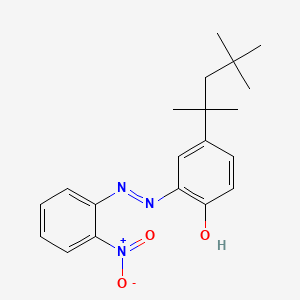
2-((2-Nitrophenyl)azo)-4-(1,1,3,3-tetramethylbutyl)phenol
Katalognummer B1605365
Molekulargewicht: 355.4 g/mol
InChI-Schlüssel: HOWCUYQDKCPWDV-UHFFFAOYSA-N
Achtung: Nur für Forschungszwecke. Nicht für den menschlichen oder tierärztlichen Gebrauch.
Patent
US04780541
Procedure details


2-nitro-2'-hydroxy-5'-methylazobenzene 12.9 g was added to a mixture of methanol 60 ml, water 30 ml and 97% sodium hydroxide 12.4 g, and the resultant mixure was stirred while raising temperature to 65° C. Thereafter, the mixture was cooled to 40° C., and 9-fluorenone 0.8 g and then 80% paraformaldehyde 2.1 g were added to the mixture for 1 hour. The resultant mixture was then heated to the boiling point (75° C.), and was stirred at the boiling point for 6 hours, thus almost all of the azobenzene having disappeared to produce 2-(2-hydroxy-5-methylphenyl)benzotriazole-N-oxide (Process (b) having completed).

[Compound]
Name
resultant mixture
Quantity
0 (± 1) mol
Type
reactant
Reaction Step Three

Identifiers
|
REACTION_CXSMILES
|
[N+:1](C1C=CC=CC=1N=NC1C=C(C)C=CC=1O)([O-:3])=[O:2].[OH-:20].[Na+].[CH:22]1[C:34]2[C:33](=O)[C:32]3[C:27](=CC=C[CH:31]=3)[C:26]=2C=CC=1.[CH2:36]=O.[N:38]([C:46]1[CH:51]=[CH:50][CH:49]=[CH:48][CH:47]=1)=[N:39][C:40]1[CH:45]=[CH:44][CH:43]=[CH:42][CH:41]=1>O.CO>[N+:1]([C:51]1[CH:50]=[CH:49][CH:48]=[CH:47][C:46]=1[N:38]=[N:39][C:40]1[CH:45]=[C:44]([C:32]([CH2:33][C:34]([CH3:26])([CH3:22])[CH3:36])([CH3:31])[CH3:27])[CH:43]=[CH:42][C:41]=1[OH:20])([O-:3])=[O:2] |f:1.2|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
12.9 g
|
|
Type
|
reactant
|
|
Smiles
|
[N+](=O)([O-])C1=C(C=CC=C1)N=NC1=C(C=CC(=C1)C)O
|
|
Name
|
|
|
Quantity
|
12.4 g
|
|
Type
|
reactant
|
|
Smiles
|
[OH-].[Na+]
|
|
Name
|
|
|
Quantity
|
30 mL
|
|
Type
|
solvent
|
|
Smiles
|
O
|
|
Name
|
|
|
Quantity
|
60 mL
|
|
Type
|
solvent
|
|
Smiles
|
CO
|
Step Two
|
Name
|
|
|
Quantity
|
0.8 g
|
|
Type
|
reactant
|
|
Smiles
|
C1=CC=CC=2C3=CC=CC=C3C(C12)=O
|
|
Name
|
|
|
Quantity
|
2.1 g
|
|
Type
|
reactant
|
|
Smiles
|
C=O
|
Step Three
[Compound]
|
Name
|
resultant mixture
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
|
Step Four
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
N(=NC1=CC=CC=C1)C1=CC=CC=C1
|
Conditions
Temperature
|
Control Type
|
UNSPECIFIED
|
|
Setpoint
|
65 °C
|
Stirring
|
Type
|
CUSTOM
|
|
Details
|
the resultant mixure was stirred
|
|
Rate
|
UNSPECIFIED
|
|
RPM
|
0
|
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
TEMPERATURE
|
Type
|
TEMPERATURE
|
|
Details
|
Thereafter, the mixture was cooled to 40° C.
|
STIRRING
|
Type
|
STIRRING
|
|
Details
|
was stirred at the boiling point for 6 hours
|
|
Duration
|
6 h
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
[N+](=O)([O-])C1=C(C=CC=C1)N=NC1=C(C=CC(=C1)C(C)(C)CC(C)(C)C)O
|
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
