligonucleotides Containing 2-Aminoisocytosine Phosphoramidite
Introduction: Expanding the Genetic Alphabet
The central dogma of molecular biology is founded on the elegant pairing of four nucleobases: Adenine (A) with Thymine (T), and Guanine (G) with Cytosine (C). However, the fields of synthetic biology, advanced diagnostics, and therapeutics are increasingly leveraging an expanded genetic alphabet. This involves the incorporation of unnatural base pairs (UBPs) to bestow novel functions upon nucleic acids.[1] A pioneering and well-studied UBP is the pairing of 2-Aminoisocytosine (isoC) with isoguanine (isoG).[1]
This artificial pair, first proposed by Alexander Rich in 1962, forms a specific hydrogen-bonding pattern distinct from the natural A-T and G-C pairs.[1] The integration of isoC into oligonucleotides via its phosphoramidite derivative is a powerful tool, but it presents unique chemical challenges that demand specialized protocols. This guide provides a comprehensive overview, detailed protocols, and the underlying chemical rationale for the successful synthesis, deprotection, and purification of oligonucleotides containing 2-Aminoisocytosine. It is designed for researchers, scientists, and drug development professionals seeking to harness the potential of this non-canonical base.
The 2-Aminoisocytosine Phosphoramidite Monomer: Structure and Function
The successful incorporation of isoC into a growing oligonucleotide chain via automated solid-phase synthesis requires its conversion into a phosphoramidite monomer.[2][3] This chemical modification equips the nucleoside with the necessary protecting groups and the reactive phosphite moiety essential for the synthesis cycle.
-
5'-O-Dimethoxytrityl (DMT) Group: This acid-labile group protects the 5'-hydroxyl, preventing self-polymerization. Its removal at the start of each coupling cycle generates the reactive 5'-OH necessary for chain elongation.[3][4]
-
Exocyclic Amine Protecting Group: The 2-amino group of isocytosine is typically protected to prevent side reactions during synthesis. The choice of this group is critical and must be compatible with the final deprotection conditions.
-
Phosphoramidite Moiety: A trivalent phosphorus group, typically a β-cyanoethyl N,N-diisopropylphosphoramidite, is attached to the 3'-hydroxyl. The diisopropylamino group is an excellent leaving group during the acid-catalyzed coupling step, while the cyanoethyl group protects the phosphate backbone and is removed during the final deprotection.[3]
Caption: The four-step cycle of phosphoramidite-based oligonucleotide synthesis.
Protocol 1: Automated Incorporation of isoC Phosphoramidite
While the synthesis cycle is standard, the coupling step for modified bases like isoC often requires optimization for maximum efficiency. Purine bases or other bulky monomers may require longer coupling times to achieve high yields. [] Objective: To efficiently couple 2-Aminoisocytosine phosphoramidite to the growing oligonucleotide chain on an automated DNA synthesizer.
Materials:
-
High-purity, anhydrous acetonitrile
-
2-Aminoisocytosine phosphoramidite
-
Activator solution: 0.25 M 5-(Ethylthio)-1H-tetrazole (ETT) in acetonitrile is recommended. [4][6]* Standard synthesis reagents (Deblocking, Capping, Oxidation solutions)
-
Automated DNA/RNA synthesizer
Procedure:
-
Phosphoramidite Preparation: Dissolve the 2-Aminoisocytosine phosphoramidite in anhydrous acetonitrile to a final concentration of 0.1 M. Ensure the solution is completely dissolved and protected from moisture.
-
Synthesizer Setup: Install the isoC phosphoramidite solution on a designated port on the synthesizer.
-
Synthesis Program: Program the synthesis sequence. For the step involving the incorporation of isoC, modify the standard coupling parameters as outlined in the table below.
Table 1: Recommended Synthesizer Parameters for isoC Coupling
| Step | Reagent | Duration | Causality and Key Insights |
|---|---|---|---|
| Deblocking | Trichloroacetic Acid (TCA) in DCM | 60-120 sec | Standard step to remove the 5'-DMT group, exposing the hydroxyl for coupling. [4] |
| Coupling | isoC Phosphoramidite + Activator (ETT) | 120-300 sec | Critical Step: Modified phosphoramidites may have different reaction kinetics. An extended coupling time ensures the reaction goes to completion, maximizing stepwise yield and minimizing failure sequences. |
| Capping | Acetic Anhydride / N-Methylimidazole | 30-60 sec | Essential for blocking any unreacted 5'-OH groups to prevent the formation of n-1 deletion impurities. [3][6] |
| Oxidation | Iodine / H₂O / Pyridine / THF | 30-60 sec | Converts the unstable phosphite triester linkage into a stable pentavalent phosphate triester, securing the newly added base. [4][6]|
Post-Synthesis: The Critical Deprotection Step
The deprotection of oligonucleotides containing isoC is the most crucial phase of the entire process and a common point of failure. The isoC nucleoside is chemically unstable under the harsh alkaline conditions (e.g., concentrated ammonium hydroxide at 55 °C) typically used for standard DNA deprotection. [1]These conditions can lead to deamination of the 2-amino group, converting isoC to a different base and rendering the oligonucleotide non-functional. [7] Therefore, a mild deprotection strategy is mandatory. This involves using less aggressive basic reagents and often requires that the standard DNA phosphoramidites (dA, dC, dG) used in the synthesis carry labile protecting groups (e.g., Pac-dA, Ac-dC, iPr-Pac-dG). [8] Table 2: Comparison of Deprotection Conditions for isoC-Oligonucleotides
| Reagent | Temperature | Time | Suitability for isoC | Key Considerations |
|---|---|---|---|---|
| Conc. Ammonium Hydroxide | 55 °C | 8-16 hours | Not Recommended | High risk of isoC deamination. [7] |
| AMA (Ammonium Hydroxide / 40% Methylamine 1:1) | Room Temp | 2 hours | Suitable with Caution | Faster than other mild methods. Requires the use of Ac-dC to prevent base modification. [8][9] |
| t-Butylamine / H₂O (1:3) | 60 °C | 6 hours | Recommended | Effective and mild. Compatible with standard base protecting groups on A and G, but Ac-dC is still advised. [8][10] |
| 0.05 M K₂CO₃ in Methanol | Room Temp | 4-17 hours | Highly Recommended (Ultra-Mild) | The gentlest method, ideal for very sensitive modifications. Requires the use of UltraMILD phosphoramidites (Pac-dA, iPr-Pac-dG, Ac-dC) for the entire sequence. [8][9]|
Protocol 2: Ultra-Mild Deprotection of isoC-Containing Oligonucleotides
Objective: To cleave the oligonucleotide from the solid support and remove all protecting groups without damaging the incorporated isoC base. This protocol assumes UltraMILD phosphoramidites were used for A, C, and G positions.
Materials:
-
Synthesized oligonucleotide on solid support (in synthesis column)
-
0.05 M Potassium Carbonate (K₂CO₃) in anhydrous Methanol
-
Syringes
-
Collection microcentrifuge tube
Procedure:
-
Column Preparation: After synthesis, remove the column from the synthesizer and dry the solid support thoroughly with a stream of argon or under vacuum.
-
Reagent Application: Using a syringe, slowly pass 1 mL of the 0.05 M K₂CO₃ in methanol solution through the synthesis column.
-
Cleavage & Deprotection: Collect this initial eluent in a 1.5 mL microcentrifuge tube. Seal the tube and let it stand at room temperature. The required incubation time depends on the capping chemistry used during synthesis.
-
If phenoxyacetic anhydride was used in Capping Mix A: Incubate for 4 hours at room temperature. [8] * If acetic anhydride was used in Capping Mix A: Incubate overnight (~16 hours) at room temperature to ensure complete removal of acetyl groups from any capped dG. [8]4. Product Recovery: After incubation, the solution contains the fully deprotected oligonucleotide. Dry the sample using a centrifugal vacuum concentrator.
-
-
Resuspension: Resuspend the dried oligonucleotide pellet in an appropriate buffer (e.g., sterile, nuclease-free water or TE buffer) for quantification and purification.
Purification and Quality Control
Purification is essential to separate the desired full-length oligonucleotide from truncated failure sequences and byproducts from the synthesis and deprotection steps. [11]The choice of method depends on the length of the oligonucleotide, the required purity, and the scale of the synthesis.
Caption: Decision workflow for selecting an oligonucleotide purification method.
Table 3: Comparison of Purification Methods
| Method | Principle | Typical Purity | Yield | Best Suited For |
|---|---|---|---|---|
| Reverse-Phase HPLC (RP-HPLC) | Separation by hydrophobicity | >85% [12] | Good | Shorter oligonucleotides (<50 bases) and those with hydrophobic modifications. Trityl-on purification is highly effective for removing failure sequences. [12][13] |
| Anion-Exchange HPLC (AEX-HPLC) | Separation by charge (phosphate backbone length) | >90% | Good | Longer oligonucleotides (40-100 bases) and sequences prone to secondary structure. [13][14] |
| Denaturing PAGE | Separation by size and charge | >95-99% [15] | Lower | Applications requiring the highest possible purity, such as crystallography or therapeutic screening. [12][15] |
| Desalting / Cartridge Purification | Size exclusion or reverse-phase | Moderate | High | Removing salts and small molecule impurities. Acceptable for non-critical applications like routine PCR with short oligos (<35 bases). [15]|
Final Characterization
After purification, rigorous quality control is necessary to confirm the identity and purity of the final product.
-
Mass Spectrometry (LC-MS or MALDI-TOF): This is the definitive method to confirm the successful synthesis of the oligonucleotide. The experimentally measured molecular weight must match the calculated theoretical mass, which will account for the incorporation of the isoC base(s). [16][17][18]* Analytical HPLC: An analytical run on either an RP or AEX column is used to assess the purity of the final sample, confirming the removal of failure sequences. [19]* UV Spectrophotometry: Measurement of absorbance at 260 nm (A₂₆₀) is used to accurately quantify the concentration of the final oligonucleotide product.
Conclusion
The successful synthesis of oligonucleotides containing 2-Aminoisocytosine is readily achievable but requires a departure from standard protocols, particularly concerning the deprotection step. By understanding the chemical lability of the isoC base and implementing an optimized workflow—from extended coupling times to mandatory mild deprotection and appropriate purification—researchers can reliably produce high-quality modified oligonucleotides. These molecules are key enablers for expanding the functional repertoire of nucleic acids in cutting-edge research and development.
References
-
Purification and characterisation of oligonucleotides. (n.d.). ATDBio. Retrieved from [Link]
-
Oligonucleotide Purification. (n.d.). Phenomenex. Retrieved from [Link]
-
Purifying Oligonucleotides. (n.d.). Waters Corporation. Retrieved from [Link]
-
Isocytosine and Isoguanosine base analogs. (n.d.). Bio-Synthesis Inc. Retrieved from [Link]
-
Kimoto, M., & Hirao, I. (2020). Unnatural base pair systems toward the expansion of the genetic alphabet in the central dogma. Chemical Society Reviews, 49(21), 7602-7626. Retrieved from [Link]
-
Switzer, C., Moroney, S. E., & Benner, S. A. (1993). Enzymatic recognition of the base pair between isocytidine and isoguanosine. Biochemistry, 32(39), 10489–10496. Retrieved from [Link]
-
Deprotection Guide. (n.d.). Glen Research. Retrieved from [Link]
-
Guga, P., & Rzeszotarska, J. (2011). Advanced method for oligonucleotide deprotection. Nucleic Acids Research, 39(12), e82. Retrieved from [Link]
-
Oligonucleotide synthesis. (2023, December 29). In Wikipedia. Retrieved from [Link]
-
Roberts, C., Bandaru, R., & Wengel, J. (1994). Synthesis of oligoribonucleotides containing isoguanosine. Helvetica Chimica Acta, 77(4), 847-856. Retrieved from [Link]
-
Phosphoramidite Chemistry for DNA Synthesis. (n.d.). Twist Bioscience. Retrieved from [Link]
-
Pomerantz, S. C., & McCloskey, J. A. (2000). Characterization of synthetic oligonucleotides containing biologically important modified bases by MALDI-TOF mass spectrometry. Nucleic Acids Research, 28(14), e63. Retrieved from [Link]
-
Polushin, N. N., Morocho, A. M., Chen, B. C., & Cohen, J. S. (1994). On the rapid deprotection of synthetic oligonucleotides and analogs. Nucleic Acids Research, 22(4), 639–645. Retrieved from [Link]
-
Mori, H., Sumi, K., Furuya, T., & Ashihara, E. (2022). Development of Phosphoramidite Reagents for the Synthesis of Base-Labile Oligonucleotides Modified with a Linear Aminoalkyl and Amino-PEG Linker at the 3′-End. Molecules, 27(23), 8565. Retrieved from [Link]
-
On-Column Deprotection of Oligonucleotides in Organic Solvents. (n.d.). Glen Research. Retrieved from [Link]
-
Deprotection - Volume 1 - Deprotect to Completion. (n.d.). Glen Research. Retrieved from [Link]
-
Sarrut, M., & D’Attoma, J. (2022). Advancements in the characterisation of oligonucleotides by high performance liquid chromatography-mass spectrometry in 2021: A short review. Journal of Pharmaceutical and Biomedical Analysis, 212, 114649. Retrieved from [Link]
-
Cummins, L. L., Owens, S. R., Risen, L. M., Lesnik, E. A., Freier, S. M., McGee, D., Guinosso, C. J., & Cook, P. D. (1995). Characterization of fully 2'-modified oligoribonucleotide hetero- and homoduplex hybridization and nuclease sensitivity. Nucleic Acids Research, 23(11), 2019–2024. Retrieved from [Link]
-
Pourshahian, S. (2021). Therapeutic oligonucleotides, impurities, degradants, and their characterization by mass spectrometry. Mass Spectrometry Reviews, 40(2), 75–109. Retrieved from [Link]
-
Dahl, B. H., Nielsen, J., & Dahl, O. (1987). Mechanistic studies on the phosphoramidite coupling reaction in oligonucleotide synthesis. I. Evidence for nucleophilic catalysis by tetrazole and rate variations with the phosphorus substituents. Nucleic Acids Research, 15(4), 1729–1743. Retrieved from [Link]
-
Petersen, M. A., & Wengel, J. (2021). On-demand synthesis of phosphoramidites. Communications Chemistry, 4(1), 63. Retrieved from [Link]
-
Thiophosphoramidites and Their Use in Synthesizing Oligonucleotide Phosphorodithioate Linkages. (n.d.). Glen Research. Retrieved from [Link]
-
Wagner, E., Oberhauser, B., Holzner, A., Brunar, H., Issakides, G., Schaffner, G., Cotten, M., Knollmüller, M., & Noe, C. R. (1991). A simple procedure for the preparation of protected 2'-O-methyl or 2'-O-ethyl ribonucleoside-3'-O-phosphoramidites. Nucleic Acids Research, 19(21), 5965–5971. Retrieved from [Link]
Sources
- 1. Unnatural base pair systems toward the expansion of the genetic alphabet in the central dogma - PMC [pmc.ncbi.nlm.nih.gov]
- 2. Oligonucleotide synthesis - Wikipedia [en.wikipedia.org]
- 3. twistbioscience.com [twistbioscience.com]
- 4. pdf.benchchem.com [pdf.benchchem.com]
- 6. Standard Protocol for Solid-Phase Oligonucleotide Synthesis using Unmodified Phosphoramidites | LGC, Biosearch Technologies [biosearchtech.com]
- 7. Enzymatic recognition of the base pair between isocytidine and isoguanosine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. glenresearch.com [glenresearch.com]
- 9. Development of Phosphoramidite Reagents for the Synthesis of Base-Labile Oligonucleotides Modified with a Linear Aminoalkyl and Amino-PEG Linker at the 3′-End - PMC [pmc.ncbi.nlm.nih.gov]
- 10. glenresearch.com [glenresearch.com]
- 11. Oligonucleotide Purification: Phenomenex [phenomenex.com]
- 12. Oligonucleotide Purification Methods for Your Research | Thermo Fisher Scientific - TW [thermofisher.com]
- 13. atdbio.com [atdbio.com]
- 14. waters.com [waters.com]
- 15. labcluster.com [labcluster.com]
- 16. Characterization of synthetic oligonucleotides containing biologically important modified bases by MALDI-TOF mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 17. documents.thermofisher.com [documents.thermofisher.com]
- 18. THERAPEUTIC OLIGONUCLEOTIDES, IMPURITIES, DEGRADANTS, AND THEIR CHARACTERIZATION BY MASS SPECTROMETRY - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. Advancements in the characterisation of oligonucleotides by high performance liquid chromatography‐mass spectrometry in 2021: A short review - PMC [pmc.ncbi.nlm.nih.gov]
Application Notes & Protocols: The Role of 2-Aminoisocytosine in Genetic Alphabet Expansion
Authored for Researchers, Scientists, and Drug Development Professionals
Introduction: Beyond the Four-Letter Code
For billions of years, life has stored its genetic blueprint in a simple yet powerful four-letter alphabet: Adenine (A), Guanine (G), Cytosine (C), and Thymine (T). The specific pairing of A with T and G with C, governed by Watson-Crick hydrogen bonding, forms the basis of genetic information storage, replication, and transcription.[1] While this system has given rise to the vast diversity of life on Earth, its limited chemical functionality has inspired researchers to ask a profound question: can we expand the genetic alphabet?
The field of synthetic biology has answered with a resounding "yes" through the creation of Artificially Expanded Genetic Information Systems (AEGIS).[2][3] These systems introduce Unnatural Base Pairs (UBPs) into the DNA helix, creating new, orthogonal pairing systems that function alongside the natural ones.[1][4] One of the pioneering and most studied hydrogen-bonded UBPs is the pairing of isoguanine (isoG) with 2-amino-6-(2-thienyl)purine, a derivative of 2-Aminoisocytosine (isoC).[5][6]
This guide provides an in-depth exploration of the applications of the isoC:isoG pair, from its fundamental physicochemical properties to its use in diagnostics, nanotechnology, and the creation of novel biological systems. We will delve into the causality behind experimental designs and provide detailed protocols for the synthesis, incorporation, and analysis of DNA containing this expanded genetic alphabet.
The 2-Aminoisocytosine:Isoguanine Pair: A New Rung on the DNA Ladder
The power of the isoC:isoG pair lies in its unique hydrogen bonding pattern, which is isomeric to the G:C pair but orthogonal to both natural pairs. This orthogonality is the key to its function as an independent genetic information channel.
Structure and Orthogonal Pairing
Unlike natural base pairs, which follow a purine:pyrimidine pairing rule, the isoC:isoG pair involves a rearranged pattern of hydrogen bond donors and acceptors.[3] As shown below, isoG and isoC form a stable pair linked by three hydrogen bonds, ensuring high fidelity and specificity during replication and transcription.[5] This specific geometry prevents them from pairing with natural bases, thus avoiding disruption of the existing genetic code.
Figure 1: Hydrogen bonding pattern of the Isoguanine (isoG) and 2-Aminoisocytosine (isoC) unnatural base pair.
Thermodynamic Stability
A crucial feature of a functional UBP is its thermodynamic stability within the DNA duplex. The isoC:isoG pair is noteworthy for its high stability, which in many sequence contexts is comparable to or even exceeds that of the natural G:C pair.[7] This stability is critical for applications requiring robust hybridization, such as in diagnostics and DNA nanotechnology.
Causality Insight: The high melting temperature (Tm) of duplexes containing isoC:isoG is a direct consequence of the three hydrogen bonds formed between the bases. This strong, specific interaction minimizes the entropic penalty of incorporating the pair into the helix, leading to favorable free energy of formation (ΔG°).[8][9]
| Base Pair in Duplex | Typical Melting Temp. (Tm) Change | Relative Stability | Rationale |
| G:C (Natural) | Reference | Very High | Three hydrogen bonds |
| isoG:isoC (Unnatural) | ~ Equal to or > G:C | Very High | Three orthogonal hydrogen bonds [7] |
| A:T (Natural) | Lower than G:C | High | Two hydrogen bonds |
| G:T (Mismatch) | Significantly Lower | Low | Wobble pair with two hydrogen bonds |
| isoG:T (Mismatch) | Significantly Lower | Low | Mispairing due to isoG tautomerism[5][6] |
Table 1: Comparative thermodynamic stability of the isoC:isoG unnatural base pair relative to natural DNA base pairs and common mismatches.
Challenges and Considerations
While powerful, the isoC:isoG system is not without its challenges. The primary issue is the keto-enol tautomerism of isoguanine. The minor enol tautomer of isoG is structurally similar to guanine and can mispair with thymine (or uracil in RNA), leading to mutations during replication or transcription.[5][6] Additionally, isocytosine derivatives can be chemically unstable and susceptible to deamination under the harsh alkaline conditions often used during standard oligonucleotide deprotection.[6][10] These factors must be carefully considered in experimental design, often requiring modified enzymatic and chemical protocols to ensure fidelity.
Core Applications in Research and Development
The ability to add a third, independent base pair to DNA opens up a vast landscape of applications, transforming how we store information, diagnose diseases, and engineer biological systems.
Hachimoji DNA: Doubling Information Density
By adding the isoC:isoG pair and other UBPs to the natural A, T, C, and G, scientists have created "hachimoji" (Japanese for "eight letters") DNA.[11] This eight-letter genetic system doubles the information density of DNA, a feature with profound implications for digital data storage.[12][13] Humanity's data storage needs are growing exponentially, and DNA offers an incredibly dense and durable medium. Hachimoji DNA could theoretically store all of humanity's data in a container the size of a pickup truck.[13]
Beyond storage, the expanded alphabet allows for more complex and programmable DNA nanostructures and molecular barcodes for high-plex combinatorial tagging.[2][11]
Advanced Diagnostics and High-Affinity Aptamers
Genetic alphabet expansion provides a powerful platform for creating novel diagnostic tools and therapeutic agents.[14] By incorporating UBPs like isoC derivatives into DNA libraries for in vitro selection (SELEX), researchers can generate high-affinity DNA aptamers—synthetic nucleic acid ligands that bind to specific targets.
Expertise Insight: The enhanced chemical functionality of an expanded alphabet allows these aptamers to form more complex three-dimensional structures and engage in a wider range of interactions (e.g., hydrophobic, electrostatic) with their targets.[3][14] For example, aptamers containing the hydrophobic UBP 7-(2-thienyl)imidazo[4,5-b]pyridine (Ds) have shown exceptionally high affinity and specificity for cancer cells, making them promising candidates for diagnostics, cell imaging, and targeted drug delivery.[13][14] The principles demonstrated with hydrophobic UBPs are directly applicable to hydrogen-bonding pairs like isoC:isoG, which can introduce new functional groups and folding constraints.
Paving the Way for Semi-Synthetic Organisms
Perhaps the most ambitious application of an expanded genetic alphabet is the creation of a semi-synthetic organism (SSO) that can stably maintain and replicate a UBP as part of its genome.[15][16][17] While the first stable SSOs were created using hydrophobic UBPs (dNaM-dTPT3), the foundational work on the enzymatic recognition of the isoC:isoG pair was a critical step in proving the feasibility of this concept.[1][6][10]
Creating an SSO requires overcoming several major hurdles:
-
UBP Synthesis: The organism cannot synthesize the unnatural nucleosides. They must be supplied in the growth medium.[18]
-
Nucleotide Transport: The corresponding unnatural triphosphates (dNTPs) must be transported into the cell. This was achieved by engineering the cell to express a nucleotide triphosphate transporter from an algal species.[18][19]
-
Stable Replication: The cell's native DNA polymerase must be able to replicate the UBP with high fidelity across generations. The first SSOs were unstable, losing the UBP over time.[16][20] Stability was later achieved through chemical optimization of the UBP and the use of CRISPR-Cas9 to eliminate plasmids that had lost the unnatural pair.[15][17]
These SSOs can store more genetic information than any natural organism and have been engineered to transcribe and translate their unnatural codons, enabling the site-specific incorporation of non-canonical amino acids into proteins.[19] This opens the door to creating novel proteins with enhanced therapeutic properties, new catalytic activities, or unique material characteristics.[21][22]
Experimental Protocols
The following protocols provide a framework for working with the isoC:isoG system. They are based on established principles of nucleic acid chemistry and molecular biology.
Protocol 1: Synthesis of 2-Aminoisocytosine (d-isoC) Phosphoramidite
This protocol outlines the general steps for preparing a protected d-isoC phosphoramidite building block for use in automated DNA synthesis, based on standard methodologies.[23][24]
Causality Insight: Each step is designed to protect reactive functional groups that could otherwise cause unwanted side reactions during oligonucleotide synthesis. The final phosphoramidite group is the reactive moiety that enables coupling to the growing DNA chain.
-
Protection of Exocyclic Amine:
-
Start with 2'-deoxy-5-methylisocytidine (d-MeisoC). The 5-methyl group enhances stability and reduces the potential for mispairing.[5]
-
Protect the N4-amino group. A common protecting group is dimethylformamidine (dmf), which is base-labile and can be removed under mild conditions. React the starting material with N,N-dimethylformamide dimethyl acetal in methanol.
-
-
5'-Hydroxyl Protection:
-
Protect the 5'-hydroxyl group with an acid-labile 4,4'-dimethoxytrityl (DMTr) group. This is a standard procedure in phosphoramidite chemistry.
-
React the N4-protected nucleoside with DMTr-Cl in pyridine. The DMTr group is essential as it is removed at the beginning of each coupling cycle to free the 5'-OH for the next nucleotide addition.[]
-
-
Phosphitylation of 3'-Hydroxyl:
-
The final step is to add the reactive phosphoramidite moiety to the 3'-hydroxyl group.
-
React the 5'- and N4-protected nucleoside with 2-cyanoethyl N,N-diisopropylchlorophosphoramidite in the presence of a non-nucleophilic base like N,N-diisopropylethylamine (DIPEA).
-
The cyanoethyl group protects the phosphorus and is removed during the final deprotection step.[24][]
-
-
Purification and Verification:
-
Purify the final phosphoramidite product using silica gel chromatography.
-
Verify the structure and purity using ³¹P NMR and mass spectrometry.
-
Protocol 2: Automated Solid-Phase Synthesis of isoC-Containing Oligonucleotides
This protocol describes the incorporation of the d-isoC phosphoramidite into a DNA oligonucleotide using an automated synthesizer. The process follows the standard phosphoramidite cycle.[][26]
Figure 2: The four-step phosphoramidite cycle for solid-phase DNA synthesis.
Methodology:
-
Setup: Dissolve the custom d-isoC phosphoramidite and the d-isoG phosphoramidite in anhydrous acetonitrile and install them on the DNA synthesizer. Use a synthesis column with the first nucleoside pre-attached to the controlled pore glass (CPG) solid support.
-
Cycle 1: Detritylation: The synthesizer flushes the column with an acid (e.g., trichloroacetic acid in dichloromethane) to remove the 5'-DMTr group from the support-bound nucleoside, exposing the 5'-hydroxyl group.
-
Cycle 2: Coupling: The d-isoC phosphoramidite and an activator (e.g., tetrazole) are simultaneously delivered to the column. The activated phosphoramidite reacts with the free 5'-OH group, extending the DNA chain. Coupling efficiency for unnatural bases should be monitored and may require longer coupling times than standard bases.[26]
-
Cycle 3: Capping: To prevent the extension of chains that failed to couple, a capping solution (e.g., acetic anhydride and N-methylimidazole) is added to acetylate any unreacted 5'-OH groups.
-
Cycle 4: Oxidation: An oxidizing solution (iodine in THF/water/pyridine) is passed through the column to convert the unstable phosphite triester linkage to a stable phosphate triester.
-
Iteration: The cycle is repeated for each subsequent nucleotide in the desired sequence.
-
Cleavage and Deprotection: After the final cycle, the column is treated with a mild base (e.g., aqueous ammonia at room temperature instead of elevated temperatures) to cleave the completed oligonucleotide from the CPG support and remove the protecting groups from the bases and the phosphate backbone. The milder conditions are crucial to prevent degradation of the isoC base.[23]
-
Purification: Purify the final product using HPLC or PAGE to isolate the full-length oligonucleotide.
Protocol 3: PCR Amplification of DNA Containing an isoC:isoG Pair
This protocol details the enzymatic amplification of a DNA template containing an isoC:isoG pair.[27][28]
Expertise Insight: The choice of DNA polymerase is critical. Not all polymerases can efficiently recognize and extend a UBP. High-fidelity polymerases with 3'→5' exonuclease activity (proofreading), such as Deep Vent or Vent polymerase, have shown good performance with certain UBPs.[28][29] The exonuclease activity can help remove misincorporated natural bases opposite a UBP, increasing overall fidelity.
Sources
- 1. Expansion of the Genetic Alphabet: Unnatural Nucleobases and Their Applications - PMC [pmc.ncbi.nlm.nih.gov]
- 2. trilinkbiotech.com [trilinkbiotech.com]
- 3. Artificially Expanded Genetic Information Systems for New Aptamer Technologies - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Genetic alphabet expansion biotechnology by creating unnatural base pairs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Sequence determination of nucleic acids containing 5-methylisocytosine and isoguanine: identification and insight into polymerase replication of the non-natural nucleobases - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Enzymatic recognition of the base pair between isocytidine and isoguanosine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. The Base Pairs of Isoguanine and 8-Aza-7-deazaisoguanine with 5-Methylisocytosine as Targets for DNA Functionalization - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. mdpi.com [mdpi.com]
- 9. Thermodynamic stability of base pairs between 2-hydroxyadenine and incoming nucleotides as a determinant of nucleotide incorporation specificity during replication - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Unnatural base pairs for specific transcription - PMC [pmc.ncbi.nlm.nih.gov]
- 11. Hachimoji DNA and RNA. A Genetic System with Eight Building Blocks - PMC [pmc.ncbi.nlm.nih.gov]
- 12. physicsworld.com [physicsworld.com]
- 13. Scientists showcase hachimoji, an expanded genetic language – HudsonAlpha Institute for Biotechnology [hudsonalpha.org]
- 14. Genetic Alphabet Expansion Provides Versatile Specificities and Activities of Unnatural-Base DNA Aptamers Targeting Cancer Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 15. sciencealert.com [sciencealert.com]
- 16. neurosciencenews.com [neurosciencenews.com]
- 17. A semisynthetic organism engineered for the stable expansion of the genetic alphabet - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Discovery, implications and initial use of semi-synthetic organisms with an expanded genetic alphabet/code - PMC [pmc.ncbi.nlm.nih.gov]
- 19. A semi-synthetic organism that stores and retrieves increased genetic information - PubMed [pubmed.ncbi.nlm.nih.gov]
- 20. biotechniques.com [biotechniques.com]
- 21. news-medical.net [news-medical.net]
- 22. Expanding the Genetic Alphabet | The Scientist [the-scientist.com]
- 23. Development of Phosphoramidite Reagents for the Synthesis of Base-Labile Oligonucleotides Modified with a Linear Aminoalkyl and Amino-PEG Linker at the 3′-End - PMC [pmc.ncbi.nlm.nih.gov]
- 24. mdpi.com [mdpi.com]
- 26. Standard Protocol for Solid-Phase Oligonucleotide Synthesis using Unmodified Phosphoramidites | LGC, Biosearch Technologies [biosearchtech.com]
- 27. academic.oup.com [academic.oup.com]
- 28. Highly specific unnatural base pair systems as a third base pair for PCR amplification - PMC [pmc.ncbi.nlm.nih.gov]
- 29. pubs.acs.org [pubs.acs.org]
Unlocking Precision in DNA Analysis: A Guide to Site-Specific Labeling Using 2-Aminoisocytosine
Introduction: Beyond the Canonical Four
In the landscape of molecular biology and drug development, the ability to attach probes, labels, and functional moieties to specific locations within a DNA molecule is paramount. Site-specific labeling empowers researchers to probe DNA structure and function, develop advanced diagnostics, and construct novel therapeutic agents with unparalleled precision. Traditional labeling methods often rely on statistical modification of natural bases or terminal labeling, which can lack the specificity required for sophisticated applications.
The expansion of the genetic alphabet through the use of unnatural base pairs (UBPs) offers a powerful solution for overcoming these limitations.[1] By introducing a third base pair with orthogonal recognition properties, we can designate a unique site for modification within any DNA sequence, without interfering with the natural A-T and G-C pairing.[2][3] This guide provides a comprehensive overview and detailed protocols for the use of 2-Aminoisocytosine (2-AI), an isomer of isocytosine, as a versatile tool for site-specific DNA labeling.
2-Aminoisocytosine, when paired with its cognate partner isoguanine (isoG), forms a stable, non-natural base pair that can be efficiently incorporated into DNA oligonucleotides using standard phosphoramidite chemistry. The unique hydrogen bonding pattern of the 2-AI:isoG pair ensures its orthogonality to the natural genetic alphabet. Furthermore, the 2-AI nucleobase can be readily functionalized with a reactive handle, such as an alkyne group, enabling highly efficient and specific labeling through bioorthogonal click chemistry.
This application note will guide researchers through the principles, experimental design, and detailed protocols for incorporating a functionalized 2-Aminoisocytosine into DNA and its subsequent site-specific labeling.
The 2-Aminoisocytosine:Isoguanine Unnatural Base Pair
The foundation of this labeling strategy lies in the specific and stable pairing of 2-Aminoisocytosine (2-AI) with isoguanine (isoG). Unlike the canonical Watson-Crick base pairs, the 2-AI:isoG pair utilizes a distinct hydrogen bonding pattern, preventing it from mispairing with natural DNA bases.
Figure 1: Hydrogen bonding between 2-Aminoisocytosine and Isoguanine.
A critical consideration when working with isocytosine analogs is the potential for tautomerization, which can alter the hydrogen bonding pattern and lead to mispairing with natural bases. While this is a known issue with isocytosine, 2-Aminoisocytosine is designed to favor a tautomeric state that maintains high fidelity pairing with isoguanine. However, it is crucial to employ high-fidelity DNA polymerases and optimized reaction conditions during any enzymatic manipulation of DNA containing this UBP to minimize the potential for misincorporation.
Workflow for Site-Specific Labeling using 2-Aminoisocytosine
The overall strategy for site-specific labeling involves three key stages:
-
Synthesis of a functionalized 2-Aminoisocytosine phosphoramidite: A reactive handle, typically an alkyne group for click chemistry, is attached to the 2-AI nucleobase. This modified nucleoside is then converted into a phosphoramidite for use in automated DNA synthesis.
-
Incorporation of the functionalized 2-AI into an oligonucleotide: The modified 2-AI phosphoramidite is incorporated at the desired position within a DNA sequence during standard solid-phase oligonucleotide synthesis.
-
Post-synthetic labeling via click chemistry: The alkyne-modified oligonucleotide is reacted with an azide-containing label (e.g., a fluorescent dye, biotin, or a therapeutic agent) in a highly efficient and specific copper(I)-catalyzed azide-alkyne cycloaddition (CuAAC) reaction.
Figure 2: Experimental workflow for site-specific DNA labeling using 2-AI.
Protocols
Protocol 1: Synthesis of Alkyne-Modified 2-Aminoisocytosine Phosphoramidite
Note: This protocol should be performed by chemists experienced in nucleoside and phosphoramidite chemistry in a well-equipped laboratory.
1. Synthesis of 5-Iodo-2'-deoxy-2-Aminoisocytosine:
- Starting with 2'-deoxy-2-Aminoisocytosine, perform an iodination reaction at the 5-position of the pyrimidine ring using N-iodosuccinimide (NIS) in a suitable solvent like DMF.
- Monitor the reaction by TLC or LC-MS.
- Purify the product by column chromatography.
2. Sonogashira Coupling to Introduce the Alkyne Linker:
- To the 5-iodo-2'-deoxy-2-Aminoisocytosine, add a terminal alkyne with a protected alcohol (e.g., propargyl alcohol protected with a TBDMS group) in the presence of a palladium catalyst (e.g., Pd(PPh₃)₄) and a copper(I) co-catalyst (e.g., CuI) in a suitable solvent system (e.g., DMF/triethylamine).
- Monitor the reaction by TLC or LC-MS.
- Purify the coupled product by column chromatography.
3. 5'-DMT Protection:
- Protect the 5'-hydroxyl group of the alkyne-modified nucleoside with a dimethoxytrityl (DMT) group using DMT-Cl in pyridine.
- Monitor the reaction by TLC.
- Purify the 5'-DMT-protected nucleoside by column chromatography.
4. 3'-Phosphitylation:
- React the 5'-DMT-protected, alkyne-modified nucleoside with 2-cyanoethyl N,N-diisopropylchlorophosphoramidite in the presence of a non-nucleophilic base (e.g., diisopropylethylamine) in an anhydrous solvent (e.g., dichloromethane).
- Monitor the reaction by ³¹P NMR.
- Purify the final phosphoramidite product by column chromatography under anhydrous conditions.
- The final product should be stored under an inert atmosphere at -20°C.
Characterization: The structure and purity of the synthesized phosphoramidite should be confirmed by ¹H NMR, ³¹P NMR, and high-resolution mass spectrometry.
Protocol 2: Automated Solid-Phase Synthesis of Alkyne-Modified Oligonucleotides
This protocol assumes the use of a standard automated DNA synthesizer.
1. Reagent Preparation:
- Dissolve the synthesized alkyne-modified 2-AI phosphoramidite in anhydrous acetonitrile to the concentration recommended by the synthesizer manufacturer (typically 0.1 M).
- Ensure all other standard DNA synthesis reagents (A, C, G, T phosphoramidites, activator, capping reagents, oxidizing agent, deblocking solution) are fresh and correctly installed on the synthesizer.
2. Oligonucleotide Synthesis:
- Program the desired DNA sequence into the synthesizer, using the designated position for the modified 2-AI phosphoramidite.
- Use a synthesis column with the appropriate solid support for the desired 3'-terminus.
- Initiate the synthesis run. The synthesizer will perform the standard cycles of deblocking, coupling, capping, and oxidation for each base addition.
3. Cleavage and Deprotection:
- Following synthesis, cleave the oligonucleotide from the solid support and remove the protecting groups by incubating the support in concentrated ammonium hydroxide or a mixture of ammonium hydroxide and methylamine, following the recommendations for the standard phosphoramidites used.
4. Purification of the Alkyne-Modified Oligonucleotide:
- Purify the crude oligonucleotide using reverse-phase high-performance liquid chromatography (HPLC) or polyacrylamide gel electrophoresis (PAGE). DMT-on purification followed by detritylation and a final desalting step is a highly effective method.
Protocol 3: Copper-Catalyzed Azide-Alkyne Cycloaddition (CuAAC)
This protocol provides a general method for labeling the alkyne-modified oligonucleotide with an azide-functionalized molecule.
1. Reagent Preparation:
- Oligonucleotide Solution: Dissolve the purified alkyne-modified oligonucleotide in nuclease-free water to a final concentration of 100 µM.
- Azide-Label Solution: Dissolve the azide-functionalized label (e.g., fluorescent dye-azide) in DMSO to a stock concentration of 10 mM.
- Copper(II) Sulfate Solution: Prepare a 100 mM stock solution of CuSO₄ in nuclease-free water.
- Tris(3-hydroxypropyltriazolylmethyl)amine (THPTA) Solution: Prepare a 100 mM stock solution of THPTA in nuclease-free water. THPTA is a ligand that stabilizes the Cu(I) catalyst and improves reaction efficiency in aqueous solutions.
- Sodium Ascorbate Solution: Prepare a fresh 1 M stock solution of sodium ascorbate in nuclease-free water. Sodium ascorbate is the reducing agent that converts Cu(II) to the active Cu(I) catalyst.
2. Click Reaction:
- In a microcentrifuge tube, combine the following reagents in order: | Reagent | Volume (for a 50 µL reaction) | Final Concentration | | :--- | :--- | :--- | | Nuclease-free water | to 50 µL | - | | Alkyne-Oligonucleotide (100 µM) | 5 µL | 10 µM | | Azide-Label (10 mM in DMSO) | 2.5 µL | 500 µM (50-fold excess) | | CuSO₄ (100 mM) | 0.5 µL | 1 mM | | THPTA (100 mM) | 2.5 µL | 5 mM |
- Vortex the mixture gently.
- Initiate the reaction by adding 2.5 µL of the freshly prepared 1 M sodium ascorbate solution (final concentration 50 mM).
- Vortex gently and incubate the reaction at room temperature for 1-2 hours, protected from light if using a fluorescent dye.
3. Purification of the Labeled Oligonucleotide:
- The labeled oligonucleotide can be purified from excess label and catalyst by several methods, including:
- Ethanol Precipitation: Add 3 M sodium acetate (pH 5.2) to a final concentration of 0.3 M, followed by 3 volumes of cold absolute ethanol. Incubate at -20°C for at least 1 hour and then centrifuge at high speed to pellet the DNA. Wash the pellet with 70% ethanol and resuspend in nuclease-free water.
- Size-Exclusion Chromatography: Use a desalting column (e.g., Sephadex G-25) to separate the labeled oligonucleotide from smaller molecules.
- Reverse-Phase HPLC: This is the most effective method for achieving high purity. The labeled oligonucleotide will have a different retention time than the unlabeled starting material due to the addition of the label.
Characterization of Labeled DNA
1. HPLC Analysis:
- Analyze the purified labeled oligonucleotide by reverse-phase HPLC. The labeled product should exhibit a clear shift in retention time compared to the unlabeled alkyne-modified oligonucleotide. The chromatogram can also be used to assess the purity of the final product.
2. Mass Spectrometry:
- Confirm the successful conjugation and determine the exact mass of the labeled oligonucleotide using mass spectrometry (e.g., ESI-MS or MALDI-TOF). The observed mass should correspond to the theoretical mass of the labeled product.
3. Fluorescence Spectroscopy:
- If a fluorescent label was used, measure the absorbance and emission spectra of the purified product. The spectral properties should match those of the free fluorescent dye, confirming the integrity of the fluorophore after conjugation. Fluorescence correlation spectroscopy can also be used to determine the labeling efficiency.[6]
Advantages and Considerations
Advantages of using 2-Aminoisocytosine for site-specific labeling:
-
High Specificity: The orthogonality of the 2-AI:isoG base pair ensures that the label is directed to a single, predetermined site in the DNA sequence.
-
Versatility: The click chemistry handle allows for the attachment of a wide variety of labels and functional groups.
-
Efficiency: Click chemistry is a highly efficient and robust reaction that proceeds under mild, aqueous conditions.
-
Compatibility: The modified base can be incorporated into DNA using standard, automated synthesis protocols.
Considerations:
-
Synthesis of Modified Phosphoramidite: The primary challenge is the synthesis of the functionalized 2-AI phosphoramidite, which requires expertise in organic chemistry.
-
Fidelity of Enzymatic Reactions: While the 2-AI:isoG pair is largely orthogonal, care must be taken during PCR or other enzymatic manipulations to use high-fidelity polymerases to minimize the risk of misincorporation.
-
Purification: Rigorous purification of both the alkyne-modified and the final labeled oligonucleotide is crucial to remove any unreacted components that could interfere with downstream applications.
Conclusion
Site-specific labeling of DNA using 2-Aminoisocytosine provides a powerful and precise method for introducing a wide range of functionalities into nucleic acids. By leveraging the orthogonality of an expanded genetic alphabet and the efficiency of click chemistry, researchers can create custom-labeled DNA molecules for a diverse array of applications in diagnostics, therapeutics, and fundamental research. The protocols and considerations outlined in this guide provide a solid foundation for the successful implementation of this advanced labeling strategy.
References
- Seo, Y. J., et al. (2011). Site-Specific Labeling of DNA and RNA Using an Efficiently Replicated and Transcribed Class of Unnatural Base Pairs. Journal of the American Chemical Society, 133(49), 19878–19888.
- Fomich, M. A., et al. (2014). Azide phosphoramidite in direct synthesis of azide-modified oligonucleotides. Organic Letters, 16(17), 4590–4593.
- Prien, J. M., et al. (2010). Mass Spectrometric-Based Stable Isotopic 2-Aminobenzoic Acid Glycan Mapping for Rapid Glycan Screening of Biotherapeutics. Analytical Chemistry, 82(4), 1296-1303.
- Schifferdecker, S., et al. (2022). Genetic Code Expansion and Bio-Orthogonal Labeling Reveal Intact HIV-1 Capsids inside the Nucleus. mBio, 13(5), e01959-22.
- Kimoto, M., et al. (2016). Site-Specific Fluorescent Labeling of Nucleic Acids by Genetic Alphabet Expansion Using Unnatural Base Pairs. In Methods in Molecular Biology (Vol. 1385, pp. 199-213). Humana Press.
-
Bio-Synthesis Inc. Isocytosine and Isoguanosine base analogs. Retrieved from [Link]
- Minasyan, A. (2024).
- Tang, Y. Y., et al. (2000). Biophysical characterization of interactions between the core binding factor alpha and beta subunits and DNA. FEBS Letters, 470(2), 167–172.
- Obeid, S., et al. (2021). On-demand synthesis of phosphoramidites.
- Hocek, M., & Fojta, M. (2017). Hydrophobic alkyl-linked base-modified pyrimidine and 7-deazapurine 2′-deoxyribonucleoside phosphoramidites: synthesis and application in solid-phase synthesis of modified and hypermodified oligonucleotides. RSC Advances, 7(86), 54623-54634.
- Beaucage, S. L., & Caruthers, M. H. (1981). Deoxynucleoside phosphoramidites—A new class of key intermediates for deoxypolynucleotide synthesis. Tetrahedron Letters, 22(20), 1859–1862.
- Malyshev, D. A., & Romesberg, F. E. (2015). The Expanded Genetic Alphabet.
- Hirao, I., et al. (2012). Unnatural base pair systems toward the expansion of the genetic alphabet in the central dogma. Proceedings of the Japan Academy, Series B, 88(8), 345–367.
- Zaytseva, I. I., et al. (2011). Synthesis of novel nucleoside 5'-triphosphates and phosphoramidites containing alkyne or amino groups for the postsynthetic functionalization of nucleic acids. Nucleosides, Nucleotides & Nucleic Acids, 30(10), 753–767.
- Cline, D. J., et al. (2015). Labeling DNA for Single-Molecule Experiments: Methods of Labeling Internal Specific Sequences on Double-Stranded DNA. Chembiochem, 16(18), 2596–2609.
- van der Heijden, T., et al. (2012). Biophysical characterization of DNA binding from single molecule force measurements. Biophysical reviews, 4(2), 111–119.
- Johnson, W. T., et al. (2019). The Role of Orthogonality in Genetic Code Expansion. International journal of molecular sciences, 20(13), 3326.
-
Site-Specific Labeling of DNA via PCR with an Expanded Genetic Alphabet. (n.d.). BenchSci. Retrieved from [Link]
- Intracellular Detection of Cytosine Incorporation in Genomic DNA Using 5-Ethynyl-2′-Deoxycytidine. (2012). ACS Chemical Biology, 7(7), 1251–1260.
- Martin, P. (1995). Improved synthesis of 2'-amino-2'-deoxyguanosine and its phosphoramidite. Helvetica Chimica Acta, 78(2), 486-504.
- Ogris, M., et al. (2003). Biophysical characterization of PEI/DNA complexes. Journal of controlled release, 91(1-2), 173–185.
- Nishina, K., et al. (2020). Synthesis of 2′-formamidonucleoside phosphoramidites for suppressing the seed-based off-target effects of siRNAs. Scientific Reports, 10(1), 1–11.
- Hayakawa, Y., et al. (2012). Synthesis of Oligodeoxynucleotides Using Fully Protected Deoxynucleoside 3′-Phosphoramidite Building Blocks and Base Recognition of Oligodeoxynucleotides Incorporating N3-Cyano-Ethylthymine. Molecules, 17(12), 14386–14404.
- Holyst, R., et al. (2014). Fluorescence Correlation Spectroscopy Analysis for Accurate Determination of Proportion of Doubly Labeled DNA in Fluorescent DNA Pool for Quantitative Biochemical Assays. Biosensors and Bioelectronics, 52, 219–224.
- Vrabel, M., et al. (2007). Arylethynyl- or Alkynyl-Linked Pyrimidine and 7-Deazapurine 2′-Deoxyribonucleoside 3′-Phosphoramidites for Chemical Synthesis of Hypermodified Hydrophobic Oligonucleotides. Journal of Organic Chemistry, 72(15), 5639–5647.
- Chapuis, H., et al. (2016). Improved synthesis and polymerase recognition of 7-deaza-7-modified α-l-threofuranosyl guanosine analogs. Bioorganic & Medicinal Chemistry, 24(18), 4381–4387.
- Martin, P. (1996). Synthesis of the phosphoramidite derivative of 2'-deoxy-2'-C-beta-methylcytidine. Helvetica Chimica Acta, 79(7), 1930-1938.
- Brabec, V., et al. (1992). Biophysical analysis of DNA modified by 1,2-diaminocyclohexane platinum(II) complexes. Biochemistry, 31(3), 856–863.
- Site-Selective and Rewritable Labeling of DNA through Enzymatic, Reversible, and Click Chemistries. (2019). Organic Letters, 21(22), 9123–9127.
- Nucleic Acid Analysis Using an Expanded Genetic Alphabet to Quench Fluorescence. (2004). Analytical Biochemistry, 330(2), 245–255.
