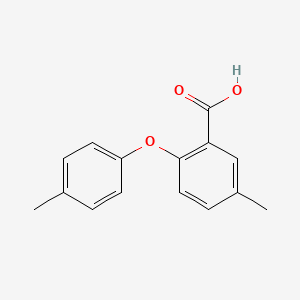
2-(4-Methylphenoxy)-5-methyl-benzoic acid
カタログ番号 B8525668
分子量: 242.27 g/mol
InChIキー: PYKAWUBGSXYSCD-UHFFFAOYSA-N
注意: 研究専用です。人間または獣医用ではありません。
Patent
US04091023
Procedure details


393 G. of 2-iodo-5-methyl-benzoic acid in 150 ml. of nitrobenzene are heated to 145° C. 138 G. of potassium carbonate are added thereto in small portions with stirring. Subsequently, 156 ml. of 4-methyl-phenol and 276 g. of potassium carbonate are added. To the resulting mixture, 3 g. of copper powder are carefully added, and the mixture is subsequently stirred at 165° C. for 20 minutes. After cooling, 1.25 liters of water are added to the mixture which is then extracted twice with ether. The aqueous phase is acidified with hydrochloric acid and extracted twice with ether. The ethereal solutions are washed with water, dried over sodium sulfate and concentrated in vacuo. The residue (brown crystals) is recrystallized from 1100 ml. of methanol and 700 ml. of water, and there is obtained 2-(4-methylphenoxy)-5-methyl-benzoic acid, which after repeated recrystallization from methanol/water, melts at 113°-115° C.

Name
copper
Quantity
0 (± 1) mol
Type
catalyst
Reaction Step Six

Identifiers
|
REACTION_CXSMILES
|
I[C:2]1[CH:10]=[CH:9][C:8]([CH3:11])=[CH:7][C:3]=1[C:4]([OH:6])=[O:5].[N+](C1C=CC=CC=1)([O-])=O.C(=O)([O-])[O-].[K+].[K+].[CH3:27][C:28]1[CH:33]=[CH:32][C:31]([OH:34])=[CH:30][CH:29]=1>[Cu].O>[CH3:27][C:28]1[CH:33]=[CH:32][C:31]([O:34][C:2]2[CH:10]=[CH:9][C:8]([CH3:11])=[CH:7][C:3]=2[C:4]([OH:6])=[O:5])=[CH:30][CH:29]=1 |f:2.3.4|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
IC1=C(C(=O)O)C=C(C=C1)C
|
Step Two
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
[N+](=O)([O-])C1=CC=CC=C1
|
Step Three
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C([O-])([O-])=O.[K+].[K+]
|
Step Four
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
CC1=CC=C(C=C1)O
|
Step Five
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C([O-])([O-])=O.[K+].[K+]
|
Step Six
|
Name
|
copper
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
catalyst
|
|
Smiles
|
[Cu]
|
Step Seven
|
Name
|
|
|
Quantity
|
1.25 L
|
|
Type
|
solvent
|
|
Smiles
|
O
|
Conditions
Stirring
|
Type
|
CUSTOM
|
|
Details
|
in small portions with stirring
|
|
Rate
|
UNSPECIFIED
|
|
RPM
|
0
|
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
STIRRING
|
Type
|
STIRRING
|
|
Details
|
the mixture is subsequently stirred at 165° C. for 20 minutes
|
|
Duration
|
20 min
|
TEMPERATURE
|
Type
|
TEMPERATURE
|
|
Details
|
After cooling
|
EXTRACTION
|
Type
|
EXTRACTION
|
|
Details
|
is then extracted twice with ether
|
EXTRACTION
|
Type
|
EXTRACTION
|
|
Details
|
extracted twice with ether
|
WASH
|
Type
|
WASH
|
|
Details
|
The ethereal solutions are washed with water
|
DRY_WITH_MATERIAL
|
Type
|
DRY_WITH_MATERIAL
|
|
Details
|
dried over sodium sulfate
|
CONCENTRATION
|
Type
|
CONCENTRATION
|
|
Details
|
concentrated in vacuo
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
The residue (brown crystals) is recrystallized from 1100 ml
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
CC1=CC=C(OC2=C(C(=O)O)C=C(C=C2)C)C=C1
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
