Patent
US06153786
Procedure details


0.42 g (0.36 mmol) of tetrakis(triphenylphosphine)palladium(0), 20 mg (0.16 mmol) of 4-dimethylamino-pyridine and 2.87 g (18.5 mmol) of 1,2,2,6,6-penta-methylpiperidine are introduced into 30 ml of dichloromethane in a 60 ml autoclave under argon. Then 10 bar of acetylene are injected, and the autoclave is heated to 40° C. 5 g (36.6 mmol) of n-butyl chloroformate are pumped in over the course of 10 min, and then acetylene is further injected to 20 bar. The amount of acetylene taken up is replenished hourly over the course of 24 h, and, after cooling, the reaction discharge is flushed with nitrogen and the reaction mixture is distilled. n-Butyl propiolate is isolated in 85% yield.


Name
Yield
85%
Identifiers
|
REACTION_CXSMILES
|
CN1C(C)(C)CC[CH2:4][C:3]1(C)C.C#C.Cl[C:15]([O:17][CH2:18][CH2:19][CH2:20][CH3:21])=[O:16]>CN(C)C1C=CN=CC=1.C1C=CC([P]([Pd]([P](C2C=CC=CC=2)(C2C=CC=CC=2)C2C=CC=CC=2)([P](C2C=CC=CC=2)(C2C=CC=CC=2)C2C=CC=CC=2)[P](C2C=CC=CC=2)(C2C=CC=CC=2)C2C=CC=CC=2)(C2C=CC=CC=2)C2C=CC=CC=2)=CC=1.ClCCl>[C:15]([O:17][CH2:18][CH2:19][CH2:20][CH3:21])(=[O:16])[C:3]#[CH:4] |^1:34,36,55,74|
|
Inputs
Step One
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C#C
|
Step Two
|
Name
|
|
|
Quantity
|
5 g
|
|
Type
|
reactant
|
|
Smiles
|
ClC(=O)OCCCC
|
Step Three
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C#C
|
Step Four
|
Name
|
|
|
Quantity
|
0 (± 1) mol
|
|
Type
|
reactant
|
|
Smiles
|
C#C
|
Step Five
|
Name
|
|
|
Quantity
|
2.87 g
|
|
Type
|
reactant
|
|
Smiles
|
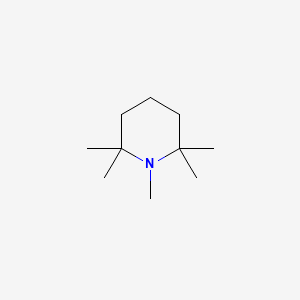
CN1C(CCCC1(C)C)(C)C
|
|
Name
|
|
|
Quantity
|
20 mg
|
|
Type
|
catalyst
|
|
Smiles
|
CN(C1=CC=NC=C1)C
|
|
Name
|
|
|
Quantity
|
0.42 g
|
|
Type
|
catalyst
|
|
Smiles
|
C=1C=CC(=CC1)[P](C=2C=CC=CC2)(C=3C=CC=CC3)[Pd]([P](C=4C=CC=CC4)(C=5C=CC=CC5)C=6C=CC=CC6)([P](C=7C=CC=CC7)(C=8C=CC=CC8)C=9C=CC=CC9)[P](C=1C=CC=CC1)(C=1C=CC=CC1)C=1C=CC=CC1
|
|
Name
|
|
|
Quantity
|
30 mL
|
|
Type
|
solvent
|
|
Smiles
|
ClCCl
|
Conditions
Temperature
|
Control Type
|
UNSPECIFIED
|
|
Setpoint
|
40 °C
|
Other
|
Conditions are dynamic
|
1
|
|
Details
|
See reaction.notes.procedure_details.
|
Workups
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
are pumped in over the course of 10 min
|
|
Duration
|
10 min
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
taken up is replenished hourly over the course of 24 h
|
|
Duration
|
24 h
|
TEMPERATURE
|
Type
|
TEMPERATURE
|
|
Details
|
after cooling
|
CUSTOM
|
Type
|
CUSTOM
|
|
Details
|
the reaction discharge is flushed with nitrogen
|
DISTILLATION
|
Type
|
DISTILLATION
|
|
Details
|
the reaction mixture is distilled
|
Outcomes
Product
|
Name
|
|
|
Type
|
product
|
|
Smiles
|
C(C#C)(=O)OCCCC
|
Measurements
| Type | Value | Analysis |
|---|---|---|
| YIELD: PERCENTYIELD | 85% |
Source
|
Source
|
Open Reaction Database (ORD) |
|
Description
|
The Open Reaction Database (ORD) is an open-access schema and infrastructure for structuring and sharing organic reaction data, including a centralized data repository. The ORD schema supports conventional and emerging technologies, from benchtop reactions to automated high-throughput experiments and flow chemistry. Our vision is that a consistent data representation and infrastructure to support data sharing will enable downstream applications that will greatly improve the state of the art with respect to computer-aided synthesis planning, reaction prediction, and other predictive chemistry tasks. |