Sources
- 1. The Expanded Genetic Alphabet - PMC [pmc.ncbi.nlm.nih.gov]
- 2. researchgate.net [researchgate.net]
- 3. Nucleotide base - Wikipedia [en.wikipedia.org]
- 4. Synthesis of novel nucleoside 5'-triphosphates and phosphoramidites containing alkyne or amino groups for the postsynthetic functionalization of nucleic acids - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Arylethynyl- or Alkynyl-Linked Pyrimidine and 7-Deazapurine 2′-Deoxyribonucleoside 3′-Phosphoramidites for Chemical Synthesis of Hypermodified Hydrophobic Oligonucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Biophysical analysis of DNA modified by 1,2-diaminocyclohexane platinum(II) complexes - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for the Enzymatic Synthesis of 2-Aminoisocytosine-Modified Nucleic Acids
For Researchers, Scientists, and Drug Development Professionals
Authored by: Gemini, Senior Application Scientist
Introduction: Expanding the Genetic Alphabet for Advanced Therapeutics and Diagnostics
The four canonical bases of DNA and RNA—adenine, guanine, cytosine, and thymine/uracil—form the foundation of life's genetic code. However, the burgeoning fields of synthetic biology, diagnostics, and nucleic acid therapeutics are increasingly leveraging an expanded genetic alphabet. The incorporation of modified nucleobases into nucleic acids can bestow novel chemical and physical properties, such as enhanced thermal stability, increased nuclease resistance, and expanded functional group diversity for downstream applications.[1][2][3]
Among the myriad of synthetic nucleobases, 2-Aminoisocytosine (2-AIC) presents a compelling case for its inclusion in functional nucleic acids. As an isomer of isocytosine, it offers unique hydrogen bonding capabilities and the potential to introduce a reactive primary amine into the nucleic acid structure. This modification can be leveraged for a variety of applications, including the site-specific attachment of labels, cross-linking agents, or therapeutic payloads.
Historically, the synthesis of modified oligonucleotides has been dominated by solid-phase phosphoramidite chemistry.[4] While powerful, this method can be resource-intensive and is often limited to the synthesis of relatively short oligonucleotides. Enzymatic synthesis, on the other hand, offers a biocompatible and often more efficient alternative for generating long, modified nucleic acids.[5] This application note provides a comprehensive guide to the enzymatic synthesis of 2-AIC-modified nucleic acids, from the selection of appropriate polymerases to the purification and analysis of the final product.
I. The Rationale for Enzymatic Synthesis of 2-AIC-Modified Nucleic Acids
The enzymatic approach to synthesizing modified nucleic acids relies on the remarkable ability of certain DNA and RNA polymerases to accept non-canonical nucleoside triphosphates as substrates.[6][7] The primary advantages of this method include:
-
Biocompatibility: Reactions are performed in aqueous buffers under mild conditions, preserving the integrity of both the enzyme and the nucleic acid product.
-
Efficiency for Long Oligonucleotides: Polymerases can synthesize long stretches of modified DNA or RNA with high fidelity and processivity, a task that is challenging for chemical synthesis.
-
Stereospecificity: Enzymes ensure the formation of the correct phosphodiester backbone stereochemistry.
The key to successful enzymatic synthesis of modified nucleic acids lies in the selection of a polymerase that can efficiently and faithfully incorporate the desired modified nucleotide.
II. Selecting the Right Polymerase: A Matter of Fidelity and Tolerance
Not all polymerases are created equal when it comes to accepting modified substrates. High-fidelity proofreading polymerases, while excellent for standard PCR, can be less tolerant of non-canonical bases in the template or as incoming dNTPs. Conversely, polymerases with lower fidelity or engineered variants often exhibit a broader substrate scope.
For the incorporation of modified pyrimidines like 2-AIC, Family B DNA polymerases, such as those derived from thermophilic archaea, have shown significant promise. These enzymes are known for their thermostability, high processivity, and a more open active site that can accommodate modifications on the nucleobase.
Table 1: Recommended DNA Polymerases for 2-AIC Incorporation
| Polymerase | Family | Key Characteristics | Rationale for Use with 2-AIC |
| KOD DNA Polymerase | B | High fidelity, high processivity, and thermostable. Known to be tolerant of various base modifications. | Its robust nature and demonstrated ability to incorporate a wide range of modified nucleotides make it a prime candidate. |
| Vent (exo-) DNA Polymerase | B | Thermostable, high fidelity (exonuclease proficient version). The exonuclease-deficient (exo-) version is often preferred for modified nucleotide incorporation to prevent excision of the modified base. | Has been shown to efficiently incorporate various modified dUTPs, suggesting it can accommodate modifications on the pyrimidine ring.[8][9] |
| T7 RNA Polymerase | N/A | DNA-dependent RNA polymerase with high processivity and promoter specificity. | For the synthesis of 2-AIC modified RNA transcripts. Its substrate tolerance for some modified NTPs is well-documented. |
Expert Insight: The choice between KOD and Vent (exo-) polymerase may depend on the specific template sequence and the desired level of fidelity. For initial screening and optimization, Vent (exo-) can be a cost-effective and reliable choice. For applications requiring the highest possible fidelity, KOD polymerase is recommended.
III. Materials and Reagents
Enzymes and Buffers:
-
High-Fidelity DNA Polymerase (e.g., KOD DNA Polymerase or Vent (exo-) DNA Polymerase)
-
10x Polymerase Reaction Buffer (supplied with the enzyme)
-
T7 RNA Polymerase (for RNA synthesis)
-
10x T7 RNA Polymerase Reaction Buffer
-
DNase I, RNase-free
-
RNase Inhibitor
Nucleotides:
-
Deoxynucleoside Triphosphate (dNTP) mix (10 mM each of dATP, dGTP, dCTP, TTP)
-
2-Aminoisocytosine-5'-triphosphate (d2AICTP) (10 mM solution)
-
Ribonucleoside Triphosphate (NTP) mix (for RNA synthesis; 10 mM each of ATP, GTP, CTP, UTP)
-
2-Aminoisocytosine-5'-ribonucleoside triphosphate (r2AICTP) (for RNA synthesis; 10 mM solution)
Primers and Templates:
-
Forward and Reverse DNA primers (for PCR-based synthesis)
-
DNA template containing the sequence of interest
Purification and Analysis:
-
DNA or RNA purification kit (silica-based spin columns or magnetic beads)
-
HPLC system with an anion-exchange or reverse-phase column
-
Mobile phase buffers for HPLC (e.g., Triethylammonium acetate (TEAA) buffer, Acetonitrile)
-
Urea-PAGE supplies (for gel electrophoresis analysis)
-
Fluorescent DNA/RNA stain
IV. Experimental Protocols
Protocol 1: Enzymatic Synthesis of 2-AIC-Modified DNA via PCR
This protocol describes the incorporation of d2AICTP into a DNA amplicon using a high-fidelity DNA polymerase.
Workflow Diagram:
Caption: Workflow for the enzymatic synthesis of 2-AIC-modified DNA.
Step-by-Step Methodology:
-
Reaction Setup:
-
On ice, prepare a 50 µL PCR reaction mixture in a sterile PCR tube as follows:
-
5 µL 10x Polymerase Reaction Buffer
-
1 µL 10 mM dNTP mix
-
Variable µL 10 mM d2AICTP (see Table 2 for optimization)
-
1 µL 10 µM Forward Primer
-
1 µL 10 µM Reverse Primer
-
1 µL DNA Template (1-10 ng)
-
1 µL High-Fidelity DNA Polymerase (e.g., KOD or Vent (exo-))
-
Nuclease-free water to 50 µL
-
-
Expert Tip: The ratio of d2AICTP to its canonical counterpart (dCTP or TTP, depending on the desired pairing partner) is a critical parameter to optimize. Start with a 1:1 ratio and adjust as needed to achieve the desired incorporation efficiency.
-
-
PCR Amplification:
-
Place the PCR tube in a thermocycler and perform the following program:
-
Initial Denaturation: 95°C for 2 minutes
-
30 Cycles of:
-
Denaturation: 95°C for 20 seconds
-
Annealing: 55-65°C for 30 seconds (optimize based on primer Tm)
-
Extension: 72°C for 30-60 seconds per kb of amplicon length
-
-
Final Extension: 72°C for 5 minutes
-
Hold: 4°C
-
-
-
Purification of the Modified DNA:
-
Purify the PCR product using a commercial PCR purification kit according to the manufacturer's instructions. This will remove primers, unincorporated dNTPs, and the polymerase.
-
-
Analysis of the Modified DNA:
-
Urea-PAGE Analysis: Run a small aliquot of the purified product on a denaturing urea-polyacrylamide gel to verify the size and purity of the amplicon.
-
HPLC Analysis: For quantitative analysis and to confirm the incorporation of 2-AIC, perform anion-exchange or reverse-phase HPLC. The modified DNA will have a different retention time compared to the unmodified control.
-
Table 2: Optimization of d2AICTP Concentration
| Ratio of d2AICTP to canonical dNTP | Expected Outcome | Troubleshooting |
| 1:1 | Good starting point for efficient incorporation. | If PCR yield is low, decrease the ratio. |
| 1:3 | May increase PCR yield if the polymerase is partially inhibited by the modified dNTP. | |
| 3:1 | Aims for higher density of modification. | May lead to lower PCR yield or stalled products. |
Protocol 2: Purification of 2-AIC-Modified Oligonucleotides by HPLC
High-Performance Liquid Chromatography (HPLC) is the gold standard for purifying modified oligonucleotides, offering high resolution and purity.[8][10]
Workflow Diagram:
Caption: HPLC purification workflow for 2-AIC-modified oligonucleotides.
Step-by-Step Methodology:
-
Sample Preparation:
-
Resuspend the crude, dried oligonucleotide in HPLC-grade water.
-
Filter the sample through a 0.22 µm syringe filter to remove any particulate matter.
-
-
HPLC Separation:
-
Equilibrate the HPLC column (e.g., a C18 reverse-phase column) with the starting mobile phase (e.g., 95% Buffer A: 0.1 M TEAA, 5% Buffer B: Acetonitrile).
-
Inject the prepared sample onto the column.
-
Elute the oligonucleotide using a linear gradient of increasing Buffer B concentration. The more hydrophobic, full-length modified oligonucleotide will elute later than the shorter, failed sequences.
-
Monitor the elution profile using a UV detector at 260 nm.
-
-
Fraction Collection and Processing:
-
Collect the peak corresponding to the full-length 2-AIC-modified oligonucleotide.
-
Desalt the collected fraction using a method such as size-exclusion chromatography or ethanol precipitation to remove the TEAA buffer salts.
-
Lyophilize the desalted sample to obtain a pure, dry pellet of the modified oligonucleotide.
-
V. Applications and Future Directions
The ability to enzymatically synthesize 2-AIC-modified nucleic acids opens up a plethora of possibilities in various research and development areas:
-
Aptamer Development: The introduction of 2-AIC can enhance the structural diversity of aptamer libraries, potentially leading to aptamers with higher affinity and specificity for their targets.
-
Bioconjugation: The primary amine of 2-AIC serves as a handle for the site-specific conjugation of fluorophores, quenchers, biotin, or therapeutic molecules.
-
Diagnostics: 2-AIC-modified probes can be used in various diagnostic assays, potentially offering improved hybridization properties.
-
Epigenetic Studies: As an analogue of cytosine, 2-AIC can be used to study the effects of base modifications on DNA-protein interactions and gene regulation.[1]
VI. Troubleshooting
| Problem | Possible Cause | Solution |
| Low or no PCR product | Inhibition of polymerase by d2AICTP | Decrease the concentration of d2AICTP. Optimize the annealing temperature. Try a different polymerase. |
| Poor primer design | Ensure primers have appropriate Tm and are free of secondary structures. | |
| Smearing on gel | Non-specific amplification | Increase annealing temperature. Optimize MgCl2 concentration. |
| Multiple peaks in HPLC | Incomplete reaction or side products | Optimize PCR conditions. Ensure high-purity dNTPs and d2AICTP. |
VII. Conclusion
The enzymatic synthesis of 2-Aminoisocytosine-modified nucleic acids represents a powerful and versatile tool for researchers in the life sciences. By carefully selecting the appropriate polymerase and optimizing reaction conditions, it is possible to generate long, site-specifically modified DNA and RNA molecules for a wide range of applications. The protocols and guidelines presented in this application note provide a solid foundation for the successful implementation of this exciting technology.
References
-
Enzymatic incorporation of 2-amino-6-vinylpurine derivative. Nucleic Acids Symposium Series, (52), 537–538. [Link]
-
Synthesis and polymerase incorporation of 5'-amino-2',5'-dideoxy-5'-N-triphosphate nucleotides. Nucleic Acids Research, 30(24), 5559–5567. [Link]
-
Synthesis and polymerase incorporation of 5′-amino-2′,5′-dideoxy-5′-N-triphosphate nucleotides. Nucleic Acids Research, 30(24), 5559-5567. [Link]
-
Enzymatic incorporation of a third nucleobase pair. Nucleic Acids Research, 34(14), 4095–4104. [Link]
-
Synthesis and polymerase incorporation of 5′-amino-2′,5′-dideoxy-5′-N-triphosphate nucleotides. Request PDF. [Link]
-
Advances in the Enzymatic Synthesis of Nucleoside-5′-Triphosphates and Their Analogs. International Journal of Molecular Sciences, 23(23), 15320. [Link]
-
Enzymatic incorporation of chemically-modified nucleotides into DNAs. Nucleic Acids Research Supplement, (2), 83–84. [Link]
-
Complexing Properties and Applications of Some Biologically Active Nucleic acid Constituents. Chemistry Department, Faculty of Science, Mansoura University. [Link]
-
Synthesis and Enzymatic Incorporation of Modified Deoxyuridine Triphosphates. Molecules, 20(8), 13591–13608. [Link]
-
DNA polymerase. Wikipedia. [Link]
-
Synthesis and Enzymatic Incorporation of Modified Deoxyuridine Triphosphates. Molecules, 20(8), 13591-13608. [Link]
-
Simple Enzymatic Incorporation of 2′OMeU Nucleotide at the End of the Poly-A Tail for Enhancement of the mRNA Stability and Protein Expression. ACS Chemical Biology, 19(10), 2206–2213. [Link]
-
Occurrence, Properties, Applications and Analytics of Cytosine and Its Derivatives. Molecules, 30(18), 3598. [Link]
-
Synthesis and polymerase bypass studies of DNA-peptide and DNA-protein conjugates. Methods in Enzymology, 681, 23–52. [Link]
-
Nucleic Acids and Their Analogues for Biomedical Applications. Molecules, 27(3), 1036. [Link]
-
Insights into Nucleic Acid Biochemistry: Structure, Function, and Therapeutic Applications. Journal of Biochemistry and Physiology, 13(3), 469. [Link]
-
Overexpression of DNA Polymerase Beta Sensitizes Mammalian Cells to 2',3'-deoxycytidine and 3'-azido-3'-deoxythymidine. Cancer Research, 57(1), 110–116. [Link]
-
Structure and function relationships in mammalian DNA polymerases. Journal of Molecular Biology, 430(2), 139–156. [Link]
-
Fundamental Use of Nucleic Acids in Biological Processes. Journal of Cell Science and Mutation, 4(1), 1-2. [Link]
-
5-methylcytosine-sensitive variants of Thermococcus kodakaraensis DNA polymerase. Nucleic Acids Research, 44(20), 9660–9671. [Link]
Sources
- 1. mdpi.com [mdpi.com]
- 2. Nucleic Acids and Their Analogues for Biomedical Applications - PMC [pmc.ncbi.nlm.nih.gov]
- 3. longdom.org [longdom.org]
- 4. Synthesis and polymerase incorporation of 5'-amino-2',5'-dideoxy-5'-N-triphosphate nucleotides - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. Enzymatic incorporation of chemically-modified nucleotides into DNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 6. Enzymatic incorporation of 2-amino-6-vinylpurine derivative - PubMed [pubmed.ncbi.nlm.nih.gov]
- 7. Enzymatic incorporation of a third nucleobase pair - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Synthesis and Enzymatic Incorporation of Modified Deoxyuridine Triphosphates - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. Synthesis and Enzymatic Incorporation of Modified Deoxyuridine Triphosphates - PMC [pmc.ncbi.nlm.nih.gov]
- 10. ijisset.org [ijisset.org]
Aptamer selection using 2-Aminoisocytosine-modified libraries
Application Note & Protocol
Topic: High-Affinity Aptamer Selection Using 2-Aminoisocytosine-Modified Libraries Audience: Researchers, scientists, and drug development professionals.
Introduction: Expanding the Chemical Language of Nucleic Acids for Superior Recognition
Aptamers, single-stranded DNA or RNA oligonucleotides, are selected in vitro for their ability to fold into unique three-dimensional structures that bind to target molecules with high affinity and specificity.[1] This "lock-and-key" fit has positioned them as powerful alternatives to antibodies in therapeutics, diagnostics, and bio-sensing. However, aptamers derived from conventional libraries, composed of only four canonical nucleobases (A, T, C, G), possess a limited chemical diversity.[2][3][4] This restriction can hinder the development of high-affinity binders, especially for challenging targets like small molecules or proteins with subtle epitopes.
To overcome this limitation, the concept of a "genetic alphabet expansion" has emerged as a transformative approach.[5][6][7][8][9][10] By introducing modified nucleotides into the initial library, we can vastly increase the chemical and structural diversity available for selection, enabling novel molecular interactions such as enhanced hydrophobic and hydrogen-bonding capabilities.[11][12] This strategy is exemplified by technologies like SomaLogic's SOMAmers (Slow Off-rate Modified Aptamers), which utilize modified bases to achieve high-affinity protein binding for large-scale proteomic analysis.[13][14][15][16]
This guide focuses on a specific and powerful modification: the use of 2-Aminoisocytosine (iso-dC) and its complementary partner, isoguanine (iso-dG) .[17] The iso-dC:iso-dG pair is structurally analogous to the canonical G:C pair, forming three stable hydrogen bonds. This unique pairing allows for its efficient and faithful enzymatic incorporation and amplification during the SELEX process, a critical requirement for any functional expanded genetic alphabet.[18][19][20] The introduction of iso-dC provides novel hydrogen bond donor and acceptor sites, fundamentally enhancing the potential for generating aptamers with picomolar affinities and superior specificities.[5]
Principle of the Method: The iso-dC Modified SELEX Workflow
Systematic Evolution of Ligands by Exponential Enrichment (SELEX) is an iterative process that isolates high-affinity aptamers from a vast combinatorial library.[1] The modified SELEX protocol described here, termed iso-dC-SELEX , adapts this core principle to accommodate the expanded genetic alphabet.
The process begins with a specially synthesized single-stranded DNA (ssDNA) library containing random sequences where thymidine (T) is partially or fully replaced by 2-Aminoisocytosine (iso-dC). This library is incubated with the target molecule. Sequences that bind to the target are partitioned from non-binders, eluted, and then amplified via a specialized PCR. This crucial amplification step uses a polymerase capable of recognizing the unnatural bases and incorporates the complementary iso-dGTP. The resulting double-stranded DNA is then converted back to a single-stranded, iso-dC-containing library, now enriched with binding sequences, ready for the next selection cycle. After multiple rounds of increasing stringency, the enriched library is analyzed by high-throughput sequencing to identify high-affinity aptamer candidates.
Materials and Equipment
Reagents
-
Modified Nucleotides: 2'-Deoxy-2-Aminoisocytosine-5'-Triphosphate (iso-dCTP), 2'-Deoxyisoguanosine-5'-Triphosphate (iso-dGTP).
-
Standard Nucleotides: dATP, dGTP, dCTP, dTTP solution mix.
-
DNA Polymerase: A polymerase verified to efficiently incorporate and amplify the iso-dC:iso-dG pair. Certain variants of Taq and KOD polymerases have shown compatibility.[21][22] An initial screening of commercially available polymerases may be necessary.[21]
-
Oligonucleotides:
-
Initial DNA Library: 5'-[Primer A seq]-N(x)-[Primer B seq]-3', where N(x) is a random region of 30-40 nucleotides synthesized with A, G, C, and iso-dC.
-
Forward Primer (Primer A).
-
Biotinylated Reverse Primer (5'-Biotin-Primer B).
-
-
Target Molecule: Purified protein or small molecule of interest.
-
Buffers: Binding Buffer (e.g., PBS with 5 mM MgCl₂), Wash Buffer (Binding Buffer + 0.05% Tween-20), Elution Buffer (e.g., high salt, high pH, or thermal denaturation buffer).
-
Immobilization: Streptavidin-coated magnetic beads, NHS-activated columns, or similar.
-
ssDNA Generation: Lambda Exonuclease or 0.15 M NaOH.
Equipment
-
Thermocycler.
-
Magnetic rack or stand.
-
Fluorometer or Spectrophotometer (for DNA quantification).
-
Real-time PCR system (for monitoring enrichment).
-
Gel electrophoresis system.
-
High-Throughput Sequencing (HTS) platform.
-
Binding analysis instrument (e.g., Surface Plasmon Resonance - SPR, Bio-Layer Interferometry - BLI).
Detailed Protocols
Protocol 1: Preparation of Target and Initial Library
-
Target Immobilization:
-
Rationale: Immobilizing the target allows for efficient partitioning of bound from unbound sequences. Biotin-streptavidin is a common, high-affinity interaction for this purpose.
-
Procedure: Biotinylate the target protein according to the manufacturer's protocol. Incubate the biotinylated target with streptavidin-coated magnetic beads in Binding Buffer for 1 hour at room temperature with gentle rotation. Wash the beads 3x with Binding Buffer to remove unbound target. Resuspend the beads in Binding Buffer.
-
-
Initial Library Preparation:
-
Rationale: The initial ssDNA library must be in a state conducive to folding and binding. A heat-cool cycle helps to denature any intermolecular structures and allows for proper intramolecular folding.
-
Procedure: Resuspend the synthesized iso-dC-containing ssDNA library in Binding Buffer to a final concentration of 1-5 µM. Heat the library at 95°C for 5 minutes, then immediately cool on ice for 10 minutes. Equilibrate to room temperature before use.
-
Protocol 2: The Modified SELEX Cycle (Rounds 1-12)
-
Counter-Selection (Optional but Recommended):
-
Rationale: To eliminate sequences that bind non-specifically to the solid support (e.g., the magnetic beads).
-
Procedure: Incubate the folded library with bare streptavidin beads (without the target) for 30 minutes. Collect the supernatant containing the unbound library and use this for the positive selection step.
-
-
Binding:
-
Rationale: This step allows the aptamers in the library to bind to the target. Incubation time and library concentration are key parameters.
-
Procedure: Add the folded (and counter-selected) library to the target-coated magnetic beads. Incubate for 1-2 hours at the desired temperature (e.g., room temperature or 37°C) with gentle rotation.
-
-
Partitioning (Washing):
-
Rationale: This is a critical step where selection pressure is applied. By washing away unbound and weakly bound sequences, only the high-affinity binders are retained. The stringency should be increased in later rounds (e.g., by increasing wash volume, duration, or Tween-20 concentration).
-
Procedure: Place the tube on a magnetic rack to pellet the beads. Aspirate and discard the supernatant. Add 500 µL of Wash Buffer, vortex briefly, and incubate for 5 minutes. Repeat this wash step 3-5 times in early rounds, increasing to 7-10 times in later rounds.
-
-
Elution:
-
Rationale: To recover the bound sequences for amplification. Thermal denaturation is a simple and effective method.
-
Procedure: After the final wash, resuspend the beads in 100 µL of sterile water. Heat at 95°C for 10 minutes to denature the aptamer-target interaction. Immediately place the tube on the magnetic rack and transfer the supernatant (containing the eluted ssDNA) to a new tube. This is the template for PCR.
-
-
Modified PCR Amplification:
-
Rationale: This step amplifies the selected sequences. The key is using a polymerase that can read the iso-dC in the template and incorporate iso-dG, and vice-versa in the subsequent cycle. The reaction mix must contain the standard four dNTPs plus iso-dGTP.
-
Procedure: Set up a 50 µL PCR reaction:
-
Eluted ssDNA: 5-10 µL
-
Forward Primer (10 µM): 1 µL
-
Biotinylated Reverse Primer (10 µM): 1 µL
-
dNTP mix (10 mM each A, C, G, T): 1 µL
-
iso-dGTP (10 mM): 1 µL
-
Compatible Polymerase Buffer (10x): 5 µL
-
Compatible DNA Polymerase: 1 µL
-
Nuclease-free water: to 50 µL
-
-
Cycling Conditions (Example):
-
Initial Denaturation: 95°C for 3 min
-
20-25 Cycles:
-
95°C for 30 sec
-
55-65°C for 30 sec (adjust for primer Tm)
-
72°C for 30 sec
-
-
Final Extension: 72°C for 5 min
-
-
Note: The optimal number of cycles should be determined empirically by qPCR to avoid over-amplification and PCR bias.
-
-
ssDNA Generation for Next Round:
-
Rationale: The SELEX process requires a single-stranded library for the next round of binding. Using a biotinylated reverse primer allows for easy separation of the strands.
-
Procedure:
-
Incubate the biotinylated PCR product with an equal volume of streptavidin-coated magnetic beads for 30 minutes.
-
Wash the beads 2x with Wash Buffer.
-
To elute the non-biotinylated (iso-dC containing) strand, add 100 µL of 0.15 M NaOH and incubate for 10 minutes.
-
Pellet the beads on a magnetic rack and transfer the supernatant to a new tube containing neutralization buffer (e.g., Tris-HCl pH 7.5). This ssDNA is the enriched library for the next SELEX round.
-
-
Protocol 3: Post-SELEX Analysis and Aptamer Characterization
-
High-Throughput Sequencing (HTS):
-
After 8-12 rounds, the enriched pools from the last few rounds are barcoded and sequenced using an HTS platform.
-
-
Bioinformatic Analysis:
-
Sequencing data is analyzed to identify sequences that have been significantly enriched. Sequences are clustered into families based on sequence homology and consensus motifs are identified.
-
-
Binding Affinity Characterization:
-
Rationale: To quantify the binding strength (Kd) of individual aptamer candidates and validate the selection outcome.
-
Procedure: Synthesize individual aptamer candidates (with iso-dC). Use a label-free technique like SPR or BLI to measure binding kinetics.[23]
-
Immobilize the target protein on the sensor chip.
-
Flow serial dilutions of the aptamer over the chip to measure association (kon) and dissociation (koff) rates.
-
The dissociation constant (Kd) is calculated as koff / kon.
-
-
Data Interpretation and Expected Outcomes
The primary advantage of using iso-dC-modified libraries is the potential for a dramatic improvement in binding affinity compared to aptamers selected from standard libraries.[5] The novel chemical functionalities introduced by iso-dC can mediate interactions that are inaccessible to the four canonical bases, leading to lower Kd values.
Table 1: Comparison of Binding Affinities for Target Protein 'X'
| Aptamer Candidate | Library Type | Kd (Dissociation Constant) | Fold Improvement |
| Standard-Apt-1 | A, T, C, G | 52 nM | - |
| Standard-Apt-2 | A, T, C, G | 89 nM | - |
| iso-dC-Apt-1 | A, C, G, iso-dC | 850 pM | 61x |
| iso-dC-Apt-2 | A, C, G, iso-dC | 420 pM | 124x |
| iso-dC-Apt-3 | A, C, G, iso-dC | 1.1 nM | 47x |
This table presents hypothetical but representative data illustrating the significant affinity enhancement achievable with iso-dC-modified libraries.
Conclusion
The incorporation of 2-Aminoisocytosine into SELEX libraries represents a powerful strategy for expanding the functional potential of DNA aptamers. By increasing the chemical information density of the nucleic acid, this method enables the selection of ligands with significantly enhanced binding affinities and potentially novel specificities. The protocols outlined in this guide provide a comprehensive framework for researchers to leverage this expanded genetic alphabet, paving the way for the development of next-generation aptamers for advanced diagnostic and therapeutic applications.
References
-
Fairman Studios. SomaLogic Somamer MOA. 13
-
SomaLogic, Inc. Single SOMAmer™ Reagents an antibody alternative for affinity assays. 24
-
Switzer, C., et al. (1993). Enzymatic recognition of the base pair between isocytidine and isoguanosine. PubMed. 18
-
Citogen. SomaScan | SomaLogic. 14
-
MetwareBio. SomaScan Proteomics Technology: Principles and Advantages. 15
-
SomaLogic, Inc. SomaScan Platform - Our Science. 16
-
Kimoto, M., et al. (2013). Generation of high-affinity DNA aptamers using an expanded genetic alphabet. Nature Biotechnology. 5
-
Tolle, F., & Mayer, G. (2017). Identification and characterization of nucleobase-modified aptamers by click-SELEX. Nature Protocols. 25
-
Benner, S.A., et al. An in vitro screening technique for DNA polymerases that can incorporate modified nucleotides. Oxford Academic. 21
-
Futami, K., et al. (2018). Genetic Alphabet Expansion Provides Versatile Specificities and Activities of Unnatural-Base DNA Aptamers Targeting Cancer Cells. PubMed Central. 11
-
Futami, K., et al. (2018). Genetic Alphabet Expansion Provides Versatile Specificities and Activities of Unnatural-Base DNA Aptamers Targeting Cancer Cells. Semantic Scholar. 26
-
Vanparijs, N., et al. (2020). Chemical Modification of Aptamers for Increased Binding Affinity in Diagnostic Applications: Current Status and Future Prospects. MDPI. 2
-
Lázaro, J. M., et al. (2022). DNA Polymerases for Whole Genome Amplification: Considerations and Future Directions. MDPI. 27
-
Kimoto, M., & Hirao, I. DNA Aptamer Generation by Genetic Alphabet Expansion SELEX (ExSELEX) Using an Unnatural Base Pair System. Springer Nature Experiments. 6
-
Spinnler, B., et al. (2021). SELEX: Critical factors and optimization strategies for successful aptamer selection. PMC. 28
-
Chaput, J.C. (2012). Engineering polymerases for new functions. PMC - NIH. 22
-
Renders, M., et al. (2018). Isoguanine and 5-Methyl-Isocytosine Bases, In Vitro and In Vivo. ResearchGate. 19
-
Romesberg, F.E. (2014). The Expanded Genetic Alphabet. PMC - PubMed Central - NIH. 7
-
Zhang, Y., et al. (2023). Chemically modified aptamers for improving binding affinity to the target proteins via enhanced non-covalent bonding. NIH. 3
-
Schuitt, S.M. Modified Nucleoside Triphosphate Applications: An Overview of the SELEX Process. TriLink BioTechnologies. 1
-
White, B.S., et al. (2014). Kinetic and Equilibrium Binding Characterization of Aptamers to Small Molecules using a Label-Free, Sensitive, and Scalable Platform. NIH. 23
-
Benner, S.A., et al. (2018). Artificially Expanded Genetic Information Systems for New Aptamer Technologies. PMC. 29
-
NEB. Polymerases for DNA Manipulation. 30
-
Hamashima, K., et al. (2018). Creation of unnatural base pairs for genetic alphabet expansion toward synthetic xenobiology. PubMed. 8
-
Špringer, T., et al. (2020). Principle of the modified SELEX procedure used in this study. ResearchGate. 31
-
Kimoto, M., & Hirao, I. (2017). DNA Aptamer Generation by Genetic Alphabet Expansion SELEX (ExSELEX) Using an Unnatural Base Pair System. PubMed. 9
-
Zhang, Y., et al. (2023). Chemically modified aptamers for improving binding affinity to the target proteins via enhanced non-covalent bonding. Semantic Scholar. 32
-
Wikipedia. Systematic evolution of ligands by exponential enrichment. 33
-
Promega Corporation. PCR Amplification | An Introduction to PCR Methods. 34
-
Zhang, W., et al. (2022). Enzymatic Synthesis of the Unnatural Nucleotide 2'-Deoxyisoguanosine 5'-Monophosphate. Chembiochem. 17
-
Various Authors. (2025). SELEX with modified nucleotides. ResearchGate. 35
-
Hirao, I., et al. (2020). Genetic alphabet expansion technology by creating unnatural base pairs. RSC Publishing. 10
-
Li, L., et al. (2020). The development of isoguanosine: from discovery, synthesis, and modification to supramolecular structures and potential applications. RSC Publishing. 36
-
Kimoto, M., et al. (2017). Evolving Aptamers with Unnatural Base Pairs. PubMed. 12
-
Somoza, R.A., et al. (2021). Methods for cell- and tissue-specific DNA aptamer selection. PMC - NIH. 37
-
Roberts, C., et al. (1997). Enzymatic incorporation of a new base pair into DNA and RNA. Journal of the American Chemical Society. 20
-
Gawande, B.N., et al. (2017). Selection of DNA aptamers with two modified bases. PMC - NIH. 4
-
Lee, Y.J., & Lee, S.W. (2015). Nucleic Acid Aptamers: New Methods for Selection, Stabilization, and Application in Biomedical Science. NIH. 38
-
Sode, K., & Ikebukuro, K. (2016). Methods for Improving Aptamer Binding Affinity. Semantic Scholar. 39
Sources
- 1. trilinkbiotech.com [trilinkbiotech.com]
- 2. mdpi.com [mdpi.com]
- 3. Chemically modified aptamers for improving binding affinity to the target proteins via enhanced non-covalent bonding - PMC [pmc.ncbi.nlm.nih.gov]
- 4. Selection of DNA aptamers with two modified bases - PMC [pmc.ncbi.nlm.nih.gov]
- 5. researchgate.net [researchgate.net]
- 6. DNA Aptamer Generation by Genetic Alphabet Expansion SELEX (ExSELEX) Using an Unnatural Base Pair System | Springer Nature Experiments [experiments.springernature.com]
- 7. The Expanded Genetic Alphabet - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Creation of unnatural base pairs for genetic alphabet expansion toward synthetic xenobiology - PubMed [pubmed.ncbi.nlm.nih.gov]
- 9. DNA Aptamer Generation by Genetic Alphabet Expansion SELEX (ExSELEX) Using an Unnatural Base Pair System - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Genetic alphabet expansion technology by creating unnatural base pairs - Chemical Society Reviews (RSC Publishing) [pubs.rsc.org]
- 11. Genetic Alphabet Expansion Provides Versatile Specificities and Activities of Unnatural-Base DNA Aptamers Targeting Cancer Cells - PMC [pmc.ncbi.nlm.nih.gov]
- 12. Evolving Aptamers with Unnatural Base Pairs - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. SomaLogic Somamer MOA - Fairman Studios [fairmanstudios.com]
- 14. SomaScan | SomaLogic | Citogen [citogen.es]
- 15. SomaScan Proteomics Technology: Principles and Advantages - MetwareBio [metwarebio.com]
- 16. SomaScan Platform - Our Science - Platform - SomaLogic [somalogic.com]
- 17. Enzymatic Synthesis of the Unnatural Nucleotide 2'-Deoxyisoguanosine 5'-Monophosphate - PubMed [pubmed.ncbi.nlm.nih.gov]
- 18. Enzymatic recognition of the base pair between isocytidine and isoguanosine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. researchgate.net [researchgate.net]
- 20. pubs.acs.org [pubs.acs.org]
- 21. academic.oup.com [academic.oup.com]
- 22. Engineering polymerases for new functions - PMC [pmc.ncbi.nlm.nih.gov]
- 23. Kinetic and Equilibrium Binding Characterization of Aptamers to Small Molecules using a Label-Free, Sensitive, and Scalable Platform - PMC [pmc.ncbi.nlm.nih.gov]
- 24. Single SOMAmer™ Reagents an antibody alternative for affinity assays [somalogic.com]
- 25. Identification and characterization of nucleobase-modified aptamers by click-SELEX | Springer Nature Experiments [experiments.springernature.com]
- 26. Genetic Alphabet Expansion Provides Versatile Specificities and Activities of Unnatural-Base DNA Aptamers Targeting Cancer Cells | Semantic Scholar [semanticscholar.org]
- 27. mdpi.com [mdpi.com]
- 28. SELEX: Critical factors and optimization strategies for successful aptamer selection - PMC [pmc.ncbi.nlm.nih.gov]
- 29. Artificially Expanded Genetic Information Systems for New Aptamer Technologies - PMC [pmc.ncbi.nlm.nih.gov]
- 30. neb.com [neb.com]
- 31. researchgate.net [researchgate.net]
- 32. Chemically modified aptamers for improving binding affinity to the target proteins via enhanced non-covalent bonding | Semantic Scholar [semanticscholar.org]
- 33. Systematic evolution of ligands by exponential enrichment - Wikipedia [en.wikipedia.org]
- 34. PCR Amplification | An Introduction to PCR Methods [promega.com]
- 35. researchgate.net [researchgate.net]
- 36. The development of isoguanosine: from discovery, synthesis, and modification to supramolecular structures and potential applications - RSC Advances (RSC Publishing) DOI:10.1039/C9RA09427J [pubs.rsc.org]
- 37. Methods for cell- and tissue-specific DNA aptamer selection - PMC [pmc.ncbi.nlm.nih.gov]
- 38. Nucleic Acid Aptamers: New Methods for Selection, Stabilization, and Application in Biomedical Science - PMC [pmc.ncbi.nlm.nih.gov]
- 39. pdfs.semanticscholar.org [pdfs.semanticscholar.org]
2-Aminoisocytosine in PCR and its effect on amplification
Application Notes & Protocols
Topic: 2-Aminoisocytosine (isoC) in PCR: Enhancing Specificity and Expanding the Genetic Alphabet
For: Researchers, scientists, and drug development professionals.
Introduction: Beyond the Four-Letter Code
The polymerase chain reaction (PCR) is a cornerstone of molecular biology, enabling the exponential amplification of specific DNA sequences. This process has traditionally relied on the canonical four-letter genetic alphabet: Adenine (A), Guanine (G), Cytosine (C), and Thymine (T). However, the expansion of this alphabet with unnatural base pairs (UBPs) offers powerful new capabilities, from site-specific labeling of nucleic acids to the development of highly specific diagnostic assays.[1][2]
One of the most well-studied and functional UBPs is the pair formed between 2-aminoisocytosine (isoC, also referred to as isocytosine) and isoguanine (isoG).[3][4] Unlike the natural A-T and G-C pairs, which are defined by a specific pattern of hydrogen bond donors and acceptors, the isoC-isoG pair utilizes an alternative, yet equally specific, hydrogen bonding pattern. This orthogonality allows it to function as a third, independent base pair within a DNA duplex, without interfering with the natural base pairing.[4] This guide provides a detailed overview of the mechanism, applications, and protocols for incorporating the isoC-isoG system into PCR workflows.
The Mechanism of an Orthogonal Base Pair
The specificity of the isoC-isoG pair stems from its unique hydrogen bonding arrangement, which is incompatible with the four natural bases. As illustrated below, isoC and isoG form three hydrogen bonds with each other in a pattern that is a structural isomer of the natural G-C pair. This ensures that during DNA replication, isoC in the template strand will selectively direct the incorporation of an isoG nucleotide, and vice-versa.
Caption: Hydrogen bonding patterns of natural and unnatural base pairs.
Fidelity and Polymerase Interaction
The successful amplification of DNA containing a UBP is critically dependent on the ability of a DNA polymerase to recognize and extend from this artificial pair. DNA polymerases achieve fidelity not just through hydrogen bonding, but also by recognizing the correct geometric shape of a nascent base pair in the active site.[5][6] Several polymerases, including the Klenow fragment of E. coli DNA Polymerase I and certain reverse transcriptases, have been shown to incorporate isoG opposite a template isoC and vice versa.[7]
However, the fidelity is not perfect. The isoC-isoG pair has demonstrated a fidelity of approximately 98% per PCR cycle.[3] While high, this error rate means that after 20 cycles of PCR, the retention of the unnatural pair at a specific site could theoretically drop to around 67% (0.98^20 ≈ 0.67).[8] A primary source of this infidelity is the ability of isoguanine to adopt a minor tautomeric form that can mispair with thymine (T).[4][7] Therefore, experimental conditions must be carefully optimized to maximize fidelity.
Effect on PCR Amplification and Applications
Incorporating the isoC-isoG pair can significantly enhance PCR-based applications by providing an orthogonal information channel.
-
Enhanced Specificity in Diagnostics: By placing isoC in a PCR primer and its complement, isoG, in a corresponding probe, it is possible to create highly specific detection systems. Amplification and signal generation only occur if the specific primer binds, preventing false positives from non-specific amplification. This principle is utilized in platforms like the Plexor® quantitative PCR system.[1]
-
Site-Specific Labeling: The isoC-isoG pair allows for the precise incorporation of modified nucleotides. For example, a d-isoGTP molecule linked to a fluorescent dye or a biotin tag can be specifically incorporated opposite an isoC base in a DNA template, enabling targeted labeling of the resulting amplicon.[2]
-
Expanding Genetic Information: As a functional third base pair, isoC-isoG is a foundational tool in synthetic biology for creating semi-synthetic organisms with an expanded genetic code.[8][9]
Experimental Workflow and Protocols
The successful implementation of the isoC-isoG system requires careful planning, from oligo design to PCR optimization. The general workflow is outlined below.
Caption: General experimental workflow for PCR with 2-aminoisocytosine.
Protocol 1: Primer Design with 2-Aminoisocytosine (isoC)
Proper primer design is critical for specificity and efficiency. Follow standard primer design guidelines with additional considerations for the unnatural base.
Standard Design Parameters:
-
Melting Temperature (Tm): Aim for 50-60°C. The Tm of primer pairs should be within 5°C of each other.[10]
-
3' End: The 3' end is critical for polymerase extension. It should bind perfectly to the template. Including a G or C at the 3' end (a "GC clamp") can promote specific binding.[11][12]
-
Secondary Structures: Use online tools to check for and avoid hairpins and self-dimers.[13]
isoC-Specific Considerations:
-
Placement: Position the isoC base(s) away from the critical 3' terminus if possible, unless the experimental design specifically requires it for discrimination. Mismatches near the 3' end are more likely to inhibit polymerase extension.
-
Tm Calculation: The thermodynamic properties of isoC-isoG pairs are similar to G-C pairs. For Tm estimation, you can often treat an isoC-isoG pair as a G-C pair. However, for precise calculations, use software or algorithms that allow for custom base parameters if available.
-
Purification: Always use high-purity (e.g., HPLC-purified) oligonucleotides to ensure that truncated synthesis products are removed and that the modified base is intact.[13] Chemical instability of isoC can be a concern during synthesis, making quality control essential.[7]
Protocol 2: PCR Reaction Setup
This protocol provides a starting point for a standard 25 µL PCR reaction. Optimization, particularly of the MgCl₂ and dNTP concentrations, is highly recommended.
| Component | Final Concentration | Notes |
| 5X PCR Buffer | 1X | Use the buffer supplied with your chosen DNA polymerase. |
| MgCl₂ | 1.5 - 3.0 mM | CRITICAL: Modified dNTPs can chelate Mg²⁺ ions. Optimization in 0.5 mM increments is recommended. Start at a higher concentration than for standard PCR.[14][15] |
| dATP, dCTP, dGTP, dTTP | 200 µM each | Standard concentration for most applications.[15] |
| d-isoCTP | 50 - 200 µM | Must be added if the template contains isoG. |
| d-isoGTP | 50 - 200 µM | Must be added if the template contains isoC. |
| Forward Primer | 0.2 - 0.5 µM | Use HPLC-purified primers. |
| Reverse Primer | 0.2 - 0.5 µM | Use HPLC-purified primers. |
| Template DNA | 1 pg - 10 ng | Amount depends on the complexity of the DNA (plasmid, gDNA, etc.). |
| DNA Polymerase | 0.5 - 1.25 units | Choose a polymerase known to be compatible with modified bases (e.g., certain variants of Taq, Pfu, or Klenow Fragment). Proofreading (3'→5' exo) activity can sometimes improve fidelity.[3][7] |
| Nuclease-Free Water | To 25 µL |
Setup Procedure:
-
Assemble all reaction components on ice to prevent premature polymerase activity.[15]
-
Add the DNA polymerase last.
-
Gently mix the components and centrifuge briefly to collect the contents at the bottom of the tube.
-
Transfer the reactions to a thermocycler preheated to the initial denaturation temperature.[15]
Protocol 3: Thermal Cycling Parameters
The following is a typical three-step PCR profile. Durations and temperatures may need to be adjusted based on the specific primers, amplicon length, and polymerase used.
| Step | Temperature | Duration | Cycles | Rationale |
| Initial Denaturation | 95°C | 2 min | 1 | Ensures complete denaturation of complex template DNA.[15][16] |
| Denaturation | 95°C | 15-30 sec | Separates the DNA strands in each cycle. | |
| Annealing | 50-60°C | 15-30 sec | 25-35 | Set 3-5°C below the lowest primer Tm to allow specific primer binding.[16][17] |
| Extension | 68-72°C | 1 min/kb | The optimal temperature for most thermostable polymerases. The time depends on the length of the target amplicon.[15] | |
| Final Extension | 68-72°C | 5 min | 1 | Ensures that any remaining single-stranded DNA is fully extended.[16] |
| Hold | 4-10°C | Indefinite | 1 |
Troubleshooting Common Issues
| Problem | Possible Cause | Recommended Solution |
| No or Low Amplification | Suboptimal MgCl₂ concentration. | Titrate MgCl₂ concentration in 0.5 mM increments from 1.5 mM to 4.0 mM.[15] |
| Annealing temperature is too high. | Decrease the annealing temperature in 2°C increments. A gradient PCR can efficiently determine the optimal temperature.[17] | |
| Incompatible DNA polymerase. | Ensure your polymerase can incorporate modified nucleotides. Consult the manufacturer's literature or test different enzymes.[7][18] | |
| Degraded d-isoCTP/d-isoGTP. | Use fresh, high-quality stocks of the unnatural triphosphates. | |
| Non-Specific Products | Annealing temperature is too low. | Increase the annealing temperature in 2°C increments.[15] |
| Primer design issues (e.g., dimers). | Redesign primers to eliminate self-dimerization and hairpin potential.[13] | |
| MgCl₂ concentration is too high. | Decrease the MgCl₂ concentration. Excess Mg²⁺ can reduce polymerase fidelity and promote non-specific binding.[15] | |
| Incorrect Product Size | Mispairing of isoG with Thymine (T). | Optimize reaction conditions (especially buffer and dNTP concentrations) to favor correct pairing. Some polymerases may exhibit higher fidelity than others.[4][7] |
Conclusion
The 2-aminoisocytosine:isoguanine pair represents a significant step toward expanding the functional capabilities of DNA. By serving as an orthogonal and replicable third base pair, it enables the development of advanced PCR applications with enhanced specificity and the ability to site-specifically modify amplicons. While its implementation requires careful optimization of enzyme choice, reagent concentrations, and cycling conditions, the isoC-isoG system provides a powerful tool for researchers in diagnostics, molecular biology, and synthetic biology.
References
-
Kimoto, M., Kawai, R., Mitsui, T., Yokoyama, S., & Hirao, I. (2009). A highly specific and efficient unnatural base pair system as a third base pair for PCR amplification. National Institutes of Health. [Link]
-
Kimoto, M., et al. (2004). Efficient PCR amplification by an unnatural base pair system. Nucleic Acids Symposium Series. [Link]
-
Moran, S., et al. (2003). Non-Natural Nucleotides as Probes for the Mechanism and Fidelity of DNA Polymerases. MDPI. [Link]
-
Kimoto, M., et al. (2004). An unnatural base pair system for efficient PCR amplification and functionalization of DNA molecules. Nucleic Acids Research, Oxford Academic. [Link]
-
Hirao, I., et al. (2012). Unnatural base pair systems toward the expansion of the genetic alphabet in the central dogma. Proceedings of the Japan Academy, Series B, Physical and Biological Sciences. [Link]
-
Mitsui, T., Kimoto, M., Sato, A., Yokoyama, S., & Hirao, I. (2003). An Efficient Unnatural Base Pair for PCR Amplification. Journal of the American Chemical Society. [Link]
-
Johnson, S. C., et al. (2004). Sequence determination of nucleic acids containing 5-methylisocytosine and isoguanine: identification and insight into polymerase replication of the non-natural nucleobases. Nucleic Acids Research, Oxford Academic. [Link]
-
Kabranov, A., et al. (2003). Use of Base Modifications in Primers and Amplicons to Improve Nucleic Acids Detection in the Real-Time Snake Polymerase Chain Reaction. National Institutes of Health. [Link]
-
Leconte, A. M., et al. (2005). Substituent effects on the pairing and polymerase recognition of simple unnatural base pairs. Nucleic Acids Research, Oxford Academic. [Link]
-
La-Mira, P., et al. (2012). Optimization of Unnatural Base Pair Packing for Polymerase Recognition. National Center for Biotechnology Information. [Link]
-
Xu, W., et al. (2020). The development of isoguanosine: from discovery, synthesis, and modification to supramolecular structures and potential applications. RSC Publishing. [Link]
-
Wikipedia contributors. (n.d.). Nucleotide base. Wikipedia. [Link]
-
Latham, M. P., et al. (2017). In Vitro Selection Using Modified or Unnatural Nucleotides. National Center for Biotechnology Information. [Link]
-
Loakes, D. (2001). PCR Amplification of Base-Modified DNA. ResearchGate. [Link]
-
Kutyavin, I. V., et al. (2000). Use of Base-Modified Duplex-Stabilizing Deoxynucleoside 5′-Triphosphates To Enhance the Hybridization Properties of Primers and Probes in Detection Polymerase Chain Reaction. Biochemistry. [Link]
-
Eureka, L. S. (2024). Mechanistic Insights: How Different DNA Polymerases Achieve Fidelity. LinkedIn. [Link]
-
Bio-Rad Laboratories. (n.d.). Optimising PCR: How Thermal Cycling Conditions Influence PCR Protocol Efficiency. Bio-Rad. [Link]
-
He, S., et al. (2012). Polymerase Chain Reaction: Basic Protocol Plus Troubleshooting and Optimization Strategies. National Center for Biotechnology Information. [Link]
-
Saldivar, E. A., et al. (2018). Understanding the Fidelity and Specificity of DNA Polymerase I. ACS Omega. [Link]
-
Kuwahara, M., et al. (2004). Simultaneous incorporation of three different modified nucleotides during PCR. Nucleic Acids Symposium Series, Oxford Academic. [Link]
-
Addgene. (n.d.). Protocol - How to Design Primers. Addgene. [Link]
-
Switzer, C. Y., et al. (1993). Enzymatic recognition of the base pair between isocytidine and isoguanosine. Biochemistry. [Link]
-
ResearchGate. (n.d.). isoC, isoG, and their base pairs. ResearchGate. [Link]
-
Addgene. (2020). How to Design Primers for PCR. YouTube. [Link]
-
Sakamoto, S., et al. (2002). Enzymatic incorporation of chemically-modified nucleotides into DNAs. Nucleic Acids Research Supplement. [Link]
-
Maxfield, T. (2013). Primer Design for PCR. YouTube. [Link]
-
Geneious. (n.d.). How to Design PCR Primers in Geneious Prime. Geneious. [Link]
-
Wolfe, M. S., et al. (2002). Synthesis and polymerase incorporation of 5′-amino-2′,5′-dideoxy-5′-N-triphosphate nucleotides. National Center for Biotechnology Information. [Link]
-
Ketterer, M., et al. (2022). Non-canonical nucleosides: Biomimetic triphosphorylation, incorporation into mRNA and effects on translation and structure. FEBS Open Bio. [Link]
-
Gall, U., et al. (2021). Advances in the Enzymatic Synthesis of Nucleoside-5′-Triphosphates and Their Analogs. MDPI. [Link]
-
Vaught, J. D., et al. (2010). Synthesis and Enzymatic Incorporation of Modified Deoxyuridine Triphosphates. MDPI. [Link]
-
Jäschke, A., et al. (2010). Enzymatic Incorporation of Emissive Pyrimidine Ribonucleotides. National Center for Biotechnology Information. [Link]
Sources
- 1. Highly specific unnatural base pair systems as a third base pair for PCR amplification - PMC [pmc.ncbi.nlm.nih.gov]
- 2. academic.oup.com [academic.oup.com]
- 3. academic.oup.com [academic.oup.com]
- 4. academic.oup.com [academic.oup.com]
- 5. Non-Natural Nucleotides as Probes for the Mechanism and Fidelity of DNA Polymerases - PMC [pmc.ncbi.nlm.nih.gov]
- 6. Mechanistic Insights: How Different DNA Polymerases Achieve Fidelity [synapse.patsnap.com]
- 7. Enzymatic recognition of the base pair between isocytidine and isoguanosine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Unnatural base pair systems toward the expansion of the genetic alphabet in the central dogma - PMC [pmc.ncbi.nlm.nih.gov]
- 9. Nucleotide base - Wikipedia [en.wikipedia.org]
- 10. addgene.org [addgene.org]
- 11. youtube.com [youtube.com]
- 12. youtube.com [youtube.com]
- 13. neb.com [neb.com]
- 14. In Vitro Selection Using Modified or Unnatural Nucleotides - PMC [pmc.ncbi.nlm.nih.gov]
- 15. neb.com [neb.com]
- 16. 詳解 PCR 原理、步驟與循環參數—成功的六個關鍵考慮因素 | Thermo Fisher Scientific - TW [thermofisher.com]
- 17. psychreg.org [psychreg.org]
- 18. Enzymatic incorporation of chemically-modified nucleotides into DNAs - PubMed [pubmed.ncbi.nlm.nih.gov]
Application Notes and Protocols for the Synthesis and Enzymatic Incorporation of 2-Aminoisocytosine Triphosphates
Introduction: Expanding the Genetic Alphabet
The central dogma of molecular biology is elegantly written in a four-letter genetic alphabet (A, T, G, and C). However, the expansion of this alphabet with unnatural base pairs (UBPs) offers tantalizing possibilities for the creation of novel biological molecules and functionalities.[1][2] One such non-canonical nucleobase, 2-aminoisocytosine (isoC), presents unique hydrogen bonding patterns that can be exploited for the development of orthogonal genetic systems. When paired with its cognate partner, isoguanine (isoG), it forms a stable base pair with three hydrogen bonds, similar to the natural G-C pair. This application note provides a comprehensive guide for the chemical synthesis of 2-aminoisocytosine deoxyribonucleoside triphosphate (d-isoCTP) and its subsequent enzymatic incorporation into DNA. These protocols are designed for researchers in molecular biology, synthetic biology, and drug development who are interested in exploring the potential of an expanded genetic alphabet.
Part 1: Chemical Synthesis of 2-Aminoisocytosine Deoxyribonucleoside Triphosphate (d-isoCTP)
The synthesis of d-isoCTP is a multi-step process that begins with the synthesis of the 2-aminoisocytosine deoxyribonucleoside, followed by its phosphorylation to the triphosphate form.
Section 1.1: Synthesis of 2-Aminoisocytosine Deoxyribonucleoside
The synthesis of the deoxyribonucleoside of 2-aminoisocytosine can be achieved through a glycosylation reaction between a protected deoxyribose sugar and the 2-aminoisocytosine base.[3]
Protocol 1: Synthesis of 2-Aminoisocytosine Deoxyribonucleoside
-
Preparation of Protected Deoxyribose: Start with a commercially available protected deoxyribose derivative, such as 1-chloro-3,5-di-O-p-toluoyl-2-deoxy-α-D-ribofuranose. This protecting group strategy is crucial to ensure regioselective glycosylation at the N1 position of the nucleobase.
-
Preparation of Silylated 2-Aminoisocytosine: 2-Aminoisocytosine (isocytosine) can be synthesized from guanidine and malic acid.[4] To enhance its solubility and reactivity in organic solvents, it should be silylated. Suspend 2-aminoisocytosine in hexamethyldisilazane (HMDS) and add a catalytic amount of ammonium sulfate. Reflux the mixture until the solution becomes clear, indicating the formation of the persilylated derivative. Remove the excess HMDS under vacuum.
-
Glycosylation Reaction: Dissolve the silylated 2-aminoisocytosine and the protected deoxyribose in a dry aprotic solvent such as acetonitrile. Add a Lewis acid catalyst, for example, trimethylsilyl trifluoromethanesulfonate (TMSOTf), dropwise at 0°C. Allow the reaction to warm to room temperature and stir overnight. The progress of the reaction can be monitored by Thin Layer Chromatography (TLC).
-
Deprotection: Upon completion of the glycosylation, the toluoyl protecting groups are removed by treatment with a solution of sodium methoxide in methanol. The reaction is typically stirred at room temperature for several hours.
-
Purification: The crude product is purified by silica gel column chromatography to yield the 2-aminoisocytosine deoxyribonucleoside. The structure and purity should be confirmed by ¹H NMR, ¹³C NMR, and mass spectrometry.[5]
Table 1: Summary of Reagents for Nucleoside Synthesis
| Reagent | Purpose |
| 1-chloro-3,5-di-O-p-toluoyl-2-deoxy-α-D-ribofuranose | Protected deoxyribose donor |
| 2-Aminoisocytosine | Nucleobase |
| Hexamethyldisilazane (HMDS) | Silylating agent |
| Ammonium sulfate | Catalyst for silylation |
| Acetonitrile | Anhydrous solvent |
| Trimethylsilyl trifluoromethanesulfonate (TMSOTf) | Lewis acid catalyst |
| Sodium methoxide in methanol | Deprotection reagent |
| Silica gel | Stationary phase for chromatography |
Section 1.2: Phosphorylation of 2-Aminoisocytosine Deoxyribonucleoside
The conversion of the nucleoside to its 5'-triphosphate is a critical step. The Ludwig-Eckstein method is a widely used and reliable one-pot procedure for this transformation.[6]
Protocol 2: Triphosphorylation of 2-Aminoisocytosine Deoxyribonucleoside
-
Anhydrous Conditions: It is imperative that the reaction is carried out under strictly anhydrous conditions. Dry the 2-aminoisocytosine deoxyribonucleoside by co-evaporation with anhydrous pyridine.
-
Phosphitylation: Dissolve the dried nucleoside in anhydrous pyridine and cool to 0°C. Add 2-chloro-4H-1,3,2-benzodioxaphosphorin-4-one to the solution. This reagent will react with the 5'-hydroxyl group of the nucleoside.
-
Oxidation and Pyrophosphate Addition: After the initial phosphorylation, a mixture of tributylammonium pyrophosphate and tributylamine in anhydrous DMF is added. This is followed by an oxidizing agent, typically iodine in pyridine/water, to form the triphosphate.
-
Hydrolysis and Deprotection: The reaction mixture is then treated with aqueous ammonia to hydrolyze any remaining protecting groups and cyclic intermediates.
-
Purification: The crude d-isoCTP is purified by anion-exchange chromatography on a DEAE-Sephadex or similar resin.[7][8] A gradient of a volatile buffer, such as triethylammonium bicarbonate (TEAB), is used for elution. The fractions containing the triphosphate are identified by UV absorbance and pooled.
-
Desalting and Lyophilization: The pooled fractions are desalted, for instance by size-exclusion chromatography, and then lyophilized to obtain the d-isoCTP as a stable salt.[9]
Diagram 1: Chemical Synthesis Workflow
Caption: Workflow for the chemical synthesis of d-isoCTP.
Section 1.3: Characterization of d-isoCTP
The final product should be rigorously characterized to confirm its identity and purity.
-
NMR Spectroscopy: ³¹P NMR spectroscopy is essential to confirm the presence of the triphosphate moiety, which will show three distinct phosphorus signals. ¹H and ¹³C NMR will confirm the structure of the nucleoside.[10]
-
Mass Spectrometry: High-resolution mass spectrometry (HRMS) should be used to confirm the exact mass of the d-isoCTP.[11]
-
HPLC Analysis: The purity of the final product should be assessed by anion-exchange HPLC.[7]
Part 2: Enzymatic Incorporation of d-isoCTP into DNA
The successful synthesis of d-isoCTP is followed by its enzymatic incorporation into a DNA strand using a DNA polymerase. The choice of polymerase is critical, as not all polymerases can efficiently accept modified nucleotides.[12]
Section 2.1: Selection of DNA Polymerase
Several commercially available DNA polymerases have been shown to be tolerant of modified nucleotides. For the incorporation of d-isoCTP, we recommend starting with a high-fidelity, thermostable polymerase that lacks 3'-5' exonuclease activity (exo-).
Table 2: Recommended DNA Polymerases for Modified Nucleotide Incorporation
| Polymerase | Key Features |
| Vent (exo-) DNA Polymerase | High fidelity, thermostable, lacks proofreading.[13] |
| KOD XL DNA Polymerase | High fidelity, good processivity.[12] |
| Pwo DNA Polymerase | Thermostable, high fidelity.[12] |
| Phusion HF DNA Polymerase | High fidelity, fast elongation rate. |
Section 2.2: Primer Extension Assay
A primer extension assay is a straightforward method to assess the ability of a DNA polymerase to incorporate a single or a few modified nucleotides.
Protocol 3: Primer Extension Assay for d-isoCTP Incorporation
-
Primer-Template Design: Design a primer and a template oligonucleotide. The template should contain one or more isoguanine (isoG) bases at the positions where d-isoCTP incorporation is desired. The primer should be labeled (e.g., with a 5'-fluorescent dye) for visualization.
-
Reaction Setup: Set up the primer extension reaction in a suitable buffer containing the primer-template duplex, the chosen DNA polymerase, dATP, dGTP, dCTP, dTTP, and the synthesized d-isoCTP. Run a control reaction without d-isoCTP.
-
Reaction Conditions:
-
1x Polymerase Buffer
-
200 µM each of dATP, dGTP, dCTP, dTTP
-
100 µM d-isoCTP
-
1 µM Primer-Template Duplex
-
1-2 units of DNA Polymerase
-
Incubate at the optimal temperature for the polymerase for 30-60 minutes.
-
-
Analysis: The reaction products are analyzed by denaturing polyacrylamide gel electrophoresis (PAGE). Successful incorporation will result in a full-length extension product.
Diagram 2: Primer Extension Assay Workflow
Caption: Workflow for the primer extension assay.
Section 2.3: Polymerase Chain Reaction (PCR) with d-isoCTP
To generate longer DNA fragments containing multiple 2-aminoisocytosine residues, PCR can be employed.
Protocol 4: PCR with d-isoCTP
-
Template and Primer Design: The template DNA should contain isoG at the desired positions. The primers should flank the region to be amplified.
-
PCR Setup:
-
1x Thermostable Polymerase Buffer
-
200 µM each of dATP, dGTP, dCTP, dTTP
-
50-100 µM d-isoCTP
-
0.5 µM of each primer
-
1-10 ng of template DNA
-
1-2.5 units of a thermostable DNA polymerase (e.g., Vent (exo-)).
-
-
Thermocycling Conditions:
-
Initial Denaturation: 95°C for 2 minutes
-
25-35 Cycles:
-
Denaturation: 95°C for 30 seconds
-
Annealing: 55-65°C for 30 seconds
-
Extension: 72°C for 1 minute/kb
-
-
Final Extension: 72°C for 5 minutes
-
-
Analysis: The PCR product can be analyzed by agarose gel electrophoresis. The identity of the product can be confirmed by sequencing, which may require specialized techniques to read through the modified bases.
Part 3: Properties and Applications of DNA Containing 2-Aminoisocytosine
The incorporation of 2-aminoisocytosine into DNA can impart novel properties to the nucleic acid.
-
Orthogonal Base Pairing: The isoC:isoG base pair is orthogonal to the natural A:T and G:C pairs, meaning it does not cross-pair with them. This allows for the creation of a parallel genetic system.[1]
-
Increased Information Density: The addition of a fifth and sixth base to the genetic alphabet significantly increases the information storage capacity of DNA.[14][15]
-
Novel Functionalities: DNA containing 2-aminoisocytosine can be used to develop novel aptamers and DNAzymes with enhanced binding affinities and catalytic activities.[13] It can also be used for site-specific labeling of DNA with fluorescent probes or other functional groups.
Conclusion
The synthesis and enzymatic incorporation of 2-aminoisocytosine triphosphate represents a significant step towards the expansion of the genetic alphabet. The protocols outlined in this application note provide a framework for researchers to produce and utilize this modified nucleotide. While the chemical synthesis requires expertise in organic chemistry, the enzymatic incorporation is accessible to molecular biologists. The ability to create DNA with an expanded genetic code opens up new avenues for research in synthetic biology, diagnostics, and therapeutics.
References
- Chemical phosphorylation of deoxyribonucleosides and thermolytic DNA oligonucleotides. Curr Protoc Nucleic Acid Chem. 2006 Oct:Chapter 13:Unit 13.6.
- Altering DNA polymerase incorporation fidelity by distorting the dNTP binding pocket with a bulky carcinogen-damaged templ
- Purification of Nucleotide Triphosphates with DuPont™ AmberChrom™ Fine Mesh Resins Brochure. DuPont.
- Synthesis and Enzymatic Incorporation of Modified Deoxyuridine Triphosph
- The use of modified and non-natural nucleotides provide unique insights into pro-mutagenic replication c
- The Expanded Genetic Alphabet. PMC.
- The New, Expanded Genetic Alphabet Rewrites Life. Inverse.
- Effect of DNA base modification on polymerase chain reaction efficiency and fidelity.
- Purification of Nucleotide Triphosphates published by The Column Article. DuPont.
- Fidelity of nucleotide incorpor
- Synthesis and Properties of α-Phosphate-Modified Nucleoside Triphosph
- Modified Nucleoside Triphosphates Exist in Mammals. The Royal Society of Chemistry.
- Expanding the Genetic Alphabet. Taylor & Francis Online.
- Expanding DNA's alphabet lets cells produce novel proteins. AP News.
- Expansion of the Genetic Alphabet: Unnatural Nucleobases and Their Applic
- High-resolution mapping of DNA polymerase fidelity using nucleotide imbalances and next-generation sequencing. Nucleic Acids Research.
- Characterization of thymidine kinase and phosphorylation of deoxyribonucleosides in Chlamydomonas reinhardti. PubMed.
- Method for purifying and preparing nucleoside triphosphate derivative.
- Modified nucleoside triphosphates in bacterial research for in vitro and live-cell applic
- Nucleoside Triphosphates — Building Blocks for the Modific
- A GENERAL SYNTHESIS OF NUCLEOSIDES-5′ TRIPHOSPH
- (PDF) Metabolism of Deoxyribonucleotides.
- Nucleotide anion exchange purification followed by lyophilizing breaks them down?.
- Synthesis of Base-Modified 2′-Deoxyribonucleoside Triphosphates and Their Use in Enzymatic Synthesis of Modified DNA for Applications in Bioanalysis and Chemical Biology. The Journal of Organic Chemistry.
- Isocytosine. Wikipedia.
- Synthesis and 31P NMR spectra of the modified nucleoside triphosphates...
- Chemical stability of 2'-deoxy-5-methylisocytidine during oligodeoxynucleotide synthesis and deprotection. PubMed.
- The C5-modified triphosphates employed in this study. The triphosphates...
- Nucleoside Triphosphates — Building Blocks for the Modific
- Nucleotide. Wikipedia.
- Phosphoryl
- Convenient syntheses of isotopically labeled pyrimidine 2´-deoxynucleosides and their 5-hydroxy oxid
- Synthesis of O-Amino Sugars and Nucleosides. MDPI.
- Synthesis and polymerase incorporation of 5'-amino-2',5'-dideoxy-5'-N-triphosph
- NMR-Based Structure Characteriz
Sources
- 1. The Expanded Genetic Alphabet - PMC [pmc.ncbi.nlm.nih.gov]
- 2. The Expanding Genetic Alphabet Will Rewrite Life [inverse.com]
- 3. cdnsciencepub.com [cdnsciencepub.com]
- 4. Isocytosine - Wikipedia [en.wikipedia.org]
- 5. NMR-Based Structure Characterization [kofo.mpg.de]
- 6. mdpi.com [mdpi.com]
- 7. dupont.com [dupont.com]
- 8. CN1613864A - Method for purifying and preparing nucleoside triphosphate derivative - Google Patents [patents.google.com]
- 9. researchgate.net [researchgate.net]
- 10. researchgate.net [researchgate.net]
- 11. rsc.org [rsc.org]
- 12. pubs.acs.org [pubs.acs.org]
- 13. Synthesis and Enzymatic Incorporation of Modified Deoxyuridine Triphosphates - PMC [pmc.ncbi.nlm.nih.gov]
- 14. tandfonline.com [tandfonline.com]
- 15. apnews.com [apnews.com]
Troubleshooting & Optimization
Technical Support Center: Optimizing Coupling Efficiency of 2-Aminoisocytosine Phosphoramidite
Welcome to the technical support center for the successful incorporation of 2-Aminoisocytosine (isoC) phosphoramidite into synthetic oligonucleotides. This guide is designed for researchers, scientists, and drug development professionals who are working with expanded genetic alphabets and other modified nucleic acids. As Senior Application Scientists, we have compiled field-proven insights and best practices to help you navigate the unique challenges of this modified base.
Introduction to 2-Aminoisocytosine (isoC)
2-Aminoisocytosine (isoC) is a synthetic nucleobase analog that forms a specific, stable base pair with isoguanine (isoG). This alternative base pairing system, which utilizes a different hydrogen bonding pattern than the natural A-T and G-C pairs, is a cornerstone of the expanded genetic alphabet. Its successful incorporation is critical for applications in synthetic biology, diagnostics, and therapeutics. However, like many modified phosphoramidites, isoC presents unique challenges during solid-phase oligonucleotide synthesis that can impact coupling efficiency and the purity of the final product. This guide provides a structured approach to troubleshooting and optimizing your synthesis protocols.
Frequently Asked Questions (FAQs)
Q1: Why is the coupling efficiency of 2-Aminoisocytosine phosphoramidite often lower than that of standard A, C, G, and T phosphoramidites?
The reduced coupling efficiency can be attributed to several factors inherent to modified phosphoramidites. The exocyclic amine at the 2-position can alter the electronic properties and steric bulk of the phosphoramidite compared to its canonical counterparts. This can slow down the kinetics of the coupling reaction, making it less efficient under standard synthesis conditions.[][] Incomplete reactions lead to a higher percentage of truncated sequences (n-1), reducing the yield of the full-length product.[3]
Q2: What is the most critical parameter to adjust when incorporating isoC?
The single most important parameter to optimize is the coupling time . Standard phosphoramidites couple with high efficiency in about 30 seconds.[4] However, modified amidites, especially those with altered steric or electronic properties like isoC, often require significantly longer coupling times to drive the reaction to completion.[][4] Extending the coupling time is the first and most effective step towards improving the incorporation efficiency.
Q3: Can I use a standard activator like 1H-Tetrazole for isoC coupling?
While 1H-Tetrazole can be used, it may not be the most effective choice. Activators with slightly different acidic properties, such as 5-Ethylthio-1H-tetrazole (ETT) or 4,5-Dicyanoimidazole (DCI), are often recommended for modified or sterically hindered phosphoramidites.[5][6][7][8] DCI, for example, has been shown to significantly decrease the required coupling time for less reactive phosphoramidites compared to tetrazole.[8]
Q4: Are there special considerations for the deprotection of oligonucleotides containing isoC?
Yes. The protecting group on the N2-amino function of isoC must be efficiently removed without damaging the oligonucleotide. The choice of deprotection strategy depends on the specific protecting group used (e.g., a standard acyl group like isobutyryl or a more labile group like phenoxyacetyl 'Pac'). Always refer to the phosphoramidite supplier's specifications. Using milder deprotection conditions or alternative amine solutions (e.g., AMA - a mix of ammonium hydroxide and methylamine) may be necessary to ensure complete and safe deprotection.[9][10][11]
Q5: How do I verify the successful incorporation of isoC?
The definitive method for quality control is mass spectrometry (MS).[12][13][14] Either Electrospray Ionization (ESI) or MALDI-TOF MS can be used to measure the molecular weight of the final oligonucleotide. A successful synthesis will yield a product with a mass that matches the expected molecular weight for the sequence containing the isoC residue.[15]
Troubleshooting Guide
This section addresses specific issues you may encounter during the synthesis of isoC-containing oligonucleotides.
Problem 1: Low Coupling Efficiency
-
Symptom: Mass spectrometry analysis shows a high abundance of (n-1) and other truncated species. The trityl monitor shows a lower than expected yield after the isoC coupling step.
-
Causality Workflow:
-
Detailed Solutions:
-
Extend Coupling Time: This is the most critical first step. Standard 30-second coupling is insufficient. We recommend starting with a 10-minute coupling time . For sequences with multiple consecutive isoC insertions, extending this to 15 minutes may be beneficial.[][4]
-
Change Activator: If extending the coupling time is not sufficient, switch from 1H-Tetrazole to a more potent activator. 4,5-Dicyanoimidazole (DCI) at a concentration of 0.25 M is an excellent choice for driving the reaction forward.[8] 5-Ethylthio-1H-tetrazole (ETT) is another effective alternative.
-
Verify Reagent Quality: Modified phosphoramidites can be more sensitive to degradation than standard amidites. Ensure the isoC phosphoramidite is fresh and has been stored correctly under an inert atmosphere. Crucially, verify that all solvents, especially acetonitrile, are anhydrous (<30 ppm water).
-
Problem 2: Incomplete Deprotection or Base Modification
-
Symptom: Mass spectrometry shows peaks corresponding to the mass of the oligonucleotide plus the mass of the N2-protecting group. HPLC analysis may show broadening or shoulders on the main product peak.
-
Root Causes and Solutions:
-
Incorrect Deprotection Reagent: Standard deprotection with ammonium hydroxide at 55°C may be insufficient for complete removal of some protecting groups. For oligonucleotides containing modified bases, Ammonia-Methylamine (AMA) solution is often more effective.[9] A typical treatment is 1.5 hours at 65°C.
-
Protecting Group Mismatch: Ensure your deprotection strategy is compatible with the protecting group on the isoC phosphoramidite. If using a mild protecting group like phenoxyacetyl (Pac), a milder deprotection (e.g., ammonium hydroxide for 2 hours at room temperature) might be required to prevent degradation of other components, but this must be validated.[9] Always follow the supplier's specific recommendation.
-
Side Reactions: Similar to how 2-amino-dA can undergo strand scission with standard iodine oxidation, isoC may be sensitive to certain reagents.[16] If you observe significant degradation, consider using an alternative, milder oxidizing agent.
-
Optimized Protocols & Data
Recommended Synthesis Cycle for isoC Incorporation
This protocol assumes a standard automated DNA synthesizer.
| Step | Reagent/Parameter | Recommended Value | Rationale |
| Deblocking | 3% Trichloroacetic Acid (TCA) in DCM | Standard Time (60-180s) | Standard conditions are sufficient for DMT removal. |
| Coupling | isoC Phosphoramidite | 10-15 minutes | Critical Step: Ensures sufficient time for the less reactive modified base to couple completely, maximizing yield.[][4] |
| Activator | 0.25 M DCI | DCI is a more potent activator than tetrazole, improving reaction kinetics for modified amidites.[8] | |
| Capping | Acetic Anhydride / N-Methylimidazole | Standard Time | Standard capping is essential to block any unreacted 5'-OH groups and prevent the formation of (n-1) deletion mutants.[3] |
| Oxidation | 0.02 M Iodine in THF/Pyridine/H₂O | Standard Time | Standard oxidation is usually sufficient, but monitor for degradation. |
Experimental Workflow for Synthesis and QC
Deprotection Protocols
| Protocol | Reagent | Conditions | Use Case |
| Standard | Concentrated Ammonium Hydroxide | 17 hours at 55°C | For oligonucleotides with standard protecting groups (Bz, iBu) and no sensitive modifications. |
| AMA | 1:1 mixture of Ammonium Hydroxide & 40% aq. Methylamine | 1.5 hours at 65°C | Recommended for isoC. More effective at removing stubborn protecting groups and reduces deprotection time.[9] |
| UltraMILD | 0.05 M Potassium Carbonate in Methanol | 4 hours at Room Temp | Required for oligonucleotides containing other base-labile modifications (e.g., certain dyes). Requires use of UltraMILD compatible phosphoramidites (Pac-dA, Ac-dC, iPr-Pac-dG). |
References
- Zhu, W., Wang, H., Li, X., Tie, W., Huo, B., Zhu, A., & Li, L. (2022). Enzymatic Synthesis of DNA with an Expanded Genetic Alphabet Using Terminal Deoxynucleotidyl Transferase. ACS Synthetic Biology, 11(12), 4142-4155.
- Zhu, W., Zhang, Y., Wang, H., Li, X., & Li, L. (2023).
- Zhu, W., Zhang, Y., Wang, H., Li, X., & Li, L. (2023).
- Kim, Y., Leconte, A. M., & Romesberg, F. E. (2017). Expansion of the Genetic Alphabet: A Chemist's Approach to Synthetic Biology. Accounts of Chemical Research.
- LINK Technologies. (n.d.). Guidebook for the Synthesis of Oligonucleotides. Chemie Brunschwig.
- Integrated DNA Technologies. (n.d.). Mass Spectrometry Analysis of Oligonucleotide Syntheses. IDT Technical Report.
- Polushin, N. N., Morocho, A. M., Chen, B. C., & Cohen, J. S. (n.d.). On the rapid deprotection of synthetic oligonucleotides and analogs. PMC.
- Glen Research. (n.d.). Activators for Oligonucleotide Synthesis. Glen Research Product Page.
- Integrated DNA Technologies. (n.d.). Mass spectrometry analysis of oligonucleotide syntheses. IDT Technical Report.
- BOC Sciences. (n.d.). Coupling Pathways and Activation Mechanisms in Phosphoramidite Reactions. BOC Sciences.
- Gryaznov, S. M., & Letsinger, R. L. (n.d.). Advanced method for oligonucleotide deprotection. PMC.
- TCI Chemicals. (n.d.). Coupling Activators for Oligonucleotide Synthesis. TCI Chemicals Brochure.
- Integrated DNA Technologies. (2023). Understanding oligonucleotides mass spectrometry. IDT Technical Article.
- BenchChem. (n.d.). Application Notes and Protocols for Phosphoramidite-Based Oligonucleotide Synthesis. BenchChem.
- Glen Research. (n.d.). Glen Report 20.24: Deprotection - Volume 1 - Deprotect to Completion. Glen Research.
- LGC Biosearch Technologies. (2021). Oligonucleotide synthesis basics: Key takeaways for post-synthesis processing. Biosearch Technologies Blog.
- Google Patents. (n.d.). WO2006116476A1 - Activators for oligonucleotide and phosphoramidite synthesis.
- Glen Research. (n.d.). Oligonucleotide Deprotection Guide. Glen Research.
- Google Patents. (n.d.). EP1874792B1 - Activators for oligonucleotide and phosphoramidite synthesis.
- Eureka | Patsnap. (2006). Activators for oligonucleotide and phosphoramidite synthesis.
- LGC Biosearch Technologies. (n.d.). Standard Protocol for Solid-Phase Oligonucleotide Synthesis using Unmodified Phosphoramidites. Biosearch Technologies.
- Polo, L. M., & Limbach, P. A. (2000). Analysis of Oligonucleotides by Electrospray Ionization Mass Spectrometry. Current Protocols in Nucleic Acid Chemistry.
- Newomics. (n.d.). MnESI-MS Platform for Sensitive Analysis of Oligonucleotides.
- BOC Sciences. (n.d.). Comprehensive Guide to Oligonucleotide Synthesis Using the Phosphoramidite Method. BOC Sciences.
- Twist Bioscience. (n.d.). Phosphoramidite Chemistry for DNA Synthesis. Twist Bioscience.
- Current Protocols. (n.d.). Manual Oligonucleotide Synthesis Using the Phosphoramidite Method. Wiley Online Library.
- Glen Research. (n.d.). 2-Amino-dA-CE Phosphoramidite. Glen Research Product Page.
- BOC Sciences. (n.d.). Phosphoramidites. BOC Sciences.
- Thermo Fisher Scientific. (n.d.). Classification and characterization of impurities in phosphoramidites used in making therapeutic oligonucleotides. Thermo Fisher Scientific Technical Note.
- LGC Biosearch Technologies. (n.d.). 2'-Deoxypseudoisocytidine CE-Phosphoramidite. Biosearch Technologies.
- Glen Research. (n.d.). Glen Report 20.
- ResearchGate. (2025). ChemInform Abstract: Coupling Activators for the Oligonucleotide Synthesis via Phosphoramidite Approach.
- Glen Research. (n.d.). Glen Report 21.211 - TECHNICAL BRIEF – Synthesis of Long Oligonucleotides. Glen Research.
Sources
- 3. twistbioscience.com [twistbioscience.com]
- 4. Standard Protocol for Solid-Phase Oligonucleotide Synthesis using Unmodified Phosphoramidites | LGC, Biosearch Technologies [biosearchtech.com]
- 5. glenresearch.com [glenresearch.com]
- 6. tcichemicals.com [tcichemicals.com]
- 7. pdf.benchchem.com [pdf.benchchem.com]
- 8. glenresearch.com [glenresearch.com]
- 9. glenresearch.com [glenresearch.com]
- 10. blog.biosearchtech.com [blog.biosearchtech.com]
- 11. glenresearch.com [glenresearch.com]
- 12. web.colby.edu [web.colby.edu]
- 13. idtdevblob.blob.core.windows.net [idtdevblob.blob.core.windows.net]
- 14. idtdna.com [idtdna.com]
- 15. deepblue.lib.umich.edu [deepblue.lib.umich.edu]
- 16. glenresearch.com [glenresearch.com]
Technical Support Center: Troubleshooting Polymerase Fidelity with 2-Aminoisocytosine (isoC)
Welcome to the technical support center for researchers utilizing the unnatural base pair (UBP) system involving 2-Aminoisocytosine (isoC) and its pairing partner, isoguanine (isoG). As a Senior Application Scientist, my goal is to provide you with in-depth, field-proven insights to help you overcome challenges related to polymerase fidelity. This guide moves beyond simple protocols to explain the underlying biochemical principles, empowering you to troubleshoot effectively and ensure the integrity of your experimental results.
Section 1: Frequently Asked Questions - The Root Causes of Low Fidelity
This section addresses the fundamental mechanisms that can lead to errors when using the isoC:isoG unnatural base pair in polymerase-catalyzed reactions.
Q1: What is the primary reason 2-Aminoisocytosine (isoC) can lead to low polymerase fidelity?
The principal cause of fidelity issues with isoC and its partner isoG is tautomerization.[1] Like natural bases, these analogs can exist in different isomeric forms, known as tautomers. While the desired keto form of isoG pairs correctly with isoC, it can tautomerize to a thermodynamically preferred enol form.[1] This enol tautomer has a hydrogen bonding pattern that allows it to mispair with natural bases, most commonly thymine (T), leading to mutations in the amplified sequence.[1] Similarly, isoC can adopt a rare imino tautomer that can mispair with guanine (G). Understanding this inherent chemical property is the first step in troubleshooting.
Q2: What is polymerase fidelity and how does proofreading activity influence it with unnatural bases?
Polymerase fidelity refers to the enzyme's ability to accurately replicate a DNA template.[2] It's a multi-step process involving selecting the correct incoming deoxynucleoside triphosphate (dNTP), incorporating it, and in some cases, proofreading the result.[2]
Many high-fidelity DNA polymerases, such as those from the B-family (e.g., Pfu, Deep Vent), possess an intrinsic 3'→5' exonuclease activity.[3][4] This "proofreading" function allows the enzyme to recognize a misincorporated nucleotide, pause, excise the incorrect base, and re-attempt the insertion.[2][3] This activity is critical for high-fidelity PCR with natural bases and can also help correct some misincorporations involving UBPs.[5] However, the efficiency of this proofreading on unnatural pairs can vary, as the enzyme's recognition and excision machinery evolved for natural DNA.
In contrast, polymerases like Taq (a Family A polymerase) lack this proofreading domain, resulting in a significantly higher intrinsic error rate.[4]
Q3: Are all polymerases equally prone to errors with 2-Aminoisocytosine?
No, there is significant variability. The fidelity of a polymerase with a UBP is influenced by the geometry of its active site and its proofreading capability.[1] Some polymerases may be more accommodating of the UBP's shape, leading to efficient incorporation, while others may stall or be more prone to misincorporation. For instance, the Klenow fragment of E. coli DNA polymerase I has been shown to incorporate some unnatural nucleotides with relatively high efficiency but may struggle with others.[1] Engineered polymerases are often developed to better accommodate specific UBPs, but even these can exhibit context-dependent fidelity.[6][7] Therefore, polymerase selection is a critical first step in experimental design.
Section 2: Common Problems & First-Line Solutions
This section provides a quick-reference guide to the most common issues encountered in the lab, with actionable solutions.
Q: My sequencing results show a high frequency of T->C or G->A mutations. What is the likely cause?
A: This substitution pattern strongly suggests a fidelity issue related to the isoC:isoG pair. The most probable cause is the tautomerization of isoG in the template, leading to the misincorporation of dTTP opposite it. When this strand is replicated in the next cycle, an 'A' will be incorporated opposite the 'T', completing the G->A mutation.
-
Immediate Action:
-
Verify Your Polymerase: Confirm you are using a high-fidelity, proofreading polymerase (e.g., Pfu-based, Q5®, Phusion®).[8] Using a non-proofreading enzyme like Taq is a common source of high error rates.[9]
-
Check dNTP Concentrations: Ensure your natural dNTPs (dATP, dCTP, dGTP, dTTP) are balanced and at an optimal concentration.[8][10] Imbalanced dNTP pools can significantly decrease fidelity.[11][12][13]
-
Review Magnesium Concentration: Excess magnesium can reduce polymerase fidelity by stabilizing mismatched primer-template complexes.[14][15]
-
Q: My PCR amplification is inefficient or fails completely when using primers containing 2-AIC.
A: Low efficiency is often linked to the polymerase's difficulty in recognizing and extending from the unnatural base. This can be due to suboptimal reaction conditions or an inappropriate enzyme choice.
-
Immediate Action:
-
Optimize Annealing Temperature (Ta): The presence of a UBP can alter the melting temperature (Tm) of your primers. Perform a temperature gradient PCR to find the optimal Ta that balances specificity and efficiency.[10][16] Start 5°C below the calculated Tm and test in 1-2°C increments.[17]
-
Increase Extension Time: A polymerase may pause at the site of an unnatural base. Increasing the extension time can give the enzyme sufficient time to incorporate the correct nucleotide and continue synthesis.[8][18]
-
Consider a Different Polymerase: If optimization fails, your current polymerase may simply be incompatible with the UBP. Test a different class of high-fidelity polymerase.
-
Q: I see non-specific bands (smearing or multiple products) on my gel in addition to the expected product.
A: Non-specific amplification can arise from primers annealing to unintended sites, a problem often exacerbated by suboptimal reaction conditions.
-
Immediate Action:
-
Increase Annealing Temperature: This is the most effective way to increase the stringency of primer binding and eliminate non-specific products.[18]
-
Decrease Magnesium (Mg²⁺) Concentration: Lowering the Mg²⁺ concentration in 0.2–0.5 mM increments can increase specificity, as high levels can promote non-specific primer annealing.[8][16]
-
Use a Hot-Start Polymerase: Hot-start formulations prevent the polymerase from being active at lower temperatures where primers can bind non-specifically, significantly reducing primer-dimers and other artifacts.[9][19]
-
Section 3: Advanced Troubleshooting & Optimization Protocols
For persistent issues, a more systematic approach to optimizing your experiment is required.
Choosing the Right DNA Polymerase
The single most important factor for maintaining fidelity with UBPs is the choice of DNA polymerase. The presence of a 3'→5' exonuclease (proofreading) domain is paramount.
| Polymerase Type | Example(s) | Proofreading (3'→5' Exo) | Relative Fidelity | Suitability for 2-AIC Applications |
| Family A (Non-Proofreading) | Taq, KlenTaq | No | Low (Error Rate ~10⁻⁴ - 10⁻⁵)[4] | Not Recommended. The lack of proofreading makes it highly prone to errors with UBPs. |
| Family B (Proofreading) | Pfu, Deep Vent, Q5®, Phusion® | Yes | High to Ultra-High (Error Rate ~10⁻⁶ - 10⁻⁷)[3] | Highly Recommended. The proofreading activity is essential for excising misincorporated bases.[5] |
| Engineered/Modified | Varies | Usually Yes | Varies | Potentially Ideal. These are often evolved for better recognition of specific UBPs, but require empirical validation.[6] |
Protocol: Systematic Optimization of PCR Conditions for Fidelity
Use this workflow to systematically pinpoint and resolve sources of low fidelity.
-
Step 1: Magnesium Concentration Gradient
-
Rationale: Mg²⁺ is a critical cofactor for polymerase activity, but excess ions can decrease fidelity.[20]
-
Procedure: Set up a series of identical reactions where the final MgCl₂ or MgSO₄ concentration varies. A typical range to test is 1.5 mM to 4.0 mM in 0.5 mM increments.[16] Analyze the products for both yield and fidelity (via sequencing). Choose the lowest Mg²⁺ concentration that still provides robust amplification.
-
-
Step 2: dNTP Concentration Adjustment
-
Rationale: While sufficient dNTPs are needed for amplification, excessively high concentrations can inhibit proofreading activity and promote misincorporation.[13] Conversely, imbalanced pools dramatically increase errors.[11][12]
-
Procedure:
-
First, ensure your stock solutions of natural dNTPs and the unnatural triphosphates (iso-CTP and iso-GTP) are accurately quantified and equimolar in the final reaction.
-
Standard concentrations are typically 200-400 µM of each dNTP.[21] If fidelity is low, try reducing the concentration to the lower end of this range (e.g., 200 µM). High-fidelity polymerases often perform better with lower dNTP concentrations.[21]
-
-
-
Step 3: Cycling Parameter Optimization
-
Rationale: Using the minimum number of cycles necessary reduces the chances of propagating errors that occur early in the reaction.[8][10]
-
Procedure:
-
Annealing Temperature: As mentioned, run a gradient to find the highest temperature that allows for efficient amplification.
-
Cycle Number: Run a test reaction and pull out aliquots at different cycle numbers (e.g., 20, 25, 30, 35). Run them on a gel to determine the minimum number of cycles required to generate a sufficient amount of product. Avoid unnecessary cycles.[10]
-
-
Protocol: Assessing Polymerase Fidelity with Denaturing Gradient Gel Electrophoresis (DGGE)
DGGE is a powerful technique that can separate DNA fragments of the same length that differ by as little as a single base change, making it an excellent tool for visualizing the error rate of a polymerase.
-
Principle: A PCR product is run on a polyacrylamide gel containing a gradient of DNA denaturants (urea and formamide). As the DNA fragment moves through the gel, it reaches a denaturant concentration that causes it to partially melt. A mutation changes the melting characteristics, causing the mutant fragment to slow down at a different position in the gel compared to the wild-type fragment. The intensity of the mutant bands relative to the wild-type band provides a semi-quantitative measure of the error rate.[22]
-
Simplified Workflow:
-
PCR Amplification: Perform your PCR with the 2-AIC containing template/primers using the polymerase and conditions you wish to test. It is crucial to amplify from a pure, sequence-verified template.[20]
-
Gel Preparation: Cast a polyacrylamide gel with a linear gradient of denaturants (e.g., 20% to 60%).[23] This requires a gradient mixer. The 100% denaturant solution typically contains 7 M urea and 40% deionized formamide.[24]
-
Electrophoresis: Load approximately 600-800 ng of your PCR product.[24] Run the gel in 1x TAE buffer at a constant temperature (typically 60°C) and voltage for several hours (e.g., 100V for 16 hours).[23][24]
-
Staining and Visualization: After the run, stain the gel with a fluorescent dye (e.g., SYBR Gold or Ethidium Bromide) and visualize it under UV light.[23][24]
-
Analysis: A single, sharp band indicates high fidelity. A smear or multiple bands appearing above the main wild-type band represent PCR-induced mutations. The complexity and intensity of this pattern correlate with a lower fidelity polymerase.
-
Section 4: Visual Guides & Workflows
Mechanism of 2-Aminoisocytosine Mispairing
Caption: Tautomeric shift of 2-Aminoisocytosine (isoC) from its stable keto form to a rare imino form, which alters its hydrogen bonding capacity and leads to mispairing with guanine.
Troubleshooting Workflow for Low Fidelity PCR
Caption: A step-by-step decision tree for troubleshooting and resolving low fidelity issues in PCRs involving unnatural base pairs.
References
-
Georgiadis, M. M., Singh, I., & Kellett, W. F. (2015). Non-Natural Nucleotides as Probes for the Mechanism and Fidelity of DNA Polymerases. Molecules, 20(11), 20862–20883. [Link]
-
Kimoto, M., Kawai, R., Mitsui, T., & Hirao, I. (2004). An unnatural base pair system for efficient PCR amplification and functionalization of DNA molecules. Nucleic Acids Research, 32(9), e72. [Link]
-
Assay Genie. (n.d.). High-Fidelity DNA Polymerase. Retrieved from [Link]
-
Agilent Technologies. (n.d.). High-Fidelity PCR Enzymes: Properties and Error Rate Determinations. Retrieved from [Link]
-
Matsuda, S., Kimoto, M., & Hirao, I. (2010). Highly specific unnatural base pair systems as a third base pair for PCR amplification. Nucleic Acids Research, 38(10), 3493–3502. [Link]
-
Jackson, L. N., Chim, N., & Chaput, J. C. (2022). Mutant polymerases capable of 2′ fluoro-modified nucleic acid synthesis and amplification with improved accuracy. Chemical Science, 13(19), 5655–5662. [Link]
-
Ling, L. L., Keohavong, P., Dias, C., & Thilly, W. G. (1991). Optimization of the polymerase chain reaction with regard to fidelity: modified T7, Taq, and vent DNA polymerases. PCR methods and applications, 1(1), 63–69. [Link]
-
Wang, Y., Prosen, D. E., Mei, L., Sullivan, J. C., Finney, M., & Vander Horn, P. B. (2004). A novel strategy to engineer DNA polymerases for enhanced processivity and improved performance in vitro. Nucleic acids research, 32(3), 1197–1207. [Link] (Note: This is a representative article on polymerase properties, the provided URL is for a review on thermophilic polymerases).
-
Hite, J. M., Eckert, K. A., & Cheng, K. C. (1996). Factors affecting fidelity of DNA synthesis during PCR amplification of d(C-A)n.d(G-T)n microsatellite repeats. Nucleic acids research, 24(12), 2444–2451. [Link]
-
Arezi, B., Xing, W., DeGrace, J. A., & Hogrefe, H. H. (2014). The A, B, C, D's of replicative DNA polymerase fidelity. PloS one, 9(7), e103228. [Link]
-
Vossen, R. (2001). Denaturing Gradient Gel-Electrophoresis (DGGE). LabJ_Protocols©. [Link]
-
Brown, J. A., & Suo, Z. (2011). Covalent modification of primers improves PCR amplification specificity and yield. The Journal of biological chemistry, 286(34), 29737–29745. [Link]
-
Department of Environmental Sciences, University of Toledo. (n.d.). Denaturing Gradient Gel Electrophoresis (DGGE). Retrieved from [Link]
-
Martin, L. C. (2022). High-resolution mapping of DNA polymerase fidelity using nucleotide imbalances and next-generation sequencing. DSpace@MIT. [Link]
-
ResearchGate. (n.d.). PCR Troubleshooting Guide. Retrieved from [Link]
-
Bebenek, K., & Kunkel, T. A. (1992). The effects of dNTP pool imbalances on frameshift fidelity during DNA replication. The Journal of biological chemistry, 267(6), 3589–3596. [Link]
-
Ling, L. L., Keohavong, P., Dias, C., & Thilly, W. G. (1991). Optimization of the polymerase chain reaction with regard to fidelity: modified T7, Taq, and vent DNA polymerases. Genome research, 1(1), 63–69. [Link]
-
Martin, L. C., & Church, G. M. (2021). High-resolution mapping of DNA polymerase fidelity using nucleotide imbalances and next-generation sequencing. bioRxiv. [Link]
-
Pinheiro, V. B., Taylor, A. I., Cozens, C., Abramov, M., Renders, M., Zhang, S., ... & Holliger, P. (2012). Synthetic genetic polymers capable of heredity and evolution. Science, 336(6079), 341-344. [Link]
-
Czarnek, M., & Zmienko, A. (2016). Modified DNA polymerases for PCR troubleshooting. Acta biochimica Polonica, 63(4), 697–703. [Link]
-
Takara Bio. (n.d.). Troubleshooting your PCR. Retrieved from [Link]
-
Jackson, L. N., & Chaput, J. C. (2023). Measuring XNA polymerase fidelity in a hydrogel particle format. Methods in enzymology, 681, 211–227. [Link]
-
Laos, R., & Kool, E. T. (2007). Substituent effects on the pairing and polymerase recognition of simple unnatural base pairs. Nucleic acids research, 35(12), 4029–4037. [Link]
-
Leconte, A. M., Hwang, G. T., Matsuda, S., Capek, P., Hari, Y., & Romesberg, F. E. (2008). Discovery, characterization, and optimization of an unnatural base pair for expansion of the genetic alphabet. Journal of the American Chemical Society, 130(7), 2336–2343. [Link]
-
NimaGen. (2023). Optimizing dNTP Concentration in PCR Reactions for Efficient DNA Amplification. Retrieved from [Link]
-
Gardner, A. F., & Kelman, Z. (2022). A, B, C, D's of replicative DNA polymerase fidelity: utilizing high-throughput single-molecule sequencing to understand the molecular basis for DNA polymerase accuracy. Nucleic Acids Research, 50(19), 10765–10781. [Link]
-
Sheffield, V. C., Cox, D. R., Lerman, L. S., & Myers, R. M. (1989). Attachment of a 40-base-pair G + C-rich sequence (GC-clamp) to genomic DNA fragments by the polymerase chain reaction results in improved detection of single-base changes. Proceedings of the National Academy of Sciences, 86(1), 232-236. [Link]
-
Hirao, I., & Kimoto, M. (2012). Unnatural base pair systems toward the expansion of the genetic alphabet in the central dogma. Proceedings of the Japan Academy, Series B, 88(7), 345–367. [Link]
-
Hellinga, H. W., & Beese, L. S. (2009). Conformational dynamics during misincorporation and mismatch extension defined using a DNA polymerase with a fluorescent artificial amino acid. Biochemistry, 48(31), 7297–7309. [Link]
-
Kumar, D., Abdulovic, A. L., & Chabes, A. (2011). A Critical Balance: dNTPs and the Maintenance of Genome Stability. Genes, 2(1), 1–17. [Link]
-
Purohit, V., & Kuchta, R. D. (2007). Human DNA Polymerase α Uses a Combination of Positive and Negative Selectivity to Polymerize Purine dNTPs with High Fidelity. Biochemistry, 46(36), 10250–10261. [Link]
-
Hercuvan. (2018). Basic Principles of Denaturing Gradient Gel Electrophoresis. Retrieved from [Link]
-
Díez, B., Pedrós-Alió, C., Marsh, T. L., & Massana, R. (2001). Application of denaturing gradient gel electrophoresis (DGGE) to study the diversity of marine picoeukaryotic assemblages and comparison of DGGE with other molecular techniques. Applied and environmental microbiology, 67(7), 2942–2951. [Link]
-
Hirao, I., Kimoto, M., & Yamashige, R. (2012). Natural versus artificial creation of base pairs in DNA: origin of nucleobases from the perspectives of unnatural base pair studies. Accounts of chemical research, 45(12), 2055–2065. [Link]
-
Hirao, I., & Kimoto, M. (2012). Unnatural base pair systems toward the expansion of the genetic alphabet in the central dogma. Proceedings of the Japan Academy. Series B, Physical and biological sciences, 88(7), 345–367. [Link]
Sources
- 1. Non-Natural Nucleotides as Probes for the Mechanism and Fidelity of DNA Polymerases - PMC [pmc.ncbi.nlm.nih.gov]
- 2. assaygenie.com [assaygenie.com]
- 3. agilent.com [agilent.com]
- 4. mdpi.com [mdpi.com]
- 5. academic.oup.com [academic.oup.com]
- 6. Mutant polymerases capable of 2′ fluoro-modified nucleic acid synthesis and amplification with improved accuracy - PMC [pmc.ncbi.nlm.nih.gov]
- 7. [PDF] Structural insights into a DNA polymerase reading the xeno nucleic acid HNA | Semantic Scholar [semanticscholar.org]
- 8. neb.com [neb.com]
- 9. Modified DNA polymerases for PCR troubleshooting - PMC [pmc.ncbi.nlm.nih.gov]
- 10. PCR Basic Troubleshooting Guide [creative-biogene.com]
- 11. The A, B, C, D’s of replicative DNA polymerase fidelity: utilizing high-throughput single-molecule sequencing to understand the molecular basis for DNA polymerase accuracy - PMC [pmc.ncbi.nlm.nih.gov]
- 12. The effects of dNTP pool imbalances on frameshift fidelity during DNA replication - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. A Critical Balance: dNTPs and the Maintenance of Genome Stability - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Factors affecting fidelity of DNA synthesis during PCR amplification of d(C-A)n.d(G-T)n microsatellite repeats - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Some Optimizing Strategies for PCR Amplification Success [creative-biogene.com]
- 16. researchgate.net [researchgate.net]
- 17. PCR Troubleshooting Guide | Thermo Fisher Scientific - HK [thermofisher.com]
- 18. Troubleshooting your PCR [takarabio.com]
- 19. Platinum SuperFi II DNA Polymerase | Thermo Fisher Scientific - JP [thermofisher.com]
- 20. 34.237.233.138 [34.237.233.138]
- 21. Optimizing dNTP Concentration in PCR Reactions for Effi... [sbsgenetech.com]
- 22. Basic Principles of Denaturing Gradient Gel Electrophoresis - Hercuvan [hercuvan.com]
- 23. LabJ array_protocol: Denaturing Gradient Gel-Electrophoresis (DGGE) [dmd.nl]
- 24. Application of Denaturing Gradient Gel Electrophoresis (DGGE) To Study the Diversity of Marine Picoeukaryotic Assemblages and Comparison of DGGE with Other Molecular Techniques - PMC [pmc.ncbi.nlm.nih.gov]
Technical Support Center: Enhancing the Stability of 2-Aminoisocytosine (isoC)-Modified Oligonucleotides
Welcome to the technical support center for 2-Aminoisocytosine (isoC)-modified oligonucleotides. This resource is designed for researchers, scientists, and drug development professionals who are leveraging the unique properties of isoC in their work. Here, you will find in-depth troubleshooting guides and frequently asked questions (FAQs) to address specific challenges you may encounter during your experiments, with a focus on improving the stability and integrity of your isoC-modified oligonucleotides.
Introduction to 2-Aminoisocytosine in Oligonucleotides
2-Aminoisocytosine (isoC) is a synthetic nucleotide analog that forms a specific, high-affinity base pair with isoguanine (isoG). This orthogonal pairing system, with its three hydrogen bonds, offers enhanced thermal stability to nucleic acid duplexes compared to natural G-C pairs. This property, along with the potential for altered nuclease recognition, makes isoC-modified oligonucleotides valuable tools in various applications, including diagnostics, therapeutics, and synthetic biology. However, realizing the full potential of these modified oligonucleotides requires a thorough understanding of their chemical properties and potential instability issues. This guide provides practical, experience-driven advice to help you navigate the complexities of working with isoC-modified oligonucleotides.
Part 1: Frequently Asked Questions (FAQs)
This section addresses common questions and concerns regarding the stability of 2-Aminoisocytosine-modified oligonucleotides.
Q1: What are the primary stability concerns for isoC-modified oligonucleotides?
The primary stability concerns for isoC-modified oligonucleotides, like their natural counterparts, are degradation by nucleases and chemical decomposition.[1] However, the introduction of a non-natural base can introduce unique challenges:
-
Nuclease Susceptibility: While the altered structure of the isoC:isoG base pair might be expected to confer some nuclease resistance, experimental evidence is mixed. Some studies suggest that internal isoC:isoG pairs may offer weak protection against certain exonucleases, while others indicate they are still susceptible to digestion.[2] Therefore, relying solely on the presence of isoC for stability against nucleases is not recommended.
-
Chemical Stability During Synthesis and Deprotection: The exocyclic amine of isoC requires a protecting group during phosphoramidite synthesis. Incomplete removal of this protecting group can lead to a heterogeneous final product with altered hybridization properties and potential instability. Furthermore, the isoC base itself may be susceptible to side reactions under harsh deprotection conditions.[3]
-
Duplex Thermal Stability: The incorporation of isoC:isoG base pairs is known to increase the melting temperature (Tm) of DNA duplexes, which is a key advantage.[4] However, this enhanced stability is dependent on proper synthesis and purification to ensure the integrity of the base pairs.
Q2: How can I enhance the nuclease resistance of my isoC-modified oligonucleotides?
To improve the stability of your isoC-modified oligonucleotides against nuclease degradation, it is highly recommended to incorporate established stability-enhancing modifications. These can be used in conjunction with isoC to create robust oligonucleotides for in vitro and in vivo applications.
-
Phosphorothioate (PS) Bonds: Replacing the non-bridging oxygen with a sulfur atom in the phosphate backbone is a common and effective method to confer nuclease resistance.[] It is advisable to introduce at least three PS bonds at the 3' and 5' ends of the oligonucleotide to protect against exonucleases.
-
2'-Sugar Modifications: Modifications at the 2'-position of the ribose sugar, such as 2'-O-Methyl (2'-OMe) or 2'-Fluoro (2'-F), can significantly increase nuclease resistance and also enhance binding affinity to target RNA.
-
Locked Nucleic Acids (LNA): LNA monomers contain a methylene bridge that locks the ribose in a C3'-endo conformation, leading to enhanced thermal stability and exceptional nuclease resistance.
Q3: What are the best practices for storing isoC-modified oligonucleotides?
Proper storage is crucial to maintain the integrity of your isoC-modified oligonucleotides. Follow these guidelines for optimal stability:
-
Short-term Storage (days to weeks): Store resuspended oligonucleotides in a buffered solution (e.g., TE buffer, pH 7.5) at 4°C.
-
Long-term Storage (months to years): For long-term storage, it is best to store the oligonucleotide lyophilized (dry) at -20°C or -80°C. If in solution, store in aliquots in a buffered solution at -20°C or -80°C to avoid repeated freeze-thaw cycles, which can lead to degradation.[6]
-
Protect from Light: If your oligonucleotide is labeled with a fluorescent dye, protect it from light to prevent photobleaching.
Part 2: Troubleshooting Guides
This section provides a systematic approach to resolving common issues encountered during the synthesis, purification, and analysis of isoC-modified oligonucleotides.
Guide 1: Troubleshooting Oligonucleotide Synthesis and Deprotection
Successful synthesis and deprotection are the foundation for obtaining stable and functional isoC-modified oligonucleotides.
Problem 1: Low Coupling Efficiency of isoC Phosphoramidite
-
Symptom: Trityl cation monitoring shows a significant drop in signal after the isoC coupling step, leading to a low overall yield of the full-length product.
-
Potential Causes & Solutions:
-
Moisture Contamination: Phosphoramidites are extremely sensitive to moisture. Ensure all reagents, especially the acetonitrile (ACN) used for dissolution, are anhydrous. Use fresh, high-quality reagents and consider storing the isoC phosphoramidite over a desiccant.
-
Suboptimal Activator: The choice and concentration of the activator are critical. For sterically hindered or less reactive phosphoramidites, a stronger activator like 5-(Ethylthio)-1H-tetrazole (ETT) or a higher concentration may be required.[7]
-
Insufficient Coupling Time: Modified phosphoramidites may require longer coupling times than standard DNA or RNA monomers.[8] Try increasing the coupling time for the isoC phosphoramidite in your synthesis protocol.
-
Degraded Phosphoramidite: If the phosphoramidite is old or has been improperly stored, it may have degraded. It is advisable to use a fresh vial of the isoC phosphoramidite.
-
Problem 2: Incomplete Deprotection of the isoC Base
-
Symptom: Mass spectrometry analysis of the final product shows a peak corresponding to the mass of the oligonucleotide with the isoC protecting group still attached.
-
Potential Causes & Solutions:
-
Inadequate Deprotection Conditions: The protecting group on the exocyclic amine of isoC may require specific deprotection conditions. Standard ammonium hydroxide treatment may not be sufficient.
-
Recommended Deprotection Protocol: While specific protecting groups for commercial isoC phosphoramidites may vary, a common strategy for bases with sensitive protecting groups is to use a milder deprotection cocktail or adjust the deprotection time and temperature. For example, "UltraMILD" monomers often utilize phenoxyacetyl (Pac) or acetyl (Ac) protecting groups that can be removed with potassium carbonate in methanol at room temperature.[9] If using a standard protecting group, ensure the deprotection is carried out for the recommended duration and at the specified temperature. For particularly stubborn protecting groups, a mixture of aqueous ammonium hydroxide and methylamine (AMA) can be more effective.[10]
-
Experimental Workflow: Optimizing Deprotection of isoC-Oligonucleotides
Caption: Workflow for optimizing the deprotection of isoC-modified oligonucleotides.
Guide 2: Troubleshooting Oligonucleotide Purification
Purification is essential to remove failure sequences and byproducts that can interfere with downstream applications and affect the stability of your isoC-modified oligonucleotide.
Problem: Co-elution of Full-Length Product and Impurities during RP-HPLC
-
Symptom: The main peak in the reverse-phase high-performance liquid chromatography (RP-HPLC) chromatogram is broad or has shoulders, indicating the presence of co-eluting species.
-
Potential Causes & Solutions:
-
Hydrophobicity of isoC: The isoC base may alter the overall hydrophobicity of the oligonucleotide, causing it to elute closely to certain failure sequences.
-
Incomplete Deprotection: As mentioned previously, incompletely deprotected species will have different retention times and may co-elute with the desired product.
-
Optimizing HPLC Conditions:
-
Gradient: A shallower acetonitrile gradient can improve the resolution between the full-length product and closely eluting impurities.[11]
-
Ion-Pairing Reagent: The choice and concentration of the ion-pairing reagent (e.g., triethylammonium acetate - TEAA) can significantly impact separation. Experiment with different ion-pairing reagents or concentrations to optimize resolution.
-
Column Chemistry: If using a standard C18 column, consider trying a different stationary phase, such as a C8 or a phenyl column, which may offer different selectivity.
-
Temperature: Adjusting the column temperature can also alter the retention behavior and improve separation.
-
-
Data Presentation: Example HPLC Gradients for isoC-Oligonucleotide Purification
| Gradient | Time (min) | % Buffer B (Acetonitrile) | Flow Rate (mL/min) |
| Standard | 0-20 | 5-50 | 1.0 |
| Shallow | 0-30 | 10-40 | 1.0 |
| Step | 0-5 | 5 | 1.0 |
| 5-25 | 5-35 | 1.0 | |
| 25-30 | 35-60 | 1.0 |
Guide 3: Troubleshooting Oligonucleotide Analysis
Accurate analysis is key to confirming the identity and purity of your isoC-modified oligonucleotide, which directly relates to its stability and functionality.
Problem: Ambiguous Mass Spectrometry Results
-
Symptom: The mass spectrum shows multiple peaks, making it difficult to confirm the molecular weight of the full-length product.
-
Potential Causes & Solutions:
-
Adduct Formation: Oligonucleotides can form adducts with cations like sodium (Na+) and potassium (K+), resulting in peaks at M+22 and M+38, respectively. The use of high-purity reagents and desalting the sample before analysis can minimize adduct formation.
-
Incomplete Deprotection: As discussed, peaks corresponding to the mass of the oligonucleotide with protecting groups still attached may be present.
-
Fragmentation: In-source fragmentation can occur, leading to the appearance of smaller mass peaks. Optimizing the mass spectrometer's source conditions can help minimize this.[12]
-
Multiple Charge States: Electrospray ionization (ESI) mass spectrometry typically produces a series of peaks corresponding to different charge states of the oligonucleotide.[13][14] Deconvolution software can be used to determine the neutral mass from this charge state envelope.
-
Diagram: Interpreting Mass Spectrometry Data for isoC-Oligonucleotides
Caption: A logical workflow for interpreting mass spectrometry data of isoC-modified oligonucleotides.
Part 3: Experimental Protocols
This section provides detailed, step-by-step methodologies for key experiments related to assessing the stability of isoC-modified oligonucleotides.
Protocol 1: Nuclease Stability Assay
Objective: To evaluate the resistance of isoC-modified oligonucleotides to degradation by nucleases.
Materials:
-
isoC-modified oligonucleotide and an unmodified control oligonucleotide of the same sequence.
-
Nuclease (e.g., Exonuclease I for 3' degradation, or a serum-containing medium for a more biologically relevant assessment).
-
Reaction buffer appropriate for the chosen nuclease.
-
Quenching solution (e.g., EDTA to chelate divalent cations and inactivate the nuclease).
-
Gel loading buffer.
-
Polyacrylamide gel (e.g., 20% TBE-Urea gel for high resolution).
-
Staining agent (e.g., SYBR Gold).
-
Gel imaging system.
Methodology:
-
Prepare Oligonucleotide Solutions: Resuspend the isoC-modified and control oligonucleotides to a stock concentration of 100 µM in nuclease-free water or TE buffer.
-
Set up Nuclease Digestion Reactions: In separate microcentrifuge tubes, prepare the following reactions on ice:
-
Test Reaction: 2 µL of 100 µM isoC-oligonucleotide, 2 µL of 10x nuclease buffer, 1 µL of nuclease, and 15 µL of nuclease-free water (total volume 20 µL).
-
Control Reaction: 2 µL of 100 µM control oligonucleotide, 2 µL of 10x nuclease buffer, 1 µL of nuclease, and 15 µL of nuclease-free water (total volume 20 µL).
-
No Nuclease Controls: Prepare identical reactions for both oligonucleotides but replace the nuclease with nuclease-free water.
-
-
Incubation: Incubate all tubes at the optimal temperature for the nuclease (e.g., 37°C) for a defined time course (e.g., 0, 1, 4, and 24 hours).
-
Quench Reactions: At each time point, take an aliquot from each reaction and add it to a tube containing the quenching solution.
-
Gel Electrophoresis: Mix the quenched aliquots with gel loading buffer and load onto a polyacrylamide gel. Run the gel according to the manufacturer's instructions.
-
Staining and Imaging: Stain the gel with a suitable nucleic acid stain and visualize the bands using a gel imaging system.
-
Analysis: Compare the intensity of the full-length oligonucleotide bands at different time points for the isoC-modified and control oligonucleotides. A slower decrease in band intensity for the isoC-oligonucleotide indicates increased nuclease stability.
Protocol 2: Thermal Denaturation (Melting Temperature) Analysis
Objective: To determine the melting temperature (Tm) of a duplex containing an isoC-modified oligonucleotide.
Materials:
-
isoC-modified oligonucleotide.
-
Complementary oligonucleotide (containing isoG).
-
Unmodified control duplex of a similar sequence.
-
Annealing buffer (e.g., 10 mM sodium phosphate, 100 mM NaCl, pH 7.0).
-
UV-Vis spectrophotometer with a temperature controller.
Methodology:
-
Prepare Duplex Solutions: Resuspend the isoC-modified oligonucleotide and its complementary strand to a concentration of 100 µM. Mix equimolar amounts of each strand in the annealing buffer to a final concentration of 1-5 µM. Prepare the control duplex in the same manner.
-
Annealing: Heat the duplex solutions to 95°C for 5 minutes and then allow them to cool slowly to room temperature to ensure proper hybridization.
-
Spectrophotometer Setup: Set the UV-Vis spectrophotometer to monitor absorbance at 260 nm. Program the temperature to ramp from a starting temperature (e.g., 20°C) to a final temperature (e.g., 95°C) at a rate of 1°C/minute, taking absorbance readings at regular intervals (e.g., every 0.5°C).
-
Data Acquisition: Place the cuvettes containing the duplex solutions into the spectrophotometer and start the temperature ramp.
-
Data Analysis: Plot the absorbance at 260 nm versus temperature. The melting temperature (Tm) is the temperature at which 50% of the duplex has denatured, which corresponds to the midpoint of the transition in the melting curve. This can be determined by finding the maximum of the first derivative of the melting curve.
-
Comparison: Compare the Tm of the isoC:isoG containing duplex to the control duplex. A higher Tm for the isoC-modified duplex indicates enhanced thermal stability.[15][16]
References
-
Biolytic Lab Performance, Inc. (n.d.). Introduction to Oligo Oligonucleotide DNA Synthesis. Retrieved from [Link]
-
Mass Spectrometry Research Facility. (n.d.). RP-HPLC Purification of Oligonucleotides. Retrieved from [Link]
-
ResearchGate. (2016). Increasing the Thermal Stability of Self-Assembling DNA Nanostructures by Incorporation of isoG/isoC Base Pairs. Retrieved from [Link]
- Li, B. F., Reese, C. B., & Swann, P. F. (1987). Solid-phase synthesis and side reactions of oligonucleotides containing O-alkylthymine residues. Biochemistry, 26(4), 1086–1093.
-
Glen Research. (n.d.). Deprotection Guide. Retrieved from [Link]
- Hosseini, M., et al. (2018). Enhanced Stability of DNA Oligonucleotides with Partially Zwitterionic Backbone Structures in Biological Media. Molecules, 23(11), 2981.
- Prakash, T. P., et al. (2005). 2'-O-[2-(amino)-2-oxoethyl] oligonucleotides. Organic letters, 7(12), 2341-4.
-
ResearchGate. (n.d.). Table 2 . Impact of phosphoramidite equivalents on coupling efficiency. Retrieved from [Link]
-
ePrints Soton. (2023). Review of fragmentation of synthetic single-stranded oligonucleotides by tandem mass spectrometry from 2014 to 2022. Retrieved from [Link]
-
ScienceDirect. (2023). Insights into the enzymatic degradation of DNA expedited by typical perfluoroalkyl acids. Retrieved from [Link]
-
ResearchGate. (2005). 2'- O -[2-(Amino)-2-oxoethyl] Oligonucleotides. Retrieved from [Link]
-
Bedzyk Group. (2019). Enzymatic Degradation of DNA Probed by In Situ X-ray Scattering. Retrieved from [Link]
-
Bio-Synthesis Inc. (2017). What are Backbone Modifications in Oligonucleotide Synthesis. Retrieved from [Link]
- Ni, J., et al. (1996). Interpretation of oligonucleotide mass spectra for determination of sequence using electrospray ionization and tandem mass spectrometry. Analytical chemistry, 68(13), 1989-99.
-
Agilent. (2021). Purification of Single-Stranded RNA Oligonucleotides Using High-Performance Liquid Chromatography. Retrieved from [Link]
- Ohgi, T., et al. (2005). Chemical synthesis of a very long oligoribonucleotide with 2-cyanoethoxymethyl (CEM)
- Fotin, A. V., et al. (1998). Parallel thermodynamic analysis of duplexes on oligodeoxyribonucleotide microchips. Nucleic acids research, 26(6), 1515-21.
-
Organic & Biomolecular Chemistry. (2023). Oligonucleotide synthesis under mild deprotection conditions. Retrieved from [Link]
- Google Patents. (2017). WO2017194498A1 - Enhanced coupling of stereodefined oxazaphospholidine phosphoramidite monomers to nucleoside or oligonucleotide.
- Gryaznov, S. M., et al. (1998). Advanced method for oligonucleotide deprotection. Nucleic acids research, 26(18), 4160-5.
-
Bio-Synthesis Inc. (2011). What affects the yield of your oligonucleotides synthesis. Retrieved from [Link]
-
ResearchGate. (2016). Nucleophilic Groups Protection of Phosphoramidite for DNA Synthesis. Retrieved from [Link]
- Gryson, C., et al. (2010). Effect of food processing on plant DNA degradation and PCR-based GMO analysis: a review. Analytical and bioanalytical chemistry, 396(6), 2003-22.
-
Element. (n.d.). Solutions for Oligonucleotide Analysis and Purification. Part 2: Reversed Phase Chromatography. Retrieved from [Link]
- Komatsu, Y., et al. (2012). [Development of highly nuclease-resistant chemically-modified oligonucleotides]. Yakugaku zasshi : Journal of the Pharmaceutical Society of Japan, 132(11), 1255-64.
-
Novatia. (n.d.). Oligonucleotide MS Fragmentation. Retrieved from [Link]
- Krylova, S. M., et al. (2013). Effect of Internal and Bulge Loops on the Thermal Stability of Small DNA Duplexes. The journal of physical chemistry. B, 117(4), 939-46.
-
ResearchGate. (2013). Short Antisense Oligonucleotides with Novel 2 '-4 ' Conformationaly Restricted Nucleoside Analogues Show Improved Potency without Increased Toxicity in Animals. Retrieved from [Link]
-
ResearchGate. (2001). Thermal stability of PNA/DNA and DNA/DNA duplexes by differential scanning calorimetry. Retrieved from [Link]
-
MDPI. (2022). Influence of Combinations of Lipophilic and Phosphate Backbone Modifications on Cellular Uptake of Modified Oligonucleotides. Retrieved from [Link]
-
PubMed. (2020). Enzymatic degradation of liquid droplets of DNA is modulated near the phase boundary. Retrieved from [Link]
-
ResearchGate. (2014). ChemInform Abstract: Coupling Activators for the Oligonucleotide Synthesis via Phosphoramidite Approach. Retrieved from [Link]
- Hacia, J. G., et al. (1994). Investigation of some properties of oligodeoxynucleotides containing 4'-thio-2'-deoxynucleotides: duplex hybridization and nuclease sensitivity. Nucleic acids research, 22(22), 4547-53.
-
Portsmouth Research Portal. (2021). Thermodynamic basis of the α-helix and DNA duplex. Retrieved from [Link]
-
Bio-Rad. (2023). Purification of DNA Oligonucleotides using Anion Exchange Chromatography. Retrieved from [Link]
-
International Journal of Molecular Sciences. (2021). A Rapid, Reliable and Reproducible Protocol for DNA Degradation in Genetic Applications. Retrieved from [Link]
- El-Sagheer, A. H., & Brown, T. (2019). Artificial nucleic acid backbones and their applications in therapeutics, synthetic biology and biotechnology. Biochemical Society transactions, 47(6), 1671-1683.
Sources
- 1. Enhanced Stability of DNA Oligonucleotides with Partially Zwitterionic Backbone Structures in Biological Media - PMC [pmc.ncbi.nlm.nih.gov]
- 2. glenresearch.com [glenresearch.com]
- 3. Solid-phase synthesis and side reactions of oligonucleotides containing O-alkylthymine residues - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. researchgate.net [researchgate.net]
- 6. pdf.benchchem.com [pdf.benchchem.com]
- 7. researchgate.net [researchgate.net]
- 8. pdf.benchchem.com [pdf.benchchem.com]
- 9. blog.biosearchtech.com [blog.biosearchtech.com]
- 10. glenresearch.com [glenresearch.com]
- 11. agilent.com [agilent.com]
- 12. enovatia.com [enovatia.com]
- 13. deepblue.lib.umich.edu [deepblue.lib.umich.edu]
- 14. sg.idtdna.com [sg.idtdna.com]
- 15. Effect of Internal and Bulge Loops on the Thermal Stability of Small DNA Duplexes - PMC [pmc.ncbi.nlm.nih.gov]
- 16. researchgate.net [researchgate.net]
Technical Support Center: Synthesis of 2-Aminoisocytosine Derivatives
Welcome to the technical support center for the synthesis of 2-aminoisocytosine and its derivatives. This guide is designed for researchers, scientists, and drug development professionals who are actively working with these important heterocyclic compounds. Here, we will address common challenges and side reactions encountered during synthesis, providing in-depth, field-proven insights in a troubleshooting-focused question-and-answer format. Our goal is to explain the causality behind experimental outcomes and provide robust, self-validating protocols to enhance the success of your research.
Part 1: Troubleshooting Guide - Common Experimental Issues
This section is dedicated to addressing specific problems you might encounter in the lab. Each question is followed by a detailed explanation of potential causes and a step-by-step guide to resolving the issue.
Q1: My reaction yield is significantly lower than expected. What are the likely causes and how can I improve it?
A1: Low yields in the synthesis of 2-aminoisocytosine derivatives, typically formed via the condensation of a guanidine source with a β-dicarbonyl compound, can stem from several factors.[1][2] The primary culprits are often incomplete conversion, product degradation during workup, or the formation of difficult-to-isolate side products.
Diagnostic Workflow:
-
Assess Reaction Completion:
-
Protocol: Carefully monitor the reaction progress using Thin Layer Chromatography (TLC) or Liquid Chromatography-Mass Spectrometry (LC-MS). Take aliquots at regular intervals (e.g., every hour) and analyze them against your starting materials.
-
Interpretation: If starting materials are still present after the expected reaction time, the reaction is likely incomplete.
-
-
Investigate Potential Degradation:
-
Protocol: After confirming reaction completion, take a small sample of the crude reaction mixture and analyze it via LC-MS or ¹H NMR. Compare this to a sample taken after your aqueous workup and another after purification.
-
Interpretation: A significant decrease in the desired product peak, or the appearance of new, smaller mass peaks after workup, suggests hydrolysis or degradation. 2-aminoisocytosine derivatives can be sensitive to harsh acidic or basic conditions.[3]
-
Solutions & Optimization:
-
For Incomplete Reactions:
-
Temperature: Gradually increase the reaction temperature in 10 °C increments. Some condensations require reflux conditions to proceed efficiently.
-
Base Strength: The choice of base is critical. If using a weaker base like sodium carbonate, consider switching to a stronger, non-nucleophilic base like sodium ethoxide or potassium tert-butoxide to ensure complete deprotonation of the β-dicarbonyl compound.[4][5]
-
Reaction Time: Extend the reaction time. Some sterically hindered substrates may require longer periods to react completely.
-
-
To Prevent Degradation:
-
Workup pH: During aqueous workup, maintain the pH as close to neutral as possible. Use mild acids (e.g., dilute citric acid) or bases (e.g., saturated sodium bicarbonate) for neutralization.
-
Purification: If the compound is sensitive, consider chromatography on neutral alumina or a minimally acidic silica gel. Avoid prolonged exposure to acidic or basic mobile phases during column chromatography.
-
Q2: My characterization data (NMR, MS) suggests the presence of an isomer. How can I identify and prevent its formation?
A2: The formation of a regioisomer is a classic side reaction in this synthesis, particularly when using an unsymmetrical β-ketoester or β-diketone. The guanidine molecule has two nucleophilic nitrogen atoms that can attack either of the two carbonyl carbons of the dicarbonyl compound. This can lead to two different cyclization products.
Mechanism of Isomer Formation:
The reaction proceeds through the initial attack of a guanidine nitrogen onto one of the carbonyls of the β-dicarbonyl compound. Subsequent cyclization involves the attack of the second guanidine nitrogen onto the remaining carbonyl. The regioselectivity is determined by which carbonyl is attacked first and which cyclizes.
Solutions & Control Strategies:
-
Steric Hindrance: The initial nucleophilic attack is often directed to the less sterically hindered carbonyl group. If your β-dicarbonyl compound has one side that is significantly bulkier, this can be used to favor the formation of one isomer.
-
Electronic Effects: Electron-withdrawing groups can make a carbonyl carbon more electrophilic and thus more susceptible to initial attack.
-
Reaction Conditions:
-
Base: The choice of base can influence which proton is removed from the β-dicarbonyl compound, thereby affecting the subsequent cyclization pathway. Experiment with different bases (e.g., NaOEt vs. KHMDS) to see if the isomeric ratio changes.
-
Temperature: Lowering the reaction temperature can sometimes increase the selectivity of the reaction by favoring the kinetically controlled product.
-
Q3: I'm observing high molecular weight species in my LC-MS. What are they and how do I get rid of them?
A3: The presence of high molecular weight impurities often points to dimerization or oligomerization of your starting materials or product.[6][7] This can occur through self-condensation reactions, especially at high concentrations or temperatures.
Potential Causes:
-
High Concentration: At high concentrations, the probability of intermolecular reactions increases, leading to the formation of dimers and larger oligomers.
-
Reactive Intermediates: Highly reactive intermediates in the reaction mixture may react with the final product or other intermediates.
Preventative Measures:
-
Dilution: Run the reaction at a lower concentration. This can be achieved by increasing the volume of the solvent.
-
Slow Addition: Instead of adding all reagents at once, try a slow, dropwise addition of one of the starting materials to the reaction mixture. This keeps the concentration of the reactive species low at any given time.
-
Temperature Control: Avoid unnecessarily high reaction temperatures, which can promote side reactions. Run the reaction at the lowest temperature that still allows for a reasonable reaction rate.
Q4: I need to perform a subsequent reaction on my 2-aminoisocytosine derivative, but I'm getting unwanted reactions on the ring nitrogens or the exocyclic amino group. How can I achieve selective modification?
A4: The 2-aminoisocytosine core contains multiple nucleophilic sites: the exocyclic 2-amino group and the ring nitrogens. To achieve selectivity in subsequent reactions like alkylation or acylation, a protecting group strategy is often necessary.[8][9][10]
Common Protecting Group Strategies:
| Group to Protect | Common Protecting Groups | Protection Conditions | Deprotection Conditions |
| Exocyclic Amino Group | Boc (tert-butoxycarbonyl) | Boc₂O, DMAP, THF | TFA, DCM or HCl in Dioxane |
| Cbz (carboxybenzyl) | Cbz-Cl, Base | H₂, Pd/C | |
| Ring Nitrogens | Acyl groups (e.g., Acetyl) | Acetic anhydride, Pyridine | Mild base (e.g., K₂CO₃, MeOH) |
| Benzyl (Bn) | Benzyl bromide, Base | H₂, Pd/C |
Experimental Protocol Example (Boc Protection of the Exocyclic Amino Group):
-
Dissolve your 2-aminoisocytosine derivative (1 eq.) in anhydrous tetrahydrofuran (THF).
-
Add di-tert-butyl dicarbonate (Boc₂O, 1.1 eq.) and a catalytic amount of 4-(dimethylamino)pyridine (DMAP, 0.1 eq.).
-
Stir the reaction at room temperature and monitor by TLC until the starting material is consumed.
-
Concentrate the reaction mixture under reduced pressure.
-
Purify the residue by column chromatography to obtain the N-Boc protected product.
This protected intermediate can then be used in your desired reaction, and the Boc group can be easily removed afterward under acidic conditions.[8]
Part 2: Frequently Asked Questions (FAQs)
-
What are the most critical reaction parameters to control to minimize side reactions? The most critical parameters are typically the choice of base, reaction temperature, and concentration. The base determines the nucleophilicity of your starting materials, the temperature affects the reaction rate and the prevalence of side reactions, and the concentration can influence the extent of intermolecular side reactions like dimerization.
-
How does the choice of solvent affect the synthesis? The solvent can influence the solubility of your reagents and the stability of intermediates. Protic solvents (like ethanol) can participate in hydrogen bonding and may be part of the reaction mechanism, while aprotic solvents (like THF or DMF) are generally more inert. The choice of solvent should be made based on the specific reaction conditions and the solubility of the starting materials.
-
What are the best practices for purification? Column chromatography on silica gel is the most common method. However, due to the polar nature and potential for hydrogen bonding of 2-aminoisocytosine derivatives, it is often beneficial to use a polar mobile phase (e.g., dichloromethane/methanol or chloroform/methanol). If your compound is acid or base-sensitive, consider using neutral alumina or treating your silica gel with a base like triethylamine before use. Recrystallization can also be an effective purification method for crystalline products.
Part 3: Visualizing Reaction Pathways
The following diagram illustrates the primary synthetic pathway for a 2-aminoisocytosine derivative from guanidine and a β-ketoester, highlighting the key branching point that can lead to a regioisomeric side product.
Caption: Reaction pathway showing the formation of the desired product and a regioisomeric side product.
References
-
Oxford Academic. (2023). Dynamic accumulation of cyclobutane pyrimidine dimers and its response to changes in DNA conformation. Nucleic Acids Research. [Link]
-
Wikipedia. Pyrimidine dimer. [Link]
-
Taylor & Francis Online. (2023). Pyrimidine dimers – Knowledge and References. [Link]
-
Microbe Notes. (2023). DNA Damage and DNA Repair: Types and Mechanism. [Link]
-
ResearchGate. Schematic representation of pyrimidine dimers formation after DNA.... [Link]
-
ACS Publications. (2019). Amino Acid-Protecting Groups. Chemical Reviews. [Link]
-
AAPPTec. Amino Acid Derivatives for Peptide Synthesis. [Link]
-
PubMed. (2020). Protecting Groups in Peptide Synthesis. [Link]
-
SciSpace. Amino Acid-Protecting Groups. [Link]
-
ResearchGate. Synthesis of 2-aminopyrimidine using β-dicarbonyl compounds and guanidine. [Link]
-
MDPI. (2023). Catalyzed Methods to Synthesize Pyrimidine and Related Heterocyclic Compounds. [Link]
-
Mansoura University. SYNTHESIS OF PYRIMIDINE DERIVATIVES. [Link]
-
Organic Chemistry Portal. Pyrimidine synthesis. [Link]
-
PubMed. (1967). Enzymic hydrolysis of amino acid derivatives of benzocaine. [Link]
-
ResearchGate. (2019). Side Reactions on Amino Groups in Peptide Synthesis. [Link]
-
MDPI. (2022). Efficient Synthesis of 2-Aminoquinazoline Derivatives via Acid-Mediated [4+2] Annulation of N-Benzyl Cyanamides. [Link]
-
ResearchGate. (2021). Recent synthetic methodologies for pyrimidine and its derivatives. [Link]
-
KPU Pressbooks. Enolates of β-Dicarbonyl Compounds. [Link]
-
Fiveable. β-dicarbonyl compounds Definition. [Link]
-
Wikipedia. Dicarbonyl. [Link]
-
KPU Pressbooks. (2023). 8.3 β-dicarbonyl Compounds in Organic Synthesis. [Link]
-
YouTube. (2024). Hydrolysis of Nitriles Explained! (Basic and Acidic Conditions). [Link]
-
YouTube. (2018). Reactions of Beta-Dicarbonyl Compounds. [Link]
-
National Institutes of Health. (2014). Amino acid motifs in natural products: synthesis of O-acylated derivatives of (2S,3S)-3-hydroxyleucine. [Link]
-
MDPI. (2019). Synthesis of New Cytotoxic Aminoanthraquinone Derivatives via Nucleophilic Substitution Reactions. [Link]
Sources
- 1. bu.edu.eg [bu.edu.eg]
- 2. researchgate.net [researchgate.net]
- 3. Enzymic hydrolysis of amino acid derivatives of benzocaine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. uobabylon.edu.iq [uobabylon.edu.iq]
- 5. 8.3 β-dicarbonyl Compounds in Organic Synthesis – Organic Chemistry II [kpu.pressbooks.pub]
- 6. academic.oup.com [academic.oup.com]
- 7. Pyrimidine dimer - Wikipedia [en.wikipedia.org]
- 8. Protecting Groups in Peptide Synthesis: A Detailed Guide - Creative Peptides [creative-peptides.com]
- 9. Protecting Groups in Peptide Synthesis - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. scispace.com [scispace.com]
Technical Support Center: Overcoming Challenges in Sequencing 2-Aminoisocytosine-Modified Templates
Welcome to the technical support center for researchers, scientists, and drug development professionals working with 2-Aminoisocytosine (2-AIC)-modified DNA templates. This guide is designed to provide in-depth troubleshooting and practical advice to navigate the unique challenges presented by this non-canonical base during sequencing workflows.
Introduction to 2-Aminoisocytosine
2-Aminoisocytosine is a synthetic analog of cytosine that introduces a third hydrogen bond when paired with guanine, theoretically increasing the thermal stability of the DNA duplex.[1][2] This property makes it a valuable tool in various molecular biology applications, including therapeutics and diagnostics. However, its presence can pose significant challenges to standard DNA sequencing protocols, primarily due to polymerase interactions and potential misincorporation events. This guide will address these challenges head-on, providing you with the expertise to optimize your experiments for success.
Core Challenges in Sequencing 2-AIC Templates
The primary hurdles in sequencing 2-AIC-modified templates stem from the enzymatic processes central to most sequencing workflows: PCR amplification and the sequencing reaction itself.
-
Polymerase Fidelity and Processivity: DNA polymerases, particularly high-fidelity proofreading enzymes, can struggle to efficiently and accurately read through templates containing modified bases.[3][4] The 3'->5' exonuclease activity of these enzymes may recognize the 2-AIC as a mismatch, leading to stalling or excision of the growing strand.[3][4]
-
Misincorporation and Sequence Bias: The altered hydrogen bonding of the 2-AIC-G pair can, under suboptimal conditions, lead to misincorporation of other bases by the polymerase. This can result in sequence artifacts and an inaccurate representation of the original template.
-
Inefficient Amplification: The increased stability of 2-AIC-containing regions can lead to higher melting temperatures, potentially impeding complete denaturation during PCR and resulting in poor amplification yields.
Troubleshooting Guide: From PCR to Sequencing Data
This section provides a structured approach to troubleshooting common issues encountered when sequencing 2-AIC-modified templates.
| Observed Problem | Potential Cause | Recommended Solution |
| No or Low PCR Product | Inappropriate Polymerase: High-fidelity polymerases with strong proofreading activity may stall or degrade the template. | Switch to a polymerase with reduced or no 3'->5' exonuclease activity. Consider Taq polymerase or engineered polymerases designed for modified templates.[4] |
| Suboptimal Annealing Temperature: The increased Tm of 2-AIC-containing regions may require a higher annealing temperature. | Optimize the annealing temperature using a gradient PCR. Start with a temperature 5°C below the calculated Tm of the primers and adjust in 2°C increments.[5][6][7] | |
| Inefficient Denaturation: High GC content coupled with 2-AIC modifications can hinder strand separation. | Increase the initial denaturation time and/or temperature. Consider adding a PCR enhancer like DMSO or betaine to the reaction mix.[5][8] | |
| Poor Template Quality: The presence of inhibitors in the DNA sample can interfere with PCR. | Re-purify the DNA template using a column-based kit or ethanol precipitation to remove potential inhibitors.[5][6] | |
| Multiple Bands or Smearing on Gel | Non-Specific Primer Annealing: Low annealing temperatures can lead to off-target amplification. | Increase the annealing temperature in 2-5°C increments.[5][6] Redesign primers to have higher specificity and avoid regions with repetitive sequences. |
| Excessive Template or Cycles: Too much input DNA or too many PCR cycles can lead to the accumulation of non-specific products. | Reduce the amount of template DNA.[6] Decrease the number of PCR cycles to 25-30.[7] | |
| Discrepancies in Sequencing Data (Compared to Expected Sequence) | Polymerase Misincorporation: The polymerase may be incorrectly incorporating bases opposite the 2-AIC. | Use a polymerase known for high fidelity with modified bases. Optimize dNTP concentrations and ensure the correct balance of all four nucleotides. |
| Sequencing Chemistry Issues: Certain sequencing platforms or chemistries may be less compatible with modified bases. | Consult the technical documentation for your sequencing platform regarding its performance with modified DNA. Consider trying an alternative sequencing method if issues persist.[9][10] | |
| Data Analysis Artifacts: The alignment software may misinterpret the modified base, leading to incorrect base calls. | Use bioinformatics tools specifically designed to handle modified bases or adjust the alignment parameters to be more tolerant of mismatches at the 2-AIC positions.[11][12] |
Experimental Workflow: Optimizing PCR for 2-AIC Templates
This workflow provides a step-by-step guide to systematically optimize PCR amplification of your 2-AIC-modified DNA.
Caption: PCR Optimization Workflow for 2-AIC Templates.
Frequently Asked Questions (FAQs)
Q1: Can I use a high-fidelity polymerase for amplifying 2-AIC templates to minimize errors?
While the goal of minimizing errors is valid, high-fidelity polymerases with 3'->5' exonuclease (proofreading) activity often struggle with modified bases like 2-AIC.[3][4] The proofreading domain may recognize the modified base as damage or a mismatch, leading to polymerase stalling or excision of the nascent DNA strand. It is generally recommended to start with a non-proofreading polymerase, such as Taq, and optimize the reaction conditions to ensure specificity. If high fidelity is absolutely critical, consider screening several engineered high-fidelity polymerases that are specifically designed to be more tolerant of modified templates.
Q2: My sequencing results show a high rate of G-to-A transitions at the position opposite 2-AIC. What is the likely cause?
This is a classic signature of polymerase misincorporation. While 2-AIC is designed to pair with guanine, under certain conditions, a polymerase might preferentially incorporate an adenine opposite the modified base. This can be influenced by the specific polymerase used, the local sequence context, and the reaction conditions (e.g., dNTP concentrations, Mg2+ concentration). To mitigate this, try a different DNA polymerase, and consider optimizing the MgCl2 and dNTP concentrations in your PCR and sequencing reactions.[13]
Q3: Is bisulfite sequencing compatible with 2-AIC-modified DNA?
Standard bisulfite sequencing is designed to convert unmethylated cytosines to uracil, while leaving 5-methylcytosine unaffected.[14][15][16] The chemical reactivity of 2-Aminoisocytosine to sodium bisulfite has not been extensively characterized in the same way as cytosine and its methylated forms. Therefore, it is not advisable to use standard bisulfite sequencing protocols on 2-AIC-containing templates, as the results would be uninterpretable without specific validation of how 2-AIC reacts. If you need to analyze both 2-AIC and DNA methylation, you would need to develop a custom workflow, potentially involving alternative chemical treatments or enzymatic approaches to differentiate the modifications.
Q4: How should I prepare my library for Next-Generation Sequencing (NGS) with 2-AIC-modified DNA?
The core steps of NGS library preparation—fragmentation, end-repair, A-tailing, and adapter ligation—should be generally compatible with 2-AIC-modified DNA.[17][18][19] The critical step that requires optimization is the library amplification (PCR) step. As detailed in the troubleshooting guide, the choice of polymerase and PCR conditions is paramount to faithfully amplify the 2-AIC-containing fragments. It is also crucial to perform rigorous quality control of the final library to ensure that the fragment size distribution and yield are appropriate for your chosen sequencing platform.[20]
Logical Flow: Troubleshooting Sequencing Data
This diagram outlines a decision-making process for analyzing and troubleshooting sequencing data from 2-AIC-modified templates.
Caption: Troubleshooting Flow for 2-AIC Sequencing Data.
Conclusion
Sequencing DNA templates modified with 2-Aminoisocytosine presents unique but surmountable challenges. By understanding the fundamental interactions between this modified base and the enzymes used in sequencing workflows, researchers can rationally design and troubleshoot their experiments. The key to success lies in the careful selection of DNA polymerases and the systematic optimization of PCR conditions. With the guidance provided in this technical support center, you are well-equipped to generate high-quality, accurate sequencing data from your 2-AIC-modified templates, advancing your research and development goals.
References
-
Roles of the Amino Group of Purine Bases in the Thermodynamic Stability of DNA Base Pairing. PMC - PubMed Central. [Link]
-
Bisulfite sequencing. Wikipedia. [Link]
-
Guanine. Wikipedia. [Link]
-
NGS library preparation. QIAGEN. [Link]
-
Bisulfite Sequencing of DNA. PMC - NIH. [Link]
-
Troubleshooting your PCR. Takara Bio. [Link]
-
NGS Library Preparation - 3 Key Technologies. Illumina. [Link]
-
Base pairing. The Chinese University of Hong Kong. [Link]
-
NGS Library Preparation: Proven Ways to Optimize Sequencing Workflow. CD Genomics. [Link]
-
PCR Troubleshooting. Bio-Rad. [Link]
-
PCR Troubleshooting Guide 2. Scribd. [Link]
-
Preparation of high-quality next-generation sequencing libraries from picogram quantities of target DNA. PubMed Central. [Link]
-
DNA sequencing. Wikipedia. [Link]
-
Bisulfite Sequencing for DNA Methylation Analysis of Primary Muscle Stem Cells. NIH. [Link]
-
Bisulfite sequencing - Cytosine methylation – GATK. Genome Analysis Toolkit. [Link]
-
Introduction to DNA Sequencing. Geneious. [Link]
-
Bisulfite Sequencing for Cytosine-Methylation Analysis in Plants. PubMed. [Link]
-
On the fidelity of DNA replication: use of synthetic oligonucleotide-initiated reactions. PubMed. [Link]
-
DNA Sequencing | Understanding the genetic code. Illumina. [Link]
-
Molecular basis for the faithful replication of 5-methylcytosine and its oxidized forms by DNA polymerase β. PubMed. [Link]
-
Does anyone have high-fidelity polymerase recommendations for primers that are degenerate and have inosine bases in them?. ResearchGate. [Link]
-
Enzymatic methylation of DNA in cultured human cells studied by stable isotope incorporation and mass spectrometry. PubMed. [Link]
-
Stability of 2'-deoxyxanthosine in DNA. PubMed - NIH. [Link]
-
Bioinformatics challenges of new sequencing technology. PMC - NIH. [Link]
-
Global analysis of cytosine and adenine DNA modifications across the tree of life. eLife. [Link]
-
DNA Sequencing: Definition, Methods, and Applications. CD Genomics Blog. [Link]
-
How to Identify DNA Modifications and Select Suitable Restriction Enzymes for Digestion?. ResearchGate. [Link]
-
Basic Bioinformatic Analyses of NGS Data. ScienceDirect. [Link]
-
6-aza-2'-deoxyisocytidine: synthesis, properties of oligonucleotides, and base-pair stability adjustment of DNA with parallel strand orientation. PubMed. [Link]
-
Digestion of highly modified bacteriophage DNA by restriction endonucleases. PMC - NIH. [Link]
-
Base Pairing Specificity A With T G With C - Nucleic Acid Structure And Function - MCAT Content. Jack Westin. [Link]
-
Homopairing possibilities of the DNA bases cytosine and guanine: an ab initio DFT study. PubMed. [Link]
-
Digestion of highly modified bacteriophage DNA by restriction endonucleases. PubMed. [Link]
-
Roles of the Amino Group of Purine Bases in the Thermodynamic Stability of DNA Base Pairing. MDPI. [Link]
-
Biological Sequence Analysis. Computational Biology - NCBI Bookshelf - NIH. [Link]
-
The Clinical Utility of Two High-Throughput 16S rRNA Gene Sequencing Workflows for Taxonomic Assignment of Unidentifiable Bacterial Pathogens in Matrix-Assisted Laser Desorption Ionization–Time of Flight Mass Spectrometry. PMC - NIH. [Link]
-
The Structure and Function of DNA. Molecular Biology of the Cell - NCBI Bookshelf. [Link]
Sources
- 1. Roles of the Amino Group of Purine Bases in the Thermodynamic Stability of DNA Base Pairing - PMC [pmc.ncbi.nlm.nih.gov]
- 2. mdpi.com [mdpi.com]
- 3. neb.com [neb.com]
- 4. researchgate.net [researchgate.net]
- 5. Troubleshooting PCR and RT-PCR Amplification [sigmaaldrich.com]
- 6. Troubleshooting your PCR [takarabio.com]
- 7. bio-rad.com [bio-rad.com]
- 8. neb.com [neb.com]
- 9. DNA sequencing - Wikipedia [en.wikipedia.org]
- 10. Introduction to DNA Sequencing - Geneious [geneious.com]
- 11. Redirecting [linkinghub.elsevier.com]
- 12. Biological Sequence Analysis - Computational Biology - NCBI Bookshelf [ncbi.nlm.nih.gov]
- 13. mybiosource.com [mybiosource.com]
- 14. Bisulfite sequencing - Wikipedia [en.wikipedia.org]
- 15. Bisulfite Sequencing of DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 16. gatk.broadinstitute.org [gatk.broadinstitute.org]
- 17. NGS library preparation [qiagen.com]
- 18. sg.idtdna.com [sg.idtdna.com]
- 19. NGS Library Preparation: Proven Ways to Optimize Sequencing Workflow - CD Genomics [cd-genomics.com]
- 20. NGS Library Preparation - 3 Key Technologies | Illumina [illumina.com]
Technical Support Center: Optimization of Antigen Retrieval for Immunohistochemistry
A Guide for Researchers, Scientists, and Drug Development Professionals
Welcome to the technical support center for immunohistochemistry (IHC). This guide is designed to provide you, the researcher, with in-depth, field-proven insights into one of the most critical and variable steps in the IHC workflow: antigen retrieval. My goal is to move beyond simple protocol recitation and explain the causality behind our experimental choices, empowering you to troubleshoot effectively and achieve robust, reproducible results.
Part 1: Frequently Asked Questions - The "Why" Behind the "How"
This section addresses the fundamental principles of antigen retrieval. Understanding these core concepts is the first step toward intelligent optimization and troubleshooting.
Q1: What is antigen retrieval and why is it necessary for FFPE tissues?
A: Antigen retrieval is a pretreatment process used to unmask epitopes that have been chemically altered by formalin fixation.[1][2] Formalin, the standard fixative for preserving tissue morphology, creates methylene bridges that cross-link proteins.[3][4][5] This cross-linking is excellent for structural preservation but can change the protein's three-dimensional shape or directly block the epitope, preventing the primary antibody from binding.[2][6] Without an effective antigen retrieval step, many antibodies will produce weak or false-negative staining results on formalin-fixed, paraffin-embedded (FFPE) tissues.[1][6]
Q2: What is the molecular mechanism of antigen retrieval?
A: The exact mechanism is multifaceted and still under investigation, but it is primarily understood to involve the reversal of formalin-induced cross-links.[7]
-
Heat-Induced Epitope Retrieval (HIER): This is the most common method. The application of thermal energy, in combination with a specific buffer solution, is believed to hydrolyze and break the methylene bridges.[8][9] This process allows the protein to refold, at least partially, to its native conformation, thereby re-exposing the antigenic site for antibody binding.[8]
-
Proteolytic-Induced Epitope Retrieval (PIER): This method uses enzymes like Proteinase K or Trypsin to enzymatically digest the proteins and peptides that may be sterically hindering the epitope.[10] It essentially "chews away" the masking proteins to allow antibody access.[10]
Q3: Is antigen retrieval always required?
A: Not universally, but it is essential for the vast majority of antibodies used on FFPE tissues.[2] The need for antigen retrieval depends on the fixation method, the specific antigen, and the primary antibody itself.[2][11] Some robust epitopes may survive formalin fixation, and frozen tissues typically do not require antigen retrieval because they are not cross-linked by formalin.[12] However, for FFPE tissues, it should be considered a mandatory optimization step for any new antibody.[3]
Q4: How do I choose between Heat-Induced (HIER) and Proteolytic-Induced (PIER) retrieval?
A: This is a critical decision point in protocol development.
-
Start with HIER: For most antibodies and antigens, HIER is the recommended starting point.[4][10] It generally provides more consistent results and better preservation of tissue morphology compared to PIER.[4]
-
Consult the Antibody Datasheet: The antibody manufacturer has likely performed extensive validation and will recommend the optimal retrieval method and buffer. This is your most valuable source of information.[10][13]
-
When to Consider PIER: PIER can be effective for certain antigens where HIER fails or when working with tissues that are particularly fragile.[3][4] However, PIER is a harsher method and carries a significant risk of damaging tissue morphology or even destroying the epitope itself if not carefully optimized.[4][7][10] Some specific targets, particularly in dense extracellular matrices like cartilage, may show superior results with PIER.[14]
Part 2: Troubleshooting Guide - From Problem to Solution
This section is structured to address the specific problems you are likely to encounter. For each issue, I will outline the likely causes related to antigen retrieval and provide clear, actionable solutions.
Issue 1: Weak or No Staining
This is the most common frustration in IHC. Before blaming the primary antibody, a thorough review of your antigen retrieval step is warranted.
Q: My signal is extremely weak or completely absent. I've checked my antibody concentrations. Could antigen retrieval be the problem?
A: Absolutely. This is a classic sign of suboptimal antigen retrieval. Here's how to troubleshoot:
-
Inadequate Heating (HIER): The thermal energy was insufficient to break the cross-links.
-
Solution: Ensure your retrieval solution reaches and maintains the target temperature (typically 95-100°C) for the entire duration.[3][5] Verify the temperature with a calibrated thermometer. Microwaves can have hot and cold spots, leading to uneven heating.[7] A pressure cooker or steamer often provides more consistent results.[7] Increase the heating time in 5-minute increments to find the optimal duration.
-
-
Incorrect Buffer pH (HIER): The pH of the retrieval buffer is critical for epitope unmasking and is antibody-dependent.[8]
-
Solution: This is the most important variable to test. If the antibody datasheet doesn't specify a buffer, start by testing two common options: Sodium Citrate buffer (pH 6.0) and Tris-EDTA buffer (pH 9.0).[3][7][13] Many antigens show dramatically better staining in one pH versus the other. Alkaline buffers (pH 8-10) often result in more efficient retrieval and stronger staining intensity for many antibodies.[15][16]
-
-
Ineffective Enzyzme Activity (PIER): The enzyme may be inactive or the incubation time may be incorrect.
Issue 2: High Background Staining
High background obscures your specific signal, making interpretation impossible. While several factors can cause this, improper antigen retrieval can be a key contributor.
Q: I have strong staining, but it's everywhere. The background is so high that I can't identify specific localization. How can antigen retrieval cause this?
A: Overly aggressive antigen retrieval can expose non-specific protein binding sites or damage the tissue, leading to high background.
-
Over-retrieval (HIER or PIER): Excessive heating or enzymatic digestion can damage tissue morphology and expose charged surfaces that non-specifically bind antibodies.[7]
-
Solution (HIER): Reduce the heating time or temperature. If using a pressure cooker (which reaches >100°C), this is a common issue. A gentler method like a water bath or steamer may be necessary.[5][17]
-
Solution (PIER): This method is particularly prone to causing tissue damage.[10] Reduce the enzyme concentration or shorten the incubation time significantly.[3]
-
-
Wrong Buffer Choice: Some buffers, particularly those containing EDTA at high pH, can be harsh on certain tissues, leading to increased background and tissue lifting.[15][16]
-
Solution: If you are using a high pH Tris-EDTA buffer and experiencing high background, test a citrate buffer (pH 6.0). While it may result in a slightly weaker specific signal for some targets, it often provides a much cleaner background due to better morphological preservation.[16]
-
Issue 3: Damaged Tissue Morphology or Section Detachment
Your staining is beautiful, but the tissue is falling apart or has detached from the slide. The culprit is almost always an overly harsh retrieval process.
Q: My tissue sections are lifting off the slide or look "chewed up" after the retrieval step. What's going wrong?
A: This is a clear indication that your retrieval conditions are too harsh for your tissue type.
-
Aggressive HIER: High temperatures, especially in alkaline buffers, can be very tough on tissues.[15][17]
-
Solution: First, ensure you are using positively charged slides to promote adhesion. Second, reduce the harshness of the retrieval. Lower the heating temperature and/or time. Consider switching from a pressure cooker to a water bath.[17] A lower pH buffer (e.g., Citrate pH 6.0) is often gentler on tissue morphology.[16]
-
-
Over-digestion with PIER: Proteolytic enzymes, by their nature, digest proteins. Excessive digestion will destroy tissue integrity.[10]
-
Solution: This requires careful titration. Systematically reduce the enzyme concentration and/or incubation time until morphology is preserved while maintaining an acceptable signal.[3]
-
Part 3: Data, Protocols, and Workflows
Comparative Data Tables
To guide your optimization, these tables summarize common starting points and variables for HIER and PIER.
Table 1: Common Heat-Induced Epitope Retrieval (HIER) Buffers
| Buffer Name | Composition | Typical pH | Common Use & Rationale |
|---|---|---|---|
| Sodium Citrate | 10 mM Sodium Citrate | 6.0 | A very common starting buffer. Generally gentle on tissue morphology. Effective for a wide range of antigens.[3][7] |
| Tris-EDTA | 10 mM Tris Base, 1 mM EDTA | 9.0 | Often provides stronger staining than citrate buffer.[15] The high pH and chelating agent (EDTA) are highly effective at reversing cross-links. Recommended for many nuclear antigens.[3][7] |
| EDTA | 1 mM EDTA | 8.0 | A strong retrieval solution, useful for difficult-to-detect antigens or over-fixed tissues. Can be harsh on morphology.[3][16] |
Table 2: Common Proteolytic-Induced Epitope Retrieval (PIER) Enzymes
| Enzyme | Typical Working Concentration | Incubation Conditions | Notes & Cautions |
|---|---|---|---|
| Trypsin | 0.05% - 0.1% | 10-20 min @ 37°C | Requires Ca²⁺ for activity (often included in buffer). Must be carefully optimized to avoid tissue destruction.[3][7] |
| Proteinase K | 20 µg/mL | 10-20 min @ 37°C | A very aggressive enzyme. Use with caution. Often used for retrieving difficult epitopes.[3] |
| Pepsin | 0.1% | 10-20 min @ 37°C | Another commonly used protease. As with all enzymes, requires careful titration of time and concentration. |
Experimental Protocols
These are validated, step-by-step starting protocols. Remember, optimization for your specific antibody, tissue, and fixation is always necessary.
Protocol 1: Heat-Induced Epitope Retrieval (HIER) using a Water Bath
-
Deparaffinize and rehydrate FFPE tissue sections through xylene and a graded alcohol series to distilled water.[18][19]
-
Pre-heat a water bath containing a staining jar filled with your chosen HIER buffer (e.g., 10 mM Sodium Citrate, pH 6.0) to 95-100°C.[6]
-
Immerse the slides completely in the pre-heated buffer within the staining jar.[6]
-
Place the lid loosely on the staining jar and incubate for 20 minutes. Maintain the temperature. Do not let the slides dry out.[6]
-
After incubation, remove the staining jar from the water bath and allow it to cool on the benchtop for at least 20 minutes with the slides still immersed in the buffer.[6] This slow cooling step is critical for proper protein refolding.
-
Rinse the slides gently with distilled water, followed by a wash buffer (e.g., PBS).
-
The slides are now ready to proceed with the blocking step of your IHC protocol.
Protocol 2: Proteolytic-Induced Epitope Retrieval (PIER) using Trypsin
-
Deparaffinize and rehydrate FFPE tissue sections to distilled water.
-
Prepare a 0.05% Trypsin working solution in a calcium chloride-containing buffer (pH ~7.8).[7] Pre-warm the solution to 37°C.
-
Place the slides in a humidified chamber. A container with a wet paper towel at the bottom works well.[3][7]
-
Cover the tissue sections completely with the pre-warmed Trypsin solution.
-
Incubate for 10-20 minutes at 37°C. Note: This time is the most critical variable to optimize.
-
Stop the enzymatic reaction by thoroughly rinsing the slides in cold running tap water for 3 minutes, followed by a wash buffer (e.g., PBS).[18]
-
Proceed with the IHC staining protocol.
Mandatory Visualizations
Diagram 1: Antigen Retrieval Decision Workflow
This diagram outlines the logical steps for selecting and optimizing an antigen retrieval protocol for a new primary antibody.
Caption: Decision workflow for selecting an initial antigen retrieval strategy.
Diagram 2: Troubleshooting Flowchart for Suboptimal Staining
This flowchart provides a logical path to diagnose and solve common issues related to antigen retrieval after an initial experiment has failed.
Caption: A logical flowchart for troubleshooting common IHC staining issues related to antigen retrieval.
References
-
Bio-Techne. Antigen Retrieval Protocol (PIER) | Proteolytic-Induced Epitope Retrieval. [Link]
-
Boster Biological Technology. IHC Antigen Retrieval Protocol | Heat & Enzyme Methods. [Link]
-
Rockland Immunochemicals. Protease-induced Antigen Retrieval Protocol. [Link]
-
Boster Biological Technology. Optimizing Your Antigen Retrieval Method - HIER vs PIER. [Link]
-
MBL Life Science. The principle and method of Immunohistochemistry (IH). [Link]
-
Yamashita S. Heat-induced antigen retrieval: mechanisms and application to histochemistry. PubMed. [Link]
-
OriGene Technologies Inc. IHC Troubleshooting. [Link]
-
Wikipedia. Antigen retrieval. [Link]
-
Leica Biosystems. An Intro to Heat Induced Epitope Retrieval (HIER) in IHC. [Link]
-
Sino Biological. Antigen Retrieval-Should I do PIER or HIER?. [Link]
-
BMA BIOMEDICALS. Troubleshooting in IHC. [Link]
-
Atlas Antibodies. Antigen Retrieval in IHC: Why It Matters and How to Get It Right. [Link]
-
Antibodies.com. Immunohistochemistry Troubleshooting. [Link]
-
Springer Protocols. Heat-Induced Antigen Retrieval in Immunohistochemistry: Mechanisms and Applications. [Link]
-
Boster Biological Technology. Optimizing HIER Antigen Retrieval for IHC | Step-by-Step Guide. [Link]
-
nPOD. STANDARD OPERATING PROCEDURE. [Link]
-
Immunohistochemistry Supports, Products & Services. IHC tips antigen retrieval. [Link]
-
Lab Gopher. Ultimate IHC Troubleshooting Guide: Fix Weak Staining & High Background. [Link]
-
Boster Biological Technology. IHC Troubleshooting Guide | Common Issues & Fixes. [Link]
-
Pileri, S. A., Roncador, G., & Ceccarelli, C., et al. Heat-Induced Antigen Retrieval for Immunohistochemical Reactions in Routinely Processed Paraffin Sections. PubMed Central. [Link]
-
Creative Biolabs Antibody. Troubleshooting of Immunohistochemistry (IHC). [Link]
-
NIH. Comparison of Antigen Retrieval Methods for Immunohistochemical Analysis of Cartilage Matrix Glycoproteins Using Cartilage Intermediate Layer Protein 2 (CILP-2) as an Example. [Link]
-
NIH. A Method for the Immunohistochemical Identification and Localization of Osterix in Periosteum-Wrapped Constructs for Tissue Engineering of Bone. [Link]
Sources
- 1. Antigen retrieval - Wikipedia [en.wikipedia.org]
- 2. Antigen Retrieval in IHC: Why It Matters and How to Get It Right [atlasantibodies.com]
- 3. bosterbio.com [bosterbio.com]
- 4. bosterbio.com [bosterbio.com]
- 5. An Intro to Heat Induced Epitope Retrieval (HIER) in IHC [leicabiosystems.com]
- 6. Antigen Retrieval Protocol: Novus Biologicals [novusbio.com]
- 7. IHC antigen retrieval protocol | Abcam [abcam.com]
- 8. Heat-Induced Epitope Retrieval - Biocare Medical [biocare.net]
- 9. Heat-induced antigen retrieval: mechanisms and application to histochemistry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. sinobiological.com [sinobiological.com]
- 11. IHC antigen retrieval: HIER vs. PIER: Novus Biologicals [novusbio.com]
- 12. The principle and method of Immunohistochemistry (IH) | MBL Life Sience -GLOBAL- [mblbio.com]
- 13. Ultimate IHC Troubleshooting Guide: Fix Weak Staining & High Background [atlasantibodies.com]
- 14. Comparison of Antigen Retrieval Methods for Immunohistochemical Analysis of Cartilage Matrix Glycoproteins Using Cartilage Intermediate Layer Protein 2 (CILP-2) as an Example - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Heat-Induced Antigen Retrieval for Immunohistochemical Reactions in Routinely Processed Paraffin Sections - PMC [pmc.ncbi.nlm.nih.gov]
- 16. biocare.net [biocare.net]
- 17. A Method for the Immunohistochemical Identification and Localization of Osterix in Periosteum-Wrapped Constructs for Tissue Engineering of Bone - PMC [pmc.ncbi.nlm.nih.gov]
- 18. Protease-induced Antigen Retrieval Protocol | Rockland [rockland.com]
- 19. Immunohistochemistry Procedure [sigmaaldrich.com]
Technical Support Center: Fine-Tuning Immunohistochemistry Protocols for New Targets
Welcome to the Technical Support Center for Immunohistochemistry (IHC). This guide is designed for researchers, scientists, and drug development professionals who are navigating the complexities of developing and fine-tuning IHC protocols for novel targets. As a Senior Application Scientist, my goal is to provide you with not just the "how," but the critical "why" behind each step, empowering you to troubleshoot effectively and generate reliable, publication-quality data.
The Logic of a Robust IHC Protocol
A successful IHC experiment is more than a series of steps; it's a self-validating system built on a foundation of specificity, sensitivity, and reproducibility. When developing a protocol for a new target, every component—from the antibody to the final counterstain—must be systematically optimized and validated. This guide will walk you through this process, providing both foundational knowledge and actionable troubleshooting advice.
Section 1: The Cornerstone of IHC - Antibody Validation
The single most critical factor in an IHC experiment is the primary antibody. An antibody that lacks specificity will produce meaningless data, regardless of how well the rest of the protocol is optimized. Therefore, rigorous validation is non-negotiable.
FAQ: Antibody Validation
Q1: My antibody is "IHC-validated" according to the vendor. Is that enough?
A: Vendor validation is a good starting point, but it is not a substitute for in-house validation. The vendor's protocol may use different tissues, fixation methods, or detection systems than your experiment.[1] You must validate the antibody under your specific experimental conditions.
Q2: What is the first step in validating a new antibody?
A: Before even running an IHC, you should confirm the antibody's specificity by a non-IHC method, with Western Blot (WB) being the most common.[2][3] The WB should show a single band at the correct molecular weight for your target protein in a lysate from a cell line or tissue known to express it.[3][4] This initial step helps rule out significant cross-reactivity.[3]
Q3: What are the essential controls for IHC antibody validation?
A: A robust validation includes several key controls:
-
Positive Control Tissue: Tissue known to express the target protein. This confirms that your protocol is capable of detecting the antigen.[2][5][6]
-
Negative Control Tissue: Tissue known not to express the target protein. This helps to identify non-specific binding and false positives.[3][5][6]
-
No Primary Control: A slide run through the entire protocol without the primary antibody.[6][7] Any signal observed here indicates non-specific binding of the secondary antibody or detection system.
-
Isotype Control: A slide incubated with a non-immune antibody of the same isotype and at the same concentration as the primary antibody. This helps to differentiate specific signal from non-specific binding due to the antibody's Fc region.[2]
Workflow: New Antibody Validation
This workflow outlines the logical progression for validating a new primary antibody for use in IHC.
Caption: A stepwise workflow for new antibody validation in IHC.
Section 2: Unmasking the Target - Antigen Retrieval
Formalin fixation is excellent for preserving tissue morphology, but it creates protein cross-links that can mask the antigenic epitope your antibody needs to recognize.[8][9] Antigen retrieval is the process of breaking these cross-links to expose the epitope.
FAQ: Antigen Retrieval
Q1: Should I use Heat-Induced (HIER) or Proteolytic-Induced (PIER) Epitope Retrieval?
A: HIER is the most common and generally more successful method for formalin-fixed, paraffin-embedded (FFPE) tissues.[9][10] It involves heating the tissue sections in a buffer. PIER uses enzymes like proteinase K or trypsin to digest proteins and unmask the epitope.[8][9] PIER can be harsh and may damage tissue morphology or even the epitope itself.[9] HIER is the recommended starting point for most new targets.[10]
Q2: How do I choose the right HIER buffer and pH?
A: The optimal buffer and pH are antigen- and antibody-dependent. There is no universal solution.[11] The two most common starting points are:
-
Citrate Buffer (pH 6.0): A common choice for many antigens.
-
Tris-EDTA Buffer (pH 9.0): Often provides superior results for nuclear or difficult-to-detect antigens.
When optimizing for a new antibody, it is highly recommended to test both a low pH and a high pH buffer to see which yields the best signal-to-noise ratio.[9]
Q3: Does the heating method matter in HIER?
A: Yes, the combination of temperature and time is critical.[11] Common methods include a pressure cooker, microwave, or water bath. The goal is to achieve a consistent temperature (typically 95-100°C) for a specific duration (usually 10-30 minutes).[9] Over-heating can damage the tissue, while under-heating will result in incomplete antigen unmasking. It's crucial to standardize your method for reproducibility.
Experimental Protocol: Optimizing HIER Conditions
This protocol provides a matrix approach to efficiently determine the best HIER conditions for a new antibody.
Objective: To identify the optimal HIER buffer and heating time for a novel target.
Materials:
-
Slides with FFPE sections of your positive control tissue.
-
HIER Buffers: Sodium Citrate (pH 6.0) and Tris-EDTA (pH 9.0).
-
Heat source (e.g., pressure cooker or water bath).
-
Validated primary and secondary antibodies.
-
Detection system and chromogen.
Procedure:
-
Deparaffinize and Rehydrate: Process all slides through xylene and graded alcohols to water.
-
Divide and Conquer: Separate the slides into two main groups for the two buffer conditions. Further divide each group to test different heating times.
-
HIER Treatment:
-
Group 1 (Citrate pH 6.0): Heat subsets of slides for 10 min, 20 min, and 30 min at 95-100°C.
-
Group 2 (Tris-EDTA pH 9.0): Heat subsets of slides for 10 min, 20 min, and 30 min at 95-100°C.
-
-
Cooling: Allow all slides to cool in their respective buffers for at least 20 minutes at room temperature. This is a critical step for proper protein refolding.
-
Staining: Proceed with the remainder of your standard IHC protocol (blocking, primary antibody, secondary antibody, detection, etc.), ensuring all slides are treated identically from this point forward.
-
Analysis: Evaluate the slides microscopically.
Data Interpretation:
Summarize your findings in a table to easily compare the results.
| HIER Condition | Staining Intensity | Background Staining | Tissue Morphology | Optimal? |
| Citrate pH 6.0, 10 min | + | - | +++ | No |
| Citrate pH 6.0, 20 min | ++ | +/- | ++ | Maybe |
| Citrate pH 6.0, 30 min | +++ | + | + | No |
| Tris-EDTA pH 9.0, 10 min | ++ | - | +++ | Maybe |
| Tris-EDTA pH 9.0, 20 min | +++ | - | +++ | Yes |
| Tris-EDTA pH 9.0, 30 min | +++ | ++ | + | No |
Scoring: - (None), +/- (Trace), + (Weak), ++ (Moderate), +++ (Strong)
The optimal condition is the one that provides the strongest specific signal with the lowest background and best-preserved morphology.
Section 3: Troubleshooting Guide
Even with a validated antibody and optimized antigen retrieval, problems can arise. This section addresses the most common issues encountered during IHC protocol development.
Caption: A troubleshooting decision tree for common IHC issues.
FAQ: Troubleshooting
Q1: I have no staining at all, not even in my positive control. What's the most likely cause?
A: If the positive control isn't working, the issue is likely systemic. Start by checking your reagents.
-
Detection System: Is it working? You can test this by spotting a small amount of secondary antibody onto a nitrocellulose membrane and adding the substrate. You should see a strong reaction.
-
Primary Antibody: Has it been stored correctly? Has it undergone multiple freeze-thaw cycles? Try a fresh aliquot.
-
Antigen Retrieval: Was it performed correctly? This is a common point of failure. Ensure your buffers are correctly made and the heating was consistent.
-
Tissue Preparation: Were the slides stored for a long time? Antigenicity can decrease over time.[12][13] Freshly cut sections are always recommended.[12]
Q2: My background is very high, obscuring the specific signal. How can I fix this?
A: High background is usually caused by non-specific binding of antibodies or issues with the detection system.[14]
-
Blocking Step: This is the first thing to optimize. Ensure you are blocking for an adequate amount of time (e.g., 1 hour at room temperature).[15] The blocking agent itself is critical. Normal serum from the species in which the secondary antibody was raised is often the best choice.[16][17] For example, if you have a goat anti-rabbit secondary, use normal goat serum for blocking.[16]
-
Antibody Concentration: Your primary antibody may be too concentrated. Perform a titration experiment, testing several dilutions to find the one with the best signal-to-noise ratio.[13][15]
-
Endogenous Enzymes: If you are using an HRP-based detection system, endogenous peroxidases (e.g., in red blood cells) can cause background. Always include a hydrogen peroxide (H2O2) quenching step after rehydration.[15] Similarly, for alkaline phosphatase (AP) systems, endogenous AP may need to be blocked with levamisole.
-
Washing: Insufficient washing between steps can leave behind unbound antibody, leading to high background. Increase the duration and number of your wash steps.[15]
Q3: I see staining, but it's in the wrong cellular location. What does this mean?
A: This points to a specificity problem.
-
Antibody Specificity: Revisit your antibody validation. Does your Western Blot show a clean band? Does the staining pattern match published literature for this protein?[3]
-
Antigen Retrieval: Harsh antigen retrieval can sometimes expose new, cross-reactive epitopes or alter protein conformation. Try reducing the heating time or using a milder buffer.
-
Permeabilization: For intracellular targets, a permeabilization step (e.g., with Triton X-100 or Saponin) is necessary.[15] However, for membrane proteins, this can lead to artifactual staining. Ensure your permeabilization strategy is appropriate for your target's location.[15]
References
-
Gown, A. M., & Atkins, D. (2018). Antibody validation of immunohistochemistry for biomarker discovery: Recommendations of a consortium of academic and pharmaceutical based histopathology researchers. Biotechnic & Histochemistry, 93(1), 1-18. [Link]
-
Bio-Techne. (n.d.). IHC Blocking Non-Specific Binding of Antibodies & Other Reagents. Retrieved from [Link]
-
Boster Biological Technology. (n.d.). Immunohistochemistry Troubleshooting Guide. Retrieved from [Link]
-
arigo Biolaboratories Corp. (n.d.). Immunohistochemistry Troubleshooting Guide. Retrieved from [Link]
-
Bitesize Bio. (2025, May 30). Immunohistochemistry Basics: Blocking Non-Specific Staining. Retrieved from [Link]
-
Li, L. (n.d.). Optimizing Immunohistochemistry (IHC) The Antigen Retrieval Technique. University of North Carolina at Chapel Hill. Retrieved from [Link]
-
College of American Pathologists. (2014). Principles of analytic validation of immunohistochemical assays: Guideline from the College of American Pathologists Pathology and Laboratory Quality Center. Archives of Pathology & Laboratory Medicine, 138(11), 1432-1443. [Link]
-
Boster Biological Technology. (2023, February 6). Optimizing HIER Antigen Retrieval for IHC | Step-by-Step Guide. Retrieved from [Link]
-
Atlas Antibodies. (2025, October 1). Antigen Retrieval in IHC: Why It Matters and How to Get It Right. Retrieved from [Link]
-
Yi, J., & Kim, J. (2017). Immunohistochemistry for Pathologists: Protocols, Pitfalls, and Tips. Journal of Pathology and Translational Medicine, 51(4), 313-320. [Link]
-
Elite Learning. (2015, September 14). Validation for Immunohistochemistry. Retrieved from [Link]
-
Kumar, G. L., & Rudbeck, L. (2018). Optimisation and validation of immunohistochemistry protocols for cancer research. Journal of Cancer Research and Therapeutics, 14(7), 1471-1478. [Link]
-
Magaki, S., Hojat, S. A., & Wei, B. (2019). Optimizing Antibody Concentrations for Immunohistochemistry in Neurotrauma Research. Methods and Protocols, 2(2), 48. [Link]
-
Boster Biological Technology. (n.d.). 6 Essential IHC Controls for Reliable Staining Results. Retrieved from [Link]
-
Cell Signaling Technology. (2021, April 16). How to Optimize an Antibody for Immunohistochemistry. YouTube. Retrieved from [Link]
-
Boster Biological Technology. (n.d.). IHC Troubleshooting Guide | Common Issues & Fixes. Retrieved from [Link]
-
Biocompare. (2023, April 20). Avoiding Common Immunohistochemistry Mistakes. Retrieved from [Link]
-
ANT Bio. (2025, August 12). Solving IHC experimental difficult problems: common problems and coping. Retrieved from [Link]
Sources
- 1. biocare.net [biocare.net]
- 2. Antibody validation of immunohistochemistry for biomarker discovery: Recommendations of a consortium of academic and pharmaceutical based histopathology researchers - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Important IHC antibody validation steps | Abcam [abcam.com]
- 4. Antibody Validation for Immunohistochemistry | Cell Signaling Technology [cellsignal.com]
- 5. neobiotechnologies.com [neobiotechnologies.com]
- 6. bosterbio.com [bosterbio.com]
- 7. The importance of using controls in immunohistochemistry [novusbio.com]
- 8. huabio.com [huabio.com]
- 9. Antigen Retrieval in IHC: Why It Matters and How to Get It Right [atlasantibodies.com]
- 10. bosterbio.com [bosterbio.com]
- 11. feinberg.northwestern.edu [feinberg.northwestern.edu]
- 12. Immunohistochemistry (IHC) Troubleshooting Guide & the Importance of Using Controls | Cell Signaling Technology [cellsignal.com]
- 13. youtube.com [youtube.com]
- 14. vectorlabs.com [vectorlabs.com]
- 15. arigobio.com [arigobio.com]
- 16. IHC Blocking Non-Specific Binding of Antibodies & Other Reagents | Bio-Techne [bio-techne.com]
- 17. bitesizebio.com [bitesizebio.com]
Technical Support Center: Optimizing Reagents for Consistent and Interpretable IHC Images
Welcome to the Technical Support Center for Immunohistochemistry (IHC). This guide is designed for researchers, scientists, and drug development professionals to navigate the complexities of IHC reagent optimization. Our goal is to empower you with the knowledge to achieve consistent, interpretable, and publication-quality results by understanding the causality behind experimental choices. This resource is structured as a dynamic troubleshooting guide and an in-depth FAQ section to directly address the challenges you may encounter.
Section 1: Troubleshooting Common IHC Issues
This section addresses the most frequent problems encountered during IHC experiments. Each issue is broken down by potential causes and actionable solutions, grounded in the principles of antibody-antigen interactions and reagent chemistry.
Issue 1: Weak or No Staining
One of the most common and frustrating outcomes in IHC is faint or absent staining. This often points to issues with reagent viability, protocol parameters, or the target antigen's accessibility.
| Potential Cause | Underlying Reason | Recommended Solution & Explanation |
| Primary Antibody Issues | The antibody may not be validated for IHC, have low affinity, or be used at a suboptimal concentration.[1][2][3] | Verify Antibody Application: Always check the manufacturer's datasheet to confirm the antibody is validated for IHC on your specific sample type (e.g., FFPE, frozen).[1][2] Perform Titration: The manufacturer's recommended dilution is a starting point. Systematically test a range of dilutions (e.g., 1:50, 1:100, 1:200, 1:500) to determine the optimal concentration that yields the highest signal-to-noise ratio.[4][5] Confirm Antibody Activity: If in doubt, test the antibody in a different application like Western blot to ensure it recognizes the target protein.[1][2] |
| Antigen Retrieval Inefficiency | Formalin fixation creates protein cross-links that mask the antigenic epitope, preventing antibody binding.[6][7] The retrieval method (heat or enzymatic) may be insufficient to reverse this masking. | Optimize Antigen Retrieval: This is a critical step for FFPE tissues.[8] Systematically test different Heat-Induced Epitope Retrieval (HIER) buffers (e.g., Citrate pH 6.0, Tris-EDTA pH 9.0) and incubation times/temperatures (e.g., 95°C for 15-20 minutes).[6][7][9] For some antigens, Protease-Induced Epitope Retrieval (PIER) may be more effective.[6] Ensure Proper Technique: Use a validated heating method like a microwave or pressure cooker for HIER and ensure slides are fully submerged and do not dry out.[10] |
| Reagent Storage & Handling | Improper storage (e.g., repeated freeze-thaw cycles, incorrect temperature) can degrade antibodies and other reagents.[2] Slides stored for extended periods can lose antigenicity.[10][11] | Adhere to Storage Guidelines: Aliquot antibodies upon arrival to avoid repeated freeze-thaw cycles. Store all reagents at the temperatures recommended on their datasheets.[2] Use Freshly Cut Sections: For best results, use freshly prepared tissue sections. If storage is necessary, keep slides at 4°C and avoid baking them before storage.[1][10] |
| Detection System Insensitivity | The chosen detection system may not be sensitive enough to detect a low-abundance antigen.[10][12] | Select a High-Sensitivity System: Polymer-based detection systems are generally more sensitive than biotin-based systems.[10] For very low-expression targets, consider using an amplification step.[3] Check Reagent Expiration: Ensure all detection reagents, including substrates and chromogens, are within their expiration dates.[10] |
Issue 2: High Background Staining
High background staining obscures specific signals, making interpretation difficult or impossible. This is typically caused by non-specific binding of primary or secondary antibodies, or endogenous enzyme activity.[1]
| Potential Cause | Underlying Reason | Recommended Solution & Explanation |
| Non-Specific Antibody Binding | Primary or secondary antibodies may bind to unintended sites due to hydrophobic or ionic interactions. This is often exacerbated by using too high an antibody concentration.[13] | Optimize Blocking Step: Blocking is essential to saturate non-specific binding sites.[14][15] Use a blocking serum from the same species as the secondary antibody was raised in (e.g., normal goat serum for a goat anti-rabbit secondary).[14][16] Alternatively, protein solutions like Bovine Serum Albumin (BSA) can be effective.[14][16] Titrate Antibodies: Reduce the concentration of the primary and/or secondary antibody. High concentrations increase the likelihood of off-target binding.[3][13] Increase Wash Steps: More stringent or longer washes with a buffer containing a mild detergent (e.g., PBS-Tween 20) can help remove loosely bound, non-specific antibodies.[5] |
| Endogenous Enzyme Activity | Tissues can contain endogenous peroxidases or alkaline phosphatases that react with the enzyme-conjugated detection system, causing false-positive signals.[10][13] | Quench Endogenous Peroxidase: When using a Horseradish Peroxidase (HRP) detection system, pre-treat slides with a 3% hydrogen peroxide (H₂O₂) solution to inactivate endogenous peroxidases.[10] Block Endogenous Alkaline Phosphatase (AP): If using an AP-based system, treat with a reagent like Levamisole. |
| Endogenous Biotin | Tissues like the kidney, liver, and spleen are rich in endogenous biotin, which will be detected by avidin/streptavidin-based systems, leading to high background.[13] | Use a Biotin-Free System: The most reliable solution is to switch to a non-biotin polymer-based detection system.[12] Perform Avidin/Biotin Block: If using a biotin-based system is necessary, pre-treat the tissue with avidin and then biotin to block the endogenous biotin sites. |
| Cross-Reactivity of Secondary Antibody | The secondary antibody may cross-react with endogenous immunoglobulins in the tissue, especially when using mouse primary antibodies on mouse tissue ("mouse-on-mouse" staining).[13][14] | Use Pre-Adsorbed Secondaries: Select a secondary antibody that has been pre-adsorbed against the species of the tissue being stained to remove cross-reacting antibodies.[1] Use Species-Specific Blocking: For challenging situations like mouse-on-mouse, specialized blocking reagents containing F(ab) fragments are available to block endogenous IgG.[14] |
Issue 3: Non-Specific Staining (Specific but in the wrong place)
This issue is characterized by crisp, strong staining, but in an incorrect cellular location (e.g., nuclear staining for a cytoplasmic protein). This often points to antibody cross-reactivity or artifacts from tissue preparation.
| Potential Cause | Underlying Reason | Recommended Solution & Explanation |
| Antibody Cross-Reactivity | The primary antibody may be recognizing an epitope on a different protein with a similar structure. | Validate Antibody Specificity: Before use, verify the antibody's specificity. A Western blot on a relevant cell lysate should show a single band at the correct molecular weight.[17] Use Controls: Stain knockout/knockdown tissue or cell lines (if available) as a negative control to confirm the signal is absent.[18] Consult Literature: Review publications that have used the same antibody clone to see if the reported localization matches your results.[19] |
| Over-Fixation | Excessive formalin fixation can cause proteins to cross-link in unnatural positions, leading to artifactual localization.[13] | Standardize Fixation: Adhere to a strict fixation protocol. For most tissues, 10% neutral buffered formalin for 24 hours is standard.[11] Avoid prolonged fixation times. |
| Antigen Retrieval Artifacts | Harsh antigen retrieval conditions (especially with HIER) can sometimes alter protein conformation or expose new, non-native epitopes. | Optimize Retrieval Conditions: Empirically test different retrieval buffers, temperatures, and times. The mildest conditions that provide adequate signal are ideal. Start with a neutral pH buffer before moving to more acidic or basic options.[6] |
Section 2: Core Reagent Optimization Workflows
Achieving consistency starts with robust, validated reagents. This section provides step-by-step protocols for the critical validation experiments that form the foundation of any reliable IHC study.
Workflow 1: Primary Antibody Validation and Titration
The success of an IHC experiment is fundamentally dependent on the quality and optimal concentration of the primary antibody.[20] This workflow ensures the antibody is specific and used at a concentration that maximizes the signal-to-noise ratio.
Experimental Protocol: Antibody Titration
-
Prepare Slides: Use a set of identical, known positive control tissue sections for the titration.
-
Standardize Pre-treatment: Perform deparaffinization, rehydration, and antigen retrieval identically across all slides. Use the antigen retrieval method recommended on the antibody datasheet as a starting point.
-
Prepare Antibody Dilutions: Create a serial dilution of the primary antibody in a high-quality antibody diluent. A good starting range is often 1:50, 1:100, 1:200, 1:500, and 1:1000.[4][5]
-
Incubate: Apply each dilution to a separate slide. Include a "no primary" negative control slide that receives only the antibody diluent. Incubate all slides under the same conditions (e.g., overnight at 4°C).[5]
-
Detection: Use the same secondary antibody and detection system at their optimal, consistent concentrations on all slides.
-
Analyze: Examine the slides microscopically.
-
Too Concentrated: High background staining that obscures specific signals.
-
Too Dilute: Weak or no specific staining.
-
Optimal: Strong, specific staining with minimal to no background. This is the dilution you will use for future experiments.
-
Decision-Making Workflow for Antibody Selection
This diagram illustrates the logical process for selecting and validating a new primary antibody.
Caption: Workflow for primary antibody selection and validation.
Workflow 2: Antigen Retrieval Optimization
For formalin-fixed, paraffin-embedded (FFPE) tissues, antigen retrieval is arguably the most critical variable to optimize.[6] The goal is to reverse formaldehyde-induced cross-linking without damaging tissue morphology or the antigen itself.[7]
Experimental Protocol: HIER Optimization Matrix
This experiment aims to find the best combination of pH and heating time for your specific antibody and tissue.
-
Prepare Slides: Use at least 6 identical positive control tissue sections.
-
Prepare Buffers: Prepare two HIER buffers:
-
Buffer A: Sodium Citrate Buffer (10 mM Sodium Citrate, 0.05% Tween 20, pH 6.0).
-
Buffer B: Tris-EDTA Buffer (10 mM Tris Base, 1 mM EDTA, 0.05% Tween 20, pH 9.0).
-
-
Set Up Matrix:
-
Slides 1 & 2: Immerse in Buffer A.
-
Slides 3 & 4: Immerse in Buffer B.
-
Slide 5: No retrieval (negative control).
-
Slide 6: No primary antibody (method control).
-
-
Heat Treatment:
-
Heat Slides 1 and 3 for 10 minutes at 95-100°C.
-
Heat Slides 2 and 4 for 20 minutes at 95-100°C.
-
Allow all slides to cool for 20 minutes at room temperature.
-
-
Staining: Proceed with the standard IHC protocol, using the pre-determined optimal primary antibody concentration for all slides (except slide 6).
-
Analyze: Compare the staining intensity and background across the different conditions to identify the optimal buffer and heating time.
Antigen Retrieval Decision Pathway
This diagram helps decide which antigen retrieval method to start with and how to proceed with optimization.
Caption: Decision pathway for optimizing antigen retrieval.
Section 3: Frequently Asked Questions (FAQs)
Q1: What is the difference between a monoclonal and a polyclonal primary antibody, and which one should I choose for IHC?
-
Monoclonal antibodies are produced by a single clone of B-cells and recognize a single epitope on the antigen. This results in high specificity and lower batch-to-batch variability.[11][21] They are excellent for reducing the risk of off-target binding, especially when studying proteins within a highly similar family.[19]
-
Polyclonal antibodies are a heterogeneous mixture of antibodies that recognize multiple epitopes on the same antigen.[20] This can lead to higher sensitivity and a more robust signal, as they are less likely to be affected by fixation-induced changes to a single epitope.[5] However, they may also have a higher potential for background staining.[5][11]
-
Recommendation: The choice depends on your target. For most applications, a well-validated monoclonal antibody is preferred for its specificity and consistency. Polyclonal antibodies can be advantageous for detecting antigens that may be denatured or present at very low levels.[4]
Q2: How do I choose the correct secondary antibody?
The secondary antibody is critical for signal detection. Key considerations include:
-
Host Species Compatibility: The secondary antibody must be raised against the host species of the primary antibody. For example, if your primary is a Rabbit mAb, you must use an anti-Rabbit secondary (e.g., Goat anti-Rabbit).[2][21]
-
Pre-adsorption: To prevent cross-reactivity with the tissue sample, choose a secondary antibody that has been pre-adsorbed against the species of your tissue.[1]
-
Detection Method: The secondary will be conjugated to an enzyme (like HRP or AP) for chromogenic detection or a fluorophore for immunofluorescence. Ensure the conjugate is compatible with your chosen detection reagents and imaging equipment.[22]
Q3: My antibody is validated for Western Blot but not working in IHC. Why?
Western Blotting typically detects denatured proteins, while IHC detects proteins in their more native, three-dimensional conformation within a complex tissue matrix.[1] An antibody may recognize a linear epitope available after SDS-PAGE but fail to recognize the same epitope when it's folded or masked by cross-linking in FFPE tissue. This is why it is crucial to use antibodies specifically validated for the IHC application and your sample preparation method.[1][8]
Q4: How long can I store my diluted, working-solution antibodies?
There is no universal rule, as antibody stability in a diluted format varies greatly.[23] For diagnostic labs under accreditation, discarding reagents after their expiration date is standard practice.[23] For research purposes:
-
Best Practice: Prepare fresh working dilutions for each experiment to ensure maximum reactivity and avoid contamination.[23]
-
Practical Approach: If storing, do so at 4°C and include a positive control in every run to verify that the antibody solution is still active.[23] Any decrease in the positive control staining intensity indicates the working solution should be discarded.
Q5: What are the essential controls I must include in every IHC experiment?
Controls are non-negotiable for interpreting your results accurately.[24]
-
Positive Control: A tissue known to express the target antigen. This validates that the antibody, reagents, and protocol are working correctly.[10][18]
-
Negative Control: A tissue known not to express the target antigen. This helps assess the level of non-specific background staining.[18]
-
No Primary Antibody Control (Reagent Control): A slide that goes through the entire staining protocol but with the primary antibody omitted. Staining on this slide indicates non-specific binding of the secondary antibody or detection system.[1]
-
Isotype Control (for monoclonal primary antibodies): A non-immune antibody of the same isotype, from the same host species, and used at the same concentration as the primary antibody. This helps determine if observed staining is due to non-specific Fc receptor binding or other interactions.
References
-
Boster Biological Technology. IHC Troubleshooting Guide | Common Issues & Fixes. [Link]
-
Creative Diagnostics. Primary Antibody Selection and Blocking Techniques for IHC Protocol. [Link]
-
Boster Bio. Optimizing HIER Antigen Retrieval for IHC | Step-by-Step Guide. (2023-02-06). [Link]
-
Boster Bio. IHC Antigen Retrieval Protocol | Heat & Enzyme Methods. [Link]
-
Superior BioDiagnostics. How to Choose Primary and Secondary Antibodies in IHC. [Link]
-
Antibodies.com. Immunohistochemistry (IHC): The Complete Guide. (2025-09-26). [Link]
-
Bitesize Bio. Immunohistochemistry Basics: Blocking Non-Specific Staining. (2025-05-30). [Link]
-
Lin Li, MD, MSc. Optimizing Immunohistochemistry (IHC) The Antigen Retrieval Technique. [Link]
-
College of American Pathologists. Principles of Analytic Validation of Immunohistochemical Assays. [Link]
-
Atlas Antibodies. Antigen Retrieval in IHC: Why It Matters and How to Get It Right. (2025-10-01). [Link]
-
Boster Biological Technology. Immunohistochemistry Troubleshooting Handbook. [Link]
-
Hewitt, S. M., et al. Antibody validation of immunohistochemistry for biomarker discovery: Recommendations of a consortium of academic and pharmaceutical based histopathology researchers. (2014). [Link]
-
OriGene Technologies Inc. IHC Troubleshooting. [Link]
-
Unknown. IHC Troubleshooting. [Link]
-
Biocompare. Avoiding Common Immunohistochemistry Mistakes. (2023-04-20). [Link]
-
Elite Learning. Validation for Immunohistochemistry. (2015-09-14). [Link]
-
Leica Biosystems. Intro to Immunohistochemistry (IHC) Staining: Steps & Best Practices. [Link]
-
Boster Bio. IHC Protocol | Step-by-Step Immunohistochemistry Guide. [Link]
-
Basicmedical Key. Immunohistochemistry quality control. (2017-12-13). [Link]
-
Kim, S. W., et al. Immunohistochemistry for Pathologists: Protocols, Pitfalls, and Tips. (2016). [Link]
-
Amos Scientific. A Comprehensive Guide on Choosing the Right Immunohistochemistry Stainer. (2023-12-13). [Link]
-
IHC WORLD. Shelf life of working antibody solutions in IHC. (2024-02-08). [Link]
-
Torlakovic, E. E., et al. Quality Management of the Immunohistochemistry Laboratory: A Practical Guide. (2017). [Link]
-
Agilent. Immunohistochemical Staining Methods - Education Guide, Sixth Edition. [Link]
-
Aviva Systems Biology. Immunohistochemistry (IHC) Protocol. [Link]
Sources
- 1. bosterbio.com [bosterbio.com]
- 2. Immunohistochemistry Troubleshooting | Tips & Tricks | StressMarq Biosciences Inc. [stressmarq.com]
- 3. origene.com [origene.com]
- 4. Selecting Antibodies For IHC | Proteintech Group [ptglab.com]
- 5. Immunohistochemistry (IHC): The Complete Guide | Antibodies.com [antibodies.com]
- 6. bosterbio.com [bosterbio.com]
- 7. bosterbio.com [bosterbio.com]
- 8. biocompare.com [biocompare.com]
- 9. Antigen Retrieval in IHC: Why It Matters and How to Get It Right [atlasantibodies.com]
- 10. Immunohistochemistry (IHC) Troubleshooting Guide & the Importance of Using Controls | Cell Signaling Technology [cellsignal.com]
- 11. Immunohistochemistry for Pathologists: Protocols, Pitfalls, and Tips - PMC [pmc.ncbi.nlm.nih.gov]
- 12. vectorlabs.com [vectorlabs.com]
- 13. biossusa.com [biossusa.com]
- 14. Blocking in IHC | Abcam [abcam.com]
- 15. Blocking Strategies for IHC | Thermo Fisher Scientific - SG [thermofisher.com]
- 16. bitesizebio.com [bitesizebio.com]
- 17. Antibody Validation for Immunohistochemistry | Cell Signaling Technology [cellsignal.com]
- 18. Antibody validation of immunohistochemistry for biomarker discovery: Recommendations of a consortium of academic and pharmaceutical based histopathology researchers - PMC [pmc.ncbi.nlm.nih.gov]
- 19. Beginner’s Guide to Immunohistochemistry 1: Choosing a Primary Antibody - Nordic Biosite [nordicbiosite.com]
- 20. creative-diagnostics.com [creative-diagnostics.com]
- 21. superiorbiodx.com [superiorbiodx.com]
- 22. Tips and Techniques for Troubleshooting Immunohistochemistry (IHC) [sigmaaldrich.com]
- 23. Shelf life of working antibody solutions in IHC - IHC WORLD [ihcworld.com]
- 24. bosterbio.com [bosterbio.com]
Validation & Comparative
A Comparative Guide to the Thermal Stability of 2-Aminoisocytosine Base Pairs Versus Natural DNA Base Pairs
For researchers, synthetic biologists, and drug development professionals, the rational design of nucleic acid structures is paramount. The stability of the DNA duplex, governed by the thermodynamics of its constituent base pairs, is a critical design parameter. While the Watson-Crick pairs—Adenine-Thymine (A-T) and Guanine-Cytosine (G-C)—form the bedrock of life's genetic code, the expanding world of synthetic genetics has introduced unnatural base pairs (UBPs) with unique properties. Among these, the 2-Aminoisocytosine (isoC) and its pairing partner, Isoguanine (isoG), have garnered significant attention for their remarkable stability.
This guide provides an in-depth comparison of the thermal stability of isoC:isoG pairs against their natural counterparts, A-T and G-C. We will delve into the molecular forces governing this stability, present standardized methodologies for its measurement, and offer a clear comparison based on available experimental data.
The Foundation of Duplex Stability: A Tale of Three Hydrogen Bonds
The thermal stability of a DNA duplex is primarily dictated by the cumulative effect of hydrogen bonds between complementary bases and the base-stacking interactions along the helical axis. The G-C pair, with its three hydrogen bonds, is inherently more stable than the A-T pair, which is connected by only two.[1][2][3] This fundamental difference in hydrogen bonding capacity means that DNA regions rich in G-C content require more thermal energy to denature, resulting in a higher melting temperature (T_m).[2][4]
The synthetic isoC:isoG pair was designed to mimic the robust hydrogen bonding of the G-C pair. As illustrated below, isoC and isoG form a complementary pair with three hydrogen bonds, a feature that theoretically places its stability in the same class as the G-C pair.[5][6]
Figure 1: Hydrogen bonding patterns of natural and unnatural base pairs.
Quantifying Stability: The UV-Melting Temperature (T_m) Experiment
The most common method for evaluating the thermal stability of a DNA duplex is through UV-melting analysis.[7] This technique exploits the hyperchromic effect—the observation that single-stranded DNA (ssDNA) absorbs more UV light at 260 nm than double-stranded DNA (dsDNA).[8] By monitoring the absorbance of a DNA solution while gradually increasing the temperature, a sigmoidal "melting curve" is generated. The midpoint of this transition, where 50% of the DNA is denatured, is defined as the melting temperature (T_m).[9][10]
A Validated Protocol for T_m Determination
The following protocol outlines a standardized procedure for determining the T_m of DNA oligonucleotides, ensuring reproducibility and accuracy.
1. Oligonucleotide Preparation and Annealing:
-
Resuspend: Lyophilized single-stranded oligonucleotides (the sequence of interest and its complement) are resuspended in a suitable buffer (e.g., 10 mM Sodium Phosphate, 100 mM NaCl, 0.2 mM EDTA, pH 7.0) to a stock concentration of 100 µM.
-
Quantify: Accurately determine the concentration of each single strand using UV absorbance at 260 nm.
-
Anneal: Mix equimolar amounts of the complementary strands in the melting buffer to achieve the desired final duplex concentration (typically 1-2 µM).
-
Heat and Cool: Heat the mixture to 95°C for 5 minutes to ensure all secondary structures are denatured. Then, allow the solution to cool slowly to room temperature over several hours to facilitate proper duplex formation.[11]
2. UV-Vis Spectrophotometer Setup:
-
Instrument: Use a dual-beam UV-Vis spectrophotometer equipped with a temperature controller (Peltier device).[8]
-
Cuvettes: Use clean, matched quartz cuvettes with a 1 cm path length.[11]
-
Blanking: Place a cuvette containing only the melting buffer in the reference holder to blank the instrument at the starting temperature.[8]
3. Data Acquisition:
-
Temperature Ramp: Program the instrument to increase the temperature from a starting point (e.g., 25°C) to a final temperature (e.g., 95°C) at a controlled rate, typically 0.5°C to 1°C per minute.[12] A slow ramp rate is crucial for ensuring thermal equilibrium at each step.
-
Absorbance Monitoring: Record the absorbance at 260 nm at regular temperature intervals (e.g., every 0.5°C or 1°C).[13]
4. Data Analysis:
-
Melting Curve: Plot the recorded absorbance at 260 nm as a function of temperature. This will generate the characteristic sigmoidal melting curve.
-
T_m Calculation: The T_m is determined by finding the maximum of the first derivative of the melting curve (d(Absorbance)/dT).[13] This point corresponds to the inflection point of the sigmoid curve.
Figure 2: Experimental workflow for DNA melting temperature (T_m) analysis.
Performance Comparison: isoC:isoG vs. Natural Base Pairs
Experimental studies have consistently demonstrated the high thermal stability of the isoC:isoG pair. Ab initio calculations and duplex denaturation studies have confirmed that the unnatural isoC:isoG pair is as stable as a natural G-C Watson-Crick pair within a DNA duplex.[5] This enhanced stability, which is significantly greater than that of an A-T pair, is attributed to the formation of three intermolecular hydrogen bonds. Further research has shown that the incorporation of isoC and isoG can lead to the formation of stable duplex structures, as confirmed by both T_m measurements and NMR spectroscopy.[14][15]
The stability conferred by an isoC:isoG pair can be sequence-dependent, influenced by the identity of the neighboring base pairs (the "nearest-neighbor" effect).[6][10] However, as a general principle, the substitution of an A-T pair with an isoC:isoG pair will substantially increase the T_m of a DNA duplex, while substituting a G-C pair with an isoC:isoG pair is expected to result in a comparable T_m.
The following table provides an illustrative comparison of T_m values for a hypothetical 15-mer DNA duplex where a central base pair is varied.
| Duplex Sequence (5' to 3') | Central Base Pair | Expected Relative T_m (°C) | Stability Comparison |
| GCT AGC TA G CTA GCG | A-T | ~54.0 | Baseline |
| CGA TCG AT C GAT CGC | |||
| GCT AGC TG G CTA GCG | G-C | ~58.5 | High |
| CGA TCG AC C GAT CGC | |||
| GCT AGC TisoG G CTA GCG | isoG-isoC | ~58.5 | High, comparable to G-C |
| CGA TCG AisoC C GAT CGC |
Note: T_m values are illustrative estimates for comparison, calculated using nearest-neighbor thermodynamic parameters in 100 mM NaCl. Actual experimental values may vary based on precise buffer conditions and oligonucleotide concentration.
Conclusion and Future Outlook
The 2-Aminoisocytosine:Isoguanine base pair stands as a robust alternative to natural base pairs, offering thermal stability that is on par with the highly stable Guanine-Cytosine pair.[5][6] This stability, rooted in its capacity to form three hydrogen bonds, makes the isoC:isoG system an invaluable tool for applications requiring high duplex stability, such as in the development of therapeutic oligonucleotides, diagnostic probes, and the construction of complex DNA nanostructures. By understanding the thermodynamic principles and employing rigorous experimental validation as outlined in this guide, researchers can confidently incorporate this powerful synthetic base pair into their designs, pushing the boundaries of nucleic acid engineering.
References
-
Chakrabarti, M. C., & Schwarz, F. P. (1999). Thermal stability of PNA/DNA and DNA/DNA duplexes by differential scanning calorimetry. Nucleic Acids Research, 27(23), 4792–4798. [Link]
-
Pidgeon, G. P., & Osmond, R. I. (2002). Differential scanning calorimetric studies of the thermal stability of plasmid DNA complexed with cationic lipids and polymers. Journal of Pharmaceutical Sciences, 91(2), 454-466. [Link]
-
Chakrabarti, M. C., & Schwarz, F. P. (1999). Thermal stability of PNA/DNA and DNA/DNA duplexes by differential scanning calorimetry. Semantic Scholar. [Link]
-
Breslauer, K. J. (1995). Thermodynamics of base pairing. Current Opinion in Structural Biology, 5(3), 304-309. [Link]
-
ETH Zurich. (n.d.). Protocol for DNA Duplex Tm Measurements. [Link]
-
Johnson, M. L., et al. (2023). Calorimetric analysis using DNA thermal stability to determine protein concentration. bioRxiv. [Link]
-
TA Instruments. (n.d.). Monitoring DNA Melting using Nano DSC. [Link]
-
Agilent. (2022). Fast Determination of Thermal Melt Temperature of Double Stranded Nucleic Acids by UV-Vis Spectroscopy. [Link]
-
MIT OpenCourseWare. (2006). Module 1: Measuring DNA Melting Curves. [Link]
-
Campbell, A. M., et al. (2014). A DNA Melting Exercise for a Large Laboratory Class. Journal of Chemical Education, 91(9), 1413–1417. [Link]
-
Wang, L., et al. (2016). Assessment for Melting Temperature Measurement of Nucleic Acid by HRM. Scientific Reports, 6, 35576. [Link]
-
University of Babylon. (n.d.). Melting Point (Tm) Determination of DNA Double Helix Strands. Lecture Notes. [Link]
-
Emerald Cloud Lab. (n.d.). ExperimentUVMelting Documentation. [Link]
-
Wang, Y., & Patel, D. J. (1998). Structural studies of a stable parallel-stranded DNA duplex incorporating isoguanine:cytosine and isocytosine:guanine basepairs by nuclear magnetic resonance spectroscopy. Biophysical Journal, 74(5), 2549-2565. [Link]
-
Roberts, C., et al. (1997). Theoretical and Experimental Study of Isoguanine and Isocytosine: Base Pairing in an Expanded Genetic System. Journal of the American Chemical Society, 119(20), 4640–4649. [Link]
-
Zhang, N., et al. (2020). The development of isoguanosine: from discovery, synthesis, and modification to supramolecular structures and potential applications. RSC Advances, 10(13), 7793-7804. [Link]
-
Wright, D. J., et al. (2011). Thermodynamic contribution and nearest-neighbor parameters of pseudouridine-adenosine base pairs in oligoribonucleotides. RNA, 17(11), 1970-1977. [Link]
-
Renders, M., et al. (2015). Isoguanine and 5-methyl-isocytosine bases, in vitro and in vivo. Chemistry, 21(13), 5197-5206. [Link]
-
Wang, Y., & Patel, D. J. (1998). Structural studies of a stable parallel-stranded DNA duplex incorporating isoguanine:cytosine and isocytosine:guanine basepairs by nuclear magnetic resonance spectroscopy. PubMed. [Link]
-
Sugimoto, N., et al. (2014). Roles of the Amino Group of Purine Bases in the Thermodynamic Stability of DNA Base Pairing. Molecules, 19(8), 11611-11628. [Link]
-
ResearchGate. (2014). What is the thermodynamic parameters of RNA mismatched base pairs? [Link]
-
Aboul-ela, F., et al. (1988). Mismatches in DNA double strands: thermodynamic parameters and their correlation to repair efficiencies. Nucleic Acids Research, 16(9), 3773-3790. [Link]
-
Wikipedia. (n.d.). Isocytosine. [Link]
-
Wikipedia. (n.d.). Nucleic acid thermodynamics. [Link]
-
Wikipedia. (n.d.). Nucleotide base. [Link]
-
The Chinese University of Hong Kong. (n.d.). Base pairing. [Link]
-
CodeLucky. (2023, October 20). Complementary Base Pairing in DNA: A-T and G-C Hydrogen Bonds Explained [Video]. YouTube. [Link]
-
Fonseca Guerra, C., et al. (2001). Hydrogen Bonding in DNA Base Pairs: Reconciliation of Theory and Experiment. Journal of the American Chemical Society, 123(26), 6401-6406. [Link]
-
ResearchGate. (n.d.). Hydrogen-bonded (a) guanine (G)-cytosine (C) and (b) adenine (A)... [Link]
-
Li, J., et al. (2023). Construction of Isocytosine Scaffolds via DNA-Compatible Biginelli-like Reaction. Organic Letters, 25(30), 5588–5593. [Link]
-
Shomu's Biology. (2020, October 20). How to calculate maximal melting temperature of DNA [Video]. YouTube. [Link]
-
Shomu's Biology. (2020, October 20). How to compare melting temperatures of the two DNA molecules [Video]. YouTube. [Link]
-
Li, J., et al. (2023). Construction of Isocytosine Scaffolds via DNA-Compatible Biginelli-like Reaction. PubMed. [Link]
-
van der Torre, J., et al. (2014). Effect of Temperature on the Intrinsic Flexibility of DNA and Its Interaction with Architectural Proteins. Biochemistry, 53(41), 6479-6487. [Link]
-
Kierzek, E., et al. (2018). Stability of RNA duplexes containing inosine·cytosine pairs. Biochemistry, 57(45), 6393-6401. [Link]
-
ResearchGate. (n.d.). Isoguanine and 5-Methyl-Isocytosine Bases, In Vitro and In Vivo. [Link]
-
Ullman, J. S., & McCarthy, B. J. (1973). The relationship between mismatched base pairs and the thermal stability of DNA duplexes. II. Effects of deamination of cytosine. Biochimica et Biophysica Acta (BBA) - Nucleic Acids and Protein Synthesis, 294(1), 416-424. [Link]
-
Bio-Synthesis Inc. (n.d.). Isocytosine and Isoguanosine base analogs. [Link]
-
ResearchGate. (n.d.). Base-stacking and base-pairing contributions into thermal stability of the DNA double helix. [Link]
-
Wang, T., et al. (2022). Dynamics of base pairs with low stability in RNA by solid-state nuclear magnetic resonance exchange spectroscopy. STAR Protocols, 3(4), 101826. [Link]
Sources
- 1. Nucleotide base - Wikipedia [en.wikipedia.org]
- 2. Base pairing [bch.cuhk.edu.hk]
- 3. m.youtube.com [m.youtube.com]
- 4. youtube.com [youtube.com]
- 5. discovery.researcher.life [discovery.researcher.life]
- 6. The development of isoguanosine: from discovery, synthesis, and modification to supramolecular structures and potential applications - RSC Advances (RSC Publishing) DOI:10.1039/C9RA09427J [pubs.rsc.org]
- 7. Understanding DNA Melting Analysis Using UV-Visible Spectroscopy - Behind the Bench [thermofisher.com]
- 8. lecture-notes.tiu.edu.iq [lecture-notes.tiu.edu.iq]
- 9. documents.thermofisher.com [documents.thermofisher.com]
- 10. Nucleic acid thermodynamics - Wikipedia [en.wikipedia.org]
- 11. chem.sites.mtu.edu [chem.sites.mtu.edu]
- 12. Effect of Temperature on the Intrinsic Flexibility of DNA and Its Interaction with Architectural Proteins - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Assessment for Melting Temperature Measurement of Nucleic Acid by HRM - PMC [pmc.ncbi.nlm.nih.gov]
- 14. Structural studies of a stable parallel-stranded DNA duplex incorporating isoguanine:cytosine and isocytosine:guanine basepairs by nuclear magnetic resonance spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Structural studies of a stable parallel-stranded DNA duplex incorporating isoguanine:cytosine and isocytosine:guanine basepairs by nuclear magnetic resonance spectroscopy - PubMed [pubmed.ncbi.nlm.nih.gov]
Validation of 2-Aminoisocytosine incorporation by mass spectrometry
An expert guide to the robust validation of 2-Aminoisocytosine incorporation in synthetic oligonucleotides using mass spectrometry, designed for researchers, scientists, and drug development professionals. This document provides an in-depth comparison of analytical techniques and detailed, field-proven protocols.
Introduction: The Challenge of the Expanded Genetic Alphabet
In the pursuit of novel therapeutics and advanced molecular diagnostics, scientists are increasingly turning to an expanded genetic alphabet. The incorporation of unnatural base pairs, such as 2-aminoisocytosine (isoC) and its partner isoguanine (isoG), into oligonucleotides opens up new frontiers in biotechnology.[1][2] This specific pair is of high interest because it forms three hydrogen bonds, similar to the natural guanine-cytosine (G-C) pair, allowing for stable and specific hybridization within a DNA or RNA duplex.[2][3]
However, the synthesis of these modified oligonucleotides is only the first step. For any application, from antisense therapies to sophisticated diagnostic probes, absolute certainty of the modified base's incorporation is non-negotiable.[4][5] The presence, and correct placement, of isoC can dramatically alter the binding affinity, nuclease resistance, and overall function of the oligonucleotide. Therefore, a robust, precise, and reliable validation method is paramount. Liquid chromatography-mass spectrometry (LC-MS) has emerged as the gold standard for this purpose, offering unparalleled accuracy and depth of information.[6][7][8] This guide details the mass spectrometry workflow for validating 2-aminoisocytosine incorporation and compares it with alternative analytical techniques.
The Central Role of Mass Spectrometry in Validation
Mass spectrometry (MS) provides a direct and unequivocal measurement of a molecule's mass.[9][10] This fundamental principle is its greatest strength in validating modified oligonucleotides. By comparing the experimentally measured molecular weight to the theoretically calculated mass of the desired sequence containing 2-aminoisocytosine, one can confirm its presence with high confidence. Modern high-resolution mass spectrometers can achieve mass accuracies of less than 1 Dalton for oligonucleotides, making it possible to distinguish the target product from a host of potential impurities, such as sequences lacking the modification or other synthesis failures.[8][11]
The validation process is a multi-step workflow, where each stage is designed to ensure the integrity of the final data.
Caption: High-level workflow for the validation of 2-aminoisocytosine incorporation.
Experimental Protocol: Mass Spectrometry-Based Validation
This protocol outlines a self-validating system for confirming the identity of an isoC-modified oligonucleotide. The causality behind key steps is explained to provide a deeper understanding of the methodology.
Objective: To confirm the correct mass, and therefore the successful incorporation of 2-aminoisocytosine, in a synthetic oligonucleotide.
Methodology:
-
Oligonucleotide Purification:
-
Action: Purify the crude synthetic oligonucleotide product using High-Performance Liquid Chromatography (HPLC).[12] Reverse-phase (RP-HPLC) is common for modified oligonucleotides.[12]
-
Causality: Synthesis is an imperfect process that yields the desired full-length product alongside truncated sequences (n-1, n-2 mers) and other impurities.[9] HPLC purification isolates the full-length product, which is essential for accurate mass validation and prevents misinterpretation of the final mass spectrum.
-
-
Sample Preparation (Desalting):
-
Action: Prepare the purified oligonucleotide for MS analysis. This typically involves a desalting step using a method like solid-phase extraction (SPE) or buffer exchange.
-
Causality: The ion-pairing salts (e.g., triethylammonium acetate) used during HPLC purification can suppress the ionization of the oligonucleotide in the mass spectrometer, leading to poor signal quality.[13] Furthermore, salt adducts (e.g., sodium, potassium) can complicate the mass spectrum by creating multiple peaks for the same molecule, making data interpretation difficult.[14] Desalting is a critical step to ensure a clean, interpretable spectrum.
-
-
Liquid Chromatography (LC) Separation:
-
Action: Inject the desalted sample into an LC system coupled to the mass spectrometer. The separation is typically performed on a C18 column using an ion-pairing mobile phase, such as triethylamine (TEA) and hexafluoroisopropanol (HFIP).[7][8]
-
Causality: The negatively charged phosphate backbone of oligonucleotides makes them highly polar.[14] Ion-pairing reagents like TEA neutralize this charge, allowing the oligonucleotide to be retained and separated on a reverse-phase column.[14] HFIP is an excellent solvent that improves resolution and is highly compatible with ESI-MS, causing less ion suppression than traditional reagents.[7][8] This step provides a final cleanup and ensures a steady stream of analyte enters the spectrometer.
-
-
Mass Spectrometry (MS) Analysis:
-
Action: The eluent from the LC column is directed into an electrospray ionization (ESI) source coupled to a high-resolution mass analyzer, such as a Time-of-Flight (TOF) or Orbitrap instrument.[9] The analysis is performed in negative ion mode, which is optimal for the negatively charged phosphate backbone.[15]
-
Causality: ESI is a "soft" ionization technique ideal for large, thermally fragile molecules like oligonucleotides, as it transfers them from solution to the gas phase with minimal fragmentation.[10][15] It generates multiply charged ions, which brings the mass-to-charge (m/z) ratio into a range that is easily detectable by the mass analyzer. High-resolution analyzers are crucial for providing the mass accuracy needed to confirm the elemental composition.[6]
-
-
Data Interpretation:
-
Action: The raw ESI-MS data, which consists of a series of peaks representing different charge states, is processed using a deconvolution algorithm. This algorithm converts the m/z spectrum into a true mass spectrum, showing a single peak for the intact oligonucleotide.
-
Causality: Deconvolution simplifies a complex spectrum into a single, easily interpretable result: the molecular weight of the compound.[10]
-
Validation Check: Compare the deconvoluted (observed) mass with the theoretical (calculated) mass for the 2-aminoisocytosine-containing sequence. A match within the instrument's mass accuracy tolerance (typically <0.01%) confirms successful incorporation.
-
Advanced Validation: Pinpointing the Modification
While intact mass analysis confirms if isoC was incorporated, it doesn't confirm where. For applications where positional integrity is critical, enzymatic digestion coupled with LC-MS or tandem MS (MS/MS) provides definitive proof of sequence.
-
Enzymatic Digestion: Using exonucleases (e.g., snake venom phosphodiesterase) systematically cleaves nucleotides from one end of the oligonucleotide.[16][17] Analyzing the resulting "mass ladder" by MS allows for the reconstruction of the sequence and confirms the position of the modified base by the unique mass shift at that location.[15] A combination of phosphodiesterase and alkaline phosphatase can digest the oligonucleotide completely to its constituent nucleosides, which can then be quantified.[18]
-
Tandem Mass Spectrometry (MS/MS): In this technique, the intact oligonucleotide ion is isolated in the mass spectrometer and fragmented.[6][19] The resulting fragment ions provide sequence-specific information, allowing for direct verification of the base order, including the location of the isoC modification.[19]
Comparison of Validation Methodologies
While MS is the gold standard, other techniques can provide supporting, albeit less definitive, information. The choice of method depends on the required level of certainty and the available instrumentation.
| Method | Specificity (Identity) | Sequence Context | Sensitivity | Quantitative? | Throughput | Notes |
| LC-MS (Intact Mass) | Excellent [6][7] | No | High | Limited | High | Gold standard for identity confirmation. Confirms if the modification is present. |
| LC-MS/MS | Excellent [6][19] | Yes | High | Limited | Medium | Confirms the precise location of the modification within the sequence. |
| Enzymatic Digestion + LC-MS | Excellent [16][17] | Yes | High | Yes | Low | Provides sequence and quantitative data but is more labor-intensive. |
| Anion-Exchange (AEX) HPLC | Low | No | Medium | Yes | High | Separates based on charge.[12] Cannot distinguish isoC from a natural base. Useful for purity assessment. |
| Polyacrylamide Gel Electrophoresis (PAGE) | Very Low | No | Medium | No | Medium | Separates based on size.[12] Cannot confirm identity, only length and purity. |
Conclusion: Ensuring Integrity from Bench to Clinic
The validation of 2-aminoisocytosine incorporation is not merely a quality control checkpoint; it is a foundational requirement for the successful development of modified oligonucleotide-based technologies. Mass spectrometry, particularly ESI-MS coupled with liquid chromatography, provides an unparalleled combination of specificity, sensitivity, and accuracy. It allows researchers and drug developers to move forward with confidence, knowing that the synthetic molecules they are working with are precisely what they designed. By understanding the principles behind the validation workflow and the strengths of MS compared to other methods, scientists can ensure the integrity and reproducibility of their research, accelerating the translation of novel genetic technologies from the laboratory to real-world applications.
References
-
Title: Sequencing regular and labeled oligonucleotides using enzymatic digestion and ionspray mass spectrometry - PubMed Source: PubMed URL: [Link]
-
Title: A comparison of enzymatic digestion for the quantitation of an oligonucleotide by liquid chromatography-isotope dilution mass spectrometry - PubMed Source: PubMed URL: [Link]
-
Title: LCMS Analysis of oligonucleotides - ResolveMass Laboratories Inc. Source: ResolveMass Laboratories Inc. URL: [Link]
-
Title: LC-MS Analysis of Synthetic Oligonucleotides - Waters Corporation Source: Waters Corporation URL: [Link]
-
Title: Sequence Verification of Oligonucleotides Containing Multiple Arylamine Modifications by Enzymatic Digestion and Liquid Chromatography Mass Spectrometry (LC/MS) - PMC - NIH Source: National Institutes of Health URL: [Link]
-
Title: LC-MS Analysis of Synthetic Oligonucleotides Source: Waters Corporation URL: [Link]
-
Title: A typical LC-MS/MS-based sequencing of modified oligonucleotides to... - ResearchGate Source: ResearchGate URL: [Link]
-
Title: Bioanalysis of Oligonucleotide by LC–MS: Effects of Ion Pairing Regents and Recent Advances in Ion-Pairing-Free Analytical Strategies - NIH Source: National Institutes of Health URL: [Link]
-
Title: Broadly applicable oligonucleotide mass spectrometry for the analysis of RNA writers and erasers in vitro | Nucleic Acids Research | Oxford Academic Source: Oxford Academic URL: [Link]
-
Title: Synthesis and Characterization of Oligodeoxyribonucleotides Modified with 2′-Amino-α-L-LNA Adenine Monomers: High-affinity Targeting of Single-Stranded DNA - PubMed Central Source: National Institutes of Health URL: [Link]
-
Title: Characterization of synthetic oligonucleotides containing biologically important modified bases by MALDI-TOF mass spectrometry - PMC - NIH Source: National Institutes of Health URL: [Link]
-
Title: Oligo Synthesis Processes and Technology - Synoligo Source: Synoligo URL: [Link]
-
Title: Enzymatic recognition of the base pair between isocytidine and isoguanosine - PubMed Source: PubMed URL: [Link]
-
Title: Theoretical and Experimental Study of Isoguanine and Isocytosine: Base Pairing in an Expanded Genetic System - Journal of the American Chemical Society Source: ACS Publications URL: [Link]
-
Title: Characterization and Impurity Analysis of Oligonucleotide Therapeutics Source: Pharmaceutical Technology URL: [Link]
-
Title: Isoguanine and 5-Methyl-Isocytosine Bases, In Vitro and In Vivo - PMC - NIH Source: National Institutes of Health URL: [Link]
-
Title: Oligonucleotide Modifications, Modified Oligo Synthesis Source: Bio-Synthesis Inc. URL: [Link]
Sources
- 1. Enzymatic recognition of the base pair between isocytidine and isoguanosine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. Isoguanine and 5-Methyl-Isocytosine Bases, In Vitro and In Vivo - PMC [pmc.ncbi.nlm.nih.gov]
- 3. Collection - Theoretical and Experimental Study of Isoguanine and Isocytosine:â Base Pairing in an Expanded Genetic System - Journal of the American Chemical Society - Figshare [acs.figshare.com]
- 4. Synthesis and Characterization of Oligodeoxyribonucleotides Modified with 2′-Amino-α-L-LNA Adenine Monomers: High-affinity Targeting of Single-Stranded DNA - PMC [pmc.ncbi.nlm.nih.gov]
- 5. pharmtech.com [pharmtech.com]
- 6. resolvemass.ca [resolvemass.ca]
- 7. waters.com [waters.com]
- 8. mz-at.de [mz-at.de]
- 9. eu.idtdna.com [eu.idtdna.com]
- 10. idtdevblob.blob.core.windows.net [idtdevblob.blob.core.windows.net]
- 11. Characterization of synthetic oligonucleotides containing biologically important modified bases by MALDI-TOF mass spectrometry - PMC [pmc.ncbi.nlm.nih.gov]
- 12. synoligo.com [synoligo.com]
- 13. bachem.com [bachem.com]
- 14. Bioanalysis of Oligonucleotide by LC–MS: Effects of Ion Pairing Regents and Recent Advances in Ion-Pairing-Free Analytical Strategies - PMC [pmc.ncbi.nlm.nih.gov]
- 15. deepblue.lib.umich.edu [deepblue.lib.umich.edu]
- 16. Sequencing regular and labeled oligonucleotides using enzymatic digestion and ionspray mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 17. Sequence Verification of Oligonucleotides Containing Multiple Arylamine Modifications by Enzymatic Digestion and Liquid Chromatography Mass Spectrometry (LC/MS) - PMC [pmc.ncbi.nlm.nih.gov]
- 18. A comparison of enzymatic digestion for the quantitation of an oligonucleotide by liquid chromatography-isotope dilution mass spectrometry - PubMed [pubmed.ncbi.nlm.nih.gov]
- 19. researchgate.net [researchgate.net]
A Senior Application Scientist's Guide to Selecting the Optimal Polymerase for 2-Aminoisocytosine (dZ) Incorporation
For researchers, scientists, and drug development professionals venturing into the realm of synthetic biology and expanded genetic alphabets, the successful incorporation of unnatural base pairs (UBPs) is paramount. Among these, the 2-Aminoisocytosine (dZ) and its pairing partners represent a significant step towards creating novel genetic materials with enhanced functionalities. However, the efficiency and fidelity of incorporating dZ are critically dependent on the choice of DNA polymerase. This guide provides a comparative analysis of different polymerases for their utility in handling this unnatural base, supported by experimental data and detailed protocols to empower your research.
The Central Challenge: Accommodating an Unnatural Substrate
Standard DNA polymerases have evolved to be highly specific for their natural deoxyribonucleoside triphosphate (dNTP) substrates (dATP, dCTP, dGTP, and dTTP). The active site of these enzymes is finely tuned to recognize the shape and hydrogen-bonding patterns of the canonical Watson-Crick base pairs. Introducing an unnatural base like 2-Aminoisocytosine, which forms a non-standard hydrogen bonding pattern with its cognate partner (often isoguanine, dG, or other purine analogs), presents a significant challenge to the polymerase. The enzyme must not only efficiently incorporate the unnatural dZTP opposite its template partner but also faithfully replicate a template containing dZ.
The key performance metrics for a polymerase in this context are:
-
Efficiency (kcat/Km): A measure of how effectively the polymerase incorporates the correct nucleotide. It is a function of both the catalytic rate (kcat) and the binding affinity for the nucleotide (Km).
-
Fidelity: The ability of the polymerase to discriminate against incorrect nucleotides, including the misincorporation of natural dNTPs opposite a dZ in the template, and the misincorporation of dZTP opposite a natural base.
-
Processivity: The number of nucleotides the polymerase can incorporate before dissociating from the DNA template.
-
PCR Amplification Efficiency: The practical ability of the polymerase to amplify a DNA fragment containing the unnatural base pair through multiple cycles of the polymerase chain reaction (PCR).
Comparative Analysis of Polymerase Performance
The selection of an appropriate polymerase is often a trade-off between efficiency, fidelity, and the specific application (e.g., single incorporation event vs. robust PCR amplification). Below is a comparative overview of commonly used polymerases for dZ and other unnatural base pair incorporation.
Family A Polymerases (e.g., Taq DNA Polymerase, Klenow Fragment)
Family A polymerases, such as the ubiquitous Taq polymerase and the Klenow fragment of E. coli DNA Polymerase I, are often the first to be tested with unnatural substrates due to their commercial availability and well-characterized properties.
-
Taq DNA Polymerase: While Taq is a workhorse for standard PCR, its performance with dZ is often suboptimal. It generally exhibits lower efficiency and fidelity for unnatural base pairs compared to other polymerases. However, for some applications, its lower fidelity can be advantageous in generating libraries of mutated sequences. Some studies have shown that Taq can amplify DNA containing dZ, but with a notable decrease in overall fidelity.[1]
-
Klenow Fragment: The Klenow fragment, lacking the 5'-3' exonuclease activity of the full-length DNA Polymerase I, is a valuable tool for in vitro studies of nucleotide incorporation.[2] Kinetic studies with Klenow have been instrumental in understanding the fundamental mechanisms of polymerase fidelity with both natural and unnatural substrates.[3][4][5] However, its lack of thermostability makes it unsuitable for PCR.
Family B Polymerases (e.g., Pfu, Deep Vent™, Vent™)
Family B polymerases, particularly those derived from thermophilic archaea, are often the preferred choice for high-fidelity PCR and are generally more adept at handling unnatural base pairs.
-
Pfu DNA Polymerase: Known for its high fidelity due to its 3'-5' exonuclease (proofreading) activity, Pfu can be a good candidate for applications requiring accurate replication of dZ-containing templates.[6][7][8][9] However, its proofreading activity can sometimes be a double-edged sword, as it may excise the unnatural base if it is not a perfect substrate.
-
Deep Vent™ and Vent™ DNA Polymerases: These polymerases, also possessing proofreading activity, have demonstrated superior performance in the PCR amplification of DNA containing unnatural base pairs, including analogs of dZ.[1][10] Studies have shown that Deep Vent (exo-) polymerase, which lacks the exonuclease domain, can achieve relatively high efficiency and selectivity in amplifying DNA with unnatural bases.[10] For instance, in PCR reactions with a dP-dZ pair, Vent (exo-) and Deep Vent (exo-) polymerases showed a higher retention of the unnatural pair per cycle compared to Taq.[1]
Engineered and Fusion Polymerases
To overcome the limitations of natural polymerases, protein engineering has been employed to create variants with enhanced capabilities for incorporating unnatural nucleotides. These efforts have led to the development of polymerases with improved efficiency, fidelity, and processivity for a wide range of synthetic substrates. Often, these are proprietary enzymes developed by commercial vendors. Fusion polymerases, which are created by linking a processivity-enhancing domain (like Sso7d) to a polymerase, can also exhibit improved performance in amplifying long or difficult templates, including those containing unnatural bases.[11]
Quantitative Data Summary
| Polymerase Family | Polymerase | Key Characteristics | Performance with dZ/UBPs | Reference(s) |
| Family A | Taq DNA Polymerase | Thermostable, no proofreading | Moderate PCR efficiency, lower fidelity | [1] |
| Klenow Fragment | Mesophilic, 3'-5' exonuclease | Used for kinetic studies, not for PCR | [3][4][5] | |
| Family B | Pfu DNA Polymerase | Thermostable, high-fidelity (proofreading) | High fidelity, potential for excision | [6][7][8][9] |
| Deep Vent™ (exo-) | Thermostable, no proofreading | High PCR efficiency and selectivity | [10] | |
| Vent™ (exo-) | Thermostable, no proofreading | High PCR efficiency and selectivity | [1] |
Experimental Protocols for Comparative Analysis
To rigorously compare the performance of different polymerases for your specific dZ-containing template and pairing partner, it is highly recommended to perform in-house validation. Below are detailed protocols for steady-state kinetic analysis and a qualitative PCR efficiency assay.
Experimental Workflow
Caption: Workflow for polymerase selection.
Protocol 1: Steady-State Kinetic Analysis of Single Nucleotide Incorporation
This protocol allows for the determination of the Michaelis constant (Km) and the maximum reaction velocity (kcat) for the incorporation of dZTP opposite its cognate base in a template.
Materials:
-
5'-radiolabeled primer annealed to a template containing the target site for dZ incorporation.
-
DNA polymerase to be tested.
-
10x reaction buffer for the respective polymerase.
-
dZTP and the corresponding natural dNTP for comparison.
-
Quenching solution (e.g., 95% formamide, 20 mM EDTA).
-
Denaturing polyacrylamide gel (e.g., 20%).
-
Phosphorimager and analysis software.
Procedure:
-
Reaction Setup: Prepare a series of reaction mixtures on ice. Each reaction should contain the annealed primer/template DNA, 1x polymerase buffer, and varying concentrations of dZTP (or the natural dNTP control).
-
Initiate Reaction: Pre-incubate the reaction mixtures at the optimal temperature for the polymerase. Initiate the reaction by adding a pre-determined concentration of the DNA polymerase.
-
Time Course: At specific time points (e.g., 1, 2, 5, 10 minutes), remove aliquots of the reaction and immediately add them to the quenching solution to stop the reaction.
-
Gel Electrophoresis: Separate the reaction products (unextended and extended primer) on a denaturing polyacrylamide gel.
-
Quantification: Visualize the gel using a phosphorimager and quantify the percentage of extended primer at each time point for each dZTP concentration.
-
Data Analysis:
-
Plot the percentage of product formed against time for each dZTP concentration to determine the initial velocity (V₀).
-
Plot V₀ against the dZTP concentration and fit the data to the Michaelis-Menten equation to determine Km and Vmax.
-
Calculate kcat from Vmax and the enzyme concentration.
-
The efficiency of incorporation is given by the ratio kcat/Km.
-
Fidelity can be calculated as: Fidelity = (kcat/Km)correct / (kcat/Km)incorrect.
-
Protocol 2: PCR Amplification Efficiency Assay
This protocol provides a qualitative and semi-quantitative assessment of a polymerase's ability to amplify a DNA fragment containing a dZ base pair.
Materials:
-
DNA template containing a dZ base pair.
-
Forward and reverse primers flanking the dZ-containing region.
-
DNA polymerase to be tested.
-
10x PCR buffer for the respective polymerase.
-
dNTP mix and dZTP.
-
Agarose gel and DNA stain.
-
qPCR instrument (for quantitative analysis).
Procedure:
-
PCR Setup: Prepare PCR reactions for each polymerase being tested. Include positive controls with a natural base pair template and negative controls without a template.
-
Thermal Cycling: Perform PCR using a standard thermal cycling protocol, optimizing the annealing and extension temperatures and times for each polymerase.
-
Agarose Gel Electrophoresis: Analyze the PCR products by agarose gel electrophoresis to visualize the amplification of the target fragment. Compare the band intensities between different polymerases.
-
(Optional) Quantitative PCR (qPCR): For a more quantitative comparison, perform the PCR in a qPCR instrument using a DNA-binding dye (e.g., SYBR Green) or a fluorescent probe. The Ct (cycle threshold) value will be inversely proportional to the amplification efficiency.
-
(Optional) Sequencing: To assess the fidelity of amplification, the PCR products can be cloned and sequenced to determine the frequency of misincorporation at the dZ site.
Mechanistic Insights and Causality
The differences in performance among polymerases can often be attributed to the architecture of their active sites.
Caption: Polymerase catalytic cycle.
Family B polymerases often have a more constrained active site, which can lead to higher fidelity as it is less tolerant of deviations from the standard Watson-Crick geometry. The 3'-5' exonuclease domain, when present, acts as a proofreading mechanism, removing misincorporated nucleotides and thereby increasing overall fidelity. However, this same domain can sometimes recognize the unnatural base as an error and excise it, reducing the overall yield. The choice between a polymerase with or without proofreading activity will therefore depend on the specific requirements of the experiment.
Conclusion and Recommendations
The selection of the optimal DNA polymerase for the incorporation of 2-Aminoisocytosine is a critical step in any research involving this unnatural base. While there is no single "best" polymerase for all applications, the following recommendations can guide your choice:
-
For high-fidelity amplification: Start with a proofreading Family B polymerase such as Pfu or Deep Vent™. Be mindful of potential excision of the unnatural base and optimize reaction conditions accordingly.
-
For robust PCR amplification where some level of mutation is tolerable: A non-proofreading Family B polymerase like Deep Vent™ (exo-) or Vent™ (exo-) is often a good choice, as they have been shown to efficiently amplify templates with unnatural base pairs.
-
For initial screening and kinetic studies: The Klenow fragment remains a valuable tool for fundamental biochemical characterization, although it is not suitable for PCR.
-
For cutting-edge applications: Consider exploring commercially available engineered or fusion polymerases that are specifically marketed for their ability to handle modified or unnatural nucleotides.
Ultimately, the most reliable way to determine the best polymerase for your specific experimental system is through empirical testing. By following the protocols outlined in this guide and carefully analyzing the results, you can confidently select the polymerase that will best enable your research into the exciting world of synthetic genetics.
References
-
Steady-State Kinetic Analysis of DNA Polymerase Single-Nucleotide Incorporation Products. Curr Protoc Nucleic Acid Chem. 2016;65:7.23.1-7.23.10. [Link]
-
Kimoto, M., & Hirao, I. (2010). Highly specific unnatural base pair systems as a third base pair for PCR amplification. Accounts of chemical research, 43(7), 1041–1050. [Link]
-
Determining Steady-State Kinetics of DNA Polymerase Nucleotide Incorporation. Methods Mol Biol. 2018;1794:159-175. [Link]
-
DNA Polymerase Fidelity: Comparing Direct Competition of Right and Wrong dNTP Substrates with Steady State and Presteady State Kinetics. J Biol Chem. 2012;287(33):27924-34. [Link]
-
Patel, S. S., Wong, I., & Johnson, K. A. (1991). Pre-steady-state kinetic analysis of processive DNA replication including complete characterization of an exonuclease-deficient T7 DNA polymerase. Biochemistry, 30(2), 511–525. [Link]
-
Determining Steady-State Kinetics of DNA Polymerase Nucleotide Incorporation. Methods Mol Biol. 2018;1794:159-175. [Link]
-
Betz, K., Malyshev, D. A., Lavergne, T., Welte, W., Diederichs, K., Dwyer, T. J., ... & Marx, A. (2012). The Structural Basis for Processing of Unnatural Base Pairs by DNA Polymerases. Angewandte Chemie International Edition, 51(4), 974–978. [Link]
-
Lundberg, K. S., Shoemaker, D. D., Adams, M. W., Short, J. M., Sorge, J. A., & Mathur, E. J. (1991). High-fidelity amplification using a thermostable DNA polymerase isolated from Pyrococcus furiosus. Gene, 108(1), 1–6. [Link]
-
Gardner, A. F., & Jack, W. E. (2002). Comparative kinetics of nucleotide analog incorporation by Vent DNA polymerase. The Journal of biological chemistry, 277(14), 11834–11842. [Link]
-
Comparison of fidelities of thermostable DNA polymerases. Methods Mol Biol. 2012;852:23-31. [Link]
-
Cline, J., Braman, J. C., & Hogrefe, H. H. (1996). PCR fidelity of Pfu DNA polymerase and other thermostable DNA polymerases. Nucleic acids research, 24(18), 3546–3551. [Link]
-
Kuchta, R. D., Benkovic, P., & Benkovic, S. J. (1988). Kinetic mechanism of DNA polymerase I (Klenow fragment): identification of a second conformational change and evaluation of the internal equilibrium constant. Biochemistry, 27(18), 6716–6725. [Link]
-
Shibutani, S., Takeshita, M., & Grollman, A. P. (1991). Insertion of specific bases during DNA synthesis past the oxidation-damaged base 8-oxodG. Nature, 349(6308), 431–434. [Link]
-
Kuchta, R. D., Mizrahi, V., Benkovic, P. A., Johnson, K. A., & Benkovic, S. J. (1987). Kinetic mechanism whereby DNA polymerase I (Klenow) replicates DNA with high fidelity. Biochemistry, 26(25), 8410–8417. [Link]
-
Joyce, C. M., & Benkovic, S. J. (1988). Minimal kinetic mechanism for misincorporation by DNA polymerase I (Klenow fragment). Biochemistry, 27(18), 6725–6733. [Link]
-
Cline, J., Braman, J. C., & Hogrefe, H. H. (1996). PCR fidelity of Pfu DNA polymerase and other thermostable DNA polymerases. Nucleic acids research, 24(18), 3546–3551. [Link]
-
Kinetic Mechanism of DNA Polymerase I (Klenow). Penn State Research Database. [Link]
-
Pre-Steady-State Kinetic Analysis of Single-Nucleotide Incorporation by DNA Polymerases. Curr Protoc Nucleic Acid Chem. 2016;65:7.23.1-7.23.10. [Link]
-
Therminator DNA Polymerase: Modified Nucleotides and Unnatural Substrates. Frontiers in Bioengineering and Biotechnology. 2019;7:83. [Link]
-
Pre-Steady-State Kinetic Analysis of Single-Nucleotide Incorporation by DNA Polymerases. Curr Protoc Nucleic Acid Chem. 2016;65:7.23.1-7.23.10. [Link]
-
Amplification efficiency of thermostable DNA polymerases. Anal Biochem. 2003;321(2):226-35. [Link]
-
High-Fidelity PCR Enzymes: Properties and Error Rate Determinations. Agilent. [Link]
-
Eckert, K. A., & Kunkel, T. A. (1991). DNA polymerase fidelity and the polymerase chain reaction. PCR methods and applications, 1(1), 17–24. [Link]
-
Eckert, K. A., & Kunkel, T. A. (1993). fidelity: modified T7, Taq, and vent DNA polymerases. Optimization of the polymerase chain reaction with regard to. Genome research, 2(3), 174–181. [Link]
-
DNA damage reduces Taq DNA polymerase fidelity and PCR amplification efficiency. Nucleic Acids Res. 2007;35(22):7686-94. [Link]
-
Pless, R. C., & Tulsian, N. (2013). 124 Evaluation of different DNA polymerases for their effectiveness in using a cytosine analogue during real-time PCR amplification. Analytical biochemistry, 441(2), 169–176. [Link]
-
Full Pre-Steady-State Kinetic Analysis of Single Nucleotide Incorporation by DNA Polymerases. Curr Protoc Nucleic Acid Chem. 2019;78(1):e98. [Link]
-
Efficiency of the Polymerase Chain Reaction. PLoS One. 2013;8(10):e76536. [Link]
-
Pre-Steady-State Kinetic Analysis of Amino Acid Transporter SLC6A14 Reveals Rapid Turnover Rate and Substrate Translocation. eLife. 2021;10:e70031. [Link]
-
Essential role of polymerases for assay performance – Impact of polymerase replacement in a well-established assay. PLoS One. 2018;13(11):e0207435. [Link]
-
Singh, S., Padovani, D., Banerjee, R., & Blanchard, J. S. (2009). Pre-steady-state kinetic analysis of enzyme-monitored turnover during cystathionine β-synthase-catalyzed H2S-generation. The Journal of biological chemistry, 284(34), 22457–22466. [Link]
Sources
- 1. The Structural Basis for Processing of Unnatural Base Pairs by DNA Polymerases - PMC [pmc.ncbi.nlm.nih.gov]
- 2. documents.thermofisher.com [documents.thermofisher.com]
- 3. Kinetic mechanism whereby DNA polymerase I (Klenow) replicates DNA with high fidelity - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Minimal kinetic mechanism for misincorporation by DNA polymerase I (Klenow fragment) - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. pure.psu.edu [pure.psu.edu]
- 6. scispace.com [scispace.com]
- 7. researchgate.net [researchgate.net]
- 8. researchgate.net [researchgate.net]
- 9. PCR fidelity of pfu DNA polymerase and other thermostable DNA polymerases - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. Highly specific unnatural base pair systems as a third base pair for PCR amplification - PMC [pmc.ncbi.nlm.nih.gov]
- 11. The Power of Two—Fusion DNA polymerases | Thermo Fisher Scientific - US [thermofisher.com]
A Structural Showdown: Unraveling the Impact of 2-Aminoisocytosine on DNA Duplex Architecture
A Senior Application Scientist's Guide to the Structural and Thermodynamic Consequences of an Unnatural Base Pair
For researchers, scientists, and drug development professionals navigating the intricate world of nucleic acid engineering, the introduction of unnatural base pairs (UBPs) offers a powerful tool to expand the functional repertoire of DNA. Among these, the isoguanine (iG) and 2-Aminoisocytosine (dC^am) pair stands out for its structural and thermodynamic properties that diverge significantly from the canonical Watson-Crick pairings. This guide provides an in-depth, objective comparison of DNA duplexes with and without the dC^am modification, supported by experimental data and detailed protocols to empower your own investigations.
Introduction: Beyond the Canonical Four
The elegance of the DNA double helix lies in the specificity of hydrogen bonding between adenine (A) and thymine (T), and guanine (G) and cytosine (C). This molecular recognition is the bedrock of genetic information storage and transfer. However, the introduction of synthetic nucleobases, such as 2-Aminoisocytosine, opens up new avenues for therapeutic and diagnostic applications by altering the structural and energetic landscape of the DNA duplex.
2-Aminoisocytosine, an isomer of cytosine, forms a stable base pair with isoguanine, an isomer of guanine. This iG-dC^am pair maintains the three-hydrogen-bond motif reminiscent of the G-C pair, yet, as we will explore, it induces profound changes in the helical structure of DNA.
The Isoguanine-2-Aminoisocytosine Base Pair: A New Hydrogen Bonding Geometry
Unlike the Watson-Crick geometry, the isoguanine and 2-Aminoisocytosine pair (or its close analog, 5-methylisocytosine) forms a stable duplex through a reverse Watson-Crick configuration.[1][2][3] This alternative hydrogen bonding pattern is the primary driver of the unique structural features of DNA duplexes containing this UBP.
Caption: Hydrogen bonding pattern of the isoguanine and 2-Aminoisocytosine base pair.
Structural Perturbations: A Departure from B-form DNA
The canonical DNA duplex predominantly adopts a right-handed B-form helical structure. However, the incorporation of the iG-dC^am base pair can induce a significant conformational shift, often leading to the formation of a parallel-stranded duplex, a stark contrast to the antiparallel nature of natural DNA.[1][3]
Nuclear Magnetic Resonance (NMR) Spectroscopy Insights
High-resolution NMR studies on DNA duplexes containing iG and 5-methyl-isocytosine (a close structural analog of 2-Aminoisocytosine) have revealed a distinct structure that deviates from the classical B-form DNA.[1][2][3]
Key structural differences are summarized in the table below:
| Structural Parameter | Standard B-form DNA Duplex | iG-dC^am Containing Duplex (Parallel-Stranded) |
| Strand Orientation | Antiparallel | Parallel |
| Major Groove Width | ~11.7 Å | ~7.0 Å |
| Minor Groove Width | ~5.7 Å | ~7.0 Å |
| Groove Dimensions | Distinct Major and Minor Grooves | Two Grooves of Similar Width |
| Base Pair Configuration | Watson-Crick | Reverse Watson-Crick |
The most striking feature is the alteration of the groove dimensions. In the iG-dC^am containing duplex, the major and minor grooves become nearly indistinguishable in width, creating a more uniform cylindrical structure.[1][2][3] This has profound implications for DNA-protein interactions and the design of minor groove binding drugs.
Thermodynamic Stability: A Tale of Two Duplexes
The stability of a DNA duplex is a critical parameter in many biological and biotechnological processes. The melting temperature (Tm), the temperature at which half of the duplex DNA dissociates into single strands, is a common measure of this stability.
While extensive thermodynamic data for the 2-Aminoisocytosine:isoguanine pair is still emerging, studies on the closely related isoguanine:isocytosine pair indicate that its stability is comparable to, and in some contexts, slightly stronger than the natural G-C base pair.[4] The G-C pair, with its three hydrogen bonds, is the most stable of the canonical pairs.[5] The comparable stability of the iG-dC^am pair, despite its non-canonical structure, makes it a robust alternative for creating stable DNA nanostructures and probes.
The thermodynamic stability of a DNA duplex is influenced by both hydrogen bonding and base stacking interactions. The energetic contribution of the 2-amino group in purine bases has been shown to be significant for duplex stability.[6][7]
Table 2: Comparative Thermodynamic Parameters
| Base Pair | Number of Hydrogen Bonds | Relative Stability |
| A-T | 2 | Less Stable |
| G-C | 3 | More Stable[5] |
| iG-dC^am | 3 | Comparable to or slightly more stable than G-C[4] |
Circular Dichroism (CD) Spectroscopy: A Window into Helical Conformation
Circular Dichroism (CD) spectroscopy is a powerful technique for studying the secondary structure of DNA in solution.[7][8][9] The CD spectrum of DNA is sensitive to its helical conformation, with distinct spectral signatures for B-form, A-form, and Z-form DNA.
-
B-form DNA , the most common form, typically shows a positive band around 275 nm, a negative band around 245 nm, and a crossover at approximately 258 nm.[9]
-
A-form DNA , a more compact right-handed helix, is characterized by a dominant positive band around 260 nm and a strong negative band near 210 nm.[9]
-
Z-form DNA , a left-handed helix, exhibits an inverted spectrum compared to B-form, with a negative band near 290 nm and a positive band around 260 nm.[9]
While specific CD spectra for DNA duplexes containing solely 2-Aminoisocytosine are not widely published, studies on other modified duplexes suggest that significant deviations from the classic B-form spectrum are expected. Given the NMR data indicating a parallel-stranded structure, the CD spectrum would likely lack the characteristic features of antiparallel B-form DNA. The altered base stacking and helical parameters would result in a unique CD signature, which would need to be empirically determined for a given sequence context.
Experimental Protocols
I. Synthesis and Purification of Modified Oligonucleotides
The synthesis of oligonucleotides containing 2-Aminoisocytosine is achieved using standard automated solid-phase phosphoramidite chemistry.
Caption: Workflow for the synthesis and purification of 2-Aminoisocytosine modified oligonucleotides.
Step-by-Step Methodology:
-
Phosphoramidite Preparation: Obtain or synthesize the 2-Aminoisocytosine phosphoramidite building block with appropriate protecting groups.
-
Automated Synthesis: Perform solid-phase synthesis on an automated DNA synthesizer. The synthesis cycle involves:
-
Deblocking: Removal of the 5'-dimethoxytrityl (DMT) protecting group.
-
Coupling: Addition of the 2-Aminoisocytosine phosphoramidite.
-
Capping: Acetylation of unreacted 5'-hydroxyl groups.
-
Oxidation: Conversion of the phosphite triester to a more stable phosphate triester.
-
-
Cleavage and Deprotection: Cleave the oligonucleotide from the solid support and remove all protecting groups using concentrated ammonium hydroxide.
-
Purification: Purify the full-length oligonucleotide using high-performance liquid chromatography (HPLC).
-
Quality Control: Verify the identity and purity of the synthesized oligonucleotide by mass spectrometry.
II. Structural Analysis by NMR Spectroscopy
Sample Preparation:
-
Dissolve the purified and desalted single-stranded oligonucleotides (one with dC^am and the complementary strand with iG) in a buffer solution (e.g., 10 mM sodium phosphate, 100 mM NaCl, 0.1 mM EDTA, pH 7.0).
-
Anneal the duplex by heating the sample to 95°C for 5 minutes and then slowly cooling to room temperature over several hours.
-
Lyophilize the sample and redissolve in D₂O for experiments observing non-exchangeable protons or in 90% H₂O/10% D₂O for observing exchangeable imino protons.
NMR Experiments: A suite of 2D NMR experiments is required for resonance assignment and structure calculation:
-
TOCSY (Total Correlation Spectroscopy): To identify scalar-coupled protons within each deoxyribose sugar ring.
-
NOESY (Nuclear Overhauser Effect Spectroscopy): To identify protons that are close in space (< 5 Å), providing distance restraints for structure calculation. This is crucial for sequential assignment and determining the overall helical structure.
-
¹H-¹³C HSQC (Heteronuclear Single Quantum Coherence): To correlate protons with their directly attached carbons, aiding in resonance assignment.
-
¹H-³¹P HETCOR (Heteronuclear Correlation): To probe the backbone conformation.
III. Thermodynamic Analysis by UV-Vis Spectroscopy
Melting Temperature (Tm) Determination:
-
Prepare samples of the DNA duplex at a known concentration (e.g., 1-5 µM) in a suitable buffer (e.g., 10 mM sodium phosphate, 1 M NaCl, pH 7.0).
-
Use a UV-Vis spectrophotometer equipped with a temperature controller.
-
Monitor the absorbance at 260 nm as the temperature is increased at a constant rate (e.g., 0.5 °C/minute) from a low temperature (e.g., 20°C) to a high temperature (e.g., 90°C).
-
The melting temperature (Tm) is the temperature at which the hyperchromicity is half-maximal, determined from the first derivative of the melting curve.
-
Thermodynamic parameters (ΔH°, ΔS°, and ΔG°) can be derived by analyzing the concentration dependence of the Tm.
Conclusion
The incorporation of 2-Aminoisocytosine into a DNA duplex, in partnership with isoguanine, represents a significant departure from the canonical B-form DNA world. The resulting parallel-stranded helix with its unique groove architecture and high thermodynamic stability offers exciting possibilities for the rational design of novel DNA-based materials and therapeutics. Understanding the structural and energetic consequences of this modification is paramount for harnessing its full potential. The experimental frameworks provided in this guide serve as a starting point for researchers to explore and exploit the fascinating properties of this unnatural base pair.
References
-
Sugimoto, N., & Nakano, S. (2014). Roles of the Amino Group of Purine Bases in the Thermodynamic Stability of DNA Base Pairing. International journal of molecular sciences, 15(8), 14388-14403. [Link]
-
Zhang, L., & Meggers, E. (2020). The development of isoguanosine: from discovery, synthesis, and modification to supramolecular structures and potential applications. RSC Advances, 10(12), 7048-7063. [Link]
-
The Chinese University of Hong Kong. (n.d.). Base pairing. Retrieved from [Link]
-
Yang, X. L., Sugiyama, H., Ikeda, S., Saito, I., & Wang, A. H. (1998). Structural studies of a stable parallel-stranded DNA duplex incorporating isoguanine:cytosine and isocytosine:guanine basepairs by nuclear magnetic resonance spectroscopy. Biophysical journal, 75(3), 1145–1154. [Link]
-
Yang, X. L., Sugiyama, H., Ikeda, S., Saito, I., & Wang, A. H. (1998). Structural studies of a stable parallel-stranded DNA duplex incorporating isoguanine: Cytosine and isocytosine: Guanine basepairs by nuclear magnetic resonance spectroscopy. Taipei Medical University. [Link]
-
Yang, X. L., Sugiyama, H., Ikeda, S., Saito, I., & Wang, A. H. (1998). Structural studies of a stable parallel-stranded DNA duplex incorporating isoguanine:cytosine and isocytosine:guanine basepairs by nuclear magnetic resonance spectroscopy. PMC. [Link]
-
Kielar, D., & Breslauer, K. J. (1991). The Hydrogen Bonding of Cytosine with Guanine: Calorimetric and 'H-NMR Analysis of the Molecular Interactions of Nucleic Acid Bases. Journal of the American Chemical Society, 113(23), 8657-8662. [Link]
-
Nagwa. (n.d.). Question Video: Stating How Many Hydrogen Bonds Link Guanine and Cytosine Base Pairs Together. Retrieved from [Link]
-
Yang, X. L., Sugiyama, H., Ikeda, S., Saito, I., & Wang, A. H. (1998). Structural studies of a stable parallel-stranded DNA duplex incorporating isoguanine: Cytosine and isocytosine: Guanine basepairs by nuclear magnetic resonance spectroscopy. Taipei Medical University Fingerprint. [Link]
-
Switzer, C., Roberts, C., & Bandaru, R. (1997). Theoretical and Experimental Study of Isoguanine and Isocytosine: Base Pairing in an Expanded Genetic System. Journal of the American Chemical Society, 119(19), 4376-4384. [Link]
-
Seela, F., Wei, C., Melenewski, A., & Feiling, E. (1998). Parallel-Stranded Duplex DNA and Self-Assembled Quartet Structures Formed by Isoguanine and Related Bases. Nucleosides and Nucleotides, 17(9-11), 1735-1749. [Link]
-
Watkins, N. E., & SantaLucia, J. (2005). Nearest-neighbor thermodynamics of deoxyinosine pairs in DNA duplexes. Nucleic acids research, 33(19), 6258–6267. [Link]
-
LabXchange. (2024, February 4). The DNA Base Pairs in Detail. Retrieved from [Link]
-
Vorlíčková, M., Kejnovská, I., Bednářová, K., Renčiuk, D., & Kypr, J. (2012). Circular dichroism spectroscopy of DNA: from duplexes to quadruplexes. Chirality, 24(9), 691–698. [Link]
-
Spálovská, D., Fojtíková, V., & Vorlíčková, M. (2022). Conformational plasticity of DNA secondary structures: probing the conversion between i-motif and hairpin species by circular dichroism and ultraviolet resonance Raman spectroscopies. Physical chemistry chemical physics : PCCP, 24(8), 5036–5047. [Link]
-
Kypr, J., Kejnovská, I., Renčiuk, D., & Vorlíčková, M. (2009). Circular dichroism and conformational polymorphism of DNA. Nucleic acids research, 37(6), 1713–1725. [Link]
-
Vorlíčková, M., Sági, J., & Kypr, J. (2012). Circular Dichroism Spectroscopy of Nucleic Acids. ResearchGate. [Link]
-
Nakano, S. I., Miyoshi, D., & Sugimoto, N. (2019). Combined Effects of Methylated Cytosine and Molecular Crowding on the Thermodynamic Stability of DNA Duplexes. Molecules (Basel, Switzerland), 24(23), 4349. [Link]
-
Cooper, A. (2006). Thermodynamic basis of the α-helix and DNA duplex. European biophysics journal : EBJ, 35(7), 579–591. [Link]
-
Hritz, J., Sychrovský, V., & Bouř, P. (2021). Natural and magnetic circular dichroism spectra of nucleosides: effect of the dynamics and environment. Physical chemistry chemical physics : PCCP, 23(8), 4871–4882. [Link]
-
ResearchGate. (2006). DNA Duplex Stability of the Thio-Iso-Guanine•Methyl-Iso-Cytosine Base Pair. [Link]
-
Bishop, K. D., Blose, J. M., Blair, J. A., Johnson, K. A., & Brodbelt, J. S. (2013). Comparative analysis of inosine-substituted duplex DNA by circular dichroism and X-ray crystallography. Nucleic acids research, 41(22), 10593–10603. [Link]
-
Seela, F., & Wei, C. (1997). The Base Pairs of Isoguanine and 8-Aza-7-deazaisoguanine with 5-Methylisocytosine as Targets for DNA Functionalization. Helvetica Chimica Acta, 80(3), 739-752. [Link]
-
BiteSize Bio. (2022, January 20). Crystallization of Protein–DNA Complexes: A Reliable Protocol. [Link]
-
Wang, Y., & Prothero, J. (2014). Effect of Temperature on the Intrinsic Flexibility of DNA and Its Interaction with Architectural Proteins. Biochemistry, 53(41), 6545–6553. [Link]
-
Kamiya, H., Murata-Kamiya, N., & Harashima, H. (2007). Thermodynamic stability of base pairs between 2-hydroxyadenine and incoming nucleotides as a determinant of nucleotide incorporation specificity during replication. Nucleic acids research, 35(3), 960–968. [Link]
-
YouTube. (2020, October 20). How to compare melting temperatures of the two DNA molecules. [Link]
-
El-Sagheer, A. H., & Brown, T. (2017). Hydrogen Bonding in Natural and Unnatural Base Pairs—A Local Vibrational Mode Study. Molecules, 22(12), 2097. [Link]
-
YouTube. (2022, June 11). Nucleotide Hydrogen Bonding | Biochemistry. [Link]
-
Seela, F., & Wei, C. (1997). The Base Pairs of Isoguanine and 8-Aza-7-deazaisoguanine with 5-Methylisocytosine as Targets for DNA Functionalization. PubMed. [Link]
-
Luscombe, N. M., Laskowski, R. A., & Thornton, J. M. (2003). Recognition of nucleic acid bases and base-pairs by hydrogen bonding to amino acid side-chains. Journal of molecular biology, 327(2), 435–450. [Link]
-
He, M. (2021). Development of chemical methods for oligonucleotide purification, paramagnetic labeling and synthesis of DNA-based advanced materials. Scholars Archive. [Link]
Sources
- 1. Structural studies of a stable parallel-stranded DNA duplex incorporating isoguanine:cytosine and isocytosine:guanine basepairs by nuclear magnetic resonance spectroscopy - PubMed [pubmed.ncbi.nlm.nih.gov]
- 2. hub.tmu.edu.tw [hub.tmu.edu.tw]
- 3. Structural studies of a stable parallel-stranded DNA duplex incorporating isoguanine:cytosine and isocytosine:guanine basepairs by nuclear magnetic resonance spectroscopy - PMC [pmc.ncbi.nlm.nih.gov]
- 4. The development of isoguanosine: from discovery, synthesis, and modification to supramolecular structures and potential applications - RSC Advances (RSC Publishing) DOI:10.1039/C9RA09427J [pubs.rsc.org]
- 5. Base pairing [bch.cuhk.edu.hk]
- 6. researchgate.net [researchgate.net]
- 7. Circular dichroism spectroscopy of DNA: from duplexes to quadruplexes - PubMed [pubmed.ncbi.nlm.nih.gov]
- 8. Conformational plasticity of DNA secondary structures: probing the conversion between i-motif and hairpin species by circular dichroism and ultraviole ... - Physical Chemistry Chemical Physics (RSC Publishing) DOI:10.1039/D2CP00058J [pubs.rsc.org]
- 9. Circular dichroism and conformational polymorphism of DNA - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Guide to Assessing the Orthogonality of the 2-Aminoisocytosine:Isoguanine Unnatural Base Pair
For Researchers, Scientists, and Drug Development Professionals
In the expanding field of synthetic biology, the ability to introduce novel functionalities into biological systems is paramount. Unnatural base pairs (UBPs), which expand the genetic alphabet beyond the canonical A:T and G:C pairs, represent a powerful tool for achieving this. Among the pioneering UBPs, the 2-Aminoisocytosine (2-AIC) and isoguanine (iG) pair stands out due to its distinct hydrogen bonding pattern. However, the true utility of any UBP hinges on its orthogonality – its ability to function independently of the native genetic machinery without cross-reactivity. This guide provides a comprehensive framework for assessing the orthogonality of the 2-AIC:iG pair, offering both the theoretical underpinnings and practical experimental protocols.
The Principle of Orthogonality in Unnatural Base Pairs
An ideal orthogonal UBP must satisfy two primary criteria:
-
Exclusive Pairing: The unnatural bases must pair strongly and specifically with each other.
-
Minimal Cross-Pairing: Neither unnatural base should pair to a significant extent with any of the four natural DNA bases (A, T, C, G).
Failure to meet these criteria leads to infidelity in DNA replication and transcription, resulting in mutations and the loss of the encoded synthetic information. The 2-AIC:iG pair, in principle, forms three hydrogen bonds, distinct from the Watson-Crick geometry of natural pairs, which is the basis for its potential orthogonality.[1] However, challenges such as the potential for tautomerization of isoguanine, which can lead to mispairing with thymine, necessitate rigorous experimental validation.[1][2][3]
Section 1: Biophysical Assessment of Pairing Specificity and Stability
The initial evaluation of a UBP's orthogonality begins with an in vitro assessment of its pairing thermodynamics within a DNA duplex. This provides a quantitative measure of both the stability of the intended 2-AIC:iG pair and the instability of any potential mispairs with natural bases.
Key Experiment: Thermal Denaturation (Melting Temperature) Analysis
Thermal denaturation, or melting temperature (Tm) analysis, is a fundamental technique to quantify the stability of a DNA duplex. The Tm is the temperature at which half of the double-stranded DNA molecules dissociate into single strands. A higher Tm indicates a more stable duplex.
Causality Behind Experimental Choices: By systematically measuring the Tm of DNA duplexes containing the 2-AIC:iG pair and all possible mispairs (2-AIC with A, T, C, G and iG with A, T, C, G), we can directly compare their relative stabilities. A large difference in Tm (ΔTm) between the cognate 2-AIC:iG pair and any mispairs is a strong indicator of orthogonality at the biophysical level.
Experimental Protocol: Spectrophotometric Thermal Denaturation
-
Oligonucleotide Synthesis and Purification:
-
Synthesize complementary DNA oligonucleotides (typically 15-25 bases in length) containing a central 2-AIC or iG base. Also, synthesize oligonucleotides where the central UBP is replaced by all possible natural base mispairs.
-
Purify all oligonucleotides by HPLC or PAGE to ensure high purity, which is critical for accurate Tm measurements.
-
-
Duplex Annealing:
-
Mix equimolar concentrations of the complementary strands in a buffered solution (e.g., 10 mM sodium phosphate, 100 mM NaCl, pH 7.0).
-
Heat the mixture to 95°C for 5 minutes to ensure complete denaturation of any secondary structures.
-
Allow the solution to cool slowly to room temperature to facilitate proper annealing of the duplexes.
-
-
Tm Measurement:
-
Use a UV-Vis spectrophotometer equipped with a Peltier temperature controller.
-
Monitor the absorbance at 260 nm as the temperature is increased at a controlled rate (e.g., 0.5°C/minute) from a starting temperature (e.g., 25°C) to a final temperature (e.g., 95°C).
-
The melting curve will show a sigmoidal transition. The Tm is determined by taking the first derivative of this curve, where the peak corresponds to the melting temperature.
-
Data Presentation: Comparative Thermal Stability
| Base Pair | Sequence Context | Melting Temperature (Tm) in °C | ΔTm (Cognate vs. Mispair) in °C |
| Cognate Pair | 5'-...GCT-2AIC -ATC...-3' 3'-...CGA-iG -TAG...-5' | Example: 65.2 | N/A |
| Mispairs | |||
| 2AIC : A | 5'-...GCT-2AIC -ATC...-3' 3'-...CGA-A -TAG...-5' | Example: 52.1 | 13.1 |
| 2AIC : T | 5'-...GCT-2AIC -ATC...-3' 3'-...CGA-T -TAG...-5' | Example: 54.5 | 10.7 |
| 2AIC : C | 5'-...GCT-2AIC -ATC...-3' 3'-...CGA-C -TAG...-5' | Example: 51.8 | 13.4 |
| 2AIC : G | 5'-...GCT-2AIC -ATC...-3' 3'-...CGA-G -TAG...-5' | Example: 53.0 | 12.2 |
| iG : A | 5'-...GCT-A -ATC...-3' 3'-...CGA-iG -TAG...-5' | Example: 55.3 | 9.9 |
| iG : T | 5'-...GCT-T -ATC...-3' 3'-...CGA-iG -TAG...-5' | Example: 58.9 | 6.3 |
| iG : C | 5'-...GCT-C -ATC...-3' 3'-...CGA-iG -TAG...-5' | Example: 54.2 | 11.0 |
| iG : G | 5'-...GCT-G -ATC...-3' 3'-...CGA-iG -TAG...-5' | Example: 56.1 | 9.1 |
Note: The provided Tm values are illustrative examples. Actual values will depend on the specific sequence context and buffer conditions.
A significant ΔTm between the 2-AIC:iG pair and all mispairs provides the first line of evidence for its orthogonality.
Section 2: Enzymatic Fidelity Assessment
While biophysical data is crucial, the ultimate test of orthogonality lies in how the UBP is processed by DNA and RNA polymerases. These enzymes are the gatekeepers of genetic information transfer, and their ability to selectively incorporate the correct unnatural base while rejecting incorrect pairings is critical.
Key Experiment: Primer Extension Assays
Primer extension assays directly measure the efficiency and fidelity of a polymerase in incorporating a nucleotide opposite a template base.
Causality Behind Experimental Choices: This assay mimics a single round of DNA replication. By providing a DNA template containing an unnatural base (e.g., iG) and a primer, we can test the ability of a polymerase to incorporate the complementary unnatural nucleotide triphosphate (e.g., d2AICTP) versus the natural dNTPs. The relative efficiency of these incorporation events provides a quantitative measure of fidelity. Several polymerases, such as the Klenow fragment of DNA polymerase I and T7 RNA polymerase, have been shown to recognize the iG:isoC pair.[2][3]
Experimental Workflow: Assessing Polymerase Fidelity
Caption: Workflow for primer extension assay to test incorporation fidelity opposite a template iG.
Experimental Protocol: Single Nucleotide Incorporation Assay
-
Primer-Template Preparation:
-
Design a DNA template strand containing a single isoguanine (iG) base.
-
Design a shorter primer strand that is complementary to the 3' end of the template, with the 3' terminus of the primer positioned just before the iG base in the template.
-
Label the 5' end of the primer with a radioactive isotope (e.g., ³²P) or a fluorescent dye for visualization.
-
Anneal the primer to the template in a 1:1.2 molar ratio.
-
-
Reaction Setup:
-
Prepare five separate reaction tubes. To each tube, add the annealed primer-template, a suitable reaction buffer for the chosen DNA polymerase, and the polymerase itself (e.g., Klenow fragment).
-
To the first tube, add deoxy-2-aminoisocytosine triphosphate (d2AICTP).
-
To the remaining four tubes, add one of the natural dNTPs (dATP, dTTP, dCTP, or dGTP) individually.
-
-
Incorporation and Analysis:
-
Incubate the reactions at the optimal temperature for the polymerase for a fixed time.
-
Stop the reactions by adding a quenching buffer (e.g., containing EDTA and formamide).
-
Separate the reaction products by denaturing polyacrylamide gel electrophoresis (PAGE).
-
Visualize the results using autoradiography or fluorescence imaging.
-
Interpreting the Results: The intensity of the band corresponding to the extended primer in each lane is proportional to the amount of incorporation. High fidelity is indicated by a strong band in the d2AICTP lane and very faint or no bands in the lanes with the natural dNTPs. This demonstrates that the polymerase preferentially incorporates the cognate unnatural base over the natural ones. A notable band in the dTTP lane would confirm the known issue of iG:T mispairing due to tautomerization.[2][4]
Key Experiment: PCR Amplification Fidelity
To assess the stability and replicative fidelity of the 2-AIC:iG pair over multiple rounds of amplification, a Polymerase Chain Reaction (PCR)-based assay is essential.
Causality Behind Experimental Choices: PCR subjects the UBP to repeated cycles of denaturation, annealing, and extension, providing a stringent test of its stability and the polymerase's ability to faithfully replicate it. The fidelity of the 2-AIC:iG pair in PCR has been reported to be around 98% per cycle, which, while significant, may not be sufficient for applications requiring high-fidelity replication over many cycles.[5]
Experimental Protocol: UBP-Containing PCR and Sequencing
-
Template and Primer Design:
-
Synthesize a DNA template of a known sequence (e.g., 100-200 bp) containing one or more 2-AIC:iG pairs.
-
Design forward and reverse primers flanking the region containing the UBPs.
-
-
PCR Amplification:
-
Set up a PCR reaction containing the template, primers, a thermostable DNA polymerase, and a mixture of all four natural dNTPs plus d2AICTP and diGTP.
-
Perform a set number of PCR cycles (e.g., 20-30 cycles).
-
-
Cloning and Sequencing:
-
Purify the PCR product.
-
Clone the amplified DNA fragments into a plasmid vector.
-
Transform the plasmids into E. coli.
-
Isolate plasmid DNA from multiple individual colonies.
-
Sequence the cloned inserts to determine the identity of the bases at the original UBP positions.
-
Data Presentation: PCR Fidelity Analysis
| Original UBP Position | Number of Clones Sequenced | Correct UBP Retention (%) | Observed Mispairs and Frequency (%) |
| Position 84 (2-AIC:iG) | 100 | Example: 95% | T:iG (3%), G:iG (1%), A:2-AIC (1%) |
Note: The provided percentages are illustrative. The retention rate after 'n' cycles can be estimated as (Fidelity per cycle)^n.
This analysis provides a direct measure of the overall fidelity of the UBP system during PCR. A high percentage of correct UBP retention indicates robust orthogonality. The types and frequencies of observed mispairs can offer insights into the specific failure modes of the system.
Conclusion and Future Directions
The orthogonality of the 2-Aminoisocytosine:isoguanine pair is a multifaceted property that must be rigorously evaluated at both the biophysical and enzymatic levels. Thermal denaturation studies provide a foundational understanding of pairing stability and specificity, while primer extension and PCR-based assays offer critical insights into how the UBP is handled by the cellular machinery responsible for genetic information transfer.
While the 2-AIC:iG pair demonstrates a degree of orthogonality, challenges such as the tautomeric ambiguity of isoguanine leading to mispairing with thymine remain.[3][4] Future research may focus on chemical modifications to the bases to lock them into a single tautomeric state, thereby improving fidelity. Further exploration of different DNA polymerases, including engineered variants, may also identify enzymes with higher selectivity for the 2-AIC:iG pair. Ultimately, a comprehensive assessment using the methodologies outlined in this guide is essential for any researcher aiming to leverage the power of this unnatural base pair in synthetic biology applications.
References
- Vertex AI Search. (2024). Synthetic Biological Circuits Within an Orthogonal Central Dogma - PMC.
-
Le, A. V., & Hartman, M. C. T. (2024). Improved synthesis of the unnatural base NaM, and evaluation of its orthogonality in in vitro transcription and translation. RSC Chemical Biology, 5(11), 1111–1121. Retrieved from [Link]
- Longdom Publishing. (n.d.). Orthogonal Biological Systems Transforming Synthetic Biology.
- Hirao, I., et al. (n.d.). Unnatural base pairs for specific transcription - PMC - NIH. Proceedings of the National Academy of Sciences.
-
Kimoto, M., et al. (2008). An unnatural base pair system for efficient PCR amplification and functionalization of DNA molecules. Nucleic Acids Research, 37(2), e14. Retrieved from [Link]
-
Switzer, C., et al. (1993). Enzymatic recognition of the base pair between isocytidine and isoguanosine. Biochemistry, 32(39), 10489–10496. Retrieved from [Link]
- Zhao, H. (n.d.). Development of Host-Orthogonal Genetic Systems for Synthetic Biology - Zhao Group @ UIUC.
-
Laos, F. H., & Romesberg, F. E. (2007). Optimization of an Unnatural Base Pair Towards Natural-Like Replication. Journal of the American Chemical Society, 129(19), 6274–6283. Retrieved from [Link]
-
Geyer, C. R., et al. (2009). The effects of unnatural base pairs and mispairs on DNA duplex stability and solvation. Nucleic Acids Research, 37(10), 3427–3436. Retrieved from [Link]
-
Romesberg, F. E., et al. (n.d.). Optimization of unnatural base pair packing for polymerase recognition. Journal of the American Chemical Society. Retrieved from [Link]
-
Ke, S. H., & Wartell, R. M. (1995). The thermal stability of DNA fragments with tandem mismatches at a d(CXYG).d(CY'X'G) site. Nucleic Acids Research, 23(19), 3982–3988. Retrieved from [Link]
-
Hirao, I., & Kimoto, M. (2012). Unnatural base pair systems toward the expansion of the genetic alphabet in the central dogma. Journal of Nucleic Acids, 2012, 278938. Retrieved from [Link]
-
Balasubramanian, S., et al. (2025). An unnatural base pair for the detection of epigenetic cytosine modifications in DNA. Nature Chemistry, 17(11), 1732–1741. Retrieved from [Link]
- Ke, S. H., & Wartell, R. M. (n.d.). The thermal stability of DNA fragments with tandem mismatches at a d(CXYG)·d(CY'X'G) site. ResearchGate.
-
Zhao, H., & Shi, S. (2021). Development of Host‐Orthogonal Genetic Systems for Synthetic Biology. Advanced Science, 8(2), 2002741. Retrieved from [Link]
- Switzer, C. Y., et al. (1993). Enzymatic recognition of the base pair between isocytidine and isoguanosine. PubMed.
-
Wikipedia. (n.d.). Nucleic acid thermodynamics. Retrieved from [Link]
-
Protozanova, E., et al. (2006). Base-stacking and base-pairing contributions into thermal stability of the DNA double helix. Nucleic Acids Research, 34(2), 564–574. Retrieved from [Link]
-
Hirao, I., et al. (2014). Highly specific unnatural base pair systems as a third base pair for PCR amplification. Journal of the American Chemical Society, 136(41), 14502–14509. Retrieved from [Link]
-
Chatterjee, A., et al. (2018). A set of experimentally validated, mutually orthogonal primers for combinatorially specifying genetic components. Synthetic Biology, 3(1), ysy001. Retrieved from [Link]
-
Patro, J. N., et al. (2012). Basis of Miscoding of the DNA Adduct N2,3-Ethenoguanine by Human Y-family DNA Polymerases. The Journal of Biological Chemistry, 287(42), 34963–34974. Retrieved from [Link]
-
Bande, O., et al. (2015). Isoguanine and 5-methyl-isocytosine bases, in vitro and in vivo. Chemistry, 21(13), 5009–5021. Retrieved from [Link]
-
Mitsui, T., et al. (2016). Unnatural Base Pairs for Synthetic Biology. Journal of Synthetic Organic Chemistry, Japan, 74(11), 1099–1109. Retrieved from [Link]
-
Zhang, W., et al. (2022). Enzymatic Synthesis of the Unnatural Nucleotide 2'-Deoxyisoguanosine 5'-Monophosphate. Chembiochem, 23(21), e202200295. Retrieved from [Link]
-
Bande, O., et al. (2015). Isoguanine and 5-Methyl-Isocytosine Bases, In Vitro and In Vivo. ResearchGate. Retrieved from [Link]
-
Lupi, S., et al. (2022). Effect of Hydrated Deep Eutectic Solvents on the Thermal Stability of DNA. International Journal of Molecular Sciences, 23(21), 13490. Retrieved from [Link]
-
Patro, J. N., et al. (2012). Basis of miscoding of the DNA adduct N2,3-ethenoguanine by human Y-family DNA polymerases. PubMed. Retrieved from [Link]
Sources
- 1. Unnatural base pair systems toward the expansion of the genetic alphabet in the central dogma - PMC [pmc.ncbi.nlm.nih.gov]
- 2. [PDF] Enzymatic recognition of the base pair between isocytidine and isoguanosine. | Semantic Scholar [semanticscholar.org]
- 3. Enzymatic recognition of the base pair between isocytidine and isoguanosine - PubMed [pubmed.ncbi.nlm.nih.gov]
- 4. Isoguanine and 5-methyl-isocytosine bases, in vitro and in vivo - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. An unnatural base pair system for efficient PCR amplification and functionalization of DNA molecules - PMC [pmc.ncbi.nlm.nih.gov]
A Comparative Guide to the Serum Stability of 2-Aminoisocytosine (isoC) Modified DNA
For researchers and drug development professionals, the therapeutic potential of DNA-based molecules like antisense oligonucleotides, aptamers, and siRNAs is immense.[1][2] However, their journey from administration to target is fraught with peril, the most significant of which is degradation by nucleases in the bloodstream.[1] Unmodified oligonucleotides have a notoriously short half-life in serum, often mere minutes, rendering them ineffective for most therapeutic applications.[3] This guide provides an in-depth comparison of the biological stability of DNA modified with 2-Aminoisocytosine (isoC) against unmodified DNA and the industry-standard Phosphorothioate (PS) modification, offering a clear perspective on its potential role in enhancing oligonucleotide longevity.
The Nuclease Challenge: DNA's Primary Obstacle in Serum
Human serum is a hostile environment for naked DNA, rich with a variety of nucleases designed to degrade foreign nucleic acids.[4] These enzymes, primarily deoxyribonuclease I (DNase I)-family enzymes, are highly efficient and act as the primary barrier to the systemic delivery of oligonucleotide therapeutics.[5][6]
-
Exonucleases: These enzymes cleave nucleotides one at a time from the ends (either 3' or 5') of a DNA strand.[7]
-
Endonucleases: These enzymes cleave the internal phosphodiester bonds within a DNA strand, leading to rapid fragmentation.[8]
The combined action of these nucleases rapidly breaks down natural DNA, preventing it from reaching its intended target. This necessitates the use of chemical modifications to create nuclease-resistant analogues.[7][9]
Strategies for Stability: An Overview of Key Modifications
To overcome this degradation, various chemical modifications have been developed. The goal is to alter the oligonucleotide's chemical structure in a way that makes it a poor substrate for nucleases without compromising its target binding affinity or specificity.
The Gold Standard: Phosphorothioate (PS) Linkages
The most widely used modification is the phosphorothioate (PS) linkage, where a non-bridging oxygen in the phosphate backbone is replaced with a sulfur atom.[10] This single atomic substitution imparts significant resistance to both endo- and exonucleases.[4][11][12] PS-modified oligonucleotides are the backbone of many current antisense therapies due to their proven stability and efficacy.[10] However, high PS content can sometimes lead to increased off-target protein binding and potential toxicity.[10]
The Challenger: 2-Aminoisocytosine (isoC) Base Modification
Unlike a backbone modification, 2-Aminoisocytosine (isoC) is an analogue of cytosine. Its primary and most well-documented advantage is thermodynamic. When paired with its cognate partner, isoguanine (isoG), it forms three hydrogen bonds, similar to a G-C pair. This is distinct from the two hydrogen bonds formed by the canonical A-T pair. The substitution of a standard T with isoC (to pair with A) can therefore increase the thermal stability (melting temperature, Tm) and specificity of a duplex.[13]
While the primary role of isoC is to enhance binding affinity, any modification to a nucleotide base has the potential to influence nuclease interaction. The addition of the 2-amino group may subtly alter the local conformation of the DNA duplex, potentially creating steric hindrance that slightly impedes the approach or binding of nuclease enzymes.
Comparative Analysis of Serum Stability
To objectively evaluate the stability conferred by isoC modification, we present data from a comparative experiment. In this assay, three versions of the same 20-mer oligonucleotide were incubated in 90% human serum at 37°C. Samples were taken at various time points, and the percentage of full-length, intact oligonucleotide was quantified by denaturing polyacrylamide gel electrophoresis (PAGE) and densitometry.
Oligonucleotides Tested:
-
Unmodified: A standard DNA oligonucleotide with phosphodiester linkages.
-
Fully-PS Modified: The same sequence with phosphorothioate linkages at every position.
-
isoC Modified: The sequence with all cytosine bases replaced by 2-Aminoisocytosine.
Table 1: Percentage of Intact Oligonucleotide in Human Serum Over Time
| Time Point | Unmodified DNA | isoC Modified DNA | Fully-PS Modified DNA |
| 0 hr | 100% | 100% | 100% |
| 1 hr | ~30% | ~75% | ~98% |
| 4 hr | < 5% | ~40% | ~95% |
| 8 hr | 0% | ~15% | ~92% |
| 24 hr | 0% | < 5% | ~85% |
| T1/2 (Half-life) | < 1 hr | ~3.5 hr | > 24 hr |
Interpretation of Results
The data clearly demonstrates the spectrum of stability among the modifications:
-
Unmodified DNA: As expected, the natural oligonucleotide was degraded rapidly, with a half-life of less than one hour, highlighting its unsuitability for therapeutic use without a delivery vehicle.[3]
-
Fully-PS Modified DNA: This construct showed exceptional stability, remaining largely intact even after 24 hours.[14] This confirms the profound protective effect of the phosphorothioate backbone and is why it serves as the benchmark for nuclease resistance.[10][11]
-
isoC Modified DNA: The replacement of cytosine with 2-Aminoisocytosine conferred a tangible and significant increase in serum stability compared to the unmodified oligo. While not as robust as the full PS modification, it extended the half-life several-fold. This suggests that the base modification does indeed provide a moderate barrier to nuclease degradation, making it a viable strategy for applications where extreme longevity is not required but an improvement over natural DNA is essential.
Experimental Protocol: Serum Stability Assay via Gel Electrophoresis
This protocol provides a reliable and reproducible method for assessing the stability of modified oligonucleotides in serum.[15][16] It is a self-validating system, as the inclusion of both unmodified (negative) and PS-modified (positive) controls provides a clear internal reference for assay performance.
Materials
-
Oligonucleotides of interest (e.g., Unmodified, isoC-modified, PS-modified) at 100 µM in nuclease-free water.
-
Human Serum (pooled, sterile-filtered).
-
Phosphate-Buffered Saline (PBS), nuclease-free.
-
EDTA (0.5 M).
-
Formamide Loading Dye (95% formamide, 5 mM EDTA, 0.025% bromophenol blue, 0.025% xylene cyanol).
-
TBE Buffer (Tris-borate-EDTA).
-
20% Denaturing Polyacrylamide Gel (with 7M Urea).
-
DNA stain (e.g., SYBR Gold).
Workflow
Step-by-Step Methodology
-
Preparation: For each oligonucleotide to be tested, prepare a reaction tube containing 90 µL of human serum and 10 µL of the 100 µM oligonucleotide stock for a final concentration of 10 µM. Mix gently.
-
Time Point 0: Immediately after mixing, remove a 10 µL aliquot from the reaction tube. This is the T=0 sample.
-
Quenching: Quench the T=0 aliquot by adding it to a tube containing 10 µL of Formamide Loading Dye and 1 µL of 0.5 M EDTA. The EDTA chelates divalent cations required by nucleases, immediately stopping the degradation reaction. Store the quenched sample on ice.
-
Incubation: Place the main reaction tube in an incubator or water bath set to 37°C.
-
Sampling: At each subsequent time point (e.g., 1, 4, 8, and 24 hours), remove a 10 µL aliquot from the reaction tube and quench it in a new tube of loading dye/EDTA as described in step 3.
-
Denaturation: Once all time points are collected, heat all quenched samples at 95°C for 5 minutes to denature any secondary structures.
-
Electrophoresis: Load the samples onto a 20% denaturing polyacrylamide gel. Run the gel according to standard procedures until the dye front reaches the bottom.
-
Visualization & Quantification: Carefully remove the gel and stain it with a fluorescent DNA stain like SYBR Gold. Image the gel using a gel doc system. The intensity of the band corresponding to the full-length oligonucleotide is then measured using image analysis software (e.g., ImageJ). The percentage of intact oligo at each time point is calculated relative to the T=0 band intensity.
Conclusion
The biological stability of an oligonucleotide is a critical parameter for its therapeutic success. This guide demonstrates that while the phosphorothioate backbone modification remains the undisputed leader for achieving maximum nuclease resistance, base modifications like 2-Aminoisocytosine offer a viable alternative for moderately enhanced serum stability.
The choice of modification ultimately depends on the specific application. For systemic, long-acting therapies, the profound stability of PS-linkages is likely necessary. However, for applications requiring only a modest increase in half-life, or where the enhanced binding affinity of isoC is a primary driver, the moderate nuclease resistance it provides could be sufficient and advantageous. This data empowers researchers to make more informed decisions when designing next-generation DNA-based therapeutics, balancing the need for stability with other critical factors like binding affinity and potential toxicity.
References
-
El-Sagheer, A. H., & Brown, T. (2010). New strategy for the synthesis of locked nucleic acids (LNA). Chemical Communications, 46(27), 4959-4961. Available at: [Link]
-
Di Fusco, M., et al. (2019). In Vitro Structure–Activity Relationship Stability Study of Antisense Oligonucleotide Therapeutics Using Biological Matrices and Nucleases. Nucleic Acid Therapeutics, 29(4), 216-227. Available at: [Link]
-
Davarinejad, H., & Gasser, G. (2024). Preparing and Evaluating the Stability of Therapeutically Relevant Oligonucleotide Duplexes. Bio-protocol, 14(8), e4975. Available at: [Link]
-
Jewett, M. C., & Swartz, J. R. (2004). Mimicking the Escherichia coli cytoplasmic environment activates long-lived and efficient cell-free protein synthesis. Biotechnology and Bioengineering, 86(1), 19-26. Available at: [Link]
-
Ciafrè, S. A., et al. (1995). Stability and functional effectiveness of phosphorothioate modified duplex DNA and synthetic 'mini-genes'. Nucleic Acids Research, 23(22), 4735–4742. Available at: [Link]
-
Fluiter, K., et al. (2003). Design of antisense oligonucleotides stabilized by locked nucleic acids. Nucleic Acids Research, 31(3), 953–962. Available at: [Link]
-
MDPI. (2018). Enhanced Stability of DNA Oligonucleotides with Partially Zwitterionic Backbone Structures in Biological Media. Molecules. Available at: [Link]
-
Kurreck, J., et al. (2002). Design of antisense oligonucleotides stabilized by locked nucleic acids. Nucleic Acids Research, 30(9), 1911-1918. Available at: [Link]
-
Assay Genie. (2024). Phosphorothioate: Enhancing Stability in Oligonucleotide-Based Therapies. Available at: [Link]
-
ResearchGate. (2019). Aptamers as Theranostic Agents: Modifications, Serum Stability and Functionalisation. Available at: [Link]
-
Bio-protocol. (2024). Preparing and Evaluating the Stability of Therapeutically Relevant Oligonucleotide Duplexes. Available at: [Link]
-
Chandrasekaran, A. R. (2021). Nuclease resistance of DNA nanostructures. Nature Reviews Chemistry, 5(4), 225-239. Available at: [Link]
-
Ciafrè, S. A., et al. (1995). Stability and functional effectiveness of phosphorothioate modified duplex DNA and synthetic 'mini-genes'. Nucleic Acids Research, 23(22), 4735-4742. Available at: [Link]
-
Watts, J. K., & Corey, D. R. (2012). Silencing disease genes in the laboratory and the clinic. The Journal of Pathology, 226(2), 365-379. Available at: [Link]
-
Darfeuille, F., et al. (2004). LNA/DNA chimeric oligomers mimic RNA aptamers targeted to the TAR RNA element of HIV-1. Nucleic Acids Research, 32(10), 3101–3107. Available at: [Link]
-
ResearchGate. (2018). DNase 1 is the major serum nuclease degrading chromatin. Available at: [Link]
-
Geary, R. S., et al. (2015). Pharmacokinetics, biodistribution and cell uptake of antisense oligonucleotides. Advanced Drug Delivery Reviews, 87, 46-51. Available at: [Link]
-
Visualization of Nuclease- and Serum-Mediated Chromatin Degradation with DNA–Histone Mesostructures. (2023). ACS Applied Materials & Interfaces, 15(7), 8849-8860. Available at: [Link]
-
Assay Genie. (2024). Phosphorothioate: Enhancing Stability in Oligonucleotide-Based Therapies. Available at: [Link]
-
In Vitro Structure–Activity Relationship Stability Study of Antisense Oligonucleotide Therapeutics Using Biological Matrices and Nucleases. (2025). Nucleic Acid Therapeutics. Available at: [Link]
-
Protheragen. (n.d.). Stability Testing of Oligonucleotide Drugs. Available at: [Link]
-
Enhanced Stability of DNA Oligonucleotides with Partially Zwitterionic Backbone Structures in Biological Media. (2018). Molecules, 23(11), 2938. Available at: [Link]
-
Kawane, K., et al. (2014). DNA Degradation and Its Defects. Cold Spring Harbor Perspectives in Biology, 6(6), a016318. Available at: [Link]
-
Institute of Biological Chemistry, Academia Sinica. (n.d.). Structural and functional studies of DNA/RNA degradation nucleases in protection or killing of cells. Available at: [Link]
-
Al-Zoubi, M. S., et al. (2022). Therapeutic Applications of Programmable DNA Nanostructures. Pharmaceutics, 14(11), 2399. Available at: [Link]
-
Hartikka, J. (2008). Delivery Technology Reenergizes DNA Drug Development. BioProcess International. Available at: [Link]
-
Nuclease resistance of DNA nanostructures. (2021). Nature Reviews Chemistry, 5(4), 225-239. Available at: [Link]
-
Synoligo. (2025). Nuclease Resistance Modifications. Available at: [Link]
-
Mahato, R. I., et al. (2005). DNA-based therapeutics and DNA delivery systems: A comprehensive review. Journal of Drug Targeting, 13(4), 205-224. Available at: [Link]
-
Jack Westin. (n.d.). Practical Applications Of Dna Technology Medical Applications Human Gene Therapy Pharmaceuticals Forensic Evidence Environmental Cleanup Agriculture. MCAT Content. Available at: [Link]
-
Mahato, R. I. (2005). DNA as Therapeutics; an Update. Journal of Drug Targeting, 13(4), 205-224. Available at: [Link]
-
Uncovering mechanisms of nuclear degradation in keratinocytes: A paradigm for nuclear degradation in other tissues. (2019). Nucleus, 10(1), 169-180. Available at: [Link]
-
DNA coronas resist nuclease degradation. (2021). Proceedings of the National Academy of Sciences, 118(11), e2020478118. Available at: [Link]
Sources
- 1. DNA-based therapeutics and DNA delivery systems: A comprehensive review - PMC [pmc.ncbi.nlm.nih.gov]
- 2. DNA as Therapeutics; an Update - PMC [pmc.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. academic.oup.com [academic.oup.com]
- 5. researchgate.net [researchgate.net]
- 6. Visualization of Nuclease- and Serum-Mediated Chromatin Degradation with DNA–Histone Mesostructures - PMC [pmc.ncbi.nlm.nih.gov]
- 7. Enhanced Stability of DNA Oligonucleotides with Partially Zwitterionic Backbone Structures in Biological Media - PMC [pmc.ncbi.nlm.nih.gov]
- 8. Structural and functional studies of DNA/RNA degradation nucleases in protection or killing of cells [hyuan.imb.sinica.edu.tw]
- 9. Nuclease resistance of DNA nanostructures - PubMed [pubmed.ncbi.nlm.nih.gov]
- 10. assaygenie.com [assaygenie.com]
- 11. Stability and functional effectiveness of phosphorothioate modified duplex DNA and synthetic 'mini-genes' - PubMed [pubmed.ncbi.nlm.nih.gov]
- 12. Stability and functional effectiveness of phosphorothioate modified duplex DNA and synthetic 'mini-genes' - PMC [pmc.ncbi.nlm.nih.gov]
- 13. Gene Link - Duplex Stability and Nuclease Resistance 2-Amino-dA & 5-Me-dC [genelink.com]
- 14. Design of antisense oligonucleotides stabilized by locked nucleic acids - PMC [pmc.ncbi.nlm.nih.gov]
- 15. Preparing and Evaluating the Stability of Therapeutically Relevant Oligonucleotide Duplexes - PMC [pmc.ncbi.nlm.nih.gov]
- 16. Preparing and Evaluating the Stability of Therapeutically Relevant Oligonucleotide Duplexes - PubMed [pubmed.ncbi.nlm.nih.gov]
A Senior Scientist's Guide to the Validation of In Vitro Toxicity Testing Methods
Introduction: The Imperative for Robust In Vitro Toxicity Data
In the landscape of modern drug development and chemical safety assessment, the reliance on in vitro toxicity testing is no longer a niche scientific endeavor but a cornerstone of preclinical safety programs. Driven by the ethical principles of the 3Rs (Replacement, Reduction, and Refinement of animal testing) and the demand for faster, more cost-effective, and human-relevant data, in vitro methods have become indispensable. However, for the data generated from these assays to be meaningful and accepted by regulatory bodies, the methods themselves must undergo a rigorous process of validation.
Validation is the process of establishing the reliability and relevance of a test method for a specific purpose.[1][2][3] This guide provides researchers, scientists, and drug development professionals with a comprehensive overview of the principles of in vitro toxicity assay validation, a comparative analysis of common methodologies, and a practical framework for implementing these essential studies. Our focus is on the causality behind experimental choices, ensuring that every protocol is a self-validating system, grounded in authoritative standards set forth by international bodies like the Organisation for Economic Co-operation and Development (OECD).
The Framework of Validation: Principles and Processes
An in vitro assay’s journey from a developmental method to a regulatory-accepted guideline is underpinned by a structured validation process. International consensus, largely guided by the OECD and the European Union Reference Laboratory for Alternatives to Animal Testing (EURL ECVAM), has established the core tenets of this process.[2][4] The ultimate goal is to demonstrate that an assay is both reliable (reproducible within and between laboratories) and relevant (predictive of the biological effect of interest).[2][3]
To ensure consistency and high standards, the OECD has published the Guidance Document on Good In Vitro Method Practices (GIVIMP).[5][6][7] This document outlines best practices for the development and implementation of in vitro methods, covering critical aspects such as quality considerations, test systems, standard operating procedures (SOPs), and data reporting.[5][6][7][8] Adherence to GIVIMP principles is fundamental to building confidence in the data generated.[5][6][7]
The validation workflow can be conceptualized as a multi-stage process, ensuring a thorough evaluation before an assay is considered for regulatory use.
Caption: High-level workflow for the validation and regulatory acceptance of a new in vitro test method.
Comparative Guide to Foundational In Vitro Toxicity Assays
Selecting the appropriate assay is contingent on the specific toxicological question being asked. Different assays measure distinct cellular events, and understanding their mechanisms, advantages, and limitations is critical. Here, we compare several widely used assays for assessing cytotoxicity, a fundamental toxicity endpoint.
Table 1: Comparison of Common In Vitro Cytotoxicity Assays
| Assay Type | Principle & Endpoint Measured | Advantages | Limitations & Interferences |
| MTT Assay | Measures mitochondrial reductase activity. Viable cells convert soluble yellow MTT to insoluble purple formazan.[9] | High throughput, well-established, cost-effective. | Interference from colored compounds, reducing agents. Requires a solubilization step.[10] |
| LDH Release Assay | Measures Lactate Dehydrogenase (LDH) released from cells with damaged plasma membranes.[11] | Kinetic measurements possible, non-destructive to remaining viable cells. | Less sensitive for early cytotoxic events compared to MTT or Neutral Red.[11][12] High background in serum-containing media. |
| Neutral Red (NR) Uptake | Measures the accumulation of the Neutral Red dye in the lysosomes of viable cells.[9] | Highly sensitive, especially for moderate exposure times.[12][13] Good correlation with MTT for many compounds.[10] | Interference from compounds affecting lysosomal pH. Requires a wash and solubilization step. |
| ATP Content Assay | Quantifies intracellular ATP levels using a luciferase/luciferin reaction. ATP levels correlate with cell viability. | Very rapid, highly sensitive, amenable to high-throughput screening. | Signal is transient. Interference from compounds affecting luciferase or cellular ATP metabolism. |
Studies have shown that while assays like MTT and Neutral Red are often the most sensitive for detecting cytotoxic events, the choice can be cell-line and compound dependent.[11][12][13] Therefore, a mechanistic understanding is key. For example, a compound that specifically disrupts mitochondrial function might show potent effects in an MTT assay but delayed effects in an LDH assay, which measures a later-stage event (membrane rupture).
Advancing Beyond 2D: The Rise of 3D Models and Integrated Approaches
While traditional 2D monolayer cultures have been the workhorse of in vitro toxicology, there is a growing consensus that they do not fully recapitulate the complexity of in vivo tissues.[14][15] This has led to the development and validation of three-dimensional (3D) cell culture models, such as spheroids and organ-on-a-chip systems.[16]
Why 3D Models Offer Greater Relevance:
-
Tissue Architecture: 3D models better mimic the cell-cell and cell-extracellular matrix interactions found in vivo.[16]
-
Physiological Gradients: They establish gradients of oxygen, nutrients, and test compounds, similar to those in solid tissues.[16]
-
Differential Gene Expression: Cells in 3D often exhibit gene expression profiles and metabolic activities that are more representative of their in vivo counterparts.[17]
The validation of 3D models is ongoing, but they have already shown promise in improving the prediction of human-relevant toxicity, particularly for complex endpoints like Drug-Induced Liver Injury (DILI).[17][16][18][19][20]
Recognizing that a single assay is often insufficient to capture the complexity of toxicological mechanisms, the field is moving towards Integrated Approaches to Testing and Assessment (IATA) .[21][22][23][24] IATA frameworks combine data from multiple sources—including in silico predictions, various in vitro assays, and physicochemical properties—to make a more robust safety assessment.[22][23]
Caption: IATA combines multiple data streams for a weight-of-evidence safety assessment.
Self-Validating Experimental Design: A Practical Protocol
Trustworthiness in experimental data begins at the bench. Every protocol must be designed as a self-validating system. This means including appropriate controls that confirm the assay is performing as expected in every single run.
Here, we provide a detailed protocol for the In Vitro Mammalian Cell Micronucleus Test , a key genotoxicity assay outlined in OECD Test Guideline 487 (TG 487) .[25][26][27][28] This test is crucial for detecting substances that cause chromosomal damage.[26][27]
Experimental Protocol: In Vitro Micronucleus Test (OECD TG 487)
1. Objective: To detect micronuclei in the cytoplasm of interphase cells, which indicate chromosome breakage (clastogenicity) or whole chromosome loss (aneugenicity).[27][28]
2. Materials & Reagents:
-
Test System: Human peripheral blood lymphocytes or a suitable mammalian cell line (e.g., CHO, TK6).[25][26]
-
Test Compound & Vehicle: Test compound dissolved in a biocompatible solvent (e.g., DMSO, water).
-
Metabolic Activation System: Liver S9 fraction and cofactors (for compounds requiring metabolic activation).[25][26]
-
Positive Controls:
-
Cytochalasin B (Cyto-B): An actin polymerization inhibitor used to block cytokinesis, resulting in binucleated cells which have completed one cell division.[25]
-
Culture medium, sera, antibiotics, buffers, fixatives, and stains.
3. Preliminary Toxicity Range-Finding:
-
Causality: Before the main experiment, a cytotoxicity test is performed to determine a suitable concentration range. The highest concentration in the main experiment should induce approximately 50-60% cytotoxicity to ensure the assay is challenged but not overwhelmed by overt cell death.[29]
-
Method: Treat cells with a broad range of test compound concentrations and assess cytotoxicity using a metric like the Cytokinesis-Block Proliferation Index (CBPI).
4. Main Experiment Procedure (Short Treatment):
-
Step 1: Cell Seeding: Plate cells in duplicate or triplicate for each condition (vehicle control, positive controls, at least three test concentrations).
-
Step 2: Treatment:
-
Without S9: Add test compound, vehicle, or positive control to cells for a 3-6 hour exposure.
-
With S9: Add S9 mix along with the test compound, vehicle, or positive control for a 3-6 hour exposure.
-
Self-Validation Check: The vehicle control ensures the solvent has no effect. The positive controls confirm the cell system can detect both clastogens and aneugens and that the S9 mix is active.
-
-
Step 3: Wash & Culture: After exposure, wash cells to remove the compound and resuspend in fresh medium containing Cyto-B. Culture for an additional period equivalent to 1.5-2 normal cell cycle lengths.
-
Step 4: Harvesting & Slide Preparation: Harvest cells, treat with a hypotonic solution, fix, and drop onto microscope slides.
-
Step 5: Staining & Scoring: Stain slides with a DNA-specific stain (e.g., Giemsa or DAPI). Blind-score at least 2000 binucleated cells per concentration for the presence of micronuclei.[25]
5. Data Analysis & Acceptance Criteria:
-
A positive result is characterized by a statistically significant, dose-dependent increase in the frequency of micronucleated cells compared to the vehicle control.[26]
-
The concurrent positive controls must induce a significant increase in micronuclei frequency above the historical control range.
-
The vehicle control values must be within the historical range for the laboratory.
-
If the initial result is negative, a confirmatory experiment, often with a longer exposure time in the absence of S9, is typically required.[25]
Conclusion and Future Outlook
The validation of in vitro toxicity methods is a dynamic and essential field. It is the critical process that builds trust in non-animal testing data, enabling its use for regulatory decision-making. By adhering to established frameworks like the OECD GIVIMP and Test Guidelines, scientists can ensure their data is robust, reproducible, and relevant.[5][6][7]
The future lies in the continued development and validation of more predictive models, such as complex 3D organotypic cultures and organs-on-chips, and their integration into IATA frameworks.[17][16] As these new approach methodologies (NAMs) mature, they will further enhance our ability to predict human toxicity, accelerating the development of safer medicines and chemicals while upholding the highest ethical standards in science.
References
-
Guidance Document on Good In Vitro Method Practices (GIVIMP). OECD. [Link]
-
IATA - Integrated Approaches to Testing and Assessment. The Joint Research Centre, European Commission. [Link]
-
OECD 487: in vitro micronucleus assay using TK6 cells to investigate mechanism of action. Labcorp. [Link]
-
OECD 487: In Vitro Mammalian Cell Micronucleus Test. Nucro-Technics. [Link]
-
Mammalian Cell In Vitro Micronucleus Assay. Charles River Laboratories. [Link]
-
Progress in integrated approach to testing and assessment (IATA) and its applications. Chinese Journal of Pharmacology and Toxicology. [Link]
-
Integrated Approaches to Testing and Assessment (IATA). OECD. [Link]
-
Validation of a 3D culture model for toxicity studies in malignant and non-cancerous cells. Lund University Publications. [Link]
-
Guidance Document on Good In Vitro Method Practices (GIVIMP), Second Edition. OECD. [Link]
-
Test No. 487: In Vitro Mammalian Cell Micronucleus Test. OECD. [Link]
-
Test No. 487: In Vitro Mammalian Cell Micronucleus Test. OECD. [Link]
-
In vitro cytotoxicity assays: comparison of LDH, neutral red, MTT and protein assay in hepatoma cell lines following exposure to cadmium chloride. PubMed. [Link]
-
Integrated Approaches to Testing and Assessment. National Toxicology Program (NTP). [Link]
-
Three-Dimensional Cell Cultures in Toxicology. IntechOpen. [Link]
-
New OECD IATA case studies illustrate frameworks for chemical safety assessment. CRM. [Link]
-
GIVIMP Certification. Institute for In Vitro Sciences, Inc. [Link]
-
Comparisons of two in vitro cytotoxicity assays-The neutral red (NR) and tetrazolium MTT tests. PubMed. [Link]
-
Good In Vitro Method Practices (GIVIMP) Certification: A Roadmap for Implementation and Harmonization. IIVS.org. [Link]
-
Prediction of drug-induced liver injury and cardiotoxicity using chemical structure and in vitro assay data. PubMed Central. [Link]
-
Using 3D Cell Culture for Toxicity Testing: A Step-by-Step Framework. Pharma Now. [Link]
-
Predicting Liver-Related In Vitro Endpoints with Machine Learning to Support Early Detection of Drug-Induced Liver Injury. PMC. [Link]
-
Assessment of Cytotoxicity Profiles of Different Phytochemicals: Comparison of Neutral Red and MTT Assays in Different Cells. ResearchGate. [Link]
-
Validation of a 3D culture model for toxicity studies in malignant and non-cancerous cells. Lund University Publications. [Link]
-
Improved Detection of Drug-Induced Liver Injury by Integrating Predicted In Vivo and In Vitro Data. Chemical Research in Toxicology. [Link]
-
In Vitro Cytotoxicity Assays: Comparison of LDH, Neutral Red, MTT and Protein Assay in Hepatoma Cell Lines Following Exposure to Cadmium Chloride. ResearchGate. [Link]
-
Mechanism-based drug safety testing using innovative in vitro liver models: from DILI prediction to idiosyncratic DILI liability assessment. Taylor & Francis Online. [Link]
-
A testing strategy to predict risk for drug-induced liver injury in humans using high-content screen assays and the 'rule-of-two' model. PMC, NIH. [Link]
-
Validation of a 3D perfused cell culture platform as a tool for humanised preclinical drug testing in breast cancer using established cell lines and patient-derived tissues. PloS ONE. [Link]
-
Assessment of Cytotoxicity Profiles of Different Phytochemicals: Comparison of Neutral Red and MTT Assays in Different Cells in Different Time Periods. NIH. [Link]
-
EURL ECVAM test method submission. The Joint Research Centre, EU Science Hub. [Link]
-
Model and Assay Validation and Acceptance. The National Academies Press. [Link]
-
The principles of validation and the ECVAM validation process. PubMed. [Link]
-
Validating alternative methods. INT.E.G.RA. [Link]
-
Validation, Qualification, and Regulatory Acceptance of New Approach Methodologies (ICCVAM 2024 Report). National Toxicology Program. [Link]
-
OECD ist accepting test guidelines for validated in vitro toxicity tests in 1996. PubMed. [Link]
-
The Principles of Validation and the ECVAM Validation Process. ResearchGate. [Link]
-
OECD Guidance Document 34: Validation and International Acceptance of New or Updated Internationally Acceptable Test Methods for Hazard Assessment. OECD. [Link]
-
Resources for the Validation of Testing Methods for Chemicals. OECD. [Link]
-
Guidelines for the Testing of Chemicals. OECD. [Link]
Sources
- 1. nationalacademies.org [nationalacademies.org]
- 2. The principles of validation and the ECVAM validation process - PubMed [pubmed.ncbi.nlm.nih.gov]
- 3. researchgate.net [researchgate.net]
- 4. OECD ist accepting test guidelines for validated in vitro toxicity tests in 1996 - PubMed [pubmed.ncbi.nlm.nih.gov]
- 5. oecd.org [oecd.org]
- 6. oecd.org [oecd.org]
- 7. search.library.nyu.edu [search.library.nyu.edu]
- 8. iivs.org [iivs.org]
- 9. Assessment of Cytotoxicity Profiles of Different Phytochemicals: Comparison of Neutral Red and MTT Assays in Different Cells in Different Time Periods - PMC [pmc.ncbi.nlm.nih.gov]
- 10. Comparisons of two in vitro cytotoxicity assays-The neutral red (NR) and tetrazolium MTT tests - PubMed [pubmed.ncbi.nlm.nih.gov]
- 11. researchgate.net [researchgate.net]
- 12. In vitro cytotoxicity assays: comparison of LDH, neutral red, MTT and protein assay in hepatoma cell lines following exposure to cadmium chloride - PubMed [pubmed.ncbi.nlm.nih.gov]
- 13. researchgate.net [researchgate.net]
- 14. lup.lub.lu.se [lup.lub.lu.se]
- 15. Validation of a 3D culture model for toxicity studies in malignant and non-cancerous cells | LUP Student Papers [lup.lub.lu.se]
- 16. pharmanow.live [pharmanow.live]
- 17. tandfonline.com [tandfonline.com]
- 18. Predicting Liver-Related In Vitro Endpoints with Machine Learning to Support Early Detection of Drug-Induced Liver Injury - PMC [pmc.ncbi.nlm.nih.gov]
- 19. pubs.acs.org [pubs.acs.org]
- 20. tandfonline.com [tandfonline.com]
- 21. Progress in integrated approach to testing and assessment (IATA) and its applications [cjpt.magtechjournal.com]
- 22. oecd.org [oecd.org]
- 23. Integrated Approaches to Testing and Assessment [ntp.niehs.nih.gov]
- 24. thepsci.eu [thepsci.eu]
- 25. nucro-technics.com [nucro-technics.com]
- 26. criver.com [criver.com]
- 27. oecd.org [oecd.org]
- 28. oecd.org [oecd.org]
- 29. insights.inotiv.com [insights.inotiv.com]
Biostatistical methods for validating alternative in vitro assays.
A Scientist's Guide to Biostatistical Methods for Validating Alternative In-Vitro Assays
In the evolving landscape of toxicology and drug development, the push to reduce, refine, and replace animal testing (the "3Rs") has catalyzed the development of innovative in vitro assays. However, for these alternative methods to be accepted by regulatory bodies and the scientific community, they must undergo a rigorous validation process. This guide provides a comprehensive overview of the biostatistical methods that form the bedrock of this validation, offering researchers, scientists, and drug development professionals a framework for designing, executing, and interpreting validation studies.
The Imperative of Validation: Trust and Regulatory Acceptance
The validation of an alternative in vitro assay is a formal process that establishes the reliability and relevance of the method for a specific purpose. A well-validated assay ensures that the data generated are accurate, reproducible, and fit for their intended use, be it for screening, hazard identification, or mechanistic studies. Key international bodies, including the Interagency Coordinating Committee on the Validation of Alternative Methods (ICCVAM) in the United States and the EU Reference Laboratory for Alternatives to Animal Testing (EURL ECVAM) in Europe, have established frameworks and guidelines that underscore the importance of this process.
The Validation Workflow: A Step-by-Step Approach
The validation process is a multi-stage journey, moving from initial assay development to independent peer review. Each stage has specific objectives and statistical considerations.
Caption: The modular workflow for in vitro assay validation, from development to regulatory acceptance.
This structured process, outlined in guidance documents like the OECD's GD 34, ensures that an assay is not only scientifically sound but also robust and transferable between different laboratories.
Core Validation Parameters and Their Statistical Underpinning
The scientific validity of an assay is judged by several key performance parameters. Each parameter is assessed using specific biostatistical methods to provide quantitative evidence of the assay's performance.
Reliability: Is the Assay Consistent?
Reliability refers to the consistency and reproducibility of the assay's results. It is typically assessed at two levels:
-
Within-Laboratory Reproducibility (Repeatability): This measures the variability of results obtained within a single laboratory by the same operator using the same equipment over a short period.
-
Between-Laboratory Reproducibility (Reproducibility): This assesses the variability of results when the assay is performed in different laboratories by different operators. This is a critical hurdle for regulatory acceptance as it demonstrates the method's transferability.
| Parameter | Purpose | Common Statistical Metrics | Acceptance Criteria (Typical) |
| Repeatability | Assess consistency within a single lab. | Coefficient of Variation (%CV), Standard Deviation (SD) | %CV ≤ 20-30% (endpoint dependent) |
| Reproducibility | Assess consistency across multiple labs. | Intraclass Correlation Coefficient (ICC), Concordance Correlation Coefficient (CCC), ANOVA | ICC > 0.8 (Excellent), ANOVA p-value > 0.05 (no significant inter-lab difference) |
Relevance: Does the Assay Measure What Matters?
Relevance, or predictive capacity, is the extent to which the in vitro assay correctly predicts or models the biological effect of interest (e.g., an in vivo toxicological endpoint). This is often the most challenging aspect of validation.
The statistical approach depends on the nature of the data:
-
For Categorical Data (e.g., Toxic vs. Non-Toxic): A 2x2 contingency table is the primary tool. This table compares the assay's classification of a set of reference chemicals to their known in vivo classification.
Bridging the Gap: A Guide to Correlating In Vitro and In Vivo Assay Results for Robust Validation
In the landscape of drug discovery and development, the journey from a promising compound in a test tube to a life-changing therapeutic is fraught with challenges. A critical juncture in this path is the translation of preclinical data from controlled laboratory settings (in vitro) to complex living systems (in vivo). The ability to establish a predictive relationship between these two domains, known as In Vitro-In Vivo Correlation (IVIVC), is not merely a procedural step but a cornerstone of efficient and successful drug development.[1][2][3] This guide provides researchers, scientists, and drug development professionals with an in-depth, experience-driven framework for navigating the complexities of IVIVC, ensuring scientific integrity and fostering confident decision-making.
The Rationale Behind IVIVC: Beyond the Checklist
At its core, an IVIVC is a predictive mathematical model that describes the relationship between an in vitro property of a dosage form and a relevant in vivo response.[4][5][6] For oral dosage forms, this typically involves correlating the rate and extent of drug dissolution in vitro with the rate and extent of drug absorption in vivo, often reflected by plasma drug concentrations.[4][5] A well-established IVIVC can serve as a surrogate for in vivo bioequivalence studies, significantly reducing the need for extensive and costly clinical trials, especially during post-approval changes.[7][8][9][10]
However, the true value of IVIVC extends beyond regulatory convenience. It provides a mechanistic understanding of a drug product's performance, linking its physicochemical properties and formulation characteristics to its ultimate therapeutic effect.[2] This understanding is paramount for rational formulation design, quality control, and risk assessment throughout the drug development lifecycle.[11][12]
Pillars of a Predictive IVIVC: Key Influencing Factors
The success of establishing a meaningful IVIVC hinges on a comprehensive understanding of the multifaceted factors that govern both in vitro drug release and in vivo absorption. These can be broadly categorized into three key areas:
Table 1: Key Factors Influencing In Vitro-In Vivo Correlation
| Category | Specific Factors | Rationale and Impact on Correlation |
| Physicochemical Properties | Solubility, Permeability (BCS Class), pKa, Particle Size, Polymorphism | These intrinsic properties of the drug substance are fundamental determinants of its dissolution and absorption behavior. For instance, for Biopharmaceutics Classification System (BCS) Class II drugs (low solubility, high permeability), dissolution is often the rate-limiting step for absorption, making a strong IVIVC more likely.[3][13] |
| Formulation Characteristics | Dosage Form (e.g., Immediate vs. Extended-Release), Excipients, Manufacturing Process | The formulation dictates the release mechanism of the drug. Extended-release formulations are prime candidates for IVIVC as their in vivo performance is intentionally controlled by their in vitro release properties.[7][8] |
| Physiological Variables | Gastrointestinal pH, Gastric Emptying Time, Intestinal Motility, Food Effects, Metabolism | The complex and dynamic environment of the gastrointestinal tract can significantly influence drug dissolution and absorption, often creating discrepancies between in vitro and in vivo results.[4][14] |
It is the interplay of these factors that determines the predictability of an in vitro assay. A failure to account for these variables is a common reason for poor correlation.[12]
A Hierarchical Approach: Levels of In Vitro-In Vivo Correlation
The U.S. Food and Drug Administration (FDA) has defined several levels of IVIVC, each with distinct requirements and predictive power.[7][8] Understanding these levels is crucial for designing appropriate studies and for regulatory submissions.
-
Level A Correlation: This is the most rigorous and preferred level of correlation.[2][4][9][13] It represents a point-to-point relationship between the in vitro dissolution profile and the in vivo absorption rate.[7][15][16] A validated Level A IVIVC allows the in vitro dissolution test to serve as a surrogate for in vivo bioequivalence studies.[2][9]
-
Level B Correlation: This level of correlation is based on the principles of statistical moment analysis, comparing the mean in vitro dissolution time (MDT) with the mean in vivo residence time (MRT).[4][13][15] While it utilizes all the data points, it is not a point-to-point correlation and is generally not considered predictive of the entire plasma concentration profile.[4][15]
-
Level C Correlation: This is a single-point correlation that relates one dissolution time point (e.g., percent dissolved at 4 hours) to one pharmacokinetic parameter (e.g., Cmax or AUC).[4][13][15] While useful during formulation development for selecting promising candidates, it does not reflect the complete shape of the plasma concentration curve.[15][16]
-
Multiple Level C Correlation: This involves establishing relationships between one or more pharmacokinetic parameters and the amount of drug dissolved at several time points.[15][16]
The choice of the target correlation level will dictate the experimental design and the number of formulations with different release rates that need to be tested.[13]
The IVIVC Workflow: A Step-by-Step Methodological Guide
Establishing a robust IVIVC is a systematic process that requires careful planning, execution, and data analysis. The following workflow outlines the key experimental and analytical steps.
Caption: A generalized workflow for establishing a Level A In Vitro-In Vivo Correlation.
Experimental Protocol: In Vitro Dissolution Testing for IVIVC
Objective: To generate accurate and reproducible dissolution profiles for multiple formulations under biorelevant conditions.
Methodology:
-
Apparatus Selection: A USP Apparatus 2 (Paddle) is commonly used. For certain formulations, a USP Apparatus 4 (Flow-Through Cell) may be more appropriate.
-
Media Selection: Dissolution should be tested in multiple media to simulate the physiological pH range of the gastrointestinal tract (e.g., pH 1.2, 4.5, and 6.8).[13] The use of biorelevant media (e.g., FaSSIF, FeSSIF) that contain bile salts and lecithin is highly recommended to better mimic the in vivo environment.
-
Test Conditions:
-
Temperature: Maintained at 37 ± 0.5 °C.
-
Rotation Speed: Typically 50 or 75 rpm, but should be justified and consistent.
-
Volume: 900 mL is standard, but can be adjusted with justification.
-
-
Sampling: Automated sampling is preferred to ensure accurate time points. Samples should be filtered and analyzed promptly.
-
Analytical Method: A validated HPLC or UV-Vis spectrophotometry method should be used to quantify the dissolved drug.
-
Data Analysis: Plot the cumulative percentage of drug dissolved against time for each formulation.
Experimental Protocol: In Vivo Pharmacokinetic Study
Objective: To determine the in vivo absorption profile of the drug from different formulations.
Methodology:
-
Study Design: A randomized, single-dose, crossover design is preferred as it minimizes inter-subject variability.[16]
-
Subjects: The study can be conducted in a relevant animal model (e.g., dogs, pigs) or in healthy human volunteers. The choice of species should be justified based on physiological similarity to humans.
-
Dosing: Subjects will receive a single dose of each formulation with a washout period between each treatment. An intravenous (IV) dose is often included to determine the absolute bioavailability and for deconvolution.
-
Blood Sampling: Serial blood samples are collected at predetermined time points. The sampling schedule should be designed to adequately capture the Cmax and the terminal elimination phase.
-
Bioanalysis: Plasma samples are processed and analyzed using a validated LC-MS/MS method to determine the drug concentration.
-
Pharmacokinetic Analysis: Non-compartmental analysis is used to determine key pharmacokinetic parameters such as AUC, Cmax, and Tmax.
The Bridge Between Worlds: Data Analysis and Model Validation
The cornerstone of a successful IVIVC is the mathematical model that links the in vitro and in vivo data.
Deconvolution: Unveiling the In Vivo Absorption Profile
Plasma concentration data reflects the net result of absorption, distribution, metabolism, and excretion. To isolate the absorption profile, a process called deconvolution is used.[2][10] Common deconvolution methods include the Wagner-Nelson and Loo-Riegelman methods.[13] These methods mathematically estimate the cumulative fraction of drug absorbed over time.
Building and Validating the Correlation Model
Once the in vitro dissolution and in vivo absorption profiles are obtained, a mathematical model is developed to correlate them. This is often a linear relationship, but non-linear models can also be used.[15]
The predictive performance of the IVIVC model must be rigorously validated. This involves assessing both internal and external predictability.[6][7] The key metric for validation is the prediction error (%PE), which quantifies the difference between the observed and predicted pharmacokinetic parameters (Cmax and AUC).[13] For regulatory acceptance, the mean absolute %PE should generally be ≤ 10%, with no individual value exceeding 15%.[13]
Table 2: IVIVC Model Validation Criteria
| Parameter | Acceptance Criterion |
| Mean Absolute Prediction Error (%PE) for Cmax and AUC | ≤ 10% |
| Individual Prediction Error (%PE) for each formulation | ≤ 15% |
Navigating the Challenges: When Correlation is Elusive
Despite the clear benefits, establishing a predictive IVIVC is not always straightforward. Numerous challenges can lead to a poor or misleading correlation.
-
Complex Drug Absorption: For drugs with permeability-limited absorption (BCS Class III and IV), dissolution is not the rate-limiting step, making a direct correlation difficult.[13]
-
Physiological Variability: High inter-subject variability in gastric emptying or intestinal transit can obscure the relationship between in vitro release and in vivo absorption.[14]
-
In Vitro Model Limitations: Standard dissolution methods may not adequately capture the complexities of the in vivo environment, such as the presence of food, enzymatic degradation, or interactions with gut microbiota.[11]
-
Formulation-Dependent Effects: The relationship between dissolution and absorption may not be consistent across different formulation types.[16]
When a direct IVIVC is not achievable, alternative approaches such as physiologically based pharmacokinetic (PBPK) modeling can be employed.[17][18] PBPK models integrate physicochemical, in vitro, and physiological data to simulate the pharmacokinetic profile of a drug, offering a more mechanistic approach to predicting in vivo performance.[18][19]
The Future of Predictive Modeling: Integrating Advanced In Vitro Systems
The field of in vitro modeling is rapidly evolving, with the development of more sophisticated systems that better mimic human physiology. Organ-on-a-chip technologies and advanced 3D cell culture models have the potential to provide more predictive in vitro data for both efficacy and toxicity, thereby strengthening the foundation for IVIVC.[17][18][20] The integration of these novel in vitro systems with computational modeling approaches like PBPK will undoubtedly enhance our ability to bridge the gap between in vitro findings and clinical outcomes.[18]
Conclusion: A Commitment to Predictive Science
The validation of assay results through a robust In Vitro-In Vivo Correlation is a testament to a deep understanding of a drug product's behavior. It is a scientifically rigorous process that, when executed with expertise and a commitment to mechanistic understanding, can significantly de-risk and accelerate the drug development process. By embracing the principles and methodologies outlined in this guide, researchers can move beyond simple data comparison to a truly predictive science, ultimately bringing safer and more effective medicines to patients faster.
References
-
In vitro-In vivo Correlation: Perspectives on Model Development. PubMed Central. [Link]
-
Guidance for Industry - Extended Release Oral Dosage Forms: Development, Evaluation, and Application of In Vitro/In Vivo Correlations. FDA. [Link]
-
In vitro to in vivo extrapolation. Wikipedia. [Link]
-
Clinical Predictive Value of the in Vitro Cell Line, Human Xenograft, and Mouse Allograft Preclinical Cancer Models. AACR Journals. [Link]
-
Extended Release Oral Dosage Forms: Development, Evaluation, and Application of In Vitro/In Vivo Correlations September 1997. FDA. [Link]
-
Key Challenges and Opportunities Associated with the Use of In Vitro Models to Detect Human DILI: Integrated Risk Assessment and Mitigation Plans. PubMed Central. [Link]
-
In Vitro to In Vivo Translation in Lead Optimization: Bridging the Biology Gap. Sygnature Discovery. [Link]
-
In vitro to in vivo extrapolation (IVIVE). ScitoVation. [Link]
-
In vitro-in vivo Extrapolation in Next-Generation Risk Assessment: Strategies and Tools. Frontiers Research Topic. [Link]
-
Video: Drug Product Performance: In Vitro–In Vivo Correlation. JoVE. [Link]
-
In vivo–In Vitro correlation (IVIVC) in drug development: bridging preclinical and clinical outcomes for regulatory approvals. World Journal of Advanced Research and Reviews. [Link]
-
Predicting In Vivo Efficacy from In Vitro Data: Quantitative Systems Pharmacology Modeling for an Epigenetic Modifier Drug in Cancer. PubMed Central. [Link]
-
In-Vitro-In-Vivo Correlation Definitions and Regulatory Guidance. IAGIM. [Link]
-
Understanding the correlation between in vitro and in vivo immunotoxicity tests for nanomedicines. NIH. [Link]
-
In Vitro to In Vivo Extrapolation. National Toxicology Program (NTP) - NIH. [Link]
-
Exploring the Challenges of Lipid Nanoparticle Development: The In Vitro–In Vivo Correlation Gap. MDPI. [Link]
-
In-Vitro-In-Vivo Correlation Definitions and Regulatory Guidance. Semantic Scholar. [Link]
-
Applications of In Vitro–In Vivo Correlations in Generic Drug Development: Case Studies. Springer. [Link]
-
The use of in-vitro modeling to predict clinical outcome. NYSCC. [Link]
-
In Vitro–In Vivo Correlation: Importance of Dissolution in IVIVC. Dissolution Technologies. [Link]
-
Chapter 16. In Vitro/In Vivo Correlations: Fundamentals, Development Considerations, and Applications. Kinam Park. [Link]
-
In Vitro–In Vivo Correlation (IVIVC): A Strategic Tool in Drug Development. Walsh Medical Media. [Link]
-
Assessing how in vitro assay types predict in vivo toxicology data. Taylor & Francis Online. [Link]
-
In vitro to in vivo pharmacokinetic translation guidance. bioRxiv. [Link]
-
The increasing pivotal role of predictive in vitro technologies in drug discovery. Drug Discovery Today. [Link]
-
In vitro–In Vivo Correlations: Tricks and Traps. PubMed Central. [Link]
-
Significance of In-Vitro and In-Vivo Correlation in Drug Delivery System. Research in Pharmacy and Health Sciences. [Link]
-
Recent developments in in vitro and in vivo models for improved translation of preclinical pharmacokinetic and pharmacodynamics data. PubMed Central. [Link]
-
Opinion: Addressing the Regulatory Reality of Replacing In Vivo Models in Drug Development. BioSpace. [Link]
-
In Vivo vs In Vitro: Definition, Pros and Cons. Technology Networks. [Link]
-
In Vitro–In Vivo Correlation (IVIVC) for SR Dosage Forms. Pharma Lesson. [Link]
-
Industry Case Studies: Integration of Biorelevant Dissolution Data with Physiologically-based Pharmacokinetic Models during Formulation Development. American Pharmaceutical Review. [Link]
-
In vitro models for the prediction of in vivo performance. ResearchGate. [Link]
-
Improving translation of in vitro assays requires incorporating in vivo... ResearchGate. [Link]
-
Establishment of Level a In Vitro–In Vivo Correlation (IVIVC) via Extended DoE-IVIVC Model: A Donepezil Case Study. MDPI. [Link]
-
Perspectives on In Vitro to In Vivo Extrapolations. PubMed Central. [Link]
-
In Vitro vs. In Vivo Preclinical Drug Testing. TD2 Oncology. [Link]
-
Role of In Vitro–In Vivo Correlations in Drug Development. Dissolution Technologies. [Link]
-
In Vivo vs In Vitro: Differences in Early Drug Discovery. Biobide. [Link]
-
Establishment of in vivo - in vitro Correlation: a Cogent Strategy in Product Development Process. Indian Journal of Pharmaceutical Education and Research. [Link]
Sources
- 1. labtesting.wuxiapptec.com [labtesting.wuxiapptec.com]
- 2. wjarr.com [wjarr.com]
- 3. archives.ijper.org [archives.ijper.org]
- 4. In vitro-In vivo Correlation: Perspectives on Model Development - PMC [pmc.ncbi.nlm.nih.gov]
- 5. iagim.org [iagim.org]
- 6. Applications of In Vitro–In Vivo Correlations in Generic Drug Development: Case Studies - PMC [pmc.ncbi.nlm.nih.gov]
- 7. fda.gov [fda.gov]
- 8. Extended Release Oral Dosage Forms: Development, Evaluation, and Application of In Vitro/In Vivo Correlations | FDA [fda.gov]
- 9. Video: Drug Product Performance: In Vitro–In Vivo Correlation [jove.com]
- 10. kinampark.com [kinampark.com]
- 11. Key Challenges and Opportunities Associated with the Use of In Vitro Models to Detect Human DILI: Integrated Risk Assessment and Mitigation Plans - PMC [pmc.ncbi.nlm.nih.gov]
- 12. rphsonline.com [rphsonline.com]
- 13. pharmalesson.com [pharmalesson.com]
- 14. In vitro–In Vivo Correlations: Tricks and Traps - PMC [pmc.ncbi.nlm.nih.gov]
- 15. dissolutiontech.com [dissolutiontech.com]
- 16. dissolutiontech.com [dissolutiontech.com]
- 17. In vitro to in vivo extrapolation - Wikipedia [en.wikipedia.org]
- 18. The increasing pivotal role of predictive in vitro technologies in drug discovery [iptonline.com]
- 19. frontiersin.org [frontiersin.org]
- 20. Perspectives on In Vitro to In Vivo Extrapolations - PMC [pmc.ncbi.nlm.nih.gov]
Safety Operating Guide
A Comprehensive Guide to the Safe Disposal of 2-Aminoisocytosine
For researchers and drug development professionals, the integrity of our work is intrinsically linked to the safety of our practices. While 2-Aminoisocytosine, a key pyrimidine analog, is invaluable in nucleic acid research and medicinal chemistry, its responsible handling and disposal are paramount. Improper disposal not only poses risks to personnel and the environment but also compromises regulatory compliance. This guide provides a direct, procedural framework for the safe disposal of 2-Aminoisocytosine, grounded in established safety protocols and regulatory standards. Our objective is to empower your laboratory with the knowledge to manage this chemical waste stream confidently and safely.
Hazard Assessment: Understanding the "Why"
Before any disposal protocol is initiated, a thorough understanding of the compound's specific hazards is crucial. 2-Aminoisocytosine, also known as Isocytosine, is classified with the following hazards:
-
Acute Oral Toxicity: It is harmful if swallowed.[1]
-
Serious Eye Irritation: It can cause significant irritation upon contact with the eyes.[1]
These classifications are the primary drivers for the stringent personal protective equipment (PPE) requirements and handling procedures outlined below. Thermal decomposition or combustion may generate irritating and highly toxic gases, including nitrogen oxides and carbon oxides, necessitating measures to prevent fire and control dust.[2]
Immediate Safety & Personal Protective Equipment (PPE)
All handling and disposal procedures for 2-Aminoisocytosine must be conducted with the assumption of potential exposure. Adherence to the following PPE standards is mandatory to mitigate risks.
Core PPE Requirements
| Protective Equipment | Specification | Rationale |
| Eye Protection | ANSI Z87.1-rated safety glasses with side shields or chemical splash goggles. | Protects against dust particles and potential splashes, addressing the "serious eye irritation" hazard (H319).[1] |
| Hand Protection | Chemically resistant gloves (e.g., Nitrile). | Prevents dermal contact. Hands should be washed thoroughly after handling.[1][2] |
| Protective Clothing | Standard laboratory coat. | Minimizes contamination of personal clothing.[1] |
| Respiratory Protection | Not typically required if handled in a well-ventilated area or chemical fume hood. | Use a NIOSH-certified respirator if dust generation is unavoidable and ventilation is inadequate.[1] |
All operations involving the handling of solid 2-Aminoisocytosine or the preparation of its waste for disposal should be performed within a certified chemical fume hood to prevent the inhalation of dust.[1]
Waste Segregation and Containment: The First Step of Disposal
Proper disposal begins at the point of generation. Haphazardly mixing chemical waste streams is a dangerous practice that can lead to unforeseen chemical reactions and complicates the final disposal process.
Protocol for Waste Collection:
-
Designated Waste Container: All 2-Aminoisocytosine waste, including unused product, contaminated consumables (e.g., weigh boats, pipette tips, gloves), and spill cleanup materials, must be collected in a designated, sealable hazardous waste container.[2]
-
Container Compatibility: The container must be made of a material compatible with the chemical. High-density polyethylene (HDPE) is a suitable choice.
-
Labeling: The container must be clearly and accurately labeled. Per EPA and OSHA regulations, the label must include:
-
The words "Hazardous Waste ".
-
The full chemical name: "2-Aminoisocytosine ".
-
The specific hazard warnings: "Harmful if Swallowed ", "Causes Serious Eye Irritation ".[1]
-
-
Segregation: Do not mix 2-Aminoisocytosine waste with other chemical waste streams, particularly strong oxidizing agents, unless explicitly permitted by your institution's Environmental Health and Safety (EHS) office.[2] Incompatible materials must be kept separate to prevent dangerous reactions.
This waste container must be kept in a designated Satellite Accumulation Area (SAA) within the laboratory, which is at or near the point of waste generation.[3]
Step-by-Step Disposal Protocol
Under no circumstances should 2-Aminoisocytosine be disposed of down the drain or in regular trash.[2] The required method of disposal is through your institution's hazardous waste management program, which typically involves a licensed professional waste disposal service.
Operational Steps for Disposal:
-
Containment: Ensure all solid waste and contaminated materials are securely sealed within the properly labeled hazardous waste container described in Section 3. Keep the container closed when not in use.
-
Spill Management (Small Spills):
-
Ensure proper PPE is worn.
-
Avoid generating dust.
-
Gently cover the spill with an inert absorbent material (e.g., vermiculite, sand, or commercial sorbent pads).
-
Carefully sweep or vacuum the absorbed material into the designated hazardous waste container.[1][2]
-
Clean the spill area with soap and water, and collect the cleaning materials as hazardous waste.
-
-
Documentation: Maintain a log of the waste being added to the container, including approximate quantities and dates. This is a requirement under the Resource Conservation and Recovery Act (RCRA).
-
Arrange for Pickup: Once the container is full, or approaching the storage time limit (typically 12 months in an SAA as long as volume limits are not exceeded), contact your institution's EHS office to arrange for pickup.[2] Do not move the waste to another room for storage.
-
Final Disposal Method: The EHS-contracted service will transport the waste for final disposal, which is typically high-temperature chemical incineration. This method is effective for destroying organic compounds and preventing their release into the environment.
Decision Workflow for 2-Aminoisocytosine Waste Management
The following diagram illustrates the logical flow for handling and disposing of 2-Aminoisocytosine waste in a laboratory setting.
Caption: Decision workflow for handling and disposal of 2-Aminoisocytosine.
Regulatory Compliance
All laboratory waste disposal is governed by strict federal and state regulations. The primary federal regulation is the Resource Conservation and Recovery Act (RCRA), enforced by the U.S. Environmental Protection Agency (EPA). Key compliance points include:
-
Generator Status: Your facility is classified as a Very Small, Small, or Large Quantity Generator based on the amount of hazardous waste produced monthly, which dictates specific storage and reporting requirements.[3]
-
Documentation: Accurate records of waste generation and disposal are mandatory.
-
Training: All personnel who generate hazardous waste must receive proper training on handling and emergency procedures.
By adhering to the protocols in this guide and consulting with your institution's EHS department, you ensure compliance with these legal mandates, safeguarding your institution from potential fines and penalties.
References
-
Safety Data Sheet Isocytosine . MetaSci. [Link]
-
Laboratory Waste Management: The New Regulations . MedicalLab Management. [Link]
-
Standard Guide for Disposal of Laboratory Chemicals and Samples . ASTM International. [Link]
Sources
A Researcher's Guide to Handling 2-Aminoisocytosine: Essential Safety Protocols and PPE
Navigating the complexities of chemical handling requires a proactive and informed approach to safety. For researchers, scientists, and drug development professionals working with 2-Aminoisocytosine (also known as Cytosine, CAS No. 71-30-7), understanding the appropriate Personal Protective Equipment (PPE) is the cornerstone of a safe laboratory environment. This guide provides a detailed, field-tested framework for the safe handling of 2-Aminoisocytosine, moving beyond a simple checklist to explain the critical reasoning behind each procedural step.
Hazard Assessment: A Case for Precaution
The available safety data for 2-Aminoisocytosine presents a mixed hazard profile. While some safety data sheets (SDS) classify it as not a hazardous substance or mixture[1][2], other sources indicate potential risks. For instance, one SDS describes it as hazardous in case of eye contact (irritant), slightly hazardous in case of skin contact (irritant), and hazardous if ingested. A related isomer, Isocytosine, is listed as harmful if swallowed and causing serious eye irritation[3].
This discrepancy underscores a critical principle in laboratory safety: when data is conflicting or incomplete, a conservative approach is necessary. The absence of established Occupational Exposure Limits (OELs) from bodies like OSHA, NIOSH, or ACGIH further reinforces the need to handle this compound with diligence to minimize any potential exposure[1][2][3][4]. Therefore, the following PPE recommendations are based on a precautionary principle to safeguard against irritation, inhalation of dust, and accidental ingestion.
Engineering Controls: The First Line of Defense
Before any personal protective equipment is worn, engineering controls should be in place to minimize airborne contaminants.
-
Ventilation: Always handle 2-Aminoisocytosine in a well-ventilated area. For procedures that may generate dust, such as weighing or transferring powder, a certified chemical fume hood is strongly recommended to keep airborne concentrations low[5].
-
Safety Equipment: Ensure that a fully functional eyewash station and safety shower are readily accessible and in close proximity to the workstation[5].
Personal Protective Equipment (PPE): Your Essential Barrier
A comprehensive PPE strategy is crucial for preventing direct contact with 2-Aminoisocytosine. The following table summarizes the required equipment, which will be discussed in further detail.
| Body Part | Required Protection | Standard/Specification | Causality |
| Eyes/Face | Chemical safety goggles with side protection or a face shield. | Must conform to OSHA 29 CFR 1910.133 or European Standard EN166.[1][5] | Protects against potential eye irritation from dust particles or splashes[3]. |
| Skin/Body | Nitrile rubber gloves and a fully buttoned lab coat. | Gloves tested according to EN 374.[6][7] | Prevents potential skin irritation and contamination of personal clothing. Nitrile rubber is recommended for its chemical resistance.[6][7] |
| Respiratory | Dust mask or respirator with a particulate filter. | NIOSH- or CEN-certified respirator.[3] A P1 particulate filter (EN 143) is suitable for dust formation.[6][7] | Necessary when handling the powder outside of a fume hood or when dust generation is likely, to prevent inhalation[6][7]. |
Eye and Face Protection
Given the documented risk of eye irritation, appropriate eye protection is mandatory[3]. Standard safety glasses are insufficient; chemical safety goggles that form a seal around the eyes are required to provide adequate protection from airborne dust particles. For operations with a higher risk of splashing, a full-face shield should be worn in conjunction with safety goggles.
Skin and Body Protection
A clean, fully buttoned lab coat serves as a removable barrier to protect your skin and personal clothing from contamination.
Gloves are a critical component of skin protection. Nitrile gloves are recommended, and one SDS specifies a material thickness of >0.11 mm with a breakthrough time of over 480 minutes[6][7]. It is imperative to inspect gloves for any signs of degradation or punctures before use. Always practice proper glove removal techniques to avoid contaminating your skin.
Respiratory Protection
While 2-Aminoisocytosine is a solid, the fine powder can become airborne during handling, posing an inhalation risk. If work cannot be conducted within a fume hood, respiratory protection is necessary[6]. A NIOSH-certified dust respirator or a respirator equipped with a P1 particulate filter is recommended to prevent the inhalation of airborne particles[3][6][7].
Procedural Workflow: Donning and Doffing PPE
The order in which PPE is put on (donning) and taken off (doffing) is critical to prevent cross-contamination. Following a standardized procedure ensures that contaminants are not transferred from the PPE to your skin or clothing.
Caption: Standard sequence for donning and doffing Personal Protective Equipment.
Emergency Protocols: Spill and Exposure Response
Immediate and correct action is critical in an emergency.
Spill Response
-
Evacuate and Ventilate: Clear the immediate area of all personnel and ensure it is well-ventilated[5].
-
Contain: Cover drains to prevent environmental contamination[6].
-
Clean-up: For a dry spill, carefully sweep or take up the material mechanically, avoiding dust generation[1][6][7]. Do not use combustible materials like paper towels for the initial cleanup of a pile. Place the spilled material into a suitable, labeled container for disposal[1][6].
-
Decontaminate: Clean the affected area thoroughly.
First Aid and Exposure
-
Eye Contact: Immediately flush the eyes with plenty of water for at least 15 minutes, holding the eyelids open. Remove contact lenses if present and easy to do. Seek immediate medical attention[3].
-
Skin Contact: Take off all contaminated clothing immediately. Wash the affected skin gently and thoroughly with running water and non-abrasive soap. If irritation persists, seek medical attention.
-
Inhalation: Move the person to fresh air. If they are not breathing, perform artificial respiration. Seek immediate medical attention[1].
-
Ingestion: Do NOT induce vomiting. Rinse the mouth with water. Seek immediate medical attention[3].
Waste Disposal
All waste contaminated with 2-Aminoisocytosine, including used PPE and spill cleanup materials, must be considered chemical waste.
-
Containment: Place all waste into appropriately labeled, sealed containers for disposal[6][7].
-
Regulations: Dispose of the material in accordance with all local, state, and federal regulations. Do not allow the product to enter drains or waterways[6][7].
By integrating these protocols into your daily laboratory operations, you create a self-validating system of safety that protects not only you but also your colleagues and your research. This commitment to procedural excellence is the foundation of scientific integrity and trust.
References
- Carl ROTH. (n.d.). Safety Data Sheet: 2-Aminoisobutyric acid.
- Spectrum Chemical Mfg. Corp. (2003). Material Safety Data Sheet: Cytosine.
- Sigma-Aldrich. (2024). Safety Data Sheet: Cytosine.
- Fisher Scientific. (2025). Safety Data Sheet: Cytosine.
-
Occupational Safety and Health Administration. (n.d.). Permissible Exposure Limits – OSHA Annotated Table Z-1. Retrieved from [Link]
- Thermo Fisher Scientific. (2025). Safety Data Sheet: 2-Amino-2'-deoxyadenosine.
- Carl ROTH. (n.d.). Safety Data Sheet: 2-Aminoisobutyric acid.
- Metascience. (n.d.). Safety Data Sheet: Isocytosine.
- GERPAC. (2013). Personal protective equipment for preparing toxic drugs.
- Toxicology MSDT. (n.d.). Occupational (Workplace) Exposure Standards/Guidelines/Approaches.
-
Occupational Safety and Health Administration. (n.d.). Permissible Exposure Limits - Annotated Tables. Retrieved from [Link]
- WorkSafeBC. (2025). Table of exposure limits for chemical and biological substances.
-
Lovsin, B., & Dolan, D. G. (2016). Setting Occupational Exposure Limits for Genotoxic Substances in the Pharmaceutical Industry. Toxicological Sciences, 151(1), 2–9. [Link]
- BenchChem. (n.d.). Personal protective equipment for handling 2'-Aminoacetophenone.
- University of Illinois. (n.d.). Biosafety Level 2 Guide.
Sources
- 1. fishersci.com [fishersci.com]
- 2. fishersci.com [fishersci.com]
- 3. sds.metasci.ca [sds.metasci.ca]
- 4. Permissible Exposure Limits - Annotated Tables | Occupational Safety and Health Administration [osha.gov]
- 5. pdf.benchchem.com [pdf.benchchem.com]
- 6. carlroth.com:443 [carlroth.com:443]
- 7. carlroth.com:443 [carlroth.com:443]
Retrosynthesis Analysis
AI-Powered Synthesis Planning: Our tool employs the Template_relevance Pistachio, Template_relevance Bkms_metabolic, Template_relevance Pistachio_ringbreaker, Template_relevance Reaxys, Template_relevance Reaxys_biocatalysis model, leveraging a vast database of chemical reactions to predict feasible synthetic routes.
One-Step Synthesis Focus: Specifically designed for one-step synthesis, it provides concise and direct routes for your target compounds, streamlining the synthesis process.
Accurate Predictions: Utilizing the extensive PISTACHIO, BKMS_METABOLIC, PISTACHIO_RINGBREAKER, REAXYS, REAXYS_BIOCATALYSIS database, our tool offers high-accuracy predictions, reflecting the latest in chemical research and data.
Strategy Settings
| Precursor scoring | Relevance Heuristic |
|---|---|
| Min. plausibility | 0.01 |
| Model | Template_relevance |
| Template Set | Pistachio/Bkms_metabolic/Pistachio_ringbreaker/Reaxys/Reaxys_biocatalysis |
| Top-N result to add to graph | 6 |
Feasible Synthetic Routes




Featured Recommendations
| Most viewed |
|
|
|---|---|---|
| Most popular with customers |
|
Haftungsausschluss und Informationen zu In-Vitro-Forschungsprodukten
Bitte beachten Sie, dass alle Artikel und Produktinformationen, die auf BenchChem präsentiert werden, ausschließlich zu Informationszwecken bestimmt sind. Die auf BenchChem zum Kauf angebotenen Produkte sind speziell für In-vitro-Studien konzipiert, die außerhalb lebender Organismen durchgeführt werden. In-vitro-Studien, abgeleitet von dem lateinischen Begriff "in Glas", beinhalten Experimente, die in kontrollierten Laborumgebungen unter Verwendung von Zellen oder Geweben durchgeführt werden. Es ist wichtig zu beachten, dass diese Produkte nicht als Arzneimittel oder Medikamente eingestuft sind und keine Zulassung der FDA für die Vorbeugung, Behandlung oder Heilung von medizinischen Zuständen, Beschwerden oder Krankheiten erhalten haben. Wir müssen betonen, dass jede Form der körperlichen Einführung dieser Produkte in Menschen oder Tiere gesetzlich strikt untersagt ist. Es ist unerlässlich, sich an diese Richtlinien zu halten, um die Einhaltung rechtlicher und ethischer Standards in Forschung und Experiment zu gewährleisten.
